【CV】YOLOv4官方改进版来了!指标炸裂55.8% AP!Scaled-YOLOv4:扩展跨阶段局部网络

YOLOv4-large在COCO上最高可达55.8 AP!速度也高达15 FPS!YOLOv4-tiny的模型实现了1774 FPS!(在RTX 2080Ti上测试)
作者单位:YOLOv4原班人马(AlexeyAB等人)
papers: 作者公号后台回复 SYOLO 获取
code:
https://github.com/WongKinYiu/PyTorch_YOLOv4
1
摘要

我们展示了基于CSP方法的YOLOv4目标检测神经网络,可以上下缩放,并且适用于小型和大型网络,同时保持最佳的速度和准确性。本文提出了一种网络缩放方法,该方法不仅可以修改深度,宽度,分辨率,还可以修改网络的结构。
YOLOv4-large模型达到了最先进的结果:
在Tesla V100上以15 FPS的速度,MS COCO数据集的AP为55.4%(AP50为73.3%),而随着测试时间的增加,YOLOv4-large的模型达到了55.8% AP(73.2 AP50)。据我们所知,这是目前所有已发表作品中COCO数据集的最高准确性。
YOLOv4-tiny模型在RTX 2080Ti上以443 FPS的速度实现了22.0%的AP(42.0%AP50),而使用TensorRT,批处理大小= 4和FP16精度,YOLOv4-tiny的模型实现了1774 FPS。
2
本文思路
通过对目前最先进的物体检测器的分析,我们发现YOLOv4[1]的主干CSPDarknet53几乎匹配所有通过网络架构搜索技术得到的最优架构特征。
CSPDarknet53的深度、瓶颈比、龄期间宽度生长比分别为65、1和2。因此,我们开发了基于YOLOv4的模型缩放技术,提出了scale -YOLOv4。提出的缩放yolov4具有出色的性能,如下图所示。
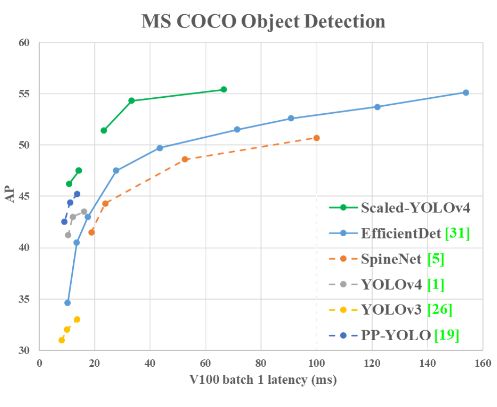
scale - yolov4的设计过程如下
首先对yolov4进行了重新设计,提出了YOLOv4-CSP,然后基于onYOLOv4-CSP开发了scale - yolov4。
在提出的scale - yolov4中,本文讨论了线性缩放模型的上界和下界,并分别分析了小模型和大模型缩放时需要注意的问题。因此,我们能够系统地开发YOLOv4-large和yolov4 -tiny模型。Scaled-YOLOv4能够在速度和精度之间实现最好的平衡,能够在15 fps、30 fps和60fps的影片以及嵌入式系统上进行实时对象检测。
我们总结了本文的工作:
设计了一种针对小模型的强大的模型缩放方法,系统地平衡了浅层CNN的计算代价和存储带宽;
设计一种简单有效的大型目标检测器缩放策略;
分析各模型缩放因子之间的关系,基于最优组划分进行模型缩放;
实验证实了FPN结构本质上是一种一次性结构;
利用上述方法开发yolov4 - tiny 和 yolo4v4 -large。
3
模型缩放原则
3.1 General principle of model scaling
在设计有效的模型比例方法时,我们的主要原则是:当比例上升/下降时,我们希望增加/减少的定量成本越低/越高越好。在这一节中,我们将展示和分析各种常用的CNN模型,并试图了解它们在面对(1)图像大小,(2)层数,(3)通道数的变化时的定量代价。我们选择的cnn是ResNet, ResNext和Darknet。
或者是具有b基层通道的k层CNNs, ResNet层的计算是k∗{conv1×1,b/4 - conv3×3,b/4 - conv1×1,b}, ResNext层的计算是k∗{conv1×1,b/2 - gconv3×3/32,b/2 - conv1×1,b}。暗网层的计算量为k∗{conv1×1,b/2 - conv3×3,b}。将可用于调整图像大小、层数和通道数的缩放因子分别设置为:当这些比例因子发生变化时,FLOPs的相应变化见表1。

由表1可以看出,尺度大小、深度和宽度都会导致计算成本的增加。它们分别表现为平方增长、线性增长和平方增长。CSPNet可以应用于各种CNN架构,同时减少了参数和计算量。此外,它还提高了准确性,减少了推理时间。我们将它应用到ResNet、ResNeXt和Darknet中,观察计算量的变化,如表2所示。

从表2所示的图中可以看出,将上述CNNs转换为CSPNet后,新的架构可以有效地减少ResNet、ResNeXt和Darknet上的计算量(FLOPs),分别减少23.5%、46.7%和50.0%。因此,我们使用CSP-ized的模型作为执行模型伸缩的最佳模型。
3.2 Scaling Tiny Models for Low-End Devices
对于低端设备,设计模型的推理速度不仅受到计算量和模型大小的影响,更重要的是必须考虑外围硬件资源的限制。因此,在执行tiny模型缩放时,我们还必须考虑诸如内存带宽、内存访问成本(MACs)和DRAM流量等因素。为了适应上述因素的同时,我们的设计必须符合以下原则:
使计算资源的申请不超过O(whkb2):
轻量级模型不同于大型模型,其参数必须更高的利用效率以达到所需的精度与少量的计算。在进行模型缩放时,我们希望计算资源的申请尽可能的低。在表3中,我们分析了有效利用参数的网络,如DenseNet和OS-ANet的计算负荷。

最小化/平衡feature map的大小:
为了在计算速度上得到最好的折衷,我们提出了一个新的概念,即在CSPOSANet的计算块之间进行梯度截断。如果我们将原来的CSPNet设计应用到DenseNet或ResNet架构上,由于这两种架构的第j层输出是第1层到(j−1)层输出的积分,我们必须将整个计算块作为一个整体来处理。
由于OSANet的计算块与平面网结构相匹配,从计算块的任意层构造CSPNet都可以达到梯度截断的效果。我们利用该特性对基层的b通道和计算块生成的kg通道进行重新规划,并将其分割为通道数相等的两条路径,如表4所示。
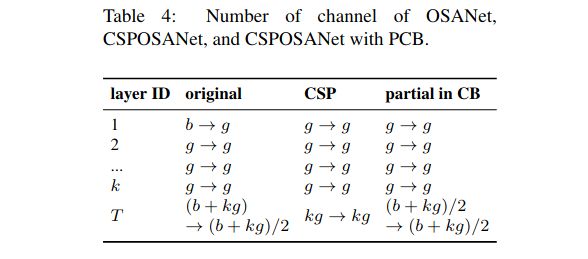
在卷积后保持相同的通道数:
在评估低端设备的计算成本时,还必须考虑功耗,影响功耗的最大因素是内存访问成本(MAC)。通常一个卷积运算的MAC计算方法如下:

最小化卷积输入/输出(CIO):
CIO是一个可以测量DRAM IO状态的指示器。表5列出了OSA、CSP和我们设计的CSP OSANet的CIO。当kg > b/2时,提出的CSP OSANet可以获得最佳的CIO。

3.3 Scaling Large Models for High-End GPUs
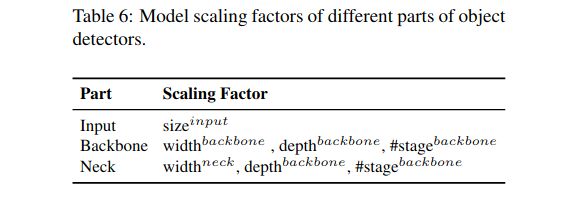
由于希望在对CNN模型进行缩放后提高准确性并保持实时推理速度,所以在进行复合缩放时,必须在目标检测器众多的缩放因子中找到最佳的组合。通常,我们可以调整对象检测器的输入、主干和颈部的比例因子。表6总结了可以调整的潜在缩放因子。
图像分类与目标检测最大的区别在于,前者只需要识别图像中最大成分的类别,而后者需要预测图像中每个目标的位置和大小。在单级目标检测器中,利用与每个位置相对应的特征向量来预测该位置的目标类别和大小。更好地预测物体大小的能力基本上取决于特征向量的感受野。在CNN的建筑中,与感受野最直接相关的是stage。feature pyramid network (FPN)的架构告诉我们,更高的stage更适合预测大的物体。表7说明了感受野与几个参数之间的关系。

4
Scaled-YOLOv4 具体实现
4.1 CSP-ized YOLOv4
YOLOv4是为通用GPU上的实时目标检测而设计的。在本节中,我们将重新设计YOLOv4 toYOLOv4-CSP,以获得最佳的速度/精度取舍。
Backbone:
在CSPDarknet53的设计中,跨级处理的下采样卷积计算不包括在残差块中。因此,我们可以推断CSPDarknet每个阶段的计算量为whb2(9/4+3/4+5k/2)。由上面推导的公式可知,CSPDarknet stage只有在满足k >1的情况下,才会比Darknet stage有更好的计算优势。CSPDarknet53中每个阶段拥有的剩余层数分别为1-2-8-8-4。为了获得更好的速度/精度折衷,我们将第一个CSP stage转换为原始的Darknet残差层。
Neck:
为了有效地减少计算量,我们对YOLOv4中的PAN体系结构进行了CSP-ize。PAN体系结构的计算列表如图2(a)所示。它主要整合来自不同特征金字塔的特征,然后通过两组反向的暗网残留层,没有捷径连接。经过csp化,新的计算列表的架构如图2(b)所示。这个新的更新有效地减少了40%的计算量。
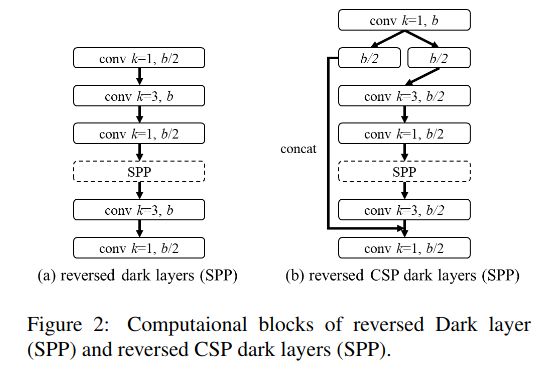
SPP:
SPP模块最初是插入在Neck第一个计算列表组的中间位置。因此,我们还将SPP模块插入到CSPPAN的第一个计算列表组的中间位置。
4.2 YOLOv4-tiny
YOLOv4-tiny是为低端GPU设备设计的,设计将遵循3.2节中提到的原则。

我们将使用PCB架构的CSPOSANet来构成YOLOv4的主干。我们设g=b/2为增长率,最终使其增长到b/2 +kg= 2bat。通过计算,我们得到k= 3,其结构如图3所示。对于每个阶段的通道数量和颈部部分,我们采用yolov3 -tiny的设计。
4.3 YOLOv4-large
YOLOv4-large是为云GPU设计的,主要目的是实现高精度的目标检测。我们设计了一个完全csp化的模型YOLOv4-P5,并将其扩展到YOLOv4-P6和YOLOv4-P7。YOLOv4-P5、YOLOv4-P6、YOLOv4-P7的结构如图4所示。我们设计了对输入大小#stage执行复合缩放,将每个阶段的深度尺度设为2^ds_i, ds设为[1,3,15,15,7,7,7]。
最后,我们进一步使用推断时间作为约束来执行额外的宽度缩放。
实验表明,当宽度缩放因子为1时,YOLOv4-P6可以在30帧/秒的视频中达到实时性能。对于YOLOv4-P7来说,当宽度缩放因子等于1.25时,它可以在15 fps的视频中达到实时性能。

5
实验结果
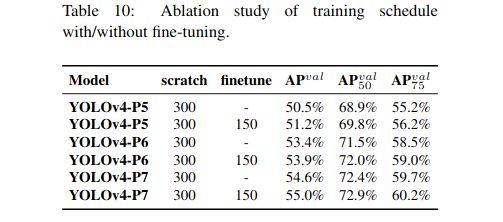
5.1 消融实验
CSP-ized

YOLOv4-tiny

YOLOv4-large
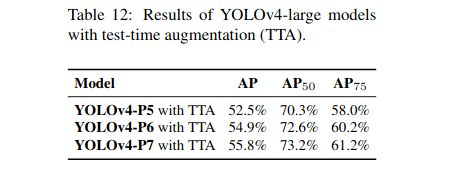
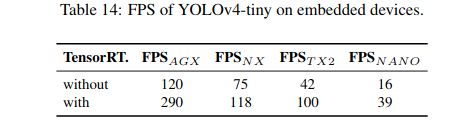
5.2 Scaled-YOLOv4对标基准




往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: