面经-腾讯前端开发工程师
<–经历的折磨–>
目前结果还不知道、做个记录、也不是非得走前端、长路漫漫、学习作伴
技术并非考的技术而是考你对待事物的态度、每一份付出总归有点滴回报
本文有很多不足之处,欢迎指出


==============================================================================
<–JS–>
单线程解释性语言
作用域:
what: 当函数执行时,会创建一个称为执行期上下文的内部对象。独一无二,自顶向下,执行后立即销毁
变量查找:
从作用域顶链 端依次向下查找
原型:
what:
是function对象的一个属性,它定义了构造函数制造出的对象的公共祖先。通过该构造函数产生的对象,可以继承该原型的属性和方法。原型也是对象。
where:(用在哪)
利用原型特点和概念,可以提取公有属性
原型链:多个原型连接成链
call 、bind 、 apply:
都是用来改变this指向、第一参数都是this的指向对象
call 的参数是直接放进去的,第二第三第 n 个参数全都用逗号分隔,直接放到后面 obj.myFun.call(objec,‘成都’, … ,‘string’ )。
apply 的所有参数都必须放在一个数组里面传进去 obj.myFun.apply(objec,[‘成都’, …, ‘string’ ])。
bind 除了返回是函数以外,它 的参数和 call 一样。
预编译:
what:
发生在函数执行前一刻的编译、但并不对函数执行产生实际影响
how:
创建AO对象
找形参和变量声明,将变量和形参作为AO属性名,值为undefined
将形参和实参值统一
在函数体里面找函数声明,将值赋予函数体
补充:
imply global暗示全局变量:及任何变量、如果变量未经声明就赋值、此变量就成为全局变量所有。(函数内未经声明的变量、变为window属性 )
一切声明的全局变量,全是window的属性
JS闭包机制
what:
但凡是内部的函数返回到了外部一定会产生闭包
why:
每个函数执行完毕都只会销毁自己的AO、而函数内部的函数的作用域链上任然存在上一个函数的AO
how:
闭包会导致原有的作用域链不释放,会造成内存泄漏(内存还是被占用)
where(用在哪):
实现公有变量(函数累加器)、可以做缓存(存储结构)、
可以实现封装,属性私有化、模块化开发,防止污染全局变量
es3.0、es5.0、es6.0
what:
penGL ES 是从 OpenGL 裁剪的定制而来的,去除了glBegin/glEnd,四边形(GL_QUADS)、多边形(GL_POLYGONS)等复杂图元等许多非绝对必要的特性。是 OpenGL三维图形 API 的子集,针对手机、PDA和游戏主机等嵌入式设备而设计。
es5.0严格模式
“use strict” //字符串形式、不会报错、向后兼容
目前大部分浏览器基于es3.0的 + es5.0的新增方法使用的,那么产生冲突的部分就是用es5.0否则则会用es3.0
1、es5.0不支持arguments.callee 、function.caller
2、es5.0不再兼容 with(){} 语法
with(obj){
会使作用域链发生改变–在内部的代码直接使用obj的属性即可–效率丧失、消耗大量资源
}
3、es5.0未经声明的变量不在允许
4、es5.0局部的this指向不再是 window 而是 undefined
5、es5.0拒绝重复属性和参数,(浏览器中重复的属性不报错)
6、es3.0不支持eval
let和var的区别
ES6 新增了let命令,用来声明局部变量。它的用法类似于var,但是所声明的变量,只在let命令所在的代码块内有效,而且有暂时性死区的约束。
ES6的let让js真正拥有了块级作用域,也是向这更安全更规范的路走,虽然加了很多约束,但是都是为了让我们更安全的使用和写代码。
==============================================================================
<–HTTP–>
HTTP过程可分为四步:
1)首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3)服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,
- 然后客户机与服务器断开连接。
https(HTTP+TLS+LLS)通信的优点:
1)客户端产生的密钥只有客户端和服务器端能得到;
2)加密的数据只有客户端和服务器端才能得到明文;
3)客户端到服务端的通信是安全的。
HTTP/1.0和HTTP/1.1的比较
HTTP/1.0 每次请求都需要建立新的TCP连接,连接不能复用。
HTTP/1.1 新的请求可以在上次请求建立的TCP连接之上发送,连接可以复用。优点是减少重复进行TCP三次握手的开销,提高效率。
HTTP1.1在Request消息头里头多了一个Host域, HTTP1.0则没有这个域。
什么是HTTP 2.0
HTTP/2(超文本传输协议第2版,最初命名为HTTP 2.0),是HTTP协议的的第二个主要版本,使用于万维网。HTTP/2是HTTP协议自1999年HTTP 1.1发布后的首个更新,主要基于SPDY协议(是Google开发的基于TCP的应用层协议,用以最小化网络延迟,提升网络速度,优化用户的网络使用体验)。
与HTTP 1.1相比,主要区别包括
HTTP/2采用二进制格式而非文本格式
HTTP/2是完全多路复用的,而非有序并阻塞的——只需一个连接即可实现并行
使用报头压缩,HTTP/2降低了开销
HTTP2支持服务器推送
HTTP2.0为什么是二进制?
比起像HTTP/1.x这样的文本协议,二进制协议解析起来更高效、“线上”更紧凑,更重要的是错误更少。
为什么 HTTP2.0 需要多路传输?
HTTP/1.x 有个问题叫线端阻塞(head-of-line blocking), 它是指一个连接(connection)一次只提交一个请求的效率比较高, 多了就会变慢。 HTTP/1.1 试过用流水线(pipelining)来解决这个问题, 但是效果并不理想(数据量较大或者速度较慢的响应, 会阻碍排在他后面的请求). 此外, 由于网络媒介(intermediary )和服务器不能很好的支持流水线, 导致部署起来困难重重。而多路传输(Multiplexing)能很好的解决这些问题, 因为它能同时处理多个消息的请求和响应; 甚至可以在传输过程中将一个消息跟另外一个掺杂在一起。所以客户端只需要一个连接就能加载一个页面。
5、消息头为什么需要压缩?
假定一个页面有80个资源需要加载(这个数量对于今天的Web而言还是挺保守的), 而每一次请求都有1400字节的消息头(着同样也并不少见,因为Cookie和引用等东西的存在), 至少要7到8个来回去“在线”获得这些消息头。这还不包括响应时间——那只是从客户端那里获取到它们所花的时间而已。这全都由于TCP的慢启动机制,它会基于对已知有多少个包,来确定还要来回去获取哪些包 – 这很明显的限制了最初的几个来回可以发送的数据包的数量。相比之下,即使是头部轻微的压缩也可以是让那些请求只需一个来回就能搞定——有时候甚至一个包就可以了。这种开销是可以被节省下来的,特别是当你考虑移动客户端应用的时候,即使是良好条件下,一般也会看到几百毫秒的来回延迟。
6、服务器推送的好处是什么?
当浏览器请求一个网页时,服务器将会发回HTML,在服务器开始发送JavaScript、图片和CSS前,服务器需要等待浏览器解析HTML和发送所有内嵌资源的请求。服务器推送服务通过“推送”那些它认为客户端将会需要的内容到客户端的缓存中,以此来避免往返的延迟。
7、虚拟主机
是用同一个WEB服务器,为不同域名网站提供服务的技术。Apache、Tomcat等均可通过配置实现这个功能。
8、http代理服务器的主要功能:
1)突破自身IP访问限制,访问国外站点。
2)访问一些单位或团体内部资源,如某大学
5)隐藏真实IP
4)提高访问速度
HTTP最常见的请求头如下:
Accept:浏览器可接受的MIME类型;
Accept-Charset:浏览器可接受的字符集;
Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。Servlet能够向支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间;
Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到;
Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中;
Connection:表示是否需要持久连接。如果Servlet看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点,Servlet需要在应答中发送一个Content-Length头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然后在正式写出内容之前计算它的大小;
Content-Length:表示请求消息正文的长度;
Cookie:这是最重要的请求头信息之一;
From:请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它;
Host:初始URL中的主机和端口;
If-Modified-Since:只有当所请求的内容在指定的日期之后又经过修改才返回它,否则返回304“Not Modified”应答;
Pragma:指定“no-cache”值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝;
Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。
User-Agent:浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用;
UA-Pixels*,UA-Color**,UA-OS**,UA-CPU*:由某些版本的IE浏览器所发送的非标准的请求头,表示屏幕大小、颜色深度、操作系统和CPU类型。
HTTP最常见的响应头如下所示:
Allow:服务器支持哪些请求方法(如GET、POST等);
Content-Encoding:文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader(“Accept-Encoding”))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面;
Content-Length:表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入ByteArrayOutputStram,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容;
Content-Type: 表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentTyep。 可在web.xml文件中配置扩展名和MIME类型的对应关系;
Date:当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦;
Expires:指明应该在什么时候认为文档已经过期,从而不再缓存它。
Last-Modified:文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置;
Location:表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302;
Refresh:表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过setHeader(“Refresh”, “5; URL=http://host/path”)让浏览器读取指定的页面。注意这种功能通常是通过设置HTML页面HEAD区的实现,这是因为,自动刷新或重定向对于那些不能使用CGI或Servlet的HTML编写者十分重要。但是,对于Servlet来说,直接设置Refresh头更加方便。注意Refresh的意义是“N秒之后刷新本页面或访问指定页面”,而不是“每隔N秒刷新本页面或访问指定页面”。因此,连续刷新要求每次都发送一个Refresh头,而发送204状态代码则可以阻止浏览器继续刷新,不管是使用Refresh头还是。注意Refresh头不属于HTTP 1.1正式规范的一部分,而是一个扩展,但Netscape和IE都支持它。
==============================================================================
<–前端安全–>
面试官:你是学网络安全的吧,这些很熟悉吧?
我:…、不会啊
CSRF攻击简介
CSRF(Cross-site request forgery),中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:CSRF/XSRF。CSRF攻击者在用户已经登录目标网站之后,诱使用户访问一个攻击页面,利用目标网站对用户的信任,以用户身份在攻击页面对目标网站发起伪造用户操作的请求,达到攻击目的。
跨域
当前发起请求的域与该请求指向的资源所在的域不同时的请求。这里的域指的是这样的一个概念:我们认为如果 “协议 + 域名 + 端口号” 均相同,那么就是同域。
1.) 资源跳转: A链接、重定向、表单提交
2.) 资源嵌入: link script img frame等dom标签,还有样式中background:url()、@font-face()等文件外链
3.) 脚本请求: js发起的ajax请求、dom和js对象的跨域操作等
同源策略(Same origin policy)
是一种约定,它是浏览器最核心也是最基本的安全功能。出于安全考虑,浏览器限制从JS脚本发起的跨源HTTP请求。 例如,XMLHttpRequest和Fetch API都遵循同源策略。域名、协议、端口有一个不同就不是同源,三者均相同,这两个网站才是同源
1)DOM 层面的同源策略:限制了来自不同源的”Document”对象或 JS 脚本,对当前“document”对象的读取或设置某些属性
2)Cookie和XMLHttprequest层面的同源策略:禁止 Ajax 直接发起跨域HTTP请求(其实可以发送请求,结果被浏览器拦截,不展示),同时 Ajax 请求不能携带与本网站不同源的 Cookie。
3)同源策略的非绝对性:
存在的安全风险
由于同源策略的限制,跨域的ajax请求不会带上cookie,然而 script / iframe / img 等标签却是支持跨域的,所以在请求的时候是会带上cookie的。
防范
对于web站点,不采用持久化的授权方法(例如cookie或者HTTP授权、切换为瞬时的授权方法)
二重加密措施
每个需要验证身份的请求都要显式地带上token值
XSS 漏洞简介
跨站脚本攻击是指恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。
xss漏洞通常是通过php的输出函数将javascript代码输出到html页面中,通过用户本地浏览器执行的,所以xss漏洞关键就是寻找参数未过滤的输出函数。
常见的输出函数有:
echo printf print print_r sprintf die var-dump var_export.
什么是SQL注入?
SQL注入(SQLi)是一种注入攻击,,可以执行恶意SQL语句。它通过将任意SQL代码插入数据库查询,使攻击者能够完全控制Web应用程序后面的数据库服务器。攻击者可以使用SQL注入漏洞绕过应用程序安全措施;可以绕过网页或Web应用程序的身份验证和授权,并检索整个SQL数据库的内容;还可以使用SQL注入来添加,修改和删除数据库中的记录。
==============================================================================
<–get 、post、 status code–>
GET与POST方法有以下区别:
GET方式:是以实体的方式得到由请求URI所指定资源的信息
POST方式:用来向目的服务器发出请求,要求它接受被附在请求后的实体,并把它当作请求队列中请求URI所指定资源的附加新子项
(1) 在客户端,Get方式在通过URL提交数据,数据在URL中可以看到;POST方式,数据放置在HTML HEADER内提交。
(2) GET方式提交的数据最多只能有1024字节,而POST则没有此限制。
(3) 安全性问题。正如在(1)中提到,使用 Get 的时候,参数会显示在地址栏上,而 Post 不会。所以,如果这些数据是中文数据而且是非敏感数据,那么使用 get;如果用户输入的数据不是中文字符而且包含敏感数据,那么还是使用 post为好。
GET和POST还有一个重大区别,
简单的说:GET产生一个TCP数据包;POST产生两个TCP数据包。
长的说:对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
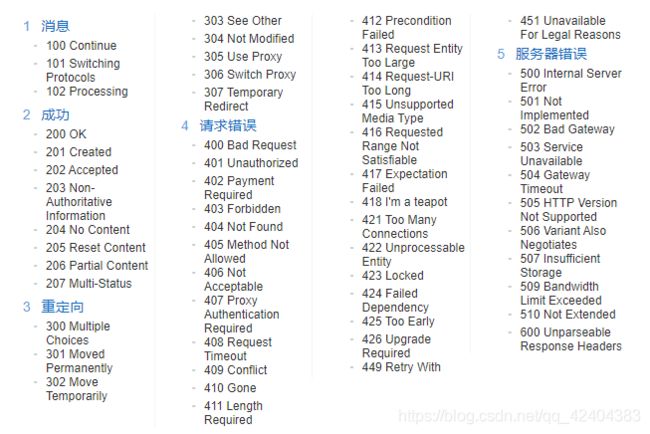
HTTP状态码
(英语:HTTP Status Code)是用以表示网页服务器超文本传输协议响应状态的3位数字代码。所有状态码的第一个数字代表了响应的五种状态之一。


==============================================================================
<–计算机网络–>
面试官:你是学网络的吧,这些很熟悉吧?
我:…、这个我、我知道
面试官:那就不问了
我:…
什么是DNS解析:
网络通讯大部分是基于TCP/IP的,而TCP/IP是基于IP地址的,所以计算机在网络上进行通讯时只能识别如“202.96.134.133”之类的IP地址,而不能认识域名,而通过URL来请求资源时,URL中的域名需要解析成IP地址才能与远程主机建立连接,如何将域名解析成IP地址就属于DNS解析的工作范畴。

域名解析记录主要分为:
A记录、MX记录、CNAME记录、 NS记录、TXT记录
-
A记录:A代表的是Address,用来指定域名对应的IP地址,A记录允许将多个域名解析到一个IP地址,但不允许将一个域名解析到多个IP上。
-
MX记录:MX代表的是Mail Exchage,就是可以将某个域名下的邮箱服务器指向自己的Mail Server
-
CNAME记录:CNAME指的是Canonical Name,也就是别名解析,可以将指定的域名解析到其他域名上,而其他域名就是指定域名的别名,整个解析过程称为别名解析。
-
NS记录:就是为了某个域名指定了特定的DNS服务器去解析。
-
TXT记录:为某个主机名或者域名设置特定的说明。
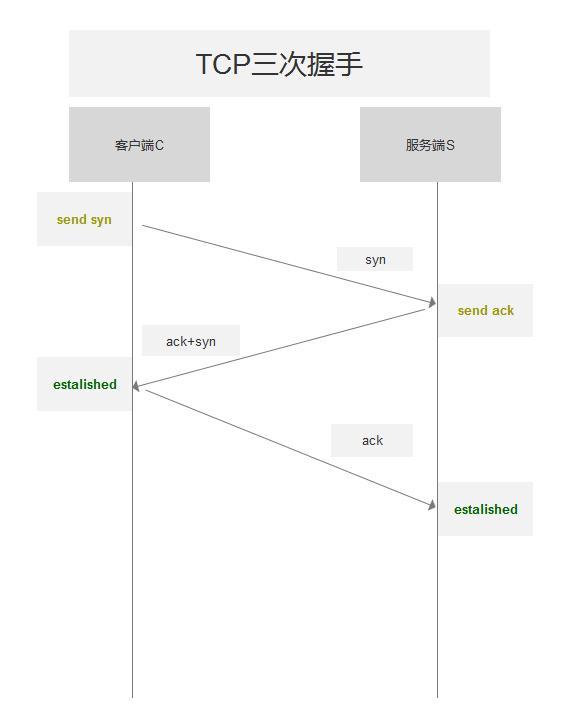
TCP三次握手
==============================================================================
<–操作系统–>
没想到会考
进程与线程的区别
-
线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
-
一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线
-
进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段,数据集,堆等)及一些进程级的资源(如打开文件和信
号等),某进程内的线程在其他进程不可见;
-
调度和切换:线程上下文切换比进程上下文切换要快得多
为何不使用多进程而是使用多线程?
线程廉价,线程启动比较快,退出比较快,对系统资源的冲击也比较小。而且线程彼此分享了大部分核心对象(File Handle)的拥有权
如果使用多重进程,但是不可预期,且测试困难
==============================================================================
<–杂项–>
前端性能优化可以分为两大类分别是
页面级别优化包含了http请求数以及内联脚本位置优化,
代码级别的优化包含DOM操作优化,CSS选择符优化以及图片优化等
前后端联调
在前后端约定好api接口后,同步进行开发,前端没有数据支持,造成了阻塞。
这时候一般前端只能做假数据(专业点叫mock数据,_)理想情况下定义好api路径和数据之间的映射即可。但这是就有第一个问题。
前端是否需要写本地数据?如果写本地数据的话,那就意味着要写本地的相对路径,那如果最后要来修改的接口呢?(那如果后台开发的慢了,最后会有多少个接口要修改呀。
mock数据,有很多中方法,gulp,webpack,fekit,多种前端自动化构建工具。
绝对路径呢,只要做一个host映射就ok了。
前端框架
学习中