手势识别调研
文章目录
- 前言
- 一、手势识别简介
- 二、 二维手势识别
-
- 1. 经典算法模型
- 2.采集信息方案
- 三、三维手势识别
-
- 1.经典算法模型
- 2.采集深度信息设备方案
- 四、现有产品技术
-
- 1.阿里云静态手势识别
- 2.腾讯云手势识别
- 3.旷视手势识别
- 4.谷歌手势识别
- 5.百度手势识别
- 五、一些开源库资料
- 总结
-
- 二维手势识别
- 三维手势识别
- 建议与改进方向
- 参考文献
前言
提示:本文主要想针对单目摄像头实现静态与动态手势识别的功能,所做的资料调研工作。因此在采集设备中并不包含基于用户佩戴的手套控制器、谷歌眼镜、加速度计陀螺仪等来实现手势采集
一、手势识别简介
- 手势识别技术
大致可以分为三个等级:二维手型识别、二维手势识别、三维手势识别;其中前两者是基于画面中的二维坐标信息进行手势识别,而三维则由于包含深度信息(z坐标)在识别技术和系统上都有更复杂的实现方式。 - 二维手型识别
静态二维手势识别,识别的是手势中最简单的一类。在获取二维信息输入之后,可识别几个静态的手势,如握拳或五指张开,这些可应用在简单的视频播放控制上。但缺点在于不能对手势的持续变化产生感应,只能对程序预设定的动作相匹配后产生反应。 - 二维手势识别
相较手型识别,二维手势识别拥有了在二维平面中追踪手势的能力。其被广泛应用在电视上,可以完成拖动、点击、暂停等较为复杂的功能。但缺点在于不能在三维中实现真正的人机交互。 - 三维手势识别
可识别各种手型、手势与动作,但应用前提是不能单仅依赖普通摄像头,需要其他设备输入手指的深度信息 - 技术实现思维导图
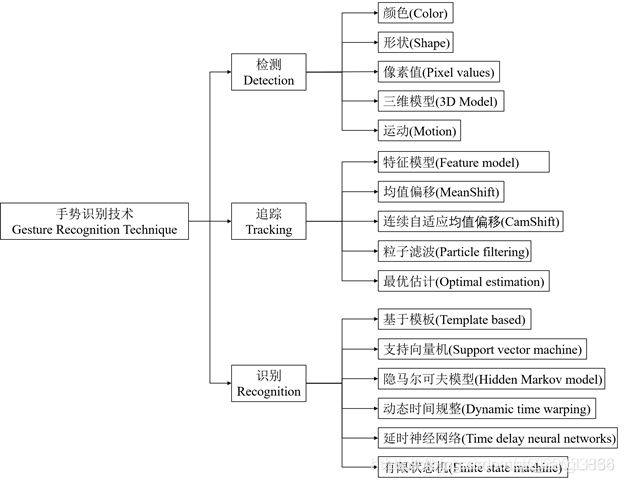
二、 二维手势识别
静态手势识别的研究对象是某个时间点上的手势图像,其识别结果与图片中手部的外观特征,如位置、轮廓、纹理有关,也与图像矩、图像特征向量以及区域直方图特征有关。
静态手势识别系统设计框架
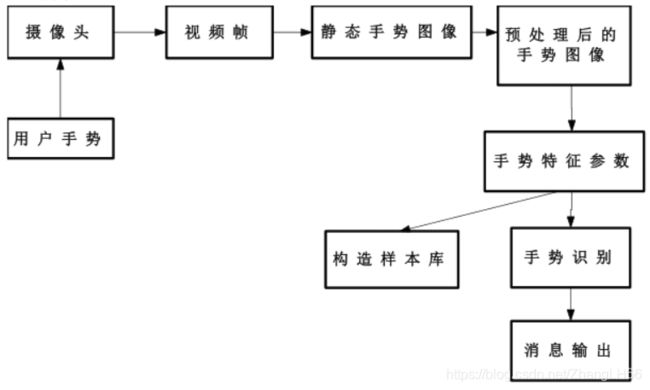
1. 经典算法模型
1.1 模板匹配技术
方案:
将待识别手势的特征参数与预先存储的模板特征参数进行匹配,通过测量两者之间的相似度来完成识别任务。《Hausdorff距离在手势识别中的运用》中利用Hausdorff距离模板匹配思想来实现手势的识别。将待识别手势和模板手势的边缘图像变换到欧式距离空间,求出它们的Hausdorff距离或修正Hausdorff距离。用该距离值代表待识别手势和模板手势的相似度。识别结果取与最小距离值对应的模板手势。
1.2 统计分析技术
方案:
从原始数据中提取特定的特征向量,对这些特征向量进行分类,而不是直接对原始数据进行识别。通过统计样本特征向量来确定分类器的基于概率统计理论的分类方法。
1.3 神经分类网络
方案
只要给定需要识别的手势,并在此基础上制作对应的数据集,随后使用一些简单的检测分类网络,即可训练出静态手势分类模型。
综合应用的一个设计案例流程
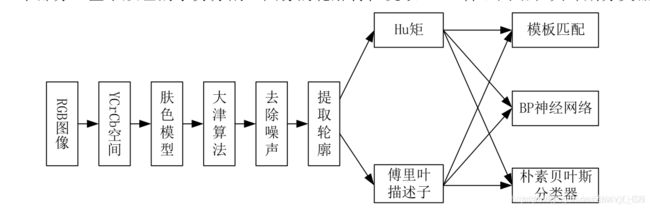
2.采集信息方案
普通的单目摄像头即可
三、三维手势识别
动态手势识别的研究对象是连续时间段上的图像序列,其识别结果与图片中手部的外观特征及序列中描述手部运动轨迹的时序特征有关。
动态手势识别技术框架
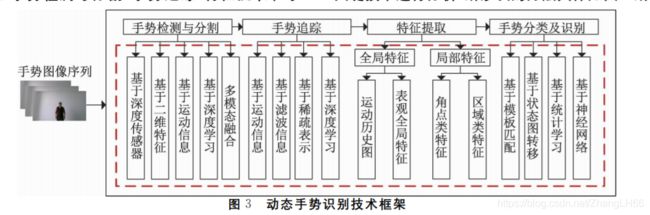
1.经典算法模型
1.1 机器学习算法
1.1.1 DTW算法
方案:
首先需要对训练集中的每个手势进行预处理,然后提取特征并将其归一化为序列模板,再对待测手势进行与训练手势一样的操作,最后将生成的结果与训练集中的每一个模板进行匹配分析,将距离最小模板的类别作为手势识别结果

评价与改进方向:
没有采用统计模型框架进行训练,也很难将上下文的各种知识用于图像识别算法中,因此在解决大数据量、复杂手势等问题时存在劣势。
1.1.2 HMM
方案:
在动态手势识别中,手部所做的一系列动作是观测序列,而手部所发生的动作为隐藏序列,HMM的任务就是从一系列可观测数据中确定隐藏数据中的内容。在动态手势识别中,每类手势对应一个隐马尔科夫模型;在训练时,首先将每个手势样本按类别划分,然后利用前向与后向算法为每类手势训练出对应的HMM模型。在测试时,待测样本利用前向算法与所有的HMM模型进行遍历,计算出每个HMM模型产生该手势序列的概率值,数值最大的HMM模型对应的类别便是待测样本的识别结果。

评价与改进方向:
对60个不同主题下的12种动态手势的识别,每类手势可获得了将近90%的识别精度。
1.2 深度学习算法
1.2.1基于Two Stream的算法
方案:
由空间网络(spatial network)和时序网络(temporal network)两个子网络组成,分别负责从RGB图片中挖掘出手部的空间信息和从堆叠的光流中挖掘出手部的运动信息,再将两种信息融合后构成时空信息用于视频分析任务。两个子网络都可采用AlexNet、VGG、ResNet、Inception等经典的2DCNNs构成。
首先从视频序列中随机采样一帧RGB图片作为spatial network的输入,并取该帧随后的5帧光流图片作为temporal network的输入;单帧RGB图片和堆叠的光流图片经过两个子网络分别学习对输入类别的预测概率向量,最后将这两个概率向量在类别的维度上取均值,得到最终的识别结果。
评价与改进方向:
在公开数据集上取得了良好的效果,但是在长时间的手势识别中会丢失信息,需要用时域分割网络等进行修缮
1.2.2基于3DCNNs的算法
方案:
从序列中同时提取出空间与时序信息,网络由多个3维卷积层、3维池化层以及激活函数组成。3维卷积层和3维池化层对特征图的操作分别与2维情形类似,仅有的差异在于2维卷积层和2维池化层只对一个特征图在宽和高的维度上进行操作,但3维卷积层和3维池化层对多个特征图同时在宽、高和时间维度上进行操作。
评价与改进方向:
简单的网络结构制约了其特征表达能力;加深网络深度需要引入残差网络,或者在在对输入序列进行特征提取前,预先引入注意力机制
2.采集深度信息设备方案
2.1. 结构光技术:
加载一个激光投射器,在激光投射器外面放一个刻有特定图样的光栅,激光通过光栅进行投射成像时会发生折射,从而使得激光最终在物体表面上的落点产生位移。当物体距离激光投射器比较近的时候,折射而产生的位移就较小;当物体距离较远时,折射而产生的位移也就会相应的变大。这时使用一个摄像头来检测采集投射到物体表面上的图样,通过图样的位移变化,就能用算法计算出物体的位置和深度信息,进而复原整个三维空间。
代表:
微软家XBOX 360的Kinect一代,其中包含RGB摄像头、红外投影仪和检测器,可通过以下任一方式映射深度结构光或飞行时间计算、麦克风阵列以及来自微软的软件和人工智能,使设备能够执行实时手势识别、语音识别以及最多四人的身体骨骼检测等功能。


产品优缺点:
在原理上依赖激光折射后产生的落点位移,所以在太近的距离上,折射导致的位移尚不明显,使用该技术就不能太精确的计算出深度信息,所以1米到4米是其最佳应用范围
2.2. 光飞技术:
加载一个发光元件,发光元件发出的光子在碰到物体表面后会反射回来。使用一个特别的CMOS传感器来捕捉这些由发光元件发出、又从物体表面反射回来的光子,就能得到光子的飞行时间。根据光子飞行时间进而可以推算出光子飞行的距离,也就得到了物体的深度信息。
代表:
目前的消费级TOF深度相机主要有:微软的Kinect 2、 MESA 的 SR4000 、Google Project Tango中使用的PMD Tech 的TOF深度相机等
产品优缺点:
缺点:
TOF深度相机对时间测量的精度要求较高,在近距离测量领域,尤其是1m范围内,TOF深度相机的精度与其他深度相机相比还具有较大的差距,这限制它在近距离高精度领域的应用。
优点:
TOF深度相机可以通过调节发射脉冲的频率改变相机测量距离;TOF深度相机与基于特征匹配原理的深度相机不同,其测量精度不会随着测量距离的增大而降低,其测量误差在整个测量范围内基本上是固定的;TOF深度相机抗干扰能力也较强。因此,在测量距离要求比较远的场合(如无人驾驶),TOF深度相机具有非常明显的优势
2.3. 多角成像:
使用两个或者两个以上的摄像头同时摄取图像,通过比对这些不同摄像头在同一时刻获得的图像的差别,使用算法来计算深度信息,从而多角三维成像。
代表:
Leap Motion公司的同名产品和Usens公司的Fingo,主要包含两个摄像头和红外传感器及光源设备
产品优缺点:
优点:
多角成像是三维手势识别技术中硬件要求最低,多角成像不需要任何额外的特殊设备,完全依赖于计算机视觉算法来匹配两张图片里的相同目标。没有结构光或者光飞时间这两种技术成本高、功耗大的缺点
缺点:
复现3d空间坐标的实现公式很复杂
四、现有产品技术
1.阿里云静态手势识别
- 功能描述
静态手势识别可以识别图片中的手势动作等。
- 应用场景
互动娱乐:异地通过远程视频,识别双方各自的手势,完成类似石头剪刀布,点赞等远程互动游戏。
电视遥控:当看电视找不到遥控器时,通过简单手势即可控制电视播放,简单又方便。
智能家电控制:通过手势发出简单指令,可以让智能家电完成各种预设配置的功能,例如停止播放音乐,打开空调,调节光线氛围等。
- 特色优势
支持手部与人体重合:可以在手部与人体其他颜色相近的部位重合情况下,准确识别手势。
低光照条件:在低光照场景下,手部区域检测准确率依然能保持较高水平。
远距离:在一般室内场景中,较远距离也可以检测到手部并识别手势。
抗模糊:在手部快速运动导致的图像一定程度模糊的情况下,依然可以部分识别出手势。
2.腾讯云手势识别
- 产品功能
识别方案中的静态手势识别定17种单手手势,如果检测到的手势不在这些类别当中,则会返回其它。下面给可识别的这17种手势的列表,包括:单手手势有:单手比心、确认、点赞、踩、爱您、胜利、摇滚、打枪、弹指、拳头、食指、中指、小指、手掌、数字3、数字4、数字6。
手势关键点识别:定位手的22个关键点的位置 指尖识别:只识别手尖位置 手势识别:基于视频识别近距离动作包括左滑、
右滑,远距离动作包括挥手、举手、敬礼等
- 性能
> 静态手势识别算法的正确率为95+% 手势关键点算法的识别正确率为94+% 手势动作识别的正确率为90+% 在 iPhone8 上
> 静态手势识别速度为22ms/fps, 手部关键点识别速度为28ms/fps 手势动作识别速度为30ms/fps
应用场景
互动娱乐、智能家居、VR/AR、智能车载、智能超市、工业检测
3.旷视手势识别
- 功能:
检测并返回图片或视频中的所有手部矩形框位置,以及手势的含义
- 优点:
19种常见手势
不限手势数量
适应各种光照
- 应用场景:
视频直播
在线教育互动
4.谷歌手势识别
- 功能:
交叉平台框架 可处理不同模态的感知数据 移动端实现了实时性,且可实现多个手的追踪 单帧推理21个3D关键点 可识别手势追踪和识别
- 优点:
> 开源完整的手势识别模型、在手机上实现了实时性能,可扩展到多只手

- 性能:

5.百度手势识别
- 功能:
手部检测 检测图像中的所有手部,识别手势类型,不限手势数量;支持自拍、他人拍摄、各种角度等多样化场景 识别24种手势
识别24种常见手势,支持单手手势和双手手势,包括拳头、OK、比心、作揖、作别、祈祷、我爱你、点赞、Diss、Rock、竖中指、数字等
- 优点:
> 丰富的手势
可识别24种常见手势,可根据业务需求灵活应用,适用于娱乐互动、手势操控各类场景
领先的算法
手势识别算法业界领先,识别准确率90%以上,近景自拍、远景他拍都能精准识别
稳定的保障
可提供企业级稳定、精确的大流量服务,拥有毫秒级识别响应能力及99.9%的可靠性保障
- 应用场景:
智能家居、视频直播、智能驾驶
五、一些开源库资料
- Kinect动态手势识别的库
CVRL FORTH HandTracker,提供了Windows和LInux上运行的脚本,唯一的遗憾是Linux上只能用Kinect2跟踪手势,Kinect V2的话要自己提供深度图和彩色图。
github地址
csdn使用介绍
- yolo系列加resnet实现手的位置识别
csdn:位置识别模型构建
- yolov5实现 手势字母识别
github地址
csdn介绍
- opencv手势识别
github地址
csdn介绍 - Alexnet手势识别
github地址
csdn介绍
备注:其实针对静态手势识别而言,就使用 letnet 即可,若闲精度不高加上Alexnet也可 ,也可以使用DNN之类的网络模型
总结
通过以上调研可知,相较于三维手势识别,二维手势识别不需要更复杂的深度模型及昂贵复杂的硬件系统设计。各个主流的技术研发公司也暂时都采用二维静态手势识别的方案,且在列的公司除了谷歌提供开源模型外,都仅提供api调用支持。
除此之外由于手势的特点:时间可变、空间可变、手势信息缺失或高度重复,二维与三维手势识别算法都有进步的空间。
二维手势识别
- 三维手势识别的难点在于:
>1. 针对不同的环境、不同的运动角度,研究者很难设计出一种对所有样本都适用的特征提取方法
三维手势识别
- 三维手势识别的难点在于:
> 1.动态手势复杂度高、每个动态手势并没有规范的动作指标
> 2.获取深度信息的设备昂贵
> 3.不同动作的手指关键区域大小不一
建议与改进方向
> 1.增加更多自然环境手势数据集(考虑在原有数据集的基础上进行数据增强)
> 2.对输入模型的手部序列进行预处理,减少环境干扰因素
> 3.在手势特征提取时需要考虑到尺度旋转和平移不变性
> 4.在连续的动态手势算法中,实现对每个动态手势的开始点与结束点的精准定位、对每个分割出来的单一手势进行精确识别
参考文献
以上内容来源于各个技术文章、论文及各公司官网资料总结,若有错漏还请谅解
知乎:三维手势识别
csdn单目手势识别算法总结:
csdn:TOF简介
阿里云静态手势识别
谷歌手势识别文档
csdn:静态手势识别
百度手势识别平台
旷视手势识别平台
腾讯手势识别平台