Pytorch的RELU函数
4.1.2 激活函数
PyTorch实现了常见的激活函数,其具体的接口信息可参见官方文档1,这些激活函数可作为独立的layer使用。这里将介绍最常用的激活函数ReLU,其数学表达式为:
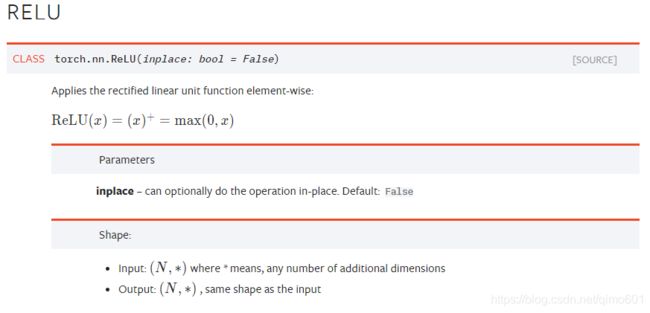
代码:
relu = nn.ReLU(inplace=True)
input = t.randn(2, 3)
print(input)
output = relu(input)
print(output) # 小于0的都被截断为0
# 等价于input.clamp(min=0)结果:
tensor([[ 1.2836, 2.0970, -0.0456],
[ 1.5909, -1.3795, 0.5264]])
tensor([[ 1.2836, 2.0970, 0.0000],
[ 1.5909, 0.0000, 0.5264]])
ReLU函数有个inplace参数,如果设为True,它会把输出直接覆盖到输入中,这样可以节省内存/显存。之所以可以覆盖是因为在计算ReLU的反向传播时,只需根据输出就能够推算出反向传播的梯度。但是只有少数的autograd操作支持inplace操作(如tensor.sigmoid_()),除非你明确地知道自己在做什么,否则一般不要使用inplace操作。
在以上的例子中,基本上都是将每一层的输出直接作为下一层的输入,这种网络称为前馈传播网络(feedforward neural network)。对于此类网络如果每次都写复杂的forward函数会有些麻烦,在此就有两种简化方式,ModuleList和Sequential。其中Sequential是一个特殊的module,它包含几个子Module,前向传播时会将输入一层接一层的传递下去。ModuleList也是一个特殊的module,可以包含几个子module,可以像用list一样使用它,但不能直接把输入传给ModuleList。下面举例说明。
代码:
# Sequential的三种写法
net1 = nn.Sequential()
net1.add_module('conv', nn.Conv2d(3, 3, 3))
net1.add_module('batchnorm', nn.BatchNorm2d(3))
net1.add_module('activation_layer', nn.ReLU())
net2 = nn.Sequential(
nn.Conv2d(3, 3, 3),
nn.BatchNorm2d(3),
nn.ReLU()
)
from collections import OrderedDict
net3= nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(3, 3, 3)),
('bn1', nn.BatchNorm2d(3)),
('relu1', nn.ReLU())
]))
print('net1:', net1)
print('net2:', net2)
print('net3:', net3)输出:
net1: Sequential(
(conv): Conv2d(3, 3, kernel_size=(3, 3), stride=(1, 1))
(batchnorm): BatchNorm2d(3, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(activation_layer): ReLU()
)
net2: Sequential(
(0): Conv2d(3, 3, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(3, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
net3: Sequential(
(conv1): Conv2d(3, 3, kernel_size=(3, 3), stride=(1, 1))
(bn1): BatchNorm2d(3, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU()
)
# 可根据名字或序号取出子module,
代码:
# 可根据名字或序号取出子module
net1.conv, net2[0], net3.conv1输出:
(Conv2d(3, 3, kernel_size=(3, 3), stride=(1, 1)),
Conv2d(3, 3, kernel_size=(3, 3), stride=(1, 1)),
Conv2d(3, 3, kernel_size=(3, 3), stride=(1, 1)))
代码:
input = t.rand(1, 3, 4, 4)
output1 = net1(input)
output2 = net2(input)
output3 = net3(input)
output4 = net3.relu1(net1.batchnorm(net1.conv(input)))
print('output1',output1)
print('output2',output2)
print('output3',output3)
print('output4',output4)结果:
output1 tensor([[[[0.4223, 0.0000],
[0.0000, 1.4133]],
[[0.0000, 0.0343],
[0.8903, 0.7163]],
[[0.9817, 0.0000],
[0.7821, 0.0000]]]], grad_fn=)
output2 tensor([[[[0.0000, 0.5348],
[1.0742, 0.0000]],
[[1.2695, 0.0000],
[0.0000, 0.3837]],
[[0.0000, 0.0000],
[1.6453, 0.0000]]]], grad_fn=)
output3 tensor([[[[0.1690, 0.7540],
[0.0000, 0.7581]],
[[1.6805, 0.0000],
[0.0000, 0.0000]],
[[0.2216, 0.5082],
[0.9433, 0.0000]]]], grad_fn=)
output4 tensor([[[[0.4223, 0.0000],
[0.0000, 1.4133]],
[[0.0000, 0.0343],
[0.8903, 0.7163]],
[[0.9817, 0.0000],
[0.7821, 0.0000]]]], grad_fn=)
ModuleList是Module的子类,代码:
modellist = nn.ModuleList([nn.Linear(3,4), nn.ReLU(), nn.Linear(4,2)])
input = t.randn(1, 3)
for model in modellist:
input = model(input)
# 下面会报错,因为modellist没有实现forward方法
# output = modelist(input)