【C深剖剖析】深入理解指针
- 一、指针
- 二、指针和数组
- 三、多维数组和多级指针
- 四、数组参数和指针参数
一、指针
我们先通过下面的问题带领我们深入理解指针
1.理解左值和右值
大家如何看待a变量?
int main()
{
int a = 0;
a = 10; //1)
int b = a; //2)
return 0;
}
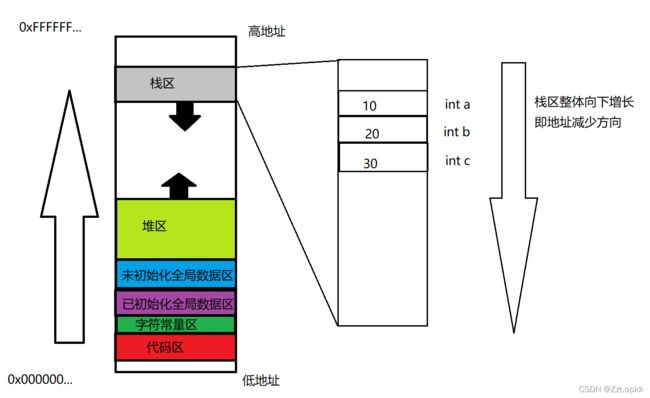
我们知道定义变量,本质是根据数据的类型在内存中开辟空间,有了空间,就必须要地址来标识空间,来方便CPU寻址。然后我们可以把数据放在该空间中,使用变量具有空间和内容这两个概念。
结论: 同样的一个a变量,在不同的场景中,它本身的含义是不同的,在等号的左边含义是空间,右边是内容。
2.指针和指针变量
-
我们知道指针就是地址,那么地址的本质是什么呢?没错!就是数据,这样它就可以保存在变量空间中了。
-
指针变量是保存指针(地址)数据的变量。
-
指针 和 指针变量又有何不同?我们口语中的"定义一个指针"究竟是什么意思?严格意义上,指针和指针变量是不同的,指针就是地址值,而指针变量是C中的变量,要在特定区域开辟空间,要用来保存 地址数据,还可以被取地址,但是,在我们交流过程中又经常把二者混为一谈,所以导致这个现象,但是我们以后应该如何认为呢?我们应该分开理解,但应该关联使用。
3.指针的产生
-
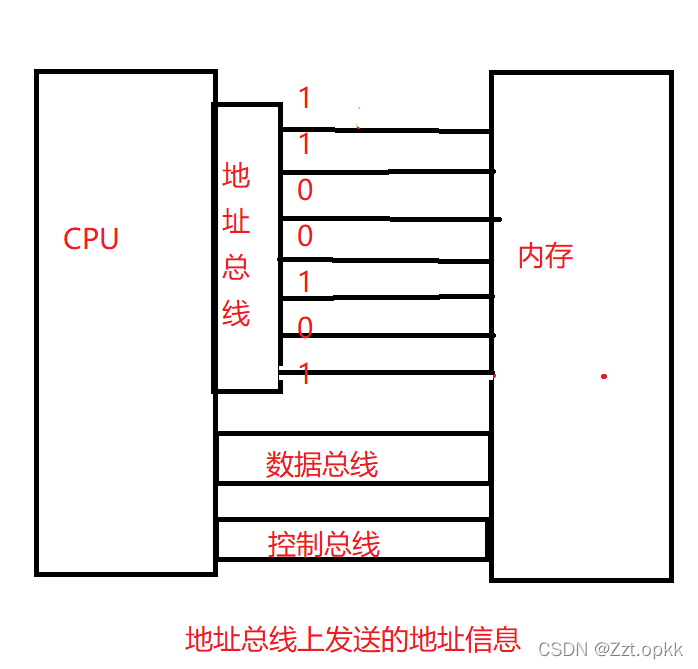
为了提高我们的寻址效率,出现了指针(这个是原因之一),在计算机中我们是通过CPU来寻址,在32位机器下寻址单位是一个字节,也就是8个比特位。
-
如何理解编址?首先,计算机中有很多硬件单元,而硬件单元是要相互协同工作的,协同就是要能够进行数据传递。但是硬件与硬件之间是互相独立的,
-
那么如何通信呢?答案很简单,用"线"连起来,而CPU和内存之间也是有大量的数据交互的,所以,两者必须也用线连起来,CPU访问内存中的某个字节空间,必须知道这个字节空间在内存的什么位置,而因为内存中字节很多,所以需要给内存进行编址,计算机中的编址,并不是把每个字节的地址记录下来,而是通过硬件设计完成的。
-
我们可以简单理解,32位机器有32根地址总线,每根线只有两态,产生低电平和高电平,表示0,1【电脉冲有无】,那么一根线,就能表示2中含义,2根线就能表示4中含义,依次类推。32根地址线,就能表示2^32中含义,每一种含义都代表一个地址。
-
地址信息被下达给内存,在内存内部,就可以找到改地址对应的数据,将数据在通过数据总线传入CPU内寄存器。
4.指针的内存布局
如何画出指针指向图,整形有4个字节,有四个地址,那么取地址是取哪一个地址?那么如何全部访问这4个字节呢?
int main()
{
int a = 10;
int* p = &a;
return 0;
}

5.指针解引用
int main()
{
int a = 10;
int* p = &a;
int b = *p;
*p = 20;
return 0;
}
*p完整理解是,取出p中的地址,访问该地址指向的内存单元(空间或者内容)(其实通过指针变量访问,本质是一种间接 寻址的方式)
口诀:对指针解引用,就是指针指向的目标。所以*p,就是a
二、指针和数组
1.数组的内存布局
首先我们先看一下下面的代码及其运行结果
#include第一次结果:
0113FB7C
0113FB70
0113FB64
第二次
00F3FE58
00F3FE4C
00F3FE40
第一:我们观察到一二次结果不同,这是由于栈随机化,这是一种保护机制。
第二:先定义的变量,地址是比较大的,后续依次减小,这是因为a,b,c都在main函数中定义,也就是在栈上开辟的临时变量。而a先定义意味着,a先开辟空间,那么a就先入栈,所以a 的地址最高,其他类似。
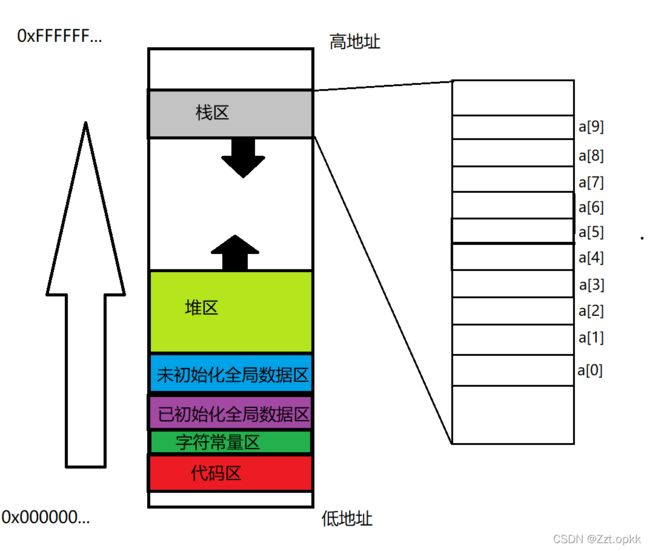
我们来康康数组元素的地址
#define N 10
int main()
{
int a[N] = { 0 };
for (int i = 0; i < N; i++)
{
printf("&a[%d]: %p\n", i, &a[i]);
}
return 0;
}
运行结果
&a[0]: 001EFBAC
&a[1]: 001EFBB0
&a[2]: 001EFBB4
&a[3]: 001EFBB8
&a[4]: 001EFBBC
&a[5]: 001EFBC0
&a[6]: 001EFBC4
&a[7]: 001EFBC8
&a[8]: 001EFBCC
&a[9]: 001EFBD0
我们发现,数组的地址排布是:&a[0] < &a[1] < &a[2] < … < &a[9],因为该数组在main函数中定义,那么也同样在栈上开辟空间,数组有多个元素,那么肯定是a[0]先被开辟空间,那么肯定&a[0]地址最大啊,可是事实上并非如此!这是因为数组是整体申请空间的,然后将地址最低的空间,作为a[0]元素,依次类推!
2.理解&a[0] &a的区别
int main()
{
char* c = NULL;
short* s = NULL;
int* i = NULL;
double* d = NULL;
printf("%p\n", c);
printf("%p\n", c + 1);
printf("%p\n", s);
printf("%p\n", s + 1);
printf("%p\n", i);
printf("%p\n", i + 1);
printf("%p\n", d);
printf("%p\n", d + 1);
return 0;
}
运行结果:
00000000
00000001
00000000
00000002
00000000
00000004
00000000
00000008
结论: 对指针+1,本质加上其所指向类型的大小。(如果发生类型转化呢?下面我们来研究)
int main()
{
int a = 0x00;
char* p = (char*)&a;
printf("%p\n", p);
printf("%p\n", p + 1);
return 0;
}
运行结果:
0058F8A0
0058F8A1
结论:对发生类型转化指针+1,本质还是加上其所指向类型的大小
3.数组名做左值和右值的区别
#define N 10
int main()
{
int arr[N] = { 0 };
arr = { 1,2,3,4,5 };
return 0;
}
能够充当左值的,必须是有空间且可被修改的,arr不可以整体使用,只能按照元素为单位进行使用
4.以指针的形式访问和以数组的形式访问
#define N 10
int main()
{
char *str = "abcdef"; //str指针变量在栈上保存,“abcdef”在字符常量区,不可被修改
char arr[] = "abcdef"; //整个数组都在栈上保存,可以被修改,这部分可以局部测试一下
1. 以指针的形式访问指针和以下标的形式访问指针
printf("以指针的形式访问指针和以下标的形式访问指针\n");
int len = strlen(str);
for (int i = 0; i < len; i++)
{
printf("%c\t", *(str + i));
printf("%c \n", str[i]);
}
printf("\n");
//2. 以指针的形式访问数组和以下标的形式访问数组
printf("以指针的形式访问数组和以下标的形式访问数组\n");
len = strlen(arr);
for (int i = 0; i < len; i++)
{
printf("%c\t", *(arr + i));
printf("%c \n", arr[i]);
}
printf("\n");
return 0;
}
arr是数组名(也就是首元素地址),我们计算机并没有为它开辟空间来存放它,而数组名是一个字面常量(不可以被修改),在我们通过指针或者下标访问时,是通过指针找到该地址然后加其对应索引找到该元素,而str是一个变量,里面是该字符串首元素地址,因为变量是可以修改,所以我们通过地址+索引算出对应元素地址,然后直接访问该地址找到该元素。
结论: 指针和数组指向或者表示一块空间的时候,访问方式是可以互通的,具有相似性。但是具有相似性,不代表是一个东西或者具有相关性
5.C为何要这样设计?
我们初步阅读一下下面代码
#define N 10
void InitArr(int* arr, int n)
{
for (int i = 0; i < n; i++)
{
*(arr + i) = i; //在这里只能以指针的形式访问
}
}
int main()
{
int arr[N];
InitArr(arr, N);
for (int i = 0; i < N; i++)
{
printf("%d\n", arr[i]); //以数组的形式访问 }
system("pause");
return 0;
}
}
这里两种写法都行,函数传参是要发生降维的,降维成指针。(这是因为如果我们不降维,就会把整个数组拷贝一份浪费了空间,如果是指针就会提高效率,节省空间)arr在main里面是数组,传入InitArr函数之后,就成了数组首元素的指针变量。
结论: 上面代码其实没有什么问题,不过,不知道大家发现没有,如果没有将指针和数组元素访问打通,那么在C中(面向过程) 如果有大量的函数调用且有大量数组传参,会要求程序员进行各种访问习惯的变化。只要是要求人做的,那么就有提升代码 出错的概率和调试的难度。所以干脆,C将指针和数组的访问方式打通,让程序员在函数内,也好像使用数组那样进行元素访问,本质值减少了编程难度!
6.a 和 &a的区别
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);
printf("%d %d\n", *(a + 1), *(ptr - 1)); ;
return 0;
}
结论: &a叫做数组的地址,a做右值叫做数组首元素的地址,本质是类型不同,进而进行±计算步长不同
int main()
{
char a[5] = { 'A', 'B', 'C', 'D' };
char(*p3)[5] = &a; //ok,因为类型匹配
char(*p4)[5] = a; //no,类型不匹配
//编译器报错 warning C4047:“初始化”:“char (*)[5]”与“char *”的间接级别不同
return 0;
}
结论: 我们指针数组和数组指针来验证了我们的想法,一般只有在 &或者sizeof() 中表识的是整个数值,其余情况下是首元素地址。
那数值元素个数是不是数值类型的一部分呢?
int main()
{
char a[5] = { 'A', 'B', 'C', 'D' };
char(*p3)[3] = &a; // warning C4048: “char (*)[3]”和“char (*)[5]”数组的下标不同
char(*p4)[3] = a; // warning C4047: “初始化”:“char (*)[3]”与“char *”的间接级别不同
return 0;
}
结论: 通过报错结果,我们很容易知道数组元素个数,也是数组类型的一部分
7.地址的强制转换
int main()
{
int a = 97;
char* p = (char*)&a;
printf("%d\n", a); //97
printf("%c\n", (char)a); //a
printf("%d\n", *(p+1)); //98
return 0;
}
结论: 强制类型转化本质是改变我们看待事物的方式,本身这个内容没有发生任何改变。
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}* p = (struct Test*)0x100000;//大小为20个字节,20(十进制)->0x14(十六进制)
int main()
{
printf("%p\n", p + 0x1); //指针加1,实际上是加上其类型的大小,即加0x14,结果为0x100014
printf("%p\n", (unsigned long)p + 0x1); //强制类型转化为无符号长整形,已经不是指针,直接计算0x100001
printf("%p\n", (unsigned int*)p + 0x1); //强转为无符号整形指针,加其类型大小4,0x1000004
return 0;
}
三、多维数组和多级指针
1.二维数组
int main()
{
char a[3][4] = { 0 };
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 4; j++)
{
printf("a[%d][%d] : %p\n", i, j, &a[i][j]);
}
}
return 0;
}
显示结果:
a[0][0] : 006FFCD4
a[0][1] : 006FFCD5
a[0][2] : 006FFCD6
a[0][3] : 006FFCD7
a[1][0] : 006FFCD8
a[1][1] : 006FFCD9
a[1][2] : 006FFCDA
a[1][3] : 006FFCDB
a[2][0] : 006FFCDC
a[2][1] : 006FFCDD
a[2][2] : 006FFCDE
a[2][3] : 006FFCDF
结论: 二维数组在内存地址空间排布上,也是线性连续且递增的。
2.二维数组的空间布局

**结论:**数组是据有相同类型元素的集合,那么数组也可以保存数组,我们可以理解所有的数组全都是一维数组,拿二维数组来解释,其内部元素是一维数组,那么内部一维数组是在内存中布局是“线性连续且递增”的,多个该一维数组构成另一个“一维数组”,那么整体便也是线性连续且递增的。
3.加强理解
int main()
{
int a[3][4] = { 0 };
printf("%d\n", sizeof(a)); //48是整个数组大小为3*4*4
printf("%d\n",sizeof(a[0][0]));//4 是第一个元素的大小为1*4
printf("%d\n",sizeof(a[0])); //16是类型为int[4]的一维数组的大小为4*4
printf("%d\n",sizeof(a[0]+1)); //4数组名是首元素地址,第一个元素是数组int[4],数组名加1也就是第二个int(a[0][1])的地址
printf("%d\n",sizeof(*(a[0]+1)));//4和上面一样只不过是找到其内容,类型为int还是4
printf("%d\n",sizeof(a+1)); //4第二个数组的地址
printf("%d\n",sizeof(*(a+1))); //16本身类型为int[ 1]的一维数组,解引用后是个int[4]的数组4*4
printf("%d\n",sizeof(&a[0]+1)); //4第二个数组的地址
printf("%d\n",sizeof(*(&a[0]+1))); //16同上和*(a+1)一样只不过这个访问方式是数组形式
printf("%d\n",sizeof(*a)); //16只要不是单独使用数组名,那么它就是一个一维数组,即4*4
printf("%d\n",sizeof(a[3]));//16虽然越界访问了,但是其类型还是个一维数组,即4*4
return 0;
}
4.**二级指针
int main()
{
int a = 10;
int* p = &a;
int** pp = &p;
p = 100;
*p = 100;
pp = 100;
*pp = 100;
**pp = 100;
return 0;
}

四、数组参数和指针参数
1.一维数组传参
void show(int a[10])
{
printf("show: %d\n", sizeof(a));
}
int main()
{
int a[10];
printf("main: %d\n", sizeof(a));
show(a);
return 0;
}
显示结果:
main: 40
show: 4
通过结果我们可以找到数组传参会发生降维的,降维成指向其内部元素类型的指针。并且形成了临时变量的拷贝。
2.一级指针传参
函数调用,指针作为参数,要不要发生拷贝?
void test(char* p)
{
printf("test: &p = %p\n", &p);
}
int main()
{
char* p = "hello world";
printf("main: &p = %p\n", &p);
test(p);
return 0;
}
显示结果:
main: &p = 0053F9A0
test: &p = 0053F8CC
结论是需要,因为指针变量,也是变量,在传参上,它也必须符合变量的要求,进行临时拷贝
3 .二维数组参数和二级指针参数
二维数组传参,要不要发生降维?
void show(char a[3][4])
{
printf("show: %d\n", sizeof(a));
}
int main()
{
char a[3][4] = { 0 };
printf("main: %d\n", sizeof(a));
show(a);
return 0;
}
显示结果:
main: 12
show: 4
可以发现是发生了降维,对于二维数组内部“元素”是一维数组!那么降维成指向一维数组的指针char(*)[4]