当谈起分库分表时我们该关注什么
当谈起分库分表时我们该关注什么
- 一、为什么分库分表
-
- 1.1 为什么分库
- 1.2 为什么分表
- 二、如何分表分库
-
- 1. 垂直切分
- 2.水平切分
- 二、分库分表面临的问题和对策
-
- 1. 分布式事务问题
- 2. 跨节点 JOIN 查询问题
- 3.跨节点排序、分页、函数计算问题
- 4. 全局主键 ID 问题
-
- UUID实现全局 ID
- redis
- Twitter 开源的分布式 ID 生产算法—snowflake
- 设置数据库 sequence 或者表自增字段步长
- 5. 扩容问题-2倍数
- 笔记
- 三、分库分表设计方案
-
- 1. proxy模式
-
- 优点:
-
- 多语言支持
- 对业务开发同学透明
- 缺点:
-
- 实现复杂
- proxy本身需要保证高可用
- 租户隔离
- 2. smart-client模式
-
- 优点:
-
- 实现简单
- 天然去中心化
- 缺点:
-
- 通常仅支持某一种语言
- 版本升级困难
- 3. ORM框架代理 (比较少用)
-
- 笔记
- 四、业界产品
-
- 1. 整体对比
- 2.shardingSphere
-
- Sharding-JDBC
-
- 对分布式事务的支持- 弱 XA和柔性事务(BASE)
- 场景
- 适合场景
- 不合适的场景
- 3. mycat
-
- 支持XA事务
- 笔记
一、为什么分库分表
首先呢,能不分表分库就不要分表分库。为什么要分库分表,用大白话说 就是数据库快扛不住了
1.1 为什么分库
瓶颈来自数据库的压力:数据库出现性能瓶颈,对外表现有几个方面:
(1)大量请求阻塞
在高并发场景下,大量请求都需要操作数据库,导致连接数不够了,请求处于阻塞状态。
(2)SQL 操作变慢
如果数据库中存在一张几千万甚至上亿数据量的表,一条 SQL 没有命中索引会全表扫描,这个查询耗时会非常久。
(3)存储出现问题
业务量剧增,单库数据量越来越大,给存储造成巨大压力。
(4)写并发能力也是有限的,还会带来一定的问题:比如:写压力高时主从同步延时,至于为什么会延时,可以参考下图:
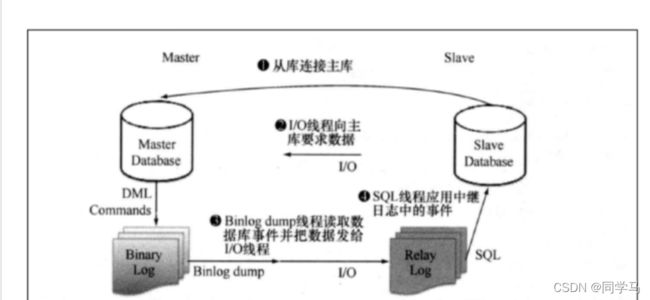 如图:其中从库是一个线程异步去拉取,且从relay Log 到slave Database 也是需要顺序读到语句之后 进行随机的磁盘读写,也会延时
如图:其中从库是一个线程异步去拉取,且从relay Log 到slave Database 也是需要顺序读到语句之后 进行随机的磁盘读写,也会延时
1.2 为什么分表
有一组数据可以参考:
基本指标: 库物理文件大小<100G;表<100;字段<200 ;单表记录数<500W
经测试在单表1000万条记录以下时,写入读取性能是比较好的. 这样在留点buffer,那么单表全是数字类型的保持在800万条记录以下, 有字符型的单表保持在500万以下。当预估业务单表数据量大,或是已经出现查询慢等情况,考虑分表。
阿里巴巴P3C规范给出一个推荐:
【推荐】单表行数超过500万行或者单表容量超过2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
二、如何分表分库
通常,分表分库分为垂直切分和水平切分两种。

1. 垂直切分
通俗的说就是竖着切。
垂直分库
是指根据业务来分库,不同的业务使用不同的数据库。 例如,订单和消费券在抢购业务中都存在着高并发,如果同时使用一个库,会占用一定的连接数,所以我们可以将数据库分为订单库和促销活动库。
垂直分表
则是指根据一张表中的字段,将一张表划分为两张表 ,其规则就是将一些不经常使用的字段拆分到另一张表中。例如,一张订单详情表有一百多个字段,显然这张表的字段太多了,一方面不方便我们开发维护,另一方面还可能引起跨页问题。这时我们就可以拆分该表字段,解决上述两个问题。
2.水平切分
通俗的说就是横着切。
水平分表 则是将表中的某一列作为切分的条件,按照某种规则(Range 或 Hash 取模)来切分为更小的表。水平分表只是在一个库中,如果存在连接数、I/O 读写以及网络吞吐等瓶颈,我们就需要考虑将水平切换的表分布到不同机器的库中,这就是水平分库分表了。
水平分库 结合以上垂直切分和水平切分,我们一般可以将数据库分为:单库单表 - 单库多表 - 多库多表。
在平时的业务开发中,我们应该优先考虑单库单表;如果数据量比较大,且热点数据比较集中、历史数据很少访问,我们可以考虑表分区;如果访问热点数据分散,基本上所有的数据都会访问到,我们可以考虑单库多表;如果并发量比较高、海量数据以及每日新增数据量巨大,我们可以考虑多库多表。
二、分库分表面临的问题和对策
1. 分布式事务问题
在提交订单时,除了创建订单之外,我们还需要扣除相应的库存。而订单表和库存表由于垂直分库,位于不同的库中,这时我们需要通过分布式事务来保证提交订单时的事务完整性。
通常,我们解决分布式事务有两种通用的方式:两阶事务提交(2PC)以及补偿事务提交(TCC)。
有一些中间件已经帮我们封装好了这两种方式的实现,例如 Spring 实现的 JTA ( Java Transaction API ),目前阿里开源的分布式事务中间件 Fescar,就很好地实现了与 Dubbo 的兼容。
2. 跨节点 JOIN 查询问题
用户在查询订单时,我们往往需要通过表连接获取到商品信息,而商品信息表可能在另外一个库中。
有几种方案可以解决:(用空间换时间)
字段冗余:把需要关联的字段放入主表中,避免 join 操作;
数据抽象:通过ETL等将数据汇合聚集,生成新的表;
全局表:比如一些基础表可以在每个数据库中都放一份;
应用层组装:将基础数据查出来,通过应用程序计算组装;
3.跨节点排序、分页、函数计算问题
我们知道,当用户在订单列表中查询所有订单时,可以通过用户 ID 的 Hash 值来快速查询到订单信息,而运营人员在后台对订单表进行查询时,则是通过订单付款时间来进行查询的,这些数据都分布在不同的库以及表中,此时就存在一个跨节点分页查询的问题了。
通常一些中间件是通过在每个表中先查询出一定的数据,然后在缓存中排序后,获取到对应的分页数据。这种方式在越往后面的查询,就越消耗性能。
通常我们建议使用两套数据来解决跨节点分页查询问题,一套是基于分库分表的用户单条或多条查询数据,一套则是基于 Elasticsearch、Solr 存储的订单数据,主要用于运营人员根据其它字段进行分页查询。为了不影响提交订单的业务性能,我们一般使用异步消息来实现 Elasticsearch、Solr 订单数据的新增和修改。
4. 全局主键 ID 问题
在分库分表后,主键将无法使用自增长来实现了,在不同的表中我们需要统一全局主键 ID。因此,我们需要单独设计全局主键,避免不同表和库中的主键重复问题。
UUID实现全局 ID
即随机生成一个 32 位 16 进制数字,这种方式可以保证一个 UUID 的唯一性
优点 最方便快捷的方式 水平扩展能力以及性能都比较高。
**缺点 **它是一个比较长的字符串,连续性差,费空间;如果作为主键使用,性能相对来说会比较差
redis
我们也可以基于 Redis 分布式锁实现一个递增的主键 ID,这种方式可以保证主键是一个整数且有一定的连续性,但分布式锁存在一定的性能消耗。
Twitter 开源的分布式 ID 生产算法—snowflake
snowflake 是通过分别截取时间、机器标识、顺序计数的位数组成一个 long 类型的主键 ID。这种算法可以满足每秒上万个全局 ID 生成,不仅性能好,而且低延时。
设置数据库 sequence 或者表自增字段步长
比如说,现在有 8 个服务节点,每个服务节点使用一个 sequence 功能来产生 ID,每个 sequence 的起始 ID 不同,并且依次递增,步长都是 8。

适合的场景:在用户防止产生的 ID 重复时,这种方案实现起来比较简单,也能达到性能目标。但是服务节点固定,步长也固定,将来如果还要增加服务节点,就不好搞了。
5. 扩容问题-2倍数
尽量使用 2 的倍数来设置表数量
随着用户的订单量增加,根据用户 ID Hash 取模的分表中,数据量也在逐渐累积。此时,我们需要考虑动态增加表,一旦动态增加表了,就会涉及到数据迁移问题。
我们在最开始设计表数据量时,尽量使用 2 的倍数来设置表数量。当我们需要扩容时,也同样按照 2 的倍数来扩容,这种方式可以减少数据的迁移量。
笔记
1 能不分表分库,就不要分表分库。
2 一旦需要分表分库,尽量避免消耗性能的跨表跨库 JOIN 查询、分页查询以及跨库事务等操作。
三、分库分表设计方案
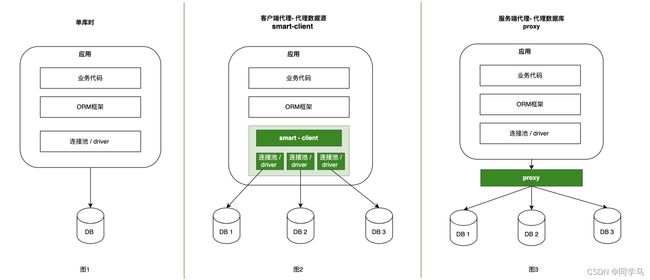
典型的数据库中间件设计方案有2种:smart-client 、proxy。下图2和3演示了这两种方案的架构:
1. proxy模式
我们独立部署一个代理服务,这个代理服务背后管理多个数据库实例。而在应用中,我们通过一个普通的数据源(c3p0、druid、dbcp等)与代理服务器建立连接,所有的sql操作语句都是发送给这个代理,由这个代理去操作底层数据库,得到结果并返回给应用。在这种方案下,分库分表和读写分离的逻辑对开发人员是完全透明的。
优点:
多语言支持
也就是说,不论用的php、java或是其他语言,都可以支持。以mysql数据库为例,如果proxy本身实现了mysql的通信协议,那么你就可以将其看成一个mysql 服务器。mysql官方团队为不同语言提供了不同的客户端驱动,如java语言的mysql-connector-java,python语言的mysql-connector-python等等。因此不同语言的开发者都可以使用mysql官方提供的对应的驱动来与这个代理服务器建通信。
对业务开发同学透明
由于可以把proxy当成mysql服务器,理论上业务同学不需要进行太多代码改造,既可以完成接入。
缺点:
实现复杂
因为proxy需要实现被代理的数据库server端的通信协议,实现难度较大。通常我们看到一些proxy模式的数据库中间件,实际上只能代理某一种数据库,如mysql。几乎没有数据库中间件,可以同时代理多种数据库(sqlserver、PostgreSQL、Oracle)。
proxy本身需要保证高可用
由于应用本来是直接访问数据库,现在改成了访问proxy,意味着proxy必须保证高可用。否则,数据库没有宕机,proxy挂了,导致数据库无法正常访问,就尴尬了。
租户隔离
可能有多个应用访问proxy代理的底层数据库,必然会对proxy自身的内存、网络、cpu等产生资源竞争,proxy需要具备隔离的能力。
2. smart-client模式
业务代码需要进行一些改造,引入支持读写分离或者分库分表的功能的sdk,这个就是我们的smart-client。通常smart-client是在连接池或者driver的基础上进行了一层封装,smart-client内部与不同的库建立连接。应用程序产生的sql交给smart-client进行处理,其内部对sql进行必要的操作,例如在读写分离情况下,选择走从库还是主库;在分库分表的情况下,进行sql解析、sql改写等操作,然后路由到不同的分库,将得到的结果进行合并,返回给应用。
优点:
实现简单
proxy需要实现数据库的服务端协议,但是smart-client不需要实现客户端通信协议。原因在于,大多数据库厂商已经针对不同的语言提供了相应的数据库驱动driver,例如mysql针对java语言提供了mysql-connector-java驱动,针对python提供了mysql-connector-python驱动,客户端的通信协议已经在driver层面做过了。因此smart-client模式的中间件,通常只需要在此基础上进行封装即可。
天然去中心化
smart-client的方式,由于本身以sdk的方式,被应用直接引入,随着应用部署到不同的节点上,且直连数据库,中间不需要有代理层。因此相较于proxy而言,除了网络资源之外,基本上不存在任何其他资源的竞争,也不需要考虑高可用的问题。只要应用的节点没有全部宕机,就可以访问数据库。(这里的高可用是相比proxy而言,数据库本身的高可用还是需要保证的)
缺点:
通常仅支持某一种语言
例如tddl、zebra、sharding-jdbc都是使用java语言开发,因此对于使用其他语言的用户,就无法使用这些中间件。如果其他语言要使用,那么就要开发多语言客户端。
版本升级困难
因为应用使用数据源代理就是引入一个jar包的依赖,在有多个应用都对某个版本的jar包产生依赖时,一旦这个版本有bug,所有的应用都需要升级。而数据库代理升级则相对容易,因为服务是单独部署的,只要升级这个代理服务器,所有连接到这个代理的应用自然也就相当于都升级了。
3. ORM框架代理 (比较少用)
Hibernate-shards,mybatis插件,与orm框架绑定,仅支持特定语言
笔记
主流有2种设计方案:smart-client 、proxy其中
「smart-client」 jar形式,实现简单,天然去中心化,但通常只支持一种语言,多应用依赖jar包,版本升级困难;
「 proxy 」多语言支持,对业务开发透明,但实现相对复杂,需要保证高可用,以及租户隔离。
四、业界产品
业界比较知名的 MySQL 分布式数据库中间件产品有:ShardingShpere、Mycat、DBLE、TDSQL 等。
无论是proxy,还是smart-client,二者的作用都是类似的。以下列出了这两种方案目前已有的实现以及各自的优缺点:
1. 整体对比
| 实现方案 | 组件 | 优点 | 缺点 |
|---|---|---|---|
| proxy | cobar、mycat、mysqI-proxy、atlas、 drds、sharding-sphere |
多语言支持 |
实现复杂 |
| smart-client | tddl,zebra,zdal,sharding-jdbc | 实现难度适中 支持各种orm框架 端到端监控 |
仅支持特定语言(如:java) 版本升级困难 |
| ORM框架代理 | Hibernate-shards,mybatis插件 | 与orm框架绑定,仅支持特定语言 |
proxy实现
目前的已有的实现方案有:
- 阿里巴巴开源的cobar
- 阿里云上的drds
- mycat团队在cobar基础上开发的mycat
- mysql官方提供的mysql-proxy
- 奇虎360在mysql-proxy基础开发的atlas(只支持分表,不支持分库)
- 当当网开源的 sharing-sphere, 于 2020 年 4 月 16 日成为 Apache 软件基金会的顶级项目、社区熟度、功能支持较多,特别是对于分布式事务的支持,有多种选择(ShardingSphere 官网地址)。
目前除了mycat、sharing-sphere,其他几个开源项目基本已经没有维护,sharing-sphere已经成为Apache
ShardingSphere
smart-client实现
目前的实现方案有:
- 阿里巴巴开源的tddl,已很久没维护
- 大众点评开源的zebra,大众点评的zebra开源版本代码已经2年没有更新 (https://github.com/Meituan-Dianping/Zebra)
- 当当网开源的sharding-jdbc,目前算是做的比较好的,文档资料比较全。是sharding-sphere的三大组件之一。
- 蚂蚁金服的zal
2.shardingSphere
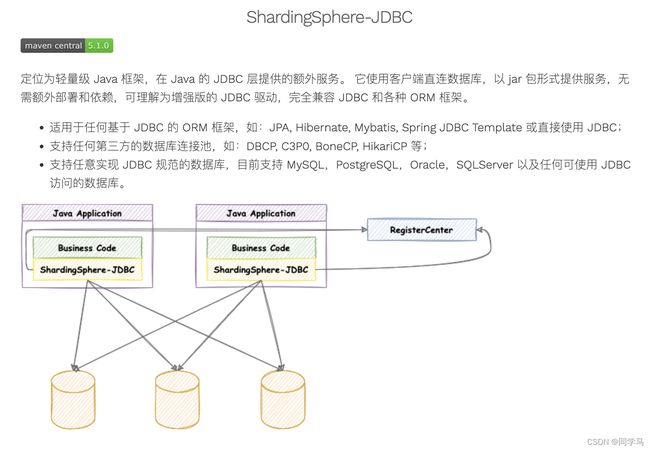
Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 ShardingSphere-JDBC 是 Apache ShardingSphere 的第一个产品,也是 Apache ShardingSphere 的前身。 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
Sharding-JDBC
对分布式事务的支持- 弱 XA和柔性事务(BASE)
目前 Sharding-JDBC 的事务支持两种,一种是弱 XA,另一种是柔性事务(BASE)。因为 XA的两阶段或三阶段提交其性能较低,因此互联网公司基本不会采用。而无论是弱 XA还是柔性事务,都无法保证事务在任意时间段完全保证一致,其中柔性事务能保证数据的最终一致性,但达到最终一致性的时间仍然不可控。因此对于对跨库事务强一致要求很高的场景,需要从设计方面去考虑数据库schema 的合理性。
场景
适合场景
对于关系型数据库数据量很大的情况,需要进行水平拆库和拆表(即分库和分表),这种场景很适合使用 Sharding-JDBC。
举例说明:假设有一亿数据的用户库,放在 MySQL 数据库里查询性能会比较低,而采用水平拆库,将其分为 10 个库,根据用户的 ID 模10,这样数据就能比较平均的分在 10 个库中,每个库只有 1000w 记录,查询性能会大大提升。分片策略类型非常多,大致分为 Hash +Mod、Range、Tag 等。
Sharding-JDBC 还提供了读写分离的能力,用于减轻写库的压力。
此外,Sharding-JDBC 可以用在 JPA 场景中,如 JPA、Hibernate、Mybatis,Spring JDBC Template 等任何 Java 的 ORM 框架。Java 的 ORM 框架也都是采用 JDBC 与数据库交互。这也是我们选择在 JDBC 层,而非选择一个 ORM 框架进行开发的原因。我们希望 Sharding-JDBC 可以尽量的兼容所有的 Java 数据库访问层,并且无缝的接入业务应用。
不合适的场景
主要是两方面:
(2.1)不适合 OLAP 的场景。虽然 Sharding-JDBC 也能做聚合分组查询,但大量的 OLAP 场景,仍然会比较慢,而且复杂的SQL(如子查询等)目前还没有支持。这种查询不太适合大数据和高并发的互联网 online 数据库,建议使用合理的 OLTP 查询。
(2.2)不适合事务强一致的要求。如上文 对分布式事务的支持里提到。
对于 JTA 事务,目前 Shariding-JDBC 没有实现 JTA 的标准。而且由于在互联网场景下使用 JTA 比较少见,因此暂时不支持 JTA 事务。
3. mycat
[mycat 官网] http://www.mycat.org.cn/
一些特性就不展开了,重点看下最新的mycat2 对分布式事务的支持。
支持XA事务
Mycat2 事务基于Vertx的异步SQL接口构建,但是其实现是自研的mysql协议实现.
1.15开始支持MySQL XA事务,事务日志表会在Mycat2启动时候在存储节点上建立mycat.xa_log表.
它记录已经进入commit节点事务,在此表有记录的分布式事务都是要提交的,而不在此表的XA PREPARE阶段事务是要回滚的.mycat.xa_log表的记录是事务已经进入commit阶段但是没有执行完成的依据.
如果访问某存储节点的sql阻塞,有可能是XA PREPARE阶段的事务没有被COMMIT或者ROLLBACK.Mycat在启动的时候会根据XA RECOVER语句,可以得到mysql上存在的PREPARE阶段事务,然后检查每个存储节点数据库的mycat.xa_log
如果有该对应的xid,则会自动执行XA COMMIT 'xxxx’补上commit,如果没有,则补上XA ROLLBACK 'xxx’回滚.这两个操作成功执行后都会删除mycat.xa_log中的xid记录
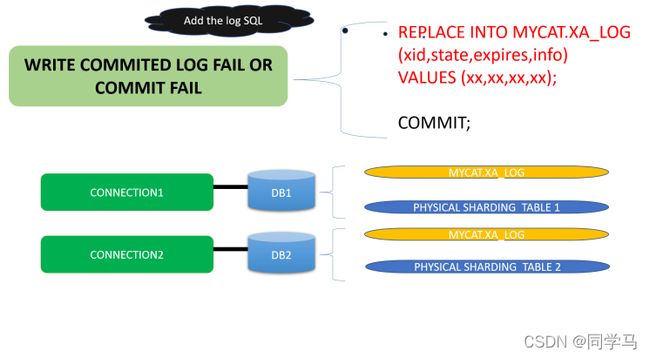
XA第一个XA COMMIT前会补上一个日志记录,注意的是,插入日志的SQL与第一个连接处于同一个事务,当此COMMIT成功,则日志记录可查,即使往后的其它节点COMMIT失败也可以根据此记录得知已经COMMIT了.如果找不到此记录,则说明第一个XA COMMIT失败,那么此XID的其它的XA PREPARE都需要回滚.所有节点XA COMMIT或者XA ROLLBACK后删除日志记录.
如果上述过程没有生效,则需要人工执行(一般重起Mycat2即可自动恢复)
或者定时向mycat2发送此sql,使mycat2检查失败的事务
mycat:readXARecoveryLog{};
笔记
「shardingSphere 中的sharding-jdbc」 是smart-client形式,引入简单,有持续维护。支持弱XA和柔性事务(BASE),无法保证跨库事务在任意时间段完全保证一致。
「mycat」是proxy模式, 支持XA 事务。除了两种模式本身的不同,还有一些特性上的区别,就不再展开了。
参考:
[mycat 官网] http://www.mycat.org.cn/
[shardingsphere] https://shardingsphere.apache.org/
[极客时间] 王宝令.java 并发编程实战 https://time.geekbang.org/column/intro/159
Mycat和Sharding-jdbc的区别 https://www.cnblogs.com/yb-ken/p/15623317.html
数据库中间件详解 https://www.cnblogs.com/jpfss/p/11577780.html
闫冬.MySQL分库分表方案 https://zhuanlan.zhihu.com/p/84224499
分库分表之后,id 主键如何处理? https://doocs.github.io/advanced-java/#/./docs/high-concurrency/database-shard-global-id-generate