C++多线程编程笔记
我觉得不错的博文:
https://blog.csdn.net/weixin_42712593/article/details/122220376?spm=1001.2014.3001.5501
目录
- 1.关于进程、线程、协程的理论知识
-
- 1.1 定义
- 1.2 关系
- 1.3 补充
- 2.C++线程的公共成员函数
-
- join()
- get_id()
- detach()
- joinable()
- 静态函数 hardware_concurrency()
- Lambda表达式(多线程实现)
-
- ①关于Lambda表达式的知识
- ②多线程实现
- 3.关于互斥量和异步线程
1.关于进程、线程、协程的理论知识
1.1 定义
-
进程的定义:进程,直观点说,就是保存在硬盘上的程序运行以后,会在内存空间里形成一个独立的内存体,这个内存体有自己独立的地址空间,有自己的堆,上级挂靠单位是操作系统。操作系统会以进程为单位,分配系统资源(CPU时间片、内存等资源),进程是资源分配的最小单位。
-
线程的定义:线程,有时被称为轻量级进程,是操作系统调度(CPU调度)执行的最小单位。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程ID,当前指令指针PC,寄存器和堆栈组成。而进程由内存空间(代码,数据,进程空间,打开的文件)和一个或多个线程组成。
-
协程的定义:是一种比线程更加轻量级的存在,协程不是被操作系统内核所管理,而完全是由程序所控制。这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。协程在子程序内部是可中断的,然后转而执行别的子程序,在适当的时候再返回来接着执行。
1.2 关系
-
进程具有的特征:
①动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的;
②并发性:任何进程都可以同其他进行一起并发执行;
③独立性:进程是系统进行资源分配和调度的一个独立单位;
④结构性:进程由程序,数据和进程控制块三部分组成。 -
进程与线程的区别:
①线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位。
②一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线。
③进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段,数据集,堆等)及一些进程级的资源(如打开文件和信号等),某进程内的线程在其他进程不可见。
④多进程的程序要比多线程的程序健壮,但多进程进行切换时要比多线程切换效率要差一些。 -
进程与线程的联系:
①一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
②资源分配给进程,同一进程的所有线程共享该进程的所有资源。
③处理机分给线程,即真正在处理机上运行的是线程。
④线程在执行过程中,需要协作同步,不同进程的线程间要利用消息通信的办法实现同步。
关于进程和线程的举例:
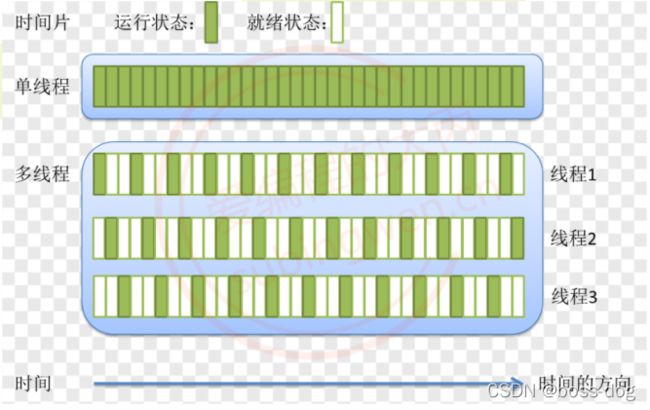
假如一个双向多车道的道路,我们把整条道路看成是一个“进程”的话,那么由中间白色虚线分隔开来的各个车道就是进程中的各个“线程”了。这些线程(车道)共享了进程(道路)的公共资源(土地资源)。这些线程(车道)必须依赖于进程(道路),也就是说,线程不能脱离于进程而存在(就像离开了道路,车道也就没有意义了)。这些线程(车道)之间可以并发执行(各个车道你走你的,我走我的),也可以互相同步(某些车道在交通灯亮时禁止继续前行或转弯,必须等待其它车道的车辆通行完毕)。这些线程(车道)之间依靠代码逻辑(交通灯)来控制运行,一旦代码逻辑控制有误(死锁,多个线程同时竞争唯一资源),那么线程将陷入混乱,无序之中。这些线程(车道)之间谁先运行是未知的,只有在线程刚好被分配到CPU时间片(交通灯变化)的那一刻才能知道。
1.3 补充
-
CPU 的调度和切换:线程的上下文切换比进程要快的多
上下文切换:进程 / 线程分时复用 CPU 时间片,在切换之前会将上一个任务的状态进行保存,下次切换回这个任务的时候,加载这个状态继续运行,任务从保存到再次加载这个过程就是一次上下文切换。 -
线程更加廉价,启动速度更快,退出也快,对系统资源的冲击小。
-
在处理多任务程序的时候使用多线程比使用多进程要更有优势,但是线程并不是越多越好,如何控制线程的个数?
①文件 IO 操作:文件 IO 对 CPU 是使用率不高,因此可以分时复用 CPU 时间片,线程的个数 = 2 * CPU 核心数 (效率最高)
②处理复杂的算法 (主要是 CPU 进行运算,压力大),线程的个数 = CPU 的核心数 (效率最高)
2.C++线程的公共成员函数
join()
- join():将子线程加入到主线程中。
join的作用是:主线程会等待/阻塞, 直到子线程执行结束,即遇到th.join(),主线程就卡住了,不会往下执行。
函数原型如下:
void join();
join() 字面意思是连接一个线程,意味着主动地等待线程的终止(线程阻塞)。在某个线程中通过子线程对象调用 join() 函数,调用这个函数的线程被阻塞,但是子线程对象中的任务函数会继续执行,当任务执行完毕之后 join() 会清理当前子线程中的相关资源然后返回,同时,调用该函数的线程解除阻塞继续向下执行。
一定要搞清楚这个函数阻塞的是哪一个线程,函数在哪个线程中被执行,那么函数就阻塞哪个线程。
如果要阻塞主线程的执行,只需要在主线程中通过子线程对象调用这个方法即可,当调用这个方法的子线程对象中的任务函数执行完毕之后,主线程的阻塞也就随之解除了。
举例一:无参函数
#include 输出:

举例二:有参函数
#include 输出:
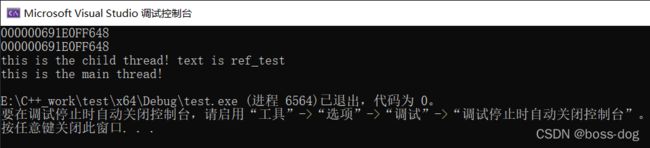
 举例三:有参函数,传入引用
举例三:有参函数,传入引用
#include 输出:
get_id()
- 应用程序启动之后默认只有一个线程,这个线程一般称之为主线程或父线程,通过线程类创建出的线程一般称之为子线程,每个被创建出的线程实例都对应一个线程 ID,这个 ID 是唯一的,可以通过这个 ID 来区分和识别各个已经存在的线程实例,这个获取线程 ID 的函数叫做 get_id()。
函数原型如下:
std::thread::id get_id() const noexcept;
#include 输出:

detach()
detach()函数的作用是进行线程分离,分离主线程和创建出的子线程。在线程分离之后,主线程退出也会一并销毁创建出的所有子线程,在主线程退出之前,它可以脱离主线程继续独立的运行,任务执行完毕之后,这个子线程会自动释放自己占用的系统资源。
函数原型如下:
void detach();
#include 输出:可以发现,使用detach()后,线程分离函数 detach () 不会阻塞线程,子线程和主线程分离之后,在主线程中就不能再对这个子线程做任何控制了,比如:无法通过 join () 阻塞主线程等待子线程中的任务执行完毕,或者调用 get_id () 获取子线程的线程 ID。

joinable()
joinable()函数用于判断主线程和子线程是否处理关联(连接)状态,一般情况下,二者之间的关系处于关联状态,该函数返回一个布尔类型:
返回值为true:主线程和子线程之间有关联(连接)关系
返回值为false:主线程和子线程之间没有关联(连接)关系
函数原型如下:
bool joinable() const noexcept;
#include 输出:
before starting, joinable: 0
after starting, joinable: 1
after joining, joinable: 0
after starting, joinable: 1
after detaching, joinable: 0
静态函数 hardware_concurrency()
- thread 线程类还提供了一个静态方法,用于获取当前计算机的 CPU 核心数,根据这个结果在程序中创建出数量相等的线程,每个线程独自占有一个CPU核心,这些线程就不用分时复用CPU时间片,此时程序的并发效率是最高的。
函数原型如下:
static unsigned hardware_concurrency() noexcept;
#include 输出:

Lambda表达式(多线程实现)
①关于Lambda表达式的知识
定义:Lambda表达式,又称匿名函数,假如在编程时,需要有一个函数只会被复用一次,其他地方再也不会调用时,lambda表达式就很实用。
Lambda表达式的基本语法如下:
[ 捕获列表 ] ( 参数列表 ) -> 返回类型 { 函数体 }
举例:
正常的函数是这样:
int Foo(int a, int b)
{
return a+b;
}
则在主函数中,匿名函数就可以这样写
int main()
{
auto c = [ ] ( int a, int b ) -> int
{
return a+b;
}
}
②多线程实现
举例:
#include 输出:

3.关于互斥量和异步线程
这个大佬写的很详细,C++多线程基础教程
lock():上锁
unlock():解锁
lock_guard()、unique_lock():能避免忘记解锁这种问题,声明一个局部的lock_guard对象,在其构造函数中进行加锁,在其析构函数中进行解锁。最终的结果就是:创建即加锁,作用域结束自动解锁。从而使用lock_guard()就可以替代lock()与unlock()。