K8s服务发现组件---CoreDNS和kubeDNS
目录
一、coredns 概述
1.1 什么是CoreDNS
1.2 CoreDNS 特点
1.3 DNS服务概述
1.4 coredns的优缺点
二、coredns的部署
三、coredns配置
3.1 K8s DNS策略
3.2 resolv.conf
3.3 coreDNS Corefile 文件
3.4 CoreDNS配置解析
四、node local dns
4.1 DNS间歇性5秒延迟
4.2 NodeLocal DNSCache
五、kubeDNS
5.1 结构
5.2 kubedns
5.3 dnsmasq
5.4 sidecar
5.5 kubedns的优缺点
六、CoreDNS和KubeDNS的性能对比
一、coredns 概述

1.1 什么是CoreDNS
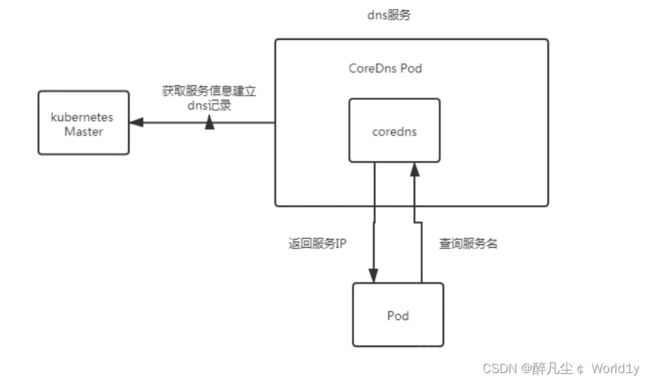
CoreDNS 是一个灵活可扩展的 DNS 服务器,可以作为 Kubernetes 集群 DNS,在Kubernetes1.12版本之后成为了默认的DNS服务。 与 Kubernetes 一样,CoreDNS 项目由 CNCF 托管。
coredns在K8S中的用途,主要是用作服务发现,也就是服务(应用)之间相互定位的过程。
在k8s中,用service资源代理pod,通过暴露service资源的固定地址(集群IP),来解决以上POD资源变化产生的IP变动问题,但是针对service还存在以下问题:
- service IP地址难以记忆
- service资源可能也会被销毁和创建
- pod ip本身也有需要暴漏的需求
为了解决以上问题,引入了coredns,在K8S,其主要用于服务发现,也就是服务(应用)之间相互定位的过程。
1.2 CoreDNS 特点
- Plugins(插件化)
- Service Discovery(服务发现)
- Fast and Flexible(快速和弹性)
- Simplicity(简单)
1.3 DNS服务概述
service发现是k8s中的一个重要机制,其基本功能为:在集群内通过服务名对服务进行访问,即需要完成从服务名到ClusterIP的解析。
k8s主要有两种service发现机制:环境变量和DNS。没有DNS服务的时候,k8s会采用环境变量的形式,但一旦有多个service,环境变量会变复杂,为解决该问题,我们使用DNS服务。
DNS服务在kubernetes中经历了三个阶段(SkyDNS-》KubeDNS-》CoreDNS):
- 【第一阶段】在kubernetes 1.2版本时,dns服务使用的是由SkyDNS提供的,由4个容器组成:kube2sky、skydns、etcd和healthz。etcd存储dns记录;kube2sky监控service变化,生成dns记录;skydns读取服务,提供查询服务;healthz提供健康检查。
- 【第二阶段】在kubernetes 1.4版本开始使用KubeDNS,有3个容器组成:kubedns、dnsmasq和sidecar。kubedns监控service变化,并记录到内存(存到内存提高性能)中;dnsmasq获取dns记录,提供dns缓存,提供dns查询服务;sidecar提供健康检查。
- 【第三阶段】从kubernetes >=1.11版本开始,dns服务有CoreDNS提供,coredns支持自定义dns记录及配置upstream dns server,可以统一管理内部dns和物理dns。coredns只有一个coredns容器。下面是coredns的架构。
1.4 coredns的优缺点
优点
- 非常灵活的配置,可以根据不同的需求给不同的域名配置不同的插件
- k8s 1.9 版本后的默认的 dns 解析
缺点
- 缓存的效率不如 dnsmasq,对集群内部域名解析的速度不如 kube-dns (10% 左右)
二、coredns的部署
coredns部署参考
部署后,可在dns中,通过如下命令查询coredns是否运行正常
dig @127.0.0.1 -p 53 www.example.com
三、coredns配置
3.1 K8s DNS策略
Kubernetes 中 Pod 的 DNS 策略有四种类型:
- Default:Pod 继承所在主机上的 DNS 配置;
- ClusterFirst:K8s 的默认设置;先在 K8s 集群配置的 coreDNS 中查询,查不到的再去继承自主机的上游 nameserver 中查询;
- ClusterFirstWithHostNet:对于网络配置为 hostNetwork 的 Pod 而言,其 DNS 配置规则与 ClusterFirst 一致;
- None:忽略 K8s 环境的 DNS 配置,只认 Pod 的 dnsConfig 设置。
3.2 resolv.conf
在部署 pod 的时候,如果用的是 K8s 集群的 DNS,那么 kubelet 在起 pause 容器的时候,会将其 DNS 解析配置初始化成集群内的配置。
如创建了一个叫 my-nginx 的 deployment,其 pod 中的 resolv.conf 文件如下:
# DNS 服务的 IP,即coreDNS 的 clusterIP
nameserver 192.168.111.20
# DNS search 域。解析域名的时候,将要访问的域名依次带入 search 域,进行 DNS 查询
# 比如访问your-nginx,其进行的 DNS 域名查询的顺序是:your-nginx.default.svc.cluster.local. -> your-nginx.svc.cluster.local. -> your-nginx.cluster.local.
search default.svc.cluster.local svc.cluster.local cluster.local
# 其他项,最常见的是 dnots。dnots 指的是如果查询的域名包含的点 “.” 小于 5,则先走search域,再用绝对域名;如果查询的域名包含点数大于或等于 5,则先用绝对域名,再走search域
# K8s 中默认的配置是 5。
options ndots:5
3.3 coreDNS Corefile 文件
CoreDNS 实现了应用的插件化,用户可以选择所需的插件编译到可执行文件中;CoreDNS 的配置文件是 Corefile 形式的,coreDNS 的 configMap如下所示:
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
# 指明 cluster.local 后缀的域名,都是 kubernetes 内部域名,coredns 会监听 service 的变化来维护域名关系,所以cluster.local 相关域名都在这里解析
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
# CoreDNS 的监控地址为:http://localhost:9153/metrics
prometheus :9153
# proxy 指 coredns 中没有找到记录,则去 /etc/resolv.conf 中的 nameserver 请求解析,而 coredns 容器中的 /etc/resolv.conf 是继承自宿主机的。
# 实际效果是如果不是 k8s 内部域名,就会去默认的 dns 服务器请求解析,并返回给 coredns 的请求者。
forward . /etc/resolv.conf
cache 30 # 允许缓存
loop # 如果找到循环,则检测简单的转发循环并停止 CoreDNS 进程
reload # 允许 Corefile 的配置自动更新。在更改 ConfigMap 后两分钟,修改生效
loadbalance # 这是一个循环 DNS 负载均衡器,可以在答案中随机化 A,AAAA 和 MX 记录的顺序
}
kind: ConfigMap
metadata:
creationTimestamp: "2019-06-10T03:19:01Z"
name: coredns
namespace: kube-system
3.4 CoreDNS配置解析
下面是coredns的配置模板
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: namespace-test
data:
Corefile: |
.:53 {
errors
health
ready
kubernetes cluster.local 10.200.0.0/16 {
pods insecure
upstream 114.114.114.114
fallthrough in-addr.arpa ip6.arpa
namespaces namespace-test
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
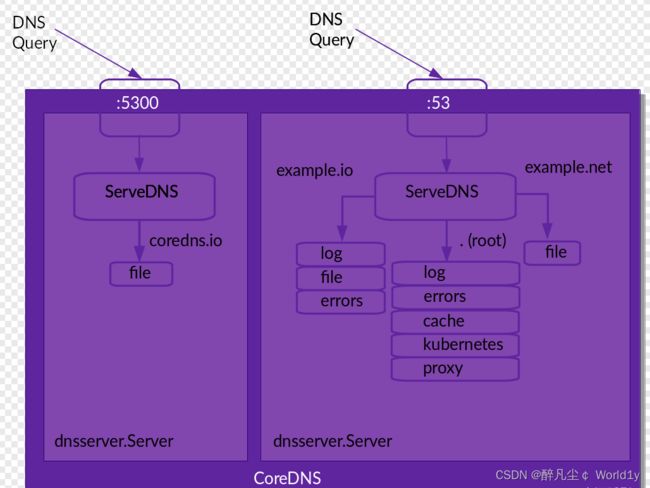
CoreDNS的主要功能是通过插件系统实现的。它实现了一种链式插件的结构,将dns的逻辑抽象成了一个个插件。
常见的插件如下:
- loadbalance:提供基于dns的负载均衡功能
- loop:检测在dns解析过程中出现的简单循环问题
- cache:提供前端缓存功能
- health:对Endpoint进行健康检查
- kubernetes:从kubernetes中读取zone数据
- etcd:从etcd读取zone数据,可以用于自定义域名记录
- file:从文件中读取zone数据
- hosts:使用/etc/hosts文件或者其他文件读取zone数据,可以用于自定义域名记录
- auto:从磁盘中自动加载区域文件
- reload:定时自动重新加载Corefile配置文件的内容
- forward:转发域名查询到上游dns服务器
- proxy:转发特定的域名查询到多个其他dns服务器,同时提供到多个dns服务器的负载均衡功能
- prometheus:为prometheus系统提供采集性能指标数据的URL
- pprof:在URL路径/debug/pprof下提供运行是的西能数据
- log:对dns查询进行日志记录
- errors:对错误信息镜像日志记录
四、node local dns
4.1 DNS间歇性5秒延迟
由于 Linux 内核中的缺陷,在 Kubernetes 集群中你很可能会碰到恼人的 DNS 间歇性 5 秒延迟问题。
原因是镜像底层库 DNS 解析行为默认使用 UDP 在同一个 socket 并发 A 和 AAAA 记录请求,由于 UDP 无状态,两个请求可能会并发创建 conntrack 表项,如果最终 DNAT 成同一个集群 DNS 的 Pod IP 就会导致 conntrack 冲突,由于 conntrack 的创建和插入是不加锁的,最终后面插入的 conntrack 表项就会被丢弃,从而请求超时,默认 5s 后重试,造成现象就是 DNS 5 秒延时。
具体原因可参见:
issues-56903
Weave works分析
4.2 NodeLocal DNSCache
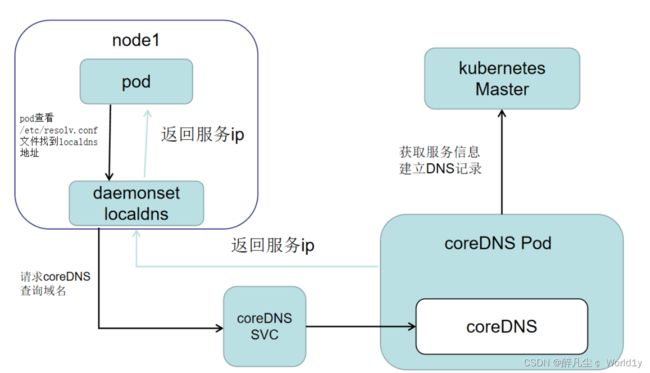
NodeLocal DNSCache通过在集群上运行一个dnsCache daemonset来提高clusterDNS性能和可靠性。相比于纯coredns方案,nodelocaldns + coredns方案能够大幅降低DNS查询timeout的频次,提升服务稳定性。
nodelocaldns配置如下,nodelocaldns只配置了一个server,监听默认的UDP 53端口,4个zone。域名后缀为cluster.local的所有域名以及in-addr.arpa和ip6.arpa形式域名走coredns进行域名解析,其他外部域名使用宿主机的/etc/resolv.conf文件配置的nameserver进行解析。
缓存分为 256 个分片,每个分片默认最多可容纳 39 个项目 - 总大小为 256 * 39 = 9984 个项目。
# 其中cluster.local、in-addr.arpa、ip6.arpa表示kubernetes插件会处理域名后缀为cluster.local的所有域名以及处理所有的in-addr.arpa中的反向dns查找和ip6.arpa形式域名,其中kuberne# 集群域名后缀是在kubelet参数中配置的,默认值为cluster.local
apiVersion: v1
data:
Corefile: |
cluster.local:53 {
errors
cache {
success 9984 30 # 对于成功的缓存最多缓存9984条域名解析记录,缓存时间为30s
denial 9984 5 # 对于失败的缓存最多缓存9984条域名解析记录,缓存时间为5s
}
reload
loop
bind 169.254.25.10
forward . 10.233.0.3 {
force_tcp
}
prometheus :9253
health 169.254.25.10:9254
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.25.10
forward . 10.233.0.3 {
force_tcp
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind 169.254.25.10
forward . 10.233.0.3 {
force_tcp
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind 169.254.25.10
forward . /etc/resolv.conf
prometheus :9253
}
kind: ConfigMap
......nodelocaldns + coredns方案,DNS查询流程如下所示:
五、kubeDNS
5.1 结构
kubeDNS由3个部分组成。
- kubedns: 依赖 client-go 中的 informer 机制监视 k8s 中的 Service 和 Endpoint 的变化,并将这些结构维护进内存来服务内部 DNS 解析请求。
- dnsmasq: 区分 Domain 是集群内部还是外部,给外部域名提供上游解析,内部域名发往 10053 端口,并将解析结果缓存,提高解析效率。
- sidecar: 对 kubedns 和 dnsmasq 进行健康检查和收集监控指标。
以下是结构图:

5.2 kubedns
在 kubedns 包含两个部分, kubedns 和 skydns。
其中 kubedns 是负责监听 k8s 集群中的 Service 和 Endpoint 的变化,并将这些变化通过 treecache 的数据结构缓存下来,作为 Backend 给 skydns 提供 Record。 而真正负责dns解析的其实是 skydns(skydns 目前有两个版本 skydns1 和 skydns2,下面所说的是 skydns2,也是当前 kubedns 所使用的版本)。
我们可以先看下 treecache,以下是 treecache 的数据结构;
// /dns/pkg/dns/treecache/treecache.go#54
type treeCache struct {
ChildNodes map[string]*treeCache
Entries map[string]interface{}
}
treeCache 的结构类似于目录树。从根节点到叶子节点的每个路径与一个域名是相对应的,顺序是颠倒的。它的叶子节点只包含 Entries,非叶子节点只包含 ChildNodes。叶子节点中保存的就是 SkyDNS 定义的 msg.Service 结构,可以理解为 DNS 记录。
在 Records 接口方法实现中,只需根据域名查找到对应的叶子节点,并返回叶子节点中保存的所有msg.Service 数据。K8S 就是通过这样的一个数据结构来保存 DNS 记录的,并替换了 etcd( skydns2 默认使用 etcd 作为存储),来提供基于内存的高效存储。
我们可以直接阅读代码来了解 kubedns 的启动流程。
首先看它的结构体
// dns/cmd/kube-dns/app/server.go#43
type KubeDNSServer struct {
// DNS domain name. = cluster.local.
domain string
healthzPort int
// skydns启动的地址和端口
dnsBindAddress string
dnsPort int
// 配置上游查询的地址,虽然 skydns 也支持上游域名解析,
// 但是在 kubedns 一般情况下并不会由它来做,因为上游域名会被 dnsmasq 提前处理
nameServers string
kd *dns.KubeDNS
}
接下来可以看到一个叫 NewKubeDNSServerDefault 的函数,它初始化了 KubeDNSServer。并执行 server.Run() 启动了服务。那么我们来看下 NewKubeDNSServerDefault 这个方法做了什么。
// dns/cmd/kube-dns/app/server.go#53
func NewKubeDNSServerDefault(config *options.KubeDNSConfig) *KubeDNSServer {
// 初始化 kubeclient
kubeClient, err := newKubeClient(config)
// 同步配置文件,如果观察到配置信息改变,就会重启skydns
var configSync dnsconfig.Sync
switch {
// 同时配置了 configMap 和 configDir 会报错
case config.ConfigMap != "" && config.ConfigDir != "":
glog.Fatal("Cannot use both ConfigMap and ConfigDir")
case config.ConfigMap != "":
configSync = dnsconfig.NewConfigMapSync(kubeClient, config.ConfigMapNs, config.ConfigMap)
case config.ConfigDir != "":
configSync = dnsconfig.NewFileSync(config.ConfigDir, config.ConfigPeriod)
default:
conf := dnsconfig.Config{Federations: config.Federations}
if len(config.NameServers) > 0 {
conf.UpstreamNameservers = strings.Split(config.NameServers, ",")
}
configSync = dnsconfig.NewNopSync(&conf)
}
return &KubeDNSServer{
domain: config.ClusterDomain,
healthzPort: config.HealthzPort,
dnsBindAddress: config.DNSBindAddress,
dnsPort: config.DNSPort,
nameServers: config.NameServers,
kd: dns.NewKubeDNS(kubeClient, config.ClusterDomain, config.InitialSyncTimeout, configSync),
}
}可以看到这里 dnsconfig 会返回一个 configSync 的 interface 用来实时同步配置,也就是 kube-dns 这个 configmap,或者是本地的 dir(但一般来说这个 dir 也是由 configmap 挂载进去的)。在方法的最后 dns.NewKubeDNS 返回一个 KubeDNS 的结构体。那么我们看下这个函数初始化了哪些东西。
// dns/pkg/dns/dns.go#124
func NewKubeDNS(client clientset.Interface, clusterDomain string, timeout time.Duration, configSync config.Sync) *KubeDNS {
kd := &KubeDNS{
kubeClient: client,
domain: clusterDomain,
// 初始化目录树
cache: treecache.NewTreeCache(),
cacheLock: sync.RWMutex{},
nodesStore: kcache.NewStore(kcache.MetaNamespaceKeyFunc),
reverseRecordMap: make(map[string]*skymsg.Service),
clusterIPServiceMap: make(map[string]*v1.Service),
domainPath: util.ReverseArray(strings.Split(strings.TrimRight(clusterDomain, "."), ".")),
initialSyncTimeout: timeout,
configLock: sync.RWMutex{},
configSync: configSync,
}
kd.setEndpointsStore()
kd.setServicesStore()
return kd
}可以看到kd.setEndpointsStore() 和 kd.setServicesStore() 这两个方法会在 informer中注册 Service 和 Endpoint 的回调,用来观测这些资源的变动并作出相应的调整。
// dns/pkg/dns/dns.go#499
func (kd *KubeDNS) newPortalService(service *v1.Service) {
// 构建了一个空的叶子节点, recordLabel是clusterIP经过 FNV-1a hash运算后得到的32位数字
// recordValue 的结构
// &msg.Service{
// Host: service.Spec.ClusterIP,
// Port: 0,
// Priority: defaultPriority,
// Weight: defaultWeight,
// Ttl: defaultTTL,
// }
subCache := treecache.NewTreeCache()
recordValue, recordLabel := util.GetSkyMsg(service.Spec.ClusterIP, 0)
subCache.SetEntry(recordLabel, recordValue, kd.fqdn(service, recordLabel))
// 查看service的ports列表,将每个port信息转换成skydns.Service并加入上面构建的叶子节点
for i := range service.Spec.Ports {
port := &service.Spec.Ports[i]
if port.Name != "" && port.Protocol != "" {
srvValue := kd.generateSRVRecordValue(service, int(port.Port))
l := []string{"_" + strings.ToLower(string(port.Protocol)), "_" + port.Name}
subCache.SetEntry(recordLabel, srvValue, kd.fqdn(service, append(l, recordLabel)...), l...)
}
}
subCachePath := append(kd.domainPath, serviceSubdomain, service.Namespace)
host := getServiceFQDN(kd.domain, service)
reverseRecord, _ := util.GetSkyMsg(host, 0)
kd.cacheLock.Lock()
defer kd.cacheLock.Unlock()
// 将构建好的叶子节点加入treecache
kd.cache.SetSubCache(service.Name, subCache, subCachePath...)
kd.reverseRecordMap[service.Spec.ClusterIP] = reverseRecord
kd.clusterIPServiceMap[service.Spec.ClusterIP] = service
}
再看一下当 Endpoint 添加到集群时,kubedns 会如何处理
// dns/pkg/dns/dns.go#460
func (kd *KubeDNS) addDNSUsingEndpoints(e *v1.Endpoints) error {
// 获取ep所属的svc
svc, err := kd.getServiceFromEndpoints(e)
if err != nil {
return err
}
// 判断这个svc,如果这个svc不是 headless,就不会处理此次添加,因为 svc 有 clusterIP 的情况,在处理
// svc 的增删改时已经都被处理了。所以当 ep 属于 headless svc 时,需要将这个 ep 加入到 cache
if svc == nil || v1.IsServiceIPSet(svc) || svc.Spec.Type == v1.ServiceTypeExternalName {
// No headless service found corresponding to endpoints object.
return nil
}
return kd.generateRecordsForHeadlessService(e, svc)
}
// 把 endpoint 添加到它所属的 headless service 的缓存下
func (kd *KubeDNS) generateRecordsForHeadlessService(e *v1.Endpoints, svc *v1.Service) error {
subCache := treecache.NewTreeCache()
generatedRecords := map[string]*skymsg.Service{}
// 遍历这个 ep 下所有的 ip+port,并将它们添加到 treecache 中
for idx := range e.Subsets {
for subIdx := range e.Subsets[idx].Addresses {
address := &e.Subsets[idx].Addresses[subIdx]
endpointIP := address.IP
recordValue, endpointName := util.GetSkyMsg(endpointIP, 0)
if hostLabel, exists := getHostname(address); exists {
endpointName = hostLabel
}
subCache.SetEntry(endpointName, recordValue, kd.fqdn(svc, endpointName))
for portIdx := range e.Subsets[idx].Ports {
endpointPort := &e.Subsets[idx].Ports[portIdx]
if endpointPort.Name != "" && endpointPort.Protocol != "" {
srvValue := kd.generateSRVRecordValue(svc, int(endpointPort.Port), endpointName)
l := []string{"_" + strings.ToLower(string(endpointPort.Protocol)), "_" + endpointPort.Name}
subCache.SetEntry(endpointName, srvValue, kd.fqdn(svc, append(l, endpointName)...), l...)
}
}
// Generate PTR records only for Named Headless service.
if _, has := getHostname(address); has {
reverseRecord, _ := util.GetSkyMsg(kd.fqdn(svc, endpointName), 0)
generatedRecords[endpointIP] = reverseRecord
}
}
}
subCachePath := append(kd.domainPath, serviceSubdomain, svc.Namespace)
kd.cacheLock.Lock()
defer kd.cacheLock.Unlock()
for endpointIP, reverseRecord := range generatedRecords {
kd.reverseRecordMap[endpointIP] = reverseRecord
}
kd.cache.SetSubCache(svc.Name, subCache, subCachePath...)
return nil
}整体流程其实和 Service 差不多,只不过在添加 cache 之前会先去查找Endpoint所属的 Service,然后不同的是 Endpoint 的叶子节点中的host存储的是 EndpointIP,而 Service 的叶子节点的 host 中存储的是 fqdn。
最后再看一下 SkyDNS 的启动过程。
// 启动skydns server
func (d *KubeDNSServer) startSkyDNSServer() {
skydnsConfig := &server.Config{
Domain: d.domain,
DnsAddr: fmt.Sprintf("%s:%d", d.dnsBindAddress, d.dnsPort),
}
if err := server.SetDefaults(skydnsConfig); err != nil {
glog.Fatalf("Failed to set defaults for Skydns server: %s", err)
}
// 使用d.kd作为存储的后端,因为kubedns实现了skydns.Backend的接口
// type Backend interface {
// HasSynced() bool
// Records(name string, exact bool) ([]msg.Service, error)
// ReverseRecord(name string) (*msg.Service, error)
// }
s := server.New(d.kd, skydnsConfig)
// ...
d.kd.SkyDNSConfig = skydnsConfig
go s.Run()
}
kubedns总结
- kubedns 有两个模块,kubedns和skydns,kubedns负责监听Service和Endpoint并将它们转换为 skydns 能够理解的格式,以目录树的形式存在内存中。
- 因为 skydns 是以 etcd 的标准作为后端存储的,所以为了兼容 etcd ,kubedns 在某些错误信息方面也都以 etcd 的格式进行定义的。因此 kubedns 的作用其实可以理解为为 skydns 提供存储。
5.3 dnsmasq
dnsmasq 也由两个部分组成
1.dnsmasq-nanny,容器里的1号进程,不负责处理 DNS LookUp 请求,只负责管理 dnsmasq。 2.dnsmasq,负责处理 DNS LookUp 请求,并缓存结果。
dnsmasq-nanny 负责监控 config 文件(/etc/k8s/dns/dnsmasq-nanny,也就是kube-dns-config这个 configmap 所挂载的位置)的变化(每 10s 查看一次),如果 config 变化了就会Kill掉 dnsmasq,并重新启动它。
// dns/pkg/dnsmasq/nanny.go#198
// RunNanny 启动 nanny 服务并处理配置变化
func RunNanny(sync config.Sync, opts RunNannyOpts, kubednsServer string) {
// ...
configChan := sync.Periodic()
for {
select {
// ...
// 观察到config变化
case currentConfig = <-configChan:
if opts.RestartOnChange {
// 直接杀掉dnsmasq进程
nanny.Kill()
nanny = &Nanny{Exec: opts.DnsmasqExec}
// 重新加载配置
nanny.Configure(opts.DnsmasqArgs, currentConfig, kubednsServer)
// 重新启动dnsmasq进程
nanny.Start()
} else {
glog.V(2).Infof("Not restarting dnsmasq (--restartDnsmasq=false)")
}
break
}
}
}
让我们看下 sync.Periodic() 这个函数做了些什么
// dns/pkg/dns/config/sync.go#81
func (sync *kubeSync) Periodic() <-chan *Config {
go func() {
// Periodic函数中设置了一个Tick,每10s会去load一下configDir下
// 所有的文件,并对每个文件进行sha256的摘要计算
// 并将这个结果返回。
resultChan := sync.syncSource.Periodic()
for {
syncResult := <-resultChan
// processUpdate函数会比较新的文件的版本和旧的
// 文件的版本,如果不一致会返回changed。
// 值得注意的是有三个文件是需要单独处理的
// federations
// stubDomains
// upstreamNameservers
// 当这三个文件变化是会触发单独的函数(打印日志)
config, changed, err := sync.processUpdate(syncResult, false)
if err != nil {
continue
}
if !changed {
continue
}
sync.channel <- config
}
}()
return sync.channel
}
dnsmasq 中是如何加载配置的呢?
// dns/pkg/dnsmasq/nanny.go#58
// Configure the nanny. This must be called before Start().
// 这个函数会配置 dnsmasq,Nanny 每次 Kill 掉 dnsmasq 后,调用 Start() 之前都会调用这个函数
// 重新加载配置。
func (n *Nanny) Configure(args []string, config *config.Config, kubednsServer string) {
// ...
for domain, serverList := range config.StubDomains {
resolver := &net.Resolver{
PreferGo: true,
Dial: func(ctx context.Context, network, address string) (net.Conn, error) {
d := net.Dialer{}
return d.DialContext(ctx, "udp", kubednsServer)
},
}
// 因为 stubDomain 中可以是以 host:port 的形式存在,所以这里还要做一次 上游的 dns 解析
for _, server := range serverList {
if isIP := (net.ParseIP(server) != nil); !isIP {
switch {
// 如果 server 是以 cluster.local(不知道为什么这里是 hardCode 的)结尾的,就会发往 kubednsServer 进行 DNS 解析
// 因为上面已经配置了 d.DialContext(ctx, "udp", kubednsServer)
case strings.HasSuffix(server, "cluster.local"):
// ...
resolver.LookupIPAddr(context.Background(), server)
default:
// 如果没有以 cluster.local 结尾,就会走外部解析 DNS
// ...
net.LookupIP(server)
}
}
}
}
// ...
}
5.4 sidecar
sidecar 启动后会在内部开启一个协程,并在循环中每默认 5s 向 kubedns 发送一次 dns 解析。并记录解析结果。
sidecar 提供了两个http的接口 /healthcheck/kubedns 和 /healthcheck/dnsmasq 给 k8s 用作 livenessProbe 的健康检查。每次请求,sidecar 会将上述记录的 DNS 解析结果返回。
5.5 kubedns的优缺点
优点
- 依赖 dnsmasq ,性能有保障
缺点
1、因为 dnsmasq-nanny 重启 dnsmasq 的方式,先杀后起,方式比较粗暴,有可能导致这段时间内大量的 DNS 请求失败。
2、dnsmasq-nanny 检测文件的方式,可能会导致以下问题:
- dnsmasq-nanny 每次遍历目录下的所有文件,然后用 ioutil.ReadFile 读取文件内容。如果目录下文件数量过多,可能出现在遍历的同时文件也在被修改,遍历的速度跟不上修改的速度。 这样可能导致遍历完了,某个配置文件才更新完。那么此时,你读取的一部分文件数据并不是和当前目录下文件数据完全一致,本次会重启 dnsmasq。进而,下次检测,还认为有文件变化,到时候,又重启一次 dnsmasq。这种方式不优雅,但问题不大。
- 文件的检测,直接使用 ioutil.ReadFile 读取文件内容,也存在问题。如果文件变化,和文件读取同时发生,很可能你读取完,文件的更新都没完成,那么你读取的并非一个完整的文件,而是坏的文件,这种文件,dnsmasq-nanny 无法做解析,不过官方代码中有数据校验,解析失败也问题不大,大不了下个周期的时候,再取到完整数据,再解析一次。
六、CoreDNS和KubeDNS的性能对比
在 CoreDNS 的官网中已有详细的性能测试报告,
- 对于内部域名解析 KubeDNS 要优于 CoreDNS 大约 10%,可能是因为 dnsmasq 对于缓存的优化会比 CoreDNS 要好
- 对于外部域名 CoreDNS 要比 KubeDNS 好 3 倍。但这个值大家看看就好,因为 kube-dns 不会缓存 Negative cache。但即使 kubeDNS 使用了 Negative cache,表现仍然也差不多
- CoreDNS 的内存占用情况会优于 KubeDNS