Pandas 模块 - 读写(1)-csv/txt等文档-read_csv/to_csv
目录
1. 读写 csv 或者 txt 文件
1.1 .read_csv()语法
1.2 .read_csv()范例
1.2.1 唯一不可缺少的参数 filepath_or_buffer
1.2.2 常用参数 sep
1.2.4 常用参数 skip_blank_lines
1.2.5 常用参数 usecols
1.2.6 常用参数 encoding数据如下
1.2.7 常用参数 prefix、nrows
1.2.8 常用参数 chunksize
1.3 .to_csv()语法
1.4 .to_csv()范例
1.4.1 代码 1)最简单的只有 path_or_buf
1.4.2 代码 2) 加上 encoding="GBK"
1.4.3 代码 3) header 和 index 的使用
1.4.4 代码 4)直接替换文档后缀名,写入 txt 文档
1.4.5 代码 5)使用 sep 分隔符
1.4.6 代码 6)line_terminator 的使用
1.4.7 代码 7)index_label 参数的使用
1.4.8 代码 8)追加模式写入
1.4.9 代码 9)float 值的写入
在 Pandas 的数据类型简单介绍-Series 与 DataFrame 中介绍了使用 Pandas.DataFrame、Pandas.DataFrame.from_dict、Pandas.DataFrame.from_records 来构造 DataFrame 数据,此外Pandas 还支持从外部读取或者写入数据,这也是办公自动化的重要基础。
Pandas 目前支持下面几种方式:
| Format Type |
Data Description |
Reader |
Writer |
| text |
CSV(opens new window) |
read_csv |
to_csv |
| text |
JSON(opens new window) |
read_json |
to_json |
| text |
HTML(opens new window) |
read_html |
to_html |
| text |
Local clipboard |
read_clipboard |
to_clipboard |
| binary |
MS Excel(opens new window) |
read_excel |
to_excel |
| binary |
OpenDocument(opens new window) |
read_excel |
|
| binary |
HDF5 Format(opens new window) |
read_hdf |
to_hdf |
| binary |
Feather Format(opens new window) |
read_feather |
to_feather |
| binary |
Parquet Format(opens new window) |
read_parquet |
to_parquet |
| binary |
Msgpack(opens new window) |
read_msgpack |
to_msgpack |
| binary |
Stata(opens new window) |
read_stata |
to_stata |
| binary |
SAS(opens new window) |
read_sas |
|
| binary |
Python Pickle Format(opens new window) |
read_pickle |
to_pickle |
| SQL(opens new window) |
SQL |
read_sql |
to_sql |
| SQL |
Google Big Query(opens new window) |
read_gbq |
to_gbq |
本文先介绍下面 4 种和外部交互数据的方式
读 | read_csv : Read a comma-separated values (csv) file into DataFrame. | read_excel : Read an Excel file into a pandas DataFrame. | read_clipboard : Read text from clipboard into DataFrame. | read_sql :Read a DataFrame from a table. 写 | to_csv : Write DataFrame to a comma-separated values (csv) file. | to_excel :Write DataFrame to an Excel file. | to_clipboard : Write a text representation of object to the system clipboard. | to_sql :Write DataFrame to a SQL database.
1. 读写 csv 或者 txt 文件
1.1 .read_csv()语法
语法:
pd.read_csv(filepath_or_buffer, sep=‘,', header='infer', names=None, usecols=None, skiprows=None, skipfooter=None, converters=None, encoding=None, index_col=0, engine='C',......)
参数说明:
filepath_or_buffer:指定txt文件或csv文件所在的具体路径
sep:指定原数据集中各字段之间的分隔符,默认为逗号”,”
header:默认 0。用来指定行数用来作为列名,数据开始行数。如果文件中没有列名,则默认为0,否则设置为None。
如果明确设定header=0 就会替换掉原来存在列名。header参数可以是一个list例如:[0,1,3],这个list表示将文件中的这些行作为列标题(意味着每一列有多个标题),介于中间的行将被忽略掉(例如本例中的2;本例中的数据1,2,4行将被作为多级标题出现,第3行数据将被丢弃,dataframe的数据从第5行开始。)。
注意:如果skip_blank_lines=True 那么header参数忽略注释行和空行,所以header=0表示第一行数据而不是文件的第一行。
names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头 usecols:指定需要读取原数据集中的哪些变量名
skiprows:数据读取时,指定需要跳过原数据集开头的行数
skipfooter:数据读取时,指定需要跳过原数据集末尾的行数 converters:用于数据类型的转换(以字典的形式指定) encoding:如果文件中含有中文,有时需要指定字符编码
index_col:默认为None,假如设置 index_col=0,则意味着第一列作为行名
converters:用于数据类型的转换(以字典的形式指定)
skip_blank_lines:默认为False,如果设置 True 那么将忽略空行和注释行,类似于 header 这种参数忽略也会有影响
engine:{‘c’, ‘python’}, 可选 。使用的分析引擎。可以选择C或者是python。C引擎快但是Python引擎功能更加完备。如果要使用”skipfooter“,那么engine 要设置为 ”Python“
1.2 .read_csv()范例
1.2.1 唯一不可缺少的参数 filepath_or_buffer
要读取的 txt 文档如下
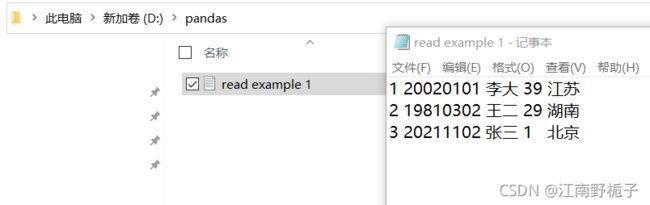
只输入 txt 文件地址
df=pd.read_csv(r"D:\pandas\read example 1.txt")
df运行结果如下,可以看出来并不是我想要的。
第一:第一行是数据,而不是表头
第二:整行被当成一个数据了,而不是分开
第三:我希望序号还是从1 开始,就如我在 txt 文档种使用的那样。
1 20020101 李大 39 江苏 0 2 19810302 王二 29 湖南 1 3 20211102 张三 1 北京
当我使用pdb进行调试,可以看到此时的参数如下,太多了。在本文只能把常见的解释一下。
ipdb> a filepath_or_buffer = 'D:\\pandas\\read example 1.txt' sep =
1.2.2 常用参数 sep
为了实现我原本的想法,我修改了代码
df=pd.read_csv(r"D:\pandas\read example 1.txt",#输入地址名
header=None,#即表头为空
sep = r'\s+',# 不是以','为分隔符,而是以空格为分隔符,一个或者多个连续空格为一个分隔符
index_col=0)# 将第一列设置为 index
df运行结果如下
1 2 3 4 0 1 20020101 李大 39 江苏 2 19810302 王二 29 湖南 3 20211102 张三 1 北京
1.2.3 常用参数 header、names、skiprows、skipfooter
如果我要处理的 txt 文档如下,我需要剔除除了数据外的行数,还要剔除空格行,并且这时候数据演示不够清晰,我要加上表头。
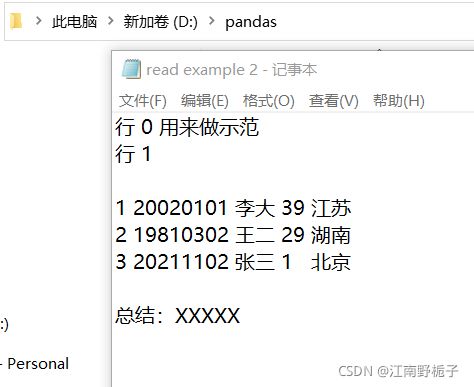
实现的代码如下
df=pd.read_csv(r"D:\pandas\read example 2.txt",#输入地址名
header=None,#即表头为空
names=["生日","姓名","年龄","籍贯"],#设置表头
skiprows=3,#不读取前3行
skipfooter=2,#不读取后1行
sep = r'\s+',# 不是以','为分隔符,而是以空格为分隔符,一个或者多个连续空格为一个分隔符
index_col=0,# 将第一列设置为 index
engine='python')#****这个一定要加上,否则无法使用 skipfooter 参数****,因为我现在使用的是C engine
df运行结果比较令人满意
生日 姓名 年龄 籍贯 1 20020101 李大 39 江苏 2 19810302 王二 29 湖南 3 20211102 张三 1 北京
1.2.4 常用参数 skip_blank_lines
如果数据中有很多空行,我需要清除掉这些无用的数据。
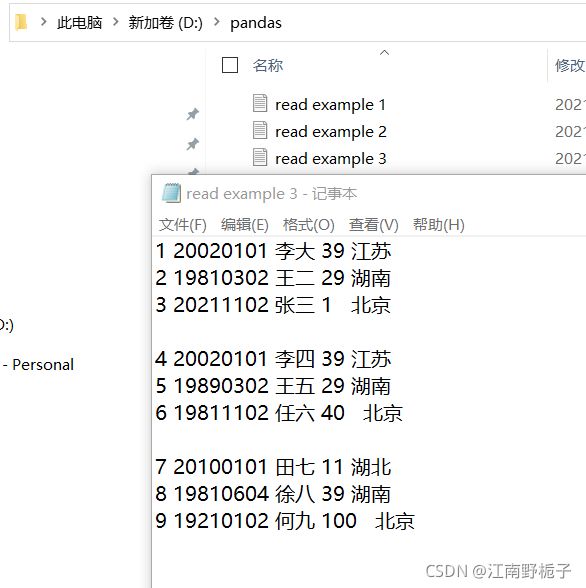
代码如下:
df=pd.read_csv(r"D:\pandas\read example 3.txt",#输入地址名
header=None,#即表头为空
names=["生日","姓名","年龄","籍贯"],#设置表头
skip_blank_lines=True, #将空行去除掉
sep = r'\s+', # 以空格为分隔符
index_col=0, #使用第一列为行名
engine='python'
)
df
生日 姓名 年龄 籍贯 1 20020101 李大 39 江苏 2 19810302 王二 29 湖南 3 20211102 张三 1 北京 4 20020101 李四 39 江苏 5 19890302 王五 29 湖南 6 19811102 任六 40 北京 7 20100101 田七 11 湖北 8 19810604 徐八 39 湖南 9 19210102 何九 100 北京
1.2.5 常用参数 usecols
我不需要所有的列,我只要特定的数据,例如姓名和年龄即可,那么对代码再做改动
使用 usecols 来选定我需要的特定列
data01 = pd.read_csv(r'D:\pandas\read example 3.txt',
sep = r'\s+',
header = None,
index_col=0,
skip_blank_lines=True,
names = ['序号','生日','姓名','年龄','籍贯'],
usecols = ['序号','姓名','生日','年龄'],
converters={"生日":str,"年龄":str},#将
engine="python")
data01运行结果是
序号 生日 姓名 年龄 1 20020101 李大 39 2 19810302 王二 29 3 20211102 张三 1 4 20020101 李四 39 5 19890302 王五 29 6 19811102 任六 40 7 20100101 田七 11 8 19810604 徐八 39 9 19210102 何九 100
1.2.6 常用参数 encoding数据如下
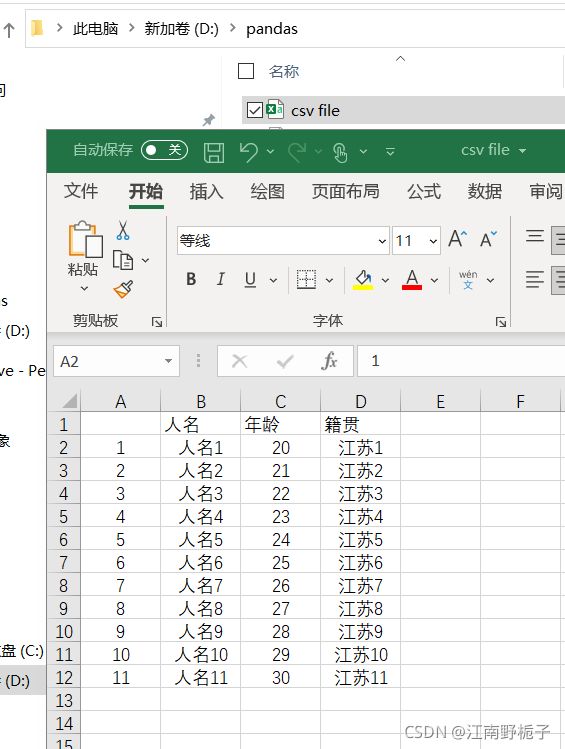
代码如下,请注意因为数据有中文,我用了encoding="GBK"进行转码,否则会出现乱码。
其余用法和读取 txt 文档类似,不再赘述
data01 = pd.read_csv(r'D:\pandas\csv file.csv',
# header = None, csv file 有头,在第一行,使用默认的 0 即可
index_col=0,
skip_blank_lines=True,# 去掉空行
encoding="GBK",# 数据中有中文
)
data01运行结果
人名 年龄 籍贯 1 人名1 20 江苏 2 人名2 21 河北 3 人名3 22 云南 4 人名4 23 河南 5 人名5 24 湖南 6 人名6 25 湖北 7 人名7 26 广东 8 人名8 27 北京 9 人名9 28 上海 10 人名10 29 海南 11 人名11 30 辽宁
1.2.7 常用参数 prefix、nrows
我再介绍一下两个可能用到的参数
prefix :str 类型, 默认为 None,在没有列标题时,给列添加前缀。例如:添加‘X’ 成为 X0, X1, ...
nrows:int 类型, 默认None,需要读取的行数(从文件头开始算起)。
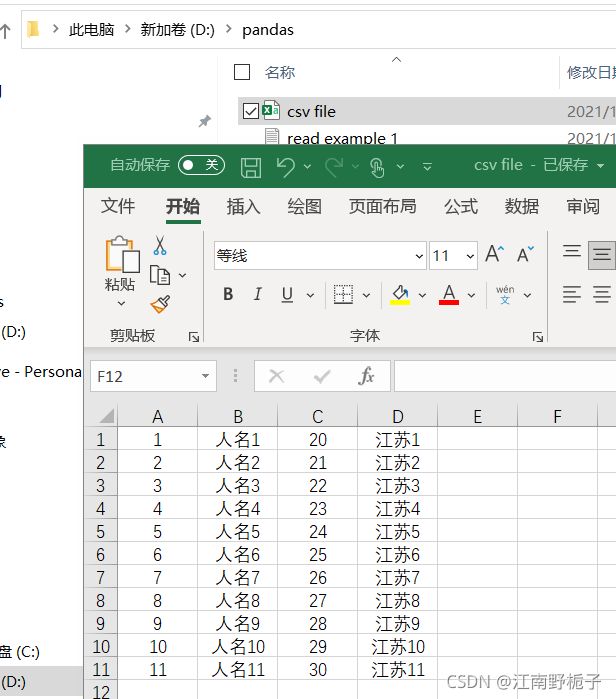
代码如下
data01 = pd.read_csv(r'D:\pandas\csv file.csv',
header = None, # 尤其在使用了prefix 时候,此时必须设置为 None
index_col=0,
skip_blank_lines=True,# 去掉空行
prefix="列名",#设置每个列的前缀为“列名”
nrows=6,#只提取前 6 行
encoding="GBK",# 数据中有中文
)
data01运行结果,请注意,因为要把行那一列也设置上列名,结果行名所在列和其余的列的列名,不在同一行。这个和直接使用 names 来赋值列名,效果是不一样的!
Out[31]:
列名1 列名2 列名3 列名0 1 人名1 20 江苏1 2 人名2 21 江苏2 3 人名3 22 江苏3 4 人名4 23 江苏4 5 人名5 24 江苏5 6 人名6 25 江苏6
如果只想得到部分列,如籍贯这一列,请千万注意,不要直接用列名!而是用列号!
如下面的代码,使列号你是可以提取出来籍贯这一列的
data01 = pd.read_csv(r'D:\pandas\csv file.csv',
header = None, # 尤其在使用了prefix 时候,此时必须设置为 None
#index_col=0,
skip_blank_lines=True,# 去掉空行
prefix="列名",#设置每个列的前缀为“列名”
usecols=[3],
nrows=10,#只提取前 10 行
encoding="GBK",# 数据中有中文
)
data01
Out[35]:
列名3 0 江苏1 1 江苏2 2 江苏3 3 江苏4 4 江苏5 5 江苏6 6 江苏7 7 江苏8 8 江苏9 9 江苏10
但是换成列名,主要是配合使用 prefix 使用时候,就会得到下面比较可怜的结果。
data01 = pd.read_csv(r'D:\pandas\csv file.csv',
header = None, # 尤其在使用了prefix 时候,此时必须设置为 None
#index_col=0,
skip_blank_lines=True,# 去掉空行
prefix="列名",#设置每个列的前缀为“列名”
usecols=["列名1"],
nrows=10,#只提取前 10 行
encoding="GBK",# 数据中有中文
)
data01运行结果
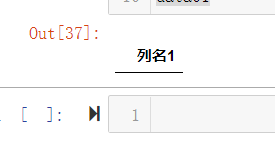
**********************************************************************************************************
不要问为什么,可以理解为 Pandas 的不完美,在功能越多时候,组合越多,代码有些顾不过来了。
我的建议是,不要用 prefix 参数,除非你必须,否则尽可能地用 names 参数。
**********************************************************************************************************
1.2.8 常用参数 chunksize
在读取大数据量的文件时候,内存很可能吃不消,也没有必要一下子提取所有数据,这时候可以用
chunksize。
data01 = pd.read_csv(r'D:\pandas\csv file.csv',
index_col=0,
encoding="GBK",# 数据中有中文
chunksize=10 #每次提取 10 行数据
)
pd.options.display.max_rows = 20 # 最多显示 20 行
print(type(data01))
for tmp in data01:
print("*"*40)
print(tmp)运行结果如下
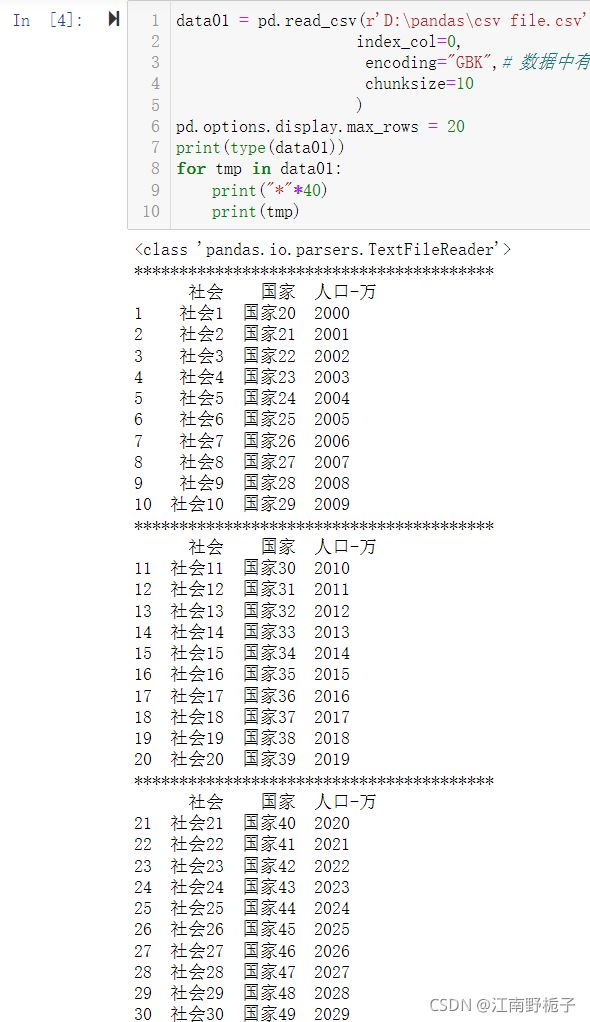
1.3 .to_csv()语法
.to_csv Write object to a comma-separated values (csv) file。
语法:DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression=None, quoting=None, quotechar='"', line_terminator='\n', chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.')
参数说明:
path_or_buf=None: 字符串或文件句柄,默认无文件;路径或对象,如果没有提供,结果将返回为字符串。
sep : 默认字符 ‘ ,’输出文件的字段分隔符。
na_rep :字符串,默认为 ‘’浮点数格式字符串
float_format : 字符串,默认为 None,浮点数格式字符串
columns : 可选项,用于选列写入
header : 字符串或布尔列表,默认为True;写出列名。如果给定字符串列表,则假定为列名的别名。
index : 布尔值,默认为Ture,写入行名称(索引)
index_label : 字符串或序列,或 False, 默认为None
如果需要,可以使用索引列的列标签。如果没有给出,且标题和索引为True,则使用索引名称。如果数据文件使用多索引,则应该使用这个序列。如果值为False,不打印索引字段。在R中使用index_label=False 更容易导入索引.
mode : 模式:值为‘str’,字符串,Python写模式,默认“w”,也可以为'a',即追加
encoding : 编码格式,字符串类型,可选;表示在输出文件中使用的编码的字符串,Python 2上默认为“ASCII” 和 Python 3上默认为“UTF-8”。
compression : 字符串类型,可选项,表示在输出文件中使用的压缩的字符串,允许值为“gzip”、“bz2”、“xz”,仅在第一个参数是文件名时使用。
line_terminator : 字符串,默认为 ‘\n’;在输出文件中使用的换行字符或字符序列
quoting : 默认值为 to_csv.QUOTE_MINIMAL,CSV模块的可选常量。如果设置了浮点格式,那么浮点将转换为字符串,因此 csv.QUOTE_NONNUMERIC会将它们视为非数值的。
quotechar : 字符串类型,(长度1),默认“”,用于引用字段的字符
doublequote : 布尔值,默认为Ture;控制一个字段内的 quotechar
escapechar : string (length 1), default None
字符串(长度为1),默认为None
在适当的时候用来转义sep和quotechar的字符
chunksize : 可以为整数,也可以为 None,默认为 None。即一次性写入多少行, chunksize=None 时候一次写入所有行
date_format : 字符串类型, 默认为 None,将字符串对象转换为日期时间对象
decimal: 字符串类型,默认’。’ 字符识别为小数点分隔符
1.4 .to_csv()范例
目前 DataFrame 数据准备如下:
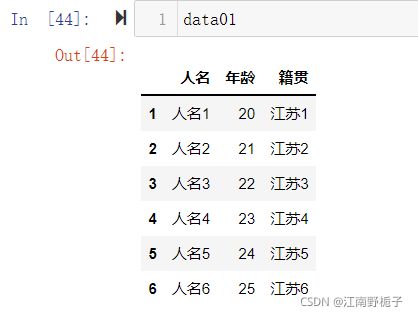
1.4.1 代码 1)最简单的只有 path_or_buf
data01.to_csv(r'D:\pandas\save csv 1.csv')运行结果如下,因为编码格式没有指定,内容是中文,现在是乱码。
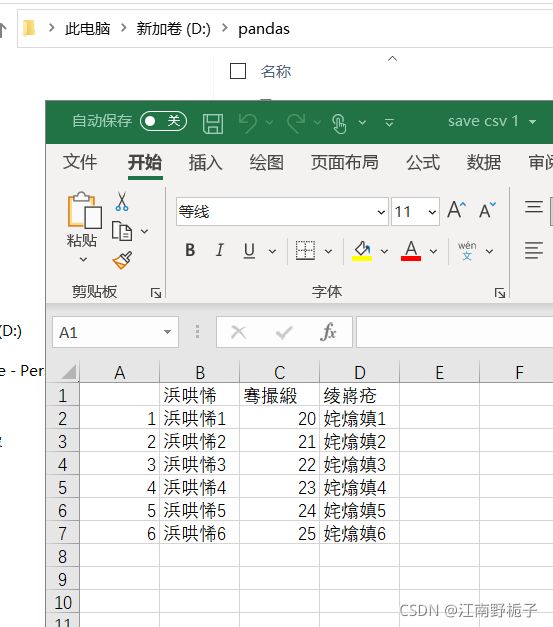
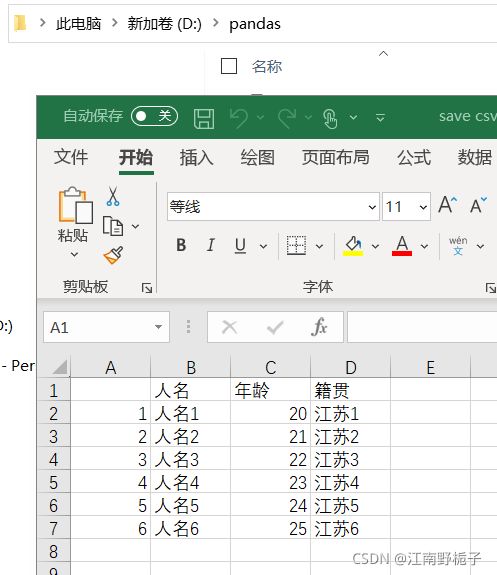
1.4.2 代码 2) 加上 encoding="GBK"
data01.to_csv(r'D:\pandas\save csv 2.csv',encoding="GBK")这时候就能正常的保存中文字符。
1.4.3 代码 3) header 和 index 的使用
如果我既不想要行名,也不行要列名,只想要单纯的数据,可以通过header=False,index=False,将这两部分取消。
data01.to_csv(r'D:\pandas\save csv 3.csv',encoding="GBK",header=False,index=False)运行结果
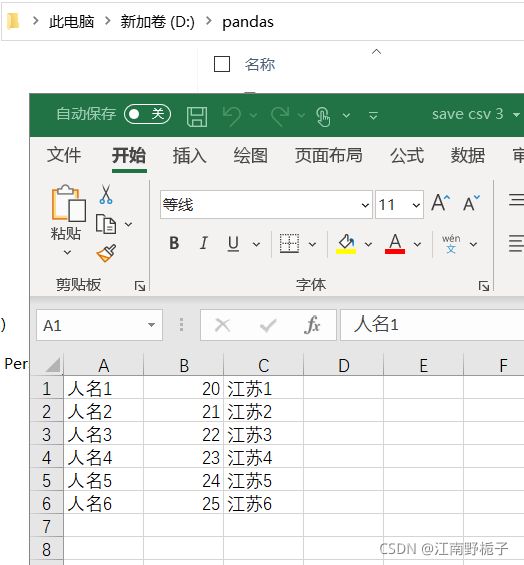
1.4.4 代码 4)直接替换文档后缀名,写入 txt 文档
data01.to_csv(r'D:\pandas\save csv 3.txt',encoding="GBK",header=False,index=False)运行结果如下,可以看到分隔符是","
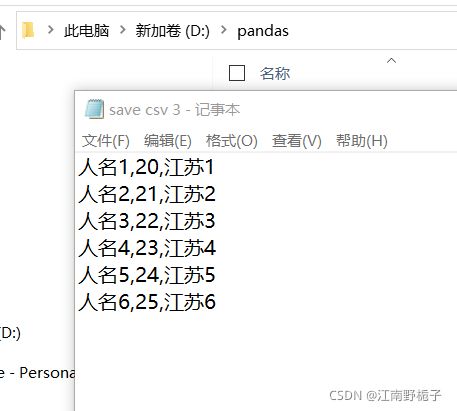
1.4.5 代码 5)使用 sep 分隔符
希望写入文档的分隔符是“|”,并且只需要人名和年龄两列,不需要籍贯。
代码如下
data01.to_csv(r'D:\pandas\save csv 4.txt',
sep="|",
encoding="GBK",
columns=["人名","年龄"]
)运行结果
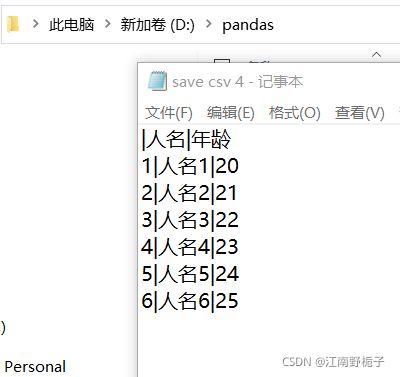
1.4.6 代码 6)line_terminator 的使用
假如我不想简单把每一行存储起来,我还想在每一行后面加点自己的东西,比如波浪符号,可以通过line_terminator="~~~~~~~\n"来实现。请注意别忘了加上"\n",否则就不会换行了
data01.to_csv(r'D:\pandas\save csv 5.txt',
sep="|",
encoding="GBK",
line_terminator="~~~~~~~\n")运行结果
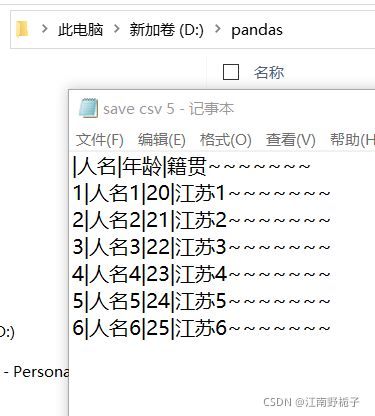
1.4.7 代码 7)index_label 参数的使用
如果想给 行名加上标签,可以使用 index_label 参数
data01.to_csv(r'D:\pandas\save csv 6.csv',
encoding="GBK",
index_label=["序号"])运行结果如下
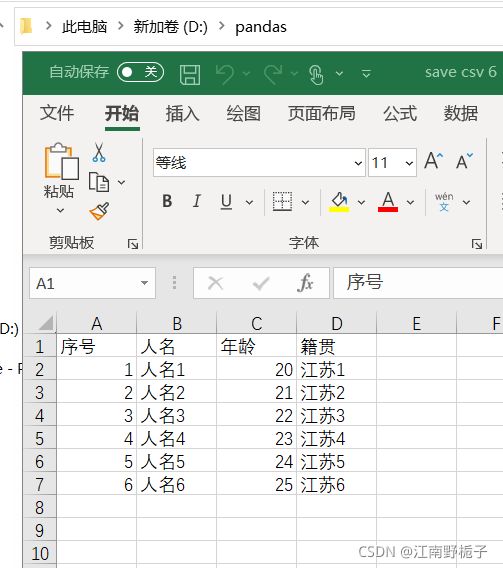
1.4.8 代码 8)追加模式写入
如果想将不同的 DataFrame 数据放到同一个文档中,需要不断地追加写入,而不是直接清理掉重新再来。应该使用 mode="a",这个有一点 Python 基础的都懂。
代码
data01.to_csv(r'D:\pandas\save csv 6.csv',
encoding="GBK",
mode="a")运行结果
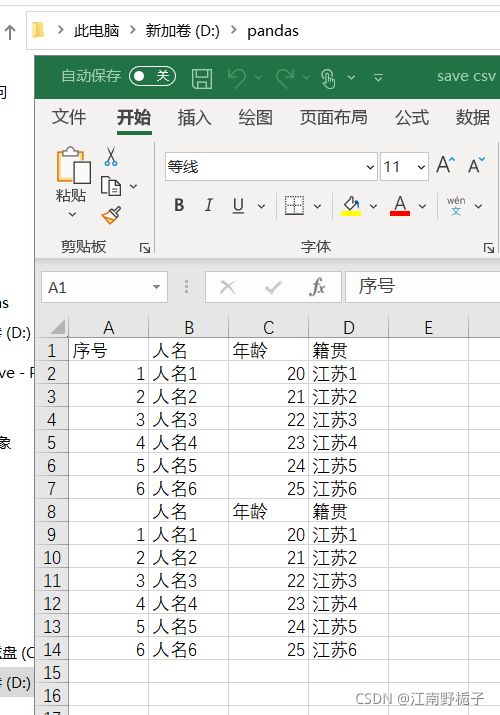
1.4.9 代码 9)float 值的写入
当前准备数据如下
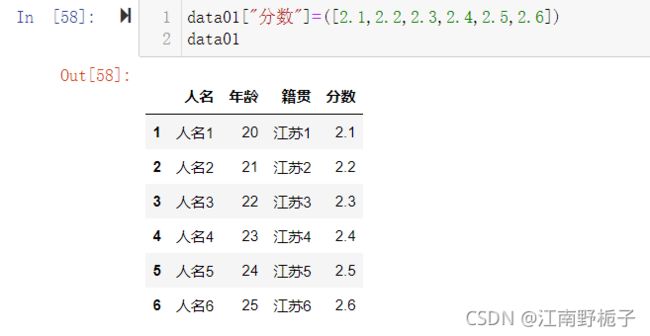
超朴实的代码就能实现下面的结果
data01.to_csv(r'D:\pandas\save csv 9.csv',encoding="GBK")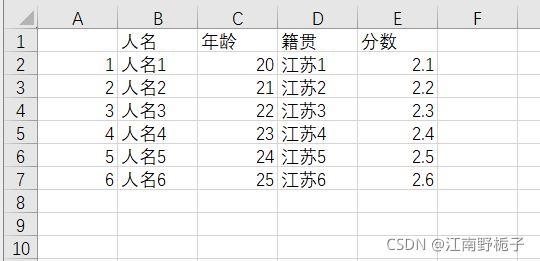
如果想 float 值后面精确到小数点后面3位,使用 float_format='%.3f'
先修改数据,然后 to_csv
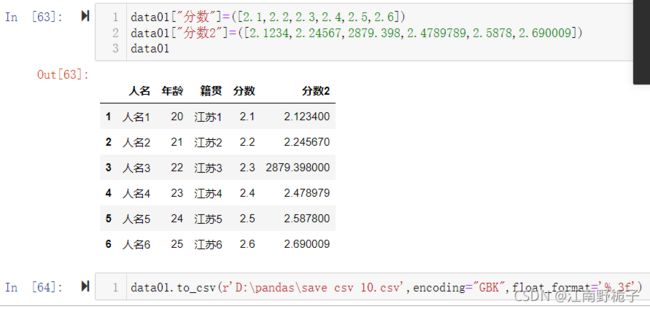
运行结果可见,数据已经被截断。
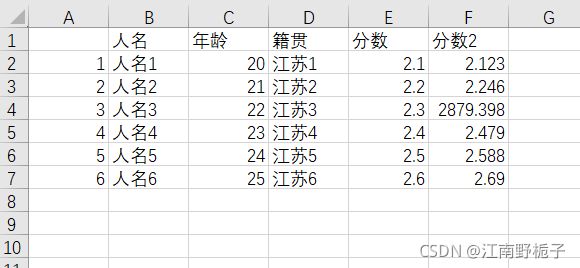
其余的参数等其他机会再一并讨论。
'''
要是大家觉得写得还行,麻烦点个赞或者收藏吧,想给博客涨涨人气,非常感谢!
'''