【3D点云】PersFormer:基于透视Transformer的3D车道检测(ECCV2022)
文章目录
- 前言
- 一、引言
-
- 三点贡献:
- 二、相关工作
- 三、方法论
-
- 0.问题公式
- 1.方法概述
- 2.透视Transformer
- 3.同时进行二维和三维车道检测
- 4.预测损失
- 四. OpenLane 数据集
- 五、实验结果
-
- 3D结果对比(在OpenLane 数据集)
- 2D结果对比(在OpenLane 数据集)
- Apollo 3D Lane Synthetic 数据集评估
- appendix(实现细节)
前言
摘要:
题目:PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark
链接:https://arxiv.org/abs/2203.11089
代码:https://github.com/OpenPerceptionX/PersFormer_3DLane
OpenLane数据集:https://github.com/OpenPerceptionX/OpenLane
PersFormer:一种端到端单目3D车道检测器,利用透视Transformer实现前视(front view)图到BEV(鸟瞰)图的转换。
解决自主驾驶场景(上坡/下坡、颠簸等)中车道布局不准确的问题。使用相机参数关注相关的前视图局部区域,生成BEV特征:PersFormer采用统一的2D/3D锚定设计和同时检测2D/3D车道的辅助任务
除此之外,我们还发布了第一批大规模真实世界3D车道数据集:OpenLane,具有高质量的注释和场景多样性。开放式车道包含200000帧、超过880000个实例级车道和14个车道类别,以及场景标记和封闭路径对象注释。
一、引言
规划和控制中的下游模块通常要求车道位置采用正交鸟瞰图(BEV)的形式,而不是前视图表示。
我们将透视车道投影到BEV空间时,必须考虑车道线的高度。如图所示,如果忽略高度,在上坡/下坡情况下,车道将分叉/会聚,导致规划和控制模块中的不当行动决策。
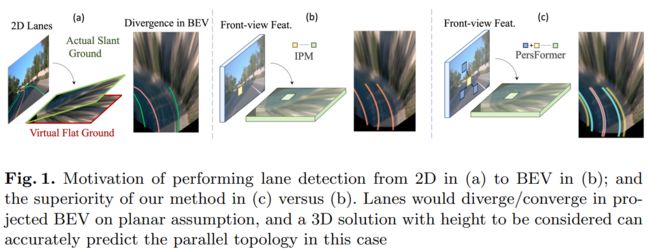
1.首先,我们将空间特征转换建模为一个学习过程,该过程具有注意机制,以捕获前视图特征中局部区域之间以及两个视图(前视图到BEV)之间的交互,从而能够生成细粒度的BEV特征表示。
2.构建了一个基于Transformer的模块来实现这一点,采用可变形注意机制显著降低计算内存需求,并通过交叉注意模块动态调整关键点,以捕获局部区域中的显著特征。与通过逆透视映射(IPM)的直接1-1变换相比,生成的特征更具代表性和鲁棒性,因为它关注周围的局部环境并聚合相关信息。
三点贡献:
1.一种新的基于Transformer的架构,用于实现特征的空间变换;
2.同时统一2D和3D车道检测的架构(结果SOTA);
3.OpenLane数据集,第一个具有高质量标记和巨大多样性的大规模真实3D车道数据集
二、相关工作
先前的工作将BEV原理引入管道,但他们没有考虑注意力机制和/或3D视觉几何(在这种情况下,是相机参数)。例如,3D LaneNet是用相机内/外矩阵建立的;IPM过程根据前视图特征生成虚拟BEV表示。DETR3D还考虑了摄像机的几何结构,并制定了一个可学习的3D到2D查询搜索注意方案。然而,没有用于鲁棒特征表示的显式BEV建模;聚集的特征可能无法在3D空间中正确表示。
如前所述,在某些情况下(上/下坡)平面假设并不总是保留凹凸。有些方法利用多模态或多视图传感器,如立体相机或激光雷达,获得三维地面拓扑。然而,这些传感器在硬件和计算资源方面存在高成本的不足,限制了它们的实际应用。最近,一些单目方法拍摄单个图像,并使用IPM预测三维空间中的车道。3D LaneNet是该领域的开创性工作,它使用一个简单的端到端神经网络,采用STN完成特征的空间投影。Gen LaneNet建立在3D LaneNet的基础上,设计了一个两级网络,用于解耦segmentation编码器和3D车道预测头。这两种方法在弯曲或挤压转弯情况下存在不正确的特征变换和不令人满意的性能。面对上述问题,我们引入PersFormer来提供更好的特征表示并优化锚定设计,以同时统一二维和三维车道检测。
三、方法论
0.问题公式
给定输入图像![]() PersFormer的目标是预测一组3D和2D车道:
PersFormer的目标是预测一组3D和2D车道:![]()
![]() 其中N_3D,N_2D分别是预定义BEV范围内的3D车道总数和原始图像空间(前视图)中的2D车道总数。从数学上讲,每个3D车道l_d由三维坐标的有序集:
其中N_3D,N_2D分别是预定义BEV范围内的3D车道总数和原始图像空间(前视图)中的2D车道总数。从数学上讲,每个3D车道l_d由三维坐标的有序集:
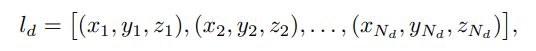 其中d是车道索引,Nd是该车道的最大采样点数。每个车道都有一个分类属性c(3D/2D),指示该车道的类型(例如,一条白色虚线)。此外,对于单个2D/3D车道中的每个点,都存在一个属性,指示该点是否可见.
其中d是车道索引,Nd是该车道的最大采样点数。每个车道都有一个分类属性c(3D/2D),指示该车道的类型(例如,一条白色虚线)。此外,对于单个2D/3D车道中的每个点,都存在一个属性,指示该点是否可见.
1.方法概述
如图所示,整体结构由三部分组成:主干、透视Transformer和车道检测头。主干输入为固定大小图片,生成多尺度前视图特征(利用ResNet变体),前视图空间特征可能存在比例变化、遮挡等缺陷。透视Transformer将特征作为输入,并借助相机的内部和外部参数生成BEV特征,而不是简单地一对一地投影。
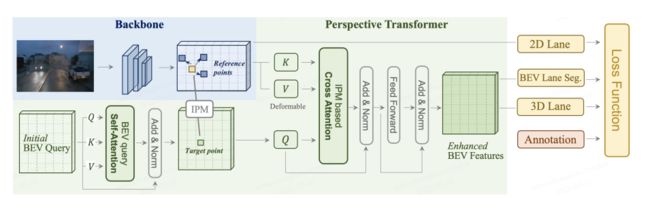
图释:PersFormer核心是学习从前视图到BEV空间的空间特征转换,以便通过关注参考点周围的局部上下文,在目标点生成的BEV特征将更具代表性。PersFormer由自注意力模块(用于与自己的BEV查询交互)和交叉关注模块(从基于IPM的前视图特征中提取键值对,以生成细粒度的BEV特征)组成。
2.透视Transformer
PersFormer的总体思想是:使用IPM中的坐标变换矩阵作为参考,通过关注前视图特征中的相关区域(局部上下文)来生成BEV特征表示。 PersFormer是一种空间变换方法(使用相机参数和数据驱动)
经典的IPM方法假设地面是平坦的,利用摄像机参数计算一组从前视图到BEV的坐标映射(BEV空间是在平面上定义的)。在前视特征图中的点p_fv及其坐标(u,v),IPM将点p_fv映射到BEV中对应的点p_bev,其中(x,y)是BEV中的坐标。该变换是通过内/外部摄像机实现的,在数学上可以表示为:
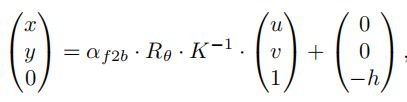
α表示前视图和BEV之间的比例因子,R_θ表示外参旋转矩阵,K表示内参矩阵,h表示摄像机高度。这样的转换对 PerFormer中的注意单元进行了很强的先验框架,以产生更有代表性的BEV特征。
PersForme的体系结构受到了 DETR 等流行方法的启发,由自注意模块和交叉注意模块组成。我们的查询没有隐式更新,而是被一个明确的含义所操纵——在BEV中检测物体或车道的物理位置。在自注意模块中 ,输出Q_bev通过(键、值、查询)输入的交互,可以描述为:
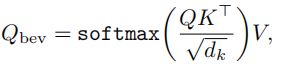
K、Q、V∈R(H_bev×W_bev×C)是在BEV中预定义的相同查询。在交叉注意力模块中,输入查询Q’_bev是几个附加层的结果,这些附加层将自我注意力输出Q_bev作为输入。Q′bev是一种明确的特征表示,因为bev中查询的生成是位置敏感的,因此应更加关注bev中的哪个部分。
下图描述了 交叉注意过程 中的特征转换过程和关键值对的生成。具体来说,给定目标BEV映射Q‘_bev中的一个查询点(x,y),我们将其投影到通过上述公式在前视图中对应的点(u,v)。根据点(u,v)学习一些偏移,以生成一组最相关的点。这些习得的点,以及(u,v)被定义为参考点。它们对bev空间中定义为目标点的查询点(x,y)贡献最大。参考点作为周围的上下文从透视图到BEV空间,对特征表示贡献最大的局部区域。它们是我们试图找到的期望键,它们的特征是交叉注意的值(value)模块。请注意,IPM中参考点的初始位置被用作坐标映射的初步位置;在学习过程中逐步调整该位置,这是可变形注意的核心作用。

生成交叉注意力中的key。BEV空间中的点(x、y)通过中间状态(x’、y’)投射前方对应的点(u、v);通过学习偏移,网络学习目标参考点从绿色矩形映射到黄色和相关的蓝色矩形作为transformer的key。交叉注意模块的输出可表述为:
![]()
其中F_bev∈R(H_bev×W_bev×C)是最终期望特征,用于后续3D车道检测头,Q‘bev表示输入查询,F_fv∈R(H_fv×W_fv×C)表示前视图特征,p_fv2bev是从前视图到BEV空间的IPM初始化的坐标映射。考虑了具有可变形单元的F_fv和p_fv2bev,得到了显式变换的BEV特征F_bev。
PersForme在 参考点中提取前视图特征,构建具有代表性的BEV特征。这种特征转换在一个通过Transformer的聚合精神被证明比基于IPM的跨视图投影性能更好。
3.同时进行二维和三维车道检测
一方面,在透视图中进行2D车道检测,是一般的高级视觉问题的一部分;另一方面,统一二维和3D任务自然是可行的,因为 the BEV features to predict 3D outputs descend from the counterpart in the 2D branch.(这块不太理解)
端到端统一框架将利用特性并从协同学习优化过程中获益,这在大多数多任务文献[33,59,28]中得到了证明。
统一anchor设计:实现统一框架的核心问题是在二维和三维结构中同时集成anchor。不幸的是,anchor在这两个域上通常不共享类似的分布。例如,流行的2D方法LaneATT解决了太多的锚点,跨越了图像中不同的方向;而最近的3D工作Gen-LaneNet放置的锚太少,在BEV中是平行和稀疏的。我们从几组锚点(这里组数设置为7)开始,在BEV空间中以不同的倾斜角度采样,然后投影到前视图中。下图阐述了二维和三维anchor的integrate:

首先将规划的anchor(红色)放在BEV空间(左),然后将它们投射到前视图(右)。
偏移量x_ik和u_ik(虚线)被预测为匹配GT(黄色和绿色)到anchor。这样就建立了对应关系,特性也一起优化。
每个anchor i 的视角位置的初始线(等距)用Xi_bev表示。与目标检测中的anchor回归类似,该网络预测了相对偏差x_i到初始位置Xi_bev;因此,沿x轴的合成车道预测为(x_i+Xi_bev)。每个车道用N_d个点表示。预测头部生成三个与车道形状相关的向量,如下:
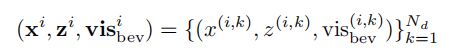
Z_i是三维意义上的车道高度,二进制vis(i,k)_bev表示车道线 i 中每个位置 k 是否可见(控制着车道的端点或长度)。注意,不需要预测沿y轴的车道位置,因为车道中N_d样本的每个y值都是预定义的-我们预测相应(固定)y位置的x(i,k)值。总之,车道在世界坐标系中的位置描述表示为(x_i + xi_bev,y,zi)。
2D anchor设计
anchor的描述和预测与三维视图中定义的相似,只是(u,v)为二维空间,没有高度。每个倾斜角度φ的3D锚Xi_bev对应一个倾斜角度θ的特定2D anchor Ui_fv;连接是通过上述公式(2)形成映射。我们通过设置同一组锚点,实现了同时统一二维和三维任务的目标。这样的设计将同时优化特特征,并使特征跨视图地对齐且具有代表性。
4.预测损失
在BEV条件下的二进制分割
与之前的许多工作一样,训练中增加更多的中间监督将提高网络的性能。车道检测属于图像分割,需要一般的大分辨率,我们将一个U-Net结构的头连接到生成的BEV特征之上。这一辅助任务是预测BEV的车道GT S_gt是一个二值图(从三维车道GT投影到BEV空间)。预测输出S_pred与S_gt相大小相同。
总体损失:给定一个图像输入及其GT,它最终计算出所有锚点的和“损失;损失是二维车道检测、三维车道检测和中间分割的可学习权重(α,β,γ)的结合:
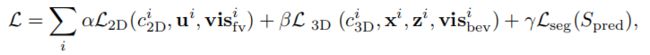
式中,c_i 分别为二维和三维域内的预测车道类别。上式输入的损失仅显示了预测部分(简洁起见,省略了GT)。二维/三维任务的分类损失是交叉熵;车道形状回归的损失是L1范数;车道能见度预测的损失是二元交叉熵;辅助头的损失是两个分割映射之间的二值交叉熵损失。
四. OpenLane 数据集
14个车道类别涵盖了广泛的车道类型,包括道路边缘。双黄色实心车道、单白色实心车道和虚线车道 (Double yellow solid lanes, single white solid and dash lanes)占近90条占总车道的百分比(可能导致长尾分布问题)。除车道外,还标注了:(a)场景标签,如天气和位置;(b)路径中最近的对象(CIPO),它被定义为最相关的目标w.r.t.也就是自车辆(ego vehicle),对于后续的模块非常实用。下图5(d)中给出了一个注释示例,以及图5(a-c)中现有的2D车道数据集中的一些典型样本。

五、实验结果
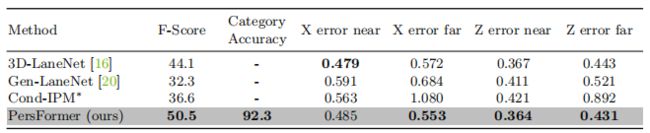
3D结果对比(在OpenLane 数据集)

下图为不同指标下的综合三维车道评估。在统一锚定设计的强度上,PersFrorr在远误差指标上优于以前的3D方法,同时保留了类似的误差在接近误差(m)。∗表示使用IPM投影从CondLaneNet[35]到BEV的二维车道结果:
2D结果对比(在OpenLane 数据集)
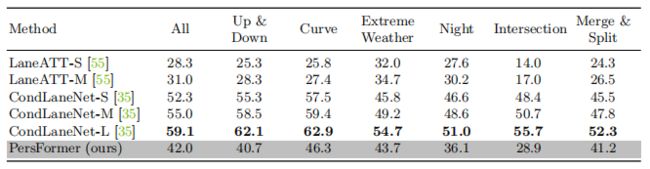
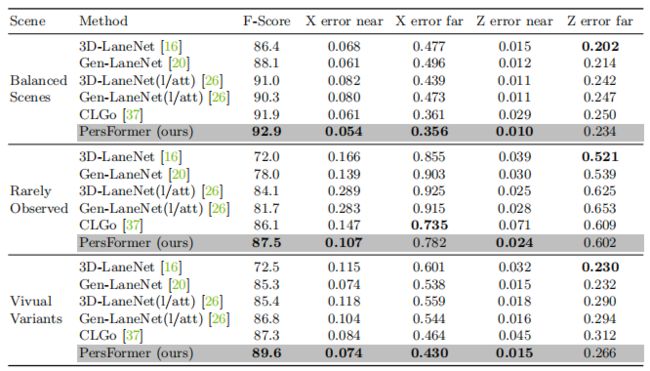
Apollo 3D Lane Synthetic 数据集评估
并与以往的阿波罗三维车道合成技术上的三维方法进行了比较。Persfrer在每个场景上获得最好的F分数,具有相当的X/Z误差(m)
下图在通常的自动驾驶场景中,presFormer善于捕捉密集和不明显的车道。

appendix(实现细节)
backbone
backbone与之前的工作略有不同,因为需要同时考虑2D/3D分支。采用 EfficientNet 提取一个特定的图层作为后续模块的输入。稍后提供了两种设计(是否使用FPN)。在使用了几个卷积层后,主干模块输出了4个不同比例的前视图特征图。他们的分辨率是180×240,90×120,45×60,22×30。然后利用PresFormer将每个前视图特征图转换为bev空间特征图,结果得到了4个BEV特征图。
Anchor 细节
我们首先在BEV空间中设置锚点。按照Gen-LaneNet的顺序,起始位置Xi_bev沿x轴均匀放置,间距为8个像素。
Gen-LaneNet只设置直向(平行于y轴),这使得很难预测具有大曲率或垂直车道的车道。针对这个问题,我们在每个Xi_bev上以不同的角度放置7个锚,即φ∈{π/2、arctan(±0.5)、arctan(±1)、arctan(±2))。此外,我们将所有的BEV锚点投影到具有数据集的平均摄像机高度和螺距角的图像空间中,从而得到相应的二维锚点。
GT 与 anchor 匹配: Y_ref的设置非常接近ego-vehiche,即Gen-LaneNet的5米,这使得它能更好地预测近区域的车道,而在远距离的表现不令人满意。在我们的实验中,我们在二维和三维任务中以最小的编辑距离将锚分配到地面真实车道。该距离是在固定的y位置上计算的:(5、10、15、20、30、40、50、60、802D锚的72个等采样高度。
3D标注过程
