MySQL索引
MySQL索引
什么是索引
- 高效的获取数据库数据的数据结构,能够加快数据库的查询速度。
- 索引本身是很大的,不可能把全部储存在内存中,索引往往是存储在磁盘上的文件中的(可能会单独存储在索引文件中,也可能和数据一起存储在数据文件中)
- 索引包含了:
- 聚集索引
- 覆盖索引
- 组合索引
- 前缀索引
- 唯一索引
没有特别说明,默认都使用B+树结构组织,(多路搜索树,并不一定是二叉)索引。
用到索引之后,就不必去扫描整个数据库
索引的优势和劣势
优势
- 可以提高数据检索的效率,降低数据库的io成本,
- 通过索引列对数据进行排序,降低数据排序的成本,降低cpu的消耗
- 被索引的列会自动进行排序,包括单列索引,组合索引,只是组合索引的排序要复杂一点
- 如果按照索引列的顺序进行排序,对应的order by语句来说,效率会提高很多。
劣势
- 索引会占用磁盘的空间
- 索引虽然会提高查询的效率,但是会降低表的更新效率,
- 每次进行对表的增,删,改msql不仅要保存数据,还要保存或者更新对应的索引文件
添加索引的五种的方法
- 添加primary key(主键索引)
alter table 表名 add primary key(列名);
- 添加unique(唯一索引)
alter table 表名 add unique(列名);
- 添加index(普通索引)
alter table 表名 add index 索引名(index_name) (列名);
- 添加fulltext(全文索引)
alter table 表名 add fulltext (列名);
- 添加多列索引
alter table 表名 add index 索引名(index_name)(列名1,列名2,......)
删除索引的方法
- 使用DROP INDEX 语句
DROP INDEX 索引名 ON 表名
- 使用ALTER TABLE语句
该语句可以用于删除索引,是将ALTER TABLE语句的语法中部分指定为一下句中的某一项
DROP PRIMARY KEY:表示删除表中的一个主键,一个表只有一个主键,主键也是索引
DROP INDEX index_name:表示删除名为index_name的索引
DROP FORELGN KEY index_name:表示删除外键
如果删除的列是索引的组成部分,那么在删除该列时,也会将该列从索引中删除,
如果组成索引的所有列都被删除,那么整个索引都被删除。
索引的结构组成
索引的本质:
- 通过不断的缩小想要的获取数据的范围筛选出最终想要的结果,同时把随机的事件变成顺序的事件,有了索引机制可以总是用一种方式来锁定数据。
磁盘中数据的存取

扇区:磁盘存储的最小单位,一般为512Byte
磁盘块:文件系统与磁盘交互的最小单位(计算机系统读写磁盘的最小单位),一个磁盘块有连续的几个扇区组成,磁盘块一般为4kb;
磁盘读取的数据:磁盘读取数据靠的是机械运动,每次读取数据花费的时间分为:
- 寻道时间
- 磁头臂移动到磁道所需要的时间,
- 旋转时间
- 磁盘旋转时间
- 传输时间
- 从磁盘中读取或者写入的时间
MySQL中的页
MySQL中磁盘交互的最小单位为页,页是MySQL中内部定义的一种数据结构,默认为16kb,相当于4个磁盘块,mysql每次从磁盘中读取一次数据是16kb,要么不读取,如果要读取就是16kb,这个值可以修改。
数据检索过程
对数据存储方式不做任何的优化,直接将数据库中的数据存储在磁盘中。比如某表中中有一个字段,为int类型,int占有4Byte,每个磁盘块可以储存1000多条数据,100万的数据需要1000个磁盘块,如果我们需要在着100万条数据中检索需要的数据,需要读取着1000个磁盘块,每次对磁盘块的io时间等于9ms,那么1000次需要9000ms等于9秒。
优化需求
1,需要一种数据存储结构:当从磁盘中检索数据的时候,能够减少磁盘的io次数,最好能够减低一个稳定的常量值。
2,需要一种检索算法:当从磁盘中读取磁盘块的数据之后,这些磁盘块中可能包含多条数据,这些数据加载到一个内存中,那么这个算法能够快速的从内存多条数据中快速检索出需要数据。
循环遍历查找
从一组无序的数据中查找目标数据吗,常见的方法是遍历查找,n条数据,数据复杂度为O(n),最快需要一次,最坏的情况需要n次。
查询效率不稳定
二分法查找
二分法查找也称为:折半查找,用于有序的数组中快速定义某一个需要查找的数据。
原理:
- 先将一组无序的数据排序(升序,降序)之后放在数组中;
升序举例:
- [1,2,3,4,5,6,7,8,9]数组查9
- 第一次查:中间值为5,9>5将范围缩小到[6,7,8,9]
- 第二次查:中间值为7和8,9>7/9>8
- 第三次查:在[9]中查9,找到了,
二分发查找数据的优点:定位数据非常块,前提:目标数组必须是有序的
有序数组
如果我们将mysql中的表数据以有序的数组方式存储在磁盘中,定位数据步骤是:
- 取出目标中的所有数据,存放在一个有序数组中(io次数过多)
- 如果目标表中的数据量非常大,从磁盘中加载到内存中需要的内存也非常大(消耗的内存空间过大)
在排序期间将数据排序需要耗费时间
链表
- 每一个data中由指针域和数据域组成为结点,指针域中的指针指向下一个结点,这样的链式数据被成为链表
- 链表的第一个结点称为,首元结点,在初始化的时候头指针始终指向首元结点
- 在首元结点之前有个头结点一般不存放数据,存放该链表的长度(size);
单链表
每个结点中持指向下一个结点的指针,只能按照一个方向遍历链表,
public class Node{
private Object data;//数据域
private Node nextNode;//指向下一个结点
}
双向链表
每一个结点中有两个指针域,分别指向当前结点的上一个结点(前驱)和下一个结点(后继)
public class Node{
private Object data;//数据域
private Node prevNode;//指向上一个结点(前驱)
private Node nextNode;//指向下一个结点(后继)
}
优点
- 可以快速的定位到上一个或者下一个结点
- 增**(只需改变指针的指向),删(改变该结点前驱指针的指向)**,改速度快
缺点
- 查找速度慢**(通过指针逐个移动查找)**
- 无法像数组一样,通过下标随机访问数据
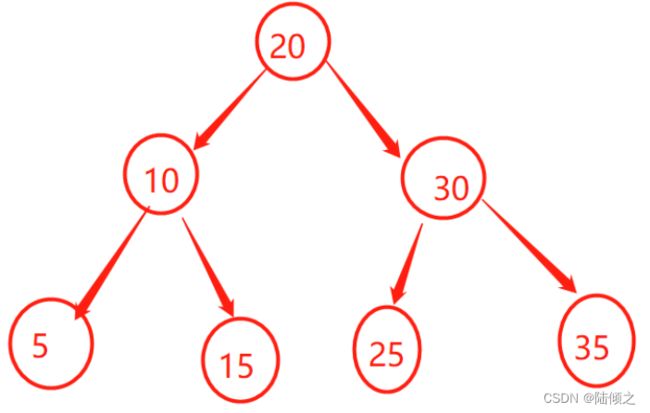
二叉树
二叉树式每个结点最多有两个子树结构,子树分别称为:左子树(left subtree),右子树(right subtree),二叉树常被用来二叉查找和二叉堆
二叉树特征:
每个结点都包含一个元素以及n个子树,0<=n<2
左子树和右子树是有序的,次序无法任意颠倒的,左子树要小于父节点,右子树的值要大于父节点
优点
- 树结构有序,
缺点
- 数据量大的情况下,会导致树的高度变高,如果每个结点对应磁盘块来存储一个数据,需要的io成本增加了,显的此结构来存储数据不可取的。
B+树
- B+树索引
- B+树在数据库中的一种实现,是最常见也是数据库中使用最为频繁的以一种索引,
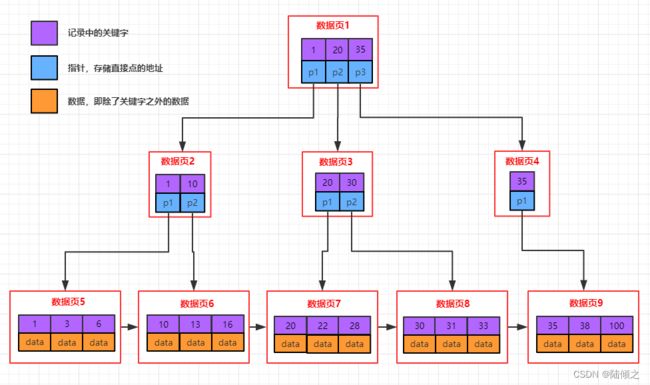
B+树的特征
- 每一个结点有n个子女
- 除了根结点外,每个结点至少有(n/2)个子女,根结点至少有两个子女
- 有x个子女的结点必有x个关键字
- 父节点中持有访问子节点的指针
- 父节点的关键字在子节点中存在,
- 除了叶子结点外,其他的结点都不存储数据
- 叶子结点之间用链表连接起来,可以非常方便范围查找