伯克利『全栈深度学习』2022最新课程;谷歌『基于Transformers的通用超参数优化』经验分享;动图编辑器;前沿论文 | ShowMeAI资讯日报

日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子
工具&框架
『PyDeepFakeDet』Deepfake 换脸检测库
https://github.com/wangjk666/PyDeepFakeDet
PyDeepFakeDet 是由复旦大学视觉与学习实验室开发的一个集成的、可扩展的 Deepfake 检测工具。
其目标是提供最先进的 Deepfake 检测模型,以及在常用的 Deepfake 数据集上训练和评估新模型的接口。
『EasyCV』PyTorch 一站式计算机视觉工具箱
https://github.com/alibaba/EasyCV
EasyCV 是一个涵盖多个领域的基于 Pytorch 的计算机视觉工具箱,聚焦自监督学习和视觉transformer关键技术,覆盖主流的视觉建模任务例如图像分类,度量学习,目标检测,关键点检测等。
『Motionity』Web 界面的动图编辑器
https://github.com/alyssaxuu/motionity
Motionity 是一个免费和开源的网络动画编辑器。它是 After Effects 和 Canva 的混合体,具有强大的功能,如关键帧、遮盖、过滤等,并集成了浏览内容的功能,轻松拖入你的视频即可处理。
『Jumanji』用 JAX 写的行业驱动的硬件加速强化学习环境
https://github.com/instadeepai/jumanji
https://instadeepai.github.io/jumanji/
Jumanji 是一套用 JAX 编写的强化学习(RL)环境,为行业驱动的研究提供干净、硬件加速的环境。 Jumanji 的高速环境能够实现更快的迭代和更大规模的实验,同时降低复杂性。Jumanji 起源于 InstaDeep 的研究团队。

『OCRmyPDF』为扫描 PDF 增加 OCR 功能
https://github.com/ocrmypdf/OCRmyPDF
http://ocrmypdf.readthedocs.io/
PDF 是存储和交换扫描文件的最佳格式,但是难以修改。 OCRmyPDF 工具将图像处理和 OCR 文字识别功能应用于 PDF 编辑,轻松地为扫描的 PDF 文件添加 OCR 文本层,使其能够被搜索或复制粘贴。
博文&分享
『Full Stack Deep Learning』伯克利·全栈深度学习·(2022 免费课程)
https://fullstackdeeplearning.com/course/2022/
https://www.youtube.com/playlist?list=PL1T8fO7ArWleMMI8KPJ_5D5XSlovTW_Ur
FSDL是一个学习社区,将人们聚集在一起,学习和分享全栈最佳实践:从问题选择、数据管理和选择 GPU 到 Web 部署、监控和再培训。这是2022年最新版『全栈深度学习课程』,内容包括:
- ① 深度学习技术(包括CNN, RNN, Transformers等)
- ② AI伦理内容(介绍responsible AI/Ethics的一些研究内容)
- ③ 测试跟模型解释(其中对测试部分的归纳非常系统)、AI部署和监控
课程安排如下:
- 第1讲:课程愿景和何时使用 ML
- 第2讲:开发基础设施和工具
- 第3讲:故障排除和测试
- 第4讲:数据管理
- 第5讲:数据管理
- 第6讲:持续学习
实验安排如下:
- 实验1-3:CNN、Transformers、PyTorch Lightning
- 实验4:实验管理
- 实验5:故障排除和测试
- 实验6:数据注释
- 实验7:Web 部署
- 实验8:Web 部署
『OptFormer: Towards Universal Hyperparameter Optimization with Transformers』基于 Transformers 的通用超参数优化
https://ai.googleblog.com/2022/08/optformer-towards-universal.html
超参数优化对机器学习非常重要,对于机器学习模型的性能具有决定性的作用。在 Google 公司内部,Google Vizier 作为默认使用的机器学习部署过程的超参数优化平台,在过去 5 年中被调用超 1000 万次。
这篇 Google 的博客分享了 OptFormer 这一基于 Transformer 的超参数调整框架,使用灵活的、基于文本的表示,从Google Vizier 追踪到的大规模优化数据中学习。

数据&资源
『Representation Learning for Reinforcement Learning』面向强化学习的表示学习相关文献列表
https://github.com/fuyw/RepL4RL

『Awesome Stable-Diffusion』Stable Diffusion 模型相关资源大列表
https://github.com/awesome-stable-diffusion/awesome-stable-diffusion

研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.08.04 『看图说话』 Prompt Tuning for Generative Multimodal Pretrained Models
- 2022.09.02 『看图说话』 LiteDepth: Digging into Fast and Accurate Depth Estimation on Mobile Devices
- 2022.08.31 『计算机视觉』 Dual-Space NeRF: Learning Animatable Avatars and Scene Lighting in Separate Spaces
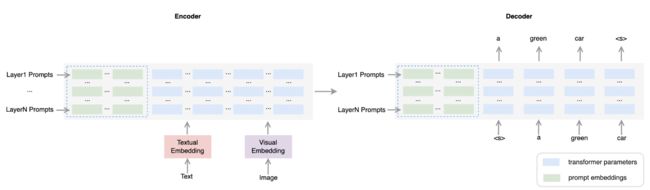
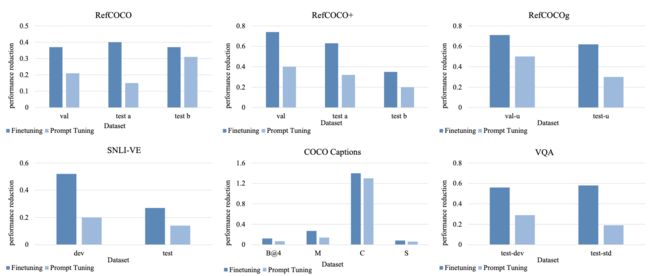
⚡ 论文:Prompt Tuning for Generative Multimodal Pretrained Models
论文时间:4 Aug 2022
领域任务:Image Captioning, Visual Entailment, 看图说话
论文地址:https://arxiv.org/abs/2208.02532
代码实现:https://github.com/ofa-sys/ofa
论文作者:Hao Yang, Junyang Lin, An Yang, Peng Wang, Chang Zhou, Hongxia Yang
论文简介:Prompt tuning has become a new paradigm for model tuning and it has demonstrated success in natural language pretraining and even vision pretraining./调优prompt已成为模型调优的新范式,它已在自然语言预训练甚至视觉预训练中显示出成功。
论文摘要:调优prompt已成为模型调优的新范式,它在自然语言预训练甚至视觉预训练中都表现出了成功。在这项工作中,我们探索了提示调谐向多模态预训练的转移,重点是生成性多模态预训练模型,而不是对比性模型。具体来说,我们在统一的序列到序列的预训练模型上实施提示调谐,以适应理解和生成任务。实验结果表明,轻量级的提示调谐可以达到与微调相当的性能,并且超过了其他轻量级的调谐方法。此外,与微调模型相比,提示性调谐模型对对抗性攻击表现出更好的鲁棒性。我们进一步发现,包括提示长度、提示深度和重新参数化在内的实验因素对模型性能有很大的影响,因此我们从经验上对提示调谐的设置提出了建议。尽管观察到了这些优点,我们仍然发现了提示调谐的一些局限性,并相应地指出了未来研究的方向。代码可在 https://github.com/OFA-Sys/OFA 获取。
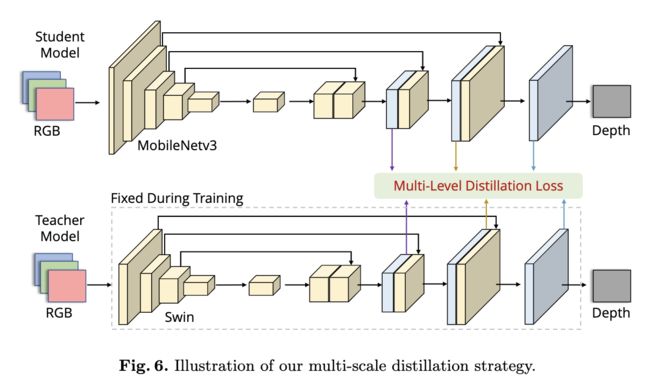
⚡ 论文:LiteDepth: Digging into Fast and Accurate Depth Estimation on Mobile Devices
论文时间:2 Sep 2022
领域任务:Data Augmentation, Monocular Depth Estimation,数据增强
论文地址:https://arxiv.org/abs/2209.00961
代码实现:https://github.com/zhyever/litedepth
论文作者:Zhenyu Li, Zehui Chen, Jialei Xu, Xianming Liu, Junjun Jiang
论文简介:Notably, our solution named LiteDepth ranks 2nd in the MAI&AIM2022 Monocular Depth Estimation Challenge}, with a si-RMSE of 0. 311, an RMSE of 3. 79, and the inference time is 37 m s ms ms tested on the Raspberry Pi 4./值得注意的是,我们名为LiteDepth的解决方案在MAI&AIM2022单眼深度估计挑战赛}中排名第二,在Raspberry Pi 4上测试的si-RMSE为0.311,RMSE为3.79,推理时间为37ms。
论文摘要:单眼深度估计是计算机视觉界的一项重要任务。虽然很多成功的方法都取得了很好的效果,但它们中的大多数都是计算昂贵的,而且不适用于实时的设备推断。在本文中,我们的目标是解决单眼深度估计的更多实际应用,其中的解决方案不仅要考虑精度,还要考虑移动设备上的推理时间。为此,我们首先开发了一个基于端到端学习的模型,其权重大小很小(1.4MB),推理时间很短(在Raspberry Pi 4上为27FPS)。然后,我们提出了一个简单而有效的数据扩充策略,称为R2 crop,以提高模型的性能。此外,我们观察到,只用一个单一损失项训练的简单轻量级模型将遭受性能瓶颈。为了缓解这个问题,我们采用了多个损失项来在训练阶段提供足够的约束。此外,通过一个简单的动态再加权策略,我们可以避免耗时的损失项的超参数选择。最后,我们采用了结构感知的蒸馏法来进一步提高模型的性能。值得注意的是,我们名为LiteDepth的解决方案在MAI&AIM2022单眼深度估计挑战赛}中排名第二,si-RMSE为0.311,RMSE为3.79,在Raspberry Pi 4上测试的推理时间为37ms。值得注意的是,我们提供了该挑战的最快解决方案。代码和模型将在 https://github.com/zhyever/LiteDepth 上发布。


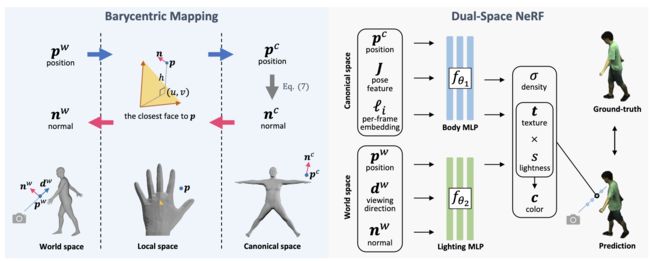
⚡ 论文:Dual-Space NeRF: Learning Animatable Avatars and Scene Lighting in Separate Spaces
论文时间:31 Aug 2022
领域任务:计算机视觉
论文地址:https://arxiv.org/abs/2208.14851
代码实现:https://github.com/zyhbili/Dual-Space-NeRF
论文作者:YiHao Zhi, Shenhan Qian, Xinhao Yan, Shenghua Gao
论文简介:Previous methods alleviate the inconsistency of lighting by learning a per-frame embedding, but this operation does not generalize to unseen poses./以前的方法通过学习每一帧的嵌入来缓解照明的不一致性,但这种操作并不能推广到未见过的姿势。
论文摘要:在一个典型的空间中对人体进行建模是捕捉和动画的一种常见做法。但当涉及到神经辐射场(NeRF)时,在典范空间中学习静态的NeRF是不够的,因为即使场景照明是恒定的,当人移动时,身体的照明也会发生变化。以前的方法通过学习每一帧的嵌入来缓解光照的不一致性,但这种操作并不能推广到未见过的姿势。鉴于照明条件在世界空间中是静态的,而人体在典型空间中是一致的,我们提出了一个双空间的NeRF,用两个MLPs在两个独立的空间中模拟场景照明和人体。为了连接这两个空间,以前的方法大多依靠线性混合蒙皮(LBS)算法。然而,动态神经场的LBS的混合权重是难以解决的,因此通常用另一个MLP来记忆,这对新的姿势没有通用性。虽然可以借用参数化网格的混合权重,如SMPL,但插值操作会引入更多的伪影。在本文中,我们建议使用巴里中心映射,它可以直接泛化到未见过的姿势,并且令人惊讶地取得了比使用神经混合权重的LBS更好的结果。在Human3.6M和ZJU-MoCap数据集上的定量和定性结果表明了我们方法的有效性。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
