IoTDB学习笔记
IoTDB
IoTDB简介
IoTDB (Internet of Things Database) 是一款时序数据库管理系统,可以为用户提供数据收集、存储和分析等服务。IoTDB由于其轻量级架构、高性能和高可用的特性,以及与 Hadoop 和 Spark 生态的无缝集成,满足了工业 IoT 领域中海量数据存储、高吞吐量数据写入和复杂数据查询分析的需求。
IoTDB是针对时间序列数据收集、存储与分析一体化的数据管理引擎。它具有体量轻、性能高、易使用的特点,完美对接Hadoop与Spark生态,适用于工业物联网应用中海量时间序列数据高速写入和复杂分析查询的需求。
IoTDB 是一个用于管理大量时间序列数据的数据库,它采用了列式存储、数据编码、预计算和索引技术,具有类 SQL 的接口,可支持每秒每节点写入数百万数据点,可以秒级获得超过数万亿个数据点的查询结果。它还可以很容易地与 Apache Hadoop、MapReduce 和 Apache Spark 集成以进行分析。
主要功能特点
IoTDB具有以下特点:
- 灵活的部署方式
- 云端一键部署
- 终端解压即用
- 终端-云端无缝连接(数据云端同步工具)
- 低硬件成本的存储解决方案
- 高压缩比的磁盘存储(10亿数据点硬盘成本低于1.4元)
- 目录结构的时间序列组织管理方式
- 支持复杂结构的智能网联设备的时间序列组织
- 支持大量同类物联网设备的时间序列组织
- 可用模糊方式对海量复杂的时间序列目录结构进行检索
- 高通量的时间序列数据读写
- 支持百万级低功耗强连接设备数据接入(海量)
- 支持智能网联设备数据高速读写(高速)
- 以及同时具备上述特点的混合负载
- 面向时间序列的丰富查询语义
- 跨设备、跨传感器的时间序列时间对齐
- 面向时序数据特征的计算
- 提供面向时间维度的丰富聚合函数支持
- 极低的学习门槛
- 支持类SQL的数据操作
- 提供JDBC的编程接口
- 完善的导入导出工具
- 完美对接开源生态环境
- 支持开源数据分析生态系统:Hadoop、Spark
- 支持开源可视化工具对接:Grafana
系统架构
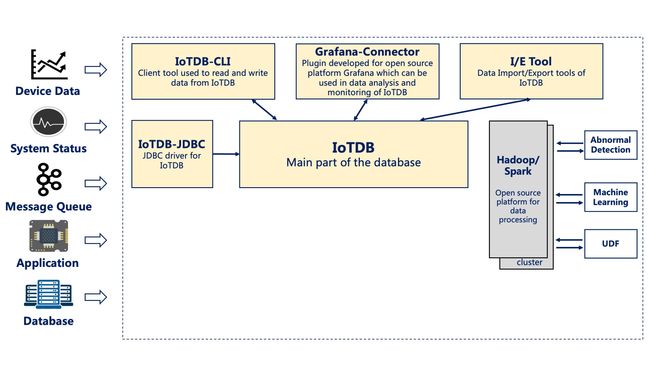
IoTDB套件由若干个组件构成,共同形成“数据收集-数据写入-数据存储-数据查询-数据可视化-数据分析”等一系列功能。
如下图展示了使用IoTDB套件全部组件后形成的整体应用架构。
下文称所有组件形成IoTDB套件,而IoTDB特指其中的时间序列数据库组件。
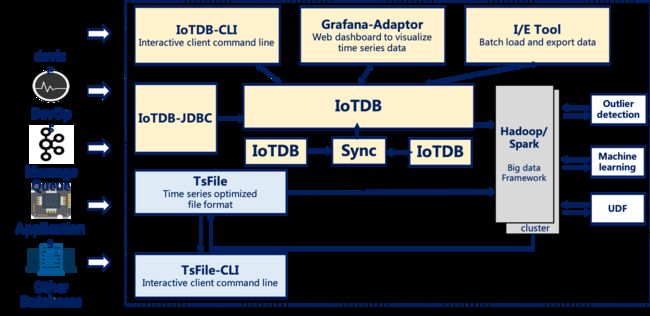
在上图中,用户可以通过JDBC将来自设备上传感器采集的时序数据、服务器负载和CPU内存等系统状态数据、消息队列中的时序数据、应用程序的时序数据或者其他数据库中的时序数据导入到本地或者远程的IoTDB中。用户还可以将上述数据直接写成本地(或位于HDFS上)的TsFile文件。
可以将TsFile文件写入到HDFS上,进而实现在Hadoop或Spark的数据处理平台上的诸如异常检测、机器学习等数据处理任务。
对于写入到HDFS或者本地的TsFile文件,可以利用TsFile-Hadoop或TsFile-Spark连接器允许Hadoop或Spark进行数据处理。
对于分析的结果,可以写回成TsFile文件。
IoTDB和TsFile还提供了相应的客户端工具,满足用户查看和写入数据的SQL形式、脚本形式和图形化形式等多种需求。
应用场景
- 场景1
某公司采用表面贴装技术(SMT)生产芯片:需要首先在芯片上的焊接点处印刷(即涂抹)锡膏,然后将元器件放置在锡膏上,进而通过加热熔化锡膏并冷却,使得元器件被焊接在芯片上。上述流程采用自动化生产线。为了确保产品质量合格,在印刷锡膏后,需要通过光学设备对锡膏印刷的质量进行评估:采用三维锡膏印刷检测(SPI)设备对每个焊接点上的锡膏的体积(v)、高度(h)、面积(a)、水平偏移(px)、竖直偏移(py)进行度量。
为了提升印刷质量,该公司有必要将各个芯片上焊接点的度量值进行存储,以便后续基于这些数据进行分析。
此时可以采用IoTDB套件中的TsFile组件、TsFileSync工具和Hadoop/Spark集成组件对数据进行存储:每新印刷一个芯片,就在SPI设备上使用SDK写一条数据,这些数据最终形成一个TsFile文件。通过TsFileSync工具,生成的TsFile文件将按一定规则(如每天)被同步到Hadoop数据中心,并由数据分析人员对其进行分析。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5OiMa8Kq-1650443396270)(F:\ZHL\学习\学习笔记\IoTDB学习笔记\static\img\每新印刷一个芯片,就在SPI设备上使用SDK写一条数据,这些数据最终形成一个TsFile文件.png)]
在场景1中,仅需要TsFile、TsFileSync部署在一台PC上,此外还需要部署Hadoop/Spark连接器用于数据中心端Hadoop/Spark集群的数据存储和分析。其示意图如上图所示。下图展示了此时的应用架构。
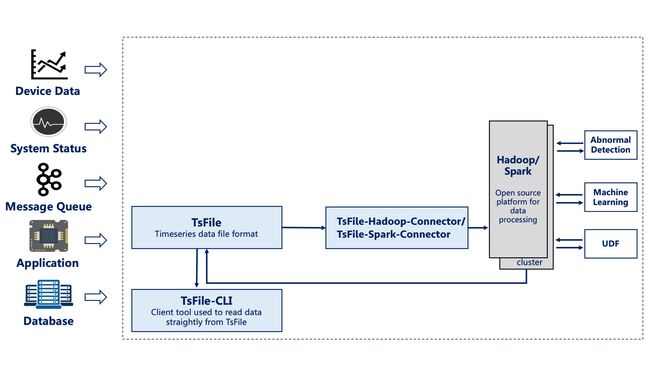
- 场景2
某公司拥有多座风力发电机,公司在每个发电机上安装了上百种传感器,分别采集该发电机的工作状态、工作环境中的风速等信息。
为了保证发电机的正常运转并对发电机及时监控和分析,公司需要收集这些传感器信息,在发电机工作环境中进行部分计算和分析,还需要将收集的原始信息上传到数据中心。
此时可以采用IoTDB套件中的IoTDB、TsFileSync工具和Hadoop/Spark集成组件等。需要部署一个场控PC机,其上安装IoTDB和TsFileSync工具,用于支持读写数据、本地计算和分析以及上传数据到数据中心。此外还需要部署Hadoop/Spark连接器用于数据中心端Hadoop/Spark集群的数据存储和分析。如下图所示。
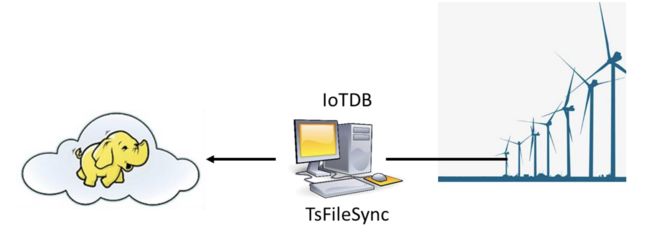
下图给出了此时的应用架构。
- 场景3
某工厂在厂区范围内拥有多种机械手设备,这些机械手设备的硬件配置有限,很难搭载复杂的应用程序。在每个机械手设备上工厂安装了很多种传感器,用以对机械手的工作状态、温度等信息进行监控。由于工厂的网络环境原因,在工厂内部的机械手均处于工厂内部局域网内,无法连接外部网络。同时,工厂中会有少量服务器能够直接连接外部公网。
为了保证机械手的监控数据能够及时监控和分析,公司需要收集这些机械手传感器信息,将其发送至可以连接外部网络的服务器上,而后将原始数据信息上传到数据中心进行复杂的计算和分析。
此时,可以采用IoTDB套件中的IoTDB、IoTDB-Client工具、TsFileSync工具和Hadoop/Spark集成组件等。将IoTDB服务器安装在工厂连接外网的服务器上,用户接收机械手传输的数据并将数据上传到数据中心。将IoTDB-Client工具安装在每一个连接工厂内网的机械手上,用于将传感器产生的实时数据上传到工厂内部服务器。再使用TsFileSync工具将原始数据上传到数据中心。此外还需要部署Hadoop/Spark连接器用于数据中心端Hadoop/Spark集群的数据存储和分析。如下图中间场景所示。

下图给出了此时的应用架构。

- 场景4
某汽车公司在其下属的汽车上均安装了传感器采集车辆的行驶状态等监控信息。这些汽车设备的硬件配置有限,很难搭载复杂的应用程序。安装传感器的汽车可以通过窄带物联网相互连接,也可以通过窄带物联网将数据发送至外部网络。
为了能够实时接收汽车传感器所采集的物联网数据,公司需要在车辆行驶的过程中将传感器数据通过窄带物联网实时发送至数据中心,而后在数据中心的服务器上进行复杂的计算和分析。
此时,可以采用IoTDB套件中的IoTDB、IoTDB-Client和Hadoop/Spark集成组件等。将IoTDB-Client工具安装在每一辆车联网内的车辆上,使用IoTDB-JDBC工具将数据直接传回数据中心的服务器。
此外还需要部署Hadoop/Spark集群用于数据中心端的数据存储和分析。如下图所示。

快速上手
GitHub:https://github.com/apache/iotdb
安装环境
安装前需要保证设备上配有JDK>=1.8的运行环境,并配置好JAVA_HOME环境变量。
(目前 1.8、11和13 已经被验证可用。请确保环变量境路径已正确设置)。
- Maven >= 3.6 (如果希望从源代码编译和安装IoTDB)。
- 设置 max open files 为 65535,以避免"too many open files"错误。
- 将 somaxconn 设置为 65535 以避免系统在高负载时出现 “connection reset” 错误。 (可选)
# Linux
> sudo sysctl -w net.core.somaxconn=65535
# FreeBSD or Darwin
> sudo sysctl -w kern.ipc.somaxconn=65535
注: 也可以选择不安装,使用我们提供的’mvnw.sh’ 或 ‘mvnw.cmd’ 工具。使用时请用’mvnw.sh’ 或 'mvnw.cmd’命令代替下文的’mvn’命令。
安装步骤
IoTDB支持多种安装途径。用户可以使用三种方式对IoTDB进行安装——使用源码、下载二进制可运行程序、使用docker镜像。
- 使用源码:您可以从代码仓库下载源码并编译,具体编译方法见下方。
- 下载二进制可运行程序:请从下载 (opens new window)页面下载最新的安装包,解压后即完成安装。
- 使用Docker镜像:dockerfile 文件位于 https://github.com/apache/iotdb/blob/master/docker/src/main
软件目录结构
- sbin 启动和停止脚本目录
- conf 配置文件目录
- tools 系统工具目录
- lib 依赖包目录
IoTDB试用
用户可以根据以下操作对IoTDB进行简单的试用,若以下操作均无误,则说明IoTDB安装成功。
启动IoTDB
用户可以使用sbin文件夹下的start-server脚本启动IoTDB。
Linux系统与MacOS系统启动命令如下:
nohup sbin/start-server.sh >/dev/null 2>&1 & or nohup sbin/start-server.sh -c <conf_path> -rpc_port <rpc_port> >/dev/null 2>&1 &
Windows系统启动命令如下:
sbin\start-server.bat -c <conf_path> -rpc_port <rpc_port>
- “-c” and “-rpc_port” 都是可选的。
- 选项 “-c” 指定了配置文件所在的文件夹。
- 选项 “-rpc_port” 指定了启动的 rpc port。
- 如果两个选项同时指定,那么rpc_port将会覆盖conf_path下面的配置。
使用Cli工具
IoTDB为用户提供多种与服务器交互的方式,在此我们介绍使用Cli工具进行写入、查询数据的基本步骤。
初始安装后的IoTDB中有一个默认用户:root,默认密码为root。用户可以使用该用户运行Cli工具操作IoTDB。
Cli工具启动脚本为sbin文件夹下的start-cli脚本。启动脚本时需要指定运行ip、port、username和password。若脚本未给定对应参数,则默认参数为"-h 127.0.0.1 -p 6667 -u root -pw -root"
以下启动语句为服务器在本机运行,且用户未更改运行端口号的示例。
Linux系统与MacOS系统启动命令如下:
sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root
Windows系统启动命令如下:
sbin\start-cli.bat -h 127.0.0.1 -p 6667 -u root -pw root
启动后出现如图提示即为启动成功。

IoTDB的基本操作
在这里,我们首先介绍一下使用Cli工具创建时间序列、插入数据并查看数据的方法。
创建组
数据在IoTDB中的组织形式是以时间序列为单位,每一个时间序列中有若干个数据-时间点对,每一个时间序列属于一个存储组。在定义时间序列之前,要首先使用SET STORAGE GROUP语句定义存储组。SQL语句如下:
定义存储组相当于创建了一个表 。创建的组必须依托与一个用户下,如下可以理解成在root用户下创建了一个ln的组。但是查询的时候
root.ln要做为一个整体,可以看成是一个组的名为root.ln。
SET STORAGE GROUP TO root.ln

查看组
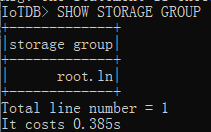
我们可以使用SHOW STORAGE GROUP语句来查看系统当前所有的存储组,SQL语句如下:
# 查看组
SHOW STORAGE GROUP
执行结果为:
IoTDB> SHOW STORAGE GROUP
+-------------+
|storage group|
+-------------+
| root.ln|
+-------------+
Total line number = 1
It costs 0.385s
创建TIMESERIES
存储组设定后,使用CREATE TIMESERIES语句可以创建新的时间序列,创建时间序列时需要定义数据的类型和编码方式。此处我们创建两个时间序列,SQL语句如下:
下列语句表示在
root.ln组中创建了status和temperature两个时间序列,时间序列相当于表中的字段。
# 创建TIMESERIES
CREATE TIMESERIES root.ln.wf01.wt01.status WITH DATATYPE=BOOLEAN, ENCODING=PLAIN
CREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE

数据类型
IoTDB总共支持六种数据类型
- BOOLEAN(布尔值)
- INT32(整数)
- INT64(长整数)
- FLOAT(单精度浮点数)
- DOUBLE(双精度浮点数)
- TEXT(字符串)
在创建浮点数的时候,可以通过 MAX_POINT_NUMBER 指定浮点数小数点后的位数。
编码方式
IoTDB编码作用
写入期间对数据进行编码,提高数据存储的效率,减少I / O操作中涉及的数据量以提高性能。
- PLAIN(PLAIN编码是默认的编码模式,即不编码,它支持多种数据类型。它具有较高的压缩和解压缩效率,同时空间存储效率低。
- TS_2DIFF(二阶差分编码更适合于单调递增或递减的序列数据的编码,不建议用于波动较大的序列数据)。
- RLE(存储具有连续整数值的序列,而不建议用于大多数时间值不同的序列数据,也可用于对浮点数进行编码,浮点值连续出现、单调递增或递减,不适合存储小数点后精度要求高或波动较大的序列数据)。
- GORILLA(具有相似值的浮点序列,不建议将其用于具有较大波动的序列数据)。
- REGULAR(更适合于对规则序列递增的数据,在这种情况下它比TS_2DIFF要好)。
如果在创建时间序列时候,编码方式和数据类型没有对上,会报错。
| 数据类型 | 支持的编码 |
|---|---|
| BOOLEAN | PLAIN, RLE |
| INT32 | PLAIN, RLE, TS_2DIFF, REGULAR |
| INT64 | PLAIN, RLE, TS_2DIFF, REGULAR |
| FLOAT | PLAIN, RLE, TS_2DIFF, GORILLA |
| DOUBLE | PLAIN, RLE, TS_2DIFF, GORILLA |
| TEXT | PLAIN |
压缩
使用压缩技术压缩数据以进一步提高空间存储效率。但编码技术通常只适用于特定的数据类型,压缩不受数据类型的限制。
支持二种
- UNCOMPRESSED (未压缩)
- SNAPPY (默认)
查看表
为了查看指定的时间序列,我们可以使用SHOW TIMESERIES 语句,其中
使用SHOW TIMESERIES语句查看系统中存在的所有时间序列,SQL语句如下:
# 查看表
SHOW TIMESERIES
执行结果为:
IoTDB> SHOW TIMESERIES
+-----------------------------+-----+-------------+--------+--------+-----------+----+----------+
| timeseries|alias|storage group|dataType|encoding|compression|tags|attributes|
+-----------------------------+-----+-------------+--------+--------+-----------+----+----------+
|root.ln.wf01.wt01.temperature| null| root.ln| FLOAT| RLE| SNAPPY|null| null|
| root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|null| null|
+-----------------------------+-----+-------------+--------+--------+-----------+----+----------+
Total line number = 2
It costs 0.073s

查看具体的时间序列root.ln.wf01.wt01.status的SQL语句如下:
SHOW TIMESERIES root.ln.wf01.wt01.status
执行结果为:
IoTDB> SHOW TIMESERIES root.ln.wf01.wt01.status
+------------------------+-----+-------------+--------+--------+-----------+----+----------+
| timeseries|alias|storage group|dataType|encoding|compression|tags|attributes|
+------------------------+-----+-------------+--------+--------+-----------+----+----------+
|root.ln.wf01.wt01.status| null| root.ln| BOOLEAN| PLAIN| SNAPPY|null| null|
+------------------------+-----+-------------+--------+--------+-----------+----+----------+
Total line number = 1
It costs 0.031s

插入数据
接下来,我们使用INSERT语句向root.ln.wf01.wt01.status时间序列中插入数据,在插入数据时需要首先指定时间戳和路径后缀名称:
插入时 第一个 timestamp 时序不能重复否则会被覆盖。
# 插入数据
INSERT INTO root.ln.wf01.wt01(timestamp,status) values(100,true);
我们也可以向多个时间序列中同时插入数据,这些时间序列同属于一个时间戳:
![]()
INSERT INTO root.ln.wf01.wt01(timestamp,status,temperature) values(200,false,20.71)
查询数据
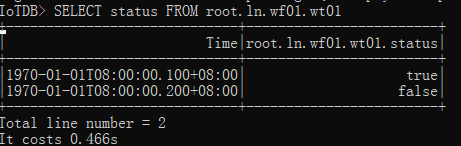
最后,我们查询之前插入的数据。使用SELECT语句我们可以查询指定的时间序列的数据结果,SQL语句如下:
# 查询数据
SELECT status FROM root.ln.wf01.wt01
查询结果如下:
IoTDB> SELECT status FROM root.ln.wf01.wt01
+-----------------------------+------------------------+
| Time|root.ln.wf01.wt01.status|
+-----------------------------+------------------------+
|1970-01-01T08:00:00.100+08:00| true|
|1970-01-01T08:00:00.200+08:00| false|
+-----------------------------+------------------------+
Total line number = 2
It costs 0.466s
我们也可以查询多个时间序列的数据结果,SQL语句如下:
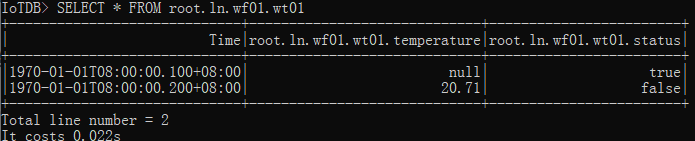
SELECT * FROM root.ln.wf01.wt01
查询结果如下:
IoTDB> SELECT * FROM root.ln.wf01.wt01
+-----------------------------+-----------------------------+------------------------+
| Time|root.ln.wf01.wt01.temperature|root.ln.wf01.wt01.status|
+-----------------------------+-----------------------------+------------------------+
|1970-01-01T08:00:00.100+08:00| null| true|
|1970-01-01T08:00:00.200+08:00| 20.71| false|
+-----------------------------+-----------------------------+------------------------+
Total line number = 2
It costs 0.022s
插入更新 别名、标签、属性
# 插入更新 别名、标签、属性
ALTER timeseries root.test.person01.name01.nickname UPSERT ALIAS=t_test TAGS(unit=Degree,owner=me) ATTRIBUTES(description=testiotdb,newAttr=v1)
查看表
SHOW TIMESERIES root.test.person01.name01.nickname

删除表
# 删除表
DELETE FROM root.ln.wf01.wt01
查询数据
SELECT * FROM root.ln.wf01.wt01

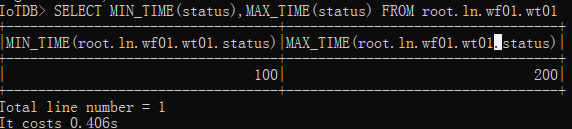
查询最大最小时间
# 查询最大最小时间
SELECT MIN_TIME(status),MAX_TIME(status) FROM root.ln.wf01.wt01
插入当前时间
INSERT INTO root.test.person01.name01(timestamp,nickname) values(now(),"lw")
查看数据
SELECT nickname FROM root.test.person01.name01
退出
输入quit或exit可退出Cli结束本次会话。
quit
或
exit
想要浏览更多IoTDB数据库支持的命令,请浏览SQL Reference.
停止IoTDB
用户可以使用$IOTDB_HOME/sbin文件夹下的stop-server脚本停止IoTDB。
Linux系统与MacOS系统停止命令如下:
$sbin/stop-server.sh
Windows系统停止命令如下:
$sbin\stop-server.bat
只编译 server
在 iotdb 根目录下执行:
mvn clean package -pl server -am -DskipTests
编译完成后,IoTDB server 将生成在: “server/target/iotdb-server-{project.version}”。
只编译 cli
在 iotdb 根目录下执行:
mvn clean package -pl cli -am -DskipTests
编译完成后,IoTDB cli 将生成在 “cli/target/iotdb-cli-{project.version}”。
基础配置
配置文件在"conf"文件夹下,包括:
- 环境配置模块 (
iotdb-env.bat,iotdb-env.sh), - 系统配置模块 (
iotdb-engine.properties) - 日志配置模块 (
logback.xml).
数据文件存储
IoTDB需要存储的数据分为三类,分别为数据文件、系统文件以及写前日志文件。
数据文件
数据文件存储了用户写入IoTDB系统的所有数据。包含TsFile文件和其他文件,可通过data_dirs配置项进行配置。
为了更好的支持用户对于磁盘空间扩展等存储需求,IoTDB为TsFile的存储配置增加了多文件目录的存储方式,用户可自主配置多个存储路径作为数据的持久化位置(详情见data_dirs配置项),并可以指定或自定义目录选择策略(详情见mult_dir_strategy配置项)。
系统文件
系统Schema文件,存储了数据文件的元数据信息。可通过base_dir配置项进行配置(详情见base_dir配置项)。
写前日志文件
写前日志文件存储了系统的写前日志。可通过wal_dir配置项进行配置(详情见wal_dir配置项)。
数据存储目录设置举例
接下来我们将举一个数据目录配置的例子,来具体说明如何配置数据的存储目录。
IoTDB涉及到的所有数据目录路径有:data_dirs, mult_dir_strategy, base_dir和wal_dir,它们分别涉及的是IoTDB的数据文件、系统文件以及写前日志文件。您可以选择输入路径自行配置,也可以不进行任何操作使用系统默认的配置项。
以下我们给出一个用户对五个目录都进行自行配置的例子。
base_dir=$IOTDB_HOME/data
data_dirs=/data1/data, /data2/data, /data3/data
multi_dir_strategy=MaxDiskUsableSpaceFirstStrategy
wal_dir= $IOTDB_HOME/data/wal
按照上述配置,系统会:
- 将TsFile存储在路径
/data1/data、路径/data2/data和路径data3/data3中。且对这三个路径的选择策略是:优先选择磁盘剩余空间最大的目录,即在每次数据持久化到磁盘时系统会自动选择磁盘剩余空间最大的一个目录将数据进行写入 - 将系统文件存储在
$IOTDB_HOME/data - 将写前日志文件存储在
$IOTDB_HOME/data/wal
数据模型与概念
数据模型
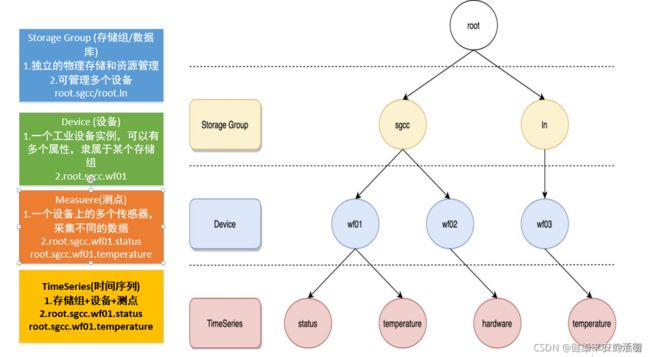
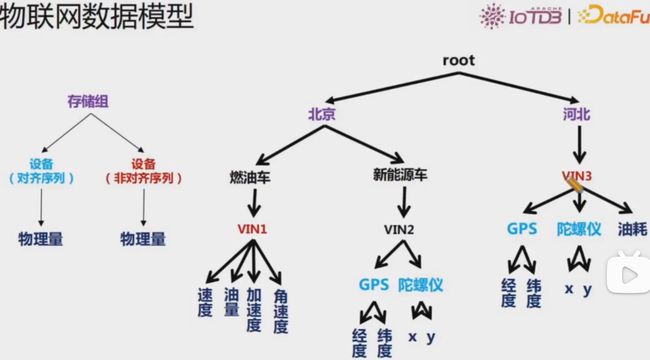
root 是整个树状结构的父节点, iotdb有存储组、设备、测点等概念,数据在存储的时候,不同的存储组的数据是存储在不同的文件夹中的。上图中有root.sgcc、root.ln两个存储组。叶子节点叫做测点,叶子节点的父节点叫做设备 。 从父节点 root 到叶子节点的全路径叫做时间序列。 比如上图中有root.sgcc.wf01.status 等 4 条时间序列。
IoTDB的语法规定, ROOT节点到叶子节点的路径以
.连接,以此完整路径命名IoTDB中的一个时间序列。ROOT.ln.wf01.wt01.status
我们以风电场物联网场景为例,说明如何在 IoTDB 中创建一个正确的数据模型。
根据企业组织结构和设备实体层次结构,我们将其物联网数据模型表示为如下图所示的属性层级组织结构,即电力集团层-风电场层-实体层-物理量层。其中 ROOT 为根节点,物理量层的每一个节点为叶子节点。IoTDB 采用树形结构定义数据模式,以从 ROOT 节点到叶子节点的路径来命名一个时间序列,层次间以“.”连接。例如,下图最左侧路径对应的时间序列名称为ROOT.ln.wf01.wt01.status。
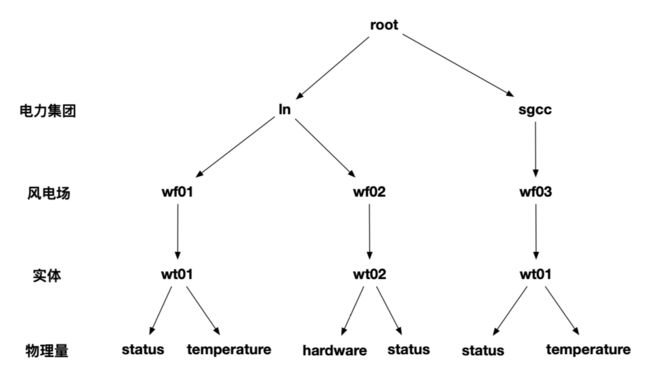
在上图所描述的实际场景中,有许多实体所采集的物理量相同,即具有相同的工况名称和类型,因此,可以声明一个元数据模板来定义可采集的物理量集合。在实践中,元数据模板的使用可帮助减少元数据的资源占用,详细内容参见 元数据模板文档。
物理量、实体、存储组、路径
物理量(Measurement)
物理量,也称工况或字段(field),是在实际场景中检测装置所记录的测量信息,且可以按一定规律变换成为电信号或其他所需形式的信息输出并发送给 IoTDB。在 IoTDB 当中,存储的所有数据及路径,都是以物理量为单位进行组织。
实体(Entity)
一个物理实体,也称设备(device),是在实际场景中拥有物理量的设备或装置。在 IoTDB 当中,所有的物理量都有其对应的归属实体。
存储组(Storage group)
一组物理实体,用户可以将任意前缀路径设置成存储组。如有 4 条时间序列root.ln.wf01.wt01.status, root.ln.wf01.wt01.temperature, root.ln.wf02.wt02.hardware, root.ln.wf02.wt02.status,路径root.ln下的两个实体 wt01, wt02可能属于同一个业主,或者同一个制造商,这时候就可以将前缀路径root.ln指定为一个存储组。未来root.ln下增加了新的实体,也将属于该存储组。
一个存储组中的所有实体的数据会存储在同一个文件夹下,不同存储组的实体数据会存储在磁盘的不同文件夹下,从而实现物理隔离。
注意 1:不允许将一个完整路径(如上例的
root.ln.wf01.wt01.status) 设置成存储组。注意 2:一个时间序列其前缀必须属于某个存储组。在创建时间序列之前,用户必须设定该序列属于哪个存储组(Storage Group)。只有设置了存储组的时间序列才可以被持久化在磁盘上。
一个前缀路径一旦被设定成存储组后就不可以再更改这个存储组的设定。
一个存储组设定后,其对应的前缀路径的祖先层级与孩子及后裔层级也不允许再设置存储组(如,root.ln设置存储组后,root 层级与root.ln.wf01不允许被设置为存储组)。
存储组节点名只支持中英文字符、数字、下划线和中划线的组合。例如root. 存储组_1-组1
路径(Path)
路径(path)是指符合以下约束的表达式:
path
: layer_name ('.' layer_name)*
;
layer_name
: wildcard? id wildcard?
| wildcard
;
wildcard
: '*'
| '**'
;
其中,对 id 的定义可以参考语法约定。
我们称一个路径中由 '.' 分割的部分叫做层级(layer_name)。例如:root.a.b.c为一个层级为 4 的路径。
下面是对层级(layer_name)的约束:
-
root作为一个保留字符,它只允许出现在下文提到的时间序列的开头,若其他层级出现root,则无法解析,提示报错。 -
除了时间序列的开头的层级(
root)外,其他的层级支持的字符如下:- 中文字符
"\u2E80"到"\u9FFF" "_","@","#","$""A"到"Z","a"到"z","0"到"9"
- 中文字符
-
除了时间序列的开头的层级(
root)和存储组层级外,层级还支持使用被`或者"符号引用的特殊字符串作为其名称。需要注意的是,被引用的字符串不可带有.字符。下面是一些合法的例子:-
root.sg."select"."+-from="."where""where"""."$",6 个层级分别为 root, sg, select, +-from, where"where", $ -
root.sg.````.`select`.`+="from"`.`$`,6 个层级分别为 root, sg, `, select, +-"from", $
-
-
层级 (
layer_name) 不允许以数字开头,除非层级 (layer_name) 以 `或者"引用。 -
特别地,如果系统在 Windows 系统上部署,那么存储组层级名称是大小写不敏感的。例如,同时创建
root.ln和root.LN是不被允许的。
路径模式(Path Pattern)
为了使得在表达多个时间序列的时候更加方便快捷,IoTDB 为用户提供带通配符*或**的路径。用户可以利用两种通配符构造出期望的路径模式。通配符可以出现在路径中的任何层。
*在路径中表示一层。例如root.vehicle.*.sensor1代表的是以root.vehicle为前缀,以sensor1为后缀,层次等于 4 层的路径。
**在路径中表示是(*)+,即为一层或多层*。例如root.vehicle.device1.**代表的是root.vehicle.device1.*, root.vehicle.device1.*.*, root.vehicle.device1.*.*.*等所有以root.vehicle.device1为前缀路径的大于等于 4 层的路径;root.vehicle.**.sensor1代表的是以root.vehicle为前缀,以sensor1为后缀,层次大于等于 4 层的路径。
注意:
*和**不能放在路径开头。
时间序列
时间戳 (Timestamp)
时间戳是一个数据到来的时间点,其中包括绝对时间戳和相对时间戳,详细描述参见 数据类型文档。
数据点(Data Point)
一个“时间戳-值”对。
时间序列(Timeseries)
一个物理实体的某个物理量在时间轴上的记录,是数据点的序列。
一个实体的一个物理量对应一个时间序列,即实体+物理量=时间序列。
时间序列也被称测点(meter)、时间线(timeline)。实时数据库中常被称作标签(tag)、参数(parameter)。
例如,ln 电力集团、wf01 风电场的实体 wt01 有名为 status 的物理量,则它的时间序列可以表示为:root.ln.wf01.wt01.status。
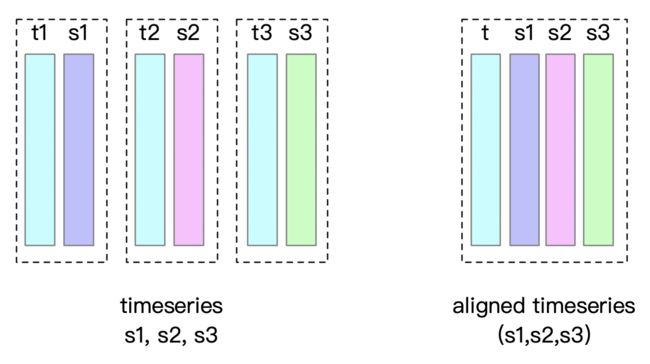
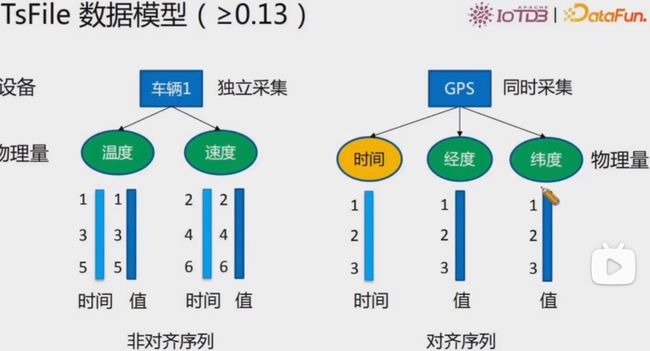
对齐时间序列(Aligned Timeseries)
在实际应用中,存在某些实体的多个物理量同时采样,形成在时间列上对齐的多条时间序列。
通过使用对齐的时间序列,在插入数据时,一组对齐序列的时间戳列在内存和磁盘中仅需存储一次,而不是每个时间序列存储一次。
对齐的一组时间序列最好同时创建。
不可以在对齐序列所属的实体下创建非对齐的序列,不可以在非对齐序列所属的实体下创建对齐序列。
查询数据时,可以对于每一条时间序列单独查询。
插入数据时,对齐的时间序列中某列的某些行允许有空值。
时间序列数据库比较时间序列数据库比较
已知的时间序列数据库
随着时间序列数据变得越来越重要,一些开源的时间序列数据库(Time Series Databases,or TSDB)诞生了。
但是,它们中很少有专门为物联网(IoT)或者工业物联网(Industrial IoT,缩写 IIoT)场景开发的。
本文把 IoTDB 和下述三种类型的时间序列数据库进行了比较:
-
InfluxDB - 原生时间序列数据库
InfluxDB 是最流行的时间序列数据库之一。
接口:InfluxQL and HTTP API
-
OpenTSDB 和 KairosDB - 基于 NoSQL 的时间序列数据库
这两种数据库是相似的,但是 OpenTSDB 基于 HBase 而 KairosDB 基于 Cassandra。
它们两个都提供 RESTful 风格的 API。
接口:Restful API
-
TimescaleDB - 基于关系型数据库的时间序列数据库
接口:SQL
Prometheus 和 Druid 也因为时间序列数据管理而闻名,但是 Prometheus 聚焦在数据采集、可视化和报警,Druid 聚焦在 OLAP 负载的数据分析,因此本文省略了 Prometheus 和 Druid。
比较
本文将从以下两个角度比较时间序列数据库:功能比较、性能比较。
功能比较
以下两节分别是时间序列数据库的基础功能比较和高级功能比较。
表格中符号的含义:
++:强大支持+:支持+-:支持但欠佳-:不支持?:未知
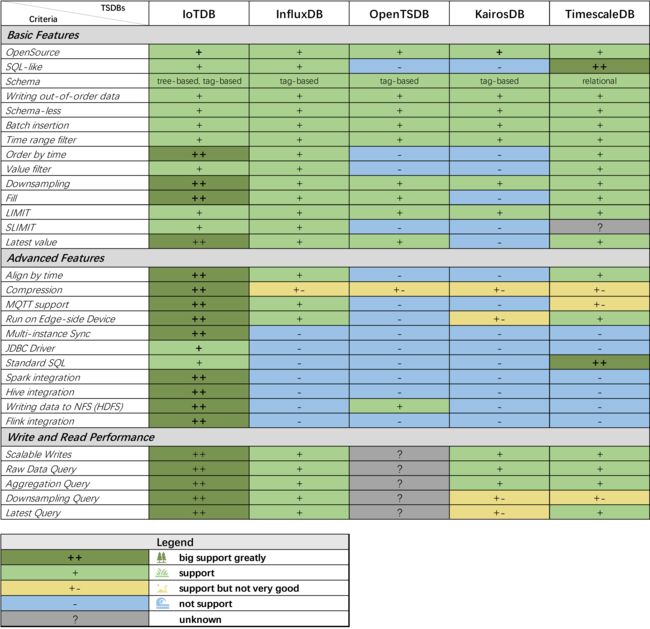
基础功能
| TSDB | IoTDB | InfluxDB | OpenTSDB | KairosDB | TimescaleDB |
|---|---|---|---|---|---|
| OpenSource | + | + | + | + | + |
| SQL-like | + | + | - | - | ++ |
| Schema | Tree-based, tag-based | tag-based | tag-based | tag-based | Relational |
| Writing out-of-order data | + | + | + | + | + |
| Schema-less | + | + | + | + | + |
| Batch insertion | + | + | + | + | + |
| Time range filter | + | + | + | + | + |
| Order by time | ++ | + | - | - | + |
| Value filter | + | + | - | - | + |
| Downsampling | ++ | + | + | + | + |
| Fill | ++ | + | + | - | + |
| LIMIT | + | + | + | + | + |
| SLIMIT | + | + | - | - | ? |
| Latest value | ++ | + | + | - | + |
具体地:
-
OpenSource:
- IoTDB 使用 Apache License 2.0。
- InfluxDB 使用 MIT license。但是,它的集群版本没有开源。
- OpenTSDB 使用 LGPL2.1,和 Apache License 不兼容。
- KairosDB 使用 Apache License 2.0。
- TimescaleDB 使用 Timescale License,对企业来说不是免费的。
-
SQL-like:
- IoTDB 和 InfluxDB 支持 SQL-like 语言。另外,IoTDB 和 Calcite 的集成几乎完成(PR 已经提交),这意味着 IoTDB 很快就能支持标准 SQL。
- OpenTSDB 和 KairosDB 只支持 Rest API。IoTDB 也支持 Rest API(PR 已经提交)。
- TimescaleDB 使用的是和 PostgreSQL 一样的 SQL。
-
Schema:
- IoTDB:IoTDB 提出了一种基于树的 schema (opens new window)这和其它时间序列数据库很不一样。这种 schema 有以下优点:
- 在许多工业场景里,设备管理是有层次的,而不是扁平的。因此我们认为基于树的 schema 比基于 tag-value 的 schema 更好。
- 在许多现实应用中,tag 的名字是不变的。例如:风力发电机制造商总是用风机所在的国家、所属的风场以及在风场中的 ID 来标识一个风机,因此,一个 4 层高的树(“root.the-country-name.the-farm-name.the-id”)来表示就足矣。你不需要重复告诉 IoTDB”树的第二层是国家名”、“树的第三层是风场名“等等这种信息。
- 这样的基于路径的时间序列 ID 定义还能够支持灵活的查询,例如:”
root.*.a.b.*“,其中、*是一个通配符。
- InfluxDB, KairosDB, OpenTSDB:使用基于 tag-value 的 schema。现在比较流行这种 schema。
- TimescaleDB 使用关系表。
- IoTDB:IoTDB 提出了一种基于树的 schema (opens new window)这和其它时间序列数据库很不一样。这种 schema 有以下优点:
-
Order by time:
对于时间序列数据库来说,Order by time 好像是一个琐碎的功能。但是当我们考虑另一个叫做”align by time“的功能时,事情就变得有趣起来。这就是为什么我们把 OpenTSDB 和 KairosDB 标记为”不支持“。事实上,所有时间序列数据库都支持单条时间序列的按时间戳排序。但是,OpenTSDB 和 KairosDB 不支持多条时间序列的按时间戳排序。
下面考虑一个新的例子:这里有两条时间序列,一条是风场 1 中的风速,一条是风场 1 中的风机 1 产生的电能。如果我们想要研究风速和产生电能之间的关系,我们首先需要知道二者在相同时间戳下的值。也就是说,我们需要按照时间戳对齐这两条时间序列。因此,结果应该是:
| 时间戳 | 风场 1 中的风速 | 风场 1 中的风机 1 产生的电能 |
|---|---|---|
| 1 | 5.0 | 13.1 |
| 2 | 6.0 | 13.3 |
| 3 | null | 13.1 |
或者:
| 时间戳 | 时间序列名 | 值 |
|---|---|---|
| 1 | 风场 1 中的风速 | 5.0 |
| 1 | 风场 1 中的风机 1 产生的电能 | 13.1 |
| 2 | 风场 1 中的风速 | 6.0 |
| 2 | 风场 1 中的风机 1 产生的电能 | 13.3 |
| 3 | 风场 1 中的风机 1 产生的电能 | 13.1 |
虽然第二个表格没有按照时间戳对齐两条时间序列,但是只需要逐行扫描数据就可以很容易地在客户端实现这个功能。
IoTDB 支持第一种表格格式(叫做 align by time),InfluxDB 支持第二种表格格式。
-
Downsampling:
Downsampling(降采样)用于改变时间序列的粒度,例如:从 10Hz 到 1Hz,或者每天 1 个点。
和其他数据库不同的是,IoTDB 能够实时降采样数据,而其它时间序列数据库在磁盘上序列化降采样数据。
也就是说:
-
IoTDB 支持在任意时间对数据进行即席(ad-hoc)降采样。例如:一条 SQL 返回从 2020-04-27 08:00:00 开始的每 5 分钟采样 1 个点的降采样数据,另一条 SQL 返回从 2020-04-27 08:00:01 开始的每 5 分 10 秒采样 1 个点的降采样数据。
(InfluxDB 也支持即席降采样,但是性能似乎并不好。)
-
IoTDB 的降采样不占用磁盘。
-
-
Fill:
有时候我们认为数据是按照某种固定的频率采集的,比如 1Hz(即每秒 1 个点)。但是通常我们会丢失一些数据点,可能由于网络不稳定、机器繁忙、机器宕机等等。在这些场景下,填充这些数据空洞是重要的。数据科学家可以因此避免很多所谓的”dirty work“比如数据清洗。
InfluxDB 和 OpenTSDB 只支持在 group by 语句里使用 fill,而 IoTDB 能支持给定一个特定的时间戳的 fill。此外,IoTDB 还支持多种填充策略。
-
Slimit:
Slimit 是指返回指定数量的 measurements(或者,InfluxDB 中的 fields)。
例如:一个风机有 1000 个测点(风速、电压等等),使用 slimit 和 soffset 可以只返回其中的一部分测点。
-
Latest value:
最基础的时间序列应用之一是监视最新数据。因此,返回一条时间序列的最新点是非常重要的查询功能。
IoTDB 和 OpenTSDB 使用一个特殊的 SQL 或 API 来支持这个功能,而 InfluxDB 使用聚合函数来支持。
IoTDB 提供一个特殊的 SQL 的原因是 IoTDB 专门优化了查询。
结论:
通过对基础功能的比较,我们可以发现:
- OpenTSDB 和 KairosDB 缺少一些重要的查询功能。
- TimescaleDB 不能被企业免费使用。
- IoTDB 和 InfluxDB 可以满足时间序列数据管理的大部分需求,同时它俩之间有一些不同之处。
高级功能
| TSDB | IoTDB | InfluxDB | OpenTSDB | KairosDB | TimescaleDB |
|---|---|---|---|---|---|
| Align by time | ++ | + | - | - | + |
| Compression | ++ | ± | ± | ± | ± |
| MQTT support | ++ | + | - | - | ± |
| Run on Edge-side Device | ++ | + | - | ± | + |
| Multi-instance Sync | ++ | - | - | - | - |
| JDBC Driver | + | - | - | - | ++ |
| Standard SQL | + | - | - | - | ++ |
| Spark integration | ++ | - | - | - | - |
| Hive integration | ++ | - | - | - | - |
| Writing data to NFS (HDFS) | ++ | - | + | - | - |
| Flink integration | ++ | - | - | - | - |
具体地:
-
Align by time:上文已经介绍过,这里不再赘述。
-
Compression:
- IoTDB 支持许多时间序列编码和压缩方法,比如 RLE, 2DIFF, Gorilla 等等,以及 Snappy 压缩。在 IoTDB 里,你可以根据数据分布选择你想要的编码方法。更多信息参考 这里 (opens new window)。
- InfluxDB 也支持编码和压缩,但是你不能定义你想要的编码方法,编码只取决于数据类型。更多信息参考 这里 (opens new window)。
- OpenTSDB 和 KairosDB 在后端使用 HBase 和 Cassandra,并且没有针对时间序列的特殊编码。
-
MQTT protocol support:
MQTT protocol 是一个被工业用户广泛知晓的国际标准。只有 IoTDB 和 InfluxDB 支持用户使用 MQTT 客户端来写数据。
-
Running on Edge-side Device:
现在,边缘计算变得越来越重要,边缘设备有越来越强大的计算资源。
在边缘侧部署时间序列数据库,对于管理边缘侧数据、服务于边缘计算来说,是有用的。
由于 OpenTSDB 和 KairosDB 依赖另外的数据库,它们的体系结构是臃肿的。特别是很难在边缘侧运行 Hadoop。
-
Multi-instance Sync:
现在假设我们在边缘侧有许多时间序列数据库实例,考虑如何把它们的数据上传到数据中心去形成一个数据湖。
一个解决方法是从这些实例读取数据,然后逐点写入到数据中心。
IoTDB 提供了另一个选项:把数据文件增量上传到数据中心,然后数据中心可以支持在数据上的服务。
-
JDBC driver:
现在只有 IoTDB 支持了 JDBC driver(虽然不是所有接口都实现),这使得 IoTDB 可以整合许多其它的基于 JDBC driver 的软件。
-
Standard SQL:
正如之前提到的,IoTDB 和 Calcite 的集成几乎完成(PR 已经提交),这意味着 IoTDB 很快就能支持标准 SQL。
-
Spark and Hive integration:
让大数据分析软件访问数据库中的数据来完成复杂数据分析是非常重要的。
IoTDB 支持 Hive-connector 和 Spark-connector 来完成更好的整合。
-
Writing data to NFS (HDFS):
Sharing nothing 的体系结构是好的,但是有时候你不得不增加新的服务器,即便你的 CPU 和内存都是空闲的而磁盘已经满了。
此外,如果我们能直接把数据文件存储到 HDFS 中,用 Spark 和其它软件来分析数据将会更加简单,不需要 ETL。
- IoTDB 支持往本地或者 HDFS 写数据。IoTDB 还允许用户扩展实现在其它 NFS 上存储数据。
- InfluxDB 和 KairosDB 只能往本地写数据。
- OpenTSDB 只能往 HDFS 写数据。
结论:
IoTDB 拥有许多其它时间序列数据库不支持的强大功能。
性能比较
如果你觉得:”如果我只需要基础功能的话,IoTDB 好像和其它的时间序列数据库没有什么不同。“
这好像是有道理的。但是如果考虑性能的话,你也许会改变你的想法。
快速浏览
| TSDB | IoTDB | InfluxDB | KairosDB | TimescaleDB |
|---|---|---|---|---|
| Scalable Writes | ++ | + | + | + |
| Raw Data Query | ++ | + | + | + |
| Aggregation Query | ++ | + | + | + |
| Downsampling Query | ++ | + | ± | ± |
| Latest Query | ++ | + | ± | + |
更多细节
我们提供了一个 benchmark 工具,叫做 IoTDB-benchamrk (opens new window)(你可以用 dev branch 来编译它)。它支持 IoTDB, InfluxDB, KairosDB, TimescaleDB, OpenTSDB。
- 对于 InfluxDB,我们把 cache-max-memory-size 和 max-series-perbase 设置成 unlimited(否则它很快就会超时)。
- 对于 KairosDB,我们把 Cassandra 的 read_repair_chance 设置为 0.1(但是这没有什么影响,因为我们只有一个结点)。
- 对于 TimescaleDB,我们用 PGTune 工具来优化 PostgreSQL。
所有的时间序列数据库运行的机器配置是:Intel® Core™ i7-10700 CPU @ 2.90GHz, (8 cores 16 threads), 32GB memory, 256G SSD and 10T HDD, OS: Ubuntu 16.04.7 LTS, 64bits.
所有的客户端运行的机器配置是:Intel® Core™ i7-8700 CPU @ 3.20GHz,(6 cores 12 threads), 16GB memory, 256G SSD, OS: Ubuntu 16.04.7 LTS, 64bits.
结论
从以上所有实验中,我们可以看到 IoTDB 的性能大大优于其他数据库。
IoTDB 具有最小的写入延迟。批处理大小越大,IoTDB 的写入吞吐量就越高。这表明 IoTDB 最适合批处理数据写入方案。
在高并发方案中,IoTDB 也可以保持吞吐量的稳定增长。 (每秒 1200 万个点可能已达到千兆网卡的限制)
在原始数据查询中,随着查询范围的扩大,IoTDB 的优势开始显现。因为数据块的粒度更大,列式存储的优势体现出来,所以基于列的压缩和列迭代器都将加速查询。
在聚合查询中,我们使用文件层的统计信息并缓存统计信息。因此,多个查询仅需要执行内存计算(不需要遍历原始数据点,也不需要访问磁盘),因此聚合性能优势显而易见。
降采样查询场景更加有趣,因为时间分区越来越大,IoTDB 的查询性能逐渐提高。它可能上升了两倍,这对应于 2 个粒度(3 小时和 4.5 天)的预先计算的信息。因此,分别加快了 1 天和 1 周范围内的查询。其他数据库仅上升一次,表明它们只有一个粒度统计。
如果您正在为您的 IIoT 应用程序考虑使用 TSDB,那么新的时间序列数据库 Apache IoTDB 是您的最佳选择。
Apache IoTDB
https://www.bilibili.com/video/BV1yi4y127js/
Apache IoTDB:基于开放数据文件格式的时序数据库
IoTDB 是清华自研时间序列数据库,2014年项目启动,2018年11月18号 IoTDB 正式进入 Apache 孵化器,成为中国高校首个进入 Apache 孵化器的项目。
Apache IoTDB简介
-
IoT:物联网
-
DB:数据库
物联网行业中的时序数据的特点:存量数据大、新增数据多(采集频率高、设备量多)。
IoTDB 是一款聚焦工业物联网、高性能轻量级的时序数据管理系统,具备低存储成本、高速数据写入(百万数据点秒级写入)、快速查询(TB级数据毫秒级查询)、功能完备(数据的增删改查、丰富的聚合函数、相似性匹配)、查询分析一体化(一份数据,满足实时查询与分析挖掘)、简单易用(采用标准的 JDBC 接口、类 SQL 查询语言)等特点。
IoTDB 功能特点
IoTDB 完成了上述问题中的几乎所有功能,而且可以灵活对接多生态,高性能优势等。
物联网中的时序数据库
物联网时序数据是工业设备物理量的数字化记录,在轨道交通、能源管控、智能制造等领域有广泛应用。
应用场景
轨道交通
对桥梁状态(挠度、应变、振动、支座位移)进行健康监测并加固,避免桥梁坍塌,保障人民出现安全。

能源管控
对化工厂进行能耗监测、报警管理、预测优化,时序节能、减排、增效,响应“碳达峰、碳中和”。
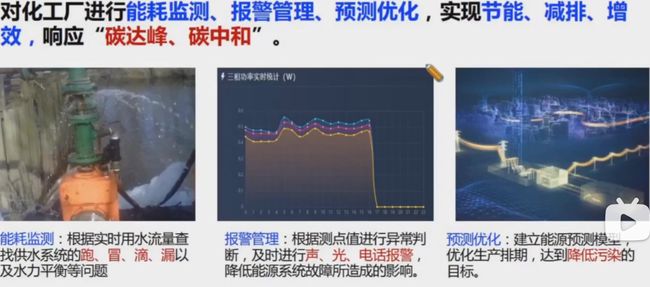
智能制造
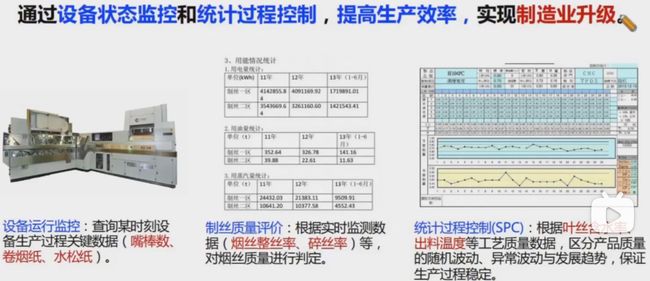
通过设备状态监控和统计过程控制,提高生产效率,实现制造业升级。
时序数据量大

时序数据库是重要资产

如何管理好时序数据?
物联网时序数据库Apache IoTDB

产品特点
易用、好用

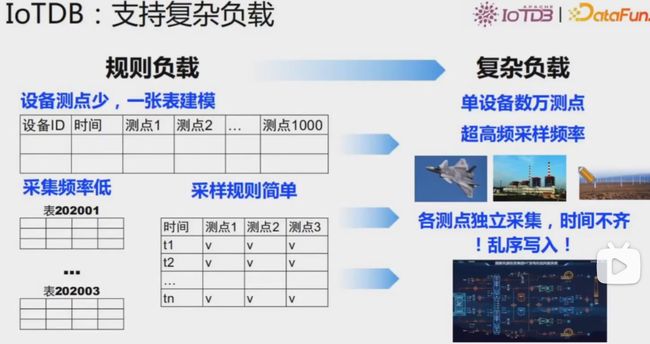
支持复杂负载
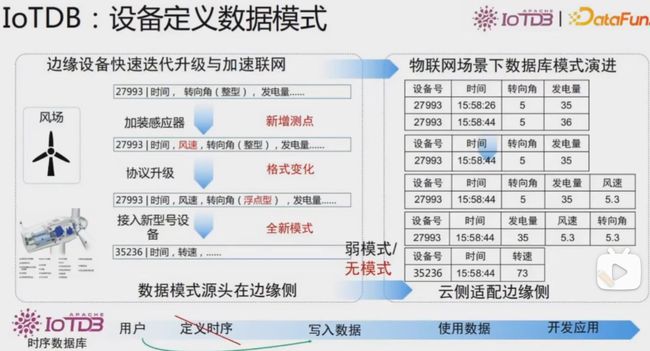
设备定义数据模式
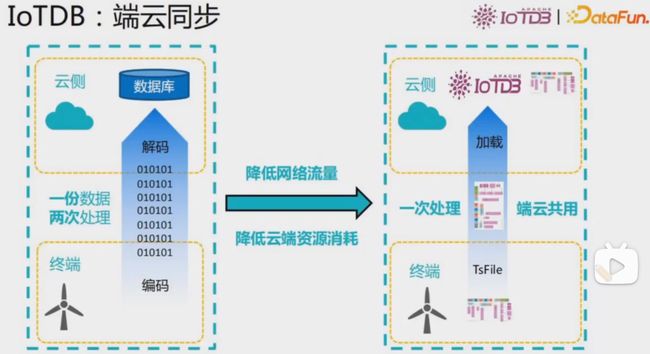
端云同步
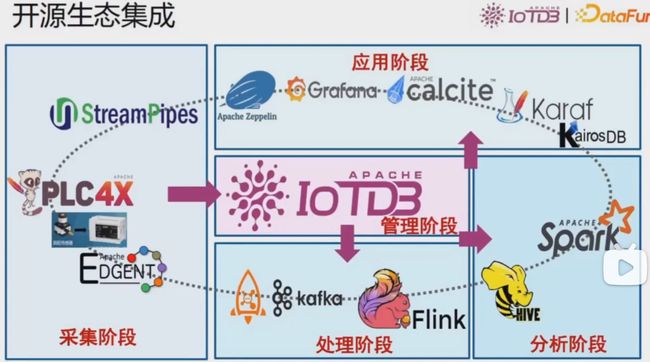
开源生态集成
产品形态
适配“端-边-云”

时序文件格式TsFile
IoTDB 于 2017 年 1 月正式在 Github 上开放 IoTDB 底层文件存储格式 TsFile。
为什么叫 TsFile ?
我听意思应该是作为 TimeSeriresFile 的缩写,也就是时序数据文件的意思。
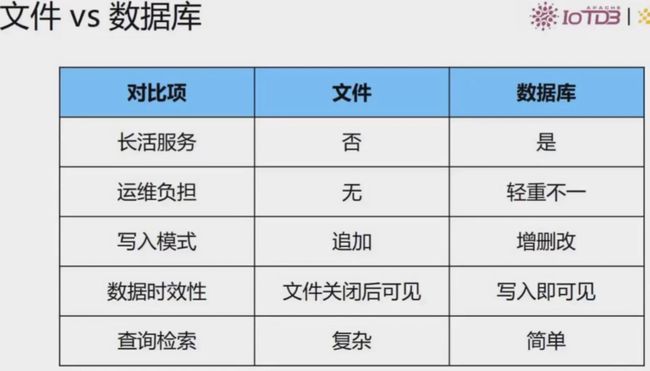
文件VS数据库
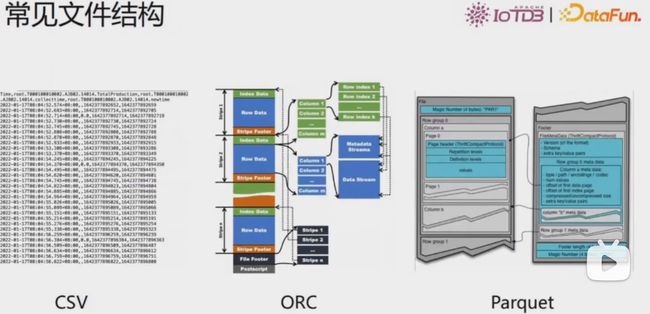
常见文件结构
-
CSV数据文件属于文本存储方式,spark默认支持,按照行以文本的方式写到文件中,每行一条记录。一般来说文本存储方式无压缩,性能相对较差。
- CSV文件(逗号分割不同列的值)常被使用普通文本格式的系统用作交换它们的表格数据。
- CSV是基于行的文件格式,这意味着文件中的每行数据都对应于表格的一行。
-
Parquet文件是以二进制方式存储的,是不可以直接读取和修改的,Parquet文件是自解析的,文件中包括该文件的数据和元数据。
- Parquet针对“一次写入,多次读取(WORM)”特性做了优化。它写入慢,但是读取特别快,特别当你只访问全部列的一部分时。有大量读取工作时,Parquet是个好选择。对于需要对整行数据处理的场景,你需要使用类似CSV或者AVRO格式。
-
ORC文件也是以二进制方式存储的,所以是不可以直接读取,ORC文件也是自解析的,它包含许多的元数据,这些元数据都是同构ProtoBuffer进行序列化的。
csv使用较为广泛,多数系统的输入都是csv格式,此外csv文件直接打开是可以理解和读懂的,而且csv文件也是支持末尾添加数据的,但是csv文件因为没有压缩,所以体积较大,某些操作上也不如列式存储。
parquet使用也较为广泛,默认使用gzip压缩,体积较小,运算效率高,但是parquet打开是不能被理解和读懂的,因为其采用二进制存储方式,当系统中无特殊要求,也去需要打开数据文件的时候,为了追求效率可以考虑。
orc也是列示存储的二进制文件,打开无法被直接理解和读懂,但是因为在文件格式中,每一个row block的开始都有一个轻型索引,所以相较于parquet,orc在检索行的时候,速度要相对较快一点。
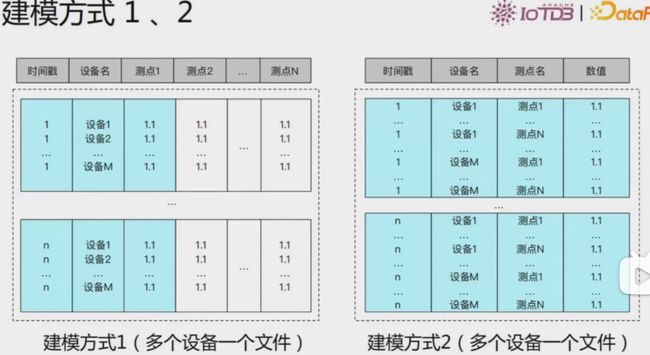
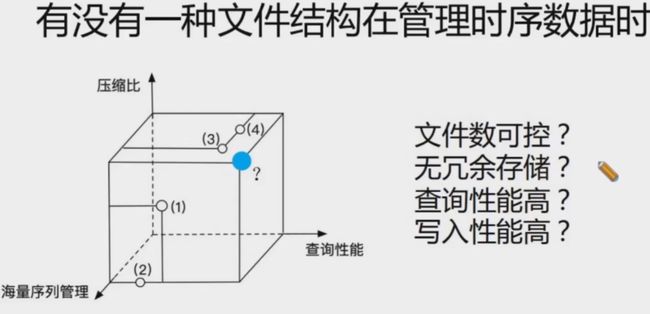
建模方式1、2
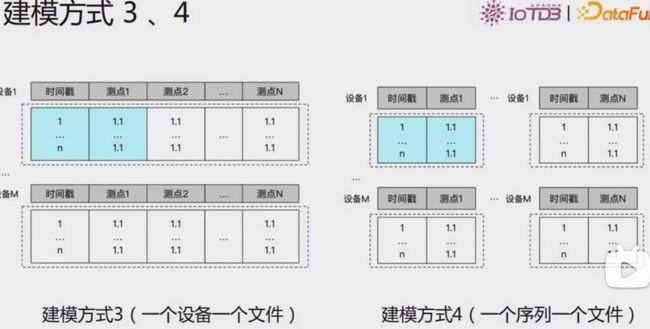
建模方式3、4
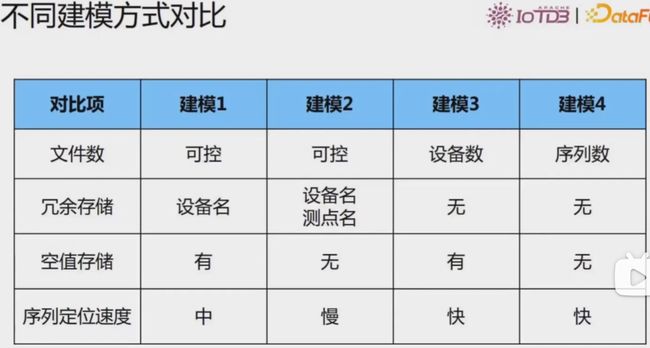
不同建模方式对比
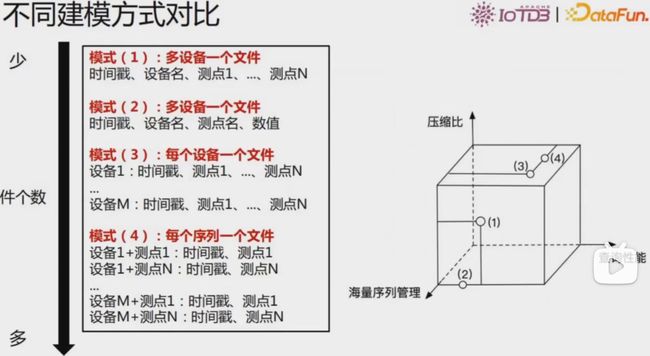
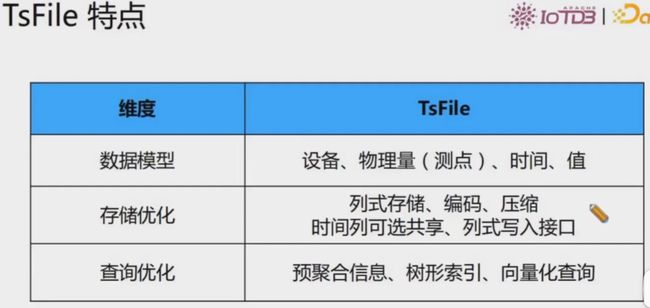
TsFile特点
TsFile数据模型(>=0.1)
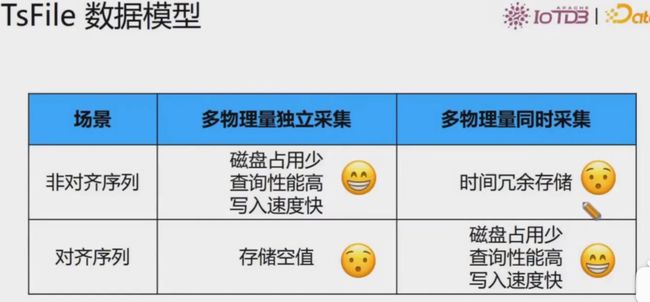
TsFile数据存储结构

Page编码压缩算法

TsFile索引结构
序列内
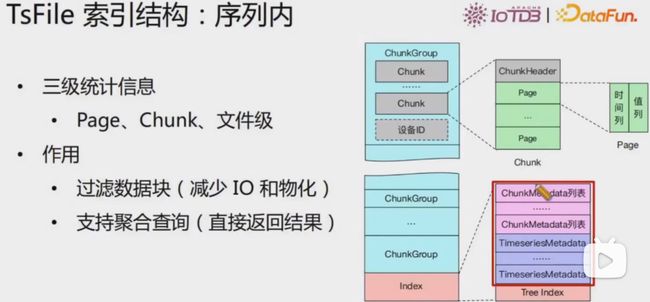
序列间

TsFile序列间索引效果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jcZRsBmU-1650443396594)(https://gitee.com/AuroraLeVi/markdown/raw/master/img/TsFile%E5%BA%8F%E5%88%97%E9%97%B4%E7%B4%A2%E5%BC%95%E6%95%88%E6%9E%9C.png)]
向量化写入接口、查询引擎

读写性能

基于开放文件的数据库架构
为什么做数据库?

TsFile是时序数据文件格式,类似 Parquet、ORC,IoTDB是在 TsFile 上构建的时序数据库,类似 MySQL。
何为开放?

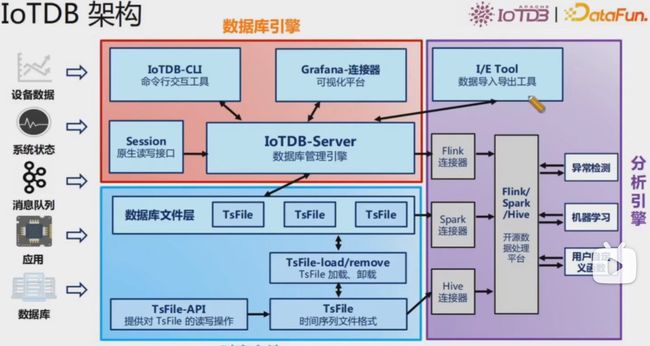
IoTDB架构
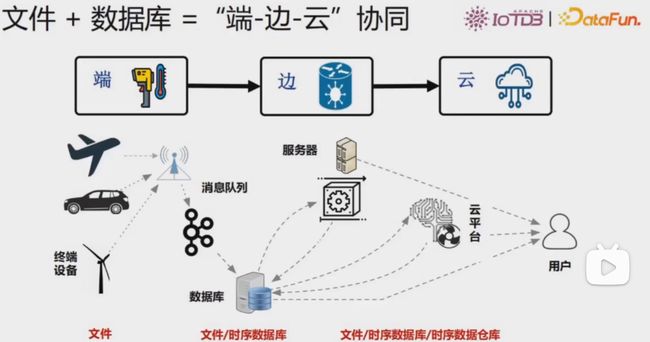
文件+数据库=“端-边-云”协同
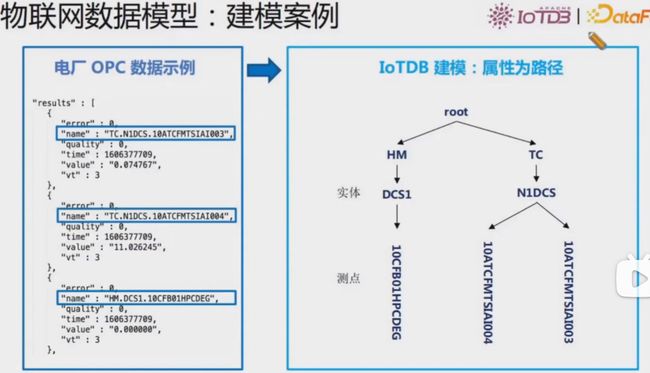
物联网数据模型
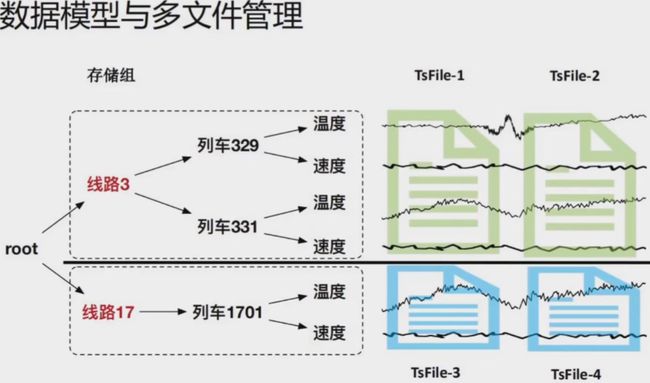
数据模型与多文件管理
物联网数据模型:建模案例

开源社区建议
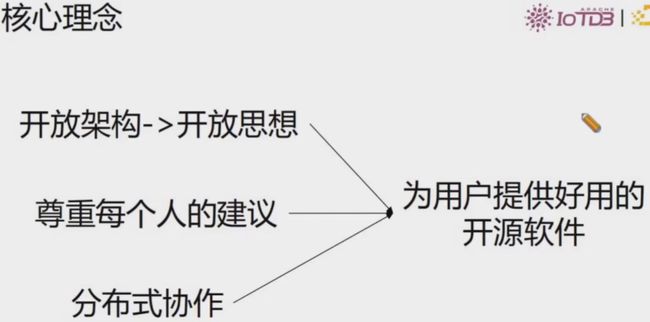
开源核心理念
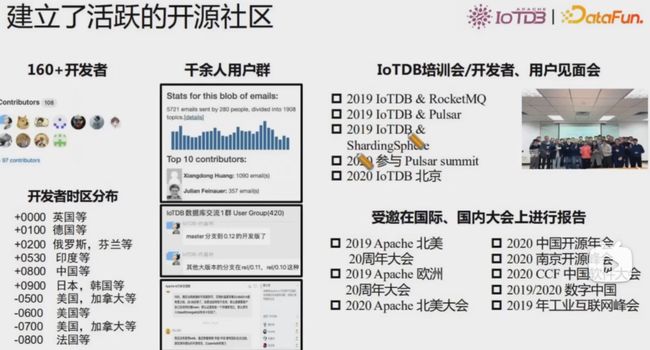
建立了活跃的开源社区
社区影响力日益凸显
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kAncoKDb-1650443396678)(https://gitee.com/AuroraLeVi/markdown/raw/master/img/IoTDB%E7%A4%BE%E5%8C%BA%E5%BD%B1%E5%93%8D%E5%8A%9B%E6%97%A5%E7%9B%8A%E5%87%B8%E6%98%BE.png)]
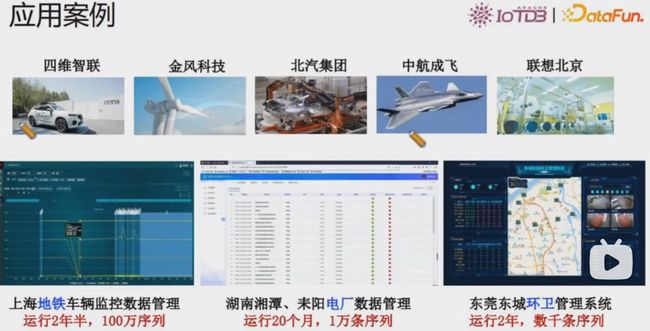
应用实例