spark 算子 详解
参考文档:Spark算子详解及案例分析(分类助记) - 云+社区 - 腾讯云
1、combineByKey 。作为spark 的核心算子之一,有必要详细了解。reduceByKey 和groupByKey 等健值对算子底层都实现该算子。(1.6.0版更新为combineByKeyWithClassTag)
combineByKey 源码定义:
def combineByKey[C](createCombiner: (V) => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
def combineByKey[C](createCombiner: (V) => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitions: Int): RDD[(K, C)]
def combineByKey[C](createCombiner: (V) => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null): RDD[(K, C)]createCombine: 对每个分区中每个key中value中的第一个值,进行处理(可以理解为,分区内部进行按Key分组,每个Key的第一个value进行预处理)预处理逻辑。
mergeValue:分区内部进行聚合,相同的Key的value进行局部运算,区间内部聚合逻辑。
mergeCombiners:此阶段发生shuffer,对不同区间局部运算后的结果再做运算。分区之间聚合逻辑。
测试样例:
val a = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
val b = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)
val c = b.zip(a)
val d = c.combineByKey(List(_), (x:List[String], y:String) => y :: x, (x:List[String], y:List[String]) => x ::: y)
d.collect
res16: Array[(Int, List[String])] = Array((1,List(cat, dog, turkey)), (2,List(gnu, rabbit, salmon, bee, bear, wolf)))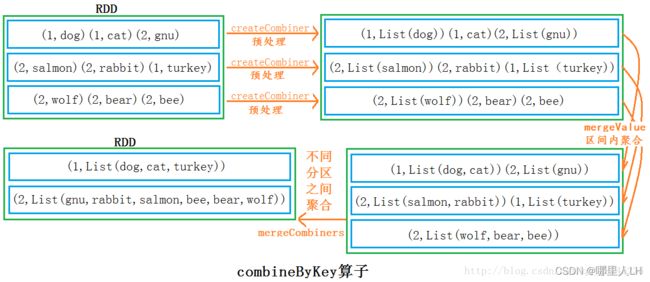
2、aggregate:允许用户对RDD使用两个不同的reduce函数,第一个reduce函数对各个分区内的数据聚集,每个分区得到一个结果。第二个reduce函数对每个分区的结果进行聚集,最终得到一个总的结果。aggregate相当于对RDD内的元素数据归并聚集,且这种聚集是可以并行的。而fold与reduced的聚集是串行的。
aggregate(n) 这里的n会被每次reduce函数用到。
https://www.cnblogs.com/chorm590/p/spark_201904201159.html
val z = sc.parallelize(List(1,2,3,4,5,6), 2)
// lets first print out the contents of the RDD with partition labels
def myfunc(index: Int, iter: Iterator[(Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
z.mapPartitionsWithIndex(myfunc).collect
res28: Array[String] = Array([partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3], [partID:1, val: 4], [partID:1, val: 5], [partID:1, val: 6])
z.aggregate(0)(math.max(_, _), _ + _)
res40: Int = 93、map,mapPartitions,mapPartitionsWithIndex
相同点分析
三个函数的共同点,都是Transformation算子。惰性的算子。
不同点分析
map函数是一条数据一条数据的处理,也就是,map的输入参数中要包含一条数据以及其他你需要传的参数。
mapPartitions函数是一个partition数据一起处理,也即是说,mapPartitions函数的输入是一个partition的所有数据构成的“迭代器”,然后函数里面可以一条一条的处理,在把所有结果,按迭代器输出。也可以结合yield使用效果更优。
mapPartitionsWithIndex函数,其实和mapPartitions函数区别不大,因为mapPartitions背后调的就是mapPartitionsWithIndex函数,只是一个参数被close了。mapPartitionsWithIndex的函数可以或得partition索引号;
参考文档:Spark的map,mapPartitions,mapPartitionsWithIndex详解_QQ1131221088的博客-CSDN博客