云原生RDS在k8s中的实现【详解】
近些年云计算最火的领域围绕PaaS层级,向下PaaS平台能部署标准云计算IaaS资源或者自建机房的基础硬件建设,向上利用PaaS微服务架构特点快速构建SaaS应用。而基于容器编排技术的Kubernetes,已然成为业界事实标准,容器化,云原生一跃成为近几年云计算领域最火的关键字,是企业数字化转型过程中的重要技术选型环节。
利用k8s平台快速部署应用大体上分为5步:
1、开发应用
2、利用Docker技术打包应用
3、创建一个kubernetes集群
4、部署容器化应用到k8s集群中
5、服务暴露、按需扩展集群
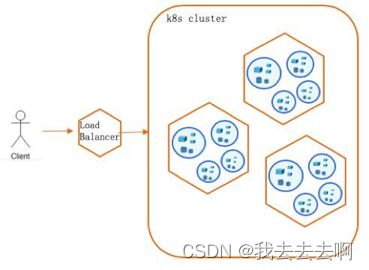
粗粒度上我们可以根据应用类型分为无状态应用(Stateless Services)和有状态应用(Stateful Services)。无状态应用较于容易横向扩展,如下图横向增加配置好的Web服务并注册到Nginx代理,即可增加客户端访问流量。

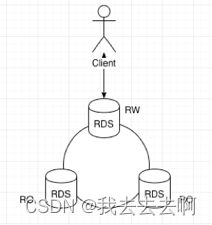
有状态服务通常是云平台建设的难点,例如分布式的关系型数据库一般大于3节点,某个时间段内Primary node提供可读写的权限,其他节点只提供只读权限,当Primary Node发生异常就需要进行高可用切换或者选主过程。
过去很长一段时间,B端企业的应用一般由各大ISV(软件独立开发商)提供或共同开发,用于存储数据的关系型数据库更是种类繁多,最为常见的有Oracle、MySQL、SQL Server、Postgresql等。数据库这类型的服务我们统称为有状态的服务或者RDS服务。如何利用K8S平台特性,运行有状态的RDS服务?主要解决以下三点问题:
- 规格配置一致
- 数据一致
- 访问入口一致
K8S自身机制保证规格配置一致性
配置规格一致交由k8s集群保证,kubernetes通俗来讲是一个分布式的资源管理平台,不管是文件还是进程,k8s都将它以资源的形式进行对待,然后对它进行管理。
- 容器资源(Docker或者rkt),容器就是一个进程,只是这个进程被隔离起来了,可以根据需要来限制它对其它资源的访问。
- pod即K8S最小调度单元,一个Pod内部客户包含多个Docker容器(Pod内的容器不可以跨物理节点),由于单个容器功能单一,一般都需要多个容器进行组合共享网络或者命名空间来完成一个完整功能。
- service服务发现pod在集群内部的ip是变化的,给对外服务提供代理。
- configmap资源类型,由于容器往往会用到一些秘钥、配置文件、环境变量进行统一管理方便做灵活的组合
- statefulSet是k8s提供的用来管理pod的资源,它将pod进行规范的管理,比如pod的启动有明确的顺序,pod与它对应的资源一旦绑定就会一直维持这个绑定关系,不会和其它pod混淆。数据库是强状态的服务,它也正是需要这些特征。
计算存储分离保证RDS的数据一致
数据一致是有状态服务的基础,在没有Docker和K8S平台的时期,计算存储分离是早期IOE的经典架构,计算和存储节点之间利用高速网络互联,如10GB万兆以太网,16GB FC channel,将计算节点的数据下沉至集中式存储做数据保护。
为了不被昂贵的小机和存储厂商绑定,缴纳高额的商业费用,阿里率先引领去IOE浪潮。MySQL开源数据库成为去“O”的数据库的首选,相继推出分布式架构解决方案,比如早期的主从复制架构,半同步和强一致性的MGR。
但是作为企业本身,希望在私有平台上构建一个同时支持多类型的集群,如果为每个数据库集群单独提供物理硬件和基础架构,那又是烟囱式的管理方式。
我们采用计算和存储分离方式,对于任何有状态的RDS应用我们会从底层存储给他分配数据卷,带来的好处不言而喻。
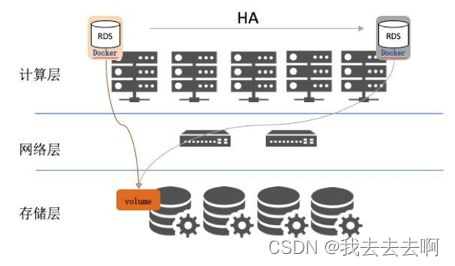
- 计算资源 / 存储资源独立扩展, 架构更清晰, 部署更容易
- 将有状态的数据下沉到存储层, Scheduler 调度时, 无需感知计算节点的存储介质, 只需调度到满足计算资源要求的 Node, 数据库实例启动时, 只需在分布式文件系统挂载mapping volume 即可. 可以显著的提高数据库实例的部署密度和计算资源利用率
- 对于数据库平台来说,计算资源所用即所需,即应用需要一个4C16G计算规格的数据库实例,平台就提供满足计算规格的数据库。通过平台的可用性检测及分布式存储卷的编排和调度能力,保证数据库高可用和数据不丢的同时,计算资源节省2/3。
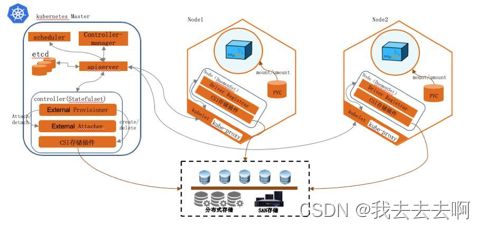
CSI插件实现外部卷管理
K8s社区在1.13版本同时release 1.10的CSI插件,正式在生产环境可用(参考:https://kubernetes.io/blog/2019/01/15/container-storage-interface-ga/)我们可以利用CSI类型的PVC资源配合外部存储的driver组件,实现挂载不同类型的分布式存储/集中式SAN存储,保护数据安全。
服务暴露
如何将RDS实例通过k8s集群暴露到真实生产环境供业务访问?通常对于RDS实例资源的使用方式,通过应用/客户端指定ip地址、端口和服务密码的方式访问数据库实例。K8s官方提供的ingress和ingress controller组件则是通过http七层转发无法满足需求。
我们通过容器化方式打包部署keepalived+keepalived-controller组件,提供RDS访问入口。

· Keepalived态配置更新
RDS实例服务暴露的IP对应real serverIP(rs),当一个RDS应用异常退出,会新建一个RDS实例来替代它。但有个特点,就是新RDS应用的IP会和之前不一样。而对应的结果就是要更新keepalived配置文件中的realserver(rs)。
· keepalived-controller
监听RDS实例服务的变化 ,如果有变化则更新keepalived的配置,并通知keepalived重新加载配置。Keepalived重新加载配置后,会更新IPVS规则,定时检测新RDS实例是否正常,管理新的ipvs规则。
利用Operator构建数据库业务应用
通过上文我们已知如何解决容器RDS资源配置一致、数据一致和访问入口一致,看起来似乎已经满足容器化云平台建设的需求,但是很遗憾k8s只认得自身的资源类型,比如pod、service、PVC,statefulset等,它并不知道什么资源类型叫做“MySQL” 或者MySQL读写分离集群的业务场景和模式。
Operator是CoreOS开发,使用了Kubernetes的自定义资源扩展API机制,如使用CRD(CustomResourceDefinition)来创建。它用来创建、配置和管理复杂的有状态应用,如数据库。
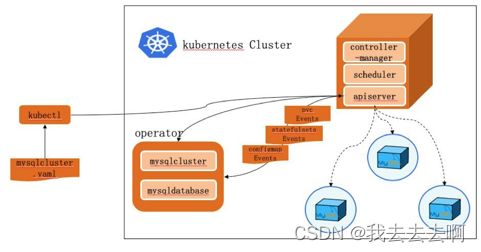
如上图我们实现K8s扩展API创建的名为“MySQLCluster”的operator,告诉k8s “MySQL”资源的创建方式是通过statefulset、pvc、configmap和service等创建出来,数据库中间件也用类似的operator方式创建完毕。
operator内的mysqlcluster控制器,再组建成如下图的MySQL一主多从,通过暴露中间件服务进行访问方式达到读写分离的业务模型。

通过k8s扩展API创建的Operator, 会不断的观察“业务模型和运行状态”
伪代码:
for{
desired := getDesiredState()
current := getCurrentState()
makeChanges(desired,current)
}
Operator不间断获取“当前运行状态”和“目标状态”做对比,一旦发生前后状态不一致情况(异常或者手动修改业务状态),Operator自动触发k8s资源管理机制,通过自动化编排调度保障业务的正常运行。
沃趣QFusion(数据库管理工具)就是基于云原生和k8s技术研发的,irds.cn开放社区版,可以一键部署实例,提供数据库全生命周期管理,包括性能监控,访问管理,异地容灾,自动故障切换,数据备份与恢复等功能,有需求的同学可以了解看看。