C/C++手撕哈希表详解
文章目录
- 关于实现源码
-
- 哈希表的理论知识
-
- 哈希表的定义
- 桶数组
- 散列函数
-
- 散列函数的构造
- 扰动函数 和 按位与
- 哈希冲突
- HashMap实现
-
- 类型定义(键值对以及对应节点)
- 哈希表的数据
- 初始化方法(构造方法)
- 根据散列函数得到位置
- put方法
- 扩容方法
- get方法
- 完整代码
- 测试:LeetCode 1.两数之和
- 总结
关于实现源码
实现源码仓库在线查看链接:
C语言实现
C++实现
哈希表的理论知识
哈希表的定义
哈希表也叫散列表,我们先来看看哈希表的定义:
哈希表是保存键值映射关系的查找表,通过关键字可以很快找到对应的值。
简单说来说,哈希表由两个要素构成:桶数组 和 散列函数(哈希函数)。
- 桶数组:用于存储键值对的空间。
- 散列函数:用于给键值对在桶数组中的位置指路。
桶数组
我们可能知道,有一类基础的数据结构 线性表,而线性表又分两种,数组 和 链表。
哈希表数据结构里,存储元素的数据结构就是数组,数组里的每个单元都可以想象成一个 桶(Bucket)。
而我们每次都是把我们需要存入的键值对加入到这样的桶子中。
散列函数
我们需要在元素和 桶数组 对应位置建立一种映射映射关系,这种映射关系就是 散列函数 ,也可以叫哈希函数。
比如我们平时生活中,碰到排队型的时候,都需要根据高矮来进行一定的队形调整,这个调整过程也可以看做是散列函数的一种体现。
散列函数的构造
散列函数有很多类,这其中的奥妙来自于数学,而不是我们程序员需要过于操心的事情。
在Java语言中只要是继承自Object类的所有类都有默认的一个 hashcode() 方法,而对于具体过程我们不需要多想,我们来看看最常用的字符串的哈希过程:
static inline size_t strHashcode(char *key) {
size_t hash = 0;
size_t index = 0;
while (key[index] != '\0') {
hash = hash * 31 + key[index++];
}
return hash;
}
很明显得出的 hashcode 是一个以31为底的次方数,关于为什么以31为底,我这里简单的描述一下:
- 以31为底能很快得出比较散且比较大的二进制码(底层的01串),这样结合子掩码的与运算有利于减少哈希冲突的产生。
31 * i == (i << 5) - i因为这个等式的成立使得运算性能也有很大的提升。(编译器一般会对31*i进行优化的)
更多细节看看这篇文章:关于为什么选31
扰动函数 和 按位与
我们通过散列函数得到一堆 01 串后,我们该怎么做?
接下来一般就是通过和桶数组的长度取余然后得到对应的位置进行插入。这样虽然也可以,但我们有更好的方式进行替代,那就是位运算。
既然要讲位运算,那么我先讲讲一个二进制串。
在只有一个 1 的二进制串里面,我们对它再减去 1 的时候,我们很快得到它的低位掩码。
比如:
0001000 - 1 = 0000111,得到的 0000111 有什么用处呢?
如果我们把一个 hashcode 和这个数进行按位与,则得到的结果肯定是介于 000~111 之间,也就是 0~7 之间,这个时候我们思考一下,如果把这个 0001000 看做是桶数组的长度,那么这个按位与的结果就可以当做需要存入的桶的具体位置了。
基于这个理论,我们只要桶数组长度是 2的倍数 则 hashcode%size 可用 hashcode&(size-1) 来替代。
这样做有以下好处:
- 位运算的性能更好。
- 便于控制 hashcode 最终得出的结果,有些时候我们得到的
hashcode不够均匀高位的1比较多,而低位的1比较少,这个时候可以利用hashcode^(hashcode>>16)进行一定程度的打散,而这个打散的过程我们一般把它叫做扰动函数。
哈希冲突
当出现键值运算结果得到的桶子位置是同一个的时候便产生了哈希冲突。
而解决哈希冲突的方案一般有以下三种:
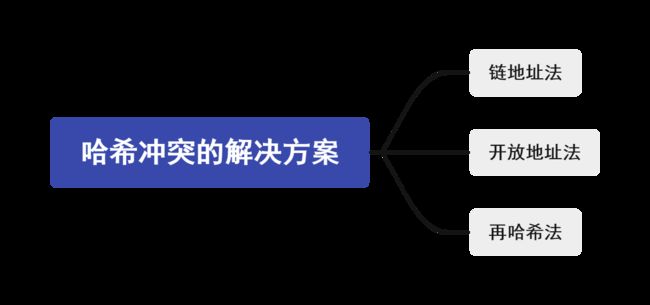
链地址法
一旦发生哈希冲突,直接生成链表往后继续延伸。
开放地址法
简单来说就是给冲突的元素再在桶数组里找到一个空闲的位置。
而常用采用的方法有:
- 线性探查法: 从冲突的位置开始,依次判断下一个位置是否空闲,直至找到空闲位置。
- 平方探查法: 从冲突的位置x开始,第一次增加
1^2个位置,第二次增加2^2…,直至找到空闲的位置。 - 双散列函数探查法
…
再哈希法
再哈希法完全可以配备以上两类方法进行使用。
当然也可单独使用,单独使用的话就行配备多个哈希函数,一个不行的话换另一个哈希函数,直到不产生哈希冲突为止。
最终的选择:
而我们常用的是 链地址法 + 再哈希 ,为了能够尽量减少内存空间的使用,我们默认从容量为 16 的桶数组开始,一旦装入的键值对超过 capacity * factor 个时,我们进行一次两倍的(左移1位)扩容,而由于扩容会导致 capacity 改变,所以通过 哈希函数 + 与运算 得出的位置也会出错,故需要经过 再哈希 。
我们其实可以继续细想,我们左移一位后,得出的结果再减一,它也仅仅多出一位掩码,而我们的 hashcode 只要在这一位上为 0 则最后得到的桶位置不会有任何改变,只有在这一位上为 1 的才会发生改变,所以根据这个特点,Java 8 进行了一些优化,更厉害的优化方式在于,只要链比较长,它还会转红黑树(这就在我的能力范围之外了)。
以上内容参考的文章为:一个HashMap和面试官扯了半小时
HashMap实现
类型定义(键值对以及对应节点)
C
#define DEFAULT_CAPACITY 16 //初始的表长
#define DEFAULT_FACTOR 0.75f //初始的装载因子
/*类型定义 和 装载因子初始化*/
typedef int key_t;
typedef int val_t;
static const float factor = DEFAULT_FACTOR; //装载因子
typedef struct node {//每个哈希表的键值对
key_t key;
val_t val;
struct node *next;
} Node;
C++
全程用的泛型模板

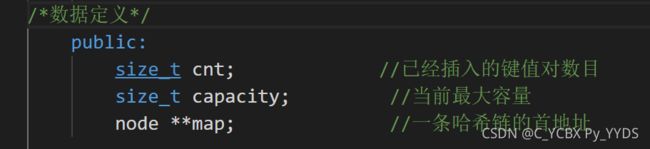
哈希表的数据
C
typedef struct {
size_t size; //记录已经存下的键值对数目
size_t capacity; //记录表长
Node **buckets; //桶子:用于记录的哈希桶,桶子中每个元素是Node*
} HashMap;
C++
初始化方法(构造方法)
C
HashMap *init() { //初始化得到一个哈希表
HashMap *ret = (HashMap *) malloc(sizeof(HashMap));
assert(ret != NULL);
ret->size = 0;
ret->capacity = DEFAULT_CAPACITY;
ret->buckets = (Node **) calloc(DEFAULT_CAPACITY, sizeof(Node *));
assert(ret->buckets != NULL);
return ret;
}
C++

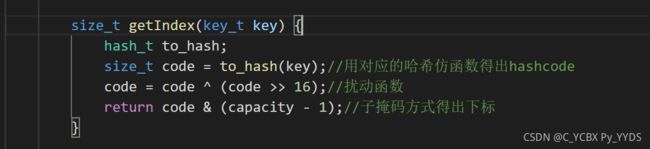
根据散列函数得到位置
C
static inline size_t getHashcode(key_t key) {
return key ^ (key >> 16);//这是32位数的扰动函数
}
static inline size_t getIndex(key_t key, size_t bucket_size) {//由于bucketsize一定是2的次方,所以size-1和key相与得到的就是下标
return getHashcode(key) & (bucket_size - 1);
}
C++
put方法
C
void put(HashMap *map, key_t key, val_t val) {
assert(map != NULL);
//判断是否需要扩容
if (map->size >= map->capacity * factor) resize(map);
putVal(key, val, map->buckets, &map->size, map->capacity);
}
static void putVal(key_t key, val_t val, Node **buckets, size_t *returnSize, size_t bucketSize) {
//获取位置
size_t index = getIndex(key, bucketSize);
Node *node = buckets[index];
if (node == NULL) {//插入位置为空
node = (Node *) malloc(sizeof(Node));
assert(node != NULL);
node->val = val;
node->key = key;
node->next = NULL;
buckets[index] = node;
(*returnSize)++; //哈希表内的元素增加
return;
}
//插入位置不为空,说明发生冲突,使用链地址法,遍历链表
while (node != NULL) {
//如果key相同就覆盖
if (node->key == key) {
node->val = val;
return;
}
node = node->next;
}
//当前的key不在链表中,则插入链表头部
Node *newNode = (Node *) malloc(sizeof(Node));
assert(newNode != NULL);
newNode->next = buckets[index];
buckets[index] = newNode;
(*returnSize)++; //哈希表内元素增加
}
C++

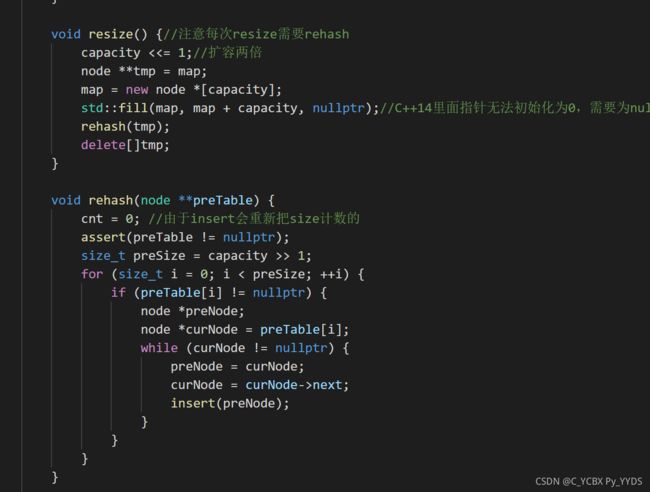
扩容方法
C
static void resize(HashMap *map) {
map->capacity <<= 1; //扩大两倍容量,相当于左移一位
Node **tmp = map->buckets; //存下之前的内存地址
map->buckets = (Node **) calloc(map->capacity, sizeof(Node *)); //重新分配
assert(map->buckets != NULL);
rehash(map, tmp);//重新哈希处理
free(tmp); //释放之前的内存
}
static void rehash(HashMap *map, Node **preTable) {//采取java1.7的方式进行rehash也就是最简单直接的直接重新哈希插入
size_t preCap = map->capacity / 2; //改变前的有效区域
for (size_t i = 0; i < preCap; i++) {
if (preTable[i] != NULL) {//判断对应的key是否需要重新换位置,如果对最新掩码多出来的1敏感则需要rehash
Node *preNode;
Node *curNode = preTable[i];
while (curNode != NULL) {
preNode = curNode;
curNode = curNode->next;
insert(map, preNode);
}
}
}
}
C++
get方法
C
val_t *get(HashMap *map, key_t key) {//前面的写好后,那么get就很好写了
int index = getIndex(key, map->capacity);
Node *node = map->buckets[index];
while (node != NULL) {
if (node->key == key) {
return &(node->val);
}
node = node->next;
}
return NULL;//没找到返回NULL指针
}
C++
C++标准中主要采用重载下标运算符的方式进行get。
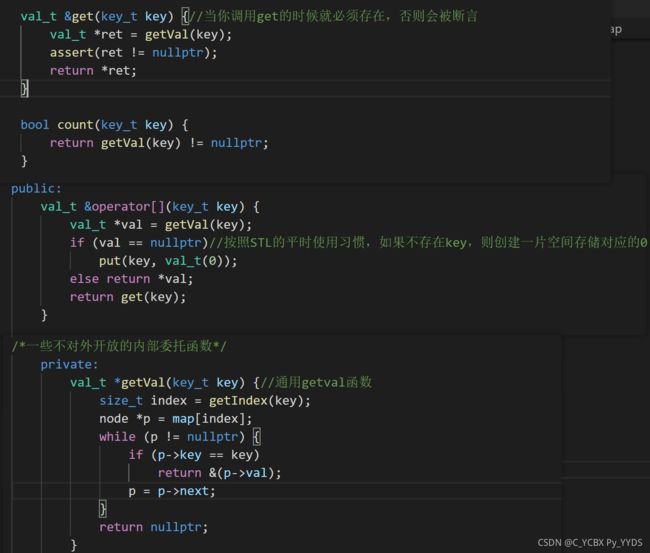
完整代码
C完整代码
C++完整代码
测试:LeetCode 1.两数之和
- 这效率在用C语言哈希表的方法里面应该是无敌的存在了。。。试了下比UT_HASH还要快一些☺

再看看之前写的比较烂的哈希表的效率

测试源码:
//
// Created by L_B__ on 2021/11/24.
//
//底层的表长都用2的次方,然后-1后可以得到低位掩码
//该设计理念急于java1.7的源代码,本来是想基于1.8的实现,
// 因为1.8巧妙太多,比如对rehash尽量能不动的就不动,再比如对于链比较长的结构直接转红黑树。可惜能力不能及
/**
* 简单说明:static修饰的函数为单文件的中间委托功能函数,不对外公开
* 简单的功能函数介绍:
* init()得到一个默认表长的哈希表
* put()插入键值,内部自动进行内存的申请
* get()得到key对应的val的地址,若不存在该键值对返回NULL
* insert()外界已经分配好node的内存和key&val对,进行哈希运算后直接插入即可
* destroy()把整个哈希表牵扯的所有内存释放
* **/
#include 总结
通过这次手撕比较规范的哈希表的收获:
- 更加深入的理解了哈希表的基本实现思想。
- 从LeetCode刷题无用的感觉到有用,比如时刻需要的链表增删操作。
- 有点遗憾,没能按照java1.8的思路再进一步优化哈希表。
看了很多大厂的面试题,现在对哈希表这块数据结构的考量是越来越严苛了,比如你如果走的 java 后端岗位,面试可能需要你回答 java HashMap 源码的相关实现部分,深挖原理,而不是死记硬背了,所以最好的学习方式就是学习源码,然后根据学到的思想自己实现一些功能。
参考:
[1]. 《数据结构与算法》
[2]. HashMap跟面试官扯了半个小时
[3]. hashCode 为什么乘以 31?