kafka面试连环问,你能撑到哪一问?
文章目录
- 前言
- 一、kafka消息发送的缓冲区是什么
- 二、生产者发送消息有几种方式?
- 三、消费者提交offset的方式有哪几种
- 四、消息丢失问题
- 五、重复消费问题
- 六、顺序消费问题
- 七、消息积压问题
- 总结
前言
本文总结了与kafka相关的面试问题,主要包括生产者发送消息的方式和消费者提交offset的几种方式以及消息丢失、重复消费等问题,供读者参考学习。
一、kafka消息发送的缓冲区是什么

1.kafka默认会创建⼀个消息缓冲区,用来存放要发送的消息,缓冲区是32m
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
2.kafka本地线程会去缓冲区中一次拉16k的数据,发送到broker
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
3.如果线程拉不到16k的数据,间隔10ms也会将已拉到的数据发到broker
props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
二、生产者发送消息有几种方式?
1.生产者的同步发送消息:在同步发送的前提下,生产者在获得集群返回的ack之前会⼀直阻塞。如果生产者发送消息没有收到ack,⽣产者会阻塞,阻塞到3s的时间,如果还没有收到消息, 会进⾏重试,重试的次数3次。
ack有3个配置:
1.ack = 0 :kafka-cluster不需要任何的broker收到消息,就⽴即返回ack给生产者,最容易丢消息的
2.ack=1(默认): 多副本之间的leader已经收到消息,并把消息写⼊到本地的log中,才 会返回ack给⽣产者,性能和安全性是最均衡的
3.ack=-1/all。里面有默认的配置min.insync.replicas=2(默认为1,推荐配置⼤于等于2), 此时就需要leader和⼀个follower同步完后,才会返回ack给生产者(此时集群中有2个 broker已完成数据的接收),这种⽅式最安全,但性能最差。
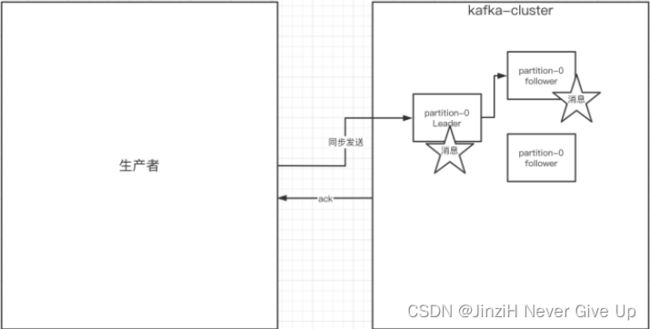
2.生产者的异步发送消息:生产者发送完消息后就可以执行之后的业务,broker在收到消息后异步调⽤⽣产者提供的callback回调⽅法。
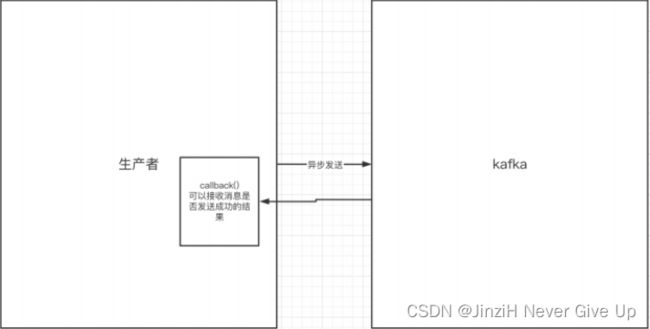
注意:使用异步发消息可能会出现消息丢失的情况,例如在异步发送时,生产者发送完消息后,由于网络问题,没有到达broker,这时候生产者就结束了,就会导致消息丢失
三、消费者提交offset的方式有哪几种
消费者无论是自动提交还是手动提交,都需要把所属的消费组+消费的某个主题+消费的某个分区及消费的偏移量,这样的信息提交到集群的_consumer_offsets主题里面。
1.自动提交:消费者poll消息下来以后就会自动提交offset,自动提交会丢消息。因为消费者在消费前提交offset,有可能提交完后还没消费时消费者挂了。
2.手动提交:需要把自动提交的配置改成false,分为手动同步提交和手动异步提交。
2.1. 手动同步提交 :在消费完消息后调用同步提交的方法,当集群返回ack前⼀直阻塞,返回ack后表示提交成功,执行之后的逻辑。
2.2. 手动异步提交 :在消息消费完后提交,不需要等到集群ack,直接执行之后的逻辑,可以设置⼀个回调方法,供集群调用。
⼀般使用同步提交,因为提交之后⼀般也没有什么逻辑代码了
四、消息丢失问题
什么情况下会出现消息丢失?
1.producer -> broker :由于网络问题,消息没有到达broker
2.leader->follower之间同步,集群环境下嘛,但可能你发送的消息后leader就挂了,这时挂掉的leader还没来得及把数据同步给别的follower,数据就自然就丢了
3.在自动提交offset的时候,消费者刚poll到消息,就提交了offset,还没来得及消费,就挂了,这时候这些消息就丢失了。
怎么防止消息丢失:
生产者:1)使用同步发送 2)把ack设成1或者all,并且设置同步的分区数>=2
消费者:把自动动提交改成手动提交
五、重复消费问题
出现原因:在防止消息丢失的方案中,如果生产者发送完消息后,因为网络抖动,没有收到ack,但实际 上broker已经收到了。 此时生产者会进行重试,于是broker就会收到多条相同的消息,而造成消费者的重复消费。
怎么解决:
1.生产者关闭重试:会造成丢消息(不建议)
2.消费者解决非幂等性消费问题,实现幂等性。 什么是幂等性:多次访问的结果是⼀样的。对于rest的请求(get(幂等)、post(非幂等)、put(幂等)、delete(幂等))
解决方案:
通过Redis做前置处理,数据库用唯一索引,最终保证来实现幂等性的
1.在处理之前,首先会去查Redis是否存在该Key,如果存在,则说明已经处理过了,直接丢掉
2.如果Redis没处理过,则继续往下处理,最终的逻辑是将处理过的数据插入到数据库上,再到最后把Key插入到Redis上
六、顺序消费问题
生产者:保证消息按顺序消费,且消息不丢失——使用同步的发送,ack设置成非0的值。
消费者:主题只能设置一个分区,消费组中只能有⼀个消费者
kafka的顺序消费使⽤场景不多,因为牺牲掉了性能,这不是kafka的强项,rocketmq在这⼀块有专门的功能已设计好。
七、消息积压问题
为什么会出现消息积压问题?
消息的消费者的消费速度远赶不上⽣产者的⽣产消息的速度,导致kafka中有⼤量的数据没有 被消费。随着没有被消费的数据堆积越多,消费者寻址的性能会越来越差,最后导致整个 kafka对外提供的服务的性能很差,从⽽造成其他服务也访问速度变慢,造成服务雪崩。
消息积压的解决方案是什么?
1.在这个消费者中,使用多线程,充分利用机器的性能进⾏消费消息。
2.通过业务的架构设计,提升业务层面消费的性能。
3.创建多个消费组,多个消费者,部署到其他机器上,⼀起消费,提⾼消费者的消费速度,但这里可能会重复消费,要做到消费者端的幂等性消费问题。
总结
文中提到的几个问题都是kafka中很常见的问题,作为kafka的使用者,对于这些问题应该要牢记于心。消息丢失、重复消费、顺序消费、消息积压问题都是实际中使用消息队列时可能遇到的问题,非常重要。