Rust 从入门到精通10-所有权
在介绍rust 所有权时,我们先介绍内存管理的一些基础概念。
1、堆和栈
一个进程在执行的时候,它所占用的内存虚拟空间一般被分割为好几个区域,我们称为”段“(Segment)。常见的几个段如下:
①、代码段:编译后的机器码存放的区域。通常是只读的。
②、bss 段:存放未初始化的全局变量和静态变量的区域。
③、数据段:存放已初始化的全局变量和静态变量的区域。
④、函数调用栈(call stack segment):存放函数参数、局部变量以及其它函数调用相关信息的区域。
⑤、堆(heap):存放动态分配内存的区域。
前面三个都好理解,我们这里重点介绍一下函数调用栈和堆。
函数调用栈简称为”栈“,基于数据结构栈来实现的,具有”后入先出“(LIFO) 的特点,最先进入的数据也是最后出来的数据。CPU有专门的指令可以用于入栈和出栈的操作。当一个函数被调用时,就会有指令把当前指令的地址压入栈内保存,然后跳转到被调用的函数中执行。函数返回的时候,就会把栈里面先前的指令地址弹出来继续执行。栈中的所有数据必须在编译器确定空间大小。
堆是动态分配预留的空间。和栈不一样,在编译器大小未知或大小可能变化的数据是存储在堆上的。当向堆中存放数据时,首先请求一定大小的空间,操作系统在堆中的某处找到一块足够大小的空位,把它标记为已使用,并返回一个该位置地址的指针(point),这个过程称为”在堆上分配内存“(对应栈上不能称为”分配“,因为大小已知,可以称为”存储“)。每个线程都有一个栈,但是每一个应用程序通常只有一个堆,在堆上分配和释放内存没有固定模式,用户可以任何时候分配和释放它,这就使得哪部分堆已经被分配和被释放变得异常复杂;有许多定制的堆内存分配策略用来为不同的使用模式下调整堆的性能。
通常操作系统提供了在堆上分配和释放内存的系统调用,但是用户不直接使用这个系统调用,而是使用封装更好的”内存分配器“(Allocator)。比如在C语言里面,运行时(runtime)就提供了 malloc 和 free 这两个函数用来管理内存。
堆和栈的区别总结如下:
一、栈上保存的局部变量在退出当前作用域的时候会自动释放。
二、堆上分配的空间没有作用域,需要手动释放。
三、一般栈上分配的空间大小是编译阶段就可以确定的(C 语言里面的VLA 除外)。
四、栈有一个确定的最大长度,超过这个长度就会产生”栈溢出“(stack overflow)。
五、堆的空间通常更大一点,堆的内存耗尽了,就会产生”内存分配不足“(out of memory)
2、内存安全
堆和栈,是内存分配的基础,理解了这个,我们再看什么是内存安全。
【内存安全】在维基百科上是这么定义的:
Memory safety is the state of being protected from various software bugs and security
vulnerabilities when dealing with memory access, such as buffer overflows and dangling pointers.
翻译过来:内存安全是指在处理内存访问时免受各种软件bug和安全漏洞(如缓冲区溢出和悬浮指针)的保护状态。
其实内存安全就是避免产生段错误”segmentation fault“,简称为”segfault",段错误通常是这样形成的:
进程空间中每个段通过硬件 MMU 映射到真正的物理空间中,在这个映射过程中,我们还可以给不同的段设置不同的访问权限,比如代码段就是只能读不能写;进程在执行过程中,如果违反了这些权限,CPU 会直接产生一个硬件异常,硬件异常会被操作系统内核处理,一般内核会向对应的进程发送一条信号;如果没有实现自己特殊的信号处理函数,默认情况下,这个进程会直接非正常退出;如果操作系统打开了 core dump 功能,在进程退出的时候操作系统会把它当时的内存状态、寄存器状态以及各种相关信息保存到一个文件中,供用户以后调试使用。
以下是一些“内存不安全的例子”:
一、空指针
解引用空指针是不安全的,这块地址空间一般是受保护的,对空指针解引用在大部分平台上都会产生 segfault;
二、野指针
野指针是未初始化的指针。它的值取决于它这个位置以前遗留下来的什么值。所以它可能指向任意一个地方。对它解引用,可能会造成segfault,也可能不会,全凭运气。但无论如何,这都不会是你预期内的行为,是一定会产生bug的。
三、悬空指针
悬空指针是指内存空间被释放了之后,继续使用。它和野指针类似,同样会读写已经不属于这个指针的内容。
四、使用未初始化内存
不只是指针类型,任何一种类型不初始化就直接使用都是危险的。造成的后果我们完全无法预测。
五、非法释放
内存分配和释放要配对。如果对同一个指针释放两次,会制造出内存错误。如果指针并不是内存分配器返回的值,对其执行释放操作,也是危险的。
六、缓冲区溢出
指针访问越界了。结果也是类似野指针,会读取或者修改临近内存空间的值,造成危险。
七、执行非法函数指针
如果一个函数指针不是准确指向一个函数地址,那么调用这个函数指针会导致一段随机数据被当做指令来执行,这是非常危险的。
八、数据竞争
在有并发的情况下,针对同一块内存同时读写,且没有同步措施。
3、内存回收方式
上面我们介绍了内存不安全的各种情况,那么如何避免内存不安全导致的segfault错误呢?
为此很多语言都有很多代码标准来规范程序员的行为,而且对一些垃圾内存管理通常有两种方式:
①、自动GC:比如Java、kotlin等语言,有自动垃圾回收机制,在程序运行过程中,会自动回收内存,而程序员不需要担心;
②、手动GC:比如C、C++等语言,没有垃圾自动回收机制,程序员必须手动分配和释放内存。
上面两种方式各有优缺点,自动GC虽然方便了程序员,但是会降低程序运行性能(会存在STW问题-GC事件发生过程中,会产生应用程序的停顿);
手动GC没有额外的性能开销,精准的手动管理,能够极致的利用机器的性能,但是对程序员要求较高,一不小心容易造成内存泄露。
对此衍生第三种内存管理方式,也就是 rust 的所有权概念。通过所有权系统管理内存,编译器在编译时会根据一系列的规则进行检查,这是一种独一无二的管理方式,从编译器就杜绝了很多内存安全问题。
4、所有权
4.1 所有权规则
我们先看看所有权的三条规则,需要牢记。
①、每个值在Rust中都有一个变量来管理它,这个变量就是这个值、这块内存的所有者;
②、每个值在一个时间点上有且只有一个所有者;
③、当所有者(变量)离开作用域时,这个值将被销毁。
之所以存在这些规则,就是为了更好的管理 堆 内存数据,解决如下问题:
1、跟踪代码的哪些部分正在使用 heap 的哪些数据;
2、最小化 heap 上的重复数据量;
3、清理 heap 上未使用的数据以避免空间不足。
4.2 所有者
所有权的前面两条规则,我们可以看下面的实例:
fn main() {
let s = String::from("hello");
let s1 = s;
println!("{}",s);
}
首先声明一个值为”hello" 的变量 s,这里的s便是这个值的所有者。
上面的代码编译会报错:
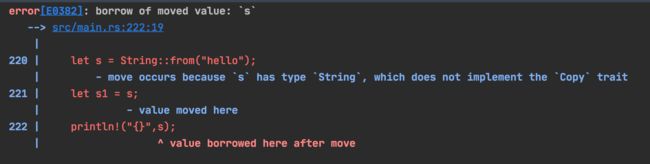
这是因为违反了所有权的第二条规则:每个值在一个时间点上有且只有一个所有者;
因为第 3 行代码,我们将 s 的所有权移交给了 s1,这时候 s 就已经被销毁了。第 4 行代码去打印 s 的值,就会报错了。
4.2 作用域
在所有权的规则中出现了作用域的概念,那么什么是作用域?
简单理解:
作用域:值在程序中的有效范围。
比如:
{ // s 在这里无效, 它尚未声明
let s = "hello"; // 从此处起,s 是有效的
// 使用 s
} // 此作用域已结束,s 不再有效
上面的实例,s 进入作用域是有效的,出了作用域则无效。
4.4 移动语义
一个变量可以把它拥有的值转移给另外一个变量,称为“所有权转移”。
赋值语句、函数调用、函数返回等,都有可能导致所有权转移。
rust中所有类型的默认语义便是“移动语义(move)”。这也是为什么下面这段代码会报错:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{}",s1);
}
let s2 = s1 。表示 s1 的所有权移交给 s2了,那么 s1 便无效,不能再被访问了。

前面我们说过当变量离开作用域后,Rust 自动调用 drop 函数并清理变量的堆内存。假设上面没有进行所有权转移,当 s1 和 s2 离开作用域时,都会尝试释放相同的内存,会造成 二次释放(double free)的错误。
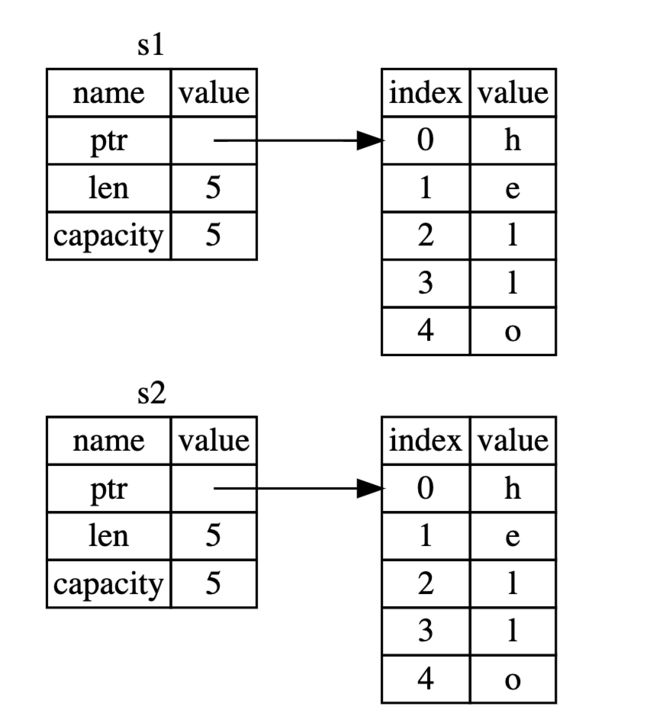
所以 移动语义 实际上如下:

PS: 上图灰色表示无效。
在别的语言中,有一种说法叫 浅拷贝(shallow copy),这里需要和 rust 的 移动(move) 区分一下:
浅拷贝 通常是复制对象的引用,但是 rust 不仅复制引用,还会让原对象失效,所以取了个新的名词-移动。
4.5 复制语义
假设我们真想复制 heap 上的数据,应该怎么办呢?
在 rust 中,只需要将上面的代码的第 3 行代码换成
let s2 = s1.clone();
那么便会编译通过了。调用 clone() 方法,会导致值在堆上重新复制一份,原来的变量依然有效,而且新增了一个新的变量。
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
println!("{}",s1);
}
如果说 移动语义是 剪切-粘贴,那么 复制语义 就是 复制-粘贴。
我们再看下面这段代码:
fn main() {
let s1 = 1;
let s2 = s1;
println!("{}",s1);
}
将 s 由字符串换成了整型,我们发现编译通过了,那这是为什么呢?
因为Rust 有一个叫做 Copy trait 的特殊注解,如果一个类型拥有 Copy trait,一个旧的变量在将其赋值给其他变量后仍然可用。
我们可以从性能的角度去考虑这个设计,像整型这样的在编译时已知大小的类型被整个存储在栈上,所以拷贝其实际的值是快速的,所以默认是复制语义。
而像字符串是存储在堆上的,大小动态变化,如果比较大,其拷贝是比较花时间的,所以默认是移动语义。
一个通用的规则,任何简单标量值的组合可以是 Copy 的,不需要分配内存或某种形式资源的类型是 Copy 的。如下是一些 Copy 的类型:
- 所有整数类型,比如
u32。 - 布尔类型,
bool,它的值是true和false。 - 所有浮点数类型,比如
f64。 - 字符类型,
char。 - 元组,当且仅当其包含的类型也都是
Copy的时候。比如,(i32, i32)是Copy的,但(i32, String)就不是。
4.6 引用
假设有这样一种情况,我们声明了一个变量,将这个变量传入一个函数,计算其长度返回,然后要能接着使用该变量。
实例如下:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: String) -> usize {
s.len()
}
编译之后报错:
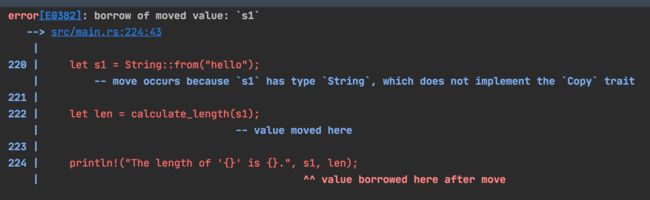
这很好理解,s1 没有实现 copy trait,走的是move 语义,在将 s1 传入函数 calculate_length() 之后,所有权也给到了函数,函数执行完毕,s1也被销毁。之后在打印 s1 肯定就报错了。
那么怎么解决呢?
给函数传递引用,而不是所有权,引用通过 & 符号实现。
实例代码改为如下:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
这时候就能正常编译了。如果声明为 mut s1,传入的是 &mut s1,那么还可以修改 s1 的值。
fn main() {
let mut s1 = String::from("hello");
let len = calculate_length(&mut s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &mut String) -> usize {
*s = String::from("world");
s.len()
}
4.7 借用
和“引用”相关联的是“借用”,上面的实例,将 s1 的引用传递给函数 calculate_length(),那么获取引用的这个函数称为“借用”。
借用指针的语法使用 “&” 和 “&mut” 符号表示,前者表示只读借用,后者表示可读写借用。借用指针(borrow pointer)也可被称为 “引用(Reference)"。借用指针和普通指针的内部数据是一模一样的,唯一的区别是语义层面上的。它的作用是告诉编译器,它对指向的这块内存区域没有所有权。
关于借用,有如下几条规则:
一、借用指针不能比它指向的变量存活的时间更长;
二、&mut 型借用只能指向本身具有 mut 修饰的变量,对于只读变量,是不可以有 &mut 型借用;
三、&mut 型借用指针存在的时候,被借用的变量本身会处于“冻结”状态;
四、如果只有 & 型借用指针,那么能同时存在多个;如果存在 &mut 型借用指针,那么只能存在一个;如果同时存在 & 和 &mut 型借用指针,那么会编译报错;
获取一个对象的引用而不是所有权。
对于所有权来讲,任何分配在堆上的空间,实际上在同一个作用域{},限定了只能存在一个非引用式的变量,称之为所有权,它购买了这个空间,其他的变量只能通过引用的方式来访问这个空间,Rust 释放内存也是通过这个拥有所有权的变量来进行的。而生命周期理论上是对作用域的一个补丁,以支持在作用域之外可以使用变量引用。
所以这个问题的本质是,堆上的空间只有一个变量拥有所有权,这个变量超出作用域后,直接free就好了。