YOLO系列目标检测算法-YOLOv5
YOLO系列目标检测算法目录
- YOLO系列目标检测算法总结对比
- YOLOv1
- YOLOv2
- YOLOv3
- YOLOv4
- Scaled-YOLOv4
- YOLOv5- 文章链接
- YOLOv6- 文章链接
- YOLOv7- 文章链接
本文总结:
YOLOv5相比YOLOv4做的改进:
- 激活函数修改为SiLU
- 新增缩放系数,模型深度系数(model depth multiple)和宽度缩放系数(layer channel multiple),用于方便扩展或缩放模型
- 修改第一层卷积为Conv2d(3, 64, kernel_size=(6, 6), stride=(2, 2), padding=(2, 2), bias=False),YOLOv4中最大卷积核为3,前两层用了两次3×3卷积
- 输入图片从608变成640
- BottleneckCSP[1,3,15,15,7,7,7]修改成C3[3,6,9,3]
- CSPSPP修改成SPPF
- BottleneckCSP2修改使用C3
- 测试时数据增强TTA
- 修改框回归公式,能匹配到更多的anchor
深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
此专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章目录
- 7. YOLO系列目标检测算法-YOLOv5
-
- 7.1 模型结构
-
- 7.1.1 Backbone
- 7.1.2 Neck
- 7.1.3 Head
- 7.1.4 整体结构
- 7.2 数据增强
- 7.3 训练策略
- 7.4 损失函数
- 7.5 Eliminate Grid Sensitivity
- 7.6 Build Targets
7. YOLO系列目标检测算法-YOLOv5
7.1 模型结构
YOLOv5(v6.0/6.1)由以下各部分构成:Backbone、Neck、Head。
7.1.1 Backbone
- 整体结构
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
- Conv结构
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
-
C3结构
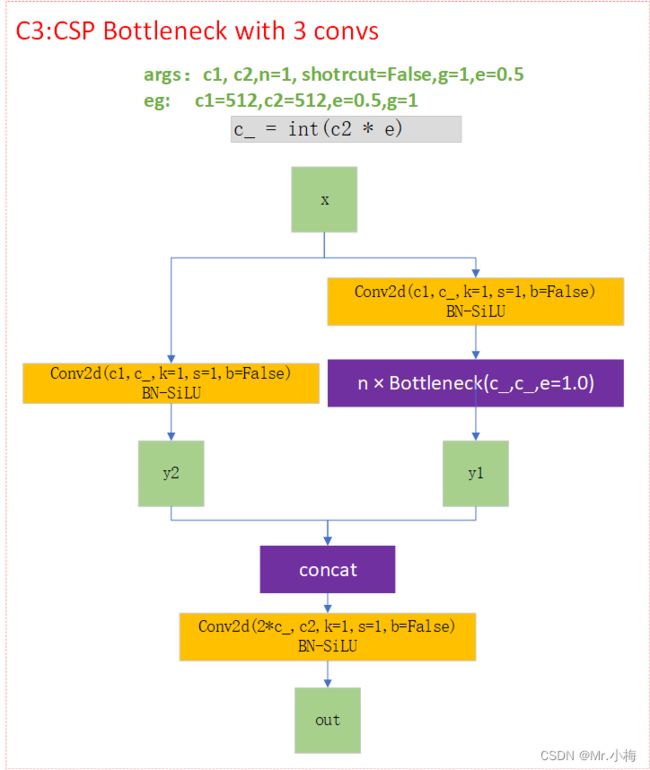
-
C3中的Bottleneck结构
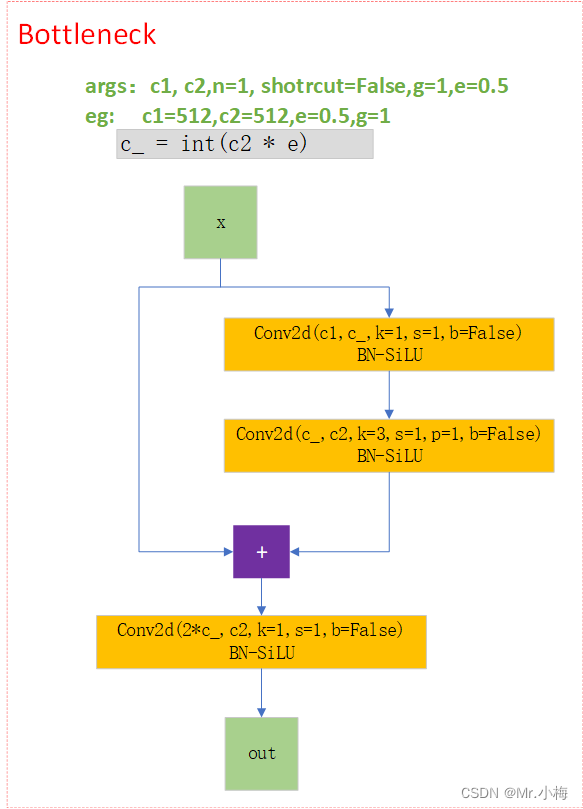
-
SPPF结构

7.1.2 Neck
- SPPF
- NEW CSP-PAN
7.1.3 Head
Head采用YOLOv3 Head。
7.1.4 整体结构
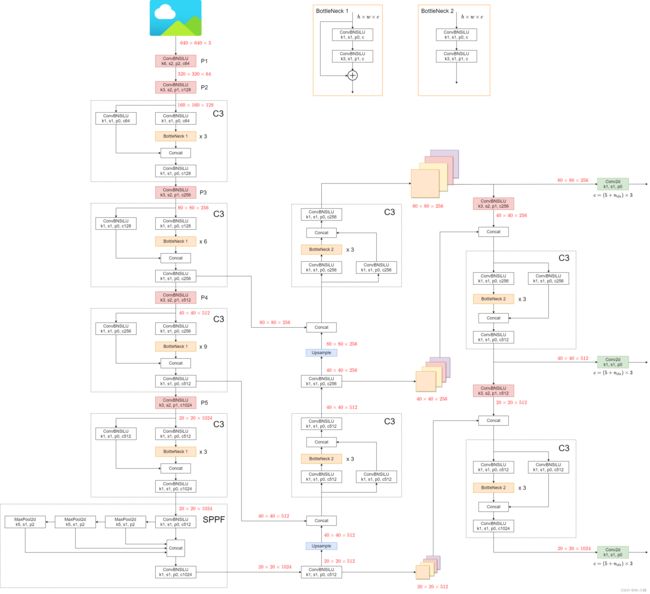
7.2 数据增强
- Mosaic
- Copy-Paste
- Random affine(Rotation, Scale, Translation and Shear)
- MixUp
- Albumentations
- Augment HSV(Hue, Saturation, Value)
- Random horizontal flip
- TTA(Test Time Augmentation)
TTA,就是在图片预测时,将一张图片通过翻转、缩放为多张图片,然后对多张图片的检测结果进行合并,这样能够提高目标检测性能,但会增加时间效果。实现代码如下:
def _forward_augment(self, x):
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self._forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
y = self._clip_augmented(y) # clip augmented tails
return torch.cat(y, 1), None # augmented inference, train
def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
# Scales img(bs,3,y,x) by ratio constrained to gs-multiple
if ratio == 1.0:
return img
h, w = img.shape[2:]
s = (int(h * ratio), int(w * ratio)) # new size
img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
if not same_shape: # pad/crop img
h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
如下图所示,每次推理时会增强成三张图片:

7.3 训练策略
- Multi-scale training(0.5~1.5x)
- AutoAnchor(For training custom data)
- Warmup and Cosine LR scheduler
- EMA(Exponential Moving Average)
- Mixed precision
- Evolve hyper-parameters
7.4 损失函数
YOLOv5的损失计算由以下三部分组成:
- Classes loss(BCE loss)
- Objectness loss(BCE loss)
- Location loss(CIoU loss)
L o s s = λ 1 L c l s + λ 2 L o b j + λ 3 L l o c Loss=\lambda_1 L_{cls}+\lambda_2 L_{obj}+\lambda_3 L_{loc} Loss=λ1Lcls+λ2Lobj+λ3Lloc
不同预测层(P3、P4、P5)的目标损失使用不同地平衡加权系数,分别为4.0、1.0和0.4。
L o b j = 4.0 ⋅ L o b j s m a l l + 1.0 ⋅ L o b j m e d i u m + 0.4 ⋅ L o b j l a r g e L_{obj}=4.0·L_{obj}^{small}+1.0· L_{obj}^{medium}+0.4·L_{obj}^{large} Lobj=4.0⋅Lobjsmall+1.0⋅Lobjmedium+0.4⋅Lobjlarge
7.5 Eliminate Grid Sensitivity
在YOLOv2和YOLOv3中,用于计算预测目标信息的公式为:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w ⋅ e t w b h = p h ⋅ e t h \begin{aligned} &b_x=\sigma(t_x)+c_x \\ &b_y=\sigma(t_y)+c_y \\ &b_w=p_w·e^{t_w} \\ &b_h=p_h·e^{t_h} \\ \end{aligned} bx=σ(tx)+cxby=σ(ty)+cybw=pw⋅etwbh=ph⋅eth

在YOLOv5中公式修改为:
b x = ( 2 ⋅ σ ( t x ) − 0.5 ) + c x b y = ( 2 ⋅ σ ( t y ) − 0.5 ) + c y b w = p w ⋅ ( 2 ⋅ σ ( t w ) ) 2 b h = p w ⋅ ( 2 ⋅ σ ( t h ) ) 2 \begin{aligned} &b_x=(2·\sigma(t_x)-0.5)+c_x \\ &b_y=(2·\sigma(t_y)-0.5)+c_y \\ &b_w=p_w·(2·\sigma(t_w))^2 \\ &b_h=p_w·(2·\sigma(t_h))^2 \end{aligned} bx=(2⋅σ(tx)−0.5)+cxby=(2⋅σ(ty)−0.5)+cybw=pw⋅(2⋅σ(tw))2bh=pw⋅(2⋅σ(th))2
修改前后中心点偏移对比如图所示:
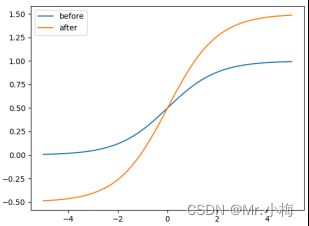
从图中可以看出,中心点偏移值范围从(0,1)调整到(-0.5,1.5)。因此,偏移值可以很容易地得到0或1。
比较调整前后的高度和宽度比例(相对于anchor)。原始的yolo/darknet box方程有一个严重的缺陷。宽度和高度完全是无界的,因为它们只是 o u t = e x p ( i n ) out=exp(in) out=exp(in),这是危险的,因为它可能导致梯度失控、不稳定性、loss为NaN等,最终完全失去训练效果。而YOLOv5中新设计的公式就不会出现这种问题,如下图所示。
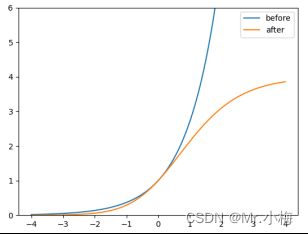
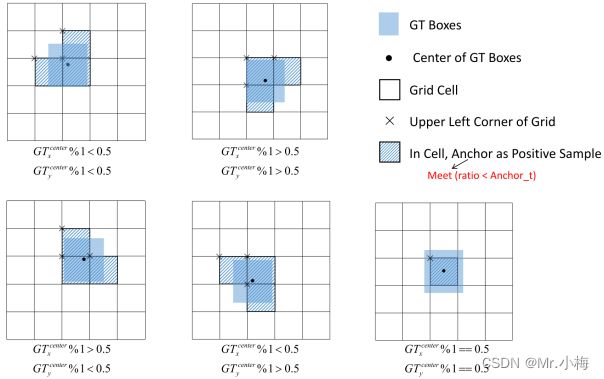
7.6 Build Targets
YOLOv5中正样本匹配过程如下:
- 计算GT和anchor的纵横比
r w = w g t / w a t r h = w g t / h a t r w m a x = m a x ( r w , 1 / r w ) r h m a x = m a x ( r h , 1 / r h ) r m a x = m a x ( r w m a x , r h m a x ) r m a x < a n c h o r t \begin{aligned} &r_w=w_{gt}/w_{at} \\ &r_h=w_{gt}/h_{at} \\ &r_w^{max}=max(r_w,1/r_w) \\ &r_h^{max}=max(r_h,1/r_h) \\ &r^{max}=max(r_w^{max},r_h^{max}) \\ &r^{max}rw=wgt/watrh=wgt/hatrwmax=max(rw,1/rw)rhmax=max(rh,1/rh)rmax=max(rwmax,rhmax)rmax<anchort
具体匹配过程如下图所示:

- 将成功匹配的anchor分配给相应的单元格

- 因为中心点偏移范围从(0,1)调整到(-0.5,1.5)。GT框可以分配给更多的anchor