白翔:趣谈“捕文捉字”-- 场景文字检测 | VALSE2017之十
点击上方“深度学习大讲堂”可订阅哦!
编者按:文字,区别于变幻莫测的图像和视频,有着更强的逻辑性和更概括的表达力。随着互联网和移动互联网技术的高速发展,越来越多的新型应用场景需要利用图像中的文字信息。从海量视频中快速检索感兴趣的文字,可以极大提高人类的认知效率。因此,自然场景中的文字提取技术,即从照片或视频中将文字识别出来,成为了近几年计算机视觉领域的热门研究课题。在本文中,来自华中科技大学的白翔教授,将为大家讲述多方向场景文字检测的奥秘。文末,大讲堂特别提供文中提到所有文章的下载链接。


我将从以下几个方面对多方向场景文字检测进行介绍:
-
首先对场景文字检测这个问题进行定义;
-
然后对这个方向的研究工作进行总结;
-
接着介绍相关的数据集及评价标准;
-
最后对场景文字检测的应用进行简要介绍。
场景文字检测的基本步骤
场景文字检测这一问题在15~20年前就出现了相关的研究工作,它与传统的文本文字检测的重要区别是需要将照片或视频中的文字识别出来。
其主要分为两个步骤:
-
对照片中存在文字的区域进行定位(Text Detection),即找到单词或文本行(word/linelevel)的边界框(bounding box);
-
然后对定位后的文字进行识别(Text Recognition)。
将这两个步骤合在一起就能得到文字的端到端检测(End-to-end Recognition)。通常来说,实现文字端到端的检测是最重要的任务,也是我们的终极目标。

区别传统方法,引入全局信息
传统的文字检测方法大多是基于字符的,即先对字符进行检测,然后将字符进行关联组合,可以将其视为Bottom-Up的方法。
但是对于人来说,即使某些场景中的字符非常模糊无法看清,但是依然可以根据周围的场景来确定这些是字符。所以我的观点是对全局信息(global information)的学习会对这个任务提供很大的帮助。

场景文字检测的发展历程
场景文字检测的发展历程与绝大多数的计算机视觉任务相似,首先是基于传统的手工设计特征(Handcraft Features),包括基于连通区域的方法,以及基于HOG的检测框描述方法。在2014年左右出现了基于深度学习的方法。

第一阶段:基于传统的手工设计特征
首先回顾一下手工设计特征(Handcraft Features),常见的一种方法是假定字符本身是具有连通性的,然后通过连通区域的检测方法找到文字字符的候选。

(一)我们在微软的工作——设计多种方向不变性的特征
我们在微软的一个工作中提出了“照片中的文字可能存在多个方向”这个问题,并且设计了包括字符级别和文本行级别等不同层次的具有方向不变性的特征。
类似于传统的方法,我们通过结合笔画宽度来计算边缘以得到存在字符的区域,区别是我们设计了多种具有方向不变性的特征。并且发布了一个包含两种语言的数据集—MSRA-TD500,来对我们的方法进行评测。



(二)其他一些方法
还有一些方法,如通过最大稳定极值区域(MSER-Maximally Stable Extremal Regions)得到字符的候选,并将这些字符候选看作连通图(graph)的顶点,此时就可以将文本行的寻找过程视为聚类(clustering)的过程,因为来自相同文本行的文本通常具有相同的方向、颜色、字体以及形状。最后使用一个文本分类器滤除非文本部分。

(三)北科大殷绪成教授组的工作
北科大殷绪成教授研究组的一个工作对文本的信息进行了更加全面的考虑,使用了文本的颜色、笔画宽度、字符方向(orientation)以及投影的特征。


第二阶段:基于深度学习的方法
在基于深度学习的方法中,使用最广泛的是基于region proposal的方法,其次是基于图像分割的方法。我们接下来将其分两部分介绍。并在第三部分介绍我们组里2017年最新的工作进展。
第一部分:基于region proposal 的方法
(一)VGG组在IJCV2016的工作
较早的端到端识别研究是VGG 组发表在 IJCV2016中的一篇文章,其识别效果很好,并且在两年内一直保持领先地位。这篇文章针对文字检测问题对R-CNN进行了改造:
-
通过edge box或其他的handcraft feature来计算proposal;
-
然后使用分类器对文本框进行分类,去掉非文本区域;
-
再使用 CNN对文本框进行回归来得到更为精确的边界框(bounding box regression);
-
最后使用一个文字识别算法进一步滤除非文本区域。

(二)我们的工作——对称性模板
我们对基于proposal的方法也进行了一些研究。由于文本行自身上下结构具有相似性,所以我们设计一个具有对称性的模板,即在不同尺度下扫描图像,通过其响应得到对称的中心点。在得到对称中心点之后通过文字的高度和连通性得到边界框(bounding box),然后使用 CNN 进行后续的处理。

(三)VGG组在CVPR2016的工作
VGG组在CVPR2016上又提出了一个很有趣的工作。文章提出文本数据非常难以标注,所以他们通过合成的方法生成了很多含有文本信息的样本。虽然图像中存在合成的文字,但是依然能得到很好的效果。

(四)华南理工大学金连文教授组
华南理工大学金连文老师研究组提出了一个基于Faster R-CNN的方法,针对文字形状和一般物体形状的区别,对其进行了完善。


(五)中科院深圳先进技术研究院乔宇研究员组(ECCV2016)的工作
中科院深圳先进技术研究院乔宇老师研究组在ECCV2016上的一个工作很有新意。
他们在VGG的特征图上取一些block(即anchor),并计算每个block的得分(score)。在计算得分的过程中同时考虑上下文的信息,并将每行的文本特征输入到双向LSTM(BLSTM)模型中以更好地判断文字的得分。
除此之外还提出了方法判断文字的高度,起始位置和结束位置。这是第一个在场景文字检测中使用RNN的方法,但其主要用于水平文字的场景。得益于使用子块(block,anchor)对文字进行表示,该方法在一定程度上也能解决文字方向变化的问题。

基于region proposal方法的发展趋势
现在的方法越来越倾向于从整体上自动处理文本行或者边界框,如 arXiv上的一篇文章就将 Faster R-CNN中的RoI pooling替换为可以快速计算任意方向的操作来对文本进行自动处理。
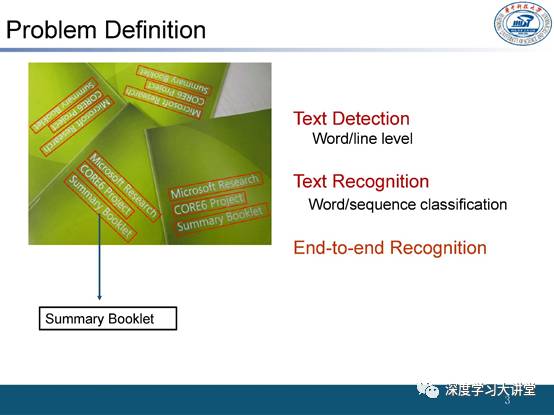
(六)金连文教授组CVPR2017工作
金连文教授发表在 CVPR2017 上的工作提出了一个重要观点:在生成 proposal 时回归矩形框不如回归一个任意多边形。
理由:这是因为文本在图像中更多的是具有不规则多边形的轮廓。他们在SSD(Single ShotMultiBox Detector)的检测框架基础上,将回归边界框的过程和匹配的过程都加入到网络结构中,取得了较好的识别效果并且兼顾了速度。


第二部分:基于图像分割的方法
(七)我们组在CVPR2016的工作
另外一个进行场景文字检测的方法是基于图像分割的方法。
我们在 CVPR2016上的一个工作将文本行视为一个需要分割的目标,通过分割得到文字的显著性图像(salience map),这样就能得到文字的大概位置、整体方向及排列方式,再结合其他的特征进行高效的文字检测。


我们发现在卷积神经网络中可以同时预测字符的位置及字符之间的连接关系,这些特征对定位文字具有很好的帮助。其过程如下:
-
得到文字文本行的分割结果;
-
得到字符中心的预测结果;
-
得到文字的连接方向。
通过得到的这三种特征构造连通图(graph),然后对图进行逐边裁剪来得到文字位置。

(八)融合分割和边界框回归的方法
最近有些方法同时使用分割(segmentation)和边界框回归(bounding box regression)的方式对场景文字进行检测。
如 CVPR2017 上的一篇文章使用PVANet对网络进行优化、加速,并输出三种不同的结果:
-
边缘部分分割的得分(score)结果;
-
可旋转的边界框(rotated bounding boxes)的回归结果;
-
多边形bounding boxes(quadrangle bounding boxes)的结果。
同时对非极大值抑制(NMS)进行改进,得到了很好的效果。

arXiv上的一篇文章使用了相似的思想:一个分支对图像分割进行预测,另一个分支对边界框(bounding box)进行预测,最后利用经过改进的非极大抑制(Refined NMS)进行融合。



第三部分:我们组最近的工作(AAAI2017, PAMI2017, CVPR2017)
(九)我们在AAAI2017的工作
我在做相关的研究工作时考虑更多的是实用性。我们AAAI2017的一个工作对SSD框架进行改进,之所以选择 SSD 作为基础框架是因为SSD是全卷积的形式,不需要全连接层,并且可以快速地计算文字在每个区域存在的可能性。
我们针对文字的形状做了一些改进:
-
首先在设计默认框(default box)时包含较长的形状;
-
另外我们发现长条形的卷积核比常用的1*1或3*3卷积核更适合文字检测;
-
最后我们使用识别模型对文字进行过滤和判断,提出了一个实用的 “检测+识别”的框架。
从实验结果中可以发现与传统的SSD相比,我们方法的定位性能有明显的提升。


(十)我们在PAMI2017的工作
我们在 PAMI2017中提出了一种识别文本序列的方法:
-
首先给定一个含有文本边界框(bounding box)的图片,先使用 CNN提取图像的特征;
-
然后用双向LSTM(BLSTM)学习文字的空间上下文信息;
-
最后对特征进行编码并得到最终的预测结果。
整个过程可以端到端(end-to-end)完成。我们将提出的定位和识别模型结合之后能得到目前端到端模型中最好的文字检测结果。


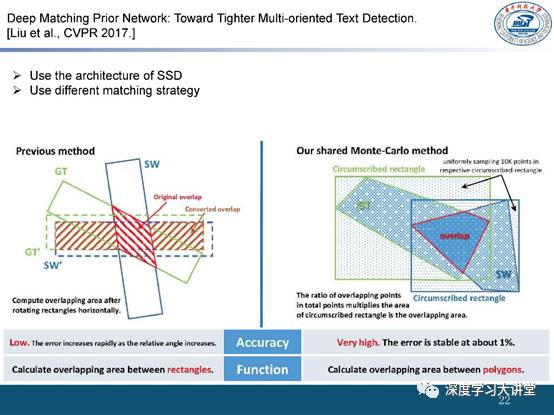
(十一)我们在CVPR2017另一个工作——part-based model
对于多方向文字检测的问题,回归或直接逼近bounding box的方法难度都比较大,所以我们考虑使用 part-based model 对多方向文字进行处理。
在我们CVPR2017上的另一个工作中,我们将文字视为小块单元。对文字小块同时进行旋转和回归。并且通过对文字小块之间的方向性进行计算来学习文字之间的联系,最后通过简单的后处理就能得到任意形状甚至具有形变的文字检测结果。
例如,对于那些很长的文本行,其卷积核的尺寸难以控制,但是如果将其分解为局部的文字单元之后就能较好地解决。
我们将其与识别模型进行结合之后在ICDAR 2015上得到了当时最好的端到端识别效果。

场景文字检测数据集
Incidental Scene Text dataset
Incidental Scene Text dataset 是 ICDAR2015竞赛中使用的数据集,是很常用的英文文字检测数据集。
-
它涵盖1000张训练图片(约包含4500个单词)和500张测试图片;
-
它重点采集了一些随机场景,在这些场景中文字具有方向任意、字体小、低像素的特性。

MSRA-TD500
我们在2012年发布了MSRA-TD500这个数据集,虽然数据量比较小,但是含有英文和中文两种语言。
-
包含了500张自然图片(涵盖室内、室外采集);
-
包含中文、英文及中英混合形式,具有不同的字体、大小、颜色、方向;
-
文本边框标注;
-
Ref. Detecting texts of arbitrary orientations in natural images,CVPR2012
RCTW-17
今年我们组织了ICDAR 2017中文场景文字检测的比赛,比赛中使用的数据集是我们组标注的中文数据集RCTW-17,并且数据量有了很大的提升。
-
包含中文文本的图片共12034张(其中8034张训练图片,4000张测试图片);
-
图片涵盖汉字、数字、英文单词,其中汉字占最大比例;
-
ICDAR2017的中文场景文字检测比赛用的是这个数据集。
-
链接:http://mclab.eic.hust.edu.cn/icdar2017chinese/
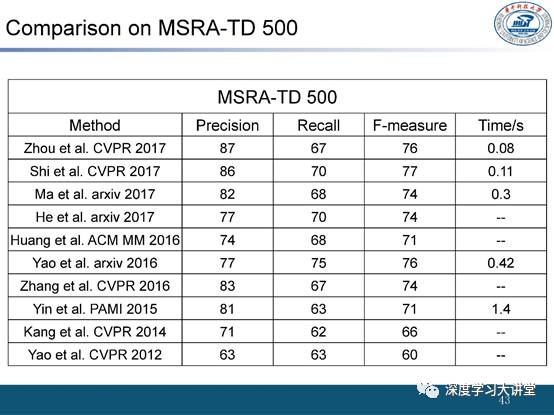
在数据集上的测试指标
从MSRA-TD 500数据集上的结果可以看到,最近一两年文本检测的性能提升很快,时间复杂度也在不断降低,基本可以达到实际的使用需求,但依然存在很多问题。

文本检测评价指标存在的问题
一个问题是如果用IoU(交并比)来评价文本检测的效果并不能很好地体现算法的性能。
例如,在进行物体检测时,检测出50% IoU的框就可以得到很好的结果,但是在文字检测问题中,即使IoU大于50%,也并不一定能保证很好的识别。这是因为对于文字检测来说,不仅要得到文本框还要得到框内的内容和细节,这就是虽然很多检测方法定位得分很高,但是文字检测性能并不好的原因。


场景文字检测的应用
下面介绍一下场景文字检测的一些应用。
(一)细粒度识别任务中的应用
首先是在细粒度识别任务中的应用,我们发现将场景和文字结合起来会对细粒度识别提供很大帮助。尤其是在商品搜索中,因为很多商品包装上都印有文字,所以文字非常有助于商品的细粒度识别。
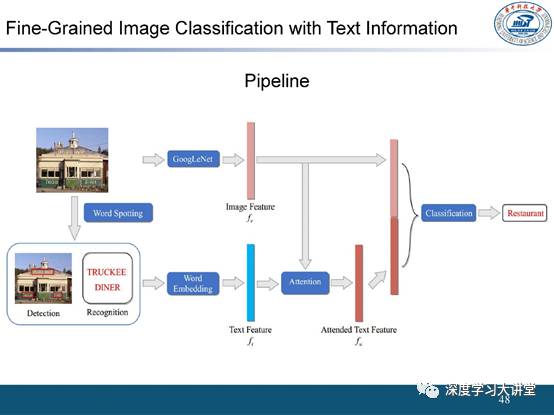
我们进行了一些这方面的尝试:
-
首先检测出文字,并使用词向量(Word Embedding)得到文本特征(Text Feature);
-
再利用注意机制(Attention Mechanism)学习到每个文本特征和图像的关联关系;
-
之后将文本特征(Text Feature)与图像特征(Image Feature)进行融合,最后基于融合的特征实现图像分类。
实验表明,在结合文字信息之后很多细粒度分类任务都能得到很好的提升。


(二)马拉松比赛中行人跟踪与检测
在马拉松比赛中需要对跑步的人进行跟踪和检测,通常的基于人脸的检测方法效果不好,但是在结合文字信息之后就能得到很好的跟踪和检测效果。

(三)港口的货箱识别
另一个应用场景是港口的货箱识别,使用文字检测来得到货箱的各种信息就可以实现对货箱的快速检查。

(四)以图搜题
还有一个应用是以图搜题,即在拍摄题目后,通过题目中的文字信息快速在题库中搜索相应的问题和答案。


文字检测的未来发展方向
-
其一是以后文字检测的热点依然会是场景文字的端到端识别(end-to-end recognition);
-
其二是如何在海量视频中快速检索感兴趣的文字;
-
其三是如何将文本和图片更好地融合。

文中所有引用文章的下载链接为:http://pan.baidu.com/s/1c2EKK0o
致谢:

本文主编袁基睿,诚挚感谢志愿者杨茹茵、贺娇瑜 、范琦 、李珊如,对本文进行了细致的整理工作。

该文章属于“深度学习大讲堂”原创,如需要转载,请联系astaryst。
作者信息:

白翔,华中科技大学电信学院教授,先后于华中科技大学获得学士、硕士、博士学位。他的主要研究领域为计算机视觉与模式识别、深度学习应用技术。尤其在形状的匹配与检索、相似性度量与融合、场景OCR取得了一系列重要研究成果,入选2014、2015、2016年Elsevier中国高被引学者。他的研究工作曾获微软学者,首届国家自然科学基金优秀青年基金的资助。他已在相关领域一流国际期刊或会议如PAMI、IJCV、CVPR、ICCV、ECCV、NIPS、ICML、AAAI、IJCAI上发表论文40余篇。任国际期刊Pattern Recognition, Pattern Recognition Letters, Neurocomputing, Frontier of Computer Science编委,VALSE指导委员,曾任VALSE在线委员会(VOOC)主席, VALSE 2016大会主席, 是VALSE在线活动(VALSE Webinar)主要发起人之一。
VALSE是视觉与学习青年学者研讨会的缩写,该研讨会致力于为计算机视觉、图像处理、模式识别与机器学习研究领域内的中国青年学者提供一个深层次学术交流的舞台。2017年4月底,VALSE2017在厦门圆满落幕,近期大讲堂将连续推出VALSE2017特刊。VALSE公众号为:VALSE,欢迎关注。

往期精彩回顾
杉山将:弱监督机器学习的研究进展 | CCAI 2017
沈春华:如何窥一斑而知全豹--Dense Per Pixel Prediction | VALSE2017之九
饮水思源--浅析深度学习框架设计中的关键技术
毕彦超:物体识别与物体知识表征的认知神经基础| VALSE2017之八
Seeta看AI:从大数据驱动到X数据驱动


欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:[email protected],想了解更多可以访问,www.seetatech.com

中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站