Spring Boot 整合 Elasticsearch
文章目录
-
- 1 概述
-
- 1.1 简介
- 1.2 基本概念
- 1.3 常用命令
- 2 创建工程并配置
- 3 使用
- 4 测试
学习在 Spring Boot 中使用 Elasticsearch。在 Spring Boot 中,使用的 Elasticsearch 实际上是
Spring Data Elasticsearch , Spring Data 是 Spring 家族的一个子项目,用于简化 SQL 和 NoSQL 的访问,在 Spring Data 中,只要你的 方法名称符合规范,它就知道你想干什么,不需要自己再去写 SQL 。
1 概述
1.1 简介
Elasticsearch 是一个基于 Lucene 的搜索服务器。它提供了一个分布式的全文搜索引擎,基于 restful web 接口。Elasticsearch 是用 Java 语言开发的,基于 Apache 协议的开源项目,是目前最受欢迎的企业搜索引擎。Elasticsearch 广泛运用于云计算中,能够达到实时搜索,具有稳定,可靠,快速的特点。
1.2 基本概念
Near Realtime(近实时):Elasticsearch 是一个近乎实时的搜索平台,这意味着从索引文档到可搜索文档之间只有一个轻微的延迟(通常是一秒钟)。- Cluster(集群):集群是一个或多个节点的集合,它们一起保存整个数据,并提供跨所有节点的联合索引和搜索功能。每个集群都有自己的唯一集群名称,节点通过名称加入集群。
Node(节点):节点是指属于集群的单个 Elasticsearch 实例,存储数据并参与集群的索引和搜索功能。可以将节点配置为按集群名称加入特定集群,默认情况下,每个节点都设置为加入一个名为 elasticsearch 的集群。Index(索引):索引是一些具有相似特征的文档集合,类似于 MySQL 中数据库的概念。Type(类型):类型是索引的逻辑类别分区,通常,为具有一组公共字段的文档类型,类似于 MySQL 中表的概念。注意:由于一些原因,在 Elasticsearch 6.0 以后,一个 Index 只能含有一个 Type。这其中的原因是:相同 index 的不同映射 type 中具有相同名称的字段是相同;在 Elasticsearch 索引中,不同映射 type 中具有相同名称的字段在 Lucene 中被同一个字段支持。在默认的情况下是_doc。在未来 8.0 的版本中,type 将被彻底删除。Document(文档):文档是可被索引的基本信息单位,以 JSON 形式表示,类似于 MySQL 中行的概念。Field(字段):类似于 MySQL 中列的概念。Shards(分片):当索引存储大量数据时,可能会超出单个节点的硬件限制,为了解决这个问题,Elasticsearch 提供了将索引细分为分片的概念。分片机制赋予了索引水平扩容的能力,并允许跨分片分发和并行化操作,从而提高性能和吞吐量。Replicas(副本):在可能出现故障的网络环境中,需要有一个故障切换机制,Elasticsearch 提供了将索引的分片复制为一个或多个副本的功能,副本在某些节点失效的情况下提供高可用性。
| Elasticsearch | 数据库 |
|---|---|
| 索引 Index | 数据库 Database |
| 类型 Type | 表 Table |
| 文档 Document | 行 Row |
| 字段 Field | 列 Column |
1.3 常用命令
详情见 Elasticsearch 常用命令
2 创建工程并配置
创建 Spring Boot 项目 spring-boot-elasticsearch ,添加 Web/Elasticsearch 依赖,如下:
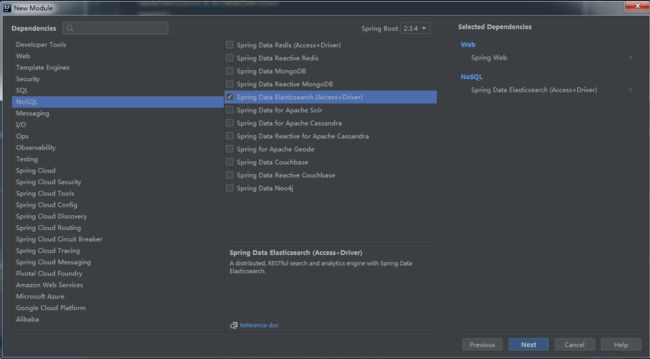
最终的依赖如下:
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
<exclusions>
<exclusion>
<groupId>org.junit.vintagegroupId>
<artifactId>junit-vintage-engineartifactId>
exclusion>
exclusions>
dependency>
dependencies>
接着在 application.properties 配置文件中添加 Elasticsearch 的基本配置,如下:
spring.data.elasticsearch.repositories.enabled=true
spring.elasticsearch.rest.uris=http://localhost:9200
spring.elasticsearch.rest.username=elastic
spring.elasticsearch.rest.password=000000
3 使用
首先创建一个 EsUser 实体类,如下:
@Document(indexName = "user", shards = 1, replicas = 0)
public class EsUser implements Serializable {
private static final long serialVersionUID = -1L;
@Id
private Integer id;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String username;
@Field(type = FieldType.Keyword)
private String password;
@Field(type = FieldType.Boolean)
private Boolean enabled = true;
@Field(type = FieldType.Boolean)
private Boolean locked = false;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String address;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String nickName;
// @Field(type = FieldType.Date, format = DateFormat.date_hour_minute_second)
// @JsonFormat(shape = JsonFormat.Shape.STRING, pattern ="yyyy-MM-dd'T'HH:mm:ss")
private Date createTime;
// @Field(type = FieldType.Date, format = DateFormat.date_hour_minute_second)
// @JsonFormat(shape = JsonFormat.Shape.STRING, pattern ="yyyy-MM-dd'T'HH:mm:ss")
private Date updateTime;
// getter/setter
}
实体类说明:
@Document注解: 标识映射到 Elasticsearch 文档上的领域对象。@Id注解: 标识文档的 id 。@Field注解: 标识字段,可以指定各字段的类型、分析器等,最终会体现在对应index的mappings上。类型如下:
public enum FieldType {
Auto, // 自动判断,默认值
Text, // 会进行分词
Keyword, // 不会进行分词
Long,
Integer,
Short,
Byte,
Double,
Float,
Half_Float,
Scaled_Float,
Date,
Date_Nanos,
Boolean,
Binary,
Integer_Range,
Float_Range,
Long_Range,
Double_Range,
Date_Range,
Ip_Range,
Object,
Nested, // 嵌套对象
Ip,
TokenCount,
Percolator,
Flattened,
Search_As_You_Type;
private FieldType() {
}
}
下面开始定义接口操作 Elasticsearch ,新增 EsUserRepository ,定义相关接口,如下:
public interface EsUserRepository extends ElasticsearchRepository<EsUser, Integer> {
// 方法定义规范:
// 1.按照 Spring Data 的规范,查询方法以 find/get/read 开头
// 2.涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性以首字母大写
// 3.支持属性的级联查询. 若当前类有符合条件的属性, 则优先使用, 而不使用级联属性. 若需要使用级联属性, 则属性之间使用 _ 进行连接
EsUser findByIdAndUsername(Integer id, String username);
Page<EsUser> findByIdGreaterThan(Integer id, Pageable pageable);
List<EsUser> findByIdLessThanOrUsernameContaining(Integer id, String username);
// 使用 @Query 注解可以用 Elasticsearch 的 DSL 语句进行查询
@Query("{\"bool\" : {\"must\" : {\"match\" : {\"address\" : \"?0\"}}}}")
Page<EsUser> findByAddress(String address, Pageable pageable);
}
接口类说明:
EsUserRepository接口继承自ElasticsearchRepository, ElasticsearchRepository 提供了一些基本的数据操作方法,例如:保存/更新/删除/列表查询/分页列表查询等。- 在
EsUserRepository接口中也可以自己声明相关的方法,只需要方法名称符合规范。在 Spring Data 中,只要按照既定的规范命名方法,Spring Data Elasticsearch 就知道你想干嘛,这样就不用写DSL语句了。相关规范参考下图:
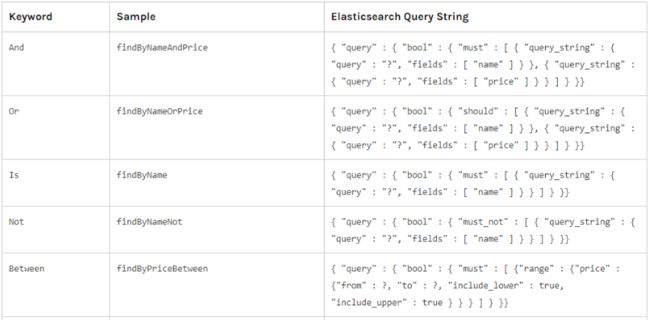
- 如果有特殊的查询,也可以自己定义方法名,使用
@Query注解通过自定义DSL语句来实现。
这时启动 Spring Boot 项目,会自动创建一个名为 user 的索引。
4 测试
最后在测试类中注入 esUserRepository 完成测试,如下:
@SpringBootTest
class SpringBootElasticsearchApplicationTests {
@Autowired
EsUserRepository esUserRepository;
// 用于自定义复杂查询
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Test
public void save() {
EsUser esUser = new EsUser();
esUser.setId(1);
esUser.setUsername("zhangsan");
esUser.setPassword("123456");
esUser.setAddress("浙江杭州");
esUser.setNickName("张三");
esUser.setCreateTime(new Date());
esUser.setUpdateTime(new Date());
EsUser esUserResult = esUserRepository.save(esUser);
System.out.println(esUserResult);
}
@Test
public void saveAll() {
List<EsUser> esUserList = new ArrayList<>();
for (int i = 2; i <= 11; i++) {
EsUser esUser = new EsUser();
esUser.setId(i);
esUser.setUsername("lisi" + i);
esUser.setPassword("123456");
esUser.setAddress("浙江宁波");
esUser.setNickName("李四" + i);
esUser.setCreateTime(new Date());
esUser.setUpdateTime(new Date());
esUserList.add(esUser);
}
Iterable<EsUser> list = esUserRepository.saveAll(esUserList);
System.out.println(list);
}
@Test
public void deleteById() {
esUserRepository.deleteById(5);
}
@Test
public void delete() {
EsUser esUser = new EsUser();
esUser.setId(6);
esUserRepository.delete(esUser);
}
@Test
public void deleteAll() {
esUserRepository.deleteAll();
}
@Test
public void findById() {
Optional<EsUser> esUser = esUserRepository.findById(1);
System.out.println(esUser.get());
}
@Test
public void findAllById() {
List<Integer> idList = new ArrayList<>();
idList.add(1);
idList.add(2);
Iterable<EsUser> list = esUserRepository.findAllById(idList);
System.out.println(list);
}
@Test
public void findAll() {
Iterable<EsUser> list = esUserRepository.findAll();
System.out.println(list);
}
@Test
public void findAllSort() {
Iterable<EsUser> list = esUserRepository.findAll(Sort.by(Sort.Direction.DESC, "id"));
System.out.println(list);
}
@Test
public void findAllPage() {
Pageable pageable = PageRequest.of(0, 2);
Page<EsUser> page = esUserRepository.findAll(pageable);
System.out.println("总记录数:" + page.getTotalElements());
System.out.println("当前页记录数:" + page.getNumberOfElements());
System.out.println("每页记录数:" + page.getSize());
System.out.println("总页数:" + page.getTotalPages());
System.out.println("查询结果:" + page.getContent());
System.out.println("当前页(从0开始计):" + page.getNumber());
System.out.println("是否为首页:" + page.isFirst());
System.out.println("是否为尾页:" + page.isLast());
}
/**
* more_like_this query
*/
@Test
public void searchSimilar() {
EsUser esUser = new EsUser();
esUser.setId(2);
Pageable pageable = PageRequest.of(0, 2);
Page<EsUser> page = esUserRepository.searchSimilar(esUser, new String[]{"address"}, pageable);
System.out.println("总记录数:" + page.getTotalElements());
System.out.println("当前页记录数:" + page.getNumberOfElements());
System.out.println("每页记录数:" + page.getSize());
System.out.println("总页数:" + page.getTotalPages());
System.out.println("查询结果:" + page.getContent());
System.out.println("当前页(从0开始计):" + page.getNumber());
System.out.println("是否为首页:" + page.isFirst());
System.out.println("是否为尾页:" + page.isLast());
}
@Test
public void existsById() {
boolean b = esUserRepository.existsById(1);
System.out.println(b);
}
@Test
public void count() {
long count = esUserRepository.count();
System.out.println(count);
}
/*=============== 自定义简单查询-开始 ===============*/
@Test
public void findByIdAndUsername() {
EsUser esUser = esUserRepository.findByIdAndUsername(2, "lisi");
System.out.println(esUser);
}
@Test
public void findByIdGreaterThan() {
Pageable pageable = PageRequest.of(0, 2);
Page<EsUser> page = esUserRepository.findByIdGreaterThan(4, pageable);
System.out.println("总记录数:" + page.getTotalElements());
System.out.println("当前页记录数:" + page.getNumberOfElements());
System.out.println("每页记录数:" + page.getSize());
System.out.println("总页数:" + page.getTotalPages());
System.out.println("查询结果:" + page.getContent());
System.out.println("当前页(从0开始计):" + page.getNumber());
System.out.println("是否为首页:" + page.isFirst());
System.out.println("是否为尾页:" + page.isLast());
}
@Test
public void findByIdLessThanOrUsernameContaining() {
List<EsUser> list = esUserRepository.findByIdLessThanOrUsernameContaining(10, "si");
System.out.println(list);
}
@Test
public void findByAddress() {
Pageable pageable = PageRequest.of(0, 2);
Page<EsUser> page = esUserRepository.findByAddress("宁波", pageable);
System.out.println("总记录数:" + page.getTotalElements());
System.out.println("当前页记录数:" + page.getNumberOfElements());
System.out.println("每页记录数:" + page.getSize());
System.out.println("总页数:" + page.getTotalPages());
System.out.println("查询结果:" + page.getContent());
System.out.println("当前页(从0开始计):" + page.getNumber());
System.out.println("是否为首页:" + page.isFirst());
System.out.println("是否为尾页:" + page.isLast());
}
/*=============== 自定义简单查询-结束 ===============*/
/*=============== 自定义复杂查询(ElasticsearchRestTemplate)-开始 ===============*/
/**
* 根据关键字搜索用户名或昵称,再增加过滤、聚合、排序、分页
*/
@Test
public void search() {
Boolean enabled = true;
Boolean locked = false;
String keyword = "四";
Integer sort = 1;
PageImpl<EsUser> page = null;
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
// 搜索
if (StringUtils.isEmpty(keyword)) {
nativeSearchQueryBuilder.withQuery(QueryBuilders.matchAllQuery());
} else {
// nativeSearchQueryBuilder.withQuery(QueryBuilders.multiMatchQuery(keyword, "username", "nickName"));
List<FunctionScoreQueryBuilder.FilterFunctionBuilder> filterFunctionBuilders = new ArrayList<>();
filterFunctionBuilders.add(new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchQuery("username", keyword),
ScoreFunctionBuilders.weightFactorFunction(10)));
filterFunctionBuilders.add(new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchQuery("nickName", keyword),
ScoreFunctionBuilders.weightFactorFunction(2)));
FunctionScoreQueryBuilder.FilterFunctionBuilder[] builders = new FunctionScoreQueryBuilder.FilterFunctionBuilder[filterFunctionBuilders.size()];
filterFunctionBuilders.toArray(builders);
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(builders)
.scoreMode(FunctionScoreQuery.ScoreMode.SUM)
.setMinScore(2);
nativeSearchQueryBuilder.withQuery(functionScoreQueryBuilder);
}
// 过滤
if (enabled != null || locked != null) {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (enabled != null) {
boolQueryBuilder.must(QueryBuilders.termQuery("enabled", enabled));
}
if (locked != null) {
boolQueryBuilder.must(QueryBuilders.termQuery("locked", locked));
}
nativeSearchQueryBuilder.withFilter(boolQueryBuilder);
}
// 聚合,对应的字段一般设置为 FieldType.Keyword
// nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("passwords").field("password"));
// nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms("addresses").field("address"));
// 排序
if (sort == 1) {
// 按id降序
nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort("id").order(SortOrder.DESC));
} else if (sort == 2) {
// 按更新时间降序
nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort("updateTime").order(SortOrder.DESC));
} else if (sort == 3) {
// 按地址升序
nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort("address").order(SortOrder.ASC));
} else {
// 按相关度
nativeSearchQueryBuilder.withSort(SortBuilders.scoreSort().order(SortOrder.DESC));
}
// 分页
Pageable pageable = PageRequest.of(0, 2);
nativeSearchQueryBuilder.withPageable(pageable);
NativeSearchQuery searchQuery = nativeSearchQueryBuilder.build();
System.out.println("DSL: " + searchQuery.getQuery().toString());
SearchHits<EsUser> searchHits = elasticsearchRestTemplate.search(searchQuery, EsUser.class);
if (searchHits.getTotalHits() <= 0) {
page = new PageImpl<>(Collections.emptyList(), pageable, 0);
}
List<EsUser> esUserList = searchHits.stream().map(SearchHit::getContent).collect(Collectors.toList());
page = new PageImpl<>(esUserList, pageable, searchHits.getTotalHits());
System.out.println("总记录数:" + page.getTotalElements());
System.out.println("当前页记录数:" + page.getNumberOfElements());
System.out.println("每页记录数:" + page.getSize());
System.out.println("总页数:" + page.getTotalPages());
System.out.println("查询结果:" + page.getContent());
System.out.println("当前页(从0开始计):" + page.getNumber());
System.out.println("是否为首页:" + page.isFirst());
System.out.println("是否为尾页:" + page.isLast());
}
/*=============== 自定义复杂查询(ElasticsearchRestTemplate)-结束 ===============*/
}
- Spring Boot 教程合集(微信左下方阅读全文可直达)。
- Spring Boot 教程合集示例代码:https://github.com/cxy35/spring-boot-samples
- 本文示例代码:https://github.com/cxy35/spring-boot-samples/tree/master/spring-boot-dao/spring-boot-elasticsearch
扫码关注微信公众号 程序员35 ,获取最新技术干货,畅聊 #程序员的35,35的程序员# 。独立站点:https://cxy35.com
