浅谈文本生成或者文本翻译解码策略
目录
一、文本生成和翻译的基本流程
翻译类模型的训练和解码
训练过程
解码过程
生成类模型的训练和解码(GPT系列)
训练过程
解码过程
二、解码策略
1、贪心搜索(greedy search)
2、beam_search集束搜索
3、随机sampling
4、Top-K Sampling和Top-p (nucleus) sampling
Top-K Sampling
Top-p (nucleus) sampling
三、transformer中的解码使用
文本生成和文本翻译的效果不仅仅在于模型层面的好坏,同时预测阶段的解码策略也是比较重要,不同的解码策略得出的效果也是不同的。经过学者们多年的研究,目前就我所知的文本生成相关的解码策略主要有贪心搜索(greedy search)、beam_search集束搜索、随机sampling、top-k sampling和Top-p Sampling,今天我们主要聊聊这几种文本解码策略算法。
一、文本生成和翻译的基本流程
翻译类模型的训练和解码
训练过程
翻译类任务的流程是一个src输入对应一个tag输入,一般而言,src长度和tag长度不一样的;一个简单的流程图如下图所示:
模型训练的结果是和tag长度一样的一个向量,output[T,B,D]经过一个分类全连接层得到[T,B]的概率分布,这个就和tag的输入[T,B]计算loss;
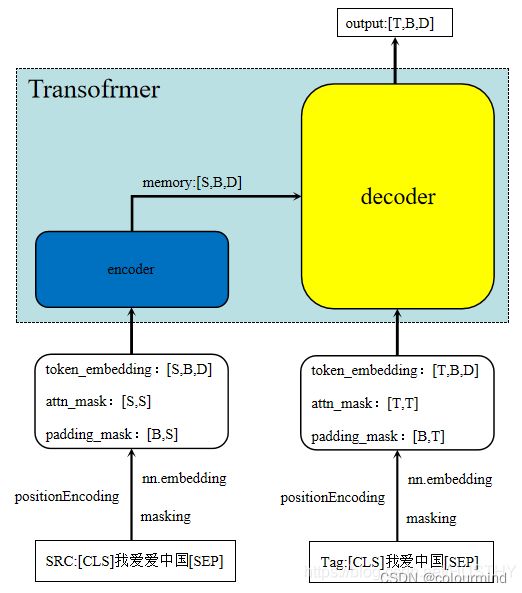
解码过程
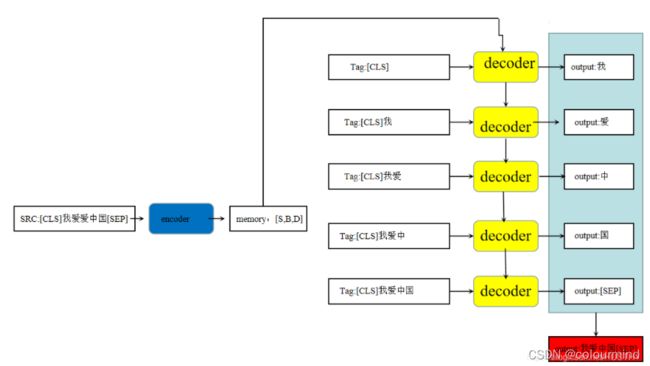
如下图所示,模型训练好以后,解码的初始就是src的embedding加上tag端的起始字符
生成类模型的训练和解码(GPT系列)
训练过程
GPT模型的训练过程直接输入一段自然文本,然后输出其embedding,然后再经过一个分类器,得到logits[B,L,V];同时把输入文本作为标签,计算交叉熵损失。模型的输入就是inputids [B,L]-------->embedding[B,L,D]------->logits[B,L,V]。
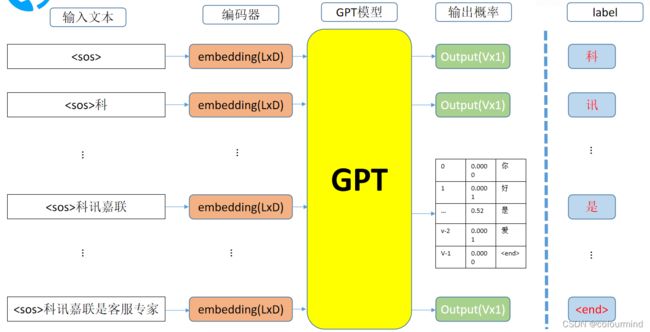
解码过程
同上面类似也是把当前解码结果token和之前的tokens合并起来作为输入解码得到下一个token。
二、解码策略
上面通过示意图简单的解释了一下生成类任务的模型训练和解码过程以及中间的向量维度变化,最后解码的结果好坏出了和模型本身有关,同时也与采用什么样的解码策略也是很相关的。
1、贪心搜索(greedy search)
预测阶段得到的概率分布,连接全连接层后,可以得到一个序列的概率分布[(B*S),vocab_size]——含义就是每个字在词表上的概率分布,共有B*S个字。怎么样通过这个概率分布得到最合理的序列。一种很直观的做法就是从每个字的概率分布中取它的最大概率的那个可能性,直到整个序列完成或者发现终止符[SEP]。简单实现,代码如下:
def gen_nopeek_mask(length):
"""
Returns the nopeek mask
Parameters:
length (int): Number of tokens in each sentence in the target batch
Returns:
mask (arr): tgt_mask, looks like [[0., -inf, -inf],
[0., 0., -inf],
[0., 0., 0.]]
"""
mask = torch.triu(torch.ones(length, length))
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def greedy_search_decode(model, src,src_key_padding_mask, max_len:int = 64, start_symbol:int = 1):
"""
:param model: Transformer model
:param src: the encoder input
:param max_len: 序列最大长度
:return:ys 这个就是预测的具体序列
解码的时候这几个mask是不能够少的
"""
src_mask = gen_nopeek_mask(src.shape[1]).to(device)
memory_key_padding_mask = src_key_padding_mask
#最开始的字符[CLS]在词表的位置是1
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len-1):
tar_mask = gen_nopeek_mask(ys.shape[1]).to(device)
out = model.forward(src, ys, src_key_padding_mask=src_key_padding_mask, tgt_key_padding_mask=None,src_mask=src_mask,tar_mask=tar_mask,memory_key_padding_mask=memory_key_padding_mask)
#预测结果out,选取最后一个概率分布
out = out[:,-1,:]
#得到最大的那个概率的index,就是该次预测的字在词表的index
_, next_word = torch.max(out, dim=1)
next_word = next_word.data[0]
if next_word != 2:
#如果没有预测出终止符[SEP]
#把这次预测的结果和以前的结果cat起来,再次循环迭代预测
ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
else:
break
return ys上面实现的缺陷就是不能并行的解码batch>1的情形,可以适当修改适应并行处理,每次batch内的数据每次解码后,做一个判定,是否batch内的每一行数据都出现了结束字符。判定代码就是:
(ys == 2).sum(1).bool().all()判定ys的每一行是否出现过2(结束符号)这个元素
解码完整代码如下图
def greedy_search_decode(model, src, src_key_padding_mask, max_len: int = 64, start_symbol: int = 1, bs:int=32):
"""
:param model: Transformer model
:param src: the encoder input
:param max_len: 序列最大长度
:return:ys 这个就是预测的具体序列
解码的时候这几个mask是不能够少的
"""
src_mask = gen_nopeek_mask(src.shape[1]).to(device)
memory_key_padding_mask = src_key_padding_mask
# 最开始的字符[CLS]在词表的位置是1
ys = torch.ones(bs, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len - 1):
tar_mask = gen_nopeek_mask(ys.shape[1]).to(device)
out = model.forward(src, ys, src_key_padding_mask=src_key_padding_mask, tgt_key_padding_mask=None,
src_mask=src_mask, tar_mask=tar_mask, memory_key_padding_mask=memory_key_padding_mask)
# 预测结果out,选取最后一个概率分布
out = out[:, -1, :]
# 得到最大的那个概率的index,就是该次预测的字在词表的index
_, next_word = torch.max(out, dim=1)
next_word = next_word.data[0]
ys = torch.cat([ys, next_word], dim=1)
#判定一个batch内是不是所有的都解码完成了
if (ys == 2).sum(1).bool().all():
break
return ys解码举例如下
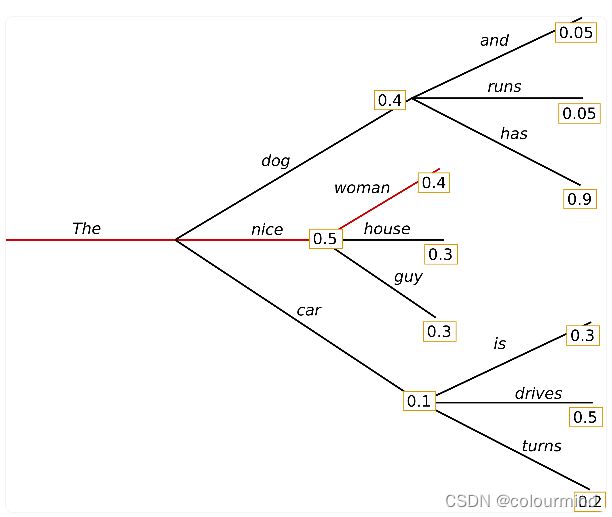
the nice woman 是每个时间步当前的最佳选择概率为0.5*0.4=0.2,但是从图上看概率最大的结果并不是这个the dog has 才具有整句最大的概率0.4*0.9 = 0.36;很明显的贪心搜索(greedy search)的缺点就是得出的序列并不一定具有整句最大概率,它很有可能遗漏掉一个比较小的当前概率后面的非常大概率的序列。为了避免这种情况,学者们提出了beam_search算法。
2、beam_search集束搜索
为了避免上述贪心搜索遗漏掉后面大概率的序列,beam search算法提出每次都保留当前最大的beam_num个结果。把当前beam_num个结果分别输入到模型中进行解码,每个序列又新生成v个新结果,共计beam_num*v个结果,排序选择最佳的beam_num个结果;然后重复上述过程,直到解码完成,最后从beam_num个结果选择出概率积最大的那个序列。——即每一步解码过程中都是保留前beam_num个最大的结果,最后才得出概率最大的那个。
以beam_num为2进行举例,图片来自——(全面了解Beam Search 1)
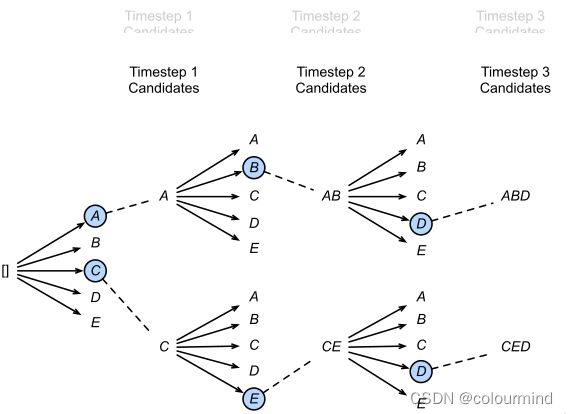
第一步解码,我们选择概率最大的两个单词[A, C],然后分别带入第二步解码,分别得到[AA, AB, AC, AD, AE, CA, CB, CC, CD, CE] 10种情况,这里仅保留最优的两种情况[AB, CE],然后再继续带入第三步解码,以此类推.....最后得到整体概率最大的序列。
bs=1时,实现beam search还是比较简单的,直接在贪心搜索的代码上做修改,记录当前最佳的beam_num个序列以及得分,然后每一步结果从beam_num*v的结果中做排序得到新的beam_num个结果。
当bs>1的时候,要实现一个高效的beam search还是比较麻烦的,参考了全面了解Beam Search 1和世界第一NLP实现库huggingface的transformers中的源码,修改如下的beam search代码:
import torch
import torch.nn.functional as F
from einops import rearrange
"""
batch_size为n 这样的处理
"""
class BeamHypotheses(object):
def __init__(self,num_beams,max_length,length_penalty):
self.max_length=max_length-1 # ignoringbos_token
self.length_penalty=length_penalty # 长度惩罚的指数系数
self.num_beams=num_beams # beamsize
self.beams=[] # 存储最优序列及其累加的log_probscore
self.worst_score=1e9 # 将worst_score初始为无穷大。
def __len__(self):
return len(self.beams)
def add(self,hyp,sum_logprobs):
score=sum_logprobs / len(hyp) ** self.length_penalty # 计算惩罚后的score
if len(self) < self.num_beams or score > self.worst_score:
# 如果类没装满num_beams个序列
# 或者装满以后,但是待加入序列的score值大于类中的最小值
# 则将该序列更新进类中,并淘汰之前类中最差的序列
self.beams.append((score, hyp))
if len(self) > self.num_beams:
sorted_scores=sorted([(s,idx)for idx, (s, _) in enumerate(self.beams)])
del self.beams[sorted_scores[0][1]]
self.worst_score = sorted_scores[1][0]
else:
# 如果没满的话,仅更新worst_score
self.worst_score = min(score, self.worst_score)
def is_done(self,best_sum_logprobs,cur_len):
# 当解码到某一层后,该层每个结点的分数表示从根节点到这里的log_prob之和
# 此时取最高的log_prob,如果此时候选序列的最高分都比类中最低分还要低的话
# 那就没必要继续解码下去了。此时完成对该句子的解码,类中有num_beams个最优序列。
if len(self) < self.num_beams:
return False
else:
cur_score = best_sum_logprobs / cur_len ** self.length_penalty
ret = self.worst_score >= cur_score
return ret
def gen_nopeek_mask(length):
"""
Returns the nopeek mask
Parameters:
length (int): Number of tokens in each sentence in the target batch
Returns:
mask (arr): tgt_mask, looks like [[0., -inf, -inf],
[0., 0., -inf],
[0., 0., 0.]]
"""
mask = rearrange(torch.triu(torch.ones(length, length)) == 1, 'h w -> w h')
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def beam_sizing(num_beams,src,src_key_padding_mask):
#为了满足beam_search 算法在解码的时候的使用,需要进行数据复制——按行进行复制,复制num_beams份
temp1 = src
temp2 = src_key_padding_mask
for i in range(num_beams-1):
temp1 = torch.cat([temp1,src],dim=0)
temp2 = torch.cat([temp2,src_key_padding_mask],dim=0)
index = 0
for i in range(src.shape[0]):
for _ in range(num_beams):
temp1[index,...] = src[i,...]
temp2[index,...] = src_key_padding_mask[i,...]
index += 1
src = temp1
src_key_padding_mask = temp2
return src,src_key_padding_mask
def beam_search(device,model,src,src_key_padding_mask,sos_token_id:int=1,pad_token_id:int=0,eos_token_id:int = 2,max_length:int = 20,num_beams:int =6,vocab_size:int=5993):
batch_size = src.shape[0]
src_mask = gen_nopeek_mask(src.shape[1]).to(device)
src,src_key_padding_mask = beam_sizing(num_beams,src,src_key_padding_mask)
memory_key_padding_mask = src_key_padding_mask
beam_scores = torch.zeros((batch_size, num_beams)).to(device) # 定义scores向量,保存累加的log_probs
beam_scores[:, 1:] = -1e9 # 需要初始化为-inf
beam_scores = beam_scores.view(-1) # 展开为(batch_size * num_beams)
done = [False for _ in range(batch_size)] # 标记每个输入句子的beam search是否完成
generated_hyps = [
BeamHypotheses(num_beams, max_length, length_penalty=0.7)
for _ in range(batch_size)
] # 为每个输入句子定义维护其beam search序列的类实例
# 初始输入: (batch_size * num_beams, 1)个sos token
input_ids = torch.full((batch_size * num_beams, 1), sos_token_id, dtype=torch.long).to(device)
cur_len = 1
while cur_len < max_length:
tar_mask = gen_nopeek_mask(input_ids.shape[1]).to(device)
memory_key_padding_mask = src_key_padding_mask
outputs,_= model.forward(src, input_ids, src_key_padding_mask=src_key_padding_mask, tgt_key_padding_mask=None,src_mask=src_mask,tar_mask=tar_mask,memory_key_padding_mask=memory_key_padding_mask)
# 取最后一个timestep的输出 (batch_size*num_beams, vocab_size)
next_token_logits = outputs[:, -1, :]
scores = F.log_softmax(next_token_logits, dim=-1) # log_softmax
next_scores = scores + beam_scores[:, None].expand_as(scores) # 累加上以前的scores
next_scores = next_scores.view(
batch_size, num_beams * vocab_size
) # 转成(batch_size, num_beams * vocab_size), 如上图所示
# 取topk,这里一定要取2*num_beams个最大值,才能保证后续下一批次每个batch内会有num_beams个需要处理的
next_scores, next_tokens = torch.topk(next_scores, 2*num_beams, dim=1, largest=True, sorted=True)
# 下一个时间步整个batch的beam列表
# 列表中的每一个元素都是三元组
# (分数, token_id, beam_id)
next_batch_beam = []
for batch_idx in range(batch_size):
if done[batch_idx]:
# 当前batch的句子都解码完了,那么对应的num_beams个句子都继续pad
next_batch_beam.extend([(0, pad_token_id, 0)] * num_beams) # pad the batch
continue
next_sent_beam = [] # 保存三元组(beam_token_score, token_id, effective_beam_id)
for beam_token_rank, (beam_token_id, beam_token_score) in enumerate(
zip(next_tokens[batch_idx], next_scores[batch_idx])
):
beam_id = beam_token_id // vocab_size # 1
token_id = beam_token_id % vocab_size # 1
# 上面的公式计算beam_id只能输出0和num_beams-1, 无法输出在(batch_size, num_beams)中的真实id
# 如上图, batch_idx=0时,真实beam_id = 0或1; batch_idx=1时,真实beam_id如下式计算为2或3
# batch_idx=1时,真实beam_id如下式计算为4或5
effective_beam_id = batch_idx * num_beams + beam_id
# 如果遇到了eos, 则讲当前beam的句子(不含当前的eos)存入generated_hyp
if (eos_token_id is not None) and (token_id.item() == eos_token_id):
is_beam_token_worse_than_top_num_beams = beam_token_rank >= num_beams
if is_beam_token_worse_than_top_num_beams:
continue
generated_hyps[batch_idx].add(
input_ids[effective_beam_id].clone(), beam_token_score.item(),
)
else:
# 保存第beam_id个句子累加到当前的log_prob以及当前的token_id
next_sent_beam.append((beam_token_score, token_id, effective_beam_id))
if len(next_sent_beam) == num_beams:
break
# 当前batch是否解码完所有句子
done[batch_idx] = done[batch_idx] or generated_hyps[batch_idx].is_done(
next_scores[batch_idx].max().item(), cur_len
) # 注意这里取当前batch的所有log_prob的最大值
# 每个batch_idx, next_sent_beam中有num_beams个三元组(假设都不遇到eos)
# batch_idx循环后,extend后的结果为num_beams * batch_size个三元组
next_batch_beam.extend(next_sent_beam)
# 如果batch中每个句子的beam search都完成了,则停止
if all(done):
break
# 准备下一次循环(下一层的解码)
# beam_scores: (num_beams * batch_size)
# beam_tokens: (num_beams * batch_size)
# beam_idx: (num_beams * batch_size)
# 这里beam idx shape不一定为num_beams * batch_size,一般是小于等于
# 因为有些beam id对应的句子已经解码完了 (下面假设都没解码完)
# print('next_batch_beam',len(next_batch_beam))
beam_scores = beam_scores.new([x[0] for x in next_batch_beam])
beam_tokens = input_ids.new([x[1] for x in next_batch_beam])
beam_idx = input_ids.new([x[2] for x in next_batch_beam])
# 取出有效的input_ids, 因为有些beam_id不在beam_idx里面,
# 因为有些beam id对应的句子已经解码完了
# print('beam_idx',beam_idx)
# print('next_scores.shape',next_scores.shape)
#以下代码是核心的必须添加上
input_ids = input_ids[beam_idx, :] # (num_beams * batch_size, seq_len)
src = src[beam_idx,...]
src_key_padding_mask = src_key_padding_mask[beam_idx,...]
# (num_beams * batch_size, seq_len) ==> (num_beams * batch_size, seq_len + 1)
input_ids = torch.cat([input_ids, beam_tokens.unsqueeze(1)], dim=-1)
cur_len = cur_len + 1
# 注意有可能到达最大长度后,仍然有些句子没有遇到eos token,这时done[batch_idx]是false
for batch_idx in range(batch_size):
if done[batch_idx]:
continue
for beam_id in range(num_beams):
# 对于每个batch_idx的每句beam,都执行加入add
# 注意这里已经解码到max_length长度了,但是并没有遇到eos,故这里全部要尝试加入
effective_beam_id = batch_idx * num_beams + beam_id
final_score = beam_scores[effective_beam_id].item()
final_tokens = input_ids[effective_beam_id]
generated_hyps[batch_idx].add(final_tokens, final_score)
# 经过上述步骤后,每个输入句子的类中保存着num_beams个最优序列
# 下面选择若干最好的序列输出
# 每个样本返回几个句子
output_num_return_sequences_per_batch = num_beams #一定要小于num_beams
output_batch_size = output_num_return_sequences_per_batch * batch_size
# 记录每个返回句子的长度,用于后面pad
sent_lengths = input_ids.new(output_batch_size)
best = []
best_score = []
# retrieve best hypotheses
for i, hypotheses in enumerate(generated_hyps):
# x: (score, hyp), x[0]: score
sorted_hyps = sorted(hypotheses.beams, key=lambda x: x[0])
for j in range(output_num_return_sequences_per_batch):
effective_batch_idx = output_num_return_sequences_per_batch * i + j
temp = sorted_hyps.pop()
best_hyp = temp[1]
best_s = temp[0]
sent_lengths[effective_batch_idx] = len(best_hyp)
best.append(best_hyp)
best_score.append(best_s)
if sent_lengths.min().item() != sent_lengths.max().item():
sent_max_len = min(sent_lengths.max().item() + 1, max_length)
# fill pad
decoded = input_ids.new(output_batch_size, sent_max_len).fill_(pad_token_id)
# 填充内容
for i, hypo in enumerate(best):
decoded[i, : sent_lengths[i]] = hypo
if sent_lengths[i] < max_length:
decoded[i, sent_lengths[i]] = eos_token_id
else:
# 否则直接堆叠起来
decoded = torch.stack(best).type(torch.long)
# (output_batch_size, sent_max_len) ==> (batch_size*output_num_return_sequences_per_batch, sent_max_len)
best_score = torch.tensor(best_score).type_as(next_scores)
return decoded,best_score
虽然解决上贪心搜索的缺陷,但是beam search解码策略也有它的缺陷。从实际使用效果来看,beam search很容易重复的出现之前的字符,尤其是在文本生成任务上,机器翻译上效果还行。

How to generate text: using different decoding methods for language generation with Transformers中给出的例子可以看出在生成很短的一句话后,就开始重复了。为了解决这个问题,学者们提出了随机sampling的算法
3、随机sampling
随机采样顾名思义就是对在解码的时候,在下一个token生成的时候,直接随机的进行采样。对于greedy方法的好处是,我们生成的文字开始有了一些随机性,不会总是生成很机械的回复了。存在的问题就很明显了——生成的话术上下文不连贯,语义上可能相互矛盾、也是容易出现一些奇怪的词。
4、Top-K Sampling和Top-p (nucleus) sampling
论文The Curious Case of Neural Text Degeneration中提出一个很有意思的语言现象——
人类的语言总是出人意料的,并不是如同beam search中选择语言模型中概率最大的序列。就是beam search解码策略的结果less surprising!为此论文就基于Top-K Sampling改进得到了核采样Top-p (nucleus) sampling,下面就来聊一聊Top-K Sampling和Top-p (nucleus) sampling。
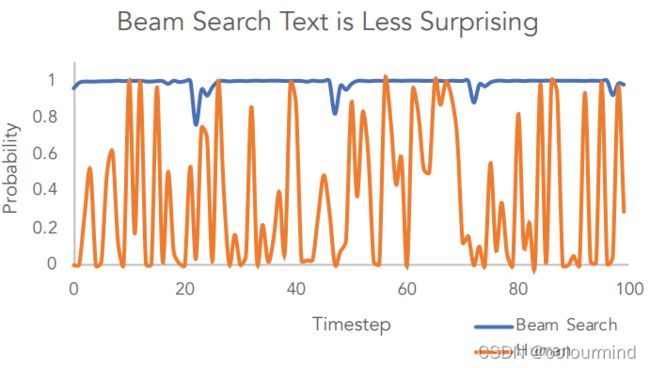
Top-K Sampling
这个是在随机sampling的基础上改进而来,既然在整个loghits概率分布上做随机采样会导致上下文不连贯,语义上可能相互矛盾、出现奇怪词语等问题,那能不能选取概率最大的K个token,重新形成概率分布,然后再做多项式分布抽样。思想很简单,torch实现起来也不困难。实际使用效果在GPT2模型上得到了很高的提升,GPT2生成的语句非常通顺流利,且重复token大幅度减少。
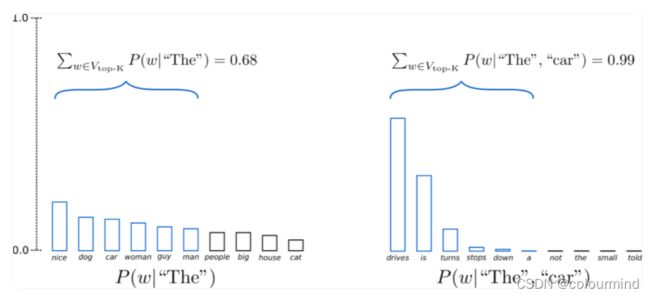
如图显示的就是K=6的时候,解码第一步6个token占据了整体tokens的三分之二,第二步则占用了99%,并且这些token都是比较合理的,同时采样的时候也采用了多项式随机采样——这样的话就会得到比较通顺流利的话语,也没有重复的词和奇怪的词。
该方法的难点在于K值如何选取
每一步解码过程中,logits的概率分布都是不一样的,在动态改变,固定的K值有可能造成取到的token是低概率的不合理的token;另外K取值过大又会和之前的随机sampling一样生成的话术上下文不连贯,语义上可能相互矛盾、也是容易出现一些奇怪的词;K过小的话,又会导致生成的语句多样性变差,less surprising!最好是K能动态的适应每一步解码的logits!为此有学者提出了核采样Top-p (nucleus) sampling
Top-p (nucleus) sampling
和Top-K Sampling不同的去一个固定的K值,Top-p (nucleus) sampling对整个logits从大到小累积概率,只要累积概率大于一个阈值,就把这些选取的token构成新的分布,然后采取多项式抽样,得到解码的next token!
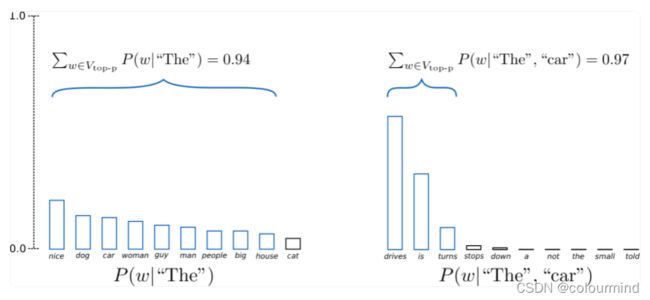
示例中累积概率阈值p = 0.92 ,第一步解码中采样从9个token中进行;第二步解码从3个token中进行;这样就可以动态的适应logtis,采取不同的K值。不过有一个点就是累积概率阈值P也是不溶于确定的,大多采用经验值。
当然从使用效果上来讲,Top-K Sampling和Top-p (nucleus) sampling都是比较不错的;当然实际使用过程中也是可以把Top-p (nucleus) sampling和Top-K Sampling结合起来,避免概率很小的token作为候选者,同时也保持动态性。
top-k和top-p 过滤代码:
def top_k_top_p_filtering_batch(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
""" Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
Args:
logits: logits distribution shape (vocabulary size)
top_k > 0: keep only top k tokens with highest probability (top-k filtering).
top_p > 0.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
"""
top_k = min(top_k, logits.size(-1)) # Safety check
if top_k > 0:
# Remove all tokens with a probability less than the last token of the top-k
# torch.topk()返回最后一维最大的top_k个元素,返回值为二维(values,indices)
# ...表示其他维度由计算机自行推断
for i in range(logits.shape[0]):
indices_to_remove = logits[i] < torch.topk(logits[i], top_k)[0][..., -1, None]
logits[i][indices_to_remove] = filter_value # 对于topk之外的其他元素的logits值设为负无穷
if top_p > 0.0:
for i in range(logits.shape[0]):
sorted_logits, sorted_indices = torch.sort(logits[i], descending=True) # 对logits进行递减排序
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
# Remove tokens with cumulative probability above the threshold
sorted_indices_to_remove = cumulative_probs > top_p
# Shift the indices to the right to keep also the first token above the threshold
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = sorted_indices[sorted_indices_to_remove]
logits[i][indices_to_remove] = filter_value
return logits然后直接调用该过滤算法进行解码
curr_input_tensor = input_ids.to(device)
generated = []
for index in range(args.max_len):
outputs = model(input_ids=curr_input_tensor)
next_token_logits = outputs[0][:,-1:]
# 对于已生成的结果generated中的每个token添加一个重复惩罚项,降低其生成概率
if index>=1:
for i in range(gen_finall.shape[0]):
gen_token_ids = gen_finall[i].clone()
gen_token_ids = list(set(gen_token_ids.detach().cpu().tolist()))
for id in gen_token_ids:
next_token_logits[i:i+1,:,id:id+1] /= args.repetition_penalty
next_token_logits = next_token_logits / args.temperature
# 对于[UNK]的概率设为无穷小,也就是说模型的预测结果不可能是[UNK]这个token
token_unk_id = tokenizer.convert_tokens_to_ids('[UNK]')
next_token_logits[:,:,token_unk_id:token_unk_id+1] = -float('Inf')
#进行top-k和top-p过滤
filtered_logits = top_k_top_p_filtering_batch(next_token_logits, top_k=args.topk, top_p=args.topp)
# torch.multinomial表示从候选集合中无放回地进行抽取num_samples个元素,权重越高,抽到的几率越高,返回元素的下标
next_token = curr_input_tensor[:,-1:].clone()
for i in range(next_token.shape[0]):
next_token[i] = torch.multinomial(F.softmax(filtered_logits[i].squeeze(0), dim=-1), num_samples=1)
generated.append(next_token)
gen_finall = torch.cat(generated,dim=1)
# print('gen_finall',gen_finall)
# print('tokenizer.sep_token_id',tokenizer.sep_token_id)
# print((gen_finall==tokenizer.sep_token_id))
# print((gen_finall==tokenizer.sep_token_id).sum(1))
# print((gen_finall==tokenizer.sep_token_id).sum(1).bool())
# print((gen_finall==tokenizer.sep_token_id).sum(1).bool().all())
#batch内所有都解码完成
if (gen_finall==tokenizer.sep_token_id).sum(1).bool().all():
break
curr_input_tensor = torch.cat((curr_input_tensor, next_token), dim=1)三、transformer中的解码使用
前文聊了文本生成和翻译的基本流程、解码策略的一些基本原理和思想以及解码策略的实现,当然更优雅的用法就是直接调用世界第一NLP实现库huggingface的transformers中关于文本翻译类或者生成类的解码函数。generation_utils.py提供了多种解码方式greedy search、beam search、sampling(直接随机sampling、top-K和Top-P)、beam_sample(beam_search+top-K和Top-P)和group_beam。至于其他的一些功能,需要读者自己去阅读源码。
解码很简单,代码如下,加载模型,喂入数据,解码,得到结果。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
from tqdm import tqdm
from torch.utils.data import DataLoader
import torch
from data_reader.dataReader_zh2en import DataReader
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("./pretrained_models/MarianMTModel_zh2en")
model = AutoModelForSeq2SeqLM.from_pretrained("./pretrained_models/MarianMTModel_zh2en")
dataset = DataReader(tokenizer, filepath='data/test_sample.csv')
test_dataloader = DataLoader(dataset=dataset,batch_size=4)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
finanl_result = []
for batch in tqdm(test_dataloader,desc='translation prediction'):
for k, v in batch.items():
batch[k] = v.to(device)
batch = {'input_ids': batch['input_ids'], 'attention_mask': batch['attention_mask']}
# Perform the translation and decode the output
translation = model.generate(**batch, top_k=5, num_return_sequences=1,num_beams=1)
batch_result = tokenizer.batch_decode(translation, skip_special_tokens=True)
finanl_result.extend(batch_result)
print(len(finanl_result))
for res in finanl_result:
print(res.replace('[','').replace(']',''))下文以翻译类任务为例,采用基于transformer架构的MarianMT模型,MarianMTModel_zh2en中文到英文的模型参数。
完整代码如下
import pandas as pd
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
from tqdm import tqdm
from torch.utils.data import DataLoader
import torch
from data_reader.dataReader_zh2en import DataReader
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("./pretrained_models/MarianMTModel_zh2en")
model = AutoModelForSeq2SeqLM.from_pretrained("./pretrained_models/MarianMTModel_zh2en")
dataset = DataReader(tokenizer, filepath='data/test_sample.csv')
test_dataloader = DataLoader(dataset=dataset,batch_size=4)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
finanl_result = []
for batch in tqdm(test_dataloader,desc='translation prediction'):
for k, v in batch.items():
batch[k] = v.to(device)
batch = {'input_ids': batch['input_ids'], 'attention_mask': batch['attention_mask']}
# Perform the translation and decode the output
#greedy
greedy_translation = model.generate(**batch,num_return_sequences = 1)
greedy_batch_result = tokenizer.batch_decode(greedy_translation, skip_special_tokens=True)
finanl_result.append(greedy_batch_result)
#beam_search
beam_translation = model.generate(**batch, num_return_sequences=1, num_beams=5)
beam_batch_result = tokenizer.batch_decode(beam_translation, skip_special_tokens=True)
finanl_result.append(beam_batch_result)
#sampling
sample_translation = model.generate(**batch, do_sample=True, num_return_sequences=1)
sample_batch_result = tokenizer.batch_decode(sample_translation, skip_special_tokens=True)
finanl_result.append(sample_batch_result)
#top-k
topk_translation = model.generate(**batch, top_k=5, num_return_sequences=1)
topk_batch_result = tokenizer.batch_decode(topk_translation, skip_special_tokens=True)
finanl_result.append(topk_batch_result)
# top-p
topp_translation = model.generate(**batch, top_p=0.92, num_return_sequences=1)
topp_batch_result = tokenizer.batch_decode(topp_translation, skip_special_tokens=True)
finanl_result.append(topp_batch_result)
# top-k和top-p
topktopp_translation = model.generate(**batch, top_k=5, top_p=0.92, num_return_sequences=1)
topktopp_batch_result = tokenizer.batch_decode(topktopp_translation, skip_special_tokens=True)
finanl_result.append(topktopp_batch_result)
# top-k和top-p+beam_search
beamtopktopp_translation = model.generate(**batch, top_k=5, top_p=0.92, num_return_sequences=1, num_beams=5)
beamtopktopp_batch_result = tokenizer.batch_decode(beamtopktopp_translation, skip_special_tokens=True)
finanl_result.append(beamtopktopp_batch_result)
decodes_policys = ['greedy search','beam_search','sampling','top-k','top-p','top-k和top-p','top-k和top-p+beam_search']
test_sample = ['【由富氏隐孢子虫引起的皮肤真菌病】。','[十二指肠转换手术中的减肥手术:体重变化和相关的营养缺乏]。','[宫腔镜研究数字图像的观察者间诊断协议]。']
print(len(finanl_result))
for i in range(3):
print(test_sample[i])
for ele,de_ty in zip(finanl_result,decodes_policys):
print(ele[i].replace('[','').replace(']',''))
print('*'*100)
翻译src文本
【由富氏隐孢子虫引起的皮肤真菌病】。
[十二指肠转换手术中的减肥手术:体重变化和相关的营养缺乏]。
[宫腔镜研究数字图像的观察者间诊断协议]。不同解码策略得到的结果对比
【由富氏隐孢子虫引起的皮肤真菌病】。
Skin fungi caused by Fung's Invisible Spores.
Skin fungus disease caused by Fung's Invisible Spores.
Skin fungi caused by Fung's spores.
Skin fungi caused by Fung's Invisible Spores.
Skin fungi caused by Fung's Invisible Spores.
Skin fungi caused by Fung's Invisible Spores.
Skin fungus disease caused by Fung's Invisible Spores.
****************************************************************************************************
[十二指肠转换手术中的减肥手术:体重变化和相关的营养缺乏]。
Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies.
Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies.
Liith finger intestinal conversion operations with dietary loss: weight changes and associated nutritional deficiencies.
Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies.
Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies.
Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies.
Twelve reference to fertility reduction in intestinal conversion operations: changes in body weight and associated nutritional deficiencies.
****************************************************************************************************
[宫腔镜研究数字图像的观察者间诊断协议]。
Observer-to-observer protocol for the study of digital images in the court cavity mirrors.
Observer-to-observer protocol for the study of digital images in the court cavity mirrors.
Observatorial protocol for the study of digital images in the uterine cavity mirror.
Observer-to-observer protocol for the study of digital images in the court cavity mirrors.
Observer-to-observer protocol for the study of digital images in the court cavity mirrors.
Observer-to-observer protocol for the study of digital images in the court cavity mirrors.
Observer-to-observer protocol for the study of digital images in the court cavity mirrors.翻译任务来看结果差异不是很大,不过也有一些差异。
参考文献
How to generate text: using different decoding methods for language generation with Transformers
Nucleus Sampling与文本生成中的不同解码策略比较
Seq2Seq解码策略-概念
全面了解Beam Search
The Curious Case of Neural Text Degeneration