转自:https://blog.csdn.net/u011974639/article/details/79704043
关于Deformable Convolutional Networks的论文解读,共分为5个部分,本章是第四部分:
- [ ] Part1: 快速学习实现仿射变换
- [ ] Part2: Spatial Transfomer Networks论文解读
- [ ] Part3: TenosorFlow实现STN
- [x] Part4: Deformable Convolutional Networks论文解读
- [ ] Part5: TensorFlow实现Deformable ConvNets
本章解读Deformable ConvNets论文,看该模型是如何让卷积可变形,如何让模型支持端对端训练。
Deformable Convolutional Networks
Deformable Convolutional Networks
收录:ICCV2017(IEEE International Conference on Computer Vision)
原文地址:Deformable-ConvNets
代码:
- 官方-MXNet
- Keras
Abstract
CNN因为其固定的几何结构限制了模型几何变换能力。论文引入了可变卷积(Deformable Convolution)和可变ROI pooling(Deformable RoI pooling)两个新模块,提高模型的空间转换能力。这两种模块增加模型空间采样位置和从task上学习偏移能力。新的模块可很容易的替换现有的CNN模型中对应的部分,并支持端对端训练。大量实验验证了可变性卷积模型能够有效的应对复杂的视觉任务。
Introduction
视觉任务中存在的问题
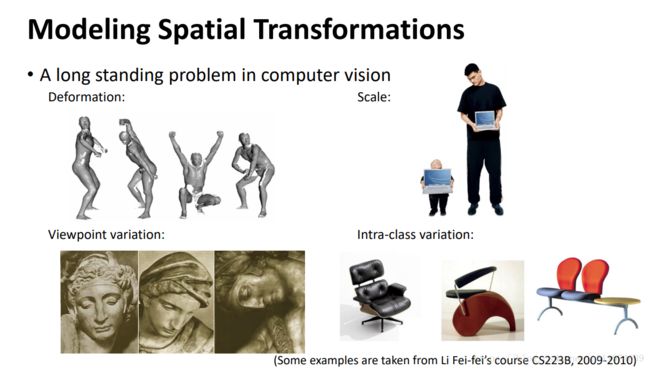
视觉识别中一个关键的挑战是如何适应物体的几何变体或目标尺度、姿态、观察点、部分变形的几何变换。如下:
针对这一问题,通常有两个办法:
- 一是构建有足够期望变化的训练数据集。这个通常是对数据做增强,例如仿射变换,放缩等。希望模型能够在多种变体数据上学习鲁棒性强的表征,但这是以计算消耗和模型复杂度为代价的。
- 二是使用变换不变的特征和算法。这有许多广泛使用的算法,例如SIFT(尺度不变特征变换),基于滑窗的目标检测等

上述的方法有两个缺点:
首先,对数据的几何变换是已知固定的,这样的先验应用于增强数据集上、设计特征和算法,会对未知几何变换的任务处理造成影响,因为没有正确的去对未知变换建模。
其次,手工设计的特征和算法难以或者不能应对复杂的变换,即使这些变换是已知的。
Motivation
近期,CNN在多个复杂视觉任务上获得了显著的提升。但是,CNN也存在上述的两个缺点。模型的几何变换能力大多来源于大量的数据增强、模型的表征能力和一个简单的手工特征(例如max-pooling应对小型平移变换)。
简而言之,CNN受限于模型内部固定的几何结构:卷积单元对输入固定的采样位置;池化层固定的下采样因子;RoI池化层将RoI分成固定数量的bin等,这缺乏处理几何变换的内部机制。
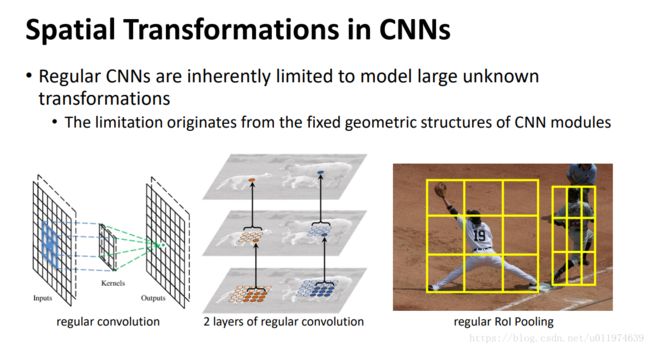
这会导致一些明显的问题。例如:CNN中同一层的所有激活单元的接受野是固定的,这不利于high-level层编码空间信息,因为不一样的位置可能会对应不同尺度或形态的目标。对于精确定位来说,自适应确定尺度和感受野尺度是理想的。此外,在目标检测上,许多模型依然依赖于基于特征提取的bbox,这对于non-rigid objects物体等是非最优的。
论文的贡献
在本文中引入两个新模块极大提高了CNN对于几何变换的建模能力:
- 第一个是
deformable convolution(可变形卷积)。这在标准卷积的常规采样网络位置上增加了一个2D偏移,这使得采样网格可以自由变形。如下图所示:
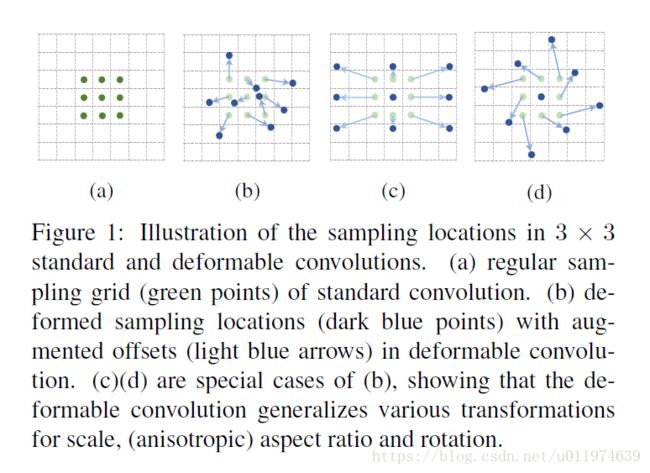
可通过附加卷积层从之前的feature上学习偏移量,这样变形以局部,密集和自适应的方式适应输入feature。
- 第二是
deformable RoI pooling(可变性RoI池化)。在先前的RoI池化的每个常规的bin上添加一个偏移。类似的,偏移也是从前面的feature和RoI上学习的,能够对不同形状的目标做自适应定位。
这两个模块都是轻量级,只增加了少量的计算和参数。并且能够轻易的替换现在CNN中对应的部分,支持端对端训练。deformable convolutional networks和STN(Part2)和可变形模块有同样的精神。都是具有内部转换参数和学习参数,都是纯粹的学习数据。deformable ConvNets相比的来讲,是更简单、有效,深度和端对端的训练。
Deformable Convolutional Networks
Deformable Convolution
2D的卷积由两部分组成:
- 在输入feature map XX上使用regular grid RR采样
- 对采样值加权ww求和
网格RR定义的是感受野尺寸和扩张率。例如:对于一个扩张率为1的3×33×3卷积核,采样的偏移量为
对于输出feature map yy上每个位置popo:
要想获得可变性卷积,可在regular grid RR上做手脚,论文是为其增加偏移量{Δpn|n=1,...,N}{Δpn|n=1,...,N},其中N=|R|N=|R|:
此时采样偏移为pn+Δpnpn+Δpn,我们想法子学习这个ΔpnΔpn就可以了。
Deformable ConvNets和STN对比
Deformable ConvNets关于可变性卷积示意图如下:
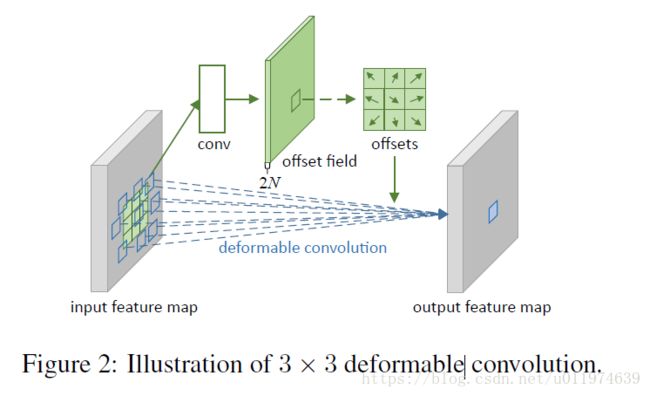
上图在input feature map上蓝色的虚线表示regular grid。
STN网络架构中的Spatial Transformer变换:
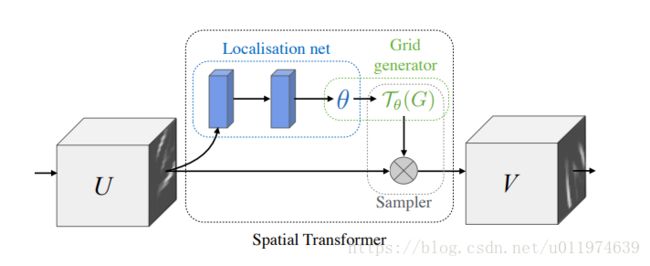
可以看到这和Deformable Convolution非常相似的,STN使用的是仿射变换,而Deformable ConvNets使用的是更泛化的偏移量。
在Part2中,我们详细分析过STN中Spatial Transformer的组成部分:
Localisation net,在输入特征映射上应用卷积或FC层,用于获取仿射矩阵,即各个θθ值。Grid generator,用于生成实际的Sampling grid坐标Sampler,实际对输入特征映射UU的采样
同样的Deformable ConvNets中关于deformable convolution的处理可分为以下部分:
- 对输入feature map原本使用一个卷积
conv得到下一层输入。现在使用另外一个offset conv卷积获取偏移量,offset conv卷积核大小和扩张率和conv相同,offset conv的输出为offset field offset field和输入特征映射相同空间分辨率,并且通道数为2N2N,对应着NN个2D的偏移量(x,y方向)- 通过双线性采样获取的最终的采样网格,配合
conv卷积核得到最终输出结果
对Deformable ConvNets的总结:
可以看到Deformable Convolution说白了是一个扩张率可学习的卷积,相比于STN学习一组仿射变换参数,Deformable学习卷积核中各个采样点的偏移量。与此相对的常规的扩张卷积是固定的偏移量。
Deformable Convolution 的反向传播
注意到在Deformable ConvNets中偏移量ΔpnΔpn常常不为整数,而在BP时需要可微求梯度的,故论文采用和Part2:STN(Spatial Transformer Network)一样的方法,使用双线性采样搞定:
G(·,·)G(·,·) 是双线性插值核函数,pp表示任意位置 p=po+pn+Δpnp=po+pn+Δpn,qq是feature map XX上所有位置的迭代。
注意GG是两维的,可以分成两个一维的核:
其中g(a,b)=max(0,1−|a−b|)g(a,b)=max(0,1−|a−b|),公式(3)可通过公式(4)做快速计算。
上述公式(3)(4)可能看的比较抽象,看看STN中使用双线性采样的表达式,再对比一下就很清晰了:
在STN中使用双线性采样核的表达式总结如下:
这其中的max(0,1−|xsi−m|)max(0,1−|ysi−n|)max(0,1−|xis−m|)max(0,1−|yis−n|)对应的就是G(q,p)G(q,p),VcVc对应的就是X(p)X(p)。 对于反向求梯度的公式,可参考Part2:STN。
Deformable RoI
所有基于侯选区域的目标检测办法都使用了RoI Pooling,这能够将任意大小的矩形区域转换为固定大小的特征。 给定特征映射XX和大小为w×hw×h的RoI,我们记RoI的左上角为p0p0,RoI pooling将RoI分为k×kk×k个bin,输出大小为k×kk×k的特征映射yy。对于序号为(i,j)(i,j)的bin:
和Deformable Convolution类似,对于RoI Pooling也是添加一个偏移量{Δpij|0≤i,j<k}{Δpij|0≤i,j
同样的,ΔpijΔpij会是非整数,故依旧是通过双线性采样来实现。
下图是Deformable RoI Pooling示意图:
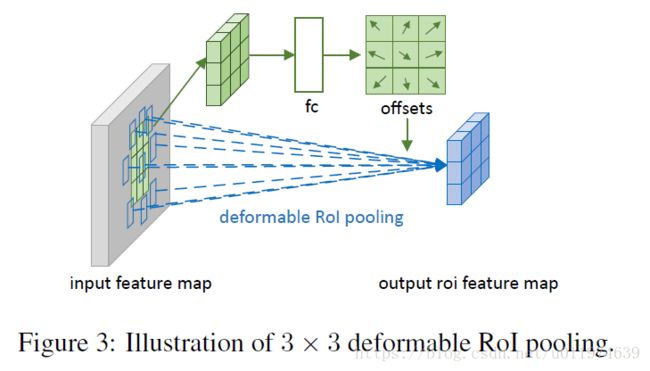
大概步骤如下:
- 首先,使用公式(5)的RoI Pooling生成池化后的特征映射。
- 在上述生成特征映射上,使用FC层生成
normalizedoffset Δpij^Δpij^。 - Δpij^Δpij^通过和RoI的宽和长逐元素相乘,即 Δpij=γ·Δpij^⋅(w,h)Δpij=γ·Δpij^⋅(w,h),变换生成 ΔpijΔpij。γγ是预设控制偏移大小的。经验设置为0.1。
Position-Sensitive(PS) RoI Pooling
如下图所示:
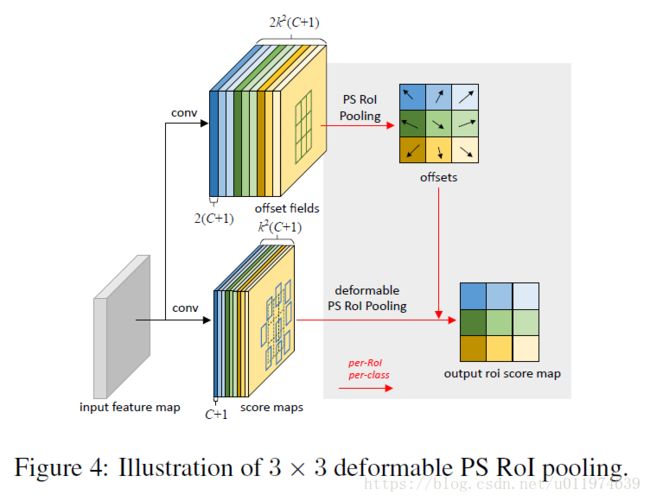
大概执行步骤:
- 将输入feature map做卷积转为k2k2个score map,因为有背景,故共有k2(C+1)k2(C+1)个特征图。(分类类别CC)
- 将这些特征图表示为{Xi,j}{Xi,j},其中(i,j)(i,j)表示bin的迭代。在这些特征图上做池化,第(i,j)(i,j)个bin是从位置Xi,jXi,j的特征图上通过sum操作获取到的。
简单的来讲,就是原本普通的特征映射XX换成了现在现在指定位置敏感的Xi,jXi,j。
同样的,对于获取偏移量的分支,也是将原本的特征图XX换成了Xi,jXi,j。对于offset的学习,按照全卷积的思想,使用一个卷积层全空间分辨率的offset fields。对于每个RoI,PS RoI pooling都应用在这样的offset field上获取normalized offset Δpn^Δpn^。
Deformable ConvNets
Deformable convolution 和RoI pooling和原本的版本具有相同的输入和输出,故能够直接替换CNN中原本对应的部分。在训练中,添加的用于学习offset的FC层或卷积层的权重设置为0。学习率设置为对应层的ββ 倍(默认β=1β=1,在Faster-RCNN中FC层的β=0.01β=0.01)。通过双线性插值的反向传播做训练。
为了将deformable ConvNets集成到先进的CNN架构中,注意到现有架构分成两个阶段:
- 一个深度全卷积网络在整个输入图片上生成特征图(特征提取层)
- 在生成特征图上做一个具体的任务
我们详细的讲解一下这两个阶段。
Deformable Convolution for Feature Extraction
论文采用了两个先进的特征提取架构:ResNet101和改进的Iception-ResNet,两个都是在ImageNet上跑过。原先的Inception-ResNet是为图片识别设计的,论文改进修复了其alignment 问题,改进后的版本称为Aligned-Inception-ResNet。
论文使用的改进版本的Aligned Xception:
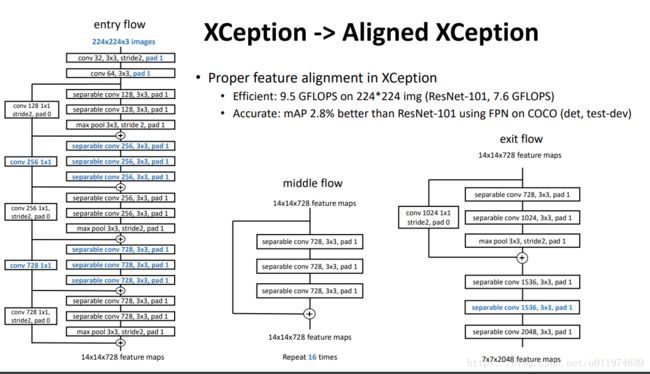
论文将两个网络的平均池化和FC层去掉,在最后添加了一个随机初始化的1×11×1卷积层将通道降维到1024。将最后一个卷积块的有效步幅从32pixel降到16pixel(步幅=HinputHoutputHinputHoutput),增加feature map的分辨率。为了补偿,在最后卷积块添加扩张率为2的扩张卷积。
Segmentation and Detection Networks
在上述特征层提取的feature map上建立一个网络用于完成具体的任务。我们将CC定义为任务分类类别数。
- DeepLab: 用于语义分割。在feature map上添加一个1×11×1卷积生成C+1C+1个maps用于表示每个像素分类结果,再接Softmax。
- Category-Aware RPN: 用于目标检测。将2分类卷积分类器换成了C+1C+1卷积分类器。
- Faster R-CNN: 用于目标检测。RPN分支添加在conv4 block的顶端。论文将RoI pooling直接接在后面,在RoI输出上接两个1024维的FC层,再接bbox回归和分类分支。和之前的网络相比,将10个层的conv5替换为2个FC层,会有轻微的精度下降,但是依旧是足够强大的baseline。
- R-FCN: R-FCN是先进的检测器。对应的每个RoI计算消耗可忽略不计。安装原先的实现,可将RoI换成PS RoI pooling。
改进前的目标检测框架:
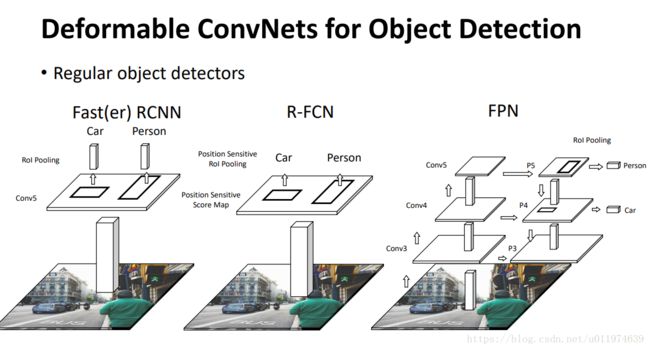
改进后的目标检测框架:
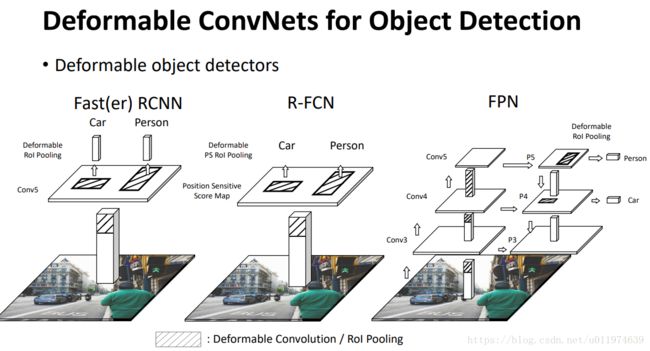
Understanding Deformable ConvNets
使用可变形卷积堆叠,示例如下:
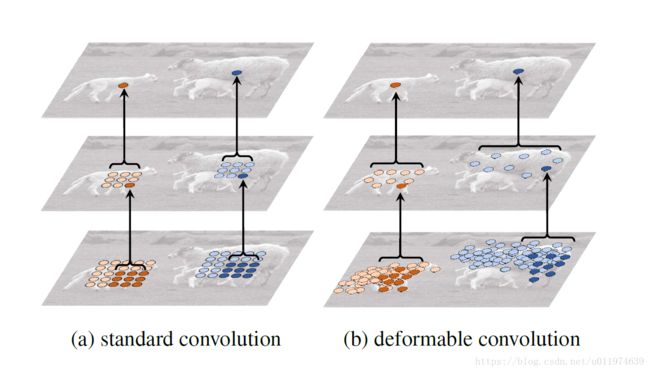
图左的标准卷积,所有采样位置和感受野是固定的。图右的可变形卷积依据目标的大小和形态自适应改变。
可变形卷积集中案例:

使用可变形RoI Pooling:

In Context of Related Works
讨论与其他工作不同之处。
Spatial Transform Network: STN工作是在深度网络中从数据上学习空间转换,使用全局参数变换包裹feature map。这样的参数学习起来很困难。STN证明了在小型形变上是有效的。
可变形卷积的offset learning 可以被考虑成STN中极其轻量级的空间变换。然而,可变形卷积不采用全局参数变换和特征变形,采样的是以局部和密集的方式管理特征映射。为了生成新的特征映射,再做加权求和操作。并且Deformable Convolution比STN更容易集成到现有的CNN架构中。
Active Convolution: 这项工作也是通过增强卷积中采样位置和学习偏移量,通过反向传播实现端对端。这个工作和deformable convolution有两处不同。一是:对于不同的空间位置共享同一偏移量。二是:offset在每个任务和每个训练中是静态模型参数。相对的deformable convolution中的offset是动态变换的。
Effective Receptive Field: 并不是所有的像素对于目标响应是相同的。在目标中间的像素贡献大点,有效感受野只占据理论感受野的一部分。理论上感受野大小随着卷积层的数量线性增加,但实际上是平方根线性增加,速度比预料要慢得多。这一发现说明了CNN顶层还是没有足够的接受野。侧面证明了扩张卷积为什么能够广泛应用于视觉任务。 可变形卷积可以自适应的接收野。
Atrous convolution: 扩张卷积能够在保持计算量和参数量的条件下扩展特征的感受野。Deformable Convolution可以看成是泛化的扩张卷积,我个人将Deformable convolution理解为学习不同方向上的扩张率。
Deformable Part Models (DPM): DPM和Deformable RoI类似,两者都是目标部件的空间变形。DPM是一个浅层模型,变形能力受限。可通过距离转换认为是特定的池化操作,它的推理算法可使用CNN完成。但它的训练不支持端对端,是启发的。相比之下,Deformable ConvNet支持端对端,并且当堆叠的更多,建模能力变的更强。
DeepID-Net: 引入了变形约束池化层,可认为是对目标检测变形的考虑。这项工作可实现起来很复杂。
Spatial manipulation in RoI pooling: 空间金字塔池化使用手工池化区域。
Transformation invariant features and their learning: 设计特征不变变换是具有极大影响的。例如SIFT、ORB。同样在CNN背景下,有工作学习CNN内在不变的表示。有工作专门制定特征的变换。但这些变换都是先验的,在许多现实场景下,变换是未知的。而deformable convolution可以在任务中学习到各种变换。
Experiment
Task
Semantic Segmentation: 在PASCAL VOC和CityScapes上做了测试。使用mIoU度量。训练期间,VOC的短边大小调整到360,CityScapes短边调整到1024。使用SGD优化器,8GPU每个batch为1。VOC和CityScapes上各跑30k和45k次迭代,在初始的2323迭代使用学习率为10−310−3,后1313迭代使用学习率为10−410−4。
Object Detection: 使用PASCAL VOC和COCO数据集。 使用标准的mAP度量。在训练和推理期间,将短边调整到600,使用SGD优化器,class-aware RPN每张图片上使用256个RoI,Faster R-CNN和R-FCN使用256和128个。RoI Pooling使用7×77×7bins。在VOC和COCO上训练迭代了30K和240K次,学习率依旧是在初始的2323迭代使用学习率为10−310−3,后1313迭代使用学习率为10−410−4。
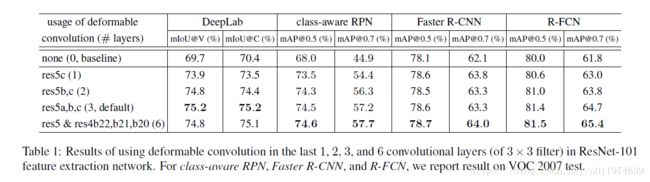
Evaluation of Deformable Convolution
Table 1评估了deformable convolution的影响,使用ResNet101做特征提取层。使用deformable convolution越多,精度稳步上升。对于DeepLab和class-ware RPN使用3个deformable convolution改进达到了饱和。
为了更好明白deformable convolution的工作机理,论文定义了effective dilation度量有效滤波器。这是滤波器中所有相邻采样位置之间距离的平均值,用于测量滤波器的感受野。
论文依据GT bbox和滤波器中心位置,将可变形卷积分为4类:small, medium, large, and background。下表显示了有效扩张值的统计数据:
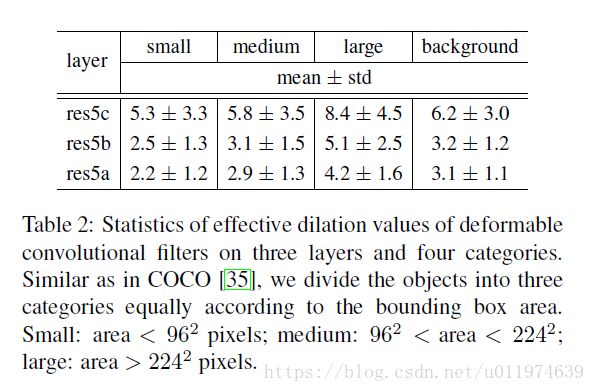
- 可变形卷积的接受野和目标大小相关,这表明形变是从内容上学习到的
- background目标的大小在medium和large之间,表明需要较大接收野来识别背景区域。
模型的ResNet在后三个卷积使用扩张率为2的扩张卷积,论文进一步尝试了4,6,8,结果如下:
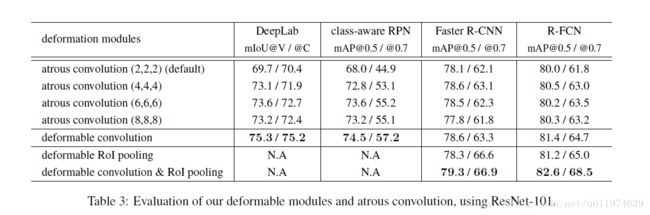
这表明:
- 精度随着扩张率提升而提升,这表明了接收野小的问题。
- 不同任务的最佳扩张率不同,例如DeepLab为6, Faster R-CNN为4
- deformable convolution具有最佳的精度
Evaluation of Deformable RoI Pooling
在COCO上的结果如下:
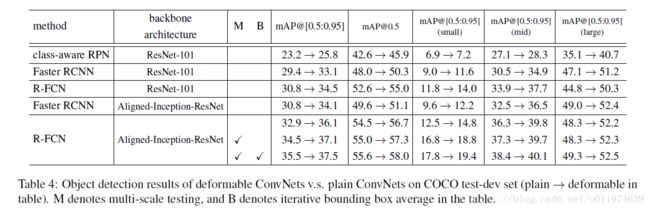
可以看到加入deformable的效果都有所提升。
Model Complexity and Runtime
模型加入deformable convolution的模型复杂度和运行时间:
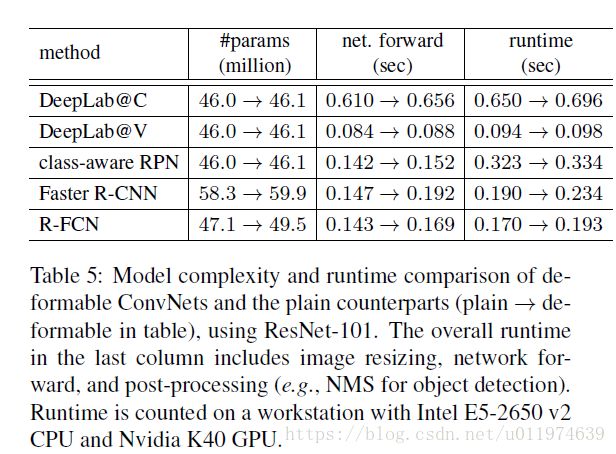
在参数和计算上增加的开销较小,这表明性能改进来自对几何变换建模的能力。
参考资料
Jifeng Dai-Deformable Convolutional Networks-MSRA COCO Detection & Segmentation Challenge 2017 Entry