【神经网络】MP神经网络模型(附实例代码讲解)
MP神经网络模型
1.MP模型介绍
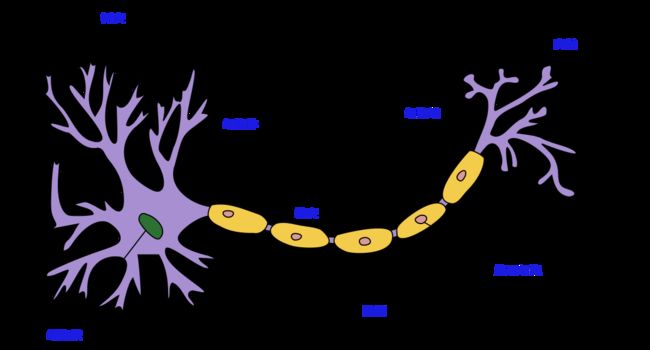
1.1 生物神经元
1.2 人工神经元
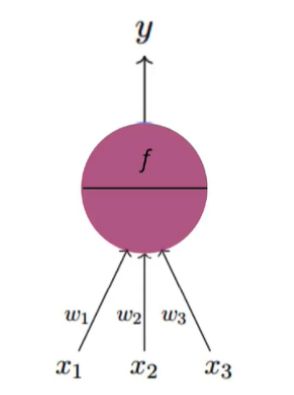
- x1,x2,x3是与生物神经元中的树突相对应的输入。
- w1,w2,w3代表对应于突触的权重。
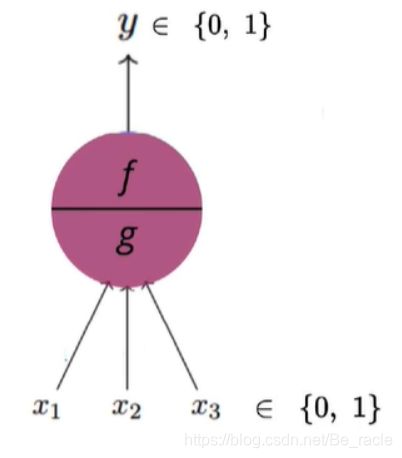
1.3 MP神经元模型
模型
- 输入只能是布尔型。
- 输出只能是布尔型。
- g是聚合输入,f根据聚合进行决策。
损失函数
损失往往是模型在预测时所产生的误差,也可能是真实值与预测值之间的差。
我们采用真实值与预测值之间的差的平方,以消除在真实值为0且预测值为1时可能出现的负号。
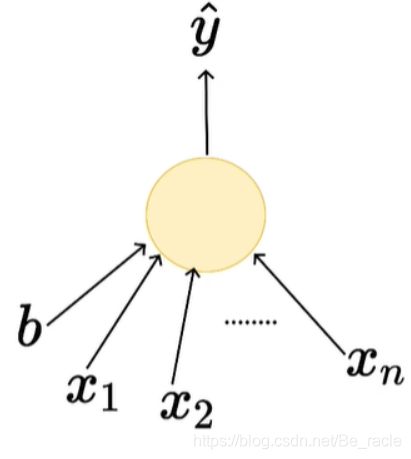
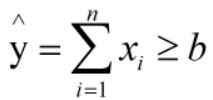
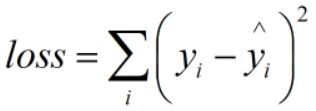
学习算法
我们希望损失函数最小,因此我们要加入b的值,然后开始逐一输入,以便获得的输出与真实值相同或接近。
在MP神经元模型的情况下,我们只能有一个参数,因此我们可以使用蛮力搜索技术来计算b的值。
考虑到我们具有n个特征,因此b的值必须在0到n的范围内。因为输入是离散值,所以b也是具有离散值。
评估
我们的模型将如何处理之前从未见过的数据或测试数据。
我们将在准确性的基础上评估我们的MP神经元模型。准确性 = 正确预测数 / 总数。
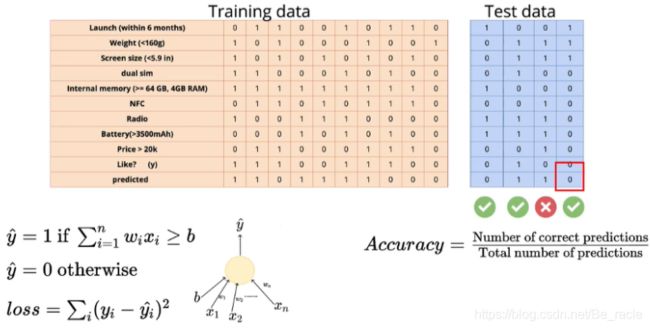
在上面的示例中,测试集上的精度为3/4,相当于75%。
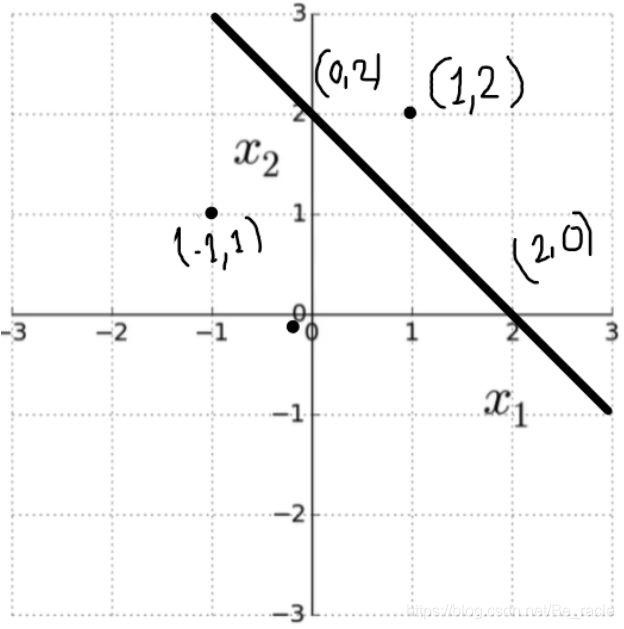
MP神经元模型的几何原理
直线的方程为:y = mx + c,将x替换为x1,将y替换为x2,得:x2 = mx1 + c,即:mx1 -x2 + c。
一般直线方程可以写成:ax1 + bx2 + c = 0。对于下图中的直线:a = 1,b = 1,c = -2。
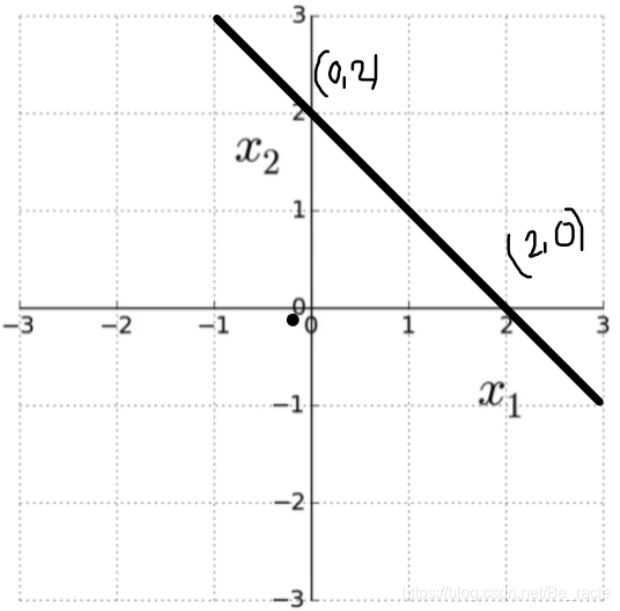
在下图中,我们可以看到两个点(1,2)和(-1,1)。考虑点(1,2),将其代入x1 + x2 - 2,得1。
- 如果 ax1 + bx2 + c > 0,则点在该直线上方。
- 如果 ax1 + bx2 + c < 0,则点在该直线下方。
- 如果 ax1 + bx2 + c = 0,则点在直线上。
2.实例
导入需要的包。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn.datasets
from sklearn.metrics import accuracy_score #精度分类得分
from sklearn.model_selection import train_test_split #将数组或矩阵拆分为随机训练和测试子集
Scikit-learn(0.24.1)的API参考:https://scikit-learn.org/stable/modules/classes.html
这里我使用的数据集是一个sklearn自带的乳腺癌数据集。
一共有569个样本。
breast_cancer = sklearn.datasets.load_breast_cancer()
X = breast_cancer.data
Y = breast_cancer.target
结果分为“恶性”和“良性”。
list(breast_cancer.target_names)
![]()
print(X)

print(Y)

data = pd.DataFrame(breast_cancer.data,columns=breast_cancer.feature_names)
data['class'] = breast_cancer.target
data
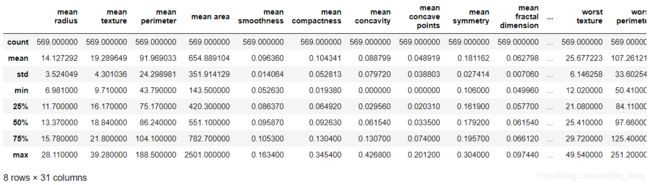
数据集的相关统计信息。
data.describe()
# 1表示良性,0表示恶性
data['class'].value_counts()

划分数据集和测试集,测试集的大小为总体数据的10%。设置stratify=Y : 按照数据集中Y的比例分配给train和test,使得train和test中各类别数据的比例与原数据集的比例一致。通常在数据集的分类分布不平衡的情况下会用到stratify。
X = data.drop('class',axis=1)
Y = data['class']
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size=0.1, stratify=Y, random_state=0)
print('Target: ',Y.mean(), Y_train.mean(), Y_test.mean())
![]()
可以看到数据集划分基本上是均匀的。
plt.figure(figsize=(8,6))
plt.plot(X_train.T,'o')
plt.xticks(rotation='vertical');
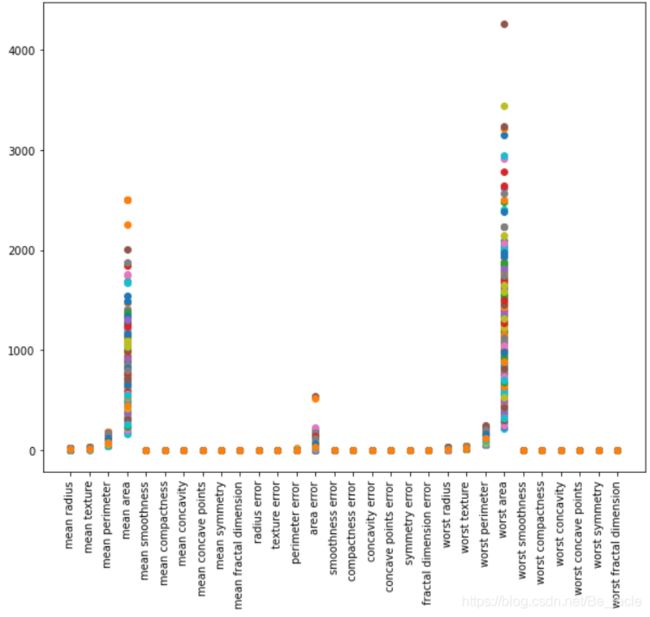
因为MP神经元模型仅能把0或1作为输入,所以我们要把数据进行处理,划分为0和1两类。
X_binarise_train = X_train.apply(pd.cut, bins=2, labels=[1,0])
X_binarise_test = X_test.apply(pd.cut, bins=2, labels=[1,0])
plt.figure(figsize=(8,6))
plt.plot(X_binarise_train.T,'o')
plt.xticks(rotation='vertical');
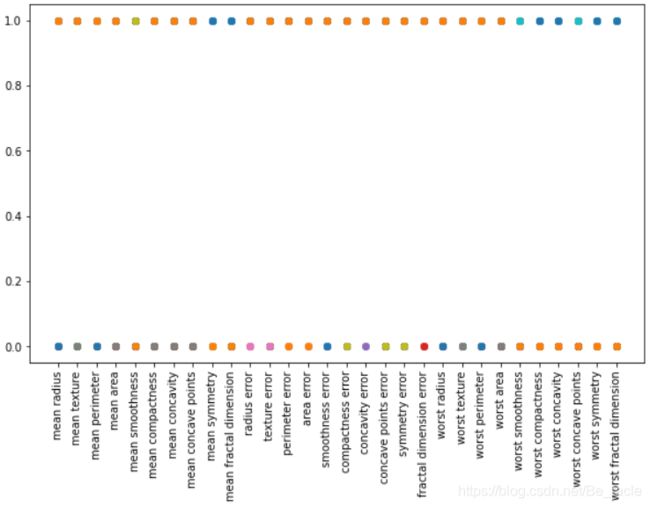
后面我们需要用数组进行计算,所以获取value。
X_binarise_train = X_binarise_train.values
X_binarise_test = X_binarise_test.values
构建MP神经元类。
class MPNeuron:
def __init__(self):
self.b = None
def model(self,x):
return (sum(x) >= self.b)
def predict(self,X):
Y = []
for x in X:
Y.append(self.model(x))
return np.array(Y)
def fit(self,X,Y):
accuracy = {}
for b in range(X.shape[1] + 1):
self.b = b
Y_pred = self.predict(X)
accuracy[b] = accuracy_score(Y_pred,Y)
best_b = max(accuracy, key = accuracy.get)
self.b = best_b
print('最佳b值:', best_b)
print('最高准确率为:', accuracy[best_b])
mp_neuron = MPNeuron()
mp_neuron.fit(X_binarise_train,Y_train)

w = mp_neuron.predict(X_binarise_test)
accuracy_score(w,Y_test)
![]()