【NLP】第7章 使用 GPT-3 引擎的Suprahuman Transformers的崛起
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
2020 年,布朗等人。(2020) 描述了 OpenAI GPT-3 模型的训练,该模型包含 1750 亿个参数,这些参数使用巨大的数据集学习,例如从 Common Crawl 数据中提取的 4000 亿字节对编码的令牌。OpenAI 在具有 285,00 个 CPU 和 10,000 个 GPU 的 Microsoft Azure 超级计算机上运行训练。
OpenAI 的 GPT-3 引擎及其超级计算机的机器智能领导了Brown等人。(2020)到零样本实验。这个想法是使用经过训练的模型来处理下游任务,而无需进一步训练参数。目标是让经过训练的模型使用 API 直接进入多任务生产,该 API 甚至可以执行未经训练的任务。
超人云AI引擎时代诞生了。OpenAI 的 API 不需要高级软件技能或 AI 知识。你可能想知道我为什么用“超人”这个词。您会发现 GPT-3 引擎在许多情况下可以像人类一样执行许多任务。目前,必须了解 GPT 模型是如何构建和运行的,才能体会到它的魔力。
本章将首先研究 Transformer 模型的架构和大小的演变。我们将研究使用训练有素的 Transformer 模型的零样本挑战,而对下游任务的模型参数几乎没有微调。我们将探索 GPT 变压器模型的创新架构。OpenAI 提供了经过特殊训练的模型版本,称为引擎。
我们将在来自 OpenAI 存储库的 TensorFlow 中使用 345M 参数 GPT-2 转换器。我们必须亲自动手才能理解 GPT 模型。我们将与模型交互以生成带有一般条件句的文本完成。
我们将继续使用 117M 参数定制的 GPT-2 模型。我们将在第 4 章“从头开始预Kant训练 RoBERTa 模型”中对用于训练 RoBERTa 模型的高级概念数据集进行标记。
然后,本章将探讨如何使用 GPT-3 引擎,该引擎不需要数据科学家、人工专家,甚至是经验丰富的开发人员即可开始。然而,这并不意味着未来不需要数据科学家或人工智能专家。
我们将看到 GPT-3 引擎有时确实需要微调。我们将运行一个 Google Colab 笔记本来微调 GPT-3 Ada 引擎。
本章将以工业 4.0 人工智能专家的新思维和技能组合结束。
在本章结束时,您将了解如何构建 GPT 模型以及如何使用无缝 GPT-3 API。您将了解工业 4.0 人工智能专家在 2020 年代可以完成的令人满意的任务!
本章涵盖以下主题:
- GPT-3 模型入门
- OpenAI GPT 模型的架构
- 定义零发射变压器模型
- 从少镜头到单镜头的路径
- 构建一个接近人类的 GPT-2 文本完成模型
- 实现一个 345M 参数模型并运行它
- 使用标准模型与 GPT-2 交互
- 训练语言建模 GPT-2 117M 参数模型
- 导入自定义的特定数据集
- 编码自定义数据集
- 调节模型
- 为特定的文本完成任务调整 GPT-2 模型
- 微调 GPT-3 模型
- 工业 4.0 人工智能专家的角色
让我们从探索 GPT-3 变压器模型开始我们的旅程。
具有 GPT-3 变压器模型的超人 NLP
GPT-3 建立在 GPT-2 架构之上。但是,经过充分训练的 GPT-3 变压器是基础模型。基础模型可以完成许多未经训练的任务。GPT-3 完成应用所有 NLP 任务,甚至编程任务。
GPT-3 是为数不多的完全训练有资格作为基础模型的变压器模型之一。GPT-3 无疑会带来更强大的 OpenAI 模型。谷歌将生产超出他们在超级计算机上训练的谷歌 BERT 版本的基础模型。基础模型代表了一种新的人工智能思维方式。
公司很快就会意识到他们不需要数据科学家或 AI 专家来使用 OpenAI 提供的 API 来启动 NLP 项目。
为什么要打扰任何其他工具?OpenAI API 可用于访问在世界上最强大的超级计算机之一上训练的最高效的变压器模型之一。
如果存在只有财力雄厚和世界上最好的研究团队才能设计的 API(例如 Google 或 OpenAI),为什么还要开发工具、下载库或使用任何其他工具?
这些问题的答案很简单。启动 GPT-3 发动机很容易,就像启动一级方程式或印地 500 赛车一样。没问题。但是,如果没有几个月的训练,想要驾驶这样的汽车几乎是不可能的!GPT-3 引擎是强大的人工智能赛车。您只需单击几下即可让它们运行。然而,掌握它们令人难以置信的马力需要您从本书开始到现在所获得的知识,以及您将在接下来的章节中发现的内容!
我们首先需要了解 GPT 模型的架构,以了解开发人员、AI 专家和数据科学家在超人类 NLP 模型时代的位置。
OpenAI GPT 变压器模型的架构
变形金刚从 2017 年底到 2020 年上半年,在不到三年的时间里,从训练到微调,最后到零样本模型。零样本 GPT-3 变压器模型不需要微调。训练好的模型参数不会针对下游的多任务进行更新,这为 NLP/NLU 任务开启了一个新纪元。
在本节中,我们将首先学习关于设计 GPT 模型的 OpenAI 团队的动机。我们将从微调零样本模型开始。然后我们将看到如何调节转换器模型以生成令人兴奋的文本完成。最后,我们将探索 GPT 模型的架构。
我们将首先介绍 OpenAI 团队的创建过程。
十亿参数Transformer模型的兴起
变压器的速度从为 NLP 任务训练的小型模型到几乎不需要微调的模型是惊人的。
瓦斯瓦尼等人。(2017) 推出了超越 CNN 的 Transformer和关于 BLEU 任务的 RNN。拉德福德等人。(2018) 引入了生成式预训练( GPT ) 模型,该模型可以在下游执行微调任务。德夫林等人。(2019) 完善了 BERT 模型的微调。拉德福德等人。(2019 年)在 GPT-2 模型上走得更远。
布朗等人。(2020) 为不需要微调的变压器定义了 GPT-3 零样本方法!
同时,王等人。(2019) 创建了 GLUE 来对 NLP 模型进行基准测试。但是变压器模型发展得如此之快,以至于它们超过了人类的基线!
王等人。(2019, 2020) 迅速创建了 SuperGLUE,将人类基线设置得更高,并使 NLU/NLP 任务更具挑战性。变形金刚发展迅速,在撰写本文时,有些变形金刚在 SuperGLUE 排行榜上已经超过了人类基线。
这怎么会发生得这么快?
我们将着眼于模型的大小这一方面,以了解这种演变是如何发生的。
变压器模型尺寸不断增加
仅从 2017 年到 2020 年,参数数量从原来 Transformer 模型中的 65M 参数增加到 GPT-3 模型中的 175B 参数,如表 7.1所示:
| Transformer Model |
Paper |
Parameters |
| Transformer Base |
Vaswani et al. (2017) |
65M |
| Transformer Big |
Vaswani et al. (2017) |
213M |
| BERT-Base |
Devlin et al. (2019) |
110M |
| BERT-Large |
Devlin et al. (2019) |
340M |
| GPT-2 |
Radford et al. (2019) |
117M |
| GPT-2 |
Radford et al. (2019) |
345M |
| GPT-2 |
Radford et al. (2019) |
1.5B |
| GPT-3 |
Brown et al. (2020) |
175B |
表 7.1仅包含在那段时间内设计的主要模型。
发布日期在模型实际设计日期之后。此外,作者还更新了论文。例如,一旦最初的 Transformer 启动了市场,Google Brain and Research、OpenAI 和 Facebook AI 就出现了变形金刚,它们都并行生产了新模型。
此外,一些 GPT-2 模型比较小的 GPT-3 模型更大。例如,GPT-3 Small 模型包含 125M 参数,小于 345M 参数的 GPT-2 模型。
架构的大小同时进化:
- 模型的层数从原始 Transformer 中的 6 层变为 GPT-3 模型中的 96 层
- 层的头部数量从原始 Transformer 模型中的 8 个变为 GPT-3 模型中的 96 个
- 上下文大小从原始 Transformer 模型中的 512 个标记变为 GPT-3 模型中的 12,288 个
架构的大小解释了为什么具有 96 层的 GPT-3 175B 比只有 40 层的 GPT-2 1,542M 产生更令人印象深刻的结果。两个模型的参数是可比的,但是层数增加了一倍。
让我们关注上下文大小,以了解变压器快速演变的另一个方面。
上下文大小和最大路径长度
Transformer 模型的基石在于注意力子层。反过来,注意力子层的关键属性是用于处理上下文大小的方法。
上下文大小是人类和机器的主要方式之一可以学习语言。上下文大小越大,我们就越能理解呈现给我们的序列。
然而,上下文大小的缺点是理解一个词所指的内容所需的距离。分析长期依赖关系的路径需要从循环层变为注意力层。
以下句子需要很长的路径才能找到代词“it”所指的内容:
“我们的房子太小了,在这么小的空间里放不下一张大沙发、一张大桌子和其他我们会喜欢的家具。我们想住一段时间,但最后还是决定卖掉它。”
“它”的含义只有在我们回到句子开头的“房子”一词时才能解释清楚。对于机器来说,这是一条相当不错的道路!
定义最大路径长度的函数顺序可以用大O表示法总结如表 7.2所示:
| Layer Type | 最大路径长度 |
Context Size |
| Self-Attention | 0(1) |
1 |
| Recurrent | 0(n) |
100 |
表 7.2:最大路径长度
瓦斯瓦尼等人。(2017)优化了原始 Transformer 模型中的上下文分析设计。注意将操作归结为一对一的令牌操作。所有层都是相同的这一事实使得扩大变压器模型的大小变得更加容易。具有大小为 100 的上下文窗口的 GPT-3 模型与大小为 10 的上下文窗口具有相同的最大长度路径。
例如,一个经常性的RNN 中的层必须存储总长度逐步的上下文。最大路径长度是上下文大小。处理 GPT-3 模型上下文大小的 RNN 的最大长度大小将是 0(n) 倍。此外,RNN 无法将上下文拆分为在并行机器架构上运行的 96 个头,例如,将操作分布在 96 个 GPU 上。
变压器的灵活和优化架构导致了对其他几个因素的影响:
- 瓦斯瓦尼等人。(2017 年)用 3600 万个句子训练了一个最先进的变压器模型。布朗等人。(2020) 训练了一个 GPT-3 模型,该模型具有从 Common Crawl 数据中提取的 4000 亿字节对编码的标记。
- 训练大型变压器模型需要世界上只有少数团队可以使用的机器能力。Brown等人总共花费了 2.14*10 23 FLOPS 。(2020) 训练 GPT-3 175B。
- 设计变压器的架构需要高素质的团队,而这些团队只能由世界上少数组织提供资金。
规模和架构将继续发展,并可能在不久的将来增加到万亿参数的模型。超级计算机将继续为训练变压器提供必要的资源。
我们现在将看到零样本模型是如何实现的。
从微调到零样本模型
从一开始,OpenAI 的研究由Radford等人领导的团队。(2018),通缉从训练有素的变形金刚模型到 GPT 模型。目标是在未标记的数据上训练转换器。让注意力层从无监督数据中学习语言是明智之举。OpenAI 没有教 Transformer 完成特定的 NLP 任务,而是决定训练 Transformer 学习一门语言。
OpenAI 想要创建一个与任务无关的模型。于是他们开始训练transformer模型基于原始数据而不是依赖于标签专家提供的数据。标记数据非常耗时,并且大大减慢了转换器的训练过程。
第一步是从变压器模型中的无监督训练开始。然后,他们只会微调模型的监督学习。
OpenAI 选择了堆叠解码器层部分中描述的仅解码器转换器。结果的指标令人信服,并迅速达到了其他 NLP 研究实验室的最佳 NLP 模型的水平。
第一版 GPT 变压器模型的有希望的结果很快导致了Radford等人。(2019)提出零样本转移模型。他们理念的核心是继续训练 GPT 模型以从原始文本中学习。然后,他们进一步研究,通过无监督分布的示例专注于语言建模:
Examples=(x1, x2, x3, ,xn)
这些示例由一系列符号组成:
Sequences=(s1, s2, s3, ,sn)
这导致了一个元模型,可以表示为任何类型输入的概率分布:
p (output/input)
目标是一旦经过训练的 GPT 模型通过强化训练理解一种语言,就可以将此概念推广到任何类型的下游任务。
GPT 模型从 117M 参数迅速发展到 345M 参数,再到其他大小,然后到 1,542M 参数。1,000,000,000+ 个参数转换器诞生了。微调量急剧减少。结果再次达到了最先进的指标。
这鼓励 OpenAI 走得更远,走得更远。布朗等人。(2020) 假设条件概率变换器模型可以进行深入训练,并且能够在对下游任务几乎没有微调的情况下产生出色的结果:
p (output/multi-tasks)
OpenAI 正在达到它的目标是训练模型然后在下游运行直接任务,无需进一步微调。这一惊人的进步可以用四个阶段来描述:
- Fine-Tuning( FT ) 旨在按照我们之前探索的意义执行章节。变压器模型经过训练,然后在下游任务上进行微调。拉德福德等人。(2018)设计了许多微调任务。OpenAI 团队随后将任务数量逐步减少到
0以下步骤。 - Few-Shot ( FS ) 代表了一个巨大的进步。GPT 是经过训练的。当模型需要为了做出推论,它展示了作为条件执行的任务的演示。调节取代了 GPT 团队从流程中排除的权重更新。我们将通过我们提供的上下文对我们的模型应用条件,以便在本章将要介绍的笔记本中获得文本完成。
- One-Shot ( 1S ) 使该过程更进一步。呈现训练好的 GPT 模型只有一个下游任务的演示要执行。也不允许更新权重。
- Zero-Shot( ZS ) 是最终目标。训练好的 GPT 模型没有演示要执行的下游任务。
这些方法中的每一种都具有不同级别的效率。OpenAI GPT 团队一直在努力制作这些最先进的变压器模型。
我们现在可以解释导致 GPT 模型架构的动机:
- 教变形金刚模型如何通过广泛的培训学习一门语言。
- 通过上下文条件关注语言建模。
- 转换器以一种新颖的方式获取上下文并生成文本完成。它不是在学习下游任务上消耗资源,而是致力于理解输入并做出推断,无论任务是什么。
- 通过屏蔽输入序列的一部分来寻找有效的模型训练方法,迫使变压器用机器智能进行思考。因此,机器智能虽然不是人类智能,但却是高效的。
我们了解动机这导致了 GPT 的架构楷模。现在让我们来看看仅解码器层的 GPT 模型。
堆叠解码器层
我们现在明白了OpenAI 团队专注于语言建模。因此,保留 masked attention 子层是有意义的。因此,选择保留解码器堆栈并排除编码器堆栈。布朗等人。(2020)显着增加了仅解码器变压器模型的大小,以获得出色的结果。
GPT 模型与Vaswani等人设计的原始 Transformer 的解码器堆栈具有相同的结构。(2017)。我们在第 2 章“ Transformer 模型架构入门”中描述了解码器堆栈。如有必要,花几分钟时间回顾一下原始 Transformer 的架构。
GPT 模型具有仅解码器架构,如图 7.1所示:
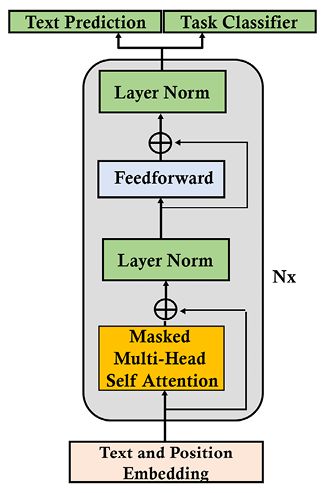
图 7.1:仅 GPT 解码器架构
我们可以识别文本和位置嵌入子层、掩码多头自注意力层、归一化子层、前馈子层和输出。此外,还有一个 GPT-2 版本,同时具有文本预测和任务分类。
OpenAI 团队逐个模型地定制和调整解码器模型。拉德福德等人。(2019) 提出了不少于四个 GPT 模型,Brown等人。(2020)描述了不少于八种模型。
GPT-3 175B 模型已经达到了一个独特的尺寸,它需要世界上很少有团队可以访问的计算机资源:
nparams = 175.0B, nlayers = 96, dmodel = 12288, nheads = 96
让我们看看成长GPT-3 引擎的数量。
GPT-3 发动机
可以训练 GPT-3 模型完成不同规模的特定任务。名单OpenAI 记录了此时可用的引擎:https ://beta.openai.com/docs/engines
基础系列发动机具有不同的功能——例如:
- 达芬奇引擎可以分析复杂的意图
- 居里引擎速度快,总结性好
- 巴贝奇引擎擅长语义搜索
- Ada引擎擅长解析文本
OpenAI 正在生产更多引擎以投放市场:
- Instruct 系列提供基于描述的说明。本章的更多 GPT-3 示例部分提供了一个示例。
- Codex 系列可以将语言翻译成代码。我们将在第 16 章“变压器驱动副驾驶的出现”中探讨这个系列。
- 内容过滤器系列过滤不安全或敏感的文本。我们将在第 16 章“变压器驱动副驾驶的出现”中探讨这个系列。
我们已经探索了引导我们从微调到零样本 GPT-3 模型的过程。我们已经看到 GPT-3 可以生产多种发动机。
现在是时候看看 GPT 模型的源代码是如何构建的了。虽然 GPT-3 变压器模型源代码目前尚未公开,但 GPT-2 模型足够强大,可以理解 GPT 模型的内部工作原理。
我们已准备好与 GPT-2 模型进行交互并对其进行训练。
我们将首先使用经过训练的 GPT-2 345M 模型进行文本完成,该模型具有 24 个解码器层和 16 个头的自注意力子层。
然后,我们将训练一个 GPT-2 117M 模型,用于自定义文本完成,具有 12 个具有自注意力的解码器层层数 12 个头。
让我们从与预训练的 345M 参数 GPT-2 模型进行交互开始。
使用 GPT-2 的通用文本完成
我们将使用 GPT-2 通用模型从上到下探索一个示例。我们将运行的示例的目标是确定 GPT 模型可以达到的抽象推理水平。
本节介绍交互使用 GPT-2 文本模型完成。我们将重点关注在附录 III,使用 GPT-2 的通用文本完成中详细描述的笔记本的第 9 步。OpenAI_GPT_2.ipynb
您可以先阅读本节,了解通用的预训练 GPT-2 模型如何对特定示例做出反应。然后阅读附录 III,使用 GPT-2 完成通用文本,详细了解如何在 Google Colab 笔记本中实现通用 GPT-2 模型。
您也可以直接阅读附录 III,其中包含下面描述的第 9 步的交互。
首先,让我们了解应用预训练的 GPT-2 的具体示例。
第 9 步:与 GPT-2 交互
在本节中,我们将互动与 GPT-2 345M 型号。
要与模型交互,请运行interact_model单元:
#@title Step 9: Interacting with GPT-2
interact_model('345M',None,1,1,300,1,0,'/content/gpt-2/models')系统将提示您输入一些上下文:
![]()
图 7.2:文本完成的上下文输入
你可以尝试任何类型你希望的上下文,因为这是一个标准的 GPT-2 模型。
我们可以试试 Immanuel Kant 写的一句话:
Human reason, in one sphere of its cognition, is called upon to
consider questions, which it cannot decline, as they are presented by
its own nature, but which it cannot answer, as they transcend every
faculty of the mind.按Enter生成文本。输出将是相对随机的,因为 GPT-2 模型没有在我们的数据集上进行训练,而且我们正在运行一个随机模型。
让我们看看 GPT 模型在我运行它时生成的前几行:
"We may grant to this conception the peculiarity that it is the only causal logic.
In the second law of logic as in the third, experience is measured at its end: apprehension is afterwards closed in consciousness.
The solution of scholastic perplexities, whether moral or religious, is not only impossible, but your own existence is blasphemous."要停止单元格,请双击单元格的运行按钮。
您也可以按Ctrl + M停止生成文本,但它可能会将代码转换为文本,您必须将其复制回程序单元格。
输出很丰富。我们可以观察到几个事实:
- 我们输入的上下文以模型生成的输出为条件。
- 上下文是模型的演示。它在不修改其参数的情况下从上下文中学习了要说什么。
- 文本完成取决于上下文。这为不需要微调的变压器模型打开了大门。
- 从语义的角度来看,输出可能更有趣。
- 从语法的角度来看,输出是令人信服的。
我们能做得更好吗?以下部分介绍了自定义文本完成的交互。
训练自定义 GPT-2 语言模型
在本节中,我们将通过探索 GPT-2 自定义模型的示例来继续我们的自上而下的方法我们将在特定数据集上进行训练。目标仍然是确定 GPT 模型可以达到的抽象推理水平。
本节描述了与在特定数据集上训练的文本完成的 GPT-2 模型的交互。我们将重点关注在附录 IV,使用 GPT-2 的自定义文本完成中详细描述的笔记本的第 12 步。Training_OpenAI_GPT_2.ipynb
您可以先阅读本节,了解使用自定义 GPT-2 模型的示例将如何改进响应。然后阅读附录 IV,使用 GPT-2 完成自定义文本,了解如何训练 GPT-2 以获得特定响应。
您也可以决定直接阅读附录 IV ,其中还包含下面描述的第 12 步的交互。
首先,让我们了解如何通过训练改进与 GPT-2 的交互。
第 12 步:交互式上下文和完成示例
我们现在将运行一个条件样本。我们输入的上下文将使模型按照我们的意愿思考,完成通过生成量身定制的文本段落。
运行单元并探索魔法:
#@title Step 12: Interactive Context and Completion Examples
import os # import after runtime is restarted
os.chdir("/content/gpt-2/src")
!python interactive_conditional_samples.py --temperature 0.8 --top_k 40 --model_name '117M'如有必要,请花几分钟时间返回第 9 步,与附录 III的 GPT-2 交互,使用 GPT-2完成通用文本,以查看响应的差异。程序提示我们输入上下文:
![]()
图 7.3:文本完成的上下文输入
让我们输入 Immanuel Kant 写的与本章通用文本完成与 GPT-2部分的第9 步相同的段落:
Human reason, in one sphere of its cognition, is called upon to
consider questions, which it cannot decline, as they are presented by
its own nature, but which it cannot answer, as they transcend every
faculty of the mind.按Enter生成像我们之前做的那样发短信。虽然结构并且合乎逻辑的是,输出可能会从一次运行到另一次运行发生变化,从而使变压器具有吸引力。这一次,结果不是随机的,而且令人印象深刻。
让我们看一下 GPT-2 模型产生的前几行:
"Now, what is the nature of the reason, except that it is of a kind and power of mind that is so called on to think, and to understand?
The reason is the thing which apprehends, and seeks to understand, the objects of its minds, which apprehend and apprehend the things of itself. No one can speak of this reason without the understanding and the understanding of the human reason. But that knowledge and understanding which is the most natural of all the faculties, which, because it is understood by the human reason, is the most natural of all the faculties, is not without reason, but only without understanding. The human reason, who sees and knows the things which the natural sense, which, though in the natural sense, does not understand, is the source of every other knowledge which we understand. The reason is the thing which does not understand, but understands the things which we comprehend, and therefore, is not to be understood. I mean that the reason is the thing which does not understand, but knows only the things which we do understand…."要停止单元格,请双击单元格的运行按钮或按Ctrl + M。
哇!我怀疑有人能看出我们训练有素的 GPT-2 模型和人类生成的文本完成之间的区别。它还可能在每次运行时生成不同的输出。
事实上,我认为我们的模型在哲学、推理和逻辑方面的抽象练习中可以胜过许多人!
我们可以从我们的实验中得出一些结论:
- 训练有素的 Transformer 模型可以在人类水平上生成文本完成
- GPT-2 模型在复杂抽象推理的文本生成中几乎可以达到人类水平
- 文本上下文是一种通过展示预期内容来调节模型的有效方法
- 如果提供上下文句子,则文本完成是基于文本条件的文本生成
您可以输入条件文本上下文示例来试验文本完成。您还可以根据自己的数据训练模型。只需dset.txt用您自己的数据替换文件的内容,看看会发生什么!
请记住,我们经过训练的 GPT-2 模型会像人类一样做出反应。如果你输入一个简短、不完整、无趣或棘手的上下文,你会得到不解或不好的结果。这是因为 GPT-2 期望我们最好的,就像在现实生活中一样!
让我们去 GPT-3 操场看看经过训练的 GPT-3 对使用 GPT-2 测试的示例有何反应。
运行 OpenAI GPT-3 任务
在本节中,我们将分两次运行 GPT-3不同的方法:
- 我们将首先在没有代码的情况下在线运行 GPT-3 任务
- 然后我们将在 Google Colab notebook 中实现 GPT-3
我们将在本书中使用 GPT-3 引擎。当您注册 GPT-3 API 时,OpenAI 会为您提供免费的入门预算。这个免费预算应该涵盖运行本书中的示例一两次的大部分成本,如果不是全部成本的话。
让我们从在线运行 NLP 任务开始。
在线运行 NLP 任务
我们现在将通过一些没有 API 的工业 4.0 示例,直接要求 GPT-3 为我们做点什么。
让我们将提示和响应的标准结构定义为:
- N = NLP 任务的名称 (INPUT)。
- E = GPT-3 引擎的解释。E在T (INPUT)之前。
- T = 我们希望 GPT-3 研究的文本或内容(输入)。
- S = 显示 GPT-3 的预期内容。S在T 之后并在必要时添加(输入)。
- R = GPT-3 的响应(输出)。
上述提示的结构是一个指南。但是,GPT-3 非常灵活,可以进行许多变化。
我们现在准备好在没有 API 的情况下在线运行一些教育示例:
- 关于现有知识 的问答(Q&A ):
E =
QT =
Who was the president of the United States in 1965?S = 无
R =
A提示和响应:
Q: Who was the president of the United States in 1965?A: Lyndon B. Johnson was president of the United States in 1965.Q: Who was the first human on the moon?A: Neil Armstrong was the first human on the moon.
- 电影到表情符号:
E = 电影片名的一些例子
T = 无
S = 通过示例隐含
R = 一些表情符号示例
提示和响应:

新的提示和响应:

- 总结二年级学生(二年级学生总结):
E =
My second grader asked me what this passage means:T =
"""The initial conclusions…."""S=
I rephrased it for him, in plain language a second grader can understand: """R = The summary
提示和响应:
My second grader asked me what this passage means:""" The initial conclusions can be divided into two categories: facts and fiction. The facts are that OpenAI has one of the most powerful NLP services in the world. The main facts are: OpenAI engines are powerful zero-shot that require no hunting for all kinds of transformer models, no pre-training, and no fine-tuning. The supercomputers used to train the models are unique. If the prompt is well-designed, we obtain surprisingly accurate responses. Implementing the NLP tasks in this section required a copy and paste action that any software beginner can perform. Fiction begins with dystopian and hype assertions AI will replace data scientists and AI specialists. Is that true? Before answering that question, first ask yourself the following questions about the example we just ran: How do we know the sentence was incorrect in the first place? How do we know the answer is correct without us humans reading and confirming this? How did the engine know it was a grammar correction task? If the response is incorrect, how can we understand what happened to help improve the prompt or revert to manual mode in a well-designed human interface? The truth is that humans will need to intervene to answers these questions manually, with rule-bases, quality control automated pipelines, and many other tools. The facts are convincing. It is true that running an NLP task requires little development. The fiction is not convincing. Humans are still required. OpenAI engines are not there to replace humans but to help them perform more high-level gratifying tasks. You can now fly a jet without having to build it! """I rephrased it for him, in plain language a second grader can understand: """The first conclusion is that OpenAI has one of the most powerful NLP services in the world. The most important facts are: OpenAI engines are very powerful zero-shot that require no hunting for all kinds of transformer models, no pre-training, and no fine-tuning. The supercomputers used to train the models are unique. If the prompt is well-designed, we get surprisingly accurate responses.
结果令人印象深刻,在 NLP 的历史上向前迈出了一大步。
我们可以使用 OpenAI 提供的零样本 GPT-3 引擎实现的 NLP 任务数量是无穷无尽的,因为我们控制了如何展示我们对变压器模型的期望。
然而,一个真实的工业 4.0 的 AI 大师在实施即用型 API 之前必须亲自动手。我们现在将探索 OpenAI GPT 模型的架构,然后构建 GPT-2 模型以了解这些引擎是如何工作的。
我们对 GPT 模型了解得越多,工业 4.0 NLP 专家就能更好地在实际项目中实施它们。
让我们继续我们的自上而下的方法,并深入研究 OpenAI GPT 变压器模型的架构。
GPT-3 引擎入门
OpenAI 拥有一些最强大的转换器世界上的发动机。一个 GPT-3 模型可以执行数百个任务。GPT-3 可以完成许多未经训练的任务。
本节将使用Getting_Started_GPT_3.ipynb.
要使用 GPT-3,您必须首先访问 OpenAI 的网站OpenAI并注册。
OpenAI 有一个供大家尝试的游乐场,就像谷歌翻译或任何用户友好的在线服务一样。所以,让我们尝试一些任务。
使用 GPT-3 运行我们的第一个 NLP 任务
让我们开始使用GPT-3 在几个脚步。
去 Google Colab 打开Getting_Started_GPT_3.ipynb,这是 GitHub 上这本书的章节目录。
您无需更改笔记本的设置。我们正在使用 API,因此对于本节中的任务,我们不需要太多的本地计算能力。
本节的步骤与笔记本中的相同。
运行 NLP 只需三个简单的步骤:
第 1 步:安装 OpenAI
安装openai使用以下命令:
try:
import openai
except:
!pip install openai
import openai如果openai未安装,则必须重新启动运行时。一条消息将指示何时执行此操作,如以下输出所示:
重新启动运行时然后再次运行此单元格以确保openai已导入。
第 2 步:输入 API 密钥
提供了一个 API 密钥可以与 Python、C#、Java 和许多其他选项一起使用。我们将在本节中使用 Python:
openai.api_key=[YOUR API KEY]您现在可以使用您的 API 密钥更新下一个单元格:
import os
import openai
os.environ['OPENAI_API_KEY'] ='[YOUR_KEY or KEY variable]'
print(os.getenv('OPENAI_API_KEY'))
openai.api_key = os.getenv("OPENAI_API_KEY")现在让我们运行一个 NLP 任务。
步骤 3:使用默认参数运行 NLP 任务
我们复制并粘贴语法校正任务的 OpenAI 示例:
response = openai.Completion.create(
engine="davinci",
prompt="Original: She no went to the market.\nStandard American English:",
temperature=0,
max_tokens=60,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0,
stop=["\n"]
)任务是纠正这个语法错误:She no went to the market.
我们可以通过解析来处理我们希望的响应。OpenAI 的响应是一个字典对象。OpenAI 对象包含有关任务的详细信息。我们可以要求显示的对象:
#displaying the response object
print(response)我们可以探索对象:
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": " She didn't go to the market."
}
],
"created": 1639424815,
"id": "cmpl-4ElZfXLl9jGRNQoojWRRGof8AKr4y",
"model": "davinci:2020-05-03",
"object": "text_completion"} “created”编号和“id”以及“model”名称可以随每次运行而变化。
然后我们可以要求对象字典显示"text"并打印处理后的输出:
#displaying the response object
r = (response["choices"][0])
print(r["text"])text字典中“”的输出是语法正确的句子:
She didn't go to the market.NLP 任务和示例
现在我们将介绍GPT-3 发动机使用的工业方法。例如,OpenAI 提供了一个不需要 API 的交互式教育界面。因此,学校教师、顾问、语言学家、哲学家或任何希望将 GPT-3 引擎用于教育目的的人都可以在完全没有人工智能经验的情况下这样做。
我们将首先在笔记本中使用 API。
语法校正
如果我们回到GPT-3 引擎入门Getting_Started_GPT_3.ipynb中开始探索的内容在本章的部分,我们可以尝试用不同的提示进行语法校正。
打开笔记本并转到第 4 步:示例 1:语法校正:
#Step 6: Running an NLP task with custom parameters
response = openai.Completion.create(
#defult engine: davinci
engine="davinci",
#default prompt for task:"Original"
prompt="Original: She no went to the market.\n Standard American English:",
temperature=0,
max_tokens=60,
top_p=1.0,
frequency_penalty=0.0,
presence_penalty=0.0,
stop=["\n"]
)请求正文不限于提示。身体包含几个关键参数:
engine="davinci". 选择使用的 OpenAI GPT-3 引擎以及未来可能使用的其他模型。temperature=0. 较高的值0.9将迫使模型承担更多风险。不要同时修改温度top_p。max_tokens=60. 响应的最大令牌数。top_p=1.0. 另一种控制采样的方法,例如temperature. 在这种情况下,top_p将考虑概率质量中令牌的百分比。0.2将使系统仅占最高概率质量的 20%。frequency_penalty=0.0. 一个介于0和1限制给定响应中令牌频率的值。presence_penalty=0.0. 一个介于两者之间的值,0并1迫使系统使用新的代币并产生新的想法。stop=["\n"]. 向模型发出停止生成新令牌的信号。
其中一些参数在步骤 7b-8:导入和定义附录 III的模型部分的源代码级别进行了描述,使用 GPT-2 完成通用文本。
如果您获得访问权限,您可以在 GPT-3 模型中使用这些参数,或者在附录 III中的 GPT-2 模型中使用这些参数,使用 GPT-2 完成通用文本。两种情况下的概念是相同的。
本节将重点介绍提示:
prompt="Original: She no went to the market.\n Standard American English:"提示可以分为分为三个部分:
Original:这向模型表明以下是原始文本,模型将对其进行处理She no went to the market.\n:这部分提示显示模型,这是原文Standard American English:这向模型显示了预期的任务
让我们看看通过改变任务我们能走多远:
- 标准美式英语产生:
prompt="Original: She no went to the market.\n Standard American English:"回应的文字是:
"text": " She didn't go to the market."这很好,但是如果我们不想在句子中出现收缩怎么办?
- 没有收缩的英语产生:
prompt="Original: She no went to the market.\n English with no contractions:"回应的文字是:
"text": " She did not go to the market."哇!这令人印象深刻。让我们尝试另一种语言。
- 没有宫缩的法语产生:
"text": " Elle n'est pas all\u00e9e au march\u00e9."这令人印象深刻。
\u00e9只需要后处理成é.
更多的选择是可能的。您的工业 4.0 跨学科想象力是极限!
更多 GPT-3 示例
OpenAI 包含很多例子。OpenAI 提供了一个可供探索的在线游乐场任务。OpenAI 还为每个示例提供了源代码:https ://beta.openai.com/examples
只需单击一个示例比如我们在语法修正部分探讨的语法例子:

图 7.4:OpenAI 的语法校正部分
OpenAI 将描述每个任务的提示和示例响应。

图 7.5:示例响应更正了提示
你可以选择去操场并在线运行它,就像我们在本章的在线运行 NLP 任务部分所做的那样。为此,请单击在 Playground 中打开按钮:

图 7.6:在 Playground 中打开按钮
您可以选择复制并粘贴代码以运行 API,就像我们在本章的 Google Colab 笔记本中所做的那样:
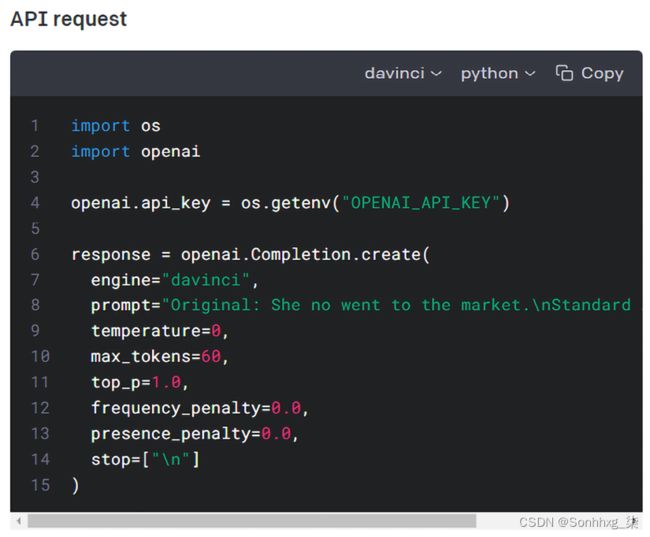 图 7.7:使用 Davinci 引擎运行代码
图 7.7:使用 Davinci 引擎运行代码
Getting_Started_GPT_3.ipynb包含十个示例,您可以运行这些示例来练习实施 OpenAI GPT-3。
对于每个示例:
- 您可以先阅读 OpenAI 提供的说明的链接。每个单元格上方都提供了指向文档的链接。
- 然后,您可以运行该单元以观察 GPT-3 的行为。
运行这十个例子在笔记本中:
- 示例 1:语法校正
- 示例 2:英法翻译
- 示例 3:提供说明的指导系列
- 示例 4:电影到表情符号
- 示例 5:将编程语言转换为另一种语言。例如,Python 到 JavaScript。警告:您可能需要从 OpenAI 获得特殊许可才能运行此示例,该示例使用代码生成器 Davinci Codex 引擎。如果此示例未在您的笔记本中运行,请联系 OpenAI 以请求访问 Codex。
- 示例 6:高级推文分类器
- 示例 7:问答
- 示例 8 总结一段文字
- 示例 9:解析非结构化数据
- 示例 10:计算时间复杂度
您可以在示例页面上运行许多其他任务:https ://beta.openai.com/examples
现在让我们比较一下 GPT-2 和 GPT-3 的输出。
比较 GPT-2 和 GPT-3 的输出
我们的好奇心必须在我们继续之前得到满足。使用我们提交给预训练 GPT-2 模型和自定义训练 GPT-2 模型的示例,强大的 GPT-3 模型可以产生什么?
我们用于 GPT-2 模型的示例:
Human reason, in one sphere of its cognition, is called upon to consider questions, which it cannot decline, as they are presented by its own nature, but which it cannot answer, as they transcend every faculty of the mind.
GPT-3's response:
What is meant by this is that there are some things in our experience that are beyond reason. It is not that reason is a bad guide or is insufficient, but that there are some things that are beyond its reach. An example of this would be the existence of God. 结果令人震惊!它解释了文本的含义,包括一些深刻的哲学反思!
我们已经证明我们在本章中的观点。Transformer 模型可以实现抽象推理,这有助于在我们快速发展的世界中做出微观决策。
OpenAI GPT-3 是一个经过全面训练的模型。但是,GPT-3 可以进行微调。让我们看看如何。
微调 GPT-3
本节介绍如何微调 GPT-3 以学习逻辑。变形金刚需要学习逻辑、推理和蕴涵,才能在人类层面理解语言。
微调是使 GPT-3 成为您自己的应用程序、对其进行自定义以使其适合您的项目需求的关键。这是一张通往 AI 自由的门票,可以摆脱偏见,教它你想让它知道的东西,并在 AI 上留下你的足迹。
在本节中,GPT-3 将使用kantgpt.csv. 我们在第 4 章“从头开始预训练 RoBERTa 模型”中使用了类似的文件来训练 BERT 类型的模型。
一旦你掌握了微调 GPT-3,你就可以使用其他类型的数据来教授它特定的领域、知识图谱和文本。
OpenAI 提供了一种高效、有据可查的服务来微调 GPT-3 引擎。它已将 GPT-3 模型训练为不同类型的引擎,如本章的十亿参数转换器模型的兴起部分所示。
达芬奇引擎功能强大,但使用起来可能更昂贵。在我们的实验中,Ada 引擎更便宜,并且产生了足够的结果来探索 GPT-3。
微调 GPT-3 涉及两个阶段:
- 准备数据
- 微调 GPT-3 模型
准备数据
在 GitHub 章节目录中的 Google Colab 中打开Fine_Tuning_GPT_3.ipynb。
OpenAI 已记录数据准备详细流程:
OpenAI API
第 1 步:安装 OpenAI
第一步是安装和进口openai:
try:
import openai
except:
!pip install openai
import openai安装完成后重新启动运行时并再次运行单元以确保已执行 import openai
import openai您还可以安装 wand 以可视化日志:
try:
import wandb
except:
!pip install wandb
import wandb我们现在将输入 API 密钥
第 2 步:输入 API 密钥
第2步是输入你的钥匙:
openai.api_key="[YOUR_KEY]"第三步:激活 OpenAI 的数据准备模块
首先,加载您的文件。在本节中,加载kantgpt.csv. 现在,kantgpt.csv. 是一个原始的非结构化文件。开放人工智能有一个内置的数据清理器,可以在每个步骤中提出问题。
OpenAI 检测到文件是 CSV 文件并将其转换为JSONL文件。JSONL包含纯结构化文本中的行。
OpenAI 跟踪我们批准的所有更改:
Based on the analysis we will perform the following actions:
- [Necessary] Your format 'CSV' will be converted to 'JSONL'
- [Necessary] Remove 27750 rows with empty completions
- [Recommended] Remove 903 duplicate rows [Y/n]: y
- [Recommended] Add a suffix separator ' ->' to all prompts [Y/n]: y
- [Recommended] Remove prefix 'completion:' from all completions [Y/n]: y
- [Recommended] Add a suffix ending '\n' to all completions [Y/n]: y
- [Recommended] Add a whitespace character to the beginning of the completion [YOpenAI 保存转换后的文件到kantgpt_prepared.jsonl.
我们已准备好微调 GPT-3。
微调 GPT-3
您可以将笔记本拆分为两个单独的笔记本:一个用于数据准备,一个用于微调。
第 4 步:创建操作系统环境
微调过程中的第 4 步os为 API 密钥创建环境:
import openai
import os
os.environ['OPENAI_API_KEY'] =[YOUR_KEY]
print(os.getenv('OPENAI_API_KEY'))第 5 步:微调 OpenAI 的 Ada 引擎
第 5 步触发微调 OpenAI Ada 引擎使用数据准备后保存的 JSONL 文件:
!openai api fine_tunes.create -t "kantgpt_prepared.jsonl" -m "ada"OpenAI 有很多要求。
如果您的 Steam 中断,OpenAI 会指示继续微调的指令。Execute fine_tunes.follow操作说明:
!openai api fine_tunes.follow -i [YOUR_FINE_TUNE]第 6 步:与微调后的模型进行交互
第 6 步是交互与微调模型。提示是一个接近于伊曼纽尔·康德可能会说的序列:
!openai api completions.create -m ada:[YOUR_MODEL INFO] "Several concepts are a priori such as"[YOUR_MODEL INFO]OpenAI 通常会在微调任务结束时显示运行完成任务的指令。您可以将其复制并粘贴到单元格中(添加"!"以运行命令行)或将您的插入[YOUR_MODEL INFO]到以下单元格中。
完成度相当令人信服:
Several concepts are a priori such as the term freedom and the concept of _free will_.substance我们对 GPT-3 进行了微调,这表明了理解转换器和设计 AI 管道的重要性使用 API。让我们看看这如何改变人工智能专家的角色。
工业 4.0 人工智能专家的角色
简而言之,角色工业 4.0 开发者的目标是成为跨学科的 AI 大师。开发人员、数据科学家和 AI 专家将逐步了解有关语言学、业务目标、主题专业知识等的更多信息。工业 4.0 人工智能专家将指导具有实用跨学科知识和经验的团队。
在实施变压器时,人类专家在三个领域是强制性的:
- 道德与伦理
工业 4.0 人工智能专家确保在实施类人变压器时执行道德和伦理实践。例如,欧洲法规非常严格,要求在必要时向用户解释自动决策。美国有反歧视法来保护公民免受自动偏见的影响。
- 提示和响应
用户和 UI 开发人员将需要工业 4.0 人工智能专家来解释如何为 NLP 任务创建正确的提示,向转换器模型展示如何执行任务,并验证响应。
- 质量控制和模型理解
即使在调整了超参数之后模型的行为也没有达到预期时会发生什么?我们将在第 14 章“解释黑盒变压器模型”中深入探讨这些问题。
初步结论
初步结论可以分为两类:事实和虚构。
一个事实是 OpenAI 拥有世界上最强大的 NLP 服务之一。其他事实包括:
- OpenAI 引擎是强大的零样本引擎,无需寻找各种 Transformer 模型,无需预训练,无需微调
- 用于训练模型的超级计算机是独一无二的
- 如果提示设计得当,我们可以得到令人惊讶的准确响应
- 实现本章中的 NLP 任务只需要任何软件初学者都可以执行的复制和粘贴操作
许多人认为人工智能将取代数据科学家和人工智能专家。真的吗?在回答这个问题之前,首先,问自己以下关于我们在本章中运行的示例的问题:
- 我们如何知道一个句子是否不正确?
- 如果没有人类阅读和确认,我们怎么知道答案是正确的?
- 引擎怎么知道这是一个语法校正任务?
- 如果响应不正确,我们如何理解发生了什么有助于改进提示或在精心设计的人机界面中恢复到手动模式?
事实是,人类需要通过规则库、质量控制的自动化管道和许多其他工具手动干预以回答这些问题。
事实令人信服。在许多情况下,使用转换器运行 NLP 任务几乎不需要开发。
仍然需要人类。OpenAI 引擎不是为了取代人类,而是为了帮助他们执行更高级的令人满意的任务。您现在可以驾驶喷气式飞机而无需建造它!
我们需要回答我们在本节中提出的令人兴奋的问题。因此,现在让我们探索您在通往 AI 未来的美妙道路上的迷人的工业 4.0 新角色!
让我们总结本章,继续下一个探索!
概括
在本章中,我们发现了在超级计算机上训练数十亿参数的变压器模型的新时代。OpenAI 的 GPT 模型使 NLU 超出了大多数 NLP 开发团队的能力范围。
我们看到了 GPT-3 零样本模型如何通过 API 甚至在没有 API 的情况下直接在线执行许多 NLP 任务。谷歌翻译的在线版本已经为人工智能的主流在线使用铺平了道路。
我们探索了 GPT 模型的设计,这些模型都建立在原始变压器的解码器堆栈上。蒙面注意力子层延续了从左到右训练的理念。然而,计算的强大功能和随后的自注意力子层使其非常高效。
然后我们用 TensorFlow 实现了一个 345M 参数的 GPT-2 模型。目标是与训练有素的模型进行交互,看看我们能用它走多远。我们看到提供的上下文决定了输出。但是,当从数据集中输入特定输入时,它没有达到预期的结果Kant。
我们在自定义数据集上训练了一个 117M 参数的 GPT-2 模型。与这个相对较小的训练模型的交互产生了令人着迷的结果。
我们使用 OpenAI 的 API 在线运行 NLP 任务并微调 GPT-3 模型。本章展示了完全预训练的转换器及其引擎可以在工程师的帮助下自动完成许多任务。
这是否意味着未来用户将不再需要 AI NLP 开发人员、数据科学家和 AI 专家?相反,用户是否会简单地将任务定义和输入文本上传到云转换器模型并下载结果?
不,根本不是这个意思。工业 4.0 数据科学家和人工智能专家将演变为强大人工智能系统的飞行员。它们将越来越有必要确保输入是合乎道德和安全的。这些现代人工智能飞行员还将了解如何构建变压器并调整人工智能生态系统的超参数。
在下一章,将 Transformer 应用于法律和财务文档以进行 AI 文本摘要,我们将把 Transformer 模型作为多任务模型发挥到极致,并探索新的前沿。