Gbase 8a MPP Cluster维护过程中可能遇到的故障管理(八-下)
导入导出
13 orato8a query 方式导出报错 ORA-02391 连接数不足
问题现象
执行 orato8a 导出,报错 ORA-02391,连接数不够了。但 sqlplus 执行 sql 不报错,
怀疑 orato8a 在一次导出数据建立了多个 session 连接。

和研发确认,orato8a 会启动两个进程,一个里面有一个链接。
解决方法
DBA 增加用户连接数设置。
14 orato8a 抽取包含 clob 字段表速度慢
问题现象
orato8a 抽取包含 clob 字段表速度慢。
原因分析
oracle server 在访问 lob 数据时 io 压力过重。
解决方法
从 oracle 服务器优化性能,方法有:
建表时对 lob 字段不使用''DISABLE STORAGE IN ROW''。
建表时对 lob 字段调整 CHUNK 参数值,使其覆盖到大部分 lob 字段数据宽度。
建表时对 lob 字段增加参数 CACHE 或 CACHE READS。
15 导出数据到 kerberos 认证 hdfs,数据可以正常导出,但会有报错信息
问题现象
通过 kerberos 认证不落地导出数据到 hdfs,数据可以正常导出,但会有报错信息,
信息如下:
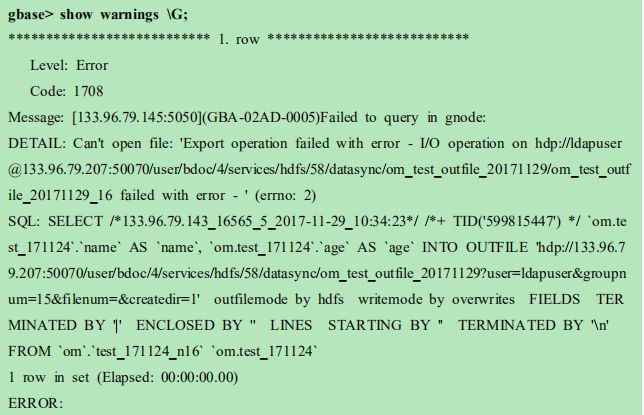
![]()
已经确定 hdfs 中已经有导出的数据,但是集群依然报错。
原因分析
通过对日志分析及模拟测试,确定问题的原因为:
Hadoop 集群在接收到并发的 token 请求后,有可能报错(不通过 8a 导出功能,
脚本就能复现)。
通过筛查现场 hadoop 日志,发现共有两种报错的堆栈,都是由 jdk 层 jgss 模块引
发,日前暂未找到从部署上规避此问题的方法。
两种报错:
GSSException: No valid credentials provided (Mechanism level: Failed to fi
nd any kerberos credentails).
GSSException:Failure unspecified at GSS-API level (Mechanism level: Req
uest a replay (34)).
其中报错 2 已明确是因为 jdk 层 jgss 模块为防止 replay 攻击的实现机制导致,而
报错 2 的具体原因目前还不清楚,推测与使用相同 Kerberos 凭据向 hadoop 进行
高并发认证相关。
解决方法
两种报错的解决方案如下,解决方案可以二选一:
GSSException: No valid credentials provided (Mechanism level: Failed to find
any kerberos credentails).
1.修改用户应用程序,在加载和导出 SQL 中使用 Hadoop 的 Namenode 主
机名代替 IP 地址;
2.升级部署的 Hadoop 版本到 2.8.0 版本。
GSSException:Failure unspecified at GSS-API level (Mechanism level: Request
a replay (34))
1) 升级 Hadoop 集群 java 环境到 1.8.0 版本;
2) 修改 GBase 8a 连接 Hadoop 的实现,支持单点登录和 token 维护。
16 gbase 导出到 hadoop 无响应
问题现象
gbase 导出到 hadoop 无响应。
原因分析
webhdfs 导出没有超时控制,hdfs 无响应时导出长时间卡住。
解决方法
增加导出超时参数解决 HDFS 导出卡住问题 gbase_export_write_timeout。
17 使用 gcdump 参数 ignore-table 不导出指定的表或视图
问题现象

解决方法
如果需要忽略报错,不导出有问题的视图,可以加--ignore-table 参数。


前提是需要事先知道哪些表或视图不需要导出,并且一个--ignore-table 参数后面只能接一个表。
18 sftp 加载大文件报错
问题现象
使用 sftp 加载大文件报错,加载小文件正常。
原因分析
当集群并发加载任务数和单任务最大加载机数较大时,会出现 sftp 文件加载失败的情况。
解决方法
确定是参数 gcluster_loader_max_data_processors 设置太大造成,将参数调小后无报错。
![]()
建议使用 sftp 加载的方式,sshd 的配置文件需要调整 maxstartup、maxsession 等参数。
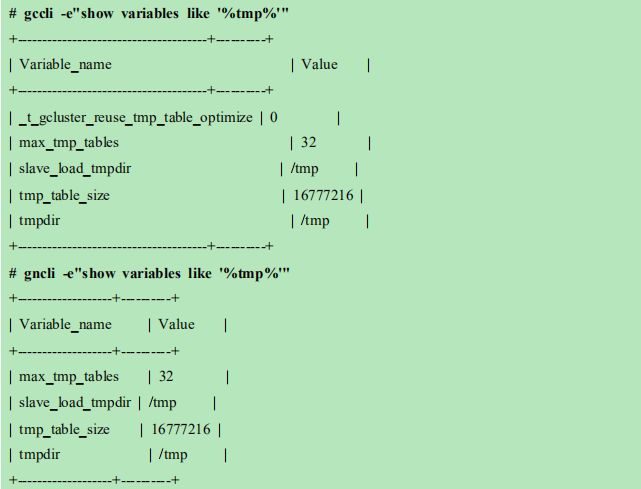
19 tmp 目录权限改变导致加载失败
问题现象
项目上进行安全扫描,将操作系统 tmp 目录的权限修改为 750,造成集群加载失
败,后修复为 777 后恢复正常。产品层面有没有办法进行调整?
解决方法
调整数据库参数,将指定/tmp 路径的,修改为 gbase 系统用户路径,如
/home/gbase/tmp。
20 orato8a 导出报错 error while loading sharedlibraries 等
问题现象
在使用 orato8a 导出数据过程中报错./orato8a: error while loading shared libraries:
libclntsh.so.11.1: cannot open shared object file: No such file or directory,报错
./orato8a: error while loading shared libraries: libHbaseThrift.so.0: cannot open
shared object file: No such file or directory 等。
解决方法
使用 orato8a-8.6.2.11-R3-redhat6.2-x86_64 在 oracle server 服务器上进行测试。
报错找不到 libclntsh.so.11.1

在 LD_LIBRARY_PATH 中添加 libclntsh.so.11.1 所在路径。
![]()
报错找不到 libHbaseThrift.so.0

libHbaseThrift.so.0 是 orato8a 安装包中自带的 lib 库,在 LD_LIBRARY_PATH
中添加 libHbaseThrift.so.0 所在路径。
![]()
报错 FAILED: OCIEnvCreate()

添加 ORACLE_HOME 解决。
![]()
导出成功。

21 orato8a 导出大数据量卡住
问题现象
用 orato8a 导出 1.2T 数据,导出 290G 左右数据就无法写入。试过全表导出和 query
方式导出,都出现了同样的现象。
orato8a 报错:

原因分析
问题是当单次查询导出数据量过大,且其它应用 DML 操作提交过多时,oracle
的快照失效引起。
解决方案
orato8a:
使用--table_name 参数,加大--parallel 并发数,以减少查询导出时间;
使用--query 参数,带 where 过滤,以减少查询导出时间。
oracle 配置
1) 增加 UNDO 表空间大小;
2) 增加 UNDO_RETENTION 时间,默认为 15 分钟。
现场其它访问 oracle 的应用
1) 避免频繁的 DML 操作提交。
22 rmt 远程导出卡住
问题现象
如果不加 first_row 或者 first_row 设置不合理,容易出现卡住的问题。每一个发送
端都会向接收端建立一个连接,用于发送数据,接收端为每一个发送端启动一个
接收线程,实现并行接收,当接收端 Buffer 满了以后就抢占串行写锁,如果抢占
成功就会将接收线程 Bufferr 的数据写入导出文件。但如果一个接收线程抢占串行
写锁后,接收 Buffer 又有源源不断的数据,就会阻塞其它接收线程的 Flush,当其
它接收的线程 Buffer 满后,发送端就会收到不能再发送的信息,这个时候发送端
就会用一个 timeout 进行不停的探测,而且每次 timeout 后这个值会递增。而持有
串行写锁的线程,释放该锁后。其它接收线程也都 Flush 完成后,发送端这个时
候还没有到 timeout,所以就没有数据发送到接收端造成导出卡住的假象出现。集
群规模越大,相对越容易出现。
临时解决方案
使用 gccli-c + (hint)first_row 参数的控制方式。
23 远程 rmt 导出 dual 表数据没有落到本地而是落到了集群节点上
问题现象
在使用 rmt 导出物理表,数据文件落在本地服务器上。使用 rmt 导出 dual 表时,
数据文件落在-h 连接的集群节点上。
例如 gccli-h132.151.55.14-ubi-pBiChinaU1!-e"rmt:select'1'from dual into outfile'
/home/gbase/zhoutt1.txt'"
数据没有导出到 gccli 所在的服务器,而是落到了 132.151.55.14 上。
测试版本 8.6.2_build23-R8。
解决方法
打开_t_gcluster_use_new_dual 参数,使用新 dual 模式,可以正常导出到 gccli 所
在服务器。
另外,使用一般用户导出还需要额外赋予用户 dual 表的 select 权限,grant select on
gclusterdb.dual to u01。
24 ftp 报错 500 OOPS: cannot changedirectory:/home/*******
问题现象
现场通过 ftp 获取数据文件,报错信息如下:
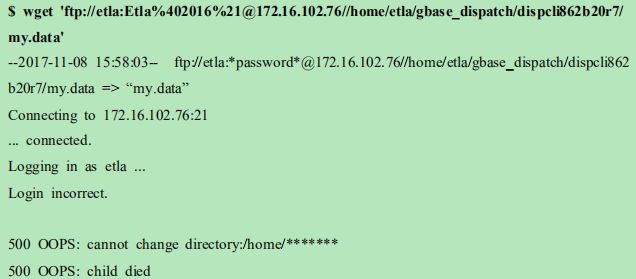
解决方法
当你看到以上提示时,试着输入以下命令解决

![]()
第一行中的-P 参数是为了以后不需要每次开机都输入这个命令。
如果使用 setsebool-P ftpd_disable_trans 1 //加-P 表示永久性。
如果提示以下错误:

可能直接使用下面这个一条就可以解决了:
![]()
如果还是不行的话再使用下面完全方式:

重启 vsftpd,即可解决问题。