MySQL进阶篇 - 索引
要看基础的小伙伴点这哦!!!
MySQL基础篇-MySQL 命令大全
什么是索引: 索引是帮助MySQL高效获取数据的数据结构
1.索引的数据结构选择:
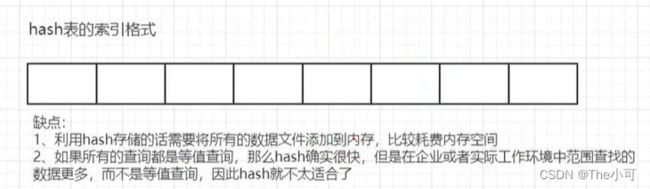
1.1 hash表
1.2 二叉树/红黑树索引格式
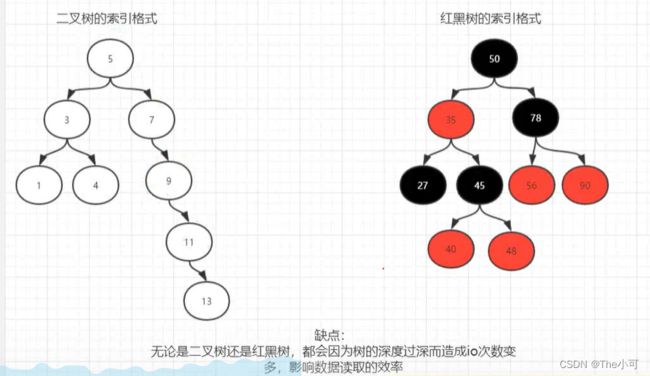
缺点: 树的深度会影响效率,增加IO次数,红黑树在数据量增大的时候需要旋转,也影响效率
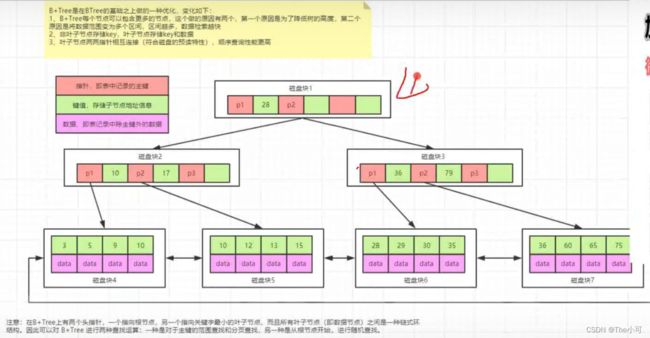
1.3 B树

图说明:
每个节点占用一个磁盘块,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为16和34,P1指针指向的子树的数据范围为小于16,P2指针指向的子树的数据范围为16-34,P3指针指向的子树的数据范围为大于34.
查找关键字过程:
- 根据根节点找到碰盘块,1读入内存。【磁盘I/O操作第1次】
- 比较关健字28在区间(16,34),找到磁盘块1的指针P2
- 根据P2指针找到磁盘块3,读入内存。【磁盘1/O操作第2次】
- 比较关健字28在区问(27,29)。找到磁盘块3的指针P2
- 根据P2指针找到磁盘块8,读入内存。【磁盘1/O操作第3次】
- 在磁盘块8中的关键字列表中找到关键字28.
缺点:
- 每个节点都有key,同时也包含data,而每个页存储空间是有限的,如果data比较大的话会导致每个节点存储的key的数量变少
- 当存储的数据量很大时会导致树的深度较大,增加查询时磁盘IO的次数,进而影响查询性能
1.4 B+树
非叶子节点存储key和指针,叶子节点存储数据(使得每次磁盘IO读取尽可能多的数据key),最多只需要3层就可达千万级数据
- INNODB 实现B+树:
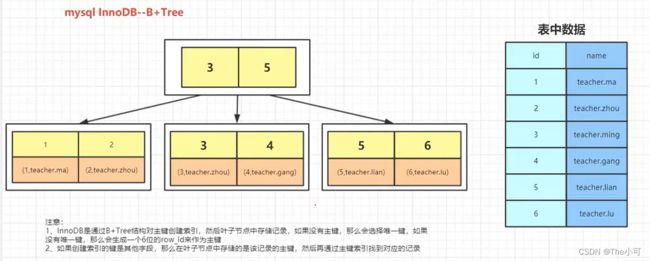
叶子节点存储数据,如果创建索引的键是其他字段(非主键),那么叶子节点存储的数据是该记录的主键,然后再通过主键查找到该记录
- MyISAM 实现B+树:
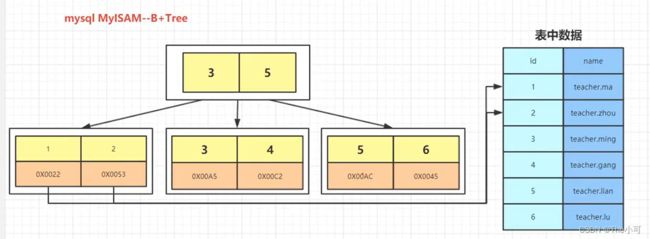
叶子节点存储的是数据的地址,再根据地址取读取数据(对应MyISAM 两个文件 。myi存储的是索引文件,myd存储的是数据文件)
2. 索引的分类:
添加索引可以提高数据的读取速度,提高项目的并发能力和抗压能力
- 主键索引 (primary key): 主键是一种唯一性索引,但必须指定为primay key
- 唯一索引 (unique):索引列的所有值都只能出现一次,必须唯一,但值可以为空
- 普通索引 : 基本的索引类型,值可以为空,没有唯一性的限制
- 全文索引 :全文索引的类型为 fulltext 全文索引可以在varchar,char,text类型上创建
- 组合索引 : 多列值组成一个索引,专门用于组合索引
例 :创建索引: alter table staffs add index idx_nap(name,age,pos)
组合索引(a,b,c)的使用情况(范围后不在使用索引):

索引的匹配方式:
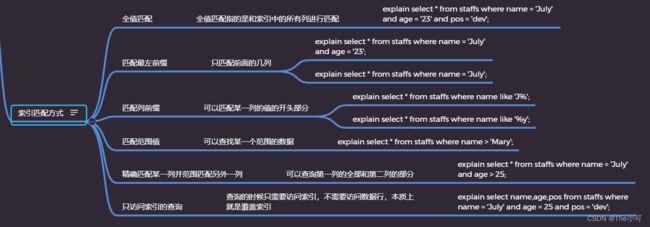
3. 存储引擎的对比:
一次磁盘IO读取 4页 16k
| MyISAM | InnoDB | |
|---|---|---|
| 索引类型 | 非聚簇索引 | 聚簇索引 |
| 支持事务 | 否 | 是 |
| 支持表锁 | 是 | 是 |
| 支持行锁 | 否 | 是 |
| 支持外键 | 否 | 是 |
| 支持全文索引 | 是 | 是(5.6后支持) |
| 适合操作类型 | 大量select | 大量 insert,delete,update |
| 数据结构 | B+树 | B+树 |
memory存储引擎的数据结构为 : hash表
4.MySQL面试专业术语:
-
回表 (普通索引才存在): 为非主键属性创建索引时,在普通索引B+树中,叶子节点存储的是该行的主键,需要通过主键再次查找主键索引的 B+树,从而得到所有的数据的过程(回表 : 再次查找主键索引的B+树获得该行的全部数据)
-
覆盖索引 :不需要回表 ,如 select id from table 可以直接从主键索引查找到 id ,就不在需要回表查找其他详细了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BnDKYUPX-1651719631481)(C:\Users\HP\Desktop\学习方向\mysql数据库\索引\覆盖索引.PNG)]
-
最左匹配 : 对于组合索引(name,age)会有最左匹配原则 ,会匹配的又 (name,age),(name),如能匹配的有 1,2,4( 4能匹配是因为MySQL优化器将name放到前面匹配)
1. select * from t1 where name = "z";
2. select * from t1 where name = "z" and age=10;
3. select * from t1 where age=10;
4. select * from t1 where age=10 and name = "z";
-
谓词下推 :如 select t1.name,t2.name from t1 join t2 on t1.id=t2.id 的步骤 :先把两张表需要的4个字段取出,然后再做表单关联
-
索引下推 (在存储引擎过滤,再返回):对于组合索引(name,age) 直接从存储索引拉取数据的时候直接按照name和age做判断,将符合的结果返回给MySQLServer (5.7 之后有的)
注意: select * from t where age>10 and name = "z"; age会走索引,但name不会走索引 (范围查询后面的都不会走索引)
聚簇索引(InnoDB):不是单独的索引类型,而是一种数据存储方式,指的是数据行和相邻的键值紧凑的存储在一起。
非聚簇索引(MyISAM):数据文件和索引文件分开存放。
聚簇索引的优缺点:

6.hash索引
memory 存储引擎使用
数据结构 : hash表
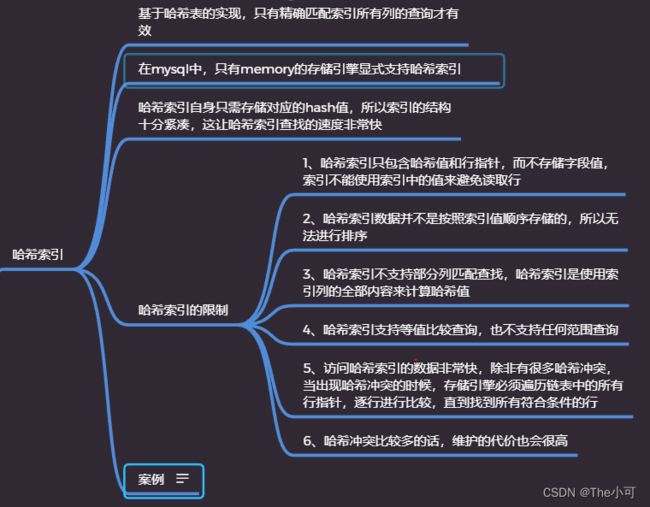
应用场景 : 存储索引占用个很大的空间时使用
当需要存储大量的URL,并且根据URL进行搜索查找,如果使用B+树,存储的内容就会很大
select id from url where url=""
也可以利用将url使用CRC32冗余校验做哈希,可以使用以下查询方式:
select id fom url where url="" and url_crc=CRC32("")
此查询性能较高原因是使用体积很小的索引来完成查找
7. 优化细节:

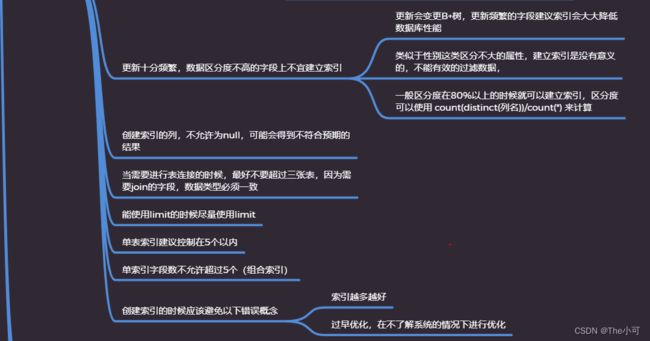
join的方式:
7.1 : Nested-Loop Join Algorithm (嵌套)
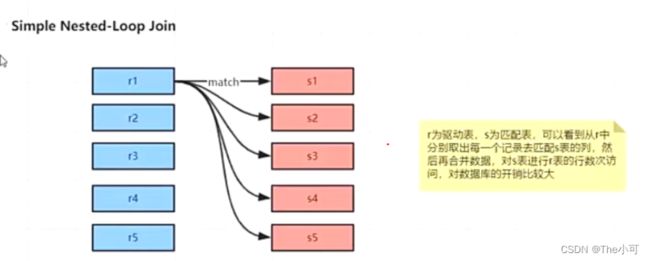
7.2 Index nested-Loop Join (有索引的情况)
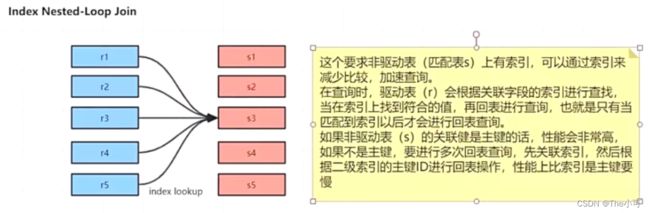
区分驱动表和非驱动表: 如 A join B(读取数据是不一定先读A再读B,但可以指定 A constraint join B 强制指定先读A再B)
7.3 Block Nested-Loop Join(没有索引的情况)
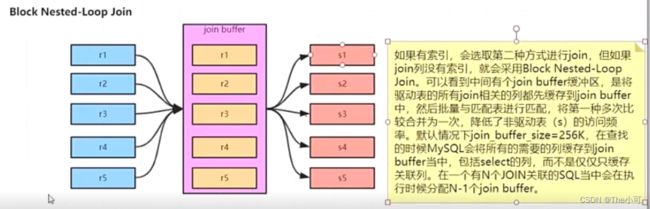
缺点: Join buffer 大小有限: 默认256MB
join连接中and 和 where 的区别
- select * from t1 join t2 on t1=id=t2.id and t1.name="z";
- select * from t1 join t2 on t1=id=t2.id where t1.name="z";
and(不参与join运算)是在表连接前过滤 A表或B表 里哪些记录符合连接条件,同时会兼顾是 left join 还是 right join,如果是左连接的话,左表的某条记录不符合连接条件,那么它不进行连接,但是任然会留在结果集中(此时右边的连接结果为NULL)。
on 条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左表的记录
8. 索引监控:
大概监控:
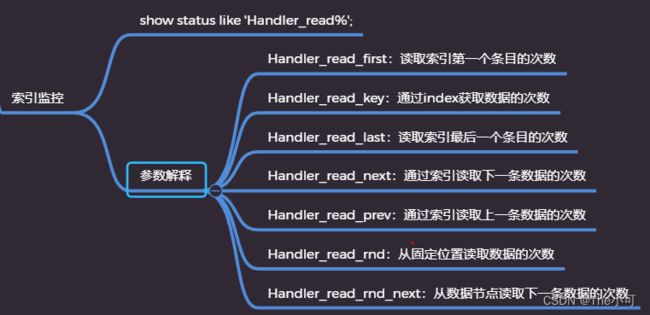
Handler_read_key 和 Handler_read_rnd_next 越达越好(使用索引查找数据的次数)
limit对于大数据量(而又只取几条数据)的调优:
select * from rental a join (select id from rental limit 100000,5) b on a.id = b.id ; //查主键索引树相对较快