深入理解ORC文件结构
官方原文如下,本文附加了一些通俗理解:Evolving Draft for ORC Specification v2https://orc.apache.org/specification/ORCv2/
ORC文件的总体结构如下:

orc文件结构对数据的查找和索引本质上是三层过滤:文件级、Stripe级、Row Group级。这样可以把最终实际要扫描读取的数据减少到部分Stripe的部分RowGroup,不用全扫整个文件。也就是先从文件末尾往前读文件元数据,再跳着读Stripe元数据,最终读需要的Stripe中的部分数据。
一、文件级
为了在SQL查询时更快跳过where等过滤条件中不需要的文件,在文件级别首先通过file tail来记录文件级别的元数据信息。file tail自底向上主要由这三部分组成:postscript、file footer、file metadata,它们都使用 Protocol Buffers 存储(因为可以提供添加新字段而不用改写reader的能力)。
1.1、PostScript
Postscript 部分提供了解释该ORC文件其余部分的必要信息,包括File Footer和Metadata部分的长度、文件的版本以及使用的压缩类型(例如none、zlib或snappy)。Postscript永远不会被压缩并在文件末尾前一个字节结束(所以整个File Tail的长度就是:footerSize + metadataSize + postScriptSize + 1 byte)。 Postscript 中存储的版本是保证能够读取文件的Hive最低版本,它存储为主要和次要版本的序列。
读取ORC文件的过程是从底部往前的。ORC reader会直接读取文件的最后16kb,希望它同时包含footer和postscript部分。文件的最后一个byte包含Postscript的序列化长度,该长度必须小于256 byte。一旦Postscript被解析,Footer的压缩序列化长度就已知,就可以被解压缩和解析。该结构具体保存的信息如下图所示:
message PostScript {
// the length of the footer section in bytes
optional uint64 footerLength = 1;
// the kind of generic compression used
optional CompressionKind compression = 2;
// the maximum size of each compression chunk
optional uint64 compressionBlockSize = 3;
// the version of the writer
repeated uint32 version = 4 [packed = true];
// the length of the metadata section in bytes
optional uint64 metadataLength = 5;
// the fixed string "ORC"
optional string magic = 8000;
}
enum CompressionKind {
NONE = 0;
ZLIB = 1;
SNAPPY = 2;
LZO = 3;
LZ4 = 4;
ZSTD = 5;
}其中的“magic”被称为魔数,个人理解类似java字节码开头的“ca fe ba be”,是为了确定该结构确实就是符合规范的ORC文件。
1.2、File footer
Footer部分包含文件主体的布局、类型schema信息、行数以及关于每列的统计信息。文章开头的结构图已经展示了ORC文件主要分为三个部分:header、body和tail。 Header由字节“ORC”组成,以支持想要扫描文件开头以确定文件类型的其他工具。Body包含行和索引,Tail提供文件级别信息,因此Tail中的File Footer就主要包含这三部分的一些元信息,如下所示:
message Footer {
// the length of the file header in bytes (always 3)
optional uint64 headerLength = 1;
// the length of the file header and body in bytes
optional uint64 contentLength = 2;
// the information about the stripes
repeated StripeInformation stripes = 3;
// the schema information
repeated Type types = 4;
// the user metadata that was added
repeated UserMetadataItem metadata = 5;
// the total number of rows in the file
optional uint64 numberOfRows = 6;
// the statistics of each column across the file
repeated ColumnStatistics statistics = 7;
// the maximum number of rows in each index entry
optional uint32 rowIndexStride = 8;
// Each implementation that writes ORC files should register for a code
// 0 = ORC Java
// 1 = ORC C++
// 2 = Presto
// 3 = Scritchley Go from https://github.com/scritchley/orc
// 4 = Trino
optional uint32 writer = 9;
// information about the encryption in this file
optional Encryption encryption = 10;
// the number of bytes in the encrypted stripe statistics
optional uint64 stripeStatisticsLength = 11;
}1.2.1、Stripe Information
ORC文件被分成多个Stripe,这种设计使得当SQL有过滤条件时,可以只通过读取文件尾部的PostScript、File Footer中的值范围信息(如每个stripe内容的最大最小值)来确定实际只需要读哪些Stripe,跳过文件中其他Stripe的读取。 每个Stripe包含三个部分:Stripe内各行的一组索引(每个Stripe包含文件的一部分行)、数据本身和Stripe Footer。 索引和数据部分都按列划分,因此只需要读取所需列的数据。File Footer中会保存每一个Stripe的Information,具体内容如下:
message StripeInformation {
// the start of the stripe within the file
optional uint64 offset = 1;
// the length of the indexes in bytes
optional uint64 indexLength = 2;
// the length of the data in bytes
optional uint64 dataLength = 3;
// the length of the footer in bytes
optional uint64 footerLength = 4;
// the number of rows in the stripe
optional uint64 numberOfRows = 5;
// If this is present, the reader should use this value for the encryption
// stripe id for setting the encryption IV. Otherwise, the reader should
// use one larger than the previous stripe's encryptStripeId.
// For unmerged ORC files, the first stripe will use 1 and the rest of the
// stripes won't have it set. For merged files, the stripe information
// will be copied from their original files and thus the first stripe of
// each of the input files will reset it to 1.
// Note that 1 was choosen, because protobuf v3 doesn't serialize
// primitive types that are the default (eg. 0).
optional uint64 encryptStripeId = 6;
// For each encryption variant, the new encrypted local key to use until we
// find a replacement.
repeated bytes encryptedLocalKeys = 7;
}1.2.2、Type
ORC 文件中的所有行必须具有相同的schema。 列类型信息是以下图所示的树结构存储的,如果是Map等复合类型,会向下继续扩散树叶节点:

这样记录的树结构其实代表的是如下建表语句中的列类型:
create table Foobar (
myInt int,
myMap map>,
myTime timestamp
); 类型树通过前序遍历被展平在一个list中(类似算法数据结构课程中二叉树的存储结构),其中每个类型都被分配了一个自增id。 显然类型树的根总是类型id为0。复合类型会有一个名为subtypes 的字段,其中包含其子类型id的list,存储的proto结构如下所示:
message Type {
enum Kind {
BOOLEAN = 0;
BYTE = 1;
SHORT = 2;
INT = 3;
LONG = 4;
FLOAT = 5;
DOUBLE = 6;
STRING = 7;
BINARY = 8;
TIMESTAMP = 9;
LIST = 10;
MAP = 11;
STRUCT = 12;
UNION = 13;
DECIMAL = 14;
DATE = 15;
VARCHAR = 16;
CHAR = 17;
TIMESTAMP_INSTANT = 18;
}
// the kind of this type
required Kind kind = 1;
// the type ids of any subcolumns for list, map, struct, or union
repeated uint32 subtypes = 2 [packed=true];
// the list of field names for struct
repeated string fieldNames = 3;
// the maximum length of the type for varchar or char in UTF-8 characters
optional uint32 maximumLength = 4;
// the precision and scale for decimal
optional uint32 precision = 5;
optional uint32 scale = 6;
}1.2.3、Column Statistics
该统计信息是对于每一列,orc writer都记录文件级别的count数并根据列类型记录其他有用字段。 对于大多数基本类型,会记录min和max值; 对于数字类型,还会存储sum,这样除了可以跳过不需要读的文件,也可以在SQL中select min、max、sum等值时直接读一下footer返回而不用实际扫描整个文件的每个值再聚合。 从Hive 1.1.0起里面还可以设置hasNull标志来记录row group内是否有任何空值。ORC的谓词下推使用该hasNull标志来更好地过滤“IS NULL”查询,跳过对应列为NULL的行,所以在SQL业务中建议用NULL而不是"-"、""等来表示空逻辑,因为NULL可以触发ORC自己的谓词下推读性能优化。该结构存储了以下信息:
message ColumnStatistics {
// the number of values
optional uint64 numberOfValues = 1;
// At most one of these has a value for any column
optional IntegerStatistics intStatistics = 2;
optional DoubleStatistics doubleStatistics = 3;
optional StringStatistics stringStatistics = 4;
optional BucketStatistics bucketStatistics = 5;
optional DecimalStatistics decimalStatistics = 6;
optional DateStatistics dateStatistics = 7;
optional BinaryStatistics binaryStatistics = 8;
optional TimestampStatistics timestampStatistics = 9;
optional bool hasNull = 10;
}1.3、File Metadata
该部分包含各Stripe级别粒度的列统计信息(上面File Footer中的ColumnStatistics是整个文件级别的)。这些统计信息可以根据SQL中的过滤条件,利用谓词下推来跳过对部分Stripe的读取。该部分存储的内容如下:
message StripeStatistics {
repeated ColumnStatistics colStats = 1;
}
message Metadata {
repeated StripeStatistics stripeStats = 1;
}二、Stripe级
ORC 文件的主体由一系列Stripe组成。 每个Stripe通常约为200MB且彼此独立,并且通常由不同的任务处理。 列存储格式的定义特征是每一列的数据是分开存储的,从文件中读取数据应该与读取的列数成正比。
在ORC文件中,每一列都存储在多个Stream中,这些Stream在文件中彼此相邻存储。 例如,一个整数列会表示为两个Stream:
(1)PRESENT,如果值为非空,则使用一个Stream,每个值记录一个位。
(2)以及记录非空值的DATA。
如果该Stripe中所有列的值都不为空,则从Stripe中省略PRESENT stream。 对于二进制数据,ORC使用三个Stream:PRESENT、DATA 和 LENGTH,它们存储每个值的长度。和文章最开头的结构图一致,每个Stripe的存储结构如下三部分所示:
index streams
unencrypted
encryption variant 1..N
data streams
unencrypted
encryption variant 1..N
stripe footer2.1、Stripe Footer
它包含每列的编码和Stream的,如下所示:
message StripeFooter {
// the location of each stream
repeated Stream streams = 1;
// the encoding of each column
repeated ColumnEncoding columns = 2;
optional string writerTimezone = 3;
// one for each column encryption variant
repeated StripeEncryptionVariant encryption = 4;
}2.1.1、Stream
Stream保存了用户真正关心的业务数据内容,这也是ORC列式存储的根本所在:正如开头的架构图一样,一个大文件由各Stripe分割,每个Stripe负责一个或多个行组(一个行组默认10000行),在一个Stripe负责的这多行范围内,各列的数据内容以Stream的形式按列存储。为了描述每个Stream,ORC以字节为单位存储Stream的类型、列ID和Stream的大小。每个Stream中存储内容的详细信息取决于列的类型和编码。也就是说,在一个Stripe中的每一列都可能有多个表示不同信息的Stream,存储内容如下所示:
message Stream {
enum Kind {
// boolean stream of whether the next value is non-null
PRESENT = 0;
// the primary data stream
DATA = 1;
// the length of each value for variable length data
LENGTH = 2;
// the dictionary blob
DICTIONARY_DATA = 3;
// deprecated prior to Hive 0.11
// It was used to store the number of instances of each value in the
// dictionary
DICTIONARY_COUNT = 4;
// a secondary data stream
SECONDARY = 5;
// the index for seeking to particular row groups
ROW_INDEX = 6;
// original bloom filters used before ORC-101
BLOOM_FILTER = 7;
// bloom filters that consistently use utf8
BLOOM_FILTER_UTF8 = 8;
// Virtual stream kinds to allocate space for encrypted index and data.
ENCRYPTED_INDEX = 9;
ENCRYPTED_DATA = 10;
// stripe statistics streams
STRIPE_STATISTICS = 100;
// A virtual stream kind that is used for setting the encryption IV.
FILE_STATISTICS = 101;
}
required Kind kind = 1;
// the column id
optional uint32 column = 2;
// the number of bytes in the file
optional uint64 length = 3;
}这些不同类型的Stream会分布在ORC文件里的不同部分,主要有以下几种(Kind)。首先是下面这5种Stream,出现在各Stripe的Row Data位置,即文章开头架构图的蓝色部分:
(1)PRESENT:几乎在各Stripe对应所有列的位置都会出现,按位标记是否非NULL。
(2)DATA:在各Stripe的基本类型列中出现(也就是不包含struct、map、list等复杂嵌套类型),记录数据内容本身。
(3)LENGTH:在各Stripe中string、varchar、char、list、map等需要记录每个值的长度的列出现,顾名思义。
(4)DICTIONARY_DATA:在各Stripe中string、varchar、char等采用了字典编码(类似RLE也是一种减小文件占用存储的技术,重复值只记录一次,并记录各重复值在文中出现的位置)的字符类型列出现,用来记录该列所有的distinct值(即重复内容只记录一次)。
(5)SECONDARY:在各Stripe中decimal、timestamp等列中出现,用来和DATA Stream搭配(副手),例如timestamp类型的列中,DATA Stream中记录该列在当前Stripe范围中每一行的秒值,而SECONDARY Stream就记录该列在当前Stripe范围中每一行的纳秒值。
而接下来这2种Stream出现在各Stripe的Index Data位置,即文章开头架构图的绿色部分:
(6)ROW_INDEX:存储当前列在该Stripe中某一个Stream的某个row group的起始位置和列偏移量,以及当前列在该Stripe的某个row group中的Statistics统计信息。
(7)BLOOM_FILTER:用于记录当前列在该Stripe中每一个row group的布隆过滤器信息,用于谓词下推跳过不用读取的行组。
有了上述各Stream功能以及所处位置的概念,那么对于某个boolean、tinyint、smallint、int、bigint、float、double、date类型的列,该列在某个Stripe中的Stream列式存储会包含这几种:

对于String、char、varchar类型的列,是否采用字典编码方式,在某个Stripe中会呈现两种不同的Stream组成(是否包含DICTIONARY_DATA Stream):

如果没有采用字典编码,UTF-8字节数据保存在DATA Stream中,每个值的长度写入LENGTH Stream。假设数据值为 [“Nevada”, “California”],那么DATA为“NevadaCalifornia”,LENGTH 为[6, 10]。
如果采用字典编码,假设要存储的数据值为[“Nevada”、“California”、“Nevada”、“California”、“Florida”],则DICTIONARY_DATA为“CaliforniaFloridaNevada”(字典只需要保存出现的唯一值),LENGTH 为[10, 7, 6],DATA是[2, 0, 2, 0, 1](以字母序排列,0这个序号就代表California,1就是Florida),这样在数据内容位置存储字典序号,比存单词值本身更加节省空间。只需要维护一个字典,知道序号几是排序字典中哪个单词的映射,读取数据值时只要去找字典中的对应序号位置代表什么内容,再展示就行。
而对于timestamp类型的列,在某个Stripe中的Stream存储会包含这几种:

对于List和Map类型的列,则在Stripe中的存储由这样的Stream组成:

因此在使用hive --orcfiledump
更简洁的orc dump结果例子也可以参考:Presto ORC及其性能优化 - armsword的涅槃之地
2.1.2、ColumnEncoding
根据列的类型,可能有几种编码选项。 编码分为直接或基于字典的不同种类,并进一步细化它们是使用RLE v1还是v2(RLE,游程编码,一种减少文件占用空间的技术,文件中的多个重复内容只存储一遍,并标明重复值所在的各个位置)。
2.2、Index
2.2.1、Row Group Index
它由每个原始列的ROW_INDEX Stream组成,每个原始列都有RowIndexEntry。 行组由orc writer控制,默认为10,000行一个row group,而一个Stripe可能有多个row group,因此也可能有多个row group index。 每个RowIndexEntry给出该列的每个Stream的位置以及该row group的统计信息,因此一个RowIndexEntry就对应一个row group。
Index Stream被放置在每个Stripe的开头(正如文章一开始结构图的绿色部分),因为在默认的流式传输情况下它们不需要被读取,除非在使用谓词下推或orc reader寻找特定行时才会读这部分。Row Group Index存储的内容如下所示:
message RowIndexEntry {
repeated uint64 positions = 1 [packed=true];
optional ColumnStatistics statistics = 2;
}
message RowIndex {
repeated RowIndexEntry entry = 1;
}为了记录position,每个Stream都需要一个数字list。 对于未压缩的Stream,position的第一个值是RLE运行开始位置的字节偏移量,第二个值是需要从运行中读取的值的数量。正如下图debug trino源码时发现的List
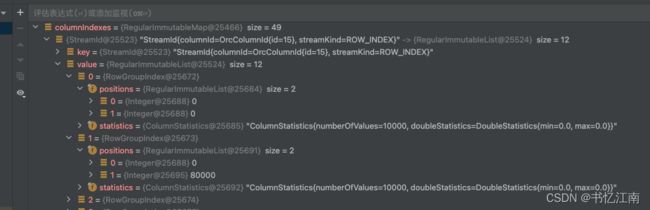
而在压缩Stream中,position的第一个数字是Stream中压缩块的开头,第二个是需要读取的解压缩字节数,最后是RLE中读取的值的数量,正如下面debug截图所示的3个值:

对于具有多个Stream的列,每个Stream中的位置序列是连接的。 这里对使用索引的代码容易出错。
因为字典是随机访问的,所以没有位置可以记录字典,即使只读取部分Stripe,也必须读取整个字典。
2.2.2、Bloom Filter Index
从 Hive 1.2.0 开始,Bloom Filters被添加到ORC索引中。 谓词下推可以利用布隆过滤器更好地修剪不满足过滤条件的row group。 Bloom Filter Index由通过“orc.bloom.filter.columns”表属性指定的每一列的 BLOOM_FILTER Stream组成。BLOOM_FILTER Stream为列中的每个row group(默认为10,000行)记录一个布隆过滤器条目。 只有满足min/max row index范围的row group才会根据布隆过滤器索引进行评估。
每个布隆过滤器条目存储使用的哈希函数('k')的数量和支持布隆过滤器的BItSet。 布隆过滤器的原始编码(ORC-101 之前)使用bitset字段编码为bitset字段中的long重复序列,采用小端序编码(0x1 是 bit 0,0x2 是 bit 1。)在 ORC-101 之后, encoding 是一个字节序列,在 utf8bitset 字段中具有小端编码。
Bloom Filter Index的存储内容如下图所示:
message BloomFilter {
optional uint32 numHashFunctions = 1;
repeated fixed64 bitset = 2;
optional bytes utf8bitset = 3;
}
message RowIndex {
repeated RowIndexEntry entry = 1;
}Bloom Filter Stream与Row Group Index Stream是交错存储的。 这种布局便于在单次读取操作中同时读取bloom stream和row index stream,如下图所示:

三、压缩
如果ORC文件writer选择压缩方式(zlib或snappy),则除Postscript之外的其他部分会进行压缩。 但是ORC的要求之一是reader能够跳过压缩字节而不解压缩整个Stream。为了管理这一点,ORC将压缩Stream写入带有header的块中,如下图所示:
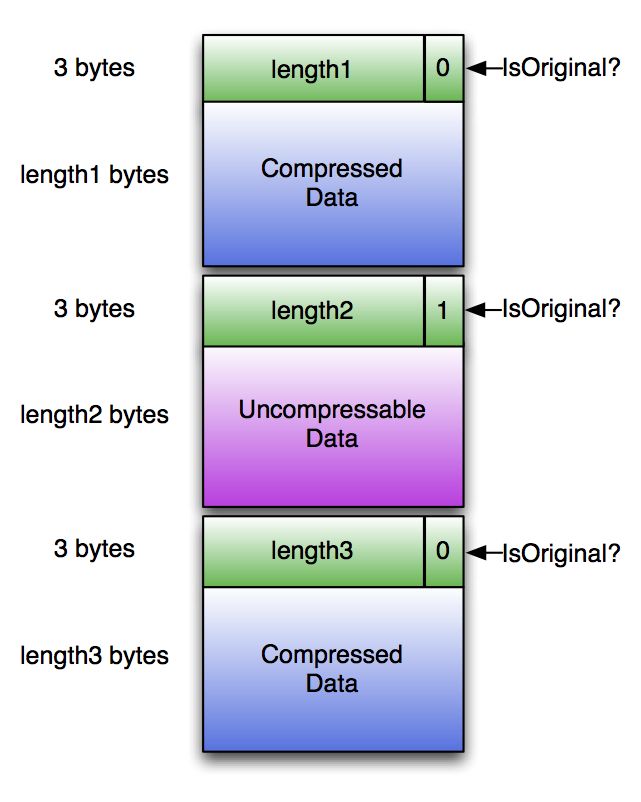
为了处理不可压缩的数据,如果压缩后数据大于原始数据,则存储原始数据并设置isOriginal标志。每个header长3个字节,即(compressedLength * 2 + isOriginal)存储为小端值。 例如,压缩到100,000字节的块的header将是[0x40, 0x0d, 0x03]。未压缩的5个字节的标头为[0x0b, 0x00, 0x00]。每个压缩块都是独立压缩的,因此只要解压缩器从header的顶部开始,就可以在没有其他先前字节的情况下开始解压缩。