2021 ICCV、CVPR 知识蒸馏相关论文
目录
2021 ICCV
2021 CVPR
2021 ICCV
Perturbed Self-Distillation: Weakly Supervised Large-Scale Point Cloud Semantic Segmentation
[pdf] [supp]
[bibtex]
Densely Guided Knowledge Distillation Using Multiple Teacher Assistants
[pdf] [supp] [arXiv]
Figure 1. Problem definition of the large gap between a teacher and a student network. (a) In general, the difference between layers at KD is approximately 1.8 times, but (b) we are interested in the challenging problem of layer differences of more than 5 times. For solving this problem, TAKD [23] has been proposed. However, (c) TAKD has a fundamental limitation such as the error avalanche problem. Assuming that a unique error occurs one by one when a higher-level teacher assistant (TA) teaches a lowerlevel TA. The error case continues to increase whenever teaching more TAs. Meanwhile, in (d), the proposed densely guided knowledge distillation can be relatively free from this error avalanche problem because it does not teach TAs at each level alone.

ISD: Self-Supervised Learning by Iterative Similarity Distillation
[pdf] [supp] [arXiv]

G-DetKD: Towards General Distillation Framework for Object Detectors via Contrastive and Semantic-Guided Feature Imitation
[pdf] [supp]
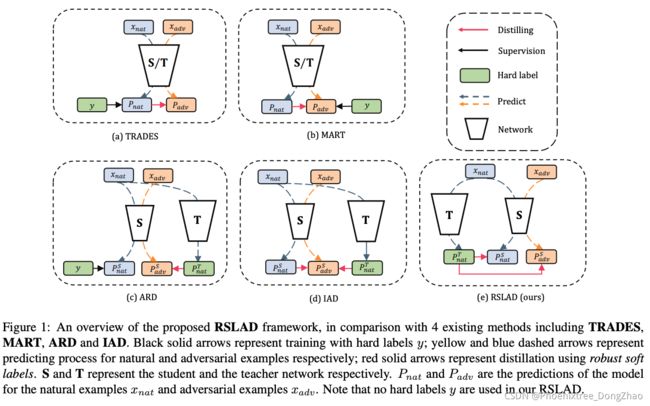
Revisiting Adversarial Robustness Distillation: Robust Soft Labels Make Student Better
[pdf] [supp] [arXiv]
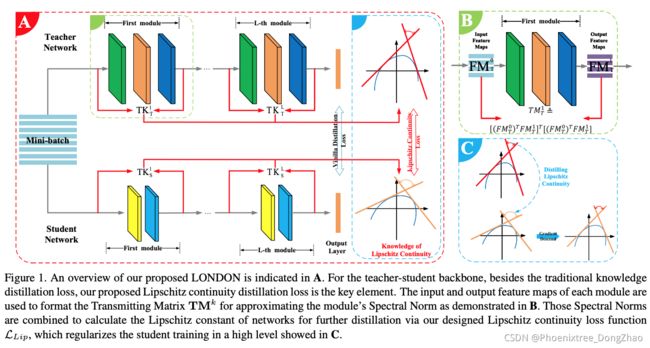
Lipschitz Continuity Guided Knowledge Distillation
[pdf] [arXiv]
Self-Mutual Distillation Learning for Continuous Sign Language Recognition
[pdf] [supp]
Knowledge-Enriched Distributional Model Inversion Attacks
[pdf] [supp] [arXiv]
Temporal Knowledge Consistency for Unsupervised Visual Representation Learning
[pdf] [supp] [arXiv]
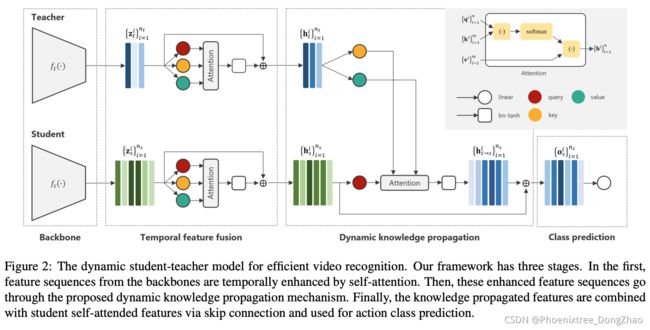
Efficient Action Recognition via Dynamic Knowledge Propagation
[pdf] [supp]
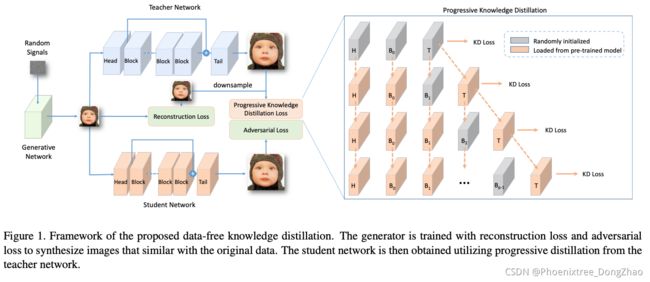
Compressing Visual-Linguistic Model via Knowledge Distillation
[pdf] [arXiv]
Self-Knowledge Distillation With Progressive Refinement of Targets
[pdf] [supp] [arXiv]
Explainable Person Re-Identification With Attribute-Guided Metric Distillation
[pdf] [supp] [arXiv]
Variational Attention: Propagating Domain-Specific Knowledge for Multi-Domain Learning in Crowd Counting
[pdf] [arXiv]
Figure 1. Data distribution comparison between ShanghaiTech [64], UCF-QNRF [15] and NWPU [54]. ShanghaiTech A is mainly composed of congested images, QNRF is of highlycongested samples and have more background scenarios, NWPU covers a much larger variety of data distributions due to density, perspective, background, etc, while ShanghaiTech B prefers low density and ordinary street-based scenes.
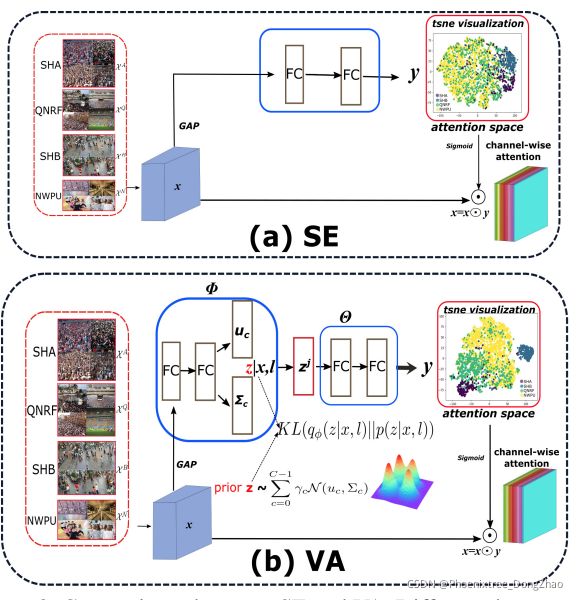
Figure 2. Comparisons between SE and VA. Different datasets are trained jointly. ⊙ means channel-wise product. One can observe that SE attention outputs are confusing, while our VA can produce more separable attention distributions for different domains by introducing the Gaussian Mixture distributed latent variable z.

TeachText: CrossModal Generalized Distillation for Text-Video Retrieval
[pdf] [supp] [arXiv]
Online Knowledge Distillation for Efficient Pose Estimation
[pdf] [arXiv]
Knowledge Mining and Transferring for Domain Adaptive Object Detection
[pdf] [supp]
Topic Scene Graph Generation by Attention Distillation From Caption
[pdf] [supp] [arXiv]
Video Pose Distillation for Few-Shot, Fine-Grained Sports Action Recognition
[pdf] [supp] [arXiv]
Ensemble Attention Distillation for Privacy-Preserving Federated Learning
[pdf]
Online Multi-Granularity Distillation for GAN Compression
[pdf] [arXiv]
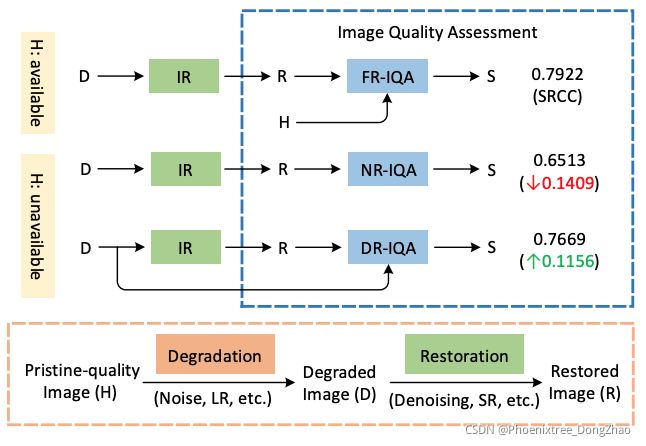
Learning Conditional Knowledge Distillation for Degraded-Reference Image Quality Assessment
[pdf] [supp] [arXiv]
Figure 1. (a) Pristine-quality images can provide strong reference information for IQA. When pristine-quality images are unavailable, (b) directly regressing restored images to quality scores causes a dramatic drop in performance. To this end, (c) we propose to extract reference information from degraded images and make such a solution effective. FR, NR, DR, S, and SRCC indicate fullreference, no-reference, degraded-reference, quality score, and Spearman’s Rank order Correlation Coefficients [30], respectively.


Text Is Text, No Matter What: Unifying Text Recognition Using Knowledge Distillation
[pdf] [supp] [arXiv]
Multimodal Knowledge Expansion
[pdf] [supp] [arXiv]
![]()
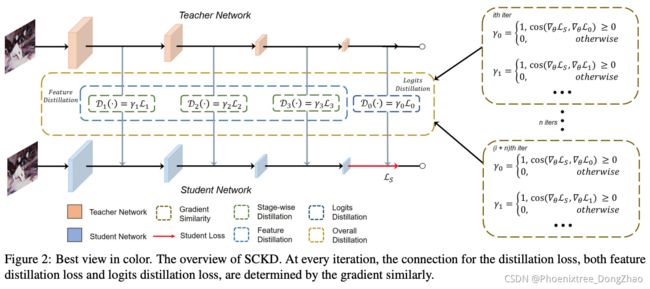
Student Customized Knowledge Distillation: Bridging the Gap Between Student and Teacher
[pdf]
Figure 1: Best view in color. Top: The gradient similarity of knowledge distillation and student loss at different iterations in the gradient space. Middle: Prior approaches. The knowledge distillation process between two networks is stationary in different iterations. Bottom: Our approach automatically decides to switch on or switch off the knowledge distillation loss based on their corresponding relative gradient direction to student loss.

![]()
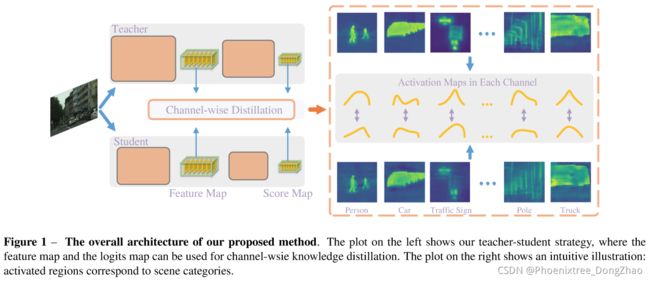
Channel-Wise Knowledge Distillation for Dense Prediction
[pdf] [supp] [arXiv]
Meta Pairwise Relationship Distillation for Unsupervised Person Re-Identification
[pdf]
AGKD-BML: Defense Against Adversarial Attack by Attention Guided Knowledge Distillation and Bi-Directional Metric Learning
[pdf] [supp]
Figure 1. A clean image (“German shepherd”) and its adversarial example (incorrectly classified as “Planetarium”) are in the first column. The class relevant attention maps (Grad-CAM) of correct and incorrect labels, and the class irrelevant attention maps are shown in the second, third and fourth columns, respectively. It shows that the adversarial perturbations corrupt the attention maps.

Lifelong Infinite Mixture Model Based on Knowledge-Driven Dirichlet Process
[pdf] [supp] [arXiv]
Distilling Holistic Knowledge With Graph Neural Networks
[pdf] [supp] [arXiv]
![]()
Distillation-Guided Image Inpainting
[pdf]

COOKIE: Contrastive Cross-Modal Knowledge Sharing Pre-Training for Vision-Language Representation
[pdf] [supp]
Self Supervision to Distillation for Long-Tailed Visual Recognition
[pdf] [arXiv]
Learning an Augmented RGB Representation With Cross-Modal Knowledge Distillation for Action Detection
[pdf] [supp] [arXiv]
The Pursuit of Knowledge: Discovering and Localizing Novel Categories Using Dual Memory
[pdf] [supp] [arXiv]
![]()
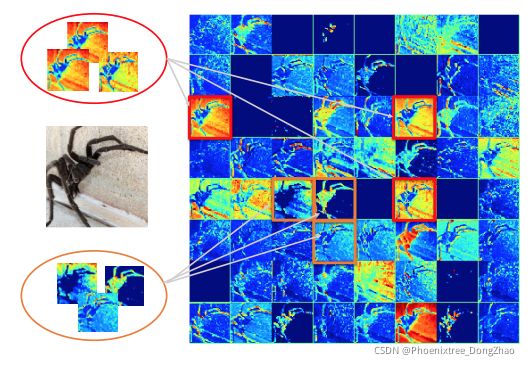
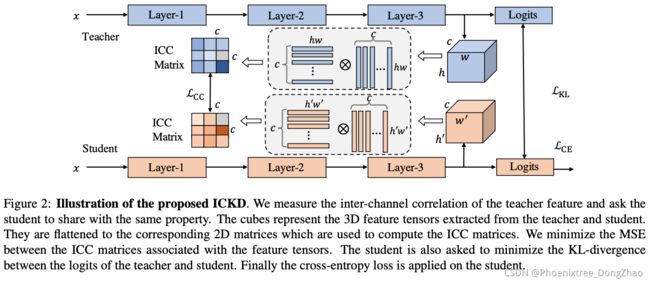
Exploring Inter-Channel Correlation for Diversity-Preserved Knowledge Distillation
[pdf] [supp]
Figure 1: Illustration of inter-channel correlation. The channels orderly extracted from the second layer of ResNet18 have been visualized. The channels denoted by red boxes are homologous both perceptually and mathematically (e.g., inner-product), while the channels denoted by orange boxes are diverse. We show the inter-channel correlation can effectively measure that each channel is homologous or diverse to others, which further reflects the richness of the feature spaces. Based on this insightful finding, our ICKD can enforce the student to mimic this property from the teacher.
Active Learning for Lane Detection: A Knowledge Distillation Approach
[pdf] [supp]
2021 CVPR
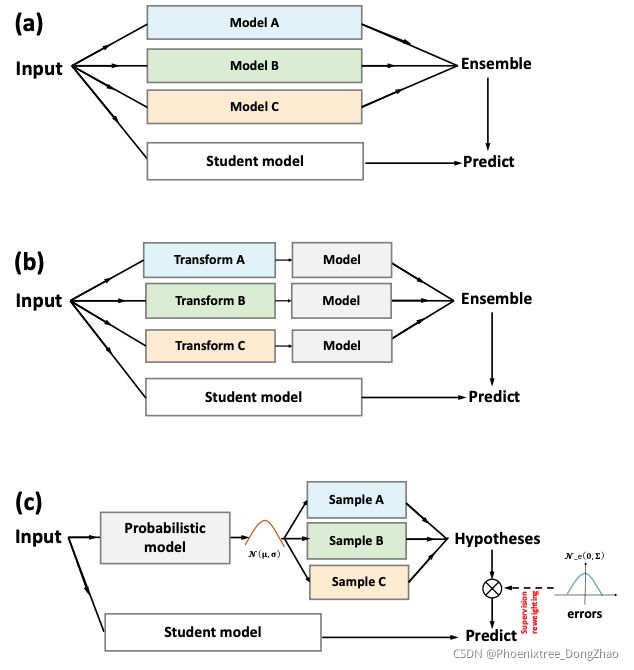
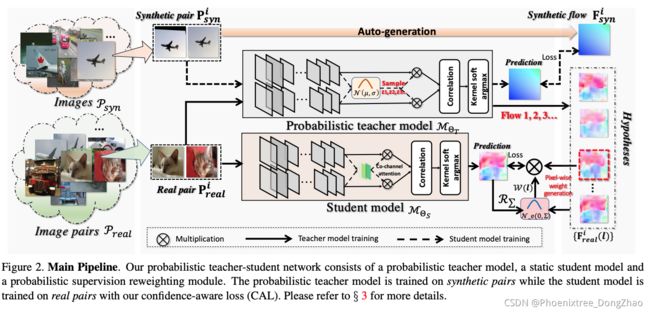
Probabilistic Model Distillation for Semantic Correspondence
[pdf]
Figure 1. Idea Illustration. Instead of (a) ensembling multiple models to generate “soft” predictions as the student’s target [22], or (b) creating a single “hard” label from different transformations [54], (c) our idea is to distill knowledge from hypotheses from a probabilistic teacher model in a probabilistic manner.
Visualizing Adapted Knowledge in Domain Transfer
[pdf] [arXiv]
Figure 1: Visualization of adapted knowledge in unsupervised domain adaptation (UDA) on the VisDA dataset [38]. To depict the knowledge difference, in our source-free image translation (SFIT) approach, we generate source-style images (b) from target images (a). Instead of accessing source images (c), the training process is guided entirely by the source and target models, so as to faithfully portray the knowledge difference between them.

Learning Graphs for Knowledge Transfer With Limited Labels
[pdf] [supp]
ECKPN: Explicit Class Knowledge Propagation Network for Transductive Few-Shot Learning
[pdf] [arXiv]
Distilling Knowledge via Knowledge Review
[pdf] [supp] [arXiv]
Figure 1. (a)-(c) Previous knowledge distillation frameworks. They only transfer knowledge within the same levels. (d) Our proposed “knowledge review” mechanism. We use multiple layers of the teacher to supervise one layer in the student. Thus, knowledge passing arises among different levels.


Complementary Relation Contrastive Distillation
[pdf] [arXiv]
Figure 1: Sample contrastive distillation vs. Relation preserving distillation. Four neighboring samples and their corresponding features are displayed, and capital letters are used to identify them. While pulling f^S_A closer to f^T_A , sample contrastive distillation will simultaneously push f S A away from f^T_B , f^T_C and f^T_D without distinction, whereas relation preserving distillation preserves the feature relations across the feature space, thus f S A can be optimized along the optimal direction.


3D-to-2D Distillation for Indoor Scene Parsing
[pdf] [supp] [arXiv]
Farewell to Mutual Information: Variational Distillation for Cross-Modal Person Re-Identification
[pdf] [supp] [arXiv]
![]()
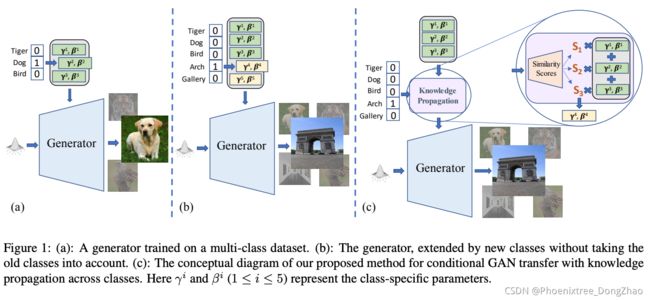
Efficient Conditional GAN Transfer With Knowledge Propagation Across Classes
[pdf] [supp] [arXiv]
Figure 2: Intuitive visualization of how different layers might borrow information from different classes based on the hierarchy of features such as shape and color (for a better visualization, only two layers are illustrated). Pictures in the figure are obtained from our experiment on AnimalFace dataset [35] (refer to Fig. 9 for more visualizations).
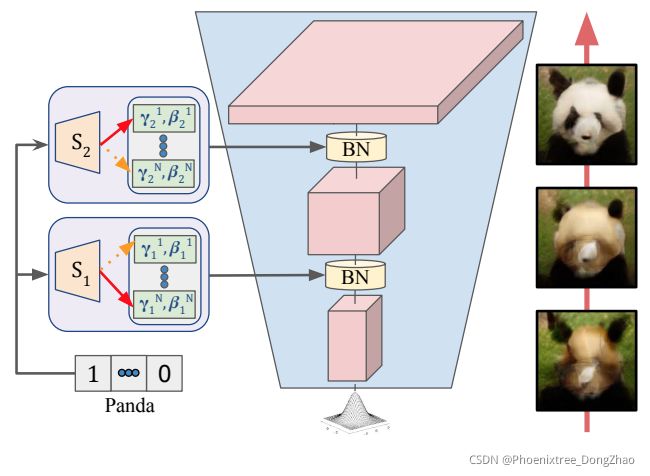
Room-and-Object Aware Knowledge Reasoning for Remote Embodied Referring Expression
[pdf] [supp]
Self-Attention Based Text Knowledge Mining for Text Detection
[pdf] [supp]
Distilling Audio-Visual Knowledge by Compositional Contrastive Learning
[pdf] [supp] [arXiv]
Learning From the Master: Distilling Cross-Modal Advanced Knowledge for Lip Reading
[pdf]
![]()
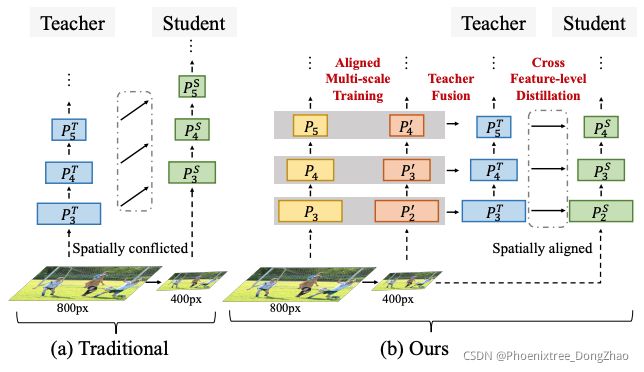
Multi-Scale Aligned Distillation for Low-Resolution Detection
[pdf] [supp]
Figure 1: Conceptual comparison between (a) traditional teacher-student approach and (b) ours, in the setting of using a high-resolution teacher to guide a low-resolution student. In this setting, the traditional approach of transferring knowledge along the same feature levels fails due to spatially-conflicted feature maps. To resolve it, we introduce a multi-scale aligned distillation approach.
OpenMix: Reviving Known Knowledge for Discovering Novel Visual Categories in an Open World
[pdf] [arXiv]
Semantic-Aware Knowledge Distillation for Few-Shot Class-Incremental Learning
[pdf] [arXiv]
Figure 1: (a) Knowledge distillation as described in [16] does not work on few-shot class-incremental learning [32] since adding new tasks appends new trainable weights (Wn) to the network in addition to base weights (Wb). (b) The impact of using only a few instances of novel classes. As few samples are not sufficient to learn new parameters, the network gets biased towards base classes, overfitted on few examples of novel classes, and not wellseparated from base classes. (c) Our semantically guided network does not add new parameters while adding new classes incrementally. We only include word vectors of new tasks (sn) in addition to the base classes (sb) and keep fine-tuning the base network (F) (d) As a result, the knowledge distillation process can help the network, remembering base training, generalizing to novel classes, and finding well-separated representation of classes.

![]()
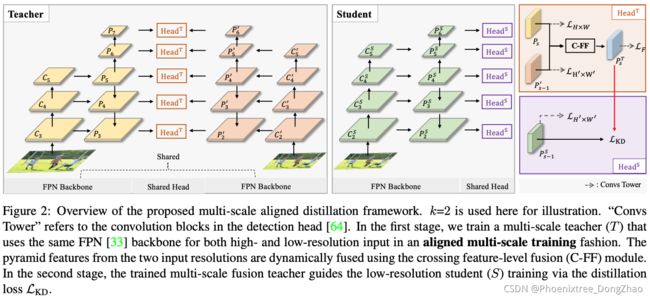
General Instance Distillation for Object Detection
[pdf] [arXiv]
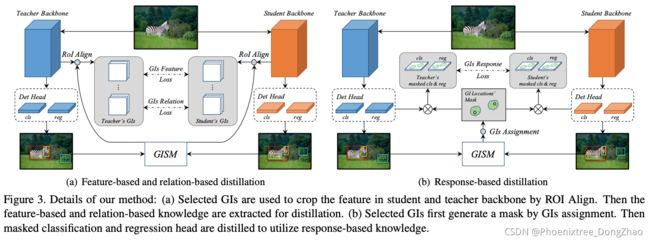
Figure 1. Overall pipeline of general instance distillation (GID). General instances (GIs) are adaptively selected by the output both from teacher and student model. Then the feature-based, relationbased and response-based knowledge are extracted for distillation based on the selected GIs.
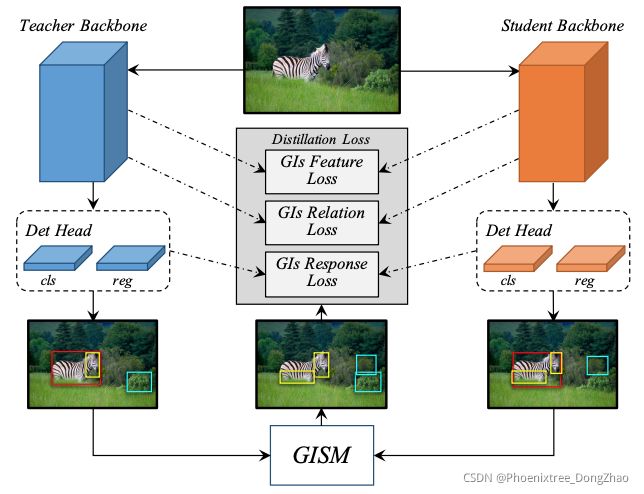
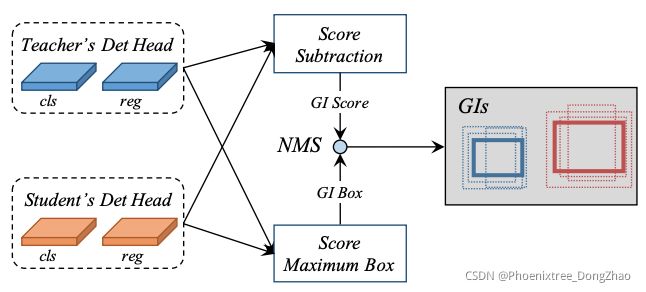
Figure 2. Illustration of the general instance selection module (GISM). To obtain the most informative locations, we calculate the L1 distance of classification scores from student and teacher as GI scores, and preserve regression boxes with higher scores as GI boxes. To avoid losses double counting, we use the non-maximum suppression (NMS) algorithm to remove duplicates.
Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution
[pdf] [arXiv]
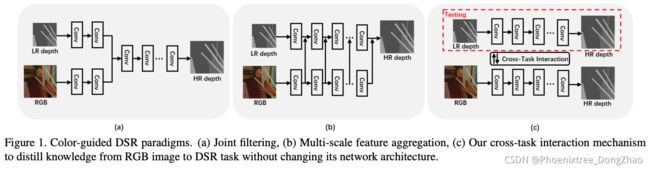

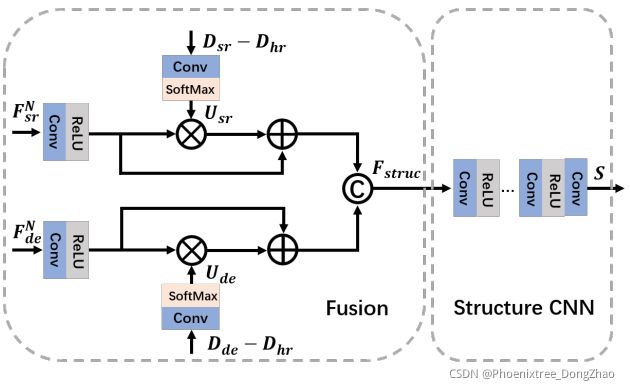
Figure 3. The proposed SPNet. We fuse F^N_sr and F^N_de by our proposed uncertainty-induced attention fusion module.
Tree-Like Decision Distillation
[pdf] [supp]
Figure 1. An illustrative diagram of the coarse-to-fine decision process on CIFAR10. After the first group of ResNet56, vehicles and animals can be distinguished with accuracy of 80%, while the 10-way classification here reaches only 34%.


UniT: Unified Knowledge Transfer for Any-Shot Object Detection and Segmentation
[pdf] [supp] [arXiv]
Rectification-Based Knowledge Retention for Continual Learning
[pdf] [supp] [arXiv]
Exploring and Distilling Posterior and Prior Knowledge for Radiology Report Generation
[pdf] [arXiv]
Dense Relation Distillation With Context-Aware Aggregation for Few-Shot Object Detection
[pdf] [supp] [arXiv]
Refine Myself by Teaching Myself: Feature Refinement via Self-Knowledge Distillation
[pdf] [supp] [arXiv]
![]()
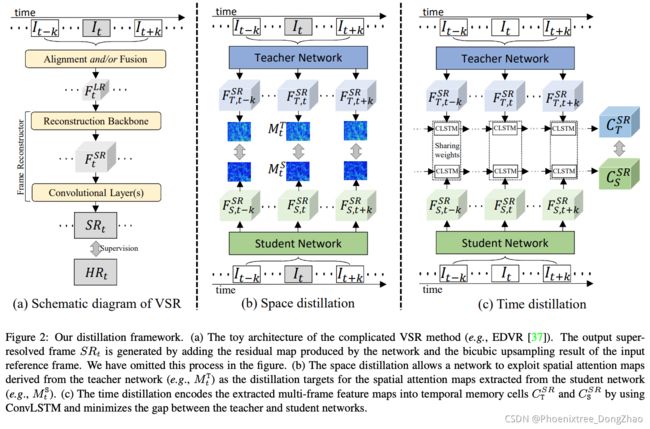
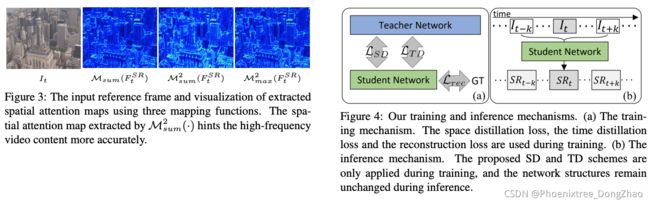
Space-Time Distillation for Video Super-Resolution
[pdf] [supp]
Explicit Knowledge Incorporation for Visual Reasoning
[pdf] [supp]
There Is More Than Meets the Eye: Self-Supervised Multi-Object Detection and Tracking With Sound by Distilling Multimodal Knowledge
[pdf] [supp] [arXiv]
Asymmetric Metric Learning for Knowledge Transfer
[pdf] [supp] [arXiv]
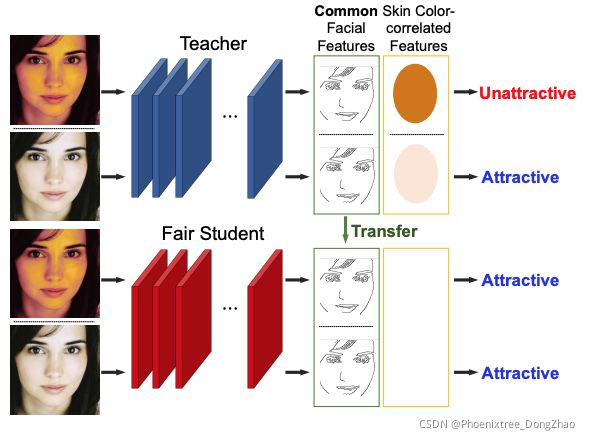
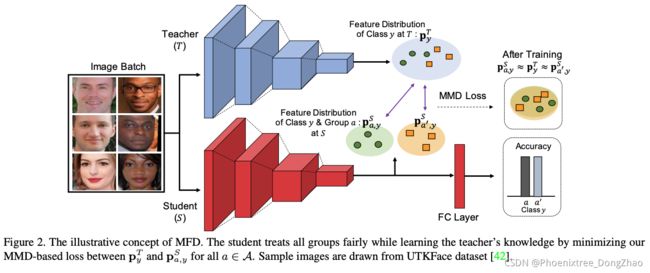
Fair Feature Distillation for Visual Recognition
[pdf] [supp] [arXiv]
Figure 1. An illustrative example of motivation to our work. The “teacher” model may depend heavily on the skin color when deciding whether the face is attractive, while it may also have learned useful common (unbiased) facial features. To train a fair “student” model via feature distillation, only the unbiased common features from the teacher should be transferred to the student so that both high accuracy and fairness can be achieved.
Knowledge Evolution in Neural Networks
[pdf] [supp] [arXiv]

![]()
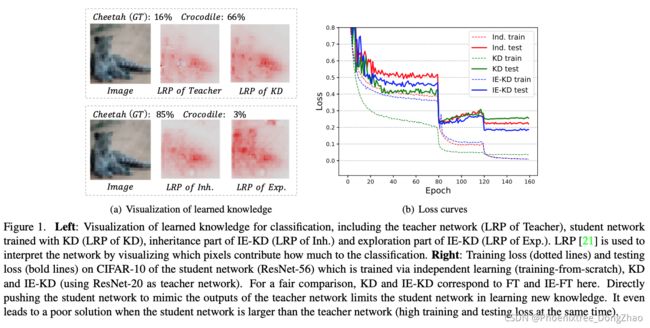
Revisiting Knowledge Distillation: An Inheritance and Exploration Framework
[pdf]

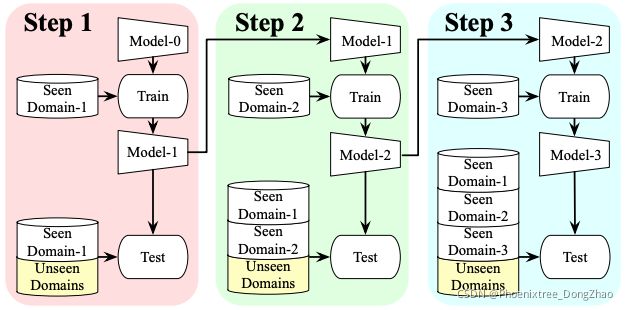
Lifelong Person Re-Identification via Adaptive Knowledge Accumulation
[pdf] [supp] [arXiv]
Figure 1: Pipeline of the proposed lifelong person reidentification task. The person identities among the involved domains are completely disjoint.
KRISP: Integrating Implicit and Symbolic Knowledge for Open-Domain Knowledge-Based VQA
[pdf] [supp] [arXiv]
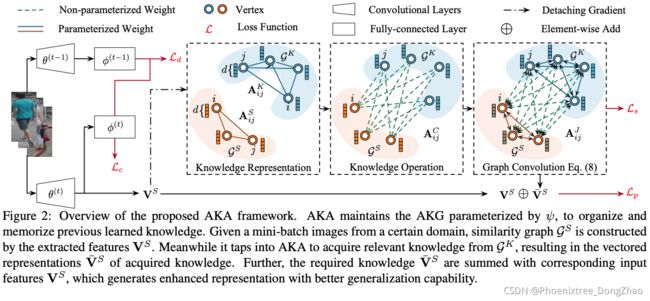
Amalgamating Knowledge From Heterogeneous Graph Neural Networks
[pdf]
Wasserstein Contrastive Representation Distillation
[pdf] [supp] [arXiv]
Prototype Completion With Primitive Knowledge for Few-Shot Learning
[pdf] [supp] [arXiv]
Improving Weakly Supervised Visual Grounding by Contrastive Knowledge Distillation
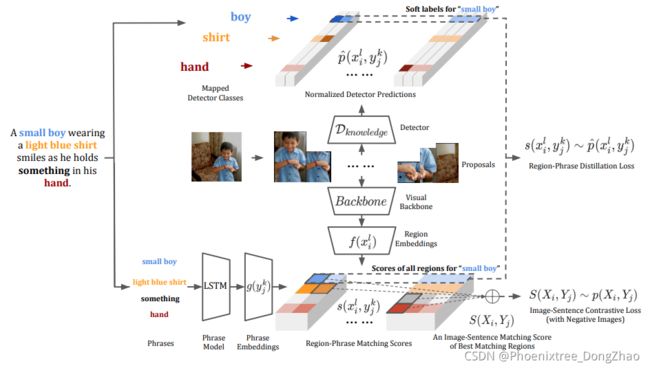
[pdf] [supp] [arXiv]
Figure 1: Our method uses object detector predictions to guide the learning of region-phrase matching in training. At the inference time, our method no longer requires object detectors and directly predicts the box with the highest score.
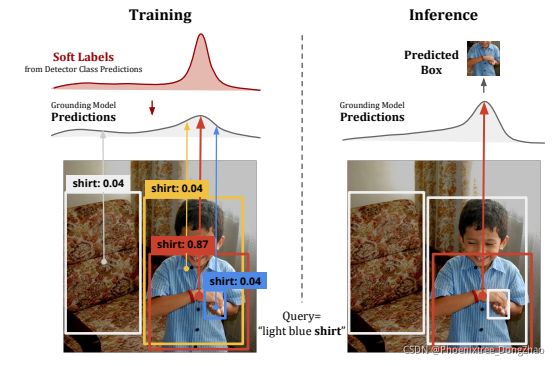
Figure 2: Overview of our method in training. A contrastive learning framework is designed to account for both region-phrase and image-sentence matching. The top part illustrates region-phrase matching learned by distilling from object detection outputs, while the bottom part shows image-sentence matching supervised by ground-truth image-sentence pairs.
EvDistill: Asynchronous Events To End-Task Learning via Bidirectional Reconstruction-Guided Cross-Modal Knowledge Distillation
[pdf]
Joint-DetNAS: Upgrade Your Detector With NAS, Pruning and Dynamic Distillation
[pdf] [supp]
![]()
Multiresolution Knowledge Distillation for Anomaly Detection
[pdf] [supp] [arXiv]

![]()
Data-Free Knowledge Distillation for Image Super-Resolution
[pdf] [supp]