Pytorch张量(Tensor)基本介绍与使用
文章目录
- 前言
- 一、Pytorch张量与数据类型
-
- 1.生成随机矩阵
- 2.查看随机矩阵规模
- 3.Tensor(张量)基本数据类型及其转换
- 二、张量运算与形状变换
-
- 1.Tensor(张量)计算原则
- 2.Tensor(张量)形状变换
- 三、张量微分运算
-
- 1.张量的自动微分
- 2. 设置Tensor不可跟踪计算(测试集常用)
- 3.就地改变Tensor(张量)变量的requires_grad值
前言
Pytorch最基本的操作对象是Tensor(张量),
它表示一个多维矩阵,
张量类似于NumPy的ndarrays,
张量可以在GPU上使用以加速计算.
一、Pytorch张量与数据类型
1.生成随机矩阵
Tensor(张量)
构造一个随机初始化的矩阵:torch.rand
全0矩阵:torch.zeros
全0矩阵:torch.ones
直接从数据构造张量:torch.tensor
示例代码如下
import torch
# 0-1之间均匀分布随机数,2行3列数组
x = torch.rand(2, 3)
print(x)
# 0-1之间正态分布随机数, 3行4列数组
y = torch.randn(3, 4)
print(y)
# 全0数组
z = torch.zeros(2, 3)
print(z)
# 全1数组,可以理解为两个3*4的矩阵,三维的
q = torch.ones(2, 3, 4)
print(q)
运行效果见下图:

2.查看随机矩阵规模
shape与size()区别:
假设x为一个tensor
x.size()与x.shape 效果相同
x.size()若加具体参数,可以显示该参数位置下的维度(参数位置从0开始)
示例如下
import torch
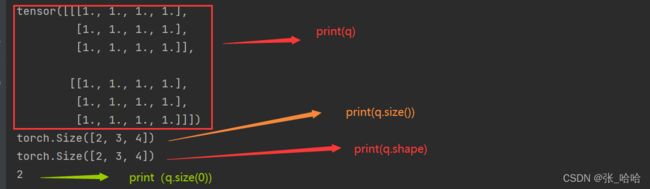
q = torch.ones(2, 3, 4)
print(q)
print(q.size())
print(q.shape)
print(q.size(0))
运行效果见下图:
3.Tensor(张量)基本数据类型及其转换
Tensor的最基本数据类型:
- 32位浮点型:torch.float32 (最常用)
- 64位浮点型:torch.float64 (最常用)
- 32位整型:torch.int32
- 16位整型:torch.int16
- 64位整型:torch.int64
x.type 可以查看数据类型
ndarray 与 tensor 之间可以相互转换
示例代码如下:
import numpy as np
import torch
x = torch.tensor([6, 2], dtype=torch.float32)
print(x)
print(x.type()) # 查看数据类型
# 数据类型转换 float32 转 int64
x = x.type(torch.int64)
print(x)
# 数据类型转换 ndarray 转 tensor
a = np.random.randn(2, 3)
print(a) # 输出ndarray
z = torch.from_numpy(a)
print(z) # 输出转换后的tensor
# 数据类型转换 tensor 转 numpy
print(z.numpy())
运行效果见下图

二、张量运算与形状变换
1.Tensor(张量)计算原则
(1)两个随机矩阵相加:对应元素相加
(2)广播原则:加常数,则每一个元素都加
(3)当一个运算符后加_表示就地改变内存中的值将原有内存中的值覆盖掉,
例如 x1.add(x2) 与 x1.add_(x2)区别
示例代码如下:
import torch
# 两个随机矩阵相加:对应元素相加
x1 = torch.rand(2, 3)
x2 = torch.rand(2, 3)
print(x1)
print(x2)
print(x1+x2)
# 广播原则:加常数,则每一个元素都加
x3 = x1 + 3
print(x3)
# 当一个运算符后加_表示就地改变内存中的值
# 将原有内存中的值覆盖掉, 例如 x1.add(x1)
print(x1.add(x2))
print(x1) # 会发现x1的值未被改变
print(x1.add_(x2))
print(x1) # 会发现x1的值已经被覆盖
运行效果如下图:

2.Tensor(张量)形状变换
(1)view()方法变换数据形状,展平数据
(2).mean() .sum()等方法与NumPy中用法一致
(3)单个值Tensor返回一个标量 .item()
示例代码如下:
import torch
# 形状变换
x1 = torch.rand(2, 3)
x2 = torch.rand(2, 3)
print(x1.shape) # 查看x1的形状
# 经常用到它展平数据
print(x1.view(3, 2))
# 前面-1表示根据个数自动计算,后面-1表示第二维是1 shape(n,1)
print(x1.view(-1, 1))
# 有些方法与NumPy中方法一致
# 求x1的均值
print(x1.mean())
# 求x1的和
print(x1.sum())
# 从单个数值的tensor直接取出一个标量值
x = x1.sum()
print(x.item()) # 直接获得一个值
运行结果如下图:

三、张量微分运算
1.张量的自动微分
将Torch.Tensor属性,.requires_grad 设置为True,
pytorch将开始跟踪对此张量的所有操作。
完成计算后,可以调用.backward()方法自动计算所有梯度。
该张量的梯度将累加到.grad属性中。
代码示例如下:
import torch
# 张量的自动微分
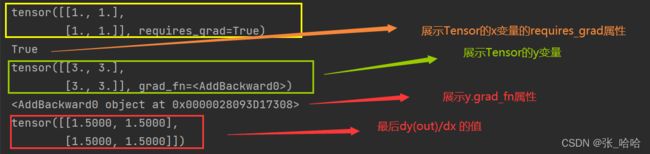
x = torch.ones(2, 2, requires_grad=True)
print(x)
print(x.requires_grad)
y = x + 2
print(y) # y是通过计算得来的
print(y.grad_fn)
z = y * y + 3
out = z.mean() # 求z的均值
# out = f(x)
# 下面求d(out)/d(x)
out.backward()
print(x.grad)
运行结果如下图所示:
2. 设置Tensor不可跟踪计算(测试集常用)
有时候不需要去跟踪计算,例如测试数据,用于测试集
示例代码如下:
import torch
# 张量的自动微分
x = torch.ones(2, 2, requires_grad=True)
# 一般用于测试集,不需要去跟踪计算
with torch.no_grad():
print((x**2).requires_grad)
运行结果如下图:

3.就地改变Tensor(张量)变量的requires_grad值
注意Python中下划线的作用,可以就地改变值,覆盖原内存
示例代码如下:
import torch
# 注意只有float变量才可计算梯度
a = torch.tensor([3, 2], dtype=torch.float32)
print(a)
print(a.requires_grad)
# 就地改变Tensor变量a的requires_grad属性为True
a.requires_grad_(True) # 注意下划线的作用
print(a.requires_grad)
运行结果如下图所示:

THE END