mysql 分布式主键_分布式主键--生成方法
下面介绍几种分布式id的生成策略:
1、UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:cc8fd628-ef02-426d-a954-89294591024c
java中java.util包中直接提供了生成UUID的方法:
UUID.randomUUID().toString()
优点:
因为是本地生成的,所以没有网络消耗,性能非常高。
缺点:
太长了!是一个36长度的长字符串,不利于存储。
不太安全,UUID基于mac地址生成,会造成mac地址泄露。
不适用于作为主键,以mysql为例,mysql官方建议主键长度越短越好,而UUID则是36位,不建议适用;并且UUID因为其无序性,如果作为主键插入时会引起数据位置的频繁变动,严重影响性能。
2、数据库生成
以mysql为例,在设置主键时可以通过设置自动递增来保证ID自增。
优点:
实现简单,基于数据库功能实现,不需要编码,对开发成本小。
ID有顺序递增,在某些业务场景下非常适用,适用于作为mysql的主键,也是mysql官方推荐的主键生成策略。
缺点:
对数据库依赖太高,当数据库异常时,整个系统不可用。
性能不高,主要性能限制为单台mysql的读写性能。
对于以上的缺点性能问题,可以有以下的方案来进行解决:
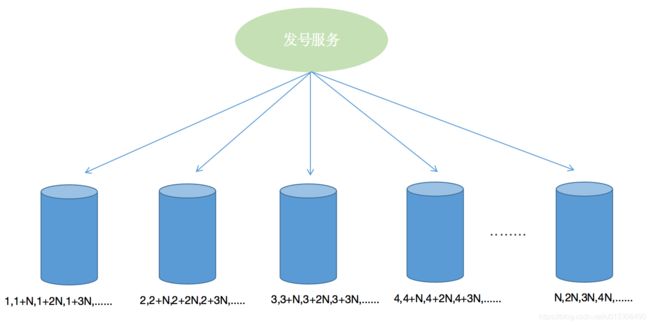
多部署几台机器,每台机器设置不用的初始值,步长和机器数量相同。例如2台机器server1、server2,server1初始值为1,server2初始值为2,步长都为2,则server1的号段为1、3、5、7、9......,server2的号段为2、4、6、8、10......。同理,如果部署N台机器,则每台的初始值依次为1,2,3,4,5....N,步长为N,则整体架构图如下:
3.雪花算法(Snowflake)
Snowflake来源于Twitter,原理是生成一个64bit大小的长整型。sharding-jdbc如果分片键不设置值,则默认使用Snowflake生成一个值。先说说优点:
SnowFlake生成ID能够按照时间有序生成
SnowFlake算法生成id的结果是一个64bit大小的整数,换算为长整形为18位
分布式系统内不会产生重复id
原理:
编号由四部分组成,从高位到低位(从左到右)分别是:
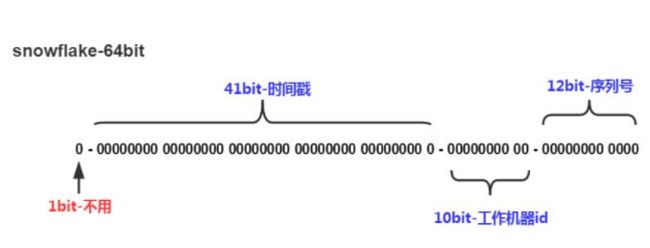
符号位:长度1bit,等于0。
时间戳:长度41bit,从 2016/11/01 零点开始的毫秒数(1480166465631L),支持 2 ^41 /365/24/60/60/1000=69.7年。
工作进程编号:长度10bit,所以最多支持2 ^10也就是1024个进程。
序列号(自增编号):长度12bit,每毫秒从 0 开始自增,支持2 ^12也就是 4096 个编号。
可见,每个工作进程每毫秒可以产生最多4096个ID,则每秒可以产生4096000个。
放一波代码:


public class IdGenerator implementsKeyGenerator {/*** 时间偏移量,从2016年11月1日零点开始*/
public static final long EPOCH = 1540000000000L;/*** 自增量占用比特*/
private static final long SEQUENCE_BITS = 12L;/*** 工作进程ID比特*/
private static final long WORKER_ID_BITS = 10L;/*** 自增量掩码(最大值)*/
private static final long SEQUENCE_MASK = (1 << SEQUENCE_BITS) - 1;/*** 工作进程ID左移比特数(位数)*/
private static final long WORKER_ID_LEFT_SHIFT_BITS =SEQUENCE_BITS;/*** 时间戳左移比特数(位数)*/
private static final long TIMESTAMP_LEFT_SHIFT_BITS = WORKER_ID_LEFT_SHIFT_BITS +WORKER_ID_BITS;/*** 上一次的序列号,解决并发量小总是偶数的问题*/
private long lastSequence = 0L;private static TimeService timeService = newTimeService();/*** 工作进程ID*/
private static longworkerId;/*** 最后自增量*/
private longsequence;/*** 最后生成编号时间戳,单位:毫秒*/
private longlastTime;static{/*** 浏览 IPKeyGenerator 工作进程编号生成的规则后,感觉对服务器IP后10位(特别是IPV6)数值比较约束。
* 有以下优化思路:
* 因为工作进程编号最大限制是 2^10,我们生成的工程进程编号只要满足小于 1024 即可。
* 1.针对IPV4:
* ....IP最大 255.255.255.255。而(255+255+255+255) < 1024。
* ....因此采用IP段数值相加即可生成唯一的workerId,不受IP位限制
*
* @Author DogFc*/InetAddress address;try{
address=InetAddress.getLocalHost();
}catch (finalUnknownHostException e) {throw new IllegalStateException("Cannot get LocalHost InetAddress, please check your network!");
}byte[] ipAddressByteArray =address.getAddress();long workerId = 0L;//IPV4
if (ipAddressByteArray.length == 4) {for (bytebyteNum : ipAddressByteArray) {
workerId+= byteNum & 0xFF;
}//IPV6
} else if (ipAddressByteArray.length == 16) {for (bytebyteNum : ipAddressByteArray) {
workerId+= byteNum &0B111111;
}
}else{throw new IllegalStateException("Bad LocalHost InetAddress, please check your network!");
}
IdGenerator.workerId=workerId;
}
@OverridepublicNumber generateKey() {//保证当前时间大于最后时间。时间回退会导致产生重复id
long currentMillis =timeService.getCurrentMillis();
Preconditions.checkState(lastTime<=currentMillis,"Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds", lastTime,
currentMillis);//获取序列号
if (lastTime ==currentMillis) {if (0L == (sequence = ++sequence & SEQUENCE_MASK)) { //当获得序号超过最大值时,归0,并去获得新的时间
currentMillis =waitUntilNextTime(currentMillis);
}
}else{//根据上一次sequence决定本次序列从0还是1开始,保证低并发时奇偶交替
if (lastSequence == 0) {
sequence= 1L;
}else{
sequence= 0L;
}
}
lastSequence=sequence;//设置最后时间戳
lastTime =currentMillis;//生成编号
return ((currentMillis - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS) | (workerId <
}/*** 不停获得时间,直到大于最后时间
*
*@paramlastTime 最后时间
*@return时间*/
private long waitUntilNextTime(final longlastTime) {long time =timeService.getCurrentMillis();while (time <=lastTime) {
time=timeService.getCurrentMillis();
}returntime;
}
}
View Code
说明:
1、算法思路整体较为简单,主要的操作就是对workId、自增序号、还有时钟回拨的处理( 如果时钟回拨的时间超过最大容忍的毫秒数阈值,则程序报错;如果在可容忍的范围内,默认分布式主键生成器会等待时钟同步到最后一次主键生成的时间后再继续工作。 最大容忍的时钟回拨毫秒数的默认值为0,可通过属性设置)。
2、上面的算法在SnowFlake的基础上进行了两个优化。
优化了wordId的设置策略,采用分别对ipv4、ipv6的ip取不同位进行处理,具体策略可见注释。
优化了SnowFlake在低并发情况下生成的id为偶数的问题,这个问题的原因就是因为最后几位表示的是同一毫秒下的并发编号自增,当并发较低时,最后几位始终都是0,所以最后生成的ID均为偶数,上面的算法加入了一个自增量sequence字段,根据上一次sequence决定本次序列从0还是1开始,保证了低并发下奇偶交替。
原文链接: https://blog.csdn.net/u013308490/article/details/94719497