Win10截屏文字识别工具;Rust超全学习指南;助理教授/博士生存指南;Stable Diffussion的Mac本地部署版;前沿论文 | ShowMeAI资讯日报

日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子
工具&框架
『Nitric』用于快速开发云原生 serverless 应用的框架
https://github.com/nitrictech/nitric
https://nitric.io/
Nitric 是一个用于快速开发云原生和无服务器应用程序的框架。根据你的应用程序所需的资源智能定义,然后为基于无服务器功能的API、事件订阅者和计划作业编写代码。基于 Nitric 构建的应用程序可以方便部署到 AWS、Azure 或谷歌云。
『sio4onnx』ONNX维度变更工具
https://github.com/PINTO0309/sio4onnx
sio4onnx是一个简单的工具,可以用于对ONNX的输入和输出维度进行变更
『Text-Grab』Win10的截屏OCR文字识别工具
https://github.com/TheJoeFin/Text-Grab
https://apps.microsoft.com/store/detail/text-grab/9MZNKQJ7SL0B?hl=en-us&gl=us
Text-Grab是一个Windows系统上的小巧光学字符识别(OCR)工具,它使所有视觉可见的文本(包括图像、视频、应用程序上的文本)都可以被复制。Text-Grab会通过文本抓取 "工具 "拍摄屏幕,将图像传给OCR引擎,然后将文本放到剪贴板中,接下来你可以轻松在任何地方粘贴使用。
OCR的过程是由 Windows API 在本地完成的,因此它没有复杂的用户界面,也不需要一个持续运行的后台进程。
『estela』基于Kubernetes的弹性网页爬虫集群
https://github.com/bitmakerla/estela
https://estela.bitmaker.la/docs/
estela 是一个运行在 Kubernetes 上的弹性网络爬虫集群。它通过 REST API 和 Web 界面提供了部署、运行和扩展网络爬虫的机制。
『Stable Diffussion Buddy』M1 Mac的Stable Diffussion本地部署版
https://github.com/breadthe/sd-buddy
Stable Diffussion Buddy是Stable Diffusion的M1 Mac版本的配套桌面应用程序。它提供非常简单的方式生成图像,让你专注于编写提示信息,而不用关注命令行复杂命令。
博文&分享
『How to learn modern Rust』Rust 学习指南
https://github.com/joaocarvalhoopen/How_to_learn_modern_Rust
Rust 是一种强大的编程语言,速度快,可编译,将安全性的新概念带入了编程,被 StackOverFlow 用户连续五年评为最受欢迎的语言。这是一个rust学习的详细指南,包含了 Rust 学习的各种主题与相关资料。
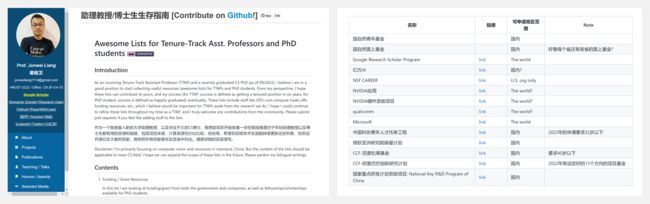
『Track Assistant Professors and PhD students』助理教授/博士生生存指南
https://github.com/JunweiLiang/awesome_lists
作为一个刚准备入职的大学助理教授,以及毕业不久的CS博士,作者趁现在开始收集一些对于年轻助理教授以及博士生都有用的资源和链接,包括项目来源、计算资源性价比比较、经验等。列表包含8个部分,使用中英双语,并持续更新中。
- Funding / Grant Resources(国内外教授可申请的资金,以及博士生奖学金)
- Social Media / Academic Profiles(会推荐研究工作的公众号和自媒体)
- Computational Resources(国内云GPU计算资源的价格以及整机购买的一些对比)
- Workshops and Competitions (顶会与比赛)
- How to Run A Lab / Recruit Candidates(如何招生、如何管理实验室)
- General Advice from Others (其他资深教授、学者的建议)
- Awesome Academic Pages (比较好的学术主页)
- Awesome Courses (优秀、开放的课程列表)
数据&资源
『Awesome Video Instance Segmentation Papers』视频实例分割相关文献资源列表
https://github.com/QingZhong1996/Awesome-Video-Instance-Segmentation-Papers

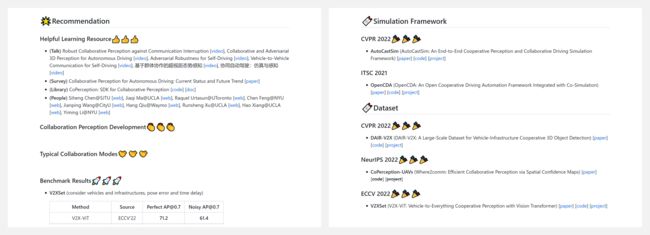
『Collaborative Perception』协同感知相关文献列表
https://github.com/Little-Podi/Collaborative_Perception
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.08.20 『图像超分辨率变换』 Diffusion Models: A Comprehensive Survey of Methods and Applications
- 2022.08.20 『图像生成』 StoryDALL-E: Adapting Pretrained Text-to-Image Transformers for Story Continuation
- 2022.08.20 『目标检测』 CenterFormer: Center-based Transformer for 3D Object Detection
⚡ 论文:Diffusion Models: A Comprehensive Survey of Methods and Applications
论文时间:2 Sep 2022
领域任务:Image Super-Resolution, Text-to-Image Generation,图像超分辨率变换,文本到图片转换
论文地址:https://arxiv.org/abs/2209.00796
代码实现:https://github.com/YangLing0818/Diffusion-Models-Papers-Survey-Taxonomy
论文作者:Ling Yang, Zhilong Zhang, Shenda Hong, Runsheng Xu, Yue Zhao, Yingxia Shao, Wentao Zhang, Ming-Hsuan Yang, Bin Cui
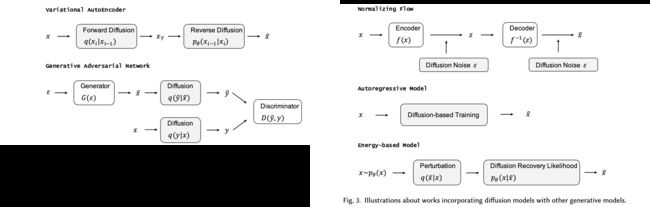
论文简介:Diffusion models are a class of deep generative models that have shown impressive results on various tasks with a solid theoretical foundation./扩散模型是一类深度生成模型,在各种任务上显示出令人印象深刻的结果,并具有坚实的理论基础。
论文摘要:扩散模型是一类深度生成模型,在各种任务上显示出令人印象深刻的结果,具有坚实的理论基础。尽管比起最先进的方法,扩散模型已经显示出成功,但它往往需要昂贵的采样程序和次优的似然估计。为了提高扩散模型在各方面的性能,人们做出了巨大的努力。在这篇文章中,我们对扩散模型的现有变体进行了全面的回顾。具体来说,我们提供了扩散模型的分类法,并将其分为三种类型:采样-加速增强、似然-最大化增强和数据-概括增强。我们还介绍了其他生成模型(即变异自动编码器、生成对抗网络、归一化流、自回归模型和基于能量的模型)并讨论了扩散模型和这些生成模型之间的联系。然后,我们回顾了扩散模型的应用,包括计算机视觉、自然语言处理、波形信号处理、多模式建模、分子图生成、时间序列建模和对抗性净化。此外,我们提出了与生成模型的发展有关的新观点。Github: https://github.com/YangLing0818/Diffusion-Models-Papers-Survey-Taxonomy
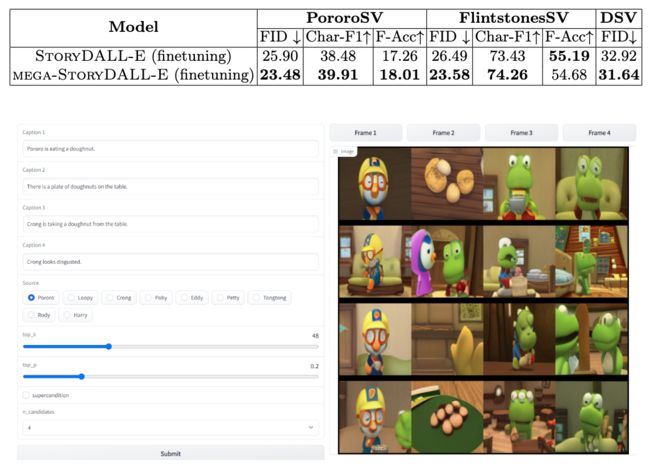
⚡ 论文:StoryDALL-E: Adapting Pretrained Text-to-Image Transformers for Story Continuation
论文时间:13 Sep 2022
领域任务:Image Generation, Story Continuation, 图像生成
论文地址:https://arxiv.org/abs/2209.06192
代码实现:https://github.com/adymaharana/storydalle
论文作者:Adyasha Maharana, Darryl Hannan, Mohit Bansal
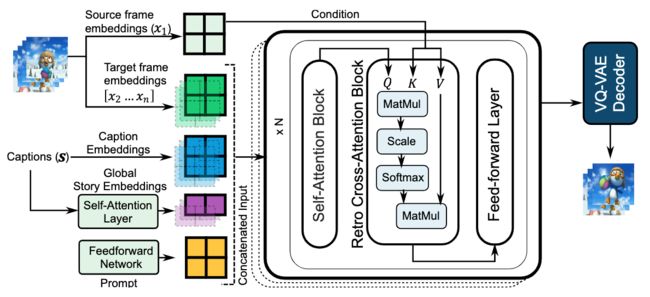
论文简介:Hence, we first propose the task of story continuation, where the generated visual story is conditioned on a source image, allowing for better generalization to narratives with new characters./因此,我们首先提出了故事延续的任务,即生成的视觉故事是以源图像为条件的,从而可以更好地推广到有新人物的叙事中。
论文摘要:最近在文本到图像合成方面的进展导致了大型的预训练transformers,它具有从给定文本生成可视化的出色能力。然而,这些模型并不适合像故事可视化这样的专门任务,它要求代理产生一连串的图像,给定相应的标题序列,形成一个叙述。此外,我们发现,故事可视化任务不能适应对新的叙述中未见过的情节和人物的概括。因此,我们首先提出了故事延续的任务,即生成的视觉故事以源图像为条件,允许更好地泛化到有新人物的叙述中。然后,我们增强或 "改装 "预训练的文本-图像合成模型,使其具有特定的任务模块,用于(a)连续的图像生成和(b)从初始帧中复制相关元素。然后,我们探索对预训练模型进行全模型微调,以及基于提示的参数有效适应的调整。我们在两个现有的数据集PororoSV和FlintstonesSV上评估了我们的方法StoryDALL-E,并介绍了一个新的数据集DiDeMoSV,该数据集是从一个视频字幕数据集中收集的。我们还开发了一个基于生成对抗网络(GAN)的故事延续模型StoryGANc,并与StoryDALL-E模型进行比较,以证明我们方法的优势。我们表明,我们的逆向拟合方法在故事延续方面优于基于GAN的模型,并且有利于复制源图像中的视觉元素,从而提高了生成的视觉故事的连续性。最后,我们的分析表明,预训练的transformers在理解包含多个角色的叙事时很困难。总的来说,我们的工作表明,预训练的文本-图像合成模型可以适应复杂的、低资源的任务,如故事的延续。
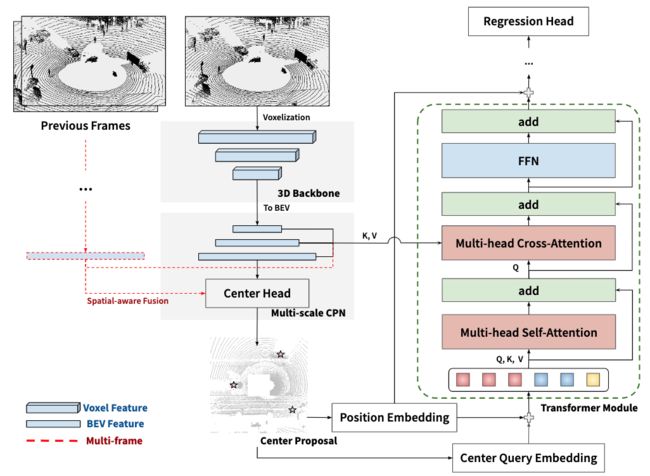
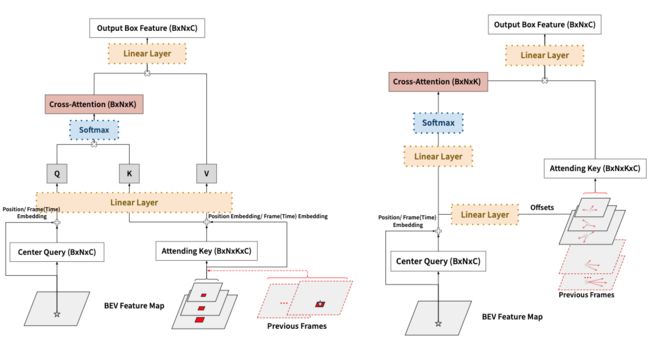
⚡ 论文:CenterFormer: Center-based Transformer for 3D Object Detection
论文时间:12 Sep 2022
领域任务:3D Object Detection, object-detection,目标检测
论文地址:https://arxiv.org/abs/2209.05588
代码实现:https://github.com/tusimple/centerformer
论文作者:Zixiang Zhou, Xiangchen Zhao, Yu Wang, Panqu Wang, Hassan Foroosh
论文简介:It then uses the feature of the center candidate as the query embedding in the transformer./然后,它使用中心候选人的特征作为变换器中的查询嵌入。
论文摘要:基于查询的transformer在许多图像领域的任务中显示出巨大的潜力,但由于点云数据的巨大尺寸,基于LiDAR的三维物体检测很少被考虑。在本文中,我们提出了CenterFormer,一个用于三维物体检测的基于中心的transformer网络。CenterFormer首先使用中心热图来选择基于标准体素的点云编码器的中心候选人。然后,它使用中心候选者的特征作为transformer中的查询嵌入。为了进一步汇总来自多个框架的特征,我们设计了一种通过交叉注意来融合特征的方法。最后,加入回归头来预测输出中心特征表示上的边界盒。我们的设计降低了收敛难度和transformer结构的计算复杂性。结果显示,与无锚物体检测网络的强大基线相比,有明显的改进。CenterFormer在Waymo开放数据集上的单一模型实现了最先进的性能,在验证集上有73.7%的mAPH,在测试集上有75.6%的mAPH,大大超过了以前发表的所有基于CNN和transformer的方法。我们的代码可在 https://github.com/TuSimple/centerformer 上公开查阅。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
