C++ 内存模型
1. 前言
对于底层开发程序来讲,程序员一定要知道程序运行在内存上的分布,这特别重要。同样,对于中级语言C++来讲,内存模型很重要!内存模型很重要!内存模型很重要! 所以今天我们来一起分析和总结一下C++程序中的内存分布情况。
2. 内核空间&用户空间
C++的每个程序运行起来以后,它将拥有自己独立的虚拟地址空间。这个空间的大小与操作系统的位数有关。
例如在32位的系统中,程序可寻址范围是0-232-1位,也就是0X00000000~0XFFFFFFFF,共有4GB大小。其中很重要的一部分是给系统内核使用的内核空间。在32位的windows操作系统中,高地址的2GB空间就是给内核使用的内核空间,用户程序空间只有2GB;而32位的linux内核空间只有1GB大小,也就是用户空间有3GB大小。
在64位系统中,可寻址范围就是0~264-1,这就要大得多,相应的用户的使空间也会很大。
我们的运行的程序也都会在用户空间中分配一块虚拟内存来运行。

3. C++运行程序内存分布
对于所有C++程序员,都应该知道,程序运行的时候,其实虚拟空间中是分为5个区域的分别是:堆区(heap)、栈区(stack)、静态存储区、常量存储区、代码区。
3.1 堆区(heap)
堆区,也叫动态内存分配区。程序员手动申请(new或者malloc)的空间都会是在堆区,堆区的内存不用编译器去维护,需要程序员手动去维护。由于堆区的内存编译器不维护,所以也需要通过delete或free来手动释放申请的空间,注意,这个申请与释放必须是成对的,只new(malloc)不delete(free)会造成内存泄漏;没有new (malloc)就delete(free)或者多次delete(free)就会造成程序崩溃。
堆区里的变量的生存周期是由程序员决定的,为从new(malloc)开始,直到手动调用delete(free)为止。这时候可能有人要问了,如果程序员只new(malloc),永远都不delete(free)怎么办?这块内存是不是永远就失去控制了?当然不是!如果我们不释放内存,程序将在退出的时候将全部分配的虚拟内存进行回收,当然也会把堆区的内存进行回收!(但是,良好的编程习惯是:需要的时候申请动态内存,如果不需要,就将其释放掉,否则就是内存泄漏。)
特点:堆区的内存是由低向高进行分配;空间比较大;没有栈区的效率高;
接下来我们来做个试验验证一下堆区内存从低向高分配的特点:
代码:
int *a = new int(1);
printf("the location of a is: %p \n", a);
int *b = new int(1);
printf("the location of b is: %p \n", b);
int *c = new int(1);
printf("the location of c is: %p \n", c);
int *d = new int(1);
printf("the location of d is: %p \n", d);
static int *e = new int(1);
printf("the location of e is: %p \n", e);
在代码里,我们分别使用new进行申请了 a,b,c,d,e五块内存,其中a,b,c,d是普通的指针,e为静态的指针;
我们来看一下结果:
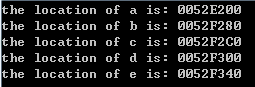
我们很直观的能够看到,使用new申请的五块内存,无论是否为静态指针,结果都是在堆上,从低到高申请。
此时,我们需要注意的是,每次运行程序,既是同一个程序,同一个电脑,他们申请的内存地址都不相同。这个内存地址与每次程序运行,程序所分配的私有用户空间有关;所有申请的地址,无论堆栈,都必须是在用户空间内。
这时候可能有c++的小伙伴会问了,前四块申请的普通内存地址都在堆区没问题。最后一个明明是static类型的指针。我们可是学过的,static 关键字可是有以下几个特征的,我们一起来复习一下static 关键字:
static 特点:
- 生存周期长,为整个程序运行期。即,程序启动时候创建(默认值为0),程序结束时候销毁。
- 隐藏性,使用static定义且非public类型的字段,只有本模块的代码可以访问。(其他文件要想访问,须使用public声明)
- static定义的变量(或函数)属于类的,非类所创建的具体对象。使用是只能是class::xxx 。
- 唯一性,static定义的变量,在内存中只有一份,具有唯一性。
- 存储在静态存储区(全局数据区)。
回忆了一下static的主要特性,大部分c++都会认为static 存储在静态存储区,或者叫全局数据区是没有问题的,可能会产生疑问,怎么到你这里的static就存储在了堆区呢?
首先,这种常规理解是正确的,不过不全面,static 的变量,也是一分为二的。这里是局部的静态变量,还有一种是全局的静态变量。它们存储的区域是不一样的。往下看,我们待会会讲到全局static的变量存储的地方。
3.2 栈区(static)
程序的栈区是由处理器直接支持维护的。堆栈在内存中是由高地址向低地址扩展(正好与堆区相反)。因此栈顶地址是不短减少的,越后入栈的数据,所处的地址也就越低,但是效率比较高。
我们平时会经常听到出栈、压栈这样的词语。这里也稍微拓展一下我们所谓的栈:
栈,是一种存储受限的线性数据结构,在存储和访问数据的时候,只能访问栈的一端。我们可以理解成为,栈就是一摞盘子,如果拿盘子的话,只能拿最上面的;同样,如果放盘子的话,也只能放到最上面。由于这一特点,可以总结为:栈是一种先进后出(FILO(first in / last out ))或者叫后进先出(LIFO(last in / first out))的后进的数据结构。
那么栈的主要操作有下面几种:
- push : 向栈顶插入一个元素(摞一个盘子上去)
- top : 获取栈顶元素 的值(看一下最上面的盘子里有什么)
- pop : 取出栈顶元素 (拿走最上面的盘子)
- clear : 清空栈 (拿走所有的盘子)
- isEmpyt: 判断栈是否为空 (看一下是否还有盘子)
到这里,既是非C++的程序员,也大概能够明白了什么叫栈以及栈的主要特性。接下来我们更加深入一下,来看看是怎么实现的。
和栈操作相关的两个寄存器分别是EBP寄存器与ESP寄存器,如果没有学过底层的小伙伴,可以简单的理解成为这就是两个指针就可以了。ESP寄存器总是指向栈顶。
执行PUSH命令,就向栈里面压入数据,这时候ESP要减4(因为栈是向下分配的,所以要减),然后将数据拷贝到ESP指向的地址。
执行POP命令时,首先将ESP指向的数据拷贝到内存地址中(或者寄存器中),然后ESP加4(出栈)。
EBP寄存器是用于访问栈中的数据的,它指向栈中的某个位置,函数的参数地址比EBP的值高,而函数的局部变量地址比EBP的值低,因此参数或局部变量总是通过EBP加减一定的偏移量来访问的。例如,要访问第一个参数应该为EBP +8。
这时候,我们已经从浅到深理解了栈了,也知道栈是由编译器维护的。那么栈中到底存储了什么数据呢?
我们总结一下大概包括:函数的参数,函数的局部变量,寄存器的值(用以恢复寄存器),函数返回的地址以及用于结构化异常处理的数据等。
这些设局按照一定的顺序组织在一起的,哦们就叫一个堆栈帧(stack frame)。一个堆栈阵对应一次函数的调用。一个堆栈帧对应一次函数的调用。我们来进一步说一下函数调用的过程:
在函数开始时,对应的堆栈帧已经完整的建立了(所有局部变量在函数帧建立时就已经分配好了空间,而不是随着函数的执行而不断创建和销毁的),在函数退出时,真个函数帧会被销毁。
举个简单例子来说明一下函数调用栈,在内存中的调用顺序:
代码:
int Fun2 (int arg1, int arg2)
{
int c = 10;
char d;
short e;
...
return 10;
}
int Fun1 (int arg1, int arg2)
{
int a = 1;
int b = 2;
int c = 3;
Fun2(30, 40);
...
return 10;
}
int main(int argc, char *argv[])
{
Fun1(10, 20);
return a.exec();
}
代码很简单,只是模拟一下函数调用的过程,其中:
- main函数中调用了Fun1函数;
- Fun1 中也调用了 Fun2函数;
- 这两个函数中都有参数,也都有返回值,里面也进行了临时变量的声明;
这个过程的栈是怎么调用的呢?我们简单地通过一张图来解释:
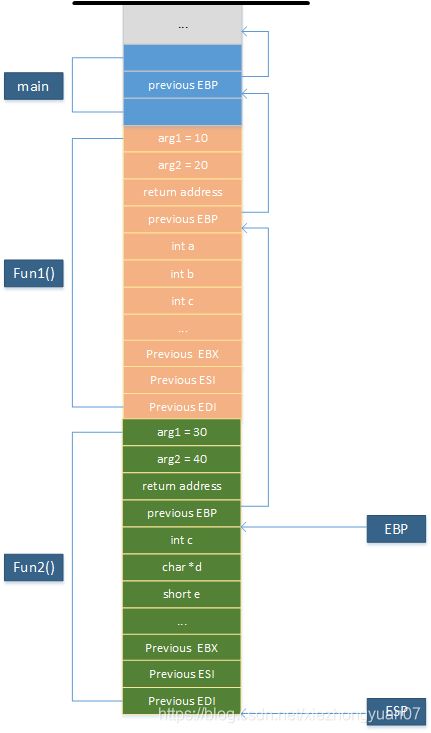
到这里,我们就能大致理解了,栈的工作原理了。这里就进行一点说明,就是最上面那条黑色实线。因为对于栈,是从高地址向低地址扩展的。所以它是有一个地址顶点的,对,那条黑线就代表栈的最高地址。
我们依旧通过代码来看一下临时变量在栈里面的存放顺序:
int a = 10;
printf("11 the location of a is: %p\n", &a);
int b = 10;
printf("22 the location of b is: %p \n", &b);
const int c = 10;
printf("33 the location of c is: %p \n", &c);
static int d = 10;
printf("44 the location of d is: %p \n", &d);
我们先分析一下代码:我们定义了4个变量,两个没有使用修饰关键字,一个const修饰,一个static修饰。那么它们会都放到栈区么?会依次降低地址么?
来看一下运行结果:
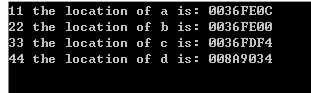
结果已经很明显了:
- 没有使用修饰的局部变量是放到了栈里面,从高地址向低地址扩展;
- 无论是否使用了const修饰,也都放到了栈里面。 与普通局部变量无异;
- 使用static修饰的局部变量明显的不在栈地址里面(上面我们也讲了一下原因,最后还会总结);
3.3 静态存储区
静态存储区是在程序编译的时候就已经分配好了,这块内存在整个程序运行时期都存在。这时候是不是感觉似曾相识的感觉? 这不就是上面我么说的 静态 static 关键字修饰的变量的特点吗? 没错,这意思就是生存周期长,为整个程序的运行期。
静态存储区主要用来存储静态数据、全局数据。
还是要再简单地解释一下
- 静态数据就是使用static修饰的变量。
- 全局数据就是在类之外声明的数量
也就是说,全局变量和静态变量的存储是放在一起的,初始化的全局变量和初始化的静态变量释放在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的区域。程序结束后由系统释放。
我们还是来使用程序来验证一下,虽然都是全局变量或者静态变量。但是初始化的数据放在一起,未初始化的数据放在一起:
先定义一些全局变量,然后打印出来,来分析一下地址:
int a = 0;
int b = 0;
static int c = 0;
int d;
int e;
static int f;
static int g = 0;
int _tmain(int argc, _TCHAR* argv[])
{
printf("111 the location of a is: %p \n", &a); //00D09498
printf("222 the location of b is: %p \n", &b); //00D0949C
printf("333 the location of c is: %p \n", &c); //00D094A0
printf("444 the location of d is: %p \n", &d); //00D094A4
printf("555 the location of e is: %p \n", &e); //00D094A8
printf("666 the location of f is: %p \n", &f); //00D094B0
printf("777 the location of g is: %p \n", &g); //00D094AC
}
我们这里定义了7个变量 ,其中,2个初始化的全局变量,2个未初始化的全局变量,2个初始化的静态变量,1个未初始化的静态变量。我们打乱顺序进行输出地址:
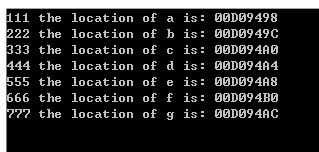
我们结合一下结果验证一下我们上面的结论:
- 两个初始化了的全局变量 a、b地址是连续的。
- 两个未初始化的全局变量 d、e地址是连续的。
- 两个初始化了的静态变量c、g的地址是在一起的。
- 剩下一个未初始化的静态变量f的地址适合未初始化的全局变量d、e在一起的。
- 他们都是在在全局/静态变量区存储的。
3.4 常量存储区
我们接下来说一下常量存储区,顾名思义,常量存储区就是文字常量(常量字符串)存放的地方,这是一块比较特殊的存储区,存放的常量不允许修改。程序结束后是由系统来释放。
比如字符串,具体的数等都放在常量数据区。
这时候可能又有小伙伴有问题了?你说的常量是具体的数字、字符串。那么我们知道一个关键字 const 表示常量。是不是使用const修饰的变量也会放在常量存储区?我们来一起来说明一下:
const 表示常量,这只是一个语言层面的约束。它只表示值不可变,我们可以使用const_cast 转换掉const 约束。
如果是局部变量的话,属于栈式内存分配,对于全局的const变量,可能被优化掉(比如直接变成立即数),所以在内存里可能没有它的位置,这时候也就是我们所谓的在代码段里了。我们认为这个变量就是一个代码。
所以无论编译器是否优化,const 修饰的变量也不会存放在常量存储区的。
3.5 代码区
最后来说一下这个代码区,代码区是用来粗放CPU执行的机器指令的,代码区是可共享的,并且是只读的。
=================================================================================
了解了程序运行时候内存分布情况,我们来做个实例来总结一下:
int a = 0; //全局初始化区
char *b; //全局未初始化区
static int c = 0; //全局初始化区
static int d; //全局未初始化区
int main()
{
int e; //栈
char f[]="abc"; //s 在栈里面 “abc” 在常量区
char *g; //栈
char *p3="123456"; //123456/0在常量区,p3在栈上。
static int c =0; //全局(静态)初始化区
p1 = (char *)malloc(10); //分配得来得10和20字节的区域就在堆区
p2 = (char *)malloc(20);
strcpy(p3,"123456"); //123456/0放在常量区,编译器可能会将它与p3所指向的"123456" 优化成一个地方。
}
总之,对于堆区、栈区和静态存储区它们之间最大的不同在于,栈的生命周期很短暂。但是堆区和静态存储区的生命周期相当于与程序的生命同时存在(如果您不在程序运行中间将堆内存delete的话),我们将这种变量或数据成为全局变量或数据。但是,对于堆区的内存空间使用更加灵活,因为它允许你在不需要它的时候,随时将它释放掉,而静态存储区将一直存在于程序的整个生命周期中。