机器学习——XGboost原理及python实现
XGboost原理及实战
- 原理
-
- 1 xgb是什么
-
- 1.1 CART 回归树
- 1.2 应用
- 1.3 目标函数
- 2 xgb数学推导
-
- 2.1 回归树
- 2.2 加法模型
- 2.3 前向分步算法
- 2.4 目标函数
- 2.5 正则项处理
- 2.6 损失函数的处理
- 3 确定树的结构
-
- 3.1 精确贪心法
- 4 具体算法流程:
- 5 优化思路:
-
- 5.1 压缩特征数——列采样
- 5.2 压缩候选切分点数量——特征值分桶
- 6系统设计
- 实现-python
-
-
- 1.库
- 2.数据加载
-
- 2.1读取CSV
- 2.2 拆分训练集和测试集
- 3.建模+训练
-
- 3.1 XGBClassifier参数
- 4模型保存
- 5模型读取与预测
- 6模型效果验证
-
原理
1 xgb是什么
XGBoost 算法是boost 集成算法中的一种,Boosting 算法的思想是将许多弱分类器集成在一起形成一个强分类器。XGBoost 是一种提升树模型,是将许多树模型集成在一起,形成强分类器。XGBoost 中使用的弱分类器为CART (classification and regression tree)回归树。
xgboost并没有提出一种新的机器学习算法,而是基于现有的GBDT/lambdaMART等tree boosting算法在系统及算法层面(主要是系统层面)进行了改进;
- 系统层面改进点包括:
- 带权重的分位点分割算法(weighted quantile sketch)
- 稀疏特征的处理(sparsity-aware splitting)
- 缓存(cache-aware access)
- out-of-core computation
- 特征并行
- 基于rabit的分布式训练等
这些改进使得xgboost无论是在单机训练还是分布式训练上的耗时都比pGBRT/scikit-learn/spark MLLib/R gbm等有至少几倍的提升;
- 算法层面的改进主要包括:
1. L1/L2正则化
2. 目标函数二阶导的应用等;
1.1 CART 回归树
CART 回归树是一种二叉树,而可用于分类也可用于回归,其每一个节点只对是否进行判断,通过自上而下的分裂不断对样本集合的特征进行分裂。XGBoost 是通过不断添加CART ,不断使特征进行分裂完成CART 若分类器的集成。每一颗新的树的学习任务是去拟合原有树的拟合残差,使得生成的树的预测结果与真实值更加接近,可以认为XGBoost 的计算结果为多颗二叉树的计算结果加和。
1.2 应用
1.3 目标函数
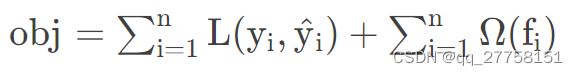
可推导为:

2 xgb数学推导
2.1 回归树
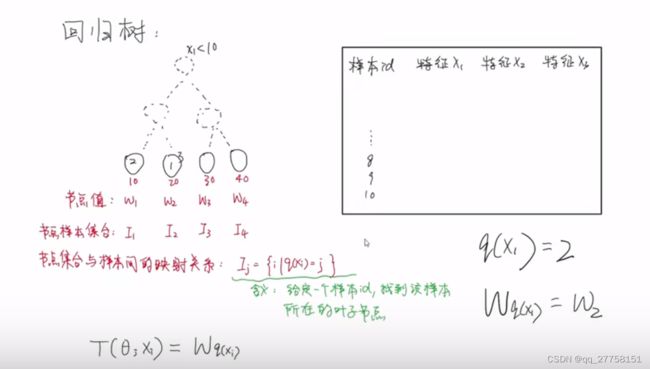
每个样本根据节点值走到叶子节点。
节点集合与样本间测映射关系为Ij={i|q(xi)=j}
即q(Xi)=j。j表示第几个叶子节点
那就可以给Wq(xi)=Wj获取样本的值
所以,最终叶子结点的值的公式表达为:T(θjXi)=Wq(xi)
注意,不能表达结构,只能表达叶子节点的值
2.2 加法模型
由T个基学习器累加起来,基学习器即回归树
i是第i个样本,Xi是特征
这里的T是树的棵数

2.3 前向分步算法
加法模型和前向分步算法在adaboost里介绍了
采用前向分布法逐步优化每一个基学习器
前向分布算法是采用贪心策略,逐棵树逐棵树的优化
假设当前需要优化的是第t棵树,表达为

2.4 目标函数
定义好模型后,写目标函数。把问题转化为求目标函数最优解问题。求出基学习器里的参数。
将N个损失函数累加起来,再加上正则项Ω,Ω是树的复杂度
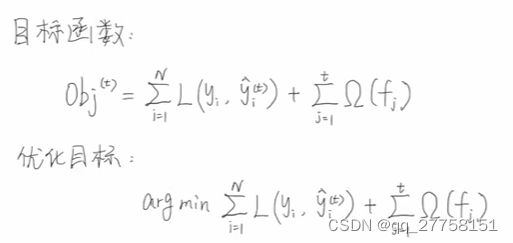
优化目标就是arg最小
前t-1棵树已经使定值,第t棵树需要确定的就是叶子节点的值W。
m是叶子节点的个数
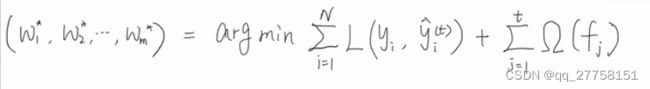
2.5 正则项处理
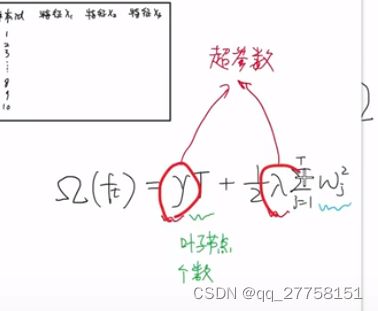
Ω(ft)=γT+1/2λ∑j=1 Twj^2
T:叶子结点个数
γ,λ:超参数,可以控制惩罚的力度
∑j=1 Twj^2:叶子节点的值平方再求和
- 树越深就越容易出现过拟合,即节点数越多,所以要进行惩罚,惩罚的力度由γ控制
- 如果节点值w比较大的话,就代表这棵回归树再所有树的占比比较大。比如5棵回归树,80%的值由一棵树贡献,那过拟合的风险是比较高的。所以要进行惩罚,惩罚的力度由λ控制
- 那么优化目标就为
前t-1棵树的正则项是常数,在优化过程中没用,可以去掉

- 代入Ω(ft),得到

当前要优化的正则项部分,只跟当前优化的这棵树的w,T有关
2.6 损失函数的处理
回顾回归树的工作流程:
5个样本,2个特征,真实值y
数据进来后,每一个样本都会被划分到属于它自己的叶子节点,得到预测值


假定损失是平方误差损失
损失和L1+L2+…+L5
-
将求损失最小值转化为求每个叶子节点的损失的最小值

比如L节点1=L3+L5
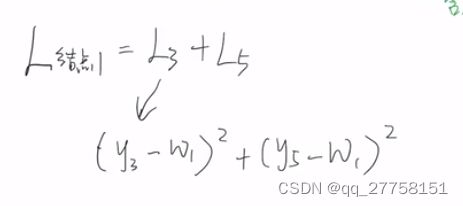
求最小值,一元二次 -
因此,obj可以从按样本方式遍历转化为按照叶子节点方式遍历
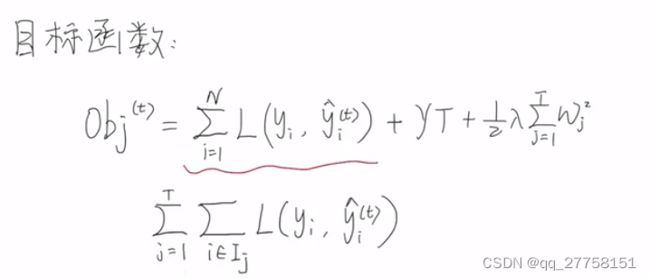
和后面的正则项合并,得到

(这里写错了,中括号应该包括到最后) -
泰勒二阶展开:
损失函数没法提前给定,找到方法可以无视损失函数继续推导
泰勒二阶展开公式
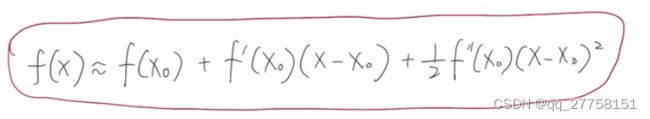
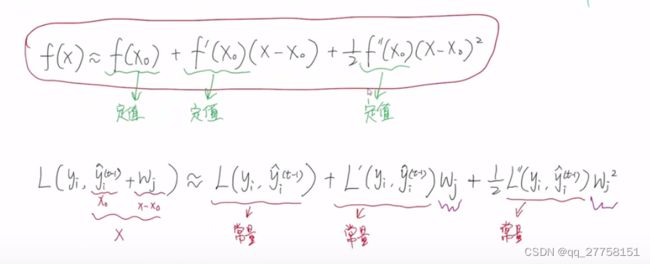
-
做优化,去掉常量部分,用gi和hi表示损失函数的一阶梯度和二阶梯度:

代入obj,合并,得到

gi,hi是常量,样本拿到就可以算出来, -
目标函数就变为
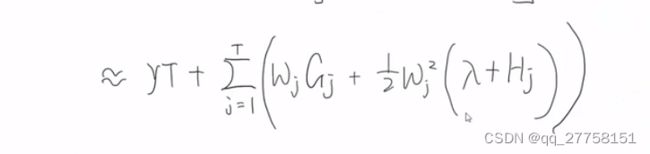
-
最优wj与最优obj:


代入obj,得到最小值

- 所以,拿到样本,先计算gi,hi,再计算G,H。就可以算出每个叶子节点的值Wj,最小损失也可以计算出来。

3 确定树的结构
前面求解都是假定树的结构是确定的,当树的结构不一样时得到的w和obj不一样。那么哪种划分方式时最优的呢,找obj最小的那颗树。
穷举法:
穷举所有可能性,不可行
3.1 精确贪心法
分步,每次只关注一个节点。
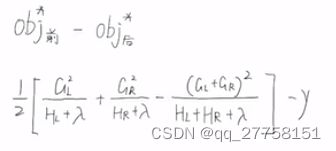
对于一个节点,计算分裂前和分裂后的obj.
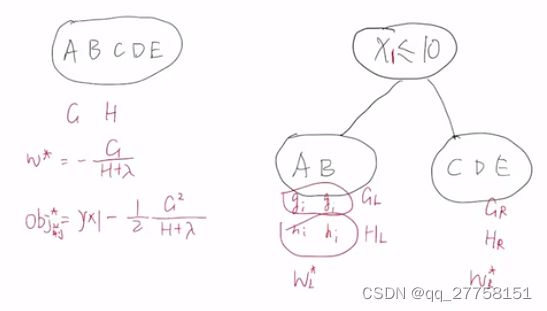
- 由不同的分裂方式,如何选择——gain
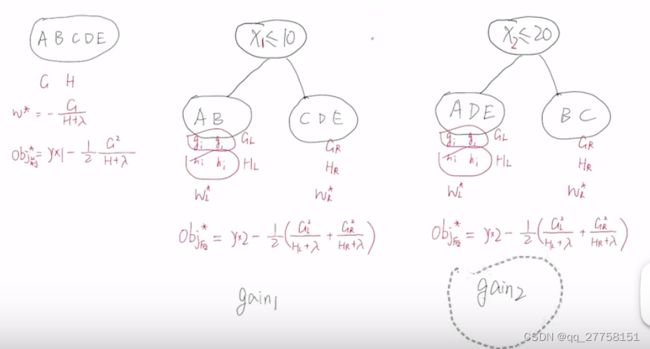
在XGB中,

gain越大,划分越好。
计算所有的划分的gain,选择最大的就是这个节点的最优划分。
每一步取最大,就是贪婪。
- 不再分裂的条件:
- 如果最大的gain都<0或者一个很小的数,就没必要划分了。
- 叶子只有一个样本
- 限制数的层级、叶子结点数防止过拟合

4 具体算法流程:

I:当前节点需要分裂的样本集合
d:特征维度,即有多少个特征
- gain初始化为0
- 要计算当前的G,H
- 遍历特征,k=1到d:
- 初始化GL,HL=0
- 对样本I根据当前特征值大小排序,遍历每个划分点计算GL,HL,G-GL,H-HL计算出GR,HR。计算gain。
- 搜索gain最大的树,得到当前特征的最优划分。

当特征值多、特征数多的时候耗时久。
跟两层循环和排序的次数有关。
5 优化思路:
1.减少特征
2.减少特征值
(有选择的采样,而不是全部用到)
牺牲精确性提升速率——近似算法
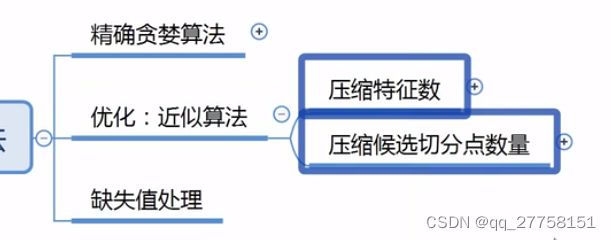
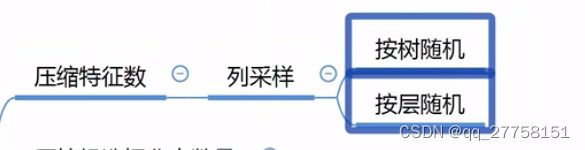
5.1 压缩特征数——列采样
按树随机:在根节点分裂之前,选好特征。即整棵树都只有选好的特征。
按层随机:每层都重新选择特征。
5.2 压缩候选切分点数量——特征值分桶
不是随机的,分桶。比如平均分:
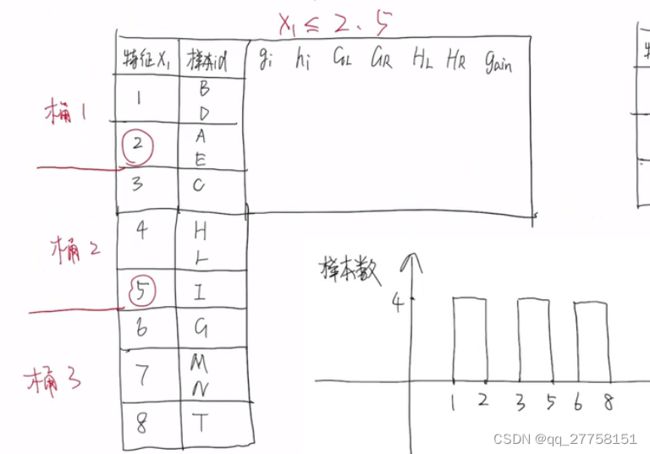
但是样本肯定是分步不均的,因此不能平均分桶。
采用加权分位法分桶。

那么h就可以看做样本的权值替代。那么分桶就应该按权值分
样本按27算,分3桶,每桶9

在实际中,会对权值hi做归一化,归到[0,1],给定ε,规定划分的宽度。


一般不会有超参数设置分多少桶,是设置ε的值。

全局策略:
x1最开始进行一次分桶,只要使用x1就也是用这个分桶值
特点:固定,如果选的值得数量少可能限制树的生长。所以采样个数多点效果才能好。
局部策略:
下一节点的分桶值和上一节点的分桶值不一样
超参eps就是特征采样分桶宽度。
缺失值处理:

实际数据集有很多缺失值,
将全部缺失样本放到左子树计算gain,再全部放到右子树计算gain。取大的放。
在排序循环的时候缺失值不参与
学习率shinkage:

单个基学习器学习的太精确了,会过拟合,加步长让它收缩。

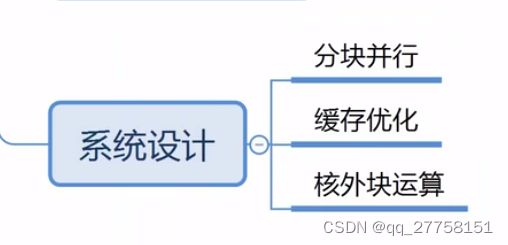
6系统设计
核外块运算
当数据集非常大时,是不能一下子全部加载到内存中的。假设内存一次只能加载两个样本,剩下的数据就会分块存储到磁盘当中,最好存到不同的磁盘中,这样能提高吞吐率。在数据处理的时候,内存就腾出来了,就可以将磁盘的数据读出来。但内存处理的速度比磁盘读取的效率快。XGB单独开了个线程读取数据。内存处理数据的同时读取数据。块存储的采取压缩算法,按列压缩,读取时先解压。块压缩,块拆分。
分块并行:
遍历是最耗时的是排序操作。计算gain的排序是互不影响的,最外层的关于特征的循环是不影响的。思路:去掉最外层特征循环。
在基学习器学习之前对特征进行排序,排好序的数据保存在特定的数据结构Bock中,block对数据是按列存储的,存储索引值和特征值。数据以csc格式存储。

牺牲空间换时间。只需要排序一次。
计算最优划分点时,不同特征可以并行处理,只需要线性扫描一遍block
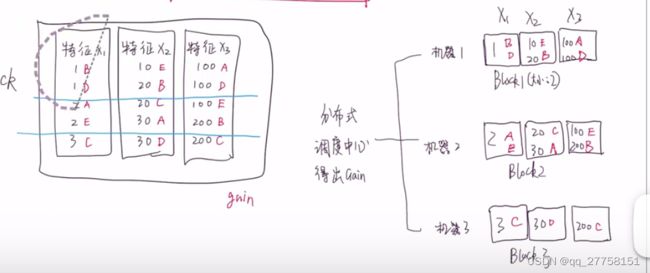
分布式并行
切块放到不同的机器上面,结果放到分布式调度中心,得出gain。
缓存优化
来源:Block数据结构导致缓存命中率低。
程序运行的时候会从磁盘中加载到内存中,同时把程序运行需要的数据加载进来,程序运算时,CPU从内存中获取数据进行计算,计算完把结果写进内存。但是,CPU运算速度快,读写速度慢。

所以,搞一个中转站,缓存。顺序拿一批数据放到缓存,计算,结果给缓存。内存从缓存回收。一批处理完,从内存再读一批。
要处理的数据在缓存就是缓存命中,不在就是缓存未命中。
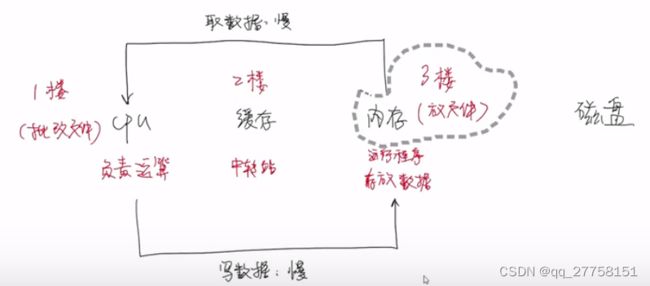
样本存储是按id存储,Block是按特征,不连续的。
导致缓存命中率低,读写速度慢。

优化:给每个特征分配一个buffer。buffer也是一个存储空间,存储样本对应的gi,hi。这样访问就是连续的了。只需要构建buffer的时候进行一次不连续的访问就好。

总结梳理:
加载数据,采用核外块运算
对每一个特征预排序。
排序好后构建Block,分配对应的buffer。
看是否采用列采样和分位数算法
确定最优划分点
缺失值处理
问题思考:
1.为什么树模型不适合使用梯度下降法做优化
按照常规机器学习的处理,可以用梯度下降优化L的参数,经过多次的迭代训练得到参数w。但是树模型不适合使用梯度下降法做优化,因为树模型都是阶跃的,是不连续的。不能求导,求梯度是没有意义的。
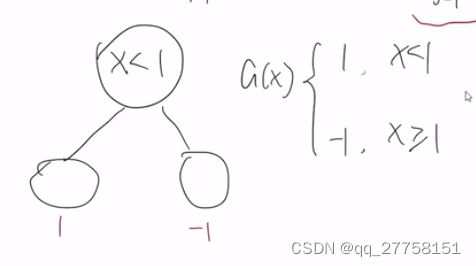
实现-python
读入数据–>设置参数–>训练模型–>效果检测,其中读入数据流程中XGBoost模块中提供了一个xgb.DMatrix()格式数据,可以读入CSV数据等二进制数据,但是也可以直接使用numpy.array数据格式放入模型中进行训练,其他流程实现较为简单,可以结合sklearn实现,因此xgboost建立过程中需要了解的为参数设置
1.库
import xgboost
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn import metrics
from xgboost import plot_importance
from matplotlib import pyplot
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score
(1)XGBoost库
Python中,可直接通过“pip install xgboost”安装XGBoost库,基分类器支持决策树和线性分类器。
(2)pandas数据的读入
(3)sklearn数据的处理
(4)matplotlib图像绘制。
-i https://pypi.tuna.tsinghua.edu.cn/simple
2.数据加载
将数据导入Python,并对数据根据7:3的比例划分为训练集和测试集,并对label进行处理,超过6分为1,否则为0。
2.1读取CSV
- pd.read_csv()
sep:读取csv文件时指定的分隔符,默认为逗号。
redwine=pd.read_csv('./data/winequality-red.csv',sep=';')
2.2 拆分训练集和测试集
train_test_split()
test_size: 测试集大小
random_state: 设置随机数种子,0或不填则每次划分结果不同
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.3, random_state=17)
3.建模+训练
有使用xgboost原生库进行和使用XGBClassifier进行训练两种方式。XGBClassifier()使用sklearn接口(推荐)
建模
num_round=100
bst=XGBClassifier(max_depth=6,learning_rate=0.5,n_estimators=num_round,objective='binary:logistic',verbosity=1)
训练
- 早停止调参–early_stopping_rounds(查看的是损失是否变化) 早停必须有一个验证集 -early_stopping_rounds--当多少次的效果差不多时停止 eval_metric :指定这个衡量的标准,我们选用的是loss。 eval_set--用来作为早期停止的验证集,一般我们放x_test和y_test verbose--如果为真,并且使用了一个验证集,则写下验证过程
eval_set = [(test_x,test_y)]
bst.fit(train_x,train_y,early_stopping_rounds=10,eval_metric=['error','logloss'],eval_set=eval_set)
3.1 XGBClassifier参数
max_depth 树的最大深度
learning_rate 步长
n_estimators 迭代次数silent=1 输出运行信息
subsample=0.8, # 每个决策树所用的子样本占总样本的比例(作用于样本)
colsample_bytree=0.8, 建立树时对特征随机采样的比例(作用于特征)典型值:0.5-1
objective=‘multi:softmax’, # 多分类
num_class=3,
nthread=4,
seed=27
min_child_weight=1, # 决定最小叶子节点样本权重和,如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束。
Booster参数:
1. eta[默认是0.3] 和GBM中的learning rate参数类似。[default=0.3]; range[0,1]通过减少每一步的权重,可以提高模型的鲁棒性。典型值0.01-0.2
2. min_child_weight[默认是1] 决定最小叶子节点样本权重和。当它的值较大时,可以避免模型学习到局部的特殊样本。但如果这个值过高,会导致欠拟合。这个参数需要用cv来调整
3. max_depth [默认是6] 树的最大深度,这个值也是用来避免过拟合的3-10
4. max_leaf_nodes 树上最大的节点或叶子的数量,可以代替max_depth的作用,应为如果生成的是二叉树,一个深度为n的树最多生成2n个叶子,如果定义了这个参数max_depth会被忽略
5. gamma[默认是0] 在节点分裂时,只有在分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。这个参数值越大,算法越保守。
6. max_delta_step[默认是0] 这参数限制每颗树权重改变的最大步长。如果是0意味着没有约束。如果是正值那么这个算法会更保守,通常不需要设置。
7. subsample[默认是1] 这个参数控制对于每棵树,随机采样的比例。减小这个参数的值算法会更加保守,避免过拟合。但是这个值设置的过小,它可能会导致欠拟合。典型值:0.5-1
8. colsample_bytree[默认是1] 用来控制每颗树随机采样的列数的占比每一列是一个特征0.5-1
9. colsample_bylevel[默认是1] 用来控制的每一级的每一次分裂,对列数的采样的占比。
10. lambda[默认是1] 权重的L2正则化项
11. alpha[默认是1] 权重的L1正则化项
12. scale_pos_weight[默认是1] 各类样本十分不平衡时,把这个参数设置为一个正数,可以使算法更快收敛。
通用参数
1. booster[默认是gbtree]
选择每次迭代的模型,有两种选择:gbtree基于树的模型、gbliner线性模型 or dart,其中gbtree与dart的应用效果较为一致,dglinear应用效果稍差
2. silent[默认是0]
当这个参数值为1的时候,静默模式开启,不会输出任何信息。一般这个参数保持默认的0,这样可以帮我们更好的理解模型。
3. nthread[默认值为最大可能的线程数]
这个参数用来进行多线程控制,应当输入系统的核数,如果你希望使用cpu全部的核,就不要输入这个参数,算法会自动检测。
4.verbosity [default=1]
训练中是否打印信息,0 (silent), 1 (warning), 2 (info), 3 (debug)
学习目标参数
1. objective[默认是reg:linear]
这个参数定义需要被最小化的损失函数。最常用的值有:binary:logistic二分类的逻辑回归,返回预测的概率非类别。multi:softmax使用softmax的多分类器,返回预测的类别。在这种情况下,你还要多设置一个参数:num_class类别数目。
2. eval_metric[默认值取决于objective参数的取之]
对于有效数据的度量方法。对于回归问题,默认值是rmse,对于分类问题,默认是error。典型值有:rmse均方根误差;mae平均绝对误差;logloss负对数似然函数值;error二分类错误率;merror多分类错误率;mlogloss多分类损失函数;auc曲线下面积。
3. seed[默认是0]
随机数的种子,设置它可以复现随机数据的结果,也可以用于调整参数。
4模型保存
bst.save_model('local_xgb.model')
5模型读取与预测
#模型读取
modelfile='local_xgb.model'
xgbst=xgboost.Booster({'nthread':8},model_file=modelfile)
#模型预测
# dtest= xgboost.DMatrix(data = test_x, label = test_y)
dtest= xgboost.DMatrix(data = test_x)#.predict()里必须是DMatrix格式
y_pred=c=xgbst.predict(dtest)
test_predictions=[round(value) for value in y_pred]
6模型效果验证
指标
acc:正确预测的正反例数 /总数 (查准率)
auc:AUC(Area Under Curve)被定义为ROC曲线下的面积(ROC的积分),通常大于0.5小于1。AUC值(面积)越大的分类器,性能越好
recall:正确预测的正例数 /实际正例总数 (查全率)
f1:精确率和召回率的调和值
precision:表现为预测出是正的里面有多少真正是正的。
roc:ROC曲线越接近左上角,该分类器的性能越好。而且一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting
#模型效果验证
test_accuracy = accuracy_score(test_y, test_predictions)
print("Test Accuracy: %.2f%%" % (test_accuracy * 100.0))
test_auc=metrics.roc_auc_score(test_y,y_pred)
print("auc:%.2f%%"%(test_auc*100.0))
test_recall=metrics.recall_score(test_y,test_predictions)
print("recall:%.2f%%"%(test_recall*100.0))
test_f1=metrics.f1_score(test_y,test_predictions)
print("f1:%.2f%%"%(test_f1*100.0))
test_precision=metrics.precision_score(test_y,test_predictions)
print("precision:%.2f%%"%(test_precision*100.0))
#ROC曲线
fpr,tpr,threshold=metrics.roc_curve(test_y,y_pred)
#lw是line width
pyplot.plot(fpr,tpr,color='blue',lw=2,label='ROC curve(area=%.2f%%)'%(test_auc*100.0))
#假正率为横坐标,真正率为纵坐标做曲线
pyplot.legend(loc="lower right")
pyplot.plot([0,1],[0,1],color='navy',lw=2,linestyle='--')
pyplot.xlabel('False Positive Rate')
pyplot.ylabel('True Positive Rate')
pyplot.title('ROC curve')
pyplot.show()