Socially-Aware Self-Supervised Tri-Training forRecommendation
The existing self-supervised learning (SSL) methods mainly conduct self-discrimination based contrastive learning, where a given node can just exploit the information from itself in another view. In contrast, Yu et al. proposed a socially-aware SSL framework to conduct neighbor-discrimination based contrastive learning, where a given node can further exploit the self-supervision signals from its neighbors.
Abstract:Self-supervised learning (SSL), which can automatically generate ground-truth samples from raw data(原始数据), holds vast potential to improve recommender systems. Most existing SSL-based methods perturb the raw data graph with uniform node/edge dropout to generate new data views and then conduct the self-discrimination based contrastive learning over different views to learn generalizable representations. (学习通用的表示) Under this scheme, only a bijective mapping is built between nodes in two different views, which means that the self-supervision signals from other nodes are being neglected. Due to the widely observed homophily in recommender systems, we argue that the supervisory signals from other nodes are also highly likely to benefit the representation learning for recommendation. To capture these signals, a general socially-aware SSL framework that integrates tri-training is proposed in this paper. ( 我们的框架首先通过用户的社交信息来增强用户的数据视图。然后在多视图编码的tri-training机制下,该框架在增强视图上构建三个图编码器(只有一个编码器用于推荐),并利用其他两个编码器生成的其他用户的自监督信号对每个编码器进行迭代更新。) Our framework first enhances the user's data view through the user's social information. Then, under the tri-training mechanism of multi-view coding, the framework builds three graph encoders on the enhanced view (only one encoder is used for recommendation), and uses the self-supervised signals of other users generated by the other two encoders for each Encoders are updated iteratively.
Introduction:The basic idea of SSL is to learn automatically generated supervisory signals from raw data, which is an antidote to the problem of data sparsity in recommender systems. SSL has great potential to improve the quality of recommendation systems. Graph contrast learning performs random enhancement by removing nodes/edges or random feature transformation/masking the original graph to create complementary views, and then maximize the consistency between representations learned from different views on the same node.( 图对比学习通过去除节点/边或随机特征变换/屏蔽原始图来执行随机增强以创建互补视图,然后最大化从同一节点上的不同视图学习的表示之间的一致性) Inspired by its effectiveness, a few studies then follow this training scheme and are devoted to transplanting it to recommendation. Most existing SSL-based methods conduct the self-discrimination based contrastive learning over the augmented views to learn generalizable representations against the variance in the raw data. Under this scheme, a bijective mapping is built between nodes in two different views, and a given node can just exploit information from itself in another view. Meanwhile, the other nodes are regarded as the negatives that are pushed apart from the given node in the latent space. Obviously, a number of nodes are false negatives which are similar to the given node due to the homophily, and can actually benefit representation learning in the scenario of recommendation if they are recognized as the positives. Conversely, roughly classifying them into the negatives could lead to a performance drop.( 在该方案下,在两个不同视图中的节点之间建立一个双射,一个给定的节点可以在另一个视图中从它本身挖掘信息。同时,将在潜在空间中的其他节点视为与给定节点被推开远离的负节点。一些节点是假负样本,由于同质性,它们与给定的节点相似,如果它们被识别为正样本,那么在推荐下,实际上可以有利于表示学习。相反,把它们粗略地归入负样本可能会导致性能下降。) So, this paper proposes a socially-aware SSL framework which combines the tri-training (multi-view co-training) with SSL. We exploit the triadic structures in the user-user and user-item interactions to augment two supplementary data views, and socially explain them as profiling users’ interests in expanding social circles and sharing desired items to friends, respectively.( 我们利用用户-用户和用户-物品交互中的三元结构来增加两个补充的数据视图,并将它们分别解释为用户对扩大社交圈和向朋友分享所需物品的兴趣。) Tri-training is a popular semi-supervised learning algorithm which exploits unlabeled data using three classifiers. In this work, we employ it to mine self-supervision signals from other users in recommender systems with the multi-view encoding.
we first build three asymmetric(非对称的) graph encoders over the three views, of which two are only for learning user representations and giving pseudo-labels(伪标签), and another one working on the user-item view also undertakes the task of generating recommendations. Then we dynamically perturb the social network and user-item interaction graph to create an unlabeled example set. (我们首先在三个视图上构建了三个非对称图编码器,其中两个仅用于学习用户表示和给出伪标签,另一个针对用户-项目视图完成生成推荐的任务。然后,我们动态地扰乱社交网络和用户-项目交互图,创建一个无标签的样本集。)
The major contributions of this paper are summarized as follows贡献:
• We propose a general socially-aware self-supervised tri-training framework for recommendation. By unifying the recommendation tasks and SSL tasks under this framework, the recommendation performance can be significantly improved.
• We propose to exploit positive self-supervision signals from other users and develop a neighbor-discrimination based contrastive learning method.(一种基于邻居识别的对比学习方法)
• We conduct extensive experiments on multiple real-world datasets to demonstrate the advantages of the proposed SSL framework and investigate the effectiveness of every module.
Related work:
Graph Neural Recommendation Models:
Because of the effectiveness in solving graph-related recommendation tasks, GNNs have been focused in the field of recommendation systems. Particularly, GCN, as the prevalent(主流的) formulation of GNNs which is a first-order approximation(一阶近似) of spectral graph convolutions, has driven a multitude of graph neural recommendation models like GCMC, NGCF, and LightGCN. The basic idea of these GCN-based models is to improve the embedding of the target node by aggregating the embeddings of neighbors, thereby using higher-order neighbors in the user-item graph.( 这些基于GCN的模型的基本思想是通过聚合邻居的嵌入来利用用户-项目图中的高阶嵌入来细化目标节点的嵌入。)
Self-Supervised Learning in RS:
Self-supervised learning (SSL) is an emerging paradigm to learn with the automatically generated ground-truth samples from the raw data.
Proposer framework:

In our framework, we use two graphs as the data sources, user-item interaction graph ![]() and social network
and social network ![]() . U = {
. U = {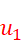 ,
,![]() , ...,
, ..., ![]() } (|U| = m) is the user nodes in both
} (|U| = m) is the user nodes in both ![]() and
and ![]() , and I = {
, and I = {![]() ,
,![]() , ...,
, ..., ![]() } (|I| = n) is the item nodes in
} (|I| = n) is the item nodes in ![]() , R ∈
, R ∈ is the binary matrix that represent user-item interactions in
is the binary matrix that represent user-item interactions in ![]() . , S ∈
. , S ∈ is the social adjacency matrix which is binary and symmetric because we work on undirected social networks with bidirectional relations. P ∈
is the social adjacency matrix which is binary and symmetric because we work on undirected social networks with bidirectional relations. P ∈ 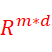 and Q ∈
and Q ∈ denote the learned final user and item embeddings for recommendation respectively.
denote the learned final user and item embeddings for recommendation respectively.
Tri-training is used to determine how to label the unlabeled examples to improve the classifiers. In contrast to the standard co-training algorithm which ideally requires two sufficient, redundant and conditionally independent views of the data samples to build two different classifiers, tri-training is easily applied by lifting the restrictions on training sets. It does not assume sufficient redundancy among the data attributes, and initializes three diverse classifiers upon three different data views generated via bootstrap sampling.
Data augmentation:
View augmentation: users and items have many similar counterparts in recommender systems, To capture the homophily for self-supervision, we exploit the user social relations for data augmentation as the social network is often known as a reflection of homophily (i.e., users who have similar preferences are more likely to become connected in the social network and vice versa). Because of inherent noisy of social relations, for accurate supplementary supervisory information, SEPT only utilizes the reliable social relations. In our framework, we can get two type of triangles: three
users socially connected with each other (e.g. u1,u2 and u4), two socially connected users with the same purchased item (e.g.u1,u2 and i1 ). The first one is socially explained as profiling users’ interests in expanding social circles, and another is illustrating users’ interests in sharing items with their friends, the mentioned two types of triangles can be efficiently extracted in the form of matrix multiplication(矩阵乘法).
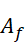 ∈
∈ 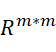 and
and ![]() ∈
∈ 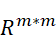 is the adjacency matrices of the users involved in these two types of triangular relations.( 是包含这两种三角关系的用户邻接矩阵) They can be calculated by:
is the adjacency matrices of the users involved in these two types of triangular relations.( 是包含这两种三角关系的用户邻接矩阵) They can be calculated by:
![]()
SS (RR⊤) accumulates the paths connecting two user via shared friends (items), and the Hadamard product⊙S makes these paths into triangles. (计算了通过共享好友(项目)连接两个用户的路径,而哈达玛积⊙将这些路径制成三角形。) The operation ⊙S ensures that the relations in ![]() and
and ![]() are subsets of the relations in S. Given
are subsets of the relations in S. Given ![]() and
and ![]() as the augmentation of S and R, we have three views that characterize users’ preferences from different perspectives and also provide us with a scenario to fuse tri-training and SSL.
as the augmentation of S and R, we have three views that characterize users’ preferences from different perspectives and also provide us with a scenario to fuse tri-training and SSL.
Unlabeled example set:
We need an unlabeled example set to conduct tri-training. We perturb the raw graph with edge dropout at a certain probability ρ to create a corrupted graph from where the learned user presentations are used as the unlabeled examples. ( 我们以概率对原始图进行边dropout,创建一个被干扰的图,从中学习的用户表示被用作无标签的样本。此过程可表述为:) 
在这个公式当中,![]() 和
和![]() 表示的是节点,
表示的是节点,![]() 和
和![]() 表示的是图
表示的是图![]() 和
和![]() 当中的边,m∈
当中的边,m∈ 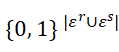 是边的掩码向量。在这里,我们同时干扰
是边的掩码向量。在这里,我们同时干扰![]() 和
和![]() ,而不是只干扰
,而不是只干扰![]() ,因为社交信息包含在上述两个增强视图中。对于集成的自监督信号,扰动连接图是必要的。
,因为社交信息包含在上述两个增强视图中。对于集成的自监督信号,扰动连接图是必要的。
SEPT: Self-Supervised Tri-Training:
框架:With the augmented views and the unlabeled example set, we follow the setting of tri-training to build three encoders. Architecturally, the proposed self-supervised training framework can be model-agnostic(模型无关的) so as to boost a multitude of graph neural recommendation models. We adopt LightGCN as the basic structure of the encoders because of its simplicity. The general form of encoders:

Here,H is the encoders, Z ∈  or Z ∈
or Z ∈  is the final representation of nodes, E is the initial node embeddings which are the bottom shared by the three encoders. V ∈ {R,
is the final representation of nodes, E is the initial node embeddings which are the bottom shared by the three encoders. V ∈ {R, ![]() ,
,![]() } is any of the three views. unlike the vanilla tri-training, SEPT is asymmetric. (与普通的tri-training不同,SEPT是不对称的)
} is any of the three views. unlike the vanilla tri-training, SEPT is asymmetric. (与普通的tri-training不同,SEPT是不对称的) ![]() and
and ![]() work on the friend view and sharing view, both of them only work for learning user representations through graph convolution and giving pseudo-labels. Meanwhile,
work on the friend view and sharing view, both of them only work for learning user representations through graph convolution and giving pseudo-labels. Meanwhile, ![]() works on the preference view also undertakes the task of generating recommendations and thus learns both user and item representations.(这里
works on the preference view also undertakes the task of generating recommendations and thus learns both user and item representations.(这里![]() and
and![]() 具有相同的结构,是辅助编码器,而
具有相同的结构,是辅助编码器,而![]() 是主编码器)
是主编码器)
构建监督信号:By performing graph convolution over the three views, the encoders learn three groups of user representations. As each view reflects a different aspect of the user preference, it is natural to seek supervisory information from the other two views to improve the encoder of the current view. Given a user, we predict its semantically positive examples in the unlabeled example set using the user representations from the other two views. Taking user u in the preference view as an instance, the labeling is formulated as: (给定一个用户,我们使用来自其他两个视图的用户表示来预测它在无标签样本集中的语义上的正样本。以偏好视图中的用户为例子,表述为:)

Here,ϕ is the cosine operation,![]() and
and ![]() are the representations of user u learned by
are the representations of user u learned by ![]() and
and ![]() ,
, ![]() is the representations of users in the unlabeled example set obtained through graph convolution, and
is the representations of users in the unlabeled example set obtained through graph convolution, and ![]() and
and ![]() are the predicted probability of each user being the semantically positive example of user u in the corresponding views.( 用户在相应视图中为用户的语义正样本的预测概率。) Under the scheme of tri-training, to avoid noisy examples, only when both
are the predicted probability of each user being the semantically positive example of user u in the corresponding views.( 用户在相应视图中为用户的语义正样本的预测概率。) Under the scheme of tri-training, to avoid noisy examples, only when both ![]() and
and ![]() agree on the labeling of a user being the positive sample, and then the user can be labeled for
agree on the labeling of a user being the positive sample, and then the user can be labeled for![]() . (在 tri-training方案下,为了避免噪声样本,只有和都同意将用户标记为正样本,才能在将用户进行标记。)
. (在 tri-training方案下,为了避免噪声样本,只有和都同意将用户标记为正样本,才能在将用户进行标记。)

根据这些概率,我们可以选择可信度最高的个正样本。select K positive samples with the highest confidence

对比学习:通过生成的伪标签,我们开发了邻居识别对比学习方法来实现SEPT中的自监督。
The idea of the neighbor discrimination is that, given a certain user in the current view, the positive pseudo-labels semantically represent his neighbors or potential neighbors in the other two views, then we should also bring these positive pairs together in the current view due to the homophily across different views. And this can be achieved through the neighbor-discrimination contrastive learning.
(neighbor discrimination的想法是,给定一个特定的用户在当前视图中,积极pseudo-labels语义表示他的邻居或潜在的邻居在另外两个视图,那么我们也应该把这些积极对在当前视图由于同质性在不同的观点。而这可以通过邻居辨别对比学习来实现。)

the discriminator function that takes two vectors as the input and then scores the agreement between them, and τ is the temperature to amplify the effect of discrimination. Compared with the self-discrimination, the neighbor-discrimination leverages the supervisory signals from the other users. When only one positive example is used and if the user itself in ![]() has the highest confidence in
has the highest confidence in ![]() , the neighbor-discrimination degenerates(退化) to the self-discrimination.
, the neighbor-discrimination degenerates(退化) to the self-discrimination.
优化:The learning of SEPT consists of two tasks: recommendation and the neighbor-discrimination based contrastive learning.
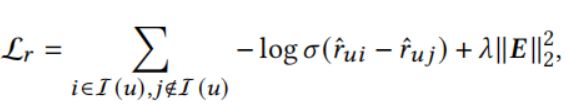
Here, I(u) is the item set that user u has interacted with,![]() =
=![]() , P and Q are obtained by splitting
, P and Q are obtained by splitting![]() , and λ is the coefficient controlling the
, and λ is the coefficient controlling the![]() regularization. The overall objective of the joint learning is defined as:
regularization. The overall objective of the joint learning is defined as:

whereβ is a hyper-parameter used to control the magnitude of the self-supervised tri-training.

SEPT的总体过程
Experimental results:
Under all the different layer settings, SEPT can significantly boost LightGCN. This can be an evidence that demonstrates the effectiveness of self-supervised learning. Besides, although both LightGCN and SEPT suffer the over-smoothed problem when the layer number is 3, SEPT can still outperform Light-GCN. We think the possible reason is that contrastive learning can, to some degree, alleviate the over-smooth problem because the dynamically generated unlabeled examples provide sufficient data variance.