spark安装以及hive on spark和spark on hive 的配置
spark安装以及hive on spark和spark on hive 的配置
1. 上传并解压安装包:tar -zxvf spark-3.2.1-bin-hadoop3.2-scala2.13.tgz -C /export/server
重命名:mv /export/server/ spark-3.2.1-bin-hadoop3.2-scala2.13.tgz /export/server/spark-3.2.1 (本人集群用的hadoop版本是hadoop-3.3.2,在实际操作中安装的spark版本也能兼容)
2. 配置spark环境变量
sudo vim /etc/profile
|
# 配置spark环境变量 export SPARK_HOME= /export/server/spark-3.2.1 export PATH=$PATH:$SPARK_HOME/bin export PATH=$PATH:$SPARK_HOME/sbin |
3. 修改spark配置文件,在$SPARK_HOME/conf下复制并重命名相关文件
cp spark-env.sh. template spark-env.sh
cp workers . template workers
cp spark-defaults.conf.template spark-defaults.conf
①修改spark-env.sh文件
vim spark-env.sh
|
export JAVA_HOME=/export/server/jdk1.8.0_131 export HADOOP_HOME=/export/server/hadoop-3.3.2 export HADOOP_CONF_DIR=/export/server/hadoop-3.3.2/etc/hadoop export SPARK_CONF_DIR=/export/server/spark-3.2.1/conf export HIVE_HOME=/export/server/apache-hive-3.1.3-bin # 指定spark的master export SPARK_MASTER_HOST=node1 # 指定spark可从hdfs上读写数据 export SPARK_DIST_CLASSPATH=$(/export/server/hadoop-3.3.2/bin/hadoop classpath) # 解除运行时无法加载本地hadoop库的提醒 export LD_LIBRARY_PATH=/export/server/hadoop-3.3.2/lib/native |
如果不配置export SPARK_DIST_CLASSPATH,启动时会报错:failed to launch: nice -n 0 /export/server/spark-3.2.1/bin/spark-class org.apache.spark.deploy.master.Master --host node1 --port 7077 --webui-port 8080

② 修改workers文件
vim workers
| node1 node2 node3 node4 |
③ 修改spark-defaults.conf文件
vim spark-defaults.conf 文末添加内容(其中8020是namenode的端口号与$HADOOP_HOME/etc/hadoop/core-site.xml中的一致/spark/spark-logs需要自行在hdfs上创建,)
|
spark.master spark://node1:7077 spark.eventLog.enabled true spark.eventLog.dir hdfs://node1:8020/spark/spark-logs spark.serializer org.apache.spark.serializer.KryoSerializer spark.driver.memory 5g spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three" |
4. 启动master/workers(先启动hadoop集群)
start-master.sh/ start-workers.sh
![]()
查看各节点进程
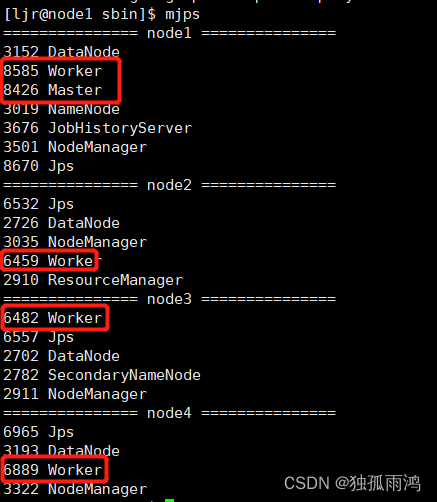
spark安装完成!
5. Hive on Spark(为hive配置spark引擎):Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。Hive默认执行引擎是mapreduce,由于效率比较低,Spark是放在内存中,所以总体来讲比MapReduce快很多(当然首次执行速度还是比较慢的)
① 纯净版的的hive需要把spark中以下三个jar包拷贝到hive的lib目录下(本人安装的是apache-hive-3.1.3-bin,里面已经包含了以下三个包可略过此步)
cp $SPARK_HOME/jars/scala-library-2.12.15.jar $HIVE_HOME/lib
cp $SPARK_HOME/jars/spark-core_2.12-3.2.1.jar $HIVE_HOME/lib
cp $SPARK_HOME/jars/ spark-network-common_2.12-3.2.1.jar $HIVE_HOME/lib
② hdfs上新建目录/spark/spark-jar并把$SPARK_HOME/jars下的文件上传到该目录下
hadoop fs -mkdir -p /spark/spark-jar
hadoop fs -put $SPARK_HOME/jars/* /spark/spark-jar
③修改hive的配置文件
vim $HIVE_HOME/conf/hive-site.xml 添加如下内容
|
|
④ 启动并连接hive
连接成功后查看执行引擎输入:set hive.execution.engine;

hive on spark 至此配置成功!
6. Spark on Hive(为spark配置SQL) : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
① 将hive-site.xml文件复制到spark的conf目录,并分发到集群其他节点
cp $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf
xsync $SPARK_HOME/conf/ hive-site.xml
② 将hive中mysql jdbc驱动复制到spark的jars目录
cp $HIVE_HOME/lib/mysql-connector-java-8.0.8-dmr-bin.jar $SPARK_HOME/jars
③启动spark-SQL
spark-sql

可以看到在hive建的test库,spark on hive 至此配置成功!