java官网教程(进阶篇)—— 集合
目录
- 集合——使用和扩展Java集合框架的课程。
-
- 简介
- 接口
-
- Collection接口
- Set接口
- List接口
- Queue 接口
- Deque接口
- Map接口
- 对象排序
- SortedSet接口
- SortedMap接口
- 接口的总结
- 问题和练习:接口
- 聚合操作
-
- 归约
- 并行化(Parallelism)
- 练习
- 实现类
-
- Set的实现
- List实现
- Map的实现
- Queue的实现
- Deque的实现
- 包装器的实现
- 便利实现
- 实现的摘要
- 问题和练习:实现
- 算法
- 自定义实现
- 互通性
-
- 兼容性
- API设计
集合——使用和扩展Java集合框架的课程。
本节描述Java集合框架。在这里,您将了解什么是集合,以及它们如何使您的工作更容易、程序更好。您将了解组成Java集合框架的核心元素——接口、实现、聚合操作和算法。
简介
告诉您什么是集合,以及它们如何使您的工作更容易,使您的程序更好。您将了解组成Collections框架的核心元素:接口、实现和算法。
集合——有时称为容器——只是将多个元素分组为一个单元的对象。集合用于存储、检索、操作和通信聚合数据。通常,它们表示形成一个自然组的数据项,如扑克手(一组纸牌)、邮件文件夹(一组信件)或电话目录(姓名到电话号码的映射)。如果您使用过Java编程语言——或者任何其他编程语言——那么您已经熟悉集合了。
什么是集合框架?
集合框架是表示和操作集合的统一架构。所有集合框架包含以下内容:
- 接口:这些是表示集合的抽象数据类型。接口允许对集合进行独立于其表示细节的操作。在面向对象语言中,接口通常形成一个层次结构。
- 实现:这些是集合接口的具体实现。本质上,它们是可重用的数据结构。
- 算法:这些方法可以在实现集合接口的对象上执行有用的计算,比如搜索和排序。这些算法被称为多态的:也就是说,相同的方法可以用于适当集合接口的许多不同实现。本质上,算法是可重用的功能。
除了Java集合框架,最著名的集合框架例子是c++标准模板库(STL)和Smalltalk的集合层次结构。从历史上看,集合框架非常复杂,这使它们以具有陡峭的学习曲线而闻名。我们相信Java集合框架打破了这一传统,您将在本章中自己了解到这一点。
Java集合框架的好处
Java集合框架提供了以下好处:
- 减少了编程工作:通过提供有用的数据结构和算法,Collections Framework使您可以将精力集中在程序的重要部分上,而不是集中在使其工作所需的低级“管道”上。通过促进不相关api之间的互操作性,Java集合框架将您从编写适配器对象或转换代码来连接api中解放出来。
- 提高编程速度和质量:这个集合框架为有用的数据结构和算法提供了高性能、高质量的实现。每个接口的各种实现都是可互换的,因此可以通过切换集合实现轻松地调优程序。因为您从编写自己的数据结构的苦差事中解脱出来,您将有更多的时间用于提高程序的质量和性能。
- 允许不相关api之间的互操作性:集合接口是api来回传递集合的本地语言。如果我的网络管理API提供了一组节点名称,如果您的GUI工具包需要一组列标题,那么我们的API将无缝地互操作,即使它们是独立编写的。
- 减少学习和使用新api的工作量:许多APIs自然地在输入时接受集合,并将它们作为输出提供。在过去,每个这样的API都有一个用于操作其集合的小的子API。这些特别的集合子API之间几乎没有一致性,所以您必须从头开始学习每一个API,并且在使用它们时很容易出错。随着标准收集接口的出现,这个问题消失了。
- 减少设计新APIs的工作量:这是先前优势的反面。设计人员和实现者在每次创建依赖于集合的API时都不必另起炉灶;相反,它们可以使用标准的集合接口。
- 促进软件复用:符合标准集合接口的新数据结构本质上是可重用的。对实现这些接口的对象进行操作的新算法也是如此。
接口
描述了核心集合接口,它们是Java集合框架的核心和灵魂。您将了解有效使用这些接口的一般指导原则,包括何时使用哪个接口。您还将了解每个接口的习惯用法,这些习惯用法将帮助您最大限度地利用接口。
核心集合接口封装了不同类型的集合,如下图所示。这些接口允许对集合进行独立于其表示细节的操作。核心集合接口是Java集合框架的基础。在下面的图中可以看到,核心集合接口形成了一个层次结构。
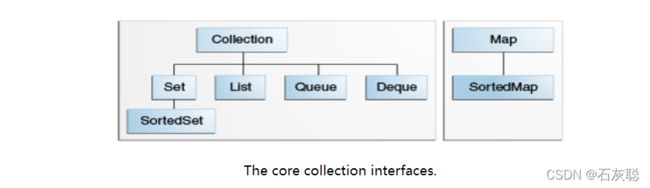
Set是一种特殊的集合,SortedSet是一种特殊的Set集合,等等。还请注意,层次结构由两棵不同的树组成——Map不是真正的Collection。
请注意,所有核心集合接口都是泛型的。例如,这是Collection接口的声明。
public interface Collection<E>...
语法告诉您该接口是泛型的。声明Collection实例时,可以并且应该指定集合中包含的对象类型。指定类型允许编译器(在编译时)验证放入集合中的对象类型是否正确,从而减少运行时的错误。有关泛型类型的信息,请参阅泛型课程。
当您理解了如何使用这些接口时,您将了解关于Java集合框架的大部分内容。本章讨论了有效使用接口的一般指导原则,包括何时使用哪个接口。您还将学习每个接口的编程习惯用法,以帮助您最大限度地利用它。
为了保持核心集合接口的可管理数量,Java平台没有为每种集合类型的每个变体提供单独的接口。(这类变量可能包括不可变的、固定大小的和仅追加的。)相反,每个接口中的修改操作被指定为可选的——一个给定的实现可能选择不支持所有操作。如果调用不支持的操作,集合将抛出UnsupportedOperationException。实现负责记录它们支持哪些可选操作。Java平台的所有通用实现都支持所有可选操作。
以下列表描述了核心集合接口:
-
Collection:集合层次结构的根。集合表示一组称为其元素的对象。Collection接口是所有集合实现的最小公分母,用于传递集合,并在需要最大通用性时对它们进行操作。有些类型的集合允许重复元素,有些则不允许。有些是有序的,有些是无序的。Java平台不提供该接口的任何直接实现,但提供了更具体的子接口的实现,如Set和List。请参见Collection接口一节。
-
Set:不能包含重复元素的集合。这个接口为数学集合抽象建模,并用于表示集合,例如组成扑克手的卡片、组成学生时间表的课程,或在机器上运行的进程。请参见Set接口一节。
-
List:有序集合(有时称为序列)。Lists可以包含重复的元素。List的用户通常可以精确地控制每个元素在列表中的插入位置,并可以通过元素的整数索引(位置)访问元素。如果您使用过Vector,那么您应该熟悉List的一般风格。请参见列表接口部分。
-
Queue:在处理之前用于保存多个元素的集合。除了基本的Collection操作外,Queue还提供了额外的插入、提取和检查操作。
队列通常(但不一定)以FIFO(先进先出)方式对元素排序。例外情况包括优先级队列,它根据提供的比较器或元素的自然顺序对元素进行排序。无论使用何种排序,队列的头都是将被删除或轮询调用删除的元素。在FIFO队列中,所有新元素都插入到队列的尾部。其他类型的队列可能使用不同的放置规则。每个Queue实现必须指定其排序属性。 请参见队列接口一节。
-
Deque:在处理之前用于保存多个元素的集合。除了基本的Collection操作外,Deque还提供了额外的插入、提取和检查操作。
Deques既可以用作FIFO(先进先出),也可以用作LIFO(后进先出)。在deque容器中,所有的新元素都可以在两端插入、检索和删除。请参见Deque接口一节。
-
Map:一个将键映射到值的对象。Map不能包含重复的键;每个键最多只能映射到一个值。如果您使用过Hashtable,那么您已经熟悉了Map的基础知识。请参见映射接口一节。
最后两个核心集合接口只是Set和Map的排序版本:
- SortedSet:按升序维护元素的Set集合。提供了几个额外的操作来利用排序的优势。排序集用于自然排序集,如单词列表和成员名单。请参见SortedSet接口一节。
- SortedMap:以升序键顺序维护映射的Map。这是SortedSet的Map模拟。排序映射用于键/值对的自然有序集合,例如字典和电话目录。请参见SortedMap接口一节。
要了解已排序的接口如何维护其元素的顺序,请参阅对象排序一节。
Collection接口
集合表示一组被称为元素的对象。Collection接口用于在需要最大通用性的地方传递对象集合。例如,按照约定,所有通用集合实现都有一个接受collection参数的构造函数。这个构造函数,称为转换构造函数,初始化新集合以包含指定集合中的所有元素,无论给定集合的子接口或实现类型是什么。换句话说,它允许您转换集合的类型。
例如,假设您有一个集合Collection c,它可能是一个列表,一个集合,或另一种类型的集合。这个习惯用法创建一个新的ArrayList (List接口的实现),最初包含c中的所有元素。
List<String> list = new ArrayList<String>(c);
或者-如果你使用的是JDK 7或更高版本-你可以使用菱形操作符:
List<String> list = new ArrayList<>(c);
Collection接口包含执行基本操作的方法,如:
int size()、
boolean isEmpty()、
boolean contains(Object元素)、
boolean add(E元素)、
boolean remove(Object元素)
Iterator<E> Iterator()
它还包含对整个集合进行操作的方法,例如:
boolean containsAll(Collection<?> c),
boolean addAll(Collection<? extends E> c)
boolean removeAll(Collection<?> c)
boolean retainAll(Collection<?> c)
void clear()
数组操作的其他方法(如Object[] toArray()和
在JDK 8及以后版本中,Collection接口还公开了Stream和Stream方法,用于从底层集合中获取连续或并行流。(有关使用流的更多信息,请参阅聚合操作一课。)
如果一个Collection表示一组对象,那么Collection接口的作用就是您所期望的。它有告诉您集合中有多少元素的方法(size, isEmpty),检查给定对象是否在集合中(contains)的方法,从集合中添加和删除元素的方法(add, remove),以及提供集合上的迭代器的方法(iterator)。
add方法的定义很普遍,因此它对于允许重复的集合和不允许重复的集合都有意义。它保证Collection将在调用完成后包含指定的元素,如果Collection因调用而发生更改,则返回true。类似地,remove方法被设计为从Collection中删除指定元素的单个实例(假设它包含开始时使用的元素),如果Collection被修改,则返回true。
遍历集合
有三种遍历集合的方法:(1)使用聚合操作(2)使用for-each构造和(3)使用迭代器。
聚合操作
在JDK 8及以后版本中,迭代集合的首选方法是获取流并对其执行聚合操作。聚合操作通常与lambda表达式一起使用,以使编程更具表现力,使用更少的代码行数。下面的代码依次遍历一个形状集合并打印出红色的对象:
myShapesCollection.stream()
.filter(e -> e.getColor() == Color.RED)
.forEach(e -> System.out.println(e.getName()));
同样地,你可以很容易地请求一个并行流,如果集合足够大并且你的计算机有足够的内核,这可能是有意义的:
myShapesCollection.parallelStream()
.filter(e -> e.getColor() == Color.RED)
.forEach(e -> System.out.println(e.getName()));
使用这个API收集数据有许多不同的方法。例如,你可能想要将Collection的元素转换为String对象,然后用逗号将它们连接起来:
String joined = elements.stream()
.map(Object::toString)
.collect(Collectors.joining(", "));
或者把所有员工的工资加起来:
int total = employees.stream()
.collect(Collectors.summingInt(Employee::getSalary)));
这些只是使用流和聚合操作的几个例子。有关更多信息和示例,请参见名为聚合操作的一节。
Collections框架一直提供大量所谓的“批量操作”作为其API的一部分。其中包括对整个集合进行操作的方法,如containsAll、addAll、removeAll等。不要将这些方法与JDK 8中引入的聚合操作混淆。新的聚合操作和现有的批量操作(containsAll、addAll等)之间的关键区别是,旧版本都是可变的,这意味着它们都修改了底层集合。相反,新的聚合操作不会修改基础集合。在使用新的聚合操作和lambda表达式时,您必须小心避免发生变化,以免在以后从并行流运行代码时引入问题。
for — each构造
for-each结构允许您使用for循环精确地遍历集合或数组——请参阅for语句。下面的代码使用for-each构造在单独的行上打印集合的每个元素。
for (Object o : collection)
System.out.println(o);
迭代器(Iterators)
Iterator是一个对象,它使您能够遍历一个集合,并在需要时有选择地从集合中删除元素。通过调用集合的迭代器方法,可以获得集合的迭代器。下面是Iterator接口。
public interface Iterator<E> {
boolean hasNext();
E next();
void remove(); //optional
}
如果迭代中有更多的元素,则hasNext方法返回true, next方法返回迭代中的下一个元素。remove方法从基础集合中删除next返回的最后一个元素。每次调用next时,remove方法只能被调用一次,如果违反了该规则,则会抛出异常。
注意,Iterator.remove是在迭代过程中修改集合的唯一安全方法;如果在迭代过程中以任何其他方式修改基础集合,则该行为是未指定的。
当需要时,使用Iterator而不是for-each构造:
- 删除当前元素。for-each构造隐藏了迭代器,因此不能调用remove。因此,for-each构造不能用于过滤。
- 并行地迭代多个集合。
下面的方法向您展示了如何使用Iterator来过滤任意的集合——即遍历集合,删除特定的元素。
static void filter(Collection<?> c) {
for (Iterator<?> it = c.iterator(); it.hasNext(); )
if (!cond(it.next()))
it.remove();
}
这段简单的代码是多态的,这意味着它适用于任何Collection,无论其实现如何。这个例子演示了使用Java集合框架编写多态算法是多么容易。
集合接口批量操作
批量操作对整个集合执行操作。您可以使用基本操作来实现这些简写操作,尽管在大多数情况下,这种实现的效率较低。以下是批量操作:
- containsAll:如果目标集合包含指定集合中的所有元素,则返回true。
- addAll:将指定集合中的所有元素添加到目标集合中。
- removeAll:从目标集合中移除指定集合中包含的所有元素。
- retainAll:从目标集合中移除指定集合中不包含的所有元素。也就是说,它只保留目标集合中也包含在指定集合中的那些元素。
- clear:从集合中移除所有元素。
如果在执行操作的过程中修改了目标Collection,则addAll、removeAll和retainAll方法都返回true。
作为批量操作强大功能的一个简单示例,请考虑以下习惯用法,从集合c中删除指定元素e的所有实例。
c.removeAll(Collections.singleton(e));
更具体地说,假设您想从Collection中删除所有的空元素。
c.removeAll(Collections.singleton(null));
这个用法使用Collections.singleton它是一个静态工厂方法,返回一个只包含指定元素的不可变的Set。
集合接口数组操作
toArray方法作为集合和希望在输入时使用数组的旧api之间的桥梁。数组操作允许将集合的内容转换为数组。不带参数的简单表单创建一个新的Object数组。更复杂的形式允许调用者提供一个数组或选择输出数组的运行时类型。
例如,假设c是一个集合。下面的代码段将c的内容转储到一个新分配的Object数组中,该数组的长度与c中的元素数量相同。
Object[] a = c.toArray();
假设已知c只包含字符串(可能是因为c的类型是Collection)。下面的代码段将c的内容转储到一个新分配的String数组中,该数组的长度与c中的元素数量相同。
String[] a = c.toArray(new String[0]);
Set接口
Set是一个不能包含重复元素的集合。它模拟了数学集合的抽象。Set接口只包含从Collection继承的方法,并添加了禁止重复元素的限制。Set还在equals和hashCode操作的行为上添加了一个更强的契约,允许Set实例进行有意义的比较,即使它们的实现类型不同。如果两个Set实例包含相同的元素,则它们相等。
Java平台包含三个通用的Set实现:HashSet、TreeSet和LinkedHashSet。将元素存储在哈希表中的HashSet是性能最好的实现;然而,它不能保证迭代的顺序。TreeSet将其元素存储在红黑树中,根据元素的值对其进行排序;它比HashSet慢很多。LinkedHashSet实现为一个哈希表,其中运行一个链表,根据元素插入到集合中的顺序(插入顺序)对其进行排序。LinkedHashSet使它的客户免受HashSet提供的不明确的、通常混乱的排序,代价只是稍微高一些。
这里有一个简单但有用的Set用法。假设您有一个集合c,您想要创建另一个包含相同元素的集合,但删除所有重复的元素。下面的一行代码完成了这个任务。
Collection<Type> noDups = new HashSet<Type>(c);
它的工作原理是创建一个Set(根据定义,它不能包含重复项),最初包含c中的所有元素。它使用集合接口一节中描述的标准转换构造函数。
或者,如果使用JDK 8或更高版本,你可以很容易地使用聚合操作将其收集到Set中:
c.stream()
.collect(Collectors.toSet()); // no duplicates
下面是一个稍微长一点的例子,它将一个名称集合积累到一个TreeSet中:
Set<String> set = people.stream()
.map(Person::getName)
.collect(Collectors.toCollection(TreeSet::new));
下面是第一个习惯用法的一个小变体,它在删除重复元素的同时保持原始集合的顺序:
Collection<Type> noDups = new LinkedHashSet<Type>(c);
下面的泛型方法封装了前面的习惯用法,返回与所传递的泛型类型相同的Set。
public static <E> Set<E> removeDups(Collection<E> c) {
return new LinkedHashSet<E>(c);
}
Set接口基本操作
size操作返回Set中的元素数量(它的基数)。isEmpty方法所做的正是您所认为的。如果指定的元素不存在,则add方法将其添加到Set中,并返回一个布尔值,指示该元素是否已添加。类似地,如果Set中存在指定的元素,remove方法将从Set中删除该元素,并返回一个布尔值来指示该元素是否存在。iterator方法返回set的迭代器。
下面的程序在其参数列表中打印出所有不同的单词。本程序提供了两个版本。第一种使用JDK 8聚合操作。第二个使用for-each结构。
使用JDK 8聚合操作:
public class FindDups {
public static void main(String[] args) {
Set<String> distinctWords = Arrays.asList(args).stream()
.collect(Collectors.toSet());
System.out.println(distinctWords.size()+
" distinct words: " +
distinctWords);
}
}
使用for-each结构:
public class FindDups {
public static void main(String[] args) {
Set<String> s = new HashSet<String>();
for (String a : args)
s.add(a);
System.out.println(s.size() + " distinct words: " + s);
}
}
现在运行两个版本的程序。
java FindDups i came i saw i left
输出如下:
4 distinct words: [left, came, saw, i]
请注意,代码总是根据其接口类型(Set)而不是其实现类型引用集合。这是一种强烈推荐的编程实践,因为它为您提供了仅仅通过更改构造函数来更改实现的灵活性。如果用于存储集合的变量或用于传递集合的参数被声明为集合的实现类型而不是接口类型,则必须更改所有这些变量和参数,以便更改其实现类型。
此外,也不能保证生成的程序能正常工作。如果程序使用了原始实现类型中存在而新实现类型中没有的任何非标准操作,则程序将失败。仅通过集合的接口引用集合可以防止您使用任何非标准操作。
在前面的例子中,Set的实现类型是HashSet,它不保证Set中元素的顺序。如果您希望程序按字母顺序打印单词列表,只需将Set的实现类型从HashSet更改为TreeSet。进行这个简单的一行更改会导致前面示例中的命令行生成以下输出。
java FindDups i came i saw i left
4 distinct words: [came, i, left, saw]
Set接口批量操作
批量操作特别适合于集合;当应用时,它们执行标准的集合代数运算。假设s1和s2是集合。以下是批量操作的内容:
- s1.containsAll(s2):如果s2是s1的子集,则返回true。(如果集合s1包含s2中的所有元素,则s2是s1的子集。)
- s1.addAll(s2):将s1变换成s1和s2的并集。(两个集合的并集是包含其中一个集合中包含的所有元素的集合。)
- s1.retainAll(s2) :将s1变换成s1和s2的交点。(两个集合的交集是只包含两个集合共有元素的集合。)
- s1.removeAll(s2):将s1转换为s1和s2的(非对称)集差。(例如,s1 - s2的集合差值是包含s1中存在但s2中没有的所有元素的集合。)
要以非破坏性的方式(不修改任何一个集合)计算两个集合的并集、交集或集差,调用者必须在调用适当的批量操作之前复制一个集合。下面是生成的用法。
Set<Type> union = new HashSet<Type>(s1);
union.addAll(s2);
Set<Type> intersection = new HashSet<Type>(s1);
intersection.retainAll(s2);
Set<Type> difference = new HashSet<Type>(s1);
difference.removeAll(s2);
在前面的习惯用法中,结果集的实现类型是HashSet,如前所述,它是Java平台中最好的全面的Set实现。但是,任何通用的Set实现都可以被替换。
让我们再来看看FindDups程序。假设您想知道参数列表中哪些单词只出现一次,哪些出现不止一次,但是您不希望重复打印任何副本。这个效果可以通过生成两个集合来实现——一个包含参数列表中的每个单词,另一个只包含重复的单词。只出现一次的词就是这两个集合的差值,我们知道如何计算。下面是程序。
public class FindDups2 {
public static void main(String[] args) {
Set<String> uniques = new HashSet<String>();
Set<String> dups = new HashSet<String>();
for (String a : args)
if (!uniques.add(a))
dups.add(a);
// Destructive set-difference
uniques.removeAll(dups);
System.out.println("Unique words: " + uniques);
System.out.println("Duplicate words: " + dups);
}
}
当使用前面使用的相同参数列表运行时(i came i saw i left),程序产生以下输出。
Unique words: [left, saw, came]
Duplicate words: [i]
一个不太常见的集合代数运算是对称集差——包含在两个指定集合中的一个但不同时包含两个指定集合中的元素的集合。下面的代码非破坏性地计算两个集合的对称集差。
Set<Type> symmetricDiff = new HashSet<Type>(s1);
symmetricDiff.addAll(s2);
Set<Type> tmp = new HashSet<Type>(s1);
tmp.retainAll(s2);
symmetricDiff.removeAll(tmp);
Set接口数组操作
除了对其他集合所做的操作外,数组操作对集合没有任何特殊的作用。这些操作将在集合接口一节中进行描述。
List接口
List是一个有序的集合(有时称为序列)。列表可能包含重复的元素。除了从Collection继承的操作之外,List接口还包括以下操作:
- 位置访问:根据元素在列表中的数值位置操作元素。这包括get、set、add、addAll和remove等方法。
- 检索:在列表中搜索指定对象并返回其数值位置。搜索方法包括indexOf和lastIndexOf。
- 迭代:继承迭代器语义,以利用列表的顺序性。listIterator方法提供了这种行为。
- 范围视图:子列表方法对列表执行任意范围操作。
Java平台包含两个通用的List实现。ArrayList通常是性能更好的实现,LinkedList在某些情况下提供了更好的性能。
集合操作
从Collection继承的操作都按照您的期望执行,假设您已经熟悉它们。如果您不熟悉Collection中的内容,那么现在最好阅读一下集合接口一节。remove操作总是从列表中删除指定元素的第一个匹配项。add和addAll操作总是将新元素附加到列表的末尾。因此,下面的习惯用法将一个列表连接到另一个列表。
list1.addAll(list2);
下面是这种习惯用法的一种非破坏性形式,它生成了第三个List,其中包含了附加在第一个List之后的第二个List。
List<Type> list3 = new ArrayList<Type>(list1);
list3.addAll(list2);
注意,这种习惯用法在其非破坏性形式中利用了ArrayList的标准转换构造函数。
下面是一个例子(JDK 8及以后版本),它聚合了一些名字到一个List中:
List<String> list = people.stream()
.map(Person::getName)
.collect(Collectors.toList());
像Set接口一样,List加强了对equals和hashCode方法的要求,以便两个List对象可以在不考虑其实现类的情况下进行逻辑相等性比较。如果两个List对象以相同的顺序包含相同的元素,则它们相等。
位置访问和搜索操作
基本的位置访问操作是get, set, add 和 remove。(set和remove操作返回被覆盖或删除的旧值。)其他操作(indexOf和lastIndexOf)返回列表中指定元素的第一个或最后一个索引。
addAll操作从指定的位置开始插入指定集合的所有元素。元素按照指定的集合迭代器返回的顺序插入。这个调用是与Collection的addAll操作类似的位置访问。
这里有一个小方法来交换List中的两个索引值。
public static <E> void swap(List<E> a, int i, int j) {
E tmp = a.get(i);
a.set(i, a.get(j));
a.set(j, tmp);
}
当然,有一个很大的区别。这是一种多态算法:它交换任何List中的两个元素,无论其实现类型如何。下面是另一个多态算法,它使用了前面的交换方法。
public static void shuffle(List<?> list, Random rnd) {
for (int i = list.size(); i > 1; i--)
swap(list, i - 1, rnd.nextInt(i));
}
该算法包含在Java平台的Collections类中,它使用指定的随机性随机置换指定的列表。这有点微妙:它从底部向上运行列表,反复交换随机选择的元素到当前位置。与大多数单纯的洗牌尝试不同的是,它是公平的(所有排列发生的可能性相等,假设一个无偏的随机性源)和快速的(需要精确的list.size()-1交换)。下面的程序使用这个算法以随机顺序打印参数列表中的单词。
public class Shuffle {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
for (String a : args)
list.add(a);
Collections.shuffle(list, new Random());
System.out.println(list);
}
}
事实上,这个程序可以做得更短更快。Arrays类有一个名为asList的静态工厂方法,它允许将数组视为List。此方法不复制数组。List中的更改会写入数组,反之亦然。生成的List不是一个通用的List实现,因为它没有实现(可选的)添加和删除操作:数组是不可调整大小的。利用数组。asList和调用shuffle的库版本(它使用默认的随机性源),您将得到下面的小程序,它的行为与前面的程序相同。
public class Shuffle {
public static void main(String[] args) {
List<String> list = Arrays.asList(args);
Collections.shuffle(list);
System.out.println(list);
}
}
迭代器
如您所料,List的Iterator操作返回的Iterator以正确的顺序返回列表中的元素。List还提供了一个更丰富的迭代器,称为ListIterator,它允许您在两个方向上遍历列表,在迭代期间修改列表,并获取迭代器的当前位置。
ListIterator从Iterator继承的三个方法(hasNext、next和remove)在两个接口中做了完全相同的事情。hasPrevious和前面的操作与hasNext和next完全相似。前一个操作指向(隐式)游标前的元素,而后一个操作指向游标后的元素。前一个操作将光标向后移动,而next操作将光标向前移动。
下面是向后遍历列表的标准习惯用法。
for (ListIterator<Type> it = list.listIterator(list.size()); it.hasPrevious(); ) {
Type t = it.previous();
...
}
注意上一个用法中listIterator的参数。List接口有两种形式的listIterator方法。不带参数的窗体返回一个定位在列表开头的ListIterator;带有int参数的窗体返回一个定位在指定索引处的ListIterator对象。该索引指的是对next的初始调用将返回的元素。对previous的初始调用将返回索引为index-1的元素。在一个长度为n的列表中,有n+1个有效的索引值,从0到n(含n)。
直观地说,游标总是在两个元素之间——一个是调用previous返回的元素,一个是调用next返回的元素。n+1个有效的索引值对应于元素之间的n+1个间隔,从第一个元素之前的间隔到最后一个元素之后的间隔。下图显示了包含四个元素的列表中的五个可能的光标位置。
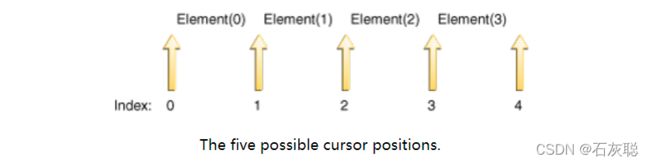
对next和previous的调用可以混合使用,但必须小心一点。对previous的第一次调用返回与对next的最后一次调用相同的元素。类似地,在对previous的一系列调用之后,对next的第一次调用将返回与对previous的最后一次调用相同的元素。
nextIndex方法返回将由后续调用next返回的元素的索引,而previousIndex返回将由后续调用previous返回的元素的索引,这不足为奇。这些调用通常用于报告发现某物的位置,或者记录ListIterator的位置,以便创建另一个具有相同位置的ListIterator。
nextIndex返回的数字总是比previousIndex返回的数字大1,这也不足为奇。这意味着两种边界情况的行为:(1)当游标在初始元素返回-1之前时调用previousIndex,(2)当游标在最终元素返回list.size()之后时调用nextIndex。为了使所有这些具体化,下面是List.indexOf的一个可能实现。
public int indexOf(E e) {
for (ListIterator<E> it = listIterator(); it.hasNext(); )
if (e == null ? it.next() == null : e.equals(it.next()))
return it.previousIndex();
// Element not found
return -1;
}
请注意,indexOf方法返回it.previousindex(),即使它正在向前遍历列表。原因是,它的nextindex()将返回我们将要检查的元素的索引,而我们希望返回我们刚刚检查的元素的索引。
Iterator接口提供了remove操作,用于从Collection中删除next返回的最后一个元素。对于ListIterator,此操作删除next或previous返回的最后一个元素。ListIterator接口提供了两个额外的操作来修改列表——set和add。set方法用指定的元素覆盖next或previous返回的最后一个元素。下面的多态算法使用set来用另一个指定值替换所有出现的值。
public static <E> void replace(List<E> list, E val, E newVal) {
for (ListIterator<E> it = list.listIterator(); it.hasNext(); )
if (val == null ? it.next() == null : val.equals(it.next()))
it.set(newVal);
}
这个例子中唯一的小技巧是val和it.next之间的相等性检验。为了防止NullPointerException异常,需要特殊处理val值为null的情况。
add方法将一个新元素插入到列表中紧挨着当前光标位置的位置。下面的多态算法演示了这个方法,它用指定列表中包含的值序列替换所有出现的指定值。
public static <E>
void replace(List<E> list, E val, List<? extends E> newVals) {
for (ListIterator<E> it = list.listIterator(); it.hasNext(); ){
if (val == null ? it.next() == null : val.equals(it.next())) {
it.remove();
for (E e : newVals)
it.add(e);
}
}
}
范围视图操作
范围视图操作subblist (int fromIndex, int toIndex)返回列表中索引范围从fromIndex(包含的)到toIndex(独占的)的那一部分的List视图。这种半开放范围反映了典型的for循环。
for (int i = fromIndex; i < toIndex; i++) {
...
}
正如视图这个术语所暗示的那样,返回的List由调用子列表的List备份,因此前者的更改反映在后者中。
该方法消除了显式范围操作的需要(数组通常存在的排序)。任何需要List的操作都可以通过传递subList视图而不是整个List来作为范围操作。例如,下面的习惯用法从List中删除了一系列元素。
list.subList(fromIndex, toIndex).clear();
可以构造类似的习惯用法来搜索范围内的元素。
int i = list.subList(fromIndex, toIndex).indexOf(o);
int j = list.subList(fromIndex, toIndex).lastIndexOf(o);
注意,前面的习惯用法返回在子列表中找到的元素的索引,而不是后面列表中的索引。
任何对List进行操作的多态算法,比如replace和shuffle例子,都可以使用subblist返回的List。
这里有一个多态算法,它的实现使用子列表来处理牌组中的手。也就是说,它返回一个新的List(“hand”),其中包含从指定的List(“deck”)末尾获取的指定数量的元素。返回的元素将从牌组中移除。
public static <E> List<E> dealHand(List<E> deck, int n) {
int deckSize = deck.size();
List<E> handView = deck.subList(deckSize - n, deckSize);
List<E> hand = new ArrayList<E>(handView);
handView.clear();
return hand;
}
请注意,该算法将手从牌组的末尾移除。对于许多常见的List实现,如ArrayList,从列表末尾删除元素的性能要比从列表开头删除元素的性能好得多。
下面是一个结合使用dealHand方法和Collections.shuffle的程序。洗牌从正常的52张牌组中产生手牌。该程序接受两个命令行参数:(1)要发牌的手数和(2)每一手牌的牌数。
public class Deal {
public static void main(String[] args) {
if (args.length < 2) {
System.out.println("Usage: Deal hands cards");
return;
}
int numHands = Integer.parseInt(args[0]);
int cardsPerHand = Integer.parseInt(args[1]);
// Make a normal 52-card deck.
String[] suit = new String[] {
"spades", "hearts",
"diamonds", "clubs"
};
String[] rank = new String[] {
"ace", "2", "3", "4",
"5", "6", "7", "8", "9", "10",
"jack", "queen", "king"
};
List<String> deck = new ArrayList<String>();
for (int i = 0; i < suit.length; i++)
for (int j = 0; j < rank.length; j++)
deck.add(rank[j] + " of " + suit[i]);
// Shuffle the deck.
Collections.shuffle(deck);
if (numHands * cardsPerHand > deck.size()) {
System.out.println("Not enough cards.");
return;
}
for (int i = 0; i < numHands; i++)
System.out.println(dealHand(deck, cardsPerHand));
}
public static <E> List<E> dealHand(List<E> deck, int n) {
int deckSize = deck.size();
List<E> handView = deck.subList(deckSize - n, deckSize);
List<E> hand = new ArrayList<E>(handView);
handView.clear();
return hand;
}
}
运行该程序产生如下所示的输出。
% java Deal 4 5
[8 of hearts, jack of spades, 3 of spades, 4 of spades,
king of diamonds]
[4 of diamonds, ace of clubs, 6 of clubs, jack of hearts,
queen of hearts]
[7 of spades, 5 of spades, 2 of diamonds, queen of diamonds,
9 of clubs]
[8 of spades, 6 of diamonds, ace of spades, 3 of hearts,
ace of hearts]
虽然sublist操作非常强大,但在使用它时必须非常小心。sublist返回的List的语义是未定义的,如果元素以除了通过返回的List之外的任何方式被添加或从支持List中移除。因此,强烈建议您只使用subblist返回的List作为一个瞬态对象—对backing List执行一个或一系列范围操作。使用子列表实例的时间越长,通过直接修改支持列表或通过另一个子列表对象修改它的可能性就越大。注意,修改子列表的子列表和继续使用原始子列表是合法的(尽管不是并发的)。
链表的算法
Collections类中的大多数多态算法都专门应用于List。拥有所有这些算法,可以很容易地操作列表。下面是这些算法的总结,在算法一节中有更详细的描述。
- sort(排序) :使用归并排序算法对List进行排序,归并排序算法提供了快速、稳定的排序。(稳定排序是不对相等的元素重新排序的排序。)
- shuffle(随机算法):随机排列List中的元素。
- reverse(反向算法) :颠倒List中元素的顺序。
- rotate(旋转算法) :将List中的所有元素旋转指定的距离。
- swap(交换算法) :交换List中指定位置的元素。
- replaceAll :用另一个指定值替换出现的所有指定值。
- fill(快速算法) :用指定的值重写List中的每个元素。
- copy(复制算法) :将源List复制到目标List中。
- binarySearch(二分查找) :使用二分搜索算法在有序列表中搜索元素。
- indexOfSubList:返回一个List的第一个子列表的索引,该子列表等于另一个。
- lastIndexOfSubList :返回一个List的最后一个子列表的索引,该子列表与另一个列表相等。
Queue 接口
Queue是在处理之前保存元素的集合。除了基本的Collection操作之外,队列还提供了额外的插入、删除和检查操作。
public interface Queue<E> extends Collection<E> {
E element();
boolean offer(E e);
E peek();
E poll();
E remove();
}
每个Queue中的方法以两种形式存在:(1)一个方法在操作失败时抛出一个异常,(2)另一个方法在操作失败时返回一个特殊值(根据操作的不同,可以是null或false)。接口规则结构如下表所示。

队列通常(但不一定)以FIFO(先进先出)方式对元素排序。优先级队列是例外,它根据元素的值对元素排序——详细信息请参阅对象排序部分)。无论使用何种排序,队列的头部元素都将被删除通过remove或poll方法。在FIFO队列中,所有新元素都插入到队列的尾部。其他类型的队列可能使用不同的放置规则。每个Queue实现必须指定其排序属性。
Queue实现可以限制其持有的元素数量;这样的队列被称为有界队列。在java.util.concurrent中,一些Queue的实现是有界的,但在java中的java.util没有。
Queue从Collection继承的add方法插入一个元素,除非它违反队列的容量限制,在这种情况下,它将抛出IllegalStateException。仅用于有界队列的offer方法与add方法的不同之处在于,它通过返回false来表示插入元素失败。
remove和poll方法都删除和返回队列的头部。确切地说是哪个元素被删除了是队列排序策略的函数。只有当队列为空时,remove和poll方法的行为才会不同。在这些情况下,删除抛出NoSuchElementException,而轮询返回null。
element和peek方法返回但不删除队列头部。它们之间的区别和remove和poll相同。如果队列为空,element抛出NoSuchElementException,而peek返回null。
队列实现通常不允许插入空元素。LinkedList也实现了Queue但是它是一个例外。由于历史原因,它允许空元素,但是您应该避免利用这一点,因为null被poll和peek方法用作特殊的返回值。队列实现通常不会定义equals和hashCode方法的基于元素的版本,而是从Object继承基于身份的版本。
Queue接口没有定义阻塞队列方法,这在并发编程中很常见。这些方法继承Queue且在接口java.util.concurrent.BlockingQueue中定义,它们等待元素出现或等待可用的空间。
在下面的示例程序中,使用队列来实现倒计时计时器。队列预加载从命令行上指定的数字到0的所有整数值(按降序排列)。然后,这些值将从队列中删除,并以一秒钟的时间间隔打印出来。
这个程序是人工的,在不使用队列的情况下做同样的事情会更自然,但它演示了在后续处理之前使用队列存储元素。
public class Countdown {
public static void main(String[] args) throws InterruptedException {
int time = Integer.parseInt(args[0]);
Queue<Integer> queue = new LinkedList<Integer>();
for (int i = time; i >= 0; i--)
queue.add(i);
while (!queue.isEmpty()) {
System.out.println(queue.remove());
Thread.sleep(1000);
}
}
}
在下面的例子中,优先队列用于对一组元素进行排序。这个程序也是人为的,没有理由使用它来支持Collection中提供的排序方法,但它说明了优先级队列的行为。
static <E> List<E> heapSort(Collection<E> c) {
Queue<E> queue = new PriorityQueue<E>(c);
List<E> result = new ArrayList<E>();
while (!queue.isEmpty())
result.add(queue.remove());
return result;
}
Deque接口
通常发音为deck, deque是一个双端队列。双端队列是元素的线性集合,支持在两个端点插入和删除元素。Deque接口是一种比Stack和Queue更丰富的抽象数据类型,因为它同时实现了栈和队列。Deque接口定义了访问Deque实例两端元素的方法。提供了插入、删除和检查元素的方法。像ArrayDeque和LinkedList这样的预定义类实现了Deque接口。
请注意,Deque接口既可以用作后进先出堆栈,也可以用作先进先出队列。Deque接口中给出的方法分为三部分:
插入
addfirst和offerFirst方法在Deque实例的开头插入元素。方法addLast和offerLast在Deque实例的末尾插入元素。当Deque实例的容量受到限制时,首选的方法是offerFirst和offerLast,因为如果addFirst已满,它可能会抛出异常。
删除
removeFirst和pollFirst方法从Deque实例的开头移除元素。removeLast和pollLast方法从末尾删除元素。当Deque为空时,方法pollFirst和pollLast返回null,而当Deque的实例为空时,方法removeFirst和removeLast抛出异常。
检索
方法getFirst和peekFirst检索Deque实例的第一个元素。这些方法不会从Deque实例中删除值。类似地,getLast和peekLast方法检索最后一个元素。如果deque实例为空,getFirst和getLast方法会抛出异常,而peekFirst和peekLast方法则返回NULL。
Deque元素的12种插入、删除和检索方法总结如下表:
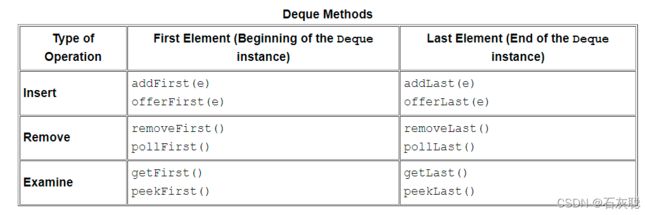
除了这些插入、删除和检查Deque实例的基本方法外,Deque接口还有一些预定义的方法。其中之一是removefirststocecuence,如果指定元素存在于Deque实例中,该方法将删除该元素第一次出现的地方。如果该元素不存在,则Deque实例保持不变。另一个类似的方法是removelastoccuen;该方法删除Deque实例中指定元素的最后一次出现。这些方法的返回类型为布尔型,如果元素存在于Deque实例中,则返回true。
Map接口
Map是一个将键映射到值的对象。map不能包含重复的键:每个键最多只能映射到一个值。它模拟了数学函数的抽象。Map接口包括用于基本操作(如put、get、remove、containsKey、containsValue、size和empty)、批量操作(如putAll和clear)和集合视图(如keySet、entrySet和values)的方法。
Java平台包含三个通用的Map实现:HashMap、TreeMap和LinkedHashMap。它们的行为和性能完全类似于HashSet、TreeSet和LinkedHashSet,如Set接口一节所述。
本页面的其余部分将详细讨论Map接口。但首先,这里有更多的收集到的使用JDK 8聚合操作的示例。在面向对象编程中,为真实世界的对象建模是一项常见的任务,因此可以合理地认为,一些程序可能会,例如,按部门分组员工:
// Group employees by department
Map<Department, List<Employee>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));
或按部门计算所有工资总额:
// Compute sum of salaries by department
Map<Department, Integer> totalByDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.summingInt(Employee::getSalary)));
或者可以通过及格或不及格来分组:
// Partition students into passing and failing
Map<Boolean, List<Student>> passingFailing = students.stream()
.collect(Collectors.partitioningBy(s -> s.getGrade()>= PASS_THRESHOLD));
你也可以按城市对人们进行分组:
// Classify Person objects by city
Map<String, List<Person>> peopleByCity
= personStream.collect(Collectors.groupingBy(Person::getCity));
甚至可以将两个收藏家按州和城市分类:
// Cascade Collectors
Map<String, Map<String, List<Person>>> peopleByStateAndCity
= personStream.collect(Collectors.groupingBy(Person::getState,
Collectors.groupingBy(Person::getCity)))
同样,这些只是关于如何使用新的JDK 8 api的一些例子。有关lambda表达式和聚合操作的深入介绍,请参阅名为聚合操作的一课。
Map接口基本操作
Map的基本操作(put、get、containsKey、containsValue、size和isEmpty)的行为与Hashtable中的对应操作完全一样。下面的程序生成一个词频表,该词频表包含其参数列表中找到的单词。频率表将每个单词映射到它在参数列表中出现的次数。
public class Freq {
public static void main(String[] args) {
Map<String, Integer> m = new HashMap<String, Integer>();
// Initialize frequency table from command line
for (String a : args) {
Integer freq = m.get(a);
m.put(a, (freq == null) ? 1 : freq + 1);
}
System.out.println(m.size() + " distinct words:");
System.out.println(m);
}
}
这个程序唯一棘手的地方是put语句的第二个参数。该参数是一个条件表达式,其效果是,如果单词以前从未见过,则将频率设置为1;如果单词已经见过,则将频率设置为比当前值多1。试着用下面的命令运行这个程序:
java Freq if it is to be it is up to me to delegate
该程序产生以下输出。
8 distinct words:
{to=3, delegate=1, be=1, it=2, up=1, if=1, me=1, is=2}
假设您希望按照字母顺序查看频率表。您所要做的就是将Map的实现类型从HashMap更改为TreeMap。进行这4个字符的更改将导致程序从同一命令行生成以下输出。
8 distinct words:
{be=1, delegate=1, if=1, is=2, it=2, me=1, to=3, up=1}
类似地,只需将映射的实现类型更改为LinkedHashMap,就可以让程序按照单词在命令行上首次出现的顺序打印频率表。这样做会得到以下输出。
8 distinct words:
{if=1, it=2, is=2, to=3, be=1, up=1, me=1, delegate=1}
这种灵活性有力地说明了基于接口的框架的强大功能。像set和listinterface一样,Map加强了对equals和hashCode方法的要求,以便两个Map对象可以在不考虑其实现类型的情况下进行逻辑相等性比较。如果两个Map实例表示相同的键值映射,则它们是相等的。按照约定,所有通用Map实现都提供了构造函数,这些构造函数接受Map对象并初始化新的Map以包含指定Map中的所有键-值映射。这个标准的Map转换构造函数完全类似于标准的Collection构造函数:它允许调用者创建所需实现类型的Map,该Map最初包含另一个Map中的所有映射,而与另一个Map的实现类型无关。例如,假设您有一个名为m的Map。下面的一行代码创建了一个新的HashMap,它最初包含与m相同的所有键值映射。
Map<K, V> copy = new HashMap<K, V>(m);
Map接口批量操作
清理操作就像你想的那样:它从Map中删除所有映射。putAll操作是Collection接口的addAll操作的Map模拟。除了将一个Map映射到另一个Map之外,它还有一个更微妙的用途。假设一个Map被用来表示一个属性值对的集合;putAll操作结合Map转换构造函数,提供了一种使用默认值实现属性映射创建的简洁方法。下面的静态工厂方法演示了这种技术。
static <K, V> Map<K, V> newAttributeMap(Map<K, V>defaults, Map<K, V> overrides) {
Map<K, V> result = new HashMap<K, V>(defaults);
result.putAll(overrides);
return result;
}
集合视图
集合视图方法允许Map以以下三种方式被视为一个集合:
- keySet :Map中包含的键的Set集合。
- **values **:Map中包含的值的集合。这个集合不是一个Set集合,因为多个键可以映射到相同的值。
- **entrySet **:Map中包含的键值对的Set集合。Map接口提供了一个称为Map.Entry的小型嵌套接口,是Set集合中元素的类型。
Collection视图提供了在Map上迭代的唯一方法。下面的例子说明了在带有for-each构造的Map中迭代键的标准习惯用法:
for (KeyType key : m.keySet())
System.out.println(key);
对于迭代器:
// Filter a map based on some
// property of its keys.
for (Iterator<Type> it = m.keySet().iterator(); it.hasNext(); )
if (it.next().isBogus())
it.remove();
迭代值的习惯用法与此类似。下面是在键值对上迭代的习惯用法。
for (Map.Entry<KeyType, ValType> e : m.entrySet())
System.out.println(e.getKey() + ": " + e.getValue());
起初,许多人担心这些习惯用法可能会很慢,因为每次调用Collection视图操作时,Map都必须创建一个新的Collection实例。很简单:Map在每次请求给定的Collection视图时,没有理由总是返回相同的对象。这正是java.util中所有Map实现的内容。
对于这三个Collection视图,调用Iterator的remove操作会从backing Map中移除关联的条目,假设backing Map一开始就支持元素移除。前面的过滤习惯用法说明了这一点。
对于entrySet视图,在迭代过程中也可以通过调用Map.Entry的setValue方法来改变与键相关联的值(同样,假设Map一开始就支持修改值)。注意,这些是在迭代过程中修改Map的唯一安全的方法;当迭代进行时,如果底层Map以任何其他方式被修改,则该行为是未指定的。
集合视图支持所有形式的元素移除——remove、removeAll、retainAll和clear操作,以及Iterator.remove删除操作。(同样,这假设支持的Map支持元素移除。)
Collection视图在任何情况下都不支持添加元素。它对于keySet和values视图没有意义,对于entrySet视图也没有必要,因为backing Map的put和putAll方法提供了相同的功能。
集合视图的奇妙使用:映射代数(Map Algebra)
当应用于Collection视图时,批量操作(containsAll、removeAll和retainAll)是非常有效的工具。对于初学者,假设您想知道一个Map是否为另一个Map的子Map —— 也就是说,第一个Map是否包含第二个Map中的所有键值映射。下面这个用法很管用。
if (m1.entrySet().containsAll(m2.entrySet())) {
...
}
类似地,假设您想知道两个Map对象是否包含对所有相同键的映射。
if (m1.keySet().equals(m2.keySet())) {
...
}
假设您有一个Map表示属性-值对的集合,两个set表示必需的属性和允许的属性。(允许的属性包括必需的属性。)下面的代码片段确定属性映射是否符合这些约束,如果不符合,则打印详细的错误消息。
static <K, V> boolean validate(Map<K, V> attrMap, Set<K> requiredAttrs, Set<K>permittedAttrs) {
boolean valid = true;
Set<K> attrs = attrMap.keySet();
if (! attrs.containsAll(requiredAttrs)) {
Set<K> missing = new HashSet<K>(requiredAttrs);
missing.removeAll(attrs);
System.out.println("Missing attributes: " + missing);
valid = false;
}
if (! permittedAttrs.containsAll(attrs)) {
Set<K> illegal = new HashSet<K>(attrs);
illegal.removeAll(permittedAttrs);
System.out.println("Illegal attributes: " + illegal);
valid = false;
}
return valid;
}
假设您想知道两个Map对象的所有公共键。
Set<KeyType>commonKeys = new HashSet<KeyType>(m1.keySet());
commonKeys.retainAll(m2.keySet());
一个类似的用法可以让你得到同样的值。
到目前为止,所有的用法都是非破坏性的;也就是说,它们不修改后台Map。这里有一些是这样的。假设您想要删除一个Map与另一个Map共有的所有键值对。
m1.entrySet().removeAll(m2.entrySet());
假设您想要从一个Map中删除所有在另一个Map中有映射的键。
m1.keySet().removeAll(m2.keySet());
当您开始在相同的批量操作中混合键和值时会发生什么?假设您有一个Map, managers,它将公司中的每个员工映射到员工的经理。我们将故意模糊键和值对象的类型。没关系,只要它们是一样的。现在假设您想知道所有的“个体贡献者”(或非管理人员)是谁。下面的代码片段准确地告诉了您想知道的内容。
Set<Employee> individualContributors = new HashSet<Employee>(managers.keySet());
individualContributors.removeAll(managers.values());
假设您想要解雇所有直接向某个经理Simon汇报的员工。
Employee simon = ... ;
managers.values().removeAll(Collections.singleton(simon));
注意,这种习惯用法使用了Collections.singleton,一个静态工厂方法,它返回一个带有单个指定元素的不可变Set。
一旦你这样做了,你可能会有一群员工,他们的经理不再为公司工作(如果Simon的直接下属本身就是经理的话)。下面的代码将告诉您哪些员工的经理不再为该公司工作。
Map<Employee, Employee> m = new HashMap<Employee, Employee>(managers);
m.values().removeAll(managers.keySet());
Set<Employee> slackers = m.keySet();
这个例子有点棘手。首先,它生成Map的临时副本,并从临时副本中删除(manager)值为原始Map中的键的所有条目。请记住,原始Map为每个员工都有一个条目。因此,临时Map中的其余条目包含来自原始Map (manager)值不再为雇员的所有条目。因此,临时副本中的键恰好代表了我们要寻找的员工。
还有许多类似于本节中所包含的用法,但将它们全部列出既不实际又乏味。一旦你掌握了它的窍门,当你需要它的时候,想出正确的方法并不难。
多重映射
multimap类似于Map,但它可以将每个键映射到多个值。Java集合框架没有包含multimap的接口,因为它们并不经常被使用。使用值为List实例的Map作为multimap容器是相当简单的事情。在下一个代码示例中演示了这种技术,它读取每行包含一个单词的单词列表(都是小写的),并打印出满足大小标准的所有拼字组。变位词组是一组单词,所有的单词都包含完全相同的字母,但顺序不同。该程序在命令行上接受两个参数:(1)字典文件的名称和(2)要打印的拼字组的最小大小。包含少于指定最小字数的字谜组将不被打印。
找到字谜组有一个标准的诀窍:对于字典中的每个单词,将单词中的字母按字母顺序排列(即将单词中的字母按字母顺序重新排序),并将一个条目放入multimap容器中,将按字母顺序排列的单词映射到原始单词。例如,单词bad导致将abd映射为bad的项放入multimap容器中。经过片刻的思考,你会发现,任何给定的键映射所对应的所有单词都构成了一个变位词组。迭代multimap容器中的键很简单,可以打印出满足大小限制的每个字谜组。
下面的程序是这种技术的一个简单实现。
public class Anagrams {
public static void main(String[] args) {
int minGroupSize = Integer.parseInt(args[1]);
// Read words from file and put into a simulated multimap
Map<String, List<String>> m = new HashMap<String, List<String>>();
try {
Scanner s = new Scanner(new File(args[0]));
while (s.hasNext()) {
String word = s.next();
String alpha = alphabetize(word);
List<String> l = m.get(alpha);
if (l == null)
m.put(alpha, l=new ArrayList<String>());
l.add(word);
}
} catch (IOException e) {
System.err.println(e);
System.exit(1);
}
// Print all permutation groups above size threshold
for (List<String> l : m.values())
if (l.size() >= minGroupSize)
System.out.println(l.size() + ": " + l);
}
private static String alphabetize(String s) {
char[] a = s.toCharArray();
Arrays.sort(a);
return new String(a);
}
}
在一个173,000字的字典文件上运行这个程序,其最小字谜组大小为8个,会产生以下输出。
9: [estrin, inerts, insert, inters, niters, nitres, sinter,
triens, trines]
8: [lapse, leaps, pales, peals, pleas, salep, sepal, spale]
8: [aspers, parses, passer, prases, repass, spares, sparse,
spears]
10: [least, setal, slate, stale, steal, stela, taels, tales,
teals, tesla]
8: [enters, nester, renest, rentes, resent, tenser, ternes,
treens]
8: [arles, earls, lares, laser, lears, rales, reals, seral]
8: [earings, erasing, gainers, reagins, regains, reginas,
searing, seringa]
8: [peris, piers, pries, prise, ripes, speir, spier, spire]
12: [apers, apres, asper, pares, parse, pears, prase, presa,
rapes, reaps, spare, spear]
11: [alerts, alters, artels, estral, laster, ratels, salter,
slater, staler, stelar, talers]
9: [capers, crapes, escarp, pacers, parsec, recaps, scrape,
secpar, spacer]
9: [palest, palets, pastel, petals, plates, pleats, septal,
staple, tepals]
9: [anestri, antsier, nastier, ratines, retains, retinas,
retsina, stainer, stearin]
8: [ates, east, eats, etas, sate, seat, seta, teas]
8: [carets, cartes, caster, caters, crates, reacts, recast,
traces]
其中很多词看起来有点假,但这不是程序的错;它们在字典文件中。下面是我们使用的字典文件。它源于公共域启用基准(Public Domain ENABLE )参考单词列表。
字典文件
对象排序
List l可以按如下顺序排序。
Collections.sort(l);
如果List由String元素组成,则将按字母顺序进行排序。如果它由Date元素组成,则将按时间顺序进行排序。这是怎么发生的?String和Date都实现了Comparable接口。类似的实现为类提供了一种自然的排序,这允许对该类的对象进行自动排序。下表总结了一些实现Comparable的更重要的Java平台类。
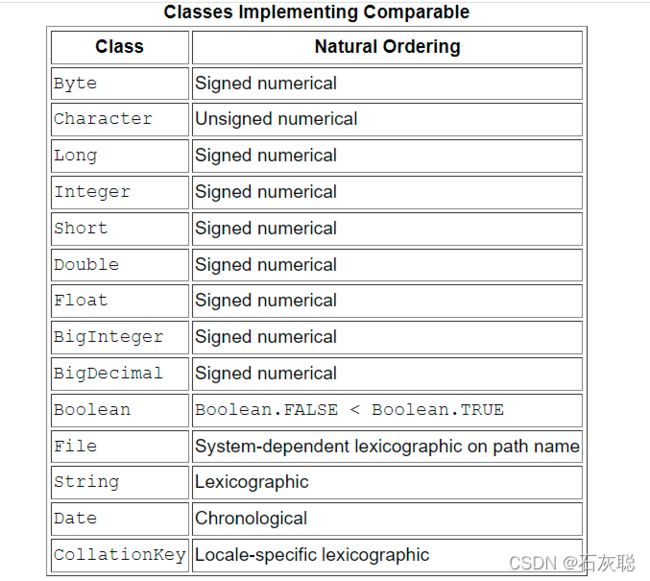
译文:如果你试图对一个列表进行排序,其中的元素没有实现Comparable, Collections.sort(list)将抛出一个ClassCastException。同样,集合。sort(list, comparator)将抛出一个ClassCastException,如果您试图对一个不能使用比较器对元素进行比较的列表进行排序。可以互相比较的元素称为相互比较的元素。虽然不同类型的元素可以相互比较,但这里列出的类都不允许类间比较。
如果您只想对可比元素列表进行排序,或者创建它们的排序集合,那么这就是您真正需要了解的有关可比接口的全部内容。如果您想要实现自己的Comparable类型,那么您将对下一节感兴趣。
写出你自己的可比类型
Comparable接口由以下方法组成。
public interface Comparable<T> {
public int compareTo(T o);
}
compareTo方法将接收对象与指定对象进行比较,并根据接收对象是否小于、等于或大于指定对象返回一个负整数、0或正整数。如果指定的对象不能与接收对象进行比较,该方法将抛出一个ClassCastException。
下面表示Name的类实现了Comparable。
public class Name implements Comparable<Name> {
private final String firstName, lastName;
public Name(String firstName, String lastName) {
if (firstName == null || lastName == null)
throw new NullPointerException();
this.firstName = firstName;
this.lastName = lastName;
}
public String firstName() { return firstName; }
public String lastName() { return lastName; }
public boolean equals(Object o) {
if (!(o instanceof Name))
return false;
Name n = (Name) o;
return n.firstName.equals(firstName) && n.lastName.equals(lastName);
}
public int hashCode() {
return 31*firstName.hashCode() + lastName.hashCode();
}
public String toString() {
return firstName + " " + lastName;
}
public int compareTo(Name n) {
int lastCmp = lastName.compareTo(n.lastName);
return (lastCmp != 0 ? lastCmp : firstName.compareTo(n.firstName));
}
}
为了保持前面的例子简短,这个类有一些限制:它不支持中间名,它需要姓和名,而且它没有以任何方式国际化。尽管如此,它说明了以下要点:
- 名称对象是不可变的。在所有其他条件相同的情况下,不可变类型是可行的,特别是对于在set中用作元素或在map中用作键的对象。如果您在集合中修改它们的元素或键,则这些集合将中断。
- 构造函数检查其参数是否为空。这确保了所有Name对象都是格式良好的,因此其他方法都不会抛出NullPointerException。
- hashCode方法被重新定义。这对于任何重新定义equals方法的类都是必要的。(相等的对象必须有相等的哈希码。)
- 如果指定的对象为空或不合适的类型,equals方法将返回false。在这些情况下,compareTo方法会抛出一个运行时异常。这两种行为都是各自方法的一般契约所要求的。
- toString方法已被重新定义,以便以人类可读的形式打印Name。这总是一个好主意,特别是对于那些要放入集合中的对象。各种集合类型的toString方法依赖于其元素、键和值的toString方法。
由于本节是关于元素排序的,所以让我们更多地讨论一下Name的compareTo方法。它实现了标准的名字排序算法,其中姓优先于名。这就是你想要的自然顺序。如果自然的秩序是不自然的,那将是非常令人困惑的!
看看compareTo是如何实现的,因为它非常典型。首先,比较对象的最重要部分(在本例中是姓)。通常,您可以使用部件类型的自然顺序。在本例中,部件是一个String,自然(字典)排序正是需要的。如果比较结果不是0(表示相等),那么就完成了:返回结果即可。如果最重要的部分是相等的,你继续比较下一个最重要的部分。在这种情况下,只有两个部分——姓和名。如果有更多的部分,您将按照明显的方式继续,比较部分,直到找到两个不相等的部分,或者比较最不重要的部分,这时您将返回比较的结果。
为了说明它的工作原理,这里有一个程序可以构建一个名称列表并对其进行排序。
public class NameSort {
public static void main(String[] args) {
Name nameArray[] = {
new Name("John", "Smith"),
new Name("Karl", "Ng"),
new Name("Jeff", "Smith"),
new Name("Tom", "Rich")
};
List<Name> names = Arrays.asList(nameArray);
Collections.sort(names);
System.out.println(names);
}
}
如果你运行这个程序,这是它输出的内容。
[Karl Ng, Tom Rich, Jeff Smith, John Smith]
对于compareTo方法的行为有四个限制,我们现在不讨论这些限制,因为它们相当技术性且枯燥,最好留在API文档中。所有实现Comparable的类都要遵守这些限制,这一点非常重要,所以如果您正在编写一个实现Comparable的类,请阅读Comparable的文档。试图对违反限制的对象列表进行排序的行为是未定义的。从技术上讲,这些限制确保了自然顺序是实现它的类对象的总顺序;这对于确保良好定义排序是必要的。
Comparators比较器
如果您想按照它们的自然顺序以外的顺序对某些对象进行排序,该怎么办?或者如果你想对一些没有实现Comparable的对象进行排序呢?要做到这两件事,你需要提供一个Comparator——一个封装排序的对象。与Comparable接口类似,Comparator接口由单个方法组成。
public interface Comparator<T> {
int compare(T o1, T o2);
}
compare方法比较它的两个参数,根据第一个参数是否小于、等于或大于第二个参数返回一个负整数、0或正整数。如果任何一个参数对Comparator具有不合适的类型,compare方法将抛出一个ClassCastException。
关于可比性所说的许多内容也适用于Comparator。编写compare方法与编写compareTo方法几乎相同,只是前者将两个对象作为参数传入。出于同样的原因,compare方法必须遵守与Comparable的compareTo方法相同的四个技术限制——Comparator必须在它所比较的对象上归纳出总的顺序。
假设您有一个名为Employee的类,如下所示。
public class Employee implements Comparable<Employee> {
public Name name() { ... }
public int number() { ... }
public Date hireDate() { ... }
...
}
让我们假设Employee实例的自然顺序是员工名的名称顺序(如前面示例中定义的那样)。不幸的是,老板要了一份按资历排序的员工名单。这意味着我们必须做一些工作,但不多。下面的程序将生成所需的列表。
public class EmpSort {
static final Comparator<Employee> SENIORITY_ORDER =
new Comparator<Employee>() {
public int compare(Employee e1, Employee e2) {
return e2.hireDate().compareTo(e1.hireDate());
}
};
// Employee database
static final Collection<Employee> employees = ... ;
public static void main(String[] args) {
List<Employee> e = new ArrayList<Employee>(employees);
Collections.sort(e, SENIORITY_ORDER);
System.out.println(e);
}
}
程序中的比较器相当简单。它依赖于对hireDate访问器方法返回的值应用Date的自然顺序。注意,Comparator将第二个参数的租用日期传递给第一个参数,而不是反之。原因是最近被雇佣的员工是级别最低的;按照聘用日期排序,员工名单就会按照与工作资历相反的顺序排列。人们有时为了达到这种效果而使用的另一种技术是保持参数的顺序,但否定比较的结果。
// Don't do this!!
return -r1.hireDate().compareTo(r2.hireDate());
您应该始终使用前一种技术,而不是后者,因为后者不能保证有效。这样做的原因是,如果compareTo方法的参数小于它所调用的对象,它可以返回任何负整数。有一个负的int在被否定时仍然是负的,尽管看起来很奇怪。
-Integer.MIN_VALUE == Integer.MIN_VALUE
上面程序中的Comparator对List进行排序工作很好,但它有一个缺陷:它不能用于对已排序的集合(如TreeSet)进行排序,因为它生成的排序与等号不兼容。这意味着这个Comparator等价于equals方法没有等价的对象。特别是,任何两个在同一天被雇佣的员工将被比较为平等的。当你对List进行排序时,这并不重要;但当你用Comparator来排序一个已排序的集合时,它是致命的。如果您使用这个Comparator将多个在同一日期雇佣的员工插入到一个TreeSet中,只有第一个员工会被添加到集合中;第二个元素将被视为重复元素并被忽略。
要解决这个问题,只需调整Comparator,使其生成一个与equals兼容的排序。换句话说,调整它,使使用compare时被视为相等的元素只有那些在使用equals进行比较时也被视为相等的元素。方法是执行两部分比较(对于Name),第一部分是我们感兴趣的部分——在本例中是雇佣日期——第二部分是唯一标识对象的属性。在这里,员工编号是明显的属性。这是比较器的结果。
static final Comparator<Employee> SENIORITY_ORDER =
new Comparator<Employee>() {
public int compare(Employee e1, Employee e2) {
int dateCmp = e2.hireDate().compareTo(e1.hireDate());
if (dateCmp != 0)
return dateCmp;
return (e1.number() < e2.number() ? -1 :
(e1.number() == e2.number() ? 0 : 1));
}
};
最后一点:你可能会想用更简单的语句来替换Comparator中最后的return语句:
return e1.number() - e2.number();
除非你绝对确定没有人会有负数的员工人数,否则不要这么做!这个技巧在一般情况下不起作用,因为有符号整数类型不够大,不足以表示两个任意有符号整数之差。如果i是一个大的正整数,j是一个大的负整数,i - j将溢出并返回一个负整数。所得到的比较器违反了我们一直在讨论的四个技术限制之一(传递性),并产生了可怕的、微妙的bug。这不是一个纯粹的理论问题;人们会因此受到伤害。
SortedSet接口
SortedSet是一个以升序维护其元素的Set,根据元素的自然顺序或根据SortedSet创建时提供的Comparator进行排序。除了正常的Set操作外,SortedSet接口还提供了以下操作:
- Range view:允许对排序集进行任意范围操作。
- **Endpoints **:返回Set排序集合中的第一个或最后一个元素。
- Comparator access:如果有的话,返回用来对Set集合排序的Comparator。
SortedSet接口的代码如下。
public interface SortedSet<E> extends Set<E> {
// Range-view
SortedSet<E> subSet(E fromElement, E toElement);
SortedSet<E> headSet(E toElement);
SortedSet<E> tailSet(E fromElement);
// Endpoints
E first();
E last();
// Comparator access
Comparator<? super E> comparator();
}
Set操作
SortedSet从Set继承的操作在排序集和普通集上的行为相同,但有两个例外:
- 迭代器操作返回的迭代器将按顺序遍历已排序的集合。
- 由toArray返回的数组按顺序包含了已排序集合的元素。
尽管接口不能保证这一点,但Java平台的SortedSet实现的toString方法返回一个字符串,该字符串包含排序集的所有元素,按顺序排列。
标准构造函数
按照约定,所有通用的Collection实现都提供了接受Collection的标准转换构造函数;SortedSet实现也不例外。在TreeSet中,这个构造函数创建一个实例,根据元素的自然顺序对其进行排序。这可能是个错误。最好是动态地检查指定的集合是否是SortedSet实例,如果是,则根据相同的标准(比较器或自然排序)对新的TreeSet进行排序。因为TreeSet采用了它所采用的方法,所以它还提供了一个构造函数,该构造函数接受SortedSet并返回一个新的TreeSet,其中包含根据相同标准排序的相同元素。请注意,是参数的编译时类型,而不是运行时类型决定调用这两个构造函数中的哪一个(以及是否保留排序条件)。
按照惯例,SortedSet实现还提供了一个构造函数,该构造函数接受一个Comparator,并返回一个根据指定的Comparator排序的空集。如果将null传递给这个构造函数,它将返回一个集合,根据元素的自然顺序对其进行排序。
Range-view操作
范围视图操作与List接口提供的操作有些类似,但有一个很大的区别。即使后台排序集被直接修改,排序集的范围视图仍然有效。这是可行的,因为排序集合的范围视图的端点是元素空间中的绝对点,而不是支持集合中的特定元素,就像列表的情况一样。一个已排序集合的范围视图实际上只是一个窗口,它指向集合中元素空间中指定部分的任意部分。对range-view的更改会写回已排序的集合,反之亦然。因此,可以在已排序的集合上长时间使用范围视图,而不像在列表上使用范围视图。
排序集提供了三种范围视图操作。第一个子集有两个端点,就像sublist一样。端点不是索引,而是对象,必须与已排序的集合中的元素具有可比性,可以使用集合的比较器,也可以使用集合中元素的自然顺序,无论集合使用哪个来对自身排序。和subList一样,这个区间是半开放的,包括它的低端点,但不包括高端点。
因此,下面的代码行告诉你在“doorbell”和“pickle”之间,包括“doorbell”但不包括“pickle”,有多少个单词包含在一个名为dictionary的字符串SortedSet中:
int count = dictionary.subSet("doorbell", "pickle").size();
以类似的方式,下面的一行代码删除所有以字母f开头的元素。
dictionary.subSet("f", "g").clear();
一个类似的技巧可以用来打印一个表格,告诉你每个字母开头的单词有多少个。
for (char ch = 'a'; ch <= 'z'; ) {
String from = String.valueOf(ch++);
String to = String.valueOf(ch);
System.out.println(from + ": " + dictionary.subSet(from, to).size());
}
假设您想要查看一个包含两个端点的闭区间,而不是一个开区间。如果元素类型允许计算元素空间中给定值的后续值,则只需请求从lowEndpoint到successor(highEndpoint)的子集。虽然这并不完全明显,但字符串s的自然顺序是s +“\0”——也就是说,s后面附加一个空字符。
因此,下面的一行代码告诉您在“doorbell”和“pickle”(包括doorbell和pickle)之间有多少个单词包含在字典中。
count = dictionary.subSet("doorbell", "pickle\0").size();
可以使用类似的技术来查看一个不包含端点的开放区间。从lowEndpoint到highEndpoint的open-interval视图是后续(lowEndpoint)到highEndpoint的半开区间。用下面的公式计算“门铃”和“泡菜”之间的字数,不包括这两个词。
count = dictionary.subSet("doorbell\0", "pickle").size();
SortedSet接口包含另外两个范围视图操作——耳机和tailSet,这两个操作都接受一个Object参数。前者返回支持SortedSet的初始部分的视图,直到但不包括指定的对象。后者返回支持SortedSet的最后一部分的视图,从指定的对象开始,一直到支持SortedSet的结束。因此,下面的代码允许您将字典看作两个不相交的卷(a-m和n-z)。
SortedSet<String> volume1 = dictionary.headSet("n");
SortedSet<String> volume2 = dictionary.tailSet("n");
终端操作
SortedSet接口包含返回排序集中的第一个和最后一个元素的操作,这毫不奇怪地被称为first和last。除了它们明显的用途之外,last还可以解决SortedSet接口中的一个缺陷。你想要对SortedSet做的一件事是进入Set的内部并向前或向后迭代。从内部出发很容易:只需要得到一个尾集并对其进行迭代。不幸的是,回头是不容易的。
下面的习惯用法获取元素空间中小于指定对象o的第一个元素。
Object predecessor = ss.headSet(o).last();
这是一种很好的方法从一个有序集合的内部的一点向后退一个元素。它可以重复地应用于向后迭代,但这是非常低效的,需要对返回的每个元素进行查找。
比较器存取操作
SortedSet接口包含一个称为comparator的访问器方法,该方法返回用于对集合排序的comparator,如果集合是根据其元素的自然顺序排序的,则返回null。提供这个方法是为了使已排序的集合能够以相同的顺序复制到新的已排序的集合中。它由前面描述的SortedSet构造函数使用。
SortedMap接口
SortedMap是按升序、按键的自然顺序或按创建SortedMap时提供的Comparator来维护其条目的Map。自然排序和比较器将在对象排序一节中讨论。SortedMap接口为普通的Map操作提供了如下操作:
- Range view:对已排序的映射执行任意范围操作。
- 端点(Endpoints):返回排序映射中的第一个或最后一个键。
- **比较器的访问 **:如果有的话,返回用来对map排序的Comparator
下面的接口是SortedSet的Map模拟。
public interface SortedMap<K, V> extends Map<K, V>{
Comparator<? super K> comparator();
SortedMap<K, V> subMap(K fromKey, K toKey);
SortedMap<K, V> headMap(K toKey);
SortedMap<K, V> tailMap(K fromKey);
K firstKey();
K lastKey();
}
Map操作
SortedMap继承自Map的操作在排序映射和法线映射上的行为相同,但有两个例外:
- 在任何已排序的映射的Collection视图上,迭代器操作返回的迭代器将按顺序遍历集合。
- 集合视图的toArray操作返回的数组按顺序包含键、值或条目。
尽管接口不能保证,但在所有Java平台的SortedMap实现中,Collection视图的toString方法都返回一个字符串,该字符串按顺序包含视图的所有元素。
标准构造函数
按照约定,所有通用Map实现都提供了接受Map的标准转换构造函数;SortedMap实现也不例外。在TreeMap中,这个构造函数创建一个实例,该实例根据键的自然顺序对条目进行排序。这可能是个错误。最好是动态检查指定的Map实例是否为SortedMap,如果是,则根据相同的标准(比较器或自然排序)对新映射进行排序。因为TreeMap采用了它所采用的方法,所以它还提供了一个构造函数,该构造函数接受SortedMap并返回一个新的TreeMap,该构造函数包含与给定的SortedMap相同的映射,并根据相同的条件进行排序。请注意,是参数的编译时类型而不是运行时类型决定了SortedMap构造函数是否优先于普通映射构造函数被调用。
按照惯例,SortedMap实现还提供了一个构造函数,该构造函数接受一个Comparator并返回一个根据指定的Comparator排序的空映射。如果null被传递给这个构造函数,它将返回一个Map,根据它们的键的自然顺序对其映射进行排序。
SortedSet的比较
因为这个接口是SortedSet的精确Map模拟,所以SortedSet接口一节中的所有习惯用法和代码示例都适用于SortedMap,只需要做一些简单的修改。
接口的总结
核心集合接口是Java集合框架的基础。
Java集合框架的层次结构由两个不同的接口树组成:
- 第一个树从Collection接口开始,该接口提供了所有集合使用的基本功能,比如添加和删除方法。它的子接口——Set、List和Queue——提供了更专门化的集合。
- Set接口不允许元素重复。这对于存储一副牌或学生记录等集合非常有用。Set接口有一个子接口SortedSet,它提供了集合中元素的顺序。
- List接口为需要精确控制每个元素插入位置的情况提供了一个有序的集合。您可以根据元素的确切位置从List中检索元素。
- Queue接口支持额外的插入、提取和检查操作。Queue中的元素通常是在FIFO基础上排序的。
- Deque接口可以在两端进行插入、删除和巡检操作。Deque中的元素可以在LIFO和FIFO中使用。
- 第二棵树从Map接口开始,该接口映射类似于Hashtable的键和值。Map的子接口SortedMap按照升序或Comparator指定的顺序维护它的键值对。
这些接口允许对集合进行独立于其表示细节的操作。
问题和练习:接口
问题
- 在本课开始时,您了解到核心集合接口被组织成两个不同的继承树。特别地,有一个接口不被认为是真正的集合,因此位于它自己树的顶部。这个接口的名称是什么?
- 集合框架中的每个接口都用语法声明,这告诉您它是泛型的。声明Collection实例时,指定它将包含的对象类型有什么好处?
- 哪个接口表示不允许重复元素的集合?
- 什么接口构成集合层次结构的根?
- 哪个接口表示可能包含重复元素的有序集合?
- 哪个接口表示在处理之前保存元素的集合?
- 哪个接口表示将键映射到值的类型?
- 什么接口表示双端队列?
- 列出三种迭代List元素的方法。
- True或False:聚合操作是修改底层集合的可变操作。
练习
- 编写一个程序,按随机顺序输出参数。不要复制参数数组。演示如何使用流和传统的增强for语句打印元素。
- 以FindDups示例为例,修改它以使用SortedSet而不是Set。指定一个Comparator,以便在排序和标识集合元素时忽略大小写。
- 编写一个方法,接受List并应用 String.trim对每个元素。
- 考虑四个核心接口:Set、List、Queue和Map。对于以下四个任务,指定四个核心接口中的哪一个最适合,并解释如何使用它来实现任务。
- 异想天开玩具公司(whimical Toys Inc)需要记录所有员工的姓名。每个月,从这些记录中随机选出一名员工,获得一件免费玩具。
- WTI已经决定,每个新产品都将以员工的名字命名,但只使用名字,而且每个名字只使用一次。准备一个独特的名字列表。
- WTI决定只使用最流行的玩具名称。把每个人都有名字的员工数量加起来。
- WTI为当地长曲棍球队购买季票,由员工共享。为这项受欢迎的运动创建一个等候名单。
答案
聚合操作
代表您对集合进行迭代,这使您能够编写更简洁、更有效的代码来处理存储在集合中的元素。
注意:为了更好地理解本节中的概念,请回顾Lambda表达式和方法引用小节。
使用集合是为了什么?您不能简单地将对象存储在集合中,然后将它们留在那里。在大多数情况下,您使用集合来检索存储在其中的项。
再考虑一下Lambda表达式一节中描述的场景。假设您正在创建一个社交网络应用程序。您希望创建一个特性,使管理员能够对满足特定条件的社交网络应用程序的成员执行任何类型的操作,比如发送消息。
和前面一样,假设这个社交网络应用程序的成员由以下Person类表示:
public class Person {
public enum Sex {
MALE, FEMALE
}
String name;
LocalDate birthday;
Sex gender;
String emailAddress;
// ...
public int getAge() {
// ...
}
public String getName() {
// ...
}
}
下面的例子使用for-each循环打印集合花名册中包含的所有成员的名称:
for (Person p : roster) {
System.out.println(p.getName());
}
下面的例子打印集合花名册中包含的所有成员,但是使用聚合操作forEach:
roster
.stream()
.forEach(e -> System.out.println(e.getName());
尽管在本例中,使用聚合操作的版本比使用for-each循环的版本更长,但您将看到使用大容量数据操作的版本对于更复杂的任务将更简洁。
本课程涵盖以下主题:
- 管道和流
- 聚合操作和迭代器的区别
在示例bulkdataoperationexamples中查找本节中描述的代码摘录。
管道和流
管道是一个聚合操作序列。下面的例子使用一个由聚合操作过滤器filter和forEach组成的管道来打印集合列表中包含的男性成员:
roster
.stream()
.filter(e -> e.getGender() == Person.Sex.MALE)
.forEach(e -> System.out.println(e.getName()));
下面的例子使用for-each循环打印集合花名册中的男性成员:
for (Person p : roster) {
if (p.getGender() == Person.Sex.MALE) {
System.out.println(p.getName());
}
}
管道包含以下组件:
-
源:这可以是一个集合、一个数组、一个生成器函数或一个I/O通道。在本例中,源是集合花名册。
-
零或多个中间操作。一个中间操作,如过滤器,产生一个新的流。
流是元素的序列。与集合不同,它不是存储元素的数据结构。相反,流通过管道来携带来自源的值。本例通过调用方法流从集合花名册创建一个流。
筛选操作返回一个新流,其中包含匹配其谓词(此操作的参数)的元素。在这个例子中,谓词是lambda表达式
e -> e.g tgender () == Person.Sex.MALE。如果对象e的gender字段的值为Person.Sex.MALE,则返回布尔值true。因此,本例中的过滤器操作返回一个流,该流包含集合花名册中的所有男性成员。 -
一个终端操作。一个终端操作,比如forEach,会产生一个非流结果,比如一个原始值(比如双精度值),一个集合,或者在forEach的情况下,一个值都没有。在本例中,forEach操作的参数是lambda表达式
e -> System.out.println(e.g tname()),它在对象e上调用方法getName(Java运行时和编译器推断对象e的类型是Person)。
下面的例子计算了集合花名册中包含的所有男性成员的平均年龄,其中包含了一个由聚合操作过滤器filter、mapToInt和average组成的管道:
double average = roster
.stream()
.filter(p -> p.getGender() == Person.Sex.MALE)
.mapToInt(Person::getAge)
.average()
.getAsDouble();
mapToInt操作返回一个IntStream类型的新流(即只包含整数值的流)。该操作将在其参数中指定的函数应用到特定流中的每个元素。在这个例子中,函数是Person::getAge,这是一个返回成员年龄的方法引用。(或者,您可以使用lambda表达式e -> e. getage()。)因此,本例中的mapToInt操作返回一个流,其中包含集合花名册中所有男性成员的年龄。
平均操作计算IntStream类型流中包含元素的平均值。它返回一个OptionalDouble类型的对象。如果流不包含元素,那么平均操作将返回一个OptionalDouble的空实例,并且调用方法getAsDouble将抛出NoSuchElementException。JDK包含许多终端操作,例如通过组合流的内容返回一个值的平均值。这些运算称为约简运算;有关更多信息,请参阅Reduction部分。
聚合操作和迭代器的区别
聚合操作,如forEach,看起来像迭代器。然而,它们有几个根本的区别:
- **他们使用内部迭代:**聚合操作不包含类似next的方法来指示它们处理集合的下一个元素。使用内部委托,应用程序决定迭代什么集合,而JDK决定如何迭代集合。使用外部迭代,应用程序可以确定它迭代什么集合以及如何迭代。但是,外部迭代只能顺序地遍历集合的元素。内部迭代没有这个限制。它可以更容易地利用并行计算,即将一个问题划分为子问题,同时解决这些问题,然后将子问题的解的结果结合起来。有关更多信息,请参见并行性一节。
- **它们处理流中的元素:**聚合来自流而不是直接来自集合的操作流程元素。因此,它们也被称为流操作。
- **它们支持行为作为参数:**您可以为大多数聚合操作指定lambda表达式作为参数。这使您能够定制特定聚合操作的行为。
归约
聚合操作一节描述了下面的计算收集花名册中所有男性成员的平均年龄的操作管道:
double average = roster
.stream()
.filter(p -> p.getGender() == Person.Sex.MALE)
.mapToInt(Person::getAge)
.average()
.getAsDouble();
JDK包含许多终端操作(例如平均值、总和、最小值、最大值和计数),这些操作通过组合流的内容返回一个值。这些运算称为归约操作。JDK还包含返回集合而不是单个值的还原操作。许多约简操作执行特定的任务,例如查找值的平均值或将元素分组到类别中。但是JDK提供了通用的reduce和collect操作,本节将详细介绍。
本节涉及以下主题:
- Stream.reduce方法
- Stream.collect方法
您可以在ReductionExamples示例中找到本节中描述的代码摘录。
Stream.reduce方法
Stream.reduce方法是一种通用的归约操作。考虑下面的管道,它计算收集花名册中男性成员的年龄总和。它使用Stream.sum归约操作:
Integer totalAge = roster
.stream()
.mapToInt(Person::getAge)
.sum();
将其与下面使用管道进行比较。使用Stream.reduce操作计算相同的值:
Integer totalAgeReduce = roster
.stream()
.map(Person::getAge)
.reduce(
0,
(a, b) -> a + b);
这个例子中的reduce操作有两个参数:
-
**identity:**如果流中没有元素,identity元素既是reduce的初始值,也是默认结果。在这个例子中,单位元素是0;这是年龄总和的初始值,如果收集名册中没有成员,则为缺省值。
-
accumulator: accumulator函数有两个参数:还原的部分结果(在本例中,是到目前为止所有处理过的整数的和)和流的下一个元素(在本例中是一个整数)。它返回一个新的部分结果。在这个例子中,accumulator函数是一个lambda表达式,它将两个Integer值相加并返回一个Integer值:
(a, b) -> a + b
reduce操作总是返回一个新值。然而,每当累加器函数处理流的一个元素时,它也会返回一个新值。假设您希望将流中的元素减少为更复杂的对象,例如集合。这可能会影响应用程序的性能。如果reduce操作涉及到向集合添加元素,那么每当累加器函数处理一个元素时,它都会创建一个包含该元素的新集合,这是低效的。对您来说,更新现有的集合会更有效。你可以用Stream.collect这个方法做这个,下一节将介绍该方法。
Stream.collect方法
reduce方法在处理元素时总是创建一个新值,与此不同,collect方法修改或改变现有的值。考虑如何在流中求值的平均值。你需要两个数据:值的总数和这些值的总和。但是,与reduce方法和所有其他reduce方法一样,collect方法只返回一个值。你可以创建一个新的数据类型,其中包含的成员变量跟踪值的总数和这些值的总和,例如下面的类,Averager:
class Averager implements IntConsumer
{
private int total = 0;
private int count = 0;
public double average() {
return count > 0 ? ((double) total)/count : 0;
}
public void accept(int i) { total += i; count++; }
public void combine(Averager other) {
total += other.total;
count += other.count;
}
}
下面的管道使用Averager类和collect方法来计算所有男性成员的平均年龄:
Averager averageCollect = roster.stream()
.filter(p -> p.getGender() == Person.Sex.MALE)
.map(Person::getAge)
.collect(Averager::new, Averager::accept, Averager::combine);
System.out.println("Average age of male members: " +
averageCollect.average());
这个例子中的collect操作有三个参数:
- **supplier:**供应商是工厂的职能;它构造新的实例。对于收集操作,它创建结果容器的实例。在这个例子中,它是Averager类的一个新实例。
- **accumulator:**累加器函数将流元素合并到结果容器中。在本例中,它修改Averager结果容器的方法是,将count变量加1,并在total成员变量中添加stream元素的值,该值是表示男性成员年龄的整数。
- **combiner:**组合器函数接受两个结果容器并合并它们的内容。在本例中,它通过将count变量与另一个Averager实例的count成员变量递增,并将另一个Averager实例的total成员变量的值添加到total成员变量中来修改Averager结果容器。
注意以下几点:
- 供应商是一个lambda表达式(或一个方法引用),而不是像reduce操作中的identity元素那样的值。
- 累加器和组合器函数不返回值。
- 您可以对并行流使用收集操作;有关更多信息,请参阅Parallelism一节。(如果在并行流中运行collect方法,那么当组合函数创建一个新对象时,JDK会创建一个新线程,例如本例中的Averager对象。因此,您不必担心同步问题。)
虽然JDK提供了平均操作来计算流中元素的平均值,但如果需要从流的元素中计算多个值,则可以使用collect操作和自定义类。聚集操作最适合于集合。下面的例子使用collect操作将男性成员的名字放入集合中:
List<String> namesOfMaleMembersCollect = roster
.stream()
.filter(p -> p.getGender() == Person.Sex.MALE)
.map(p -> p.getName())
.collect(Collectors.toList());
这个版本的收集操作接受一个类型为Collector的参数。该类封装了需要三个参数(供应者、累加器和组合器函数)的收集操作中用作参数的函数。
collector类包含许多有用的约简操作,例如将元素累积到集合中,以及根据各种标准汇总元素。这些减少操作返回类Collector的实例,因此您可以将它们用作收集操作的参数。
本例使用Collectors.toList操作,将流元素累加到List的新实例中。与Collector类中的大多数操作一样,toList操作符返回Collector的一个实例,而不是一个集合。
下列例子按性别将收集名册成员分组:
Map<Person.Sex, List<Person>> byGender =
roster
.stream()
.collect(
Collectors.groupingBy(Person::getGender));
groupingBy操作返回一个映射,它的键是应用指定为其参数的lambda表达式(称为分类函数)所产生的值。在本例中,返回的映射包含两个键,Person.Sex.MALE和Person.Sex.FEMALE。键的对应值是List的实例,其中包含流元素,当分类函数处理这些元素时,它们对应于键值。例如,key Person.Sex.MALE对应的值是List的一个实例,它包含了所有的男性成员。
下面的例子检索收集花名册中每个成员的名字,并按性别对他们进行分组:
Map<Person.Sex, List<String>> namesByGender =
roster
.stream()
.collect(
Collectors.groupingBy(
Person::getGender,
Collectors.mapping(
Person::getName,
Collectors.toList())));
本例中的groupingBy操作有两个参数,一个分类函数和一个Collector实例。Collector参数称为下游收集器。这是一个收集器,Java运行时将其应用于另一个收集器的结果。因此,此groupingBy操作使您能够对由groupingBy操作符创建的List值应用收集方法。这个示例应用收集器映射,它将映射函数Person::getName应用到流的每个元素。因此,产生的流只包含成员的名称。包含一个或多个下游收集器的管道(如本例)称为多级缩减。
下面的例子检索了每个性别成员的总年龄:
Map<Person.Sex, Integer> totalAgeByGender =
roster
.stream()
.collect(
Collectors.groupingBy(
Person::getGender,
Collectors.reducing(
0,
Person::getAge,
Integer::sum)));
还原操作需要三个参数:
- **identity:**如流。在Reduce操作中,如果流中没有元素,identity元素既是Reduce的初始值,也是默认结果。在这个例子中,单位元素是0;这是年龄总和的初始值,如果没有成员存在,则为缺省值。
- mapper: reduce操作将此映射函数应用于所有流元素。在这个例子中,映射器检索每个成员的年龄。
- operation: operation函数用于减少映射值。在本例中,operation函数添加整型值。
下面的例子检索了每个性别成员的平均年龄:
Map<Person.Sex, Double> averageAgeByGender = roster
.stream()
.collect(
Collectors.groupingBy(
Person::getGender,
Collectors.averagingInt(Person::getAge)));
并行化(Parallelism)
并行计算包括将一个问题划分为子问题,同时解决这些问题(并行地,每个子问题在一个独立的线程中运行),然后结合子问题的解决结果。Java SE提供了fork/join框架,它使您能够更容易地在应用程序中实现并行计算。但是,使用这个框架,您必须指定如何对问题进行细分(分区)。通过聚合操作,Java运行时将为您执行这种分区和组合解决方案。
在使用集合的应用程序中实现并行性的一个困难是,集合不是线程安全的,这意味着多个线程不能在不引入线程干扰或内存一致性错误的情况下操作集合。集合框架提供了同步包装器,它为任意集合添加了自动同步,使其成为线程安全的。然而,同步引入了线程争用。您希望避免线程争用,因为这会阻止线程并行运行。聚合操作和并行流使您能够实现非线程安全集合的并行性,前提是您在操作集合时不修改集合。
请注意,并行性并不会自动地比串行执行操作快,但如果您有足够的数据和处理器核心,可能会更快。虽然聚合操作使您能够更容易地实现并行性,但确定应用程序是否适合并行性仍然是您的责任。
本节涉及以下主题:
- 并行执行流
- 归约并发
- 排序
- 副作用
1)惰性
2)干扰
3)有状态的Lambda表达式
您可以在示例parallelelismexamples中找到本节中描述的代码摘录。
并行执行流
您可以串行或并行地执行流。当一个流并行执行时,Java运行时将该流划分为多个子流。聚合操作迭代并并行处理这些子流,然后组合结果。
创建流时,除非另有说明,否则它始终是串行流。要创建一个并行流,请调用Collection.parallelStream操作。或者,调用BaseStream .parallel操作。例如,下面的语句并行计算所有男性成员的平均年龄:
double average = roster
.parallelStream()
.filter(p -> p.getGender() == Person.Sex.MALE)
.mapToInt(Person::getAge)
.average()
.getAsDouble();
归约并发
再考虑以下按性别对成员进行分组的示例(在Reduction一节中描述)。下面的例子调用了collect操作,它将收集花名册缩减为一个Map:
Map<Person.Sex, List<Person>> byGender =
roster
.stream()
.collect(
Collectors.groupingBy(Person::getGender));
以下是并行的对等物:
ConcurrentMap<Person.Sex, List<Person>> byGender =
roster
.parallelStream()
.collect(
Collectors.groupingByConcurrent(Person::getGender));
这被称为并行约简。对于包含collect操作的特定管道,如果以下所有条件都成立,Java运行时将执行并发缩减:
- 这个流是平行的。
- 收集操作的参数,即collector,具有Collector.Characteristics.CONCURRENT的特征。要确定收集器的特征,请调用Collector.characteristics的方法。
- 要么流是无序的,要么收集器具有Collector.Characteristics.UNORDERED特征。要确保流是无序的,请调用BaseStream.unordered操作。
注意:这个示例返回ConcurrentMap而不是Map的实例,并调用groupingByConcurrent操作而不是groupingBy。(有关ConcurrentMap的更多信息,请参阅并发集合一节。)与操作groupingByConcurrent不同,操作groupingBy对于并行流的性能很差。(这是因为它的操作是通过键合并两个映射,这是计算上的昂贵。)类似地,操作collector。与collector . tomap操作相比,toConcurrentMap在处理并行流时性能更好。
排序
管道处理流元素的顺序取决于流是串行执行还是并行执行、流的源和中间操作。例如,考虑下面的例子,它使用forEach操作多次打印ArrayList实例的元素:
Integer[] intArray = {1, 2, 3, 4, 5, 6, 7, 8 };
List<Integer> listOfIntegers =
new ArrayList<>(Arrays.asList(intArray));
System.out.println("listOfIntegers:");
listOfIntegers
.stream()
.forEach(e -> System.out.print(e + " "));
System.out.println("");
System.out.println("listOfIntegers sorted in reverse order:");
Comparator<Integer> normal = Integer::compare;
Comparator<Integer> reversed = normal.reversed();
Collections.sort(listOfIntegers, reversed);
listOfIntegers
.stream()
.forEach(e -> System.out.print(e + " "));
System.out.println("");
System.out.println("Parallel stream");
listOfIntegers
.parallelStream()
.forEach(e -> System.out.print(e + " "));
System.out.println("");
System.out.println("Another parallel stream:");
listOfIntegers
.parallelStream()
.forEach(e -> System.out.print(e + " "));
System.out.println("");
System.out.println("With forEachOrdered:");
listOfIntegers
.parallelStream()
.forEachOrdered(e -> System.out.print(e + " "));
System.out.println("");
这个示例由5个管道组成。它输出类似如下:
listOfIntegers:
1 2 3 4 5 6 7 8
listOfIntegers sorted in reverse order:
8 7 6 5 4 3 2 1
Parallel stream:
3 4 1 6 2 5 7 8
Another parallel stream:
6 3 1 5 7 8 4 2
With forEachOrdered:
8 7 6 5 4 3 2 1
这个例子是这样的:
- 第一个流水线打印列表listOfIntegers中的元素,顺序是它们被添加到列表中的顺序。
- 第二个管道打印listOfIntegers的元素,在它被Collections.sort方法排序之后。
- 第三和第四个管道以明显随机的顺序打印列表的元素。记住,流操作在处理流元素时使用内部迭代。因此,当并行执行流时,Java编译器和运行时决定处理流元素的顺序,以最大限度地利用并行计算的好处,除非流操作另有规定。
- 第五个管道使用forEachOrdered方法,该方法按照其源指定的顺序处理流的元素,无论您是串行还是并行执行流。请注意,如果你在并行流中使用类似forEachOrdered的操作,你可能会失去并行性的好处。
副作用
如果一个方法或表达式除了返回或产生一个值之外,还修改了计算机的状态,那么它就会产生副作用。例子包括可变缩约(使用collect操作的操作;有关更多信息,请参阅Reduction一节)以及调用System.out.println方法进行调试。JDK可以很好地处理管道中的某些副作用。特别是,collect方法旨在以并行安全的方式执行最常见的具有副作用的流操作。像forEach和peek这样的操作是为副作用而设计的;返回void的lambda表达式,例如调用System.out.println除了副作用什么都做不了。即便如此,您也应该小心地使用forEach和peek操作;如果在并行流中使用这些操作之一,那么Java运行时可能会从多个线程并发地调用指定为其参数的lambda表达式。此外,永远不要将在filter和map等操作中有副作用的lambda表达式作为参数传递。以下部分将讨论干扰和有状态lambda表达式,这两者都可能是副作用的来源,并可能返回不一致或不可预测的结果,特别是在并行流中。然而,首先讨论的是懒惰的概念,因为它对干扰有直接的影响。
1)惰性
所有中间操作都是惰性操作。如果表达式、方法或算法的值仅在需要时才求值,则该表达式、方法或算法是惰性的。(如果一个算法被立即求值或处理,那么它就是紧急的。)中间操作是惰性的,因为它们直到终端操作开始时才开始处理流的内容。延迟处理流使Java编译器和运行时能够优化它们处理流的方式。例如,在诸如聚合操作一节中描述的filter-mapToInt-average示例这样的管道中,平均操作可以从mapToInt操作创建的流中获取前几个整数,mapToInt操作从筛选操作中获取元素。平均操作将重复这个过程,直到从流中获得所有需要的元素,然后计算平均。
2)干扰
流操作中的Lambda表达式不应该干扰。当管道处理流时,流的源被修改时,就会发生干扰。下面的代码尝试连接List.listOfStrings中包含的字符串。然而,它抛出一个ConcurrentModificationException:
try {
List<String> listOfStrings =
new ArrayList<>(Arrays.asList("one", "two"));
// This will fail as the peek operation will attempt to add the
// string "three" to the source after the terminal operation has
// commenced.
String concatenatedString = listOfStrings
.stream()
// Don't do this! Interference occurs here.
.peek(s -> listOfStrings.add("three"))
.reduce((a, b) -> a + " " + b)
.get();
System.out.println("Concatenated string: " + concatenatedString);
} catch (Exception e) {
System.out.println("Exception caught: " + e.toString());
}
本例使用reduce操作将listOfStrings中包含的字符串连接到一个Optional值,这是一个终端操作。但是,这里的管道调用中间操作peek,该操作试图向listOfStrings添加一个新元素。记住,所有中间操作都是惰性的。这意味着本例中的管道在调用get操作时开始执行,并在get操作完成时结束执行。peek操作的参数试图在管道执行期间修改流源,这将导致Java运行时抛出ConcurrentModificationException。
3)有状态的Lambda表达式
避免在流操作中使用有状态lambda表达式作为参数。有状态lambda表达式的结果取决于在管道执行期间可能改变的任何状态。下面的示例使用映射中间操作将List listOfIntegers中的元素添加到一个新的List实例。它这样做了两次,第一次是串行流,然后是并行流:
List<Integer> serialStorage = new ArrayList<>();
System.out.println("Serial stream:");
listOfIntegers
.stream()
// Don't do this! It uses a stateful lambda expression.
.map(e -> { serialStorage.add(e); return e; })
.forEachOrdered(e -> System.out.print(e + " "));
System.out.println("");
serialStorage
.stream()
.forEachOrdered(e -> System.out.print(e + " "));
System.out.println("");
System.out.println("Parallel stream:");
List<Integer> parallelStorage = Collections.synchronizedList(
new ArrayList<>());
listOfIntegers
.parallelStream()
// Don't do this! It uses a stateful lambda expression.
.map(e -> { parallelStorage.add(e); return e; })
.forEachOrdered(e -> System.out.print(e + " "));
System.out.println("");
parallelStorage
.stream()
.forEachOrdered(e -> System.out.print(e + " "));
System.out.println("");
lambda表达式e -> {parallelStorage.add(e);返回e;}是一个有状态的lambda表达式。每次运行代码时,其结果可能会有所不同。该示例输出如下:
Serial stream:
8 7 6 5 4 3 2 1
8 7 6 5 4 3 2 1
Parallel stream:
8 7 6 5 4 3 2 1
1 3 6 2 4 5 8 7
forEachOrdered操作按照流指定的顺序处理元素,而不管流是串行还是并行执行的。但是,当流并行执行时,map操作处理由Java运行时和编译器指定的流元素。因此,lambda表达式e ->{parallelStorage.add(e);return e;}向List中添加元素的排序,parallelStorage可以在每次运行代码时发生变化。对于确定性和可预测的结果,请确保流操作中的lambda表达式参数不是有状态的。
注意:这个例子调用了synchronizedList方法,以便List parallelStorage是线程安全的。记住,集合不是线程安全的。这意味着多个线程不应该同时访问特定的集合。假设你在创建parallelStorage时没有调用synchronizedList方法:
List<Integer> parallelStorage = new ArrayList<>();
这个例子的行为是不稳定的,因为多个线程访问和修改parallelStorage时,没有像同步这样的机制来调度一个特定线程可能访问List实例。因此,该示例可以打印类似如下的输出:
Parallel stream:
8 7 6 5 4 3 2 1
null 3 5 4 7 8 1 2
练习
提问
- 一个集合操作序列被称为___。
- 每个管道包含0个或多个___操作。
- 每条管道以___操作结束。
- 哪种操作会产生另一个流作为它的输出?
- 描述forEach聚合操作与增强的for语句或迭代器不同的一种方式。
- True或False:流与集合类似,因为它是存储元素的数据结构。
- 在这段代码中确定中间和终端操作:
double average = roster .stream() .filter(p -> p.getGender() == Person.Sex.MALE) .mapToInt(Person::getAge) .average() .getAsDouble(); - 代码
p -> p. getgender () == Person.Sex.MALE是什么例子? - 代码
Person::getAge是一个什么例子? - 组合流的内容并返回一个值的终端操作被称为什么?
- 请说出流之间的一个重要区别。Stream.reduce方法和Stream.collect方法。
- 如果您想处理一个名称流,提取男性名称,并将它们存储在一个新的列表中,将Stream.reduce或Stream.collect是最合适的操作使用?
- True或False:聚合操作使实现非线程安全集合的并行性成为可能。
- 除非另有说明,否则流总是串行的。如何请求并行处理一个流?
练习
- 将以下增强的for语句编写为带有lambda表达式的管道。提示:使用filter中间操作和forEach终端操作。
for (Person p : roster) { if (p.getGender() == Person.Sex.MALE) { System.out.println(p.getName()); } } - 将以下代码转换为使用lambda表达式和聚合操作而不是嵌套for循环的新实现。提示:按此顺序创建一个调用筛选器、排序和收集操作的管道。
List<Album> favs = new ArrayList<>(); for (Album a : albums) { boolean hasFavorite = false; for (Track t : a.tracks) { if (t.rating >= 4) { hasFavorite = true; break; } } if (hasFavorite) favs.add(a); } Collections.sort(favs, new Comparator<Album>() { public int compare(Album a1, Album a2) { return a1.name.compareTo(a2.name); }});
答案
实现类
描述JDK的通用集合实现,并告诉你何时使用哪个实现。您还将了解包装器实现,它向通用实现添加功能。
实现是用于存储集合的数据对象,集合实现接口部分中描述的接口。本课描述了以下几种实现:
- 通用的实现:是最常用的实现,为日常使用而设计。它们总结在一个名为“通用目的实现”的表中。
- 特殊用途的实现:为特殊情况下使用而设计,并显示非标准的性能特征、使用限制或行为。
- 并行实现:旨在支持高并发性,通常以牺牲单线程性能为代价。这些实现是java.util.concurrent包的一部分。
- 包装器实现:与其他类型的实现(通常是通用实现)结合使用,以提供附加的或受限制的功能。
- 便利实现:是小型实现,通常通过静态工厂方法提供,为特殊集合(例如,单例集)提供方便、高效的通用实现替代方案。
- 抽象实现:是简化自定义实现构造的框架实现——稍后在自定义集合实现一节中进行描述。这是一个高级的话题,不是特别难,但需要做的人相对较少。
下表总结了通用实现。

从表中可以看到,Java Collections Framework提供了Set、List和Map接口的几种通用实现。每种情况下,有一种实现——HashSet、ArrayList和HashMap——显然是大多数应用程序所使用的实现,其他所有条件都是相同的。注意,SortedSet和SortedMap接口在表中没有行。每个接口都有一个实现(TreeSet和TreeMap),并在Set和Map行中列出。有两种通用的Queue实现——LinkedList和PriorityQueue,前者也是List的实现,后者在表中被省略。这两个实现提供了非常不同的语义:LinkedList提供FIFO语义,而PriorityQueue则根据元素的值对元素排序。
每个通用实现都提供其接口中包含的所有可选操作。所有的元素、键和值都允许为空。没有同步的(线程安全的)。所有的迭代器都有快速失败迭代器,它可以在迭代过程中检测非法的并发修改,并快速而干净地失败,而不是在未来的未知时间冒任意的、不确定的行为的风险。它们都是可序列化的,并且都支持公共克隆方法。
这些实现是不同步的,这一事实代表了与过去的决裂:遗留集合Vector和Hashtable是同步的。之所以采用目前的方法,是因为在同步没有好处的情况下经常使用集合。这类用途包括单线程使用、只读使用,以及作为大型数据对象的一部分进行自己的同步。一般来说,良好的API设计习惯是不让用户为他们不使用的功能付费。此外,在某些情况下,不必要的同步可能导致死锁。
如果您需要线程安全的集合,那么在Wrapper实现部分中描述的同步包装器允许将任何集合转换为同步集合。因此,同步对于通用实现是可选的,而对于遗留实现是强制性的。此外,java.util.concurrent包提供了BlockingQueue接口(扩展了Queue)和ConcurrentMap接口(扩展了Map)的并发实现。这些实现提供了比单纯的同步实现更高的并发性。
通常,您应该考虑的是接口,而不是实现。这就是本节中没有编程示例的原因。在大多数情况下,实现的选择只会影响性能。如Interfaces一节所述,首选的样式是在创建Collection时选择一个实现,并立即将新集合分配给相应接口类型的变量(或将该集合传递给期望具有接口类型参数的方法)。这样,程序就不会依赖于给定实现中添加的任何方法,这样程序员就可以根据性能或行为细节随时改变实现。
下面几节将简要讨论实现。这些实现的性能用诸如常数时间、log、线性、n log(n)和二次来表示执行操作的时间复杂度的渐近上界。所有这些都很拗口,如果你不知道它的意思,这也没什么关系。如果你有兴趣了解更多,请参考任何好的算法教科书。需要记住的一件事是,这种性能指标有其局限性。有时,名义上较慢的实现可能更快。当有疑问时,测量性能!
Set的实现
Set实现分为通用实现和特殊实现。
通用的的Set实现
有三种通用的Set实现——HashSet、TreeSet和LinkedHashSet。使用这三个中的哪一个通常是很简单的。HashSet比TreeSet快得多(对于大多数操作来说是常量时间相对于日志时间),但不提供排序保证。如果您需要使用SortedSet接口中的操作,或者如果需要按值排序的迭代,则使用TreeSet;否则,使用HashSet。很有可能您最终会在大多数时间使用HashSet。
LinkedHashSet在某种意义上介于HashSet和TreeSet之间。它以一个链表的形式实现,提供了插入顺序迭代(最近插入到最近),运行速度几乎与HashSet一样快。LinkedHashSet实现使它的客户端免于HashSet提供的不确定的、通常混乱的排序,而不会导致与TreeSet相关的成本增加。
关于HashSet值得记住的一点是,迭代在条目数量和桶数量(容量)的总和上是线性的。因此,选择一个过高的初始容量会浪费空间和时间。另一方面,选择一个初始容量过低的容量会浪费时间,因为每次它被迫增加容量时都会复制数据结构。如果不指定初始容量,则默认值为16。在过去,选择一个素数作为初始容量是有一些好处的。但现在情况已经不一样了。在内部,容量总是四舍五入到2的幂。初始容量由int构造函数指定。下面这行代码分配了一个初始容量为64的HashSet。
Set<String> s = new HashSet<String>(64);
HashSet类有另一个调优参数,称为加载因子。如果您非常关心HashSet的空间消耗,请阅读HashSet文档以获得更多信息。否则,就接受默认值;这几乎总是正确的做法。
如果您接受默认的负载因子,但希望指定一个初始容量,则选择一个大约是您希望该集增长到的两倍大小的数字。如果你的猜测是错误的,你可能会浪费一些空间和时间,或者两者都浪费,但这不太可能是一个大问题。
LinkedHashSet具有与HashSet相同的调优参数,但是迭代时间不受容量的影响。TreeSet没有调优参数。
特殊的Set实现
有两种特殊目的的Set实现——EnumSet和CopyOnWriteArraySet。
EnumSet是enum类型的高性能Set实现。枚举集的所有成员必须具有相同的枚举类型。在内部,它是由位向量表示的,通常是单个长向量。Enum设置在枚举类型范围内支持迭代。例如,给定枚举声明的星期几,可以在工作日上进行迭代。EnumSet类提供了一个静态工厂,使之变得简单。
for (Day d : EnumSet.range(Day.MONDAY, Day.FRIDAY))
System.out.println(d);
枚举集还为传统的位标志提供了丰富的、类型安全的替换。
EnumSet.of(Style.BOLD, Style.ITALIC)
CopyOnWriteArraySet是一个由写时复制数组备份的Set实现。所有的可变操作,如添加、设置和删除,都是通过复制数组来实现的;不需要锁。即使是迭代也可以安全地同时进行元素的插入和删除。与大多数Set实现不同,add、remove和contains方法需要的时间与Set的大小成比例。此实现只适用于很少修改但经常迭代的集合。它非常适合维护必须防止重复的事件处理程序列表。
List实现
列表实现分为通用实现和特殊实现。
通用的List实现
有两种通用的List实现- ArrayList和LinkedList。大多数时候,您可能会使用ArrayList,它提供常量时间的位置访问,而且非常快。它不必为List中的每个元素分配一个节点对象,它可以利用System.arraycopy。当它必须同时移动多个元素时。可以把ArrayList看作Vector,而不用考虑同步开销。
如果您经常向List的开头添加元素,或者迭代List以从其内部删除元素,那么您应该考虑使用LinkedList。这些操作在LinkedList中需要常量时间,在ArrayList中需要线性时间。但是你要为性能付出很大的代价。位置访问需要在LinkedList中使用线性时间,在ArrayList中使用常量时间。此外,LinkedList的常数因素更糟糕。如果你想使用一个LinkedList,那么在做选择之前,用LinkedList和ArrayList来衡量应用程序的性能;ArrayList通常更快。
ArrayList有一个调优参数——初始容量,它指的是ArrayList在必须增长之前可以容纳的元素数量。LinkedList没有调优参数,有7个可选操作,其中一个是clone。另外六个分别是addFirst、getFirst、removeFirst、addLast、getLast和removeLast。LinkedList还实现了Queue接口。
专用List实现
CopyOnWriteArrayList是一个List实现,由写时复制数组备份。这个实现在本质上类似于CopyOnWriteArraySet。不需要同步,即使在迭代过程中,迭代器也保证不会抛出ConcurrentModificationException异常。此实现非常适合维护事件处理程序列表,在该列表中更改很少,遍历频繁且可能耗时。
如果你需要同步,一个Vector会比一个用Collections.synchronizedList同步的ArrayList稍微快一些。但是Vector有大量的遗留操作,所以一定要小心使用List接口来操作Vector,否则您将无法在以后替换实现。
如果你的List的大小是固定的——也就是说,你永远不会使用remove、add或除containsAll之外的任何批量操作——你还有第三个选择,绝对值得考虑。看到数组。更多信息请参阅便利实现部分中的asList。
Map的实现
Map实现分为通用实现、特殊实现和并发实现。
通用的Map实现
三种通用的Map实现是HashMap、TreeMap和LinkedHashMap。如果需要SortedMap操作或按键排序的集合视图迭代,请使用TreeMap;如果你想要最大的速度,而不关心迭代顺序,使用HashMap;如果您想要接近hashmap的性能和插入顺序迭代,请使用LinkedHashMap。在这方面,Map的情况类似于Set。同样,Set的实现部分中的其他内容也适用于Map实现。
LinkedHashMap提供了LinkedHashSet不可用的两个功能。在创建LinkedHashMap时,可以根据键访问而不是插入来排序。换句话说,只要查找与键相关的值,就会将该键带到映射的末尾。此外,LinkedHashMap还提供了removeEldestEntry方法,当向映射添加新映射时,可以重写该方法来强制执行一种自动删除陈旧映射的策略。这使得实现自定义缓存非常容易。
例如,这个覆盖将允许映射增长到多达100个条目,然后每次添加一个新条目时,它将删除最老的条目,保持100个条目的稳定状态。
private static final int MAX_ENTRIES = 100;
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_ENTRIES;
}
特殊的Map实现
有三种特殊用途的Map实现——EnumMap、WeakHashMap和IdentityHashMap.EnumMap在内部实现为一个数组,是用于enum键的高性能Map实现。这个实现将Map接口的丰富性和安全性与接近数组的速度结合在一起。如果您想要将一个枚举映射到一个值,您应该始终优先使用EnumMap而不是数组。
WeakHashMap是Map接口的一个实现,它只存储对其键的弱引用。仅存储弱引用允许在键值对不再在WeakHashMap外被引用时对其进行垃圾收集。这个类提供了利用弱引用功能的最简单方法。它对于实现“类似注册表”的数据结构非常有用,在这种结构中,当一个条目的键不再被任何线程访问时,它的效用就消失了。
IdentityHashMap是一个基于哈希表的基于身份的Map实现。这个类对于保持拓扑的对象图转换非常有用,比如序列化或深度复制。要执行这样的转换,您需要维护一个基于身份的“节点表”,用于跟踪已经看到的对象。基于身份的映射还用于在动态调试器和类似系统中维护对象到元信息的映射。最后,基于身份的映射在挫败“欺骗攻击”方面很有用,这种攻击是故意违反equals方法的结果,因为IdentityHashMap从不在其键上调用equals方法。这种实现的另一个好处是速度快。
并发Map实现
java.util.concurrent包包含ConcurrentMap接口,它用原子putIfAbsent、remove和replace方法扩展了Map,以及该接口的ConcurrentHashMap实现。
ConcurrentHashMap是一个由哈希表备份的高并发、高性能实现。这个实现在执行检索时不会阻塞,并允许客户端选择更新的并发级别。它是用来替代Hashtable的:除了实现ConcurrentMap之外,它还支持Hashtable特有的所有遗留方法。同样,如果您不需要遗留操作,请小心使用ConcurrentMap接口操作它。
Queue的实现
队列实现分为通用实现和并发实现。
通用的队列实现
如前一节所述,LinkedList实现了Queue接口,为添加、轮询等提供先进先出(FIFO)队列操作。PriorityQueue类是一个基于堆数据结构的优先队列。这个队列根据构造时指定的顺序对元素排序,这个顺序可以是元素的自然顺序,也可以是显式Comparator强加的顺序。
队列检索操作——poll, remove, peek, and element——访问队列头部的元素。队列的头是相对于指定的顺序来说最小的元素。如果多个元素被绑定为最小值,则head是这些元素之一;平局是随意打破的。
PriorityQueue及其迭代器实现了Collection和iterator接口的所有可选方法。方法iterator中提供的迭代器不能保证以任何特定的顺序遍历PriorityQueue中的元素。对于有序遍历,可以考虑使用Arrays.sort(pq.toArray())。
并发队列的实现
java.util.concurrent包包含一组同步的Queue接口和类。BlockingQueue扩展了Queue的操作,在获取元素时等待队列变为非空,在存储元素时等待队列中的空间变为可用。该接口由以下类实现:
- LinkedBlockingQueue:由链接节点支持的可选有界FIFO阻塞队列
- ArrayBlockingQueue:由数组支持的有边界的FIFO阻塞队列
- PriorityBlockingQueue:由堆支持的无界阻塞优先队列
- DelayQueue:由堆支持的基于时间的调度队列
- SynchronousQueue:一个使用BlockingQueue接口的简单汇合机制
在JDK 7中,TransferQueue是一个专门的BlockingQueue,在这个BlockingQueue中,向队列中添加一个元素的代码可以选择等待(阻塞)另一个线程中的代码来检索该元素。TransferQueue只有一个实现:
- LinkedTransferQueue:一个基于链接节点的无界TransferQueue
Deque的实现
Deque接口,发音为“deck”,表示一个双端队列。Deque接口可以实现为各种类型的集合。Deque接口实现分为通用实现和并发实现。
通用双端队列实现
通用实现包括LinkedList和ArrayDeque类。Deque接口支持在两端插入、移除和检索元素。ArrayDeque类是Deque接口的可调整大小的数组实现,而LinkedList类是列表实现。
Deque接口addFirst、addLast、removeFirst、removeLast、getFirst和getLast中的基本插入、删除和检索操作。addFirst方法在Deque实例的头部添加一个元素,而addLast方法在Deque实例的尾部添加一个元素。
LinkedList实现比ArrayDeque实现更灵活。LinkedList实现所有可选的列表操作。空元素可以在LinkedList实现中使用,但不能在ArrayDeque实现中使用。
在效率方面,对于两端的添加和删除操作,ArrayDeque比LinkedList更高效。LinkedList实现中的最佳操作是在迭代期间删除当前元素。LinkedList实现并不是迭代的理想结构。
LinkedList实现比ArrayDeque实现消耗更多内存。对于ArrayDeque实例遍历,请使用以下任意一种方法:
foreach
foreach快速,可用于所有类型的列表。
ArrayDeque<String> aDeque = new ArrayDeque<String>();
. . .
for (String str : aDeque) {
System.out.println(str);
}
Iterator
Iterator可以用于对所有类型的数据的所有类型的列表进行前向遍历。
ArrayDeque<String> aDeque = new ArrayDeque<String>();
. . .
for (Iterator<String> iter = aDeque.iterator(); iter.hasNext(); ) {
System.out.println(iter.next());
}
本教程中使用ArrayDeque类来实现Deque接口。本教程中使用的示例的完整代码可以在ArrayDequeSample中找到。LinkedList和ArrayDeque类都不支持多线程并发访问。
并发双端队列实现
LinkedBlockingDeque类是Deque接口的并发实现。如果deque为空,则takeFirst和takeLast等方法会等待到元素可用,然后检索和删除相同的元素。
包装器的实现
包装器实现将所有实际工作委托给指定的集合,但在此集合提供的功能之上添加额外的功能。对于设计模式的爱好者来说,这是一个装饰器模式的例子。虽然这看起来有点奇怪,但它真的很简单。
这些实现是匿名的;该库没有提供公共类,而是提供了一个静态工厂方法。所有这些实现都可以在Collections类中找到,该类仅由静态方法组成。
同步包装器
同步包装器向任意集合添加自动同步(线程安全)。六个核心集合接口——collection、Set、List、Map、SortedSet和SortedMap——都有一个静态工厂方法。
public static <T> Collection<T> synchronizedCollection(Collection<T> c);
public static <T> Set<T> synchronizedSet(Set<T> s);
public static <T> List<T> synchronizedList(List<T> list);
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m);
public static <T> SortedSet<T> synchronizedSortedSet(SortedSet<T> s);
public static <K,V> SortedMap<K,V> synchronizedSortedMap(SortedMap<K,V> m);
这些方法都返回由指定集合备份的同步(线程安全)集合。为了保证串行访问,对backing collection的所有访问都必须通过返回的collection来完成。保证这一点的简单方法是不保留对后备集合的引用。使用以下技巧创建同步集合。
List<Type> list = Collections.synchronizedList(new ArrayList<Type>());
以这种方式创建的集合与通常同步的集合(如Vector)一样都是线程安全的。
面对并发访问,在遍历返回的集合时,用户必须手动同步该集合。原因是迭代是通过对集合的多个调用来完成的,这些调用必须组合成单个原子操作。下面是在包装器同步的集合上进行迭代的习惯用法。
Collection<Type> c = Collections.synchronizedCollection(myCollection);
synchronized(c) {
for (Type e : c)
foo(e);
}
如果使用了显式迭代器,则迭代器方法必须在同步块中调用。不遵循这个建议可能会导致不确定性行为。在同步Map的Collection视图上迭代的习惯用法与此类似。当迭代任何Collection视图时,用户必须同步已同步的Map,而不是同步Collection视图本身,如下例所示。
Map<KeyType, ValType> m = Collections.synchronizedMap(new HashMap<KeyType, ValType>());
...
Set<KeyType> s = m.keySet();
...
// Synchronizing on m, not s!
synchronized(m) {
while (KeyType k : s)
foo(k);
}
使用包装器实现的一个小缺点是,您不能执行包装实现的任何非接口操作。例如,在前面的List例子中,你不能对包装好的ArrayList调用ArrayList的ensureCapacity操作。
不可变包装器
与同步包装器不同,同步包装器将功能添加到包装的集合中,不可修改的包装器将功能删除。特别是,它们通过拦截将修改集合的所有操作并抛出UnsupportedOperationException,从而剥夺了修改集合的能力。不可修改的包装器有两个主要用途,如下:
- 使集合在构建后不可变。在这种情况下,最好不要维护对支持集合的引用。这绝对保证了不变性。
- 允许某些客户端对数据结构进行只读访问。您保留对支持集合的引用,但分发对包装器的引用。通过这种方式,客户端可以查看但不能修改,而您可以保持完全访问。
与同步包装器一样,六个核心Collection接口中的每一个都有一个静态工厂方法。
public static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c);
public static <T> Set<T> unmodifiableSet(Set<? extends T> s);
public static <T> List<T> unmodifiableList(List<? extends T> list);
public static <K,V> Map<K, V> unmodifiableMap(Map<? extends K, ? extends V> m);
public static <T> SortedSet<T> unmodifiableSortedSet(SortedSet<? extends T> s);
public static <K,V> SortedMap<K, V> unmodifiableSortedMap(SortedMap<K, ? extends V> m);
检查接口的包装器
Collections.checked接口包装器提供给泛型集合使用。这些实现返回指定集合的动态类型安全视图,如果客户端试图添加错误类型的元素,则会抛出ClassCastException。该语言中的泛型机制提供了编译时(静态)类型检查,但也有可能击败这种机制。动态类型安全视图完全消除了这种可能性。
便利实现
本节介绍几种迷你实现,当您不需要它们的全部功能时,它们可能比通用实现更方便、更高效。本节中的所有实现都是通过静态工厂方法而不是公共类提供的。
数组的列表视图
Arrays.asList方法返回其数组参数的List视图。对List的更改会写入数组,反之亦然。集合的大小是数组的大小,不能更改。如果在List上调用了add或remove方法,将会产生一个UnsupportedOperationException。
此实现的正常使用是作为基于数组和基于集合的api之间的桥梁。它允许您将数组传递给期望集合或列表的方法。但是,这个实现还有另一个用途。如果您需要固定大小的List,那么它比任何通用的List实现都要高效。这是一个习惯用法。
List<String> list = Arrays.asList(new String[size]);
请注意,不保留对支持数组的引用。
不可变的多重副本列表
偶尔你会需要一个不可变的List,它由同一个元素的多个副本组成。Collections.nCopies的方法返回这样一个列表。这个实现有两个主要用途。第一个是初始化一个新创建的List;例如,假设你想要一个最初由1000个空元素组成的数组列表。下面的咒语可以达到目的。
List<Type> list = new ArrayList<Type>(Collections.nCopies(1000, (Type)null));
当然,每个元素的初始值不需要为空。第二个主要用途是扩展现有的List。例如,假设您想要将字符串“fruit bat”的69个副本添加到List< string >的末尾。现在还不清楚你为什么要这么做,但我们假设你这么做了。下面是你要做的。
lovablePets.addAll(Collections.nCopies(69, "fruit bat"));
通过使用同时接受索引和集合的addAll形式,可以将新元素添加到List的中间而不是末尾。
不可变的单例Set集合
有时你需要一个不可变的单例集,它由一个指定的元素组成。Collections.singleton方法返回这样的Set。此实现的一个用途是从集合中删除所有出现的指定元素。
c.removeAll(Collections.singleton(e));
相关的习惯用法从map中删除映射到指定值的所有元素。例如,假设您有一个Map - job,它将人们映射到他们的工作领域,并假设您希望消除所有的律师。下面的一行代码将完成这个任务。
job.values().removeAll(Collections.singleton(LAWYER));
该实现的另一个用途是向编写为接受一组值的方法提供单个输入值。
空的Set,List和Map常量
Collections类提供了返回空的Set、List和Map的方法- emptySet、emptyList和emptyMap。当您根本不想提供任何值时,这些常量的主要用途是作为接受Collection值的方法的输入,如本例中所示。
tourist.declarePurchases(Collections.emptySet());
实现的摘要
实现是用于存储集合的数据对象,集合实现了interfaces课中描述的接口。Java集合框架提供了几个核心接口的通用实现:
- 对于Set接口,HashSet是最常用的实现。
- 对于List接口,ArrayList是最常用的实现。
- 对于Map接口,HashMap是最常用的实现。
- 对于Queue接口,LinkedList是最常用的实现。
- 对于Deque接口,ArrayDeque是最常用的实现。
每个通用实现都提供其接口中包含的所有可选操作。
Java集合框架还为需要非标准性能、使用限制或其他不寻常行为的情况提供了几种特殊用途的实现。
java.util.concurrent包包含几个集合实现,它们是线程安全的,但不受单个排除锁的控制。
Collections类(与Collection接口相反)提供了操作或返回集合的静态方法,这些方法称为Wrapper实现。
最后,有几种便利实现,当您不需要它们的全部功能时,它们可能比通用实现更有效。便利实现可以通过静态工厂方法实现。
问题和练习:实现
Questions
- 您计划编写一个使用几个基本集合接口的程序:Set、List、Queue和Map。您不确定哪种实现工作得最好,因此决定使用通用实现,直到您更好地了解了程序在现实世界中的工作方式。这些实现是什么?
- 如果需要提供按值顺序迭代的Set实现,应该使用哪个类?
- 您使用哪个类来访问包装器实现?
Exercises
- 编写一个程序,将第一个命令行参数指定的文本文件读入List中。然后程序应该从文件中打印随机的行,打印的行数由第二个命令行参数指定。编写程序,以便立即分配大小正确的集合,而不是在读入文件时逐渐展开。提示:要确定文件中的行数,请使用java.io.File.length获取文件的大小,然后除以平均行数的假设大小。
Check your answers
算法
描述JDK提供的用于操作集合的多态算法。如果幸运的话,您再也不必编写自己的排序例程了!
这里描述的多态算法是Java平台提供的可重用功能的一部分。它们都来自Collections类,并且都采用静态方法的形式,静态方法的第一个参数是要执行操作的集合。Java平台提供的大多数算法都是在List实例上操作的,但也有少数算法是在任意的Collection实例上操作的。本节简要介绍以下算法:
- Sorting(排序)
- Shuffling(乱序)
- Routine Data Manipulation(常规数据操作)
- Searching(查找)
- Composition(组合)
- Finding Extreme Values(寻找极值)
Sorting
排序算法对List进行重新排序,使其元素根据排序关系按升序排列。提供了两种操作形式。这个简单的表单接受一个List,并根据其元素的自然顺序对其进行排序。如果您不熟悉自然排序的概念,请阅读对象排序部分。
排序操作使用了一个稍微优化的快速稳定的归并排序算法:
- Fast(快速):它保证在n log(n)时间内运行,并且在几乎排序的列表上运行得更快。经验测试表明,它的速度与高度优化的快速排序一样快。快速排序通常被认为比归并排序快,但它并不稳定,不能保证nlog(n)的性能。
- Stable(稳固的):它不会对相等的元素重新排序。如果您在不同的属性上重复排序相同的列表,这是很重要的。如果邮件程序的用户先按邮件日期对收件箱进行排序,然后再按发件人进行排序,那么用户自然会期望来自给定发件人的连续邮件列表将(仍然)按邮件日期进行排序。这只有在第二种类型是稳定的情况下才能保证。
下面这个简单的程序按字典顺序(字母顺序)打印出它的参数。
public class Sort {
public static void main(String[] args) {
List<String> list = Arrays.asList(args);
Collections.sort(list);
System.out.println(list);
}
}
让我们运行这个程序。
% java Sort i walk the line
生成以下输出。
[i, line, the, walk]
这个程序只是为了告诉你,算法真的很容易使用,就像它们看起来那样。
第二种形式的sort除了接受List之外还接受一个Comparator,并使用Comparator对元素进行排序。假设您想按大小的倒序打印前面示例中的字谜组——最大的字谜组先。下面的示例向您展示了如何在sort方法的第二种形式的帮助下实现这一点。
回想一下,变位组以List实例的形式作为值存储在Map中。修改后的打印代码遍历Map的值视图,将每个通过最小大小测试的List放入List of Lists中。然后,代码使用期望List实例的Comparator对List进行排序,并实现反向大小排序。最后,代码遍历已排序的List,打印其元素(换字组)。下面的代码替换了Anagrams示例中main方法末尾的打印代码。
// Make a List of all anagram groups above size threshold.
List<List<String>> winners = new ArrayList<List<String>>();
for (List<String> l : m.values())
if (l.size() >= minGroupSize)
winners.add(l);
// Sort anagram groups according to size
Collections.sort(winners, new Comparator<List<String>>() {
public int compare(List<String> o1, List<String> o2) {
return o2.size() - o1.size();
}});
// Print anagram groups.
for (List<String> l : winners)
System.out.println(l.size() + ": " + l);
在与the Map Interface部分相同的字典上运行程序,使用相同的最小字谜组大小(8个),产生以下输出。
12: [apers, apres, asper, pares, parse, pears, prase,
presa, rapes, reaps, spare, spear]
11: [alerts, alters, artels, estral, laster, ratels,
salter, slater, staler, stelar, talers]
10: [least, setal, slate, stale, steal, stela, taels,
tales, teals, tesla]
9: [estrin, inerts, insert, inters, niters, nitres,
sinter, triens, trines]
9: [capers, crapes, escarp, pacers, parsec, recaps,
scrape, secpar, spacer]
9: [palest, palets, pastel, petals, plates, pleats,
septal, staple, tepals]
9: [anestri, antsier, nastier, ratines, retains, retinas,
retsina, stainer, stearin]
8: [lapse, leaps, pales, peals, pleas, salep, sepal, spale]
8: [aspers, parses, passer, prases, repass, spares,
sparse, spears]
8: [enters, nester, renest, rentes, resent, tenser,
ternes,��treens]
8: [arles, earls, lares, laser, lears, rales, reals, seral]
8: [earings, erasing, gainers, reagins, regains, reginas,
searing, seringa]
8: [peris, piers, pries, prise, ripes, speir, spier, spire]
8: [ates, east, eats, etas, sate, seat, seta, teas]
8: [carets, cartes, caster, caters, crates, reacts,
recast,��traces]
Shuffling
shuffle算法的作用与sort算法相反,它破坏了List中可能存在的任何顺序痕迹。也就是说,该算法根据来自随机源的输入重新排序List,这样所有可能的排列都以相同的可能性发生,假设有一个公平的随机源。该算法在实现机会游戏中很有用。例如,它可以用来洗牌代表牌组的List of Card对象。同样,它对于生成测试用例也很有用。
此操作有两种形式:一种采用List并使用默认的随机性源,另一种要求调用者提供一个Random对象作为随机性源。该算法的代码用作List部分的示例。
Routine Data Manipulation
Collections类提供了对List对象进行例行数据操作的五种算法,它们都非常简单:
- **reverse(反转):**颠倒List中元素的顺序。
- fill (占满): 用指定的值重写List中的每个元素。此操作对于重新初始化List非常有用。
- **copy :**接受两个参数,一个目标List和一个源List,并将源的元素复制到目标中,覆盖其内容。目标列表必须至少与源列表一样长。如果它更长,则目标List中的其余元素不受影响。
- **swap(交换):**交换List中指定位置的元素。
- addAll: 将所有指定的元素添加到集合中。要添加的元素可以单独指定,也可以作为数组指定。
searching
binarySearch算法在一个已排序的List中搜索指定的元素。该算法有两种形式。第一个接受List和要搜索的元素(“搜索键”)。这个表单假设List是按照其元素的自然顺序升序排序的。第二种形式除了List和搜索键外还接受一个Comparator,并假定List按照指定的Comparator的升序排序。在调用binarySearch之前,可以使用排序算法对List进行排序。
这两种形式的返回值是相同的。如果List包含搜索键,则返回其索引。如果没有,返回值是(-(insertion point插入点)- 1),插入点的位置的值将被插入到List,或大于第一个元素的索引值或list.size()如果列表中的所有元素都小于指定值。这个显然很难看的公式保证了当且仅当找到搜索键时返回值为>= 0。它基本上是一种hack,将布尔(found)和整数(index)组合成一个单一的int返回值。
下面的习惯用法可用于binarySearch操作的两种形式,它查找指定的搜索键,并将其插入到适当的位置(如果它还不存在的话)。
int pos = Collections.binarySearch(list, key);
if (pos < 0)
l.add(-pos-1, key);
Composition
频率和不相交算法测试一个或多个集合组成的某些方面:
- **frequency(频率):**计算指定元素在指定集合中出现的次数
- **disjoint(拆开):**确定两个集合是否不相交;也就是说,它们是否包含相同的元素
Finding Extreme Values
min和max算法分别返回指定集合中包含的最小和最大元素。这两种操作都有两种形式。简单表单只接受一个Collection,并根据元素的自然顺序返回最小(或最大)元素。第二种形式除了接受Collection之外还接受一个Comparator,并根据指定的Comparator返回最小(或最大)元素。
自定义实现
告诉您为什么您可能想要编写自己的集合实现(而不是使用JDK提供的通用实现之一),以及如何着手。使用JDK的抽象集合实现很容易!
许多程序员永远不需要实现他们自己的Collections类。使用本章前面几节中描述的实现,您可以走得更远。然而,有一天您可能想编写自己的实现。在Java平台提供的抽象实现的帮助下,这样做是相当容易的。在讨论如何编写实现之前,我们先讨论一下为什么要编写实现。
编写实现的理由
下面的列表说明了您可能想要实现的自定义集合的类型。本报告不打算详尽无遗:
- Persistent(持续的):所有内置的Collection实现都驻留在主内存中,并在程序退出时消失。如果希望集合在下次程序启动时仍然存在,可以通过在外部数据库上构建一个贴面来实现它。这样的集合可以被多个程序同时访问。
- Application-specific(特殊用途):这是一个非常广泛的类别。一个例子是包含实时遥测数据的不可修改的地图。键可以表示位置,值可以从这些位置的传感器读取,以响应get操作。
- High-performance, special-purpose(高效的,特殊用途):许多数据结构利用受限制的使用来提供比通用实现更好的性能。例如,考虑一个包含长时间相同元素值的List。这种在文本处理中经常出现的列表可以进行游程编码——游程可以表示为包含重复元素和连续重复次数的单个对象。这个例子很有趣,因为它权衡了两个方面的性能:它比ArrayList需要更少的空间,但需要更多的时间。
- High-performance, general-purpose(高性能、多用途的):Java集合框架的设计者试图为每个接口提供最好的通用实现,但是可以使用很多很多的数据结构,而且每天都在发明新的数据结构。也许你能想出更快的办法!
- Enhanced functionality(增强功能):假设您需要一个高效的包实现(也称为multiset):一个提供常量时间包含检查的集合,同时允许重复元素。在HashMap上实现这样的集合是相当直接的。
- Convenience(便利):您可能想要提供Java平台之外的便利的其他实现。例如,您可能经常需要表示连续整数范围的List实例。
- Adapter(适配器):假设您正在使用一个具有自己的临时集合API的遗留API。您可以编写一个适配器实现,允许这些集合在Java集合框架中操作。适配器实现是对一种类型的对象进行包装,并通过将后一种类型的操作转换为对前一种类型的操作,使它们的行为类似于另一种类型的对象。
如何编写自定义实现
编写自定义实现非常简单。Java集合框架提供了专为方便定制实现而设计的抽象实现。我们将从下面的实现Arrays.asList的示例开始。
public static <T> List<T> asList(T[] a) {
return new MyArrayList<T>(a);
}
private static class MyArrayList<T> extends AbstractList<T> {
private final T[] a;
MyArrayList(T[] array) {
a = array;
}
public T get(int index) {
return a[index];
}
public T set(int index, T element) {
T oldValue = a[index];
a[index] = element;
return oldValue;
}
public int size() {
return a.length;
}
}
信不信由你,这与java.util.Arrays中包含的实现非常接近。就这么简单!提供一个构造函数和get、set和size方法,AbstractList完成其余的工作。您可以免费获得ListIterator、批量操作、搜索操作、哈希码计算、比较和字符串表示。
假设您想让实现更快一点。抽象实现的API文档精确地描述了每个方法是如何实现的,因此您将知道要覆盖哪些方法才能获得所需的性能。前面的实现的性能很好,但还可以稍加改进。特别是,toArray方法在List上迭代,每次复制一个元素。考虑到内部表示,克隆数组要快得多,而且更合理。
public Object[] toArray() {
return (Object[]) a.clone();
}
通过添加这个覆盖和其他类似的实现,这个实现与java.util.Arrays中的实现完全相同。从完全公开的角度来看,使用其他抽象实现有点困难,因为您必须编写自己的迭代器,但这仍然不是那么困难。
以下列表总结了这些抽象的实现:
- AbstractCollection:既不是集合也不是列表的集合。至少,您必须提供迭代器和size方法。
- AbstractSet:Set集合,use与AbstractCollection相同。
- AbstractList:由随机访问数据存储(如数组)备份的List。至少,必须提供位置访问方法(get和(可选)set、remove和add)以及size方法。抽象类负责listIterator(和iterator)。
- AbstractSequentialList:由顺序访问数据存储备份的列表,如链表。至少,您必须提供listIterator和size方法。抽象类负责位置访问方法。(这与AbstractList相反。)
- AbstractQueue:至少,您必须提供offer、peek、poll和size方法以及支持remove的迭代器。
- AbstractMap:Map集合,至少,您必须提供entrySet视图。这通常是通过AbstractSet类实现的。如果Map是可修改的,您还必须提供put方法。
编写自定义实现的过程如下:
- 从前面的列表中选择适当的抽象实现类。
- 为类的所有抽象方法提供实现。如果您的自定义集合是可修改的,您还必须重写一个或多个具体方法。抽象实现类的API文档将告诉您要覆盖哪些方法。
- 测试并在必要时调试实现。现在您有了一个可工作的自定义集合实现。
- 如果您关心性能,请阅读抽象实现类的API文档,了解您要继承其实现的所有方法。如果其中任何一个看起来太慢,就覆盖它们。如果您重写了任何方法,请确保在重写之前和之后测量方法的性能。您在调整性能上投入了多少精力,应该取决于实现将获得多少使用,以及使用它对性能有多重要。(通常这一步最好省略。)
互通性
告诉你集合框架如何与Java中添加集合之前的旧api进行互操作。此外,它还告诉您如何设计新的api,使它们能够与其他新的api无缝地互操作。
在本节中,您将了解以下两个方面的互操作性:
- **Compatibility(兼容性):**本小节描述如何使集合与Java平台中添加集合之前的旧api一起工作。
- **API Design(API设计):**本小节描述如何设计新的api,使它们能够无缝地相互操作。
兼容性
Java集合框架旨在确保核心集合接口和Java平台早期版本中用于表示集合的类型之间的完整互操作性:向量、哈希表、数组和枚举。在本节中,您将学习如何将旧集合转换为Java collections Framework集合,反之亦然。
向上兼容
假设您正在使用一个API,该API将返回遗留集合,同时使用另一个API,该API要求对象实现集合接口。要使这两个api顺利互操作,您必须将遗留集合转换为现代集合。幸运的是,Java集合框架使这变得容易。
假设旧API返回一个对象数组,而新API需要一个集合。集合框架有一个方便的实现,它允许将对象数组视为一个List。你使用Arrays.asList将数组传递给任何需要集合或列表的方法。
Foo[] result = oldMethod(arg);
newMethod(Arrays.asList(result));
如果旧的API返回Vector或Hashtable,则根本不用做任何工作,因为Vector被改造为实现List接口,而Hashtable被改造为实现Map。因此,Vector可以直接传递给任何调用Collection或List的方法。
Vector result = oldMethod(arg);
newMethod(result);
类似地,Hashtable可以直接传递给任何调用Map的方法。
Hashtable result = oldMethod(arg);
newMethod(result);
较少情况下,API可能返回表示对象集合的Enumeration。Collections.list方法将枚举转换为集合。
Enumeration e = oldMethod(arg);
newMethod(Collections.list(e));
向下兼容
假设您正在使用一个API,该API返回现代集合,同时使用另一个API,该API要求您传递遗留集合。要使这两个api顺利互操作,您必须将现代集合转换为旧集合。Java集合框架再次简化了这一过程。
假设新的API返回一个Collection,而旧的API需要一个Object数组。您可能已经知道,Collection接口包含一个专门为这种情况设计的toArray方法。
Collection c = newMethod();
oldMethod(c.toArray());
如果旧的API需要String(或其他类型)数组而不是Object数组呢?只需使用另一种形式的toArray—它在输入时接受一个数组。
Collection c = newMethod();
oldMethod((String[]) c.toArray(new String[0]));
如果旧的API需要一个Vector,那么标准的集合构造函数就派上用场了。
Collection c = newMethod();
oldMethod(new Vector(c));
旧API需要哈希表的情况是类似地处理的。
Map m = newMethod();
oldMethod(new Hashtable(m));
最后,如果旧的API需要Enumeration,该怎么办?这种情况并不常见,但它确实不时发生,并且 Collections.enumeration方法来处理它。这是一个静态工厂方法,它接受Collection并返回Collection元素的Enumeration。
Collection c = newMethod();
oldMethod(Collections.enumeration(c));
API设计
在这个简短但重要的部分中,您将学习一些简单的指导原则,这些指导原则将允许您的API与遵循这些指导原则的所有其他API无缝地互操作。从本质上说,这些规则定义了如何成为收藏界的优秀“公民”。
参数
如果您的API包含一个需要在输入上使用集合的方法,那么将相关参数类型声明为集合接口类型之一是至关重要的。永远不要使用实现类型,因为这违背了基于接口的Collections Framework的目的,后者允许在不考虑实现细节的情况下操作集合。
此外,您应该始终使用有意义的最不特定的类型。例如,如果集合可以,则不需要List或Set。并不是说你不应该在输入时要求List或Set;如果一个方法依赖于这些接口中的一个属性,那么这样做是正确的。例如,Java平台提供的许多算法都要求在输入时使用List,因为它们依赖于列表是有序的这一事实。然而,作为一般规则,在输入中使用的最佳类型是最通用的:Collection和Map。
注意:永远不要定义自己的临时集合类,并要求在输入时使用该类的对象。通过这样做,您将失去Java Collections Framework提供的所有好处。
返回值
您可以使用比使用输入参数更灵活的返回值。可以返回实现或扩展某个集合接口的任何类型的对象。这可以是其中一个接口,也可以是扩展或实现这些接口之一的特殊用途类型。
例如,可以想象一个名为ImageList的图像处理包,它返回实现List的新类的对象。除了List操作之外,ImageList还可以支持任何需要的特定于应用程序的操作。例如,它可能提供一个indexImage操作,该操作返回一个包含ImageList中每个图形的缩略图的图像。需要注意的是,即使API在输出时提供ImageList实例,它也应该在输入时接受任意的Collection(或者List)实例。
在某种意义上,返回值应该具有与输入参数相反的行为:最好返回最具体的可应用集合接口,而不是最通用的。例如,如果您确定您总是返回一个SortedMap,那么您应该为相关方法提供SortedMap的返回类型,而不是Map。与普通的Map实例相比,SortedMap实例的构建更耗时,而且功能更强大。既然您的模块已经投入了时间来构建SortedMap,那么让用户访问其增强的功能是很有意义的。此外,用户将能够将返回的对象传递给需要SortedMap的方法,以及那些接受任何Map的方法。
遗留的api
目前有很多api定义了它们自己的特殊集合类型。虽然这很不幸,但这是事实,因为在Java平台的前两个主要发行版中没有collection Framework。假设你拥有其中一个api;下面是你可以做的。
如果可能,修改遗留集合类型以实现标准集合接口之一。然后,您返回的所有集合将与其他基于集合的api顺利互操作。如果这是不可能的(例如,因为一个或多个先前存在的类型签名与标准集合接口冲突),则定义一个适配器类来包装一个遗留集合对象,允许它作为标准集合运行。(Adapter类就是一个自定义实现的例子。)
如果可能的话,使用遵循输入指导原则的新调用来修改API,以接受标准集合接口的对象。这类调用可以与采用遗留集合类型的调用共存。如果这是不可能的,为遗留类型提供一个构造函数或静态工厂,它接受一个标准接口的对象,并返回包含相同元素(或映射)的遗留集合。这两种方法都允许用户将任意集合传递到API中。