Bert微调技巧实验大全
背景介绍
文本分类是NLP中的一个经典任务, 通常在大型的数据集进行一些预训练的模型在文本分类上可以取得很不错的成绩。例如word2vec, CoVe(contextualized word embeddings)和ELMo都取得了不错的成绩。Bert是基于双向transformer使用masked word prediction和NSP(next sentence prediction)的任务进行预训练,然后在下游任务上进行微调。Bert的出世,横扫了各大榜单。但是他的潜能已经被完全开发了吗?本文针对文本分类基于Bert探索了几种可以优化效果的方法。
这几种方法分别是:
- Fine-tune策略
- 深度预训练
- 多任务Fine-tune
策略介绍
1. Fine-tune策略
神经网络的不同层可以捕获不同的语法和语义信息。使用Bert去训练下游任务需要考虑几个问题:
- 预训练的长本文,因为Bert的最长文本序列是512
- 层数选择,正如上文所述哦,每一层都会捕获不同的信息,因此我们需要选择最适合的层数
- 过拟合问题,因此需要考虑合适的学习率。Bert的底层会学习到更多的通用的信息,文中对Bert的不同层使用了不同的学习率。 每一层的参数迭代可以如下所示:
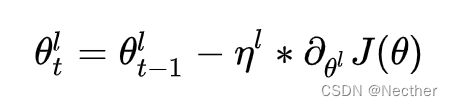
其中
- 表示第l层第t步迭代的参数
- 表示第l层的学习率,计算方式如下。 表示衰败系数,当>1表示学习率逐层衰减,否则表示逐层扩大。当=1时和传统的Bert相同。
2. 深度预训练
Bert是在通用的语料上进行预训练的,如果要在特定领域应用文本分类,数据分布一定是有一些差距的。这时候可以考虑进行深度预训练。
- Within-task pre-training:Bert在训练语料上进行预训练
- In-domain pre-training:在同一领域上的语料进行预训练
- Cross-domain pre-training:在不同领域上的语料进行预训练
3. 多任务Fine-tune
多任务微调就是使用Bert去训练不同的下游任务但是除了最后一层,在其他层共享参数。
实验结果
1. 数据集
本文使用了IMDB, Yelp评论数据集用于做情感分析,TREC(公开领域的问答数据集),yahoo问答用于问题分类,AG新闻,DBPedia和Sougou新闻做主题分类。文中使用WordPiece embeddings以##切分句子。对Sougou新闻采用"。", "?", "!"来分隔句子。

2. Fine-tune策略
- 长文本处理
对于长文本文中做了两种处理方式,截断和切分。
- 截断:一般来说文本中最重要的信息是开始和结尾,因此文中对于长文本做了截断处理。
head-only:保留前510个字符
tail-only:保留后510个字符
head+tail:保留前128个和后382个字符
- 切分: 将文本分成k段,每段的输入和Bert常规输入相同,第一个字符是[CLS]表示这段的加权信息。文中使用了Max-pooling, Average pooling和self-attention结合这些片段的表示。
下面是实验的结果,head+tail的表示在两个数据集上的效果都比较好。应该是长文本结合了句首和句尾的信息,获取的信息比较均衡。不过奇怪的是拼接的方式整体居然不如截断,个人猜测可能是将句子切成几段之后增加了模型的不稳定性,而错误叠加起来可能就会被放大。而max-pooling和self-attention也更加强调了文本中比较有用的信息,所以整体效果优于average.

2. 层数选择
文中对每层的效果和前四层的结果进行拼接,后四层的结果拼接以及12层的结果拼接进行了实验,发现后四层拼接和第11层的效果相同。

3. Catastrophic Forgetting
Catastrophic forgetting是指在学习新知识时预训练的知识被遗忘了。文中对Bert的Catastrophic Forgetting问题进行了探索。下图是IMDB数据集上不同学习率和error-rate的曲线,可以看到比较小的学习率获得效果比较好。

4. 层间学习率
层间学习率对模型的影响,可以看到初始学习率较高的时候,衰退率应该相对较低。因为深层的模型可以学到的内容较少,需要比较低的学习率进行拟合。这是不是也意味着在某一层有一个比较固定的学习可以使模型达到最优呢?

3. 深度预训练
1. Within-Task Further Pre-Training
使用训练数据进行预训练,下图是预训练的step和测试的错误率的曲线,可以看到预训练100K轮之后训练的效果有所提升。

2. In-Domain and Cross-Domain Further Pre-Training
文中将语料分为情感分析,问题分类和主题分类三个领域,在这些语料上按照领域内和跨领域的预训练。下图是预训练的结果,all是使用了所有领域内的语料进行了预训练,w/o是原始的bert。可以看到不管是领域内还是跨领域经过预训练的效果都比原始的Bert有所提高。不过需要注意,小规模语料的TREC经过领域内训练的效果变差了。

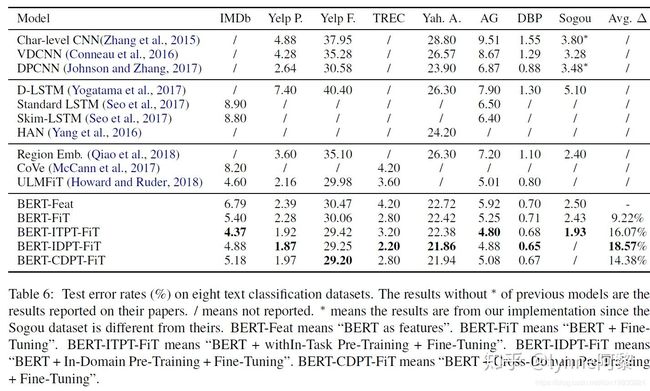
文中同时也是用Bert的特征输入Bilstm+self-attention中进行评测,效果如下所示,其中:
- BERT-Feat: BERT as features
- BERT-FiT: BERT + Fine-Tuning
- BERT-ITPT-FiT: BERT + withIn-Task Pre-Training + Fine-Tuning
- BERT-IDPT-FiT: BERT + In-Domain Pre-Training + Fine-Tuning
- BERT-CDPT-FiT: BERT + Cross-Domain Pre-Training + Fine-Tuning
4. 多任务Fine-tune
论文中使用了4个英文分类的数据集(IMDB, Yelp.P, AG, DBP)进行多任务训练,同时使用了跨领域预训练的Bert模型进行对比,效果如下。可以看到多任务学习可以提高Bert的效果,与此同时在跨领域预训练Bert模型上进行多任务Fine tune的效果是最好的。

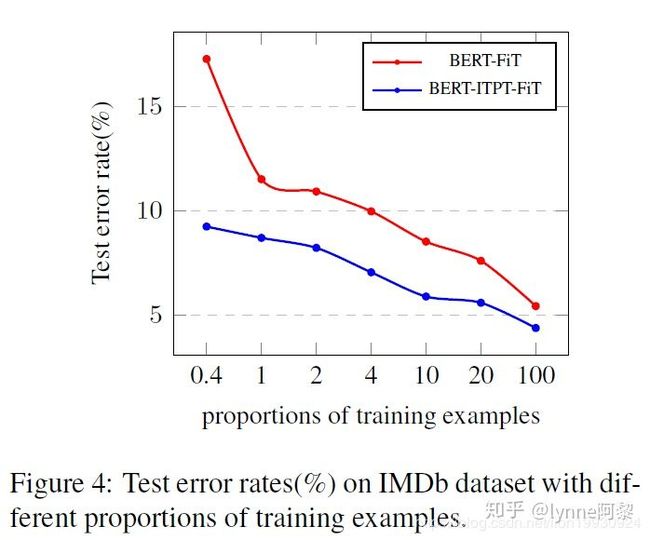
5. 训练集的规模
文中对Fine-tune时的训练集的规模对模型的效果的影响进行探索。可以看到当训练数据集比较少的时候,模型的错误率是比较高的,随着训练集的增大,模型的错误率下降。但是为什么横坐标从20到了100这里有一点迷惑。其中Bert-Fit表示Bert Fine-tune, BERT-ITPT-Fit表示BERT + withIn-Task Pre-Training + Fine-Tuning.
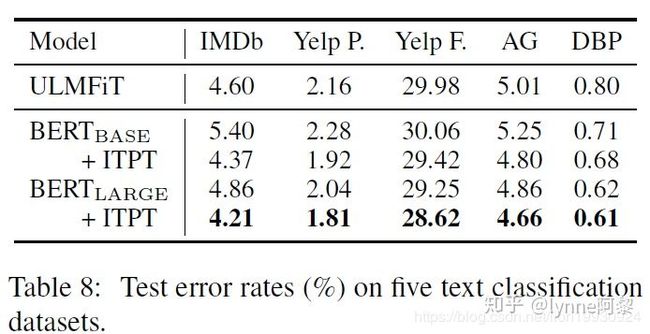
6. Bert Large预训练
文中对Bert Large也进行了With task预训练,大力出奇迹,果然Bert large的效果更好。
总结
感觉这是一篇非常扎实,考虑比较全面的实验报告,但是对于实验结果的思考和解释不多。总之使用Bert微调的时候可以考虑在领域内重新预训练,让模型多学习点知识,以及深度学习还是一如既往地大力出奇迹。
相关资料
How to Fine-Tune BERT for Text Classificationarxiv.org/pdf/1905.05583.pdf