什么是缓存架构,什么又是后端分布式多级缓存架构,全文解析
缓存,已经是一个老生常谈的技术了,在高并发读的情况下对于读服务来说可谓是抗流量的银弹。
高并发三大利器:缓存、限流、降级。
今天我们就来谈谈缓存。对于缓存,我的理解是让数据更接近于用户,目的是让用户的访问速度更快。 所以距离越接近用户的缓存,越快越有效!缓存的工作原理是先从缓存中获取数据,如果有数据则直接返回给用户,如果没有数据则从慢速设备上读取实际数据并且将数据放入缓存。
按照层级关系,我们来划分一下缓存,同时也是我们今天的大纲:
浏览器缓存
浏览器是我们网上冲浪的重要工具,为了能够让我们顺畅的冲浪,它也会帮助我们缓存一些东西,主要存放一些实时性不太敏感的数据,比如商品详情页框架、商家评分、评价、广告词等。对于实时性要求高的数据则不能使用浏览器缓存。浏览器缓存是有过期时间的,我们可以通过对响应头Expires、Cache-control进行控制。
客户端缓存
客户端缓存很容易理解,意思就是存放在客户端的缓存。它的使用场景不多,在我们大促的时候,为了防止瞬间流量把服务端击垮,一般会在大促来临之前把app需要访问的一些素材(如js/css/image等)提前下发到客户端进行缓存,在大促来临之际app就不需要去拉取这些素材了。另外的话还有一些兜底数据或者样式文件也会存放于客户端缓存中,在服务端异常或者网络异常的时候保证app不崩。
CDN缓存
CDN(Content Delivery Network),即内容分发网络。它是建立并覆盖在承载网之上,由分布在不同区域的边缘节点服务器群组成的分布式网络。我们通常会将一些静态页面数据、活动页面、图片等数据存放于CDN缓存中。
CDN缓存有两种机制:推送机制(当内容变更后主动将数据推送到CDN节点)和拉取机制(先访问CDN节点,无数据的时候会从源服务器获取数据返回并存储CDN节点)
举个例子,如果你要去买汽车,你应该是到4s店去买汽车,如果4s店有你可以直接提走,如果4s店没有,那么4s店铺需要去进一批货,然后回到店铺,然后再给你。在这个case中,4s店其实就承当了一个CDN缓存节点的角色。
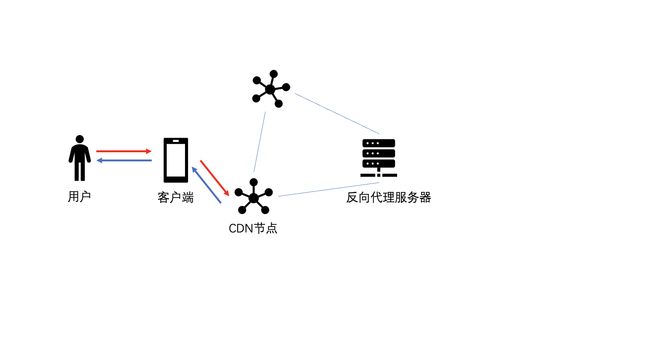
反向代理缓存
反向代理,我们一般情况都是指反向代理服务器Nginx。
Nginx缓存主要分为Nginx Http缓存与Nginx代理层缓存。
Nginx Http缓存提供expires、etag、if-modified-since指令来实现反向代理缓存。Nginx代理层缓存主要以Http模块与proxy_cacahe模块进行配置即可。
本地缓存
本地缓存,一般是指将客户机本地的物理内存划分出一部分空间用来缓冲客户机回写到服务器的数据。从全局的角度,我们可以有磁盘缓存、CPU缓存、应用缓存。
磁盘缓存分为读缓存和写缓存。
读缓存是指,操作系统为已读取的文件数据,在内存较空闲的情况下留在内存空间中(这个内存空间被称之为“内存池”),当下次软件或用户再次读取同一文件时就不必重新从磁盘上读取,从而提高速度。
写缓存实际上就是将要写入磁盘的数据先保存于系统为写缓存分配的内存空间中,当保存到内存池中的数据达到一个程度时,便将数据保存到硬盘中。
CPU缓存可以分为一级缓存(L1 Cache)、二级三级缓存(L2/L3)。当CPU要读取一个数据时,首先从L1中查找,没有的话再从L2/L3中查找,如果还没有那就从内存中查找,内存如果还没有那就从磁盘查找。查找顺序为:CPU->L1->L2/L3->内存->磁盘。
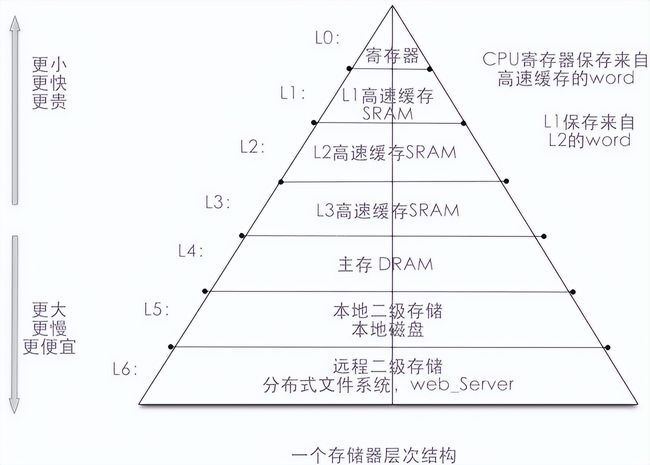
应用缓存分为本地应用缓存与其他应用缓存。
本地应用缓存指的是本服务所使用的缓存,用Java服务来举例,又分为 堆内缓存 与 堆外缓存 。
堆内缓存,一般指的是Java堆的缓存对象,堆内缓存的好处是不需要序列化/反序列化,也是最快的缓存,缺点也很明显,缓存数据多的时候,GC(垃圾回收)的频率会增大,时间会加长。堆内缓存一般使用软引用/弱引用来引用对象,使用这两种引用的好处是当堆内存不足时,可以强制回收这部分内存,释放堆空间。堆内缓存最大的问题是重启时内存中的缓存数据会丢失,如果堆内缓存使用的多,再加上刚好流量风暴,有可能击垮应用。堆内缓存的实现一般有:Guava Cache、Ehcache等。
堆外缓存,这个听说的同学比较少,它处于Java堆之外的内存,不受GC控制,也不受限堆大小,只受限于机器内存,所以,使用它一定小心谨慎,如果处理不当它可能存在内存泄漏的风险!堆外内存需要序列化/反序列化,所以它会比堆内缓存慢一些。
其他应用缓存,指的是除了本服务之外的缓存,比如local redis cache。local redis cache指的是在本服务器上部署一组Redis,应用直接读本机获取缓存数据,多机之间利用主从机制同步数据。这种方式的优点是没有网络消耗,性能是最优的。
分布式缓存
如果数据量不大的情况下,使用local redis cache的架构是最优的。
使用local redis cache最大的问题是
- 单机器容量问题
- 多实例数据一致性问题
- 多实例缓存命中率降低导致回源DB
如果遇到这样的问题,那么应该将数据分片,尽可能的均匀分布到多台服务器,这便是分布式缓存。
分布式缓存常见的分片策略有:
- 节点取余
- 一致性哈希
- 虚拟槽分区
我们最常见的Redis-Cluster集群则是使用虚拟槽分区的方式来对数据分片的。
我们点到即止,对于Redis缓存相关,后面会有很多文章来专门讨论,敬请期待吧。
其他:缓存命中率
缓存命中率是我们非常重要的一个指标,我们如果使用缓存,一定需要通过监控这个指标来看缓存的工作状态。
它的计算方式为:
命中率缓存命中次数读取总次数
缓存命中率越高越好,如何提高缓存命中率呢?我们应该对于不同场景数据有不同的缓存策略,比如:
- 大促来临之际应该提前将热点数据缓存,这种方式我们称之为缓存预热或缓存热加载;
- 在case1的基础上,将热点缓存数据与普通缓存数据做数据隔离,这一点前期需要人为干预,后期需要实时热点发现;
- 将数据分类,不同类别的数据配置合适的失效时间;
- 调整缓存粒度,通常情况下缓存粒度越小缓存命中率越高;
- 增大存储容量,当容量不够的时候会触发过期策略导致部分缓存数据失效,从而影响缓存命中率;
缓存问题:缓存穿透
[一句话概述]缓存穿透是指数据库和缓存都没有的数据,每次都要经过缓存去访问数据库,大量的请求有可能导致DB宕机。(强调都没有数据+并发访问)
这里我继续点到即止,后续奉上,敬请期待
缓存问题:缓存击穿
[一句话概述]缓存击穿是指数据库有,缓存没有的数据,大量请求访问这个缓存不存在的数据,最后请求打到DB可能导致DB宕机。(强调单个Key过期+并发访问)
这里我继续点到即止,后续奉上,敬请期待
缓存问题:缓存雪崩
[一句话概述]缓存雪崩是指数据库有,缓存没有的数据,大量请求访问这些缓存不存在的数据,最后请求打到DB可能导致DB宕机。(强调批量Key过期+并发访问)
这里我继续点到即止,后续奉上,敬请期待
缓存问题:缓存一致性
[一句话概述]缓存一致性指的是缓存与DB之间的数据一致性,我们需要通过各种手段来防止缓存与DB不一致,我们要保证缓存与DB的数据一致或者数据最终一致。
这里我继续点到即止,后续奉上,敬请期待
缓存的其他问题
缓存的好处我们非常受益,用户的每一次请求都伴随着无数缓存的诞生,但是缓存同时也给我们带来了不小的挑战,比如在上面提到的一些疑难课题:缓存穿透、缓存击穿、缓存雪崩和缓存一致性。
除此之外,我们还会涉及到其他的一些缓存难题,如:缓存倾斜、缓存阻塞、缓存慢查询、缓存主从一致性问题、缓存高可用、缓存故障发现与故障恢复、集群扩容收缩、大Key热Key......
分布式多级缓存架构的终章,如何解决大流量、高并发这样的业务场景,取决于你能不能成为这个领域金字塔上层的高手? 能不能把这个问题思考清楚决定了你的成长速度。
很多人在一个行业5年、10年,依然未达到这个行业的中层甚至还停留在底层,因为他们从来不关心这样的话题。作为砥砺前行的践行者,我觉得有必要给大家来分享一下。

开篇
服务端缓存是整个缓存体系中的重头戏,从开始的网站架构演进中,想必你已看到服务端缓存在系统性能的重要性。
但数据库确是整个系统中的“半吊子|慢性子”,有时数据库调优却能够以小搏大,在不改变架构和代码逻辑的前提下,缓存参数的调整往往是条捷径。
在系统开发的过程中,可直接在平台侧使用缓存框架,当缓存框架无法满足系统对性能的要求时,就需要在应用层自主开发应用级缓存。
缓存常用的就是Redis这东西,那到底什么是平台级、应用级缓存呢?
后面给大家揭晓。但有一点可表明,平台级就是你所选择什么开发语言来实现缓存,而应用级缓存,则是通过应用程序来达到目的。
01数据库缓存
为何说数据库是“慢性子”呢? 对现在喜欢快的你来说,慢是解决不了问题的。就好像总感觉感觉妹子回复慢
因为数据库属于IO密集型应用,主要负责数据的管理及存储。数据一多查询本身就有可能变慢, 这也是为啥数据上得了台面时,查询爱用索引提速的原因。当然数据库自身也有“缓存”来解决这个问题。
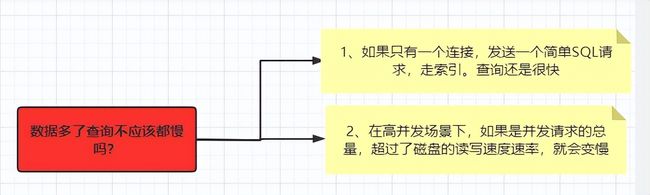
数据多了查询不应该都慢吗? 小白说吒吒辉你不懂额
。。。这个,你说的也不全是,还得分情况。例如:数据有上亿行
原因:
- 因为简单的SQL的结果不会特别多。你请求也不大,磁盘跟的上
- 并发总量超过磁盘吞吐上限,是谁都没招
就算你们不喜欢吒吒辉,我也要奋笔疾书
数据库缓存是自身一类特殊的缓存机制。大多数数据库不需要配置就可以快速运行,但并没有为特定的需求进行优化。在数据库调优的时候,缓存优化你可以考虑下。
以MySQL为例,MySQL中使用了查询缓冲机制,将SELECT语句和查询结果存放在缓冲区中,以键值对的形式存储。以后对于同样的SELECT语句,将直接从缓冲区中读取结果,以节省查询时间,提高了SQL查询的效率。
1.1.MySQL查询缓存
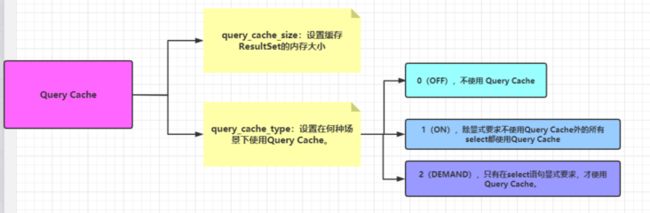
Query cache作用于整个MySQL实例,主要用于缓存MySQL中的ResultSet,也就是一条SQL语句执行的结果集,所以它只针对select语句。
当打开 Query Cache 功能,MySQL在接收到一条select语句的请求后,如果该语句满足Query Cache的条件,MySQL会直接根据预先设定好的HASH算法将接收到的select语句以字符串方式进行 hash,然后到Query Cache中直接查找是否已经缓存。

如果结果集已经在缓存中,该select请求就会直接将数据返回,从而省略后面所有的步骤(如SQL语句的解析,优化器优化以及向存储引擎请求数据等),从而极大地提高了性能。
当然,若数据变化非常频繁的情况下,使用Query Cache可能会得不偿失。
这是为啥,用它不是提速吗?咋还得不偿失
因为MySQL只要涉及到数据更改,就会重新维护缓存。
- 如果SQL请求量比较大,你在维护的时候,就透过缓存走磁盘检索。这样数据库的压力肯定大。
- 重建缓存数据,它需要mysql后台线程来工作。也会增加数据库的负载。
所以在MySQL8已经取消了它。 故一般在读多写少,数据不怎么变化的场景可用它,例如:博客
Query Cache使用需要多个参数配合,其中最为关键的是query_cache_size和query_cache_type, 前者用于设置缓存ResultSet的内存大小,后者设置在何种场景下使用Query Cache。
这样可以通过计算Query Cache的命中率来进行调整缓存大小。
1.2.检验Query Cache的合理性
检查Query Cache设置的是否合理,可以通过在MySQL控制台执行以下命令观察:
- SHOW VARIABLES LIKE '%query_cache%';
- SHOW STATUS LIKE 'Qcache%'; 通过检查以下几个参数可以知道query_cache_size设置得是否合理:
- Qcache_inserts:表示Cache多少次未命中然后插入到缓存
- Qcache_hits: 表示命中多少次,它可反映出缓存的使用效果。
如果Qcache_hits的值非常大,则表明查询缓冲使用非常频繁,如果该值较小反而会影响效率,那么可以考虑不用查询缓存;
- Qcache_lowmem_prunes: 表示多少条Query因为内存不足而被清除出Query_Cache。
如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况,因增加缓存容量。
- Qcache_free_blocks: 表示缓存区的碎片
Qcache_free_blocks值非常大,则表明缓存区中的碎片很多,可能需要寻找合适的机会进行整理。
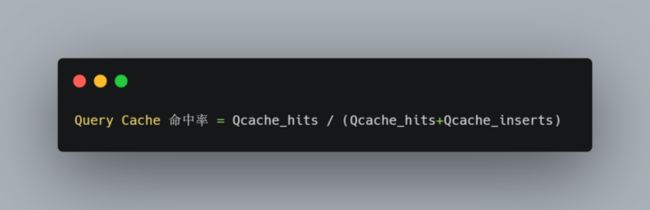
通过 Qcache_hits 和 Qcache_inserts 两个参数可以算出Query Cache的命中率:
通过 Qcache_lowmem_prunes 和 Qcache_free_memory 相互结合,能更清楚地了解到系统中Query Cache的内存大小是否真的足够,是否频繁的出现因内存不足而有Query被换出的情况。
1.3.InnoDB的缓存性能
当选择 InnoDB 时,innodb_buffer_pool_size 参数可能是影响性能的最为关键的一个参数,它用来设置缓存InnoDB索引及数据块、自适应HASH、写缓冲等内存区域大小,更像是Oracle数据库的 db_cache_size。
简单来说,当操作InnoDB表的时候,返回的所有数据或者查询过程中用到的任何一个索引块,都会在这个内存区域中去查询一遍。
和MyISAM引擎中的 key_buffer_size 一样,innodb_buffer_pool_size设置了 InnoDB 引擎需求最大的一块内存区域,直接关系到InnoDB存储引擎的性能,所以如果有足够的内存,尽可将该参数设置到足够大,将尽可能多的InnoDB的索引及数据都放入到该缓存区域中,直至全部。
说到缓存肯定少不了,缓存命中率。那innodb该如何计算?
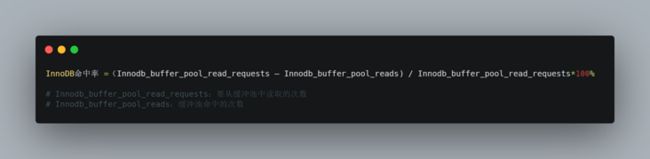
计算出缓存命中率后,在根据命中率来对
`
innodb_buffer_pool_size 参数大小进行优化`
除开查询缓存。数据库查询的性能也与MySQL的连接数有关
table_cache 用于设置 table 高速缓存的数量。
show global status like 'open%_tables'; # 查看参数
由于每个客户端连接都会至少访问一个表,因此该参数与max_connections有关。当某一连接访问一个表时,MySQL会检查当前已缓存表的数量。
如果该表已经在缓存中打开,则会直接访问缓存中的表以加快查询速度;如果该表未被缓存,则会将当前的表添加进缓存在进行查询。
在执行缓存操作之前,table_cache参数用于限制缓存表的最大数目:
如果当前已经缓存的表未达到table_cache数目,则会将新表添加进来;若已经达到此值,MySQL将根据缓存表的最后查询时间、查询率等规则释放之前的缓存。
02平台级缓存
什么是平台级缓存,说的这个玄乎?
平台级缓存是指你所用什么开发语言,具体选择的是那个平台,毕竟缓存本身就是提供给上层调用。主要针对带有缓存特性的应用框架,或者可用于缓存功能的专用库。
如:
- PHP中的Smarty模板库
- Java中,缓存框架更多,如Ehcache,Cacheonix,Voldemort,JBoss Cache,OSCache等等。
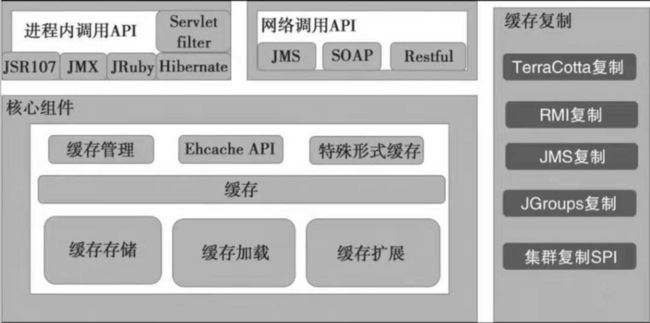
Ehcache是现在最流行的纯Java开源缓存框架,配置简单、结构清晰、功能强大,是从hibernate的缓存开始被广泛使用起来的。EhCache有如下特点:

Ehcache的系统结构如图所示:
什么是分布式缓存呢?好像我还没搞明白,小吒哥
首先得看看恒古不变的“分布式”,即它是独立的部署到多个服务节点上或者独立的进程,彼此之间仅仅通过消息传递进行通信和协调。
也就是说分布式缓存,它要么是在单机上有多个实例,要么就独立的部署到不同服务器,从而把缓存分散到各处
最后通过客户端连接到对应的节点来进行缓存操作。
Voldemort是一款基于Java开发的分布式键-值缓存系统,像JBoss的缓存一样,Voldemort同样支持多台服务器之间的缓存同步,以增强系统的可靠性和读取性能。
Voldemort有如下特点:

Voldemort的逻辑架构图
Voldemort相当于是Amazon Dynamo的一个开源实现,LinkedIn用它解决了网站的高扩展性存储问题。
简单来说,就平台级缓存而言,只需要在框架侧配置一下属性即可,而不需要调用特定的方法或函数。
系统中引入缓存技术往往就是从平台级缓存开始,平台级缓存也通常会作为一级缓存使用。
既然平台级缓存都使用框架配置来实现,这咋实现缓存的分布式呢?节点之间都没有互相的消息通讯了
如果单看,框架缓存的调用,那确实没办法做到分布式缓存,因为自身没得像Redis那样分布式的部署方式,通过网络把各节点连接 。
但本地平台缓存可通过远程过程调用,来操作分布在各个节点上的平台缓存数据。
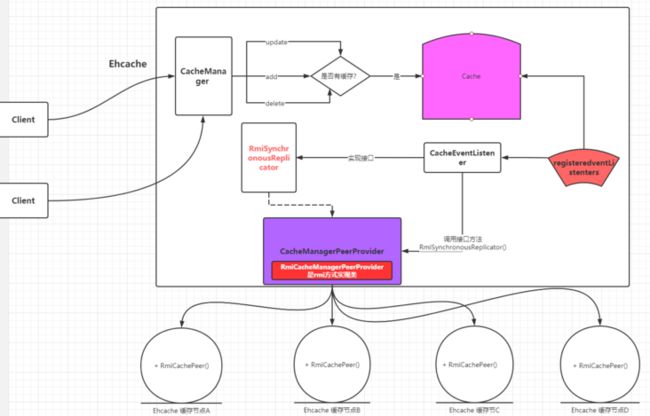
在 Ehcache 中:
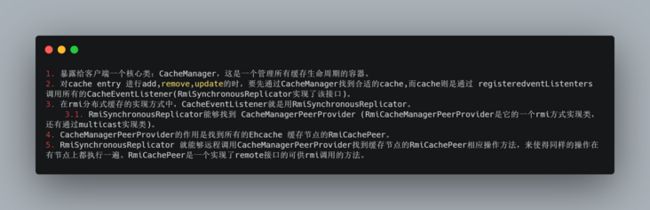
03应用级缓存
当平台级缓存不能满足系统的性能时,就要考虑使用应用级缓存。 应用级缓存,需要开发者通过代码来实现缓存机制。
有些许 一方有难,八方支援 的感觉。自己搞不定 ,请教别人
这是NoSQL的战场,不论是Redis还是MongoDB,以及Memcached都可作为应用级缓存的技术支持。
一种典型的方式是每分钟或一段时间后统一生成某类页面存储在缓存中,或者可以在热数据变化时更新缓存。
为啥平台缓存还不能满足系统性能要求呢?它不是还可以减少应用缓存的网络开销吗
那你得看这几点:

3.1面向Redis的缓存应用
Redis是一款开源的、基于BSD许可的高级键值对缓存和存储系统,例如:新浪微博有着几乎世界上最大的Redis集群。
为何新浪微博是世界上最大的Redis集群呢?
微博是一个社交平台,其中用户关注与被关注、微博热搜榜、点击量、高可用、缓存穿透等业务场景和技术问题。Redis都有对应的hash、ZSet、bitmap、cluster等技术方案来解决。
在这种数据关系复杂、易变化的场景上面用到它会显得很简单。比如:
用户关注与取消:用hash就可以很方便的维护用户列表,你可以直接找到key,然后更改value里面的关注用户即可。
如果你像 memcache ,那只能先序列化好用户关注列表存储,更改在反序列化。然后再缓存起来,像大V有几百万、上千万的用户,一旦关注/取消。
当前任务的操作就会有延迟。
Reddis主要功能特点
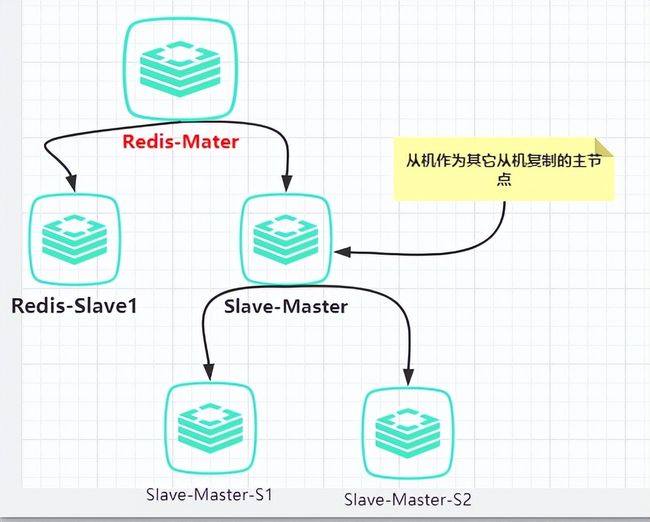
- 主从同步
Redis支持主从同步,数据可以从主服务器向任意数量的从服务器同步,从服务器可做为关联其他从服务器的主服务器。这使得Redis可执行单层树状复制。
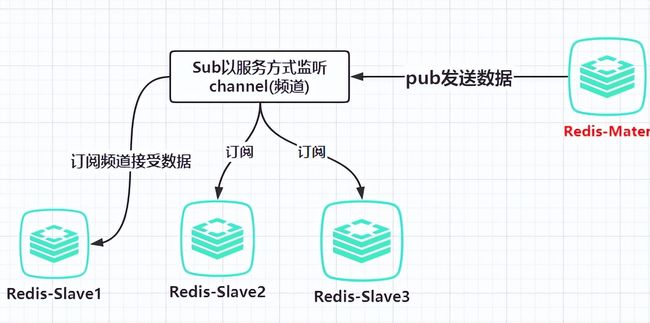
- 发布/订阅
由于实现了发布/订阅机制,使得从服务器在任何地方同步树的时候,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
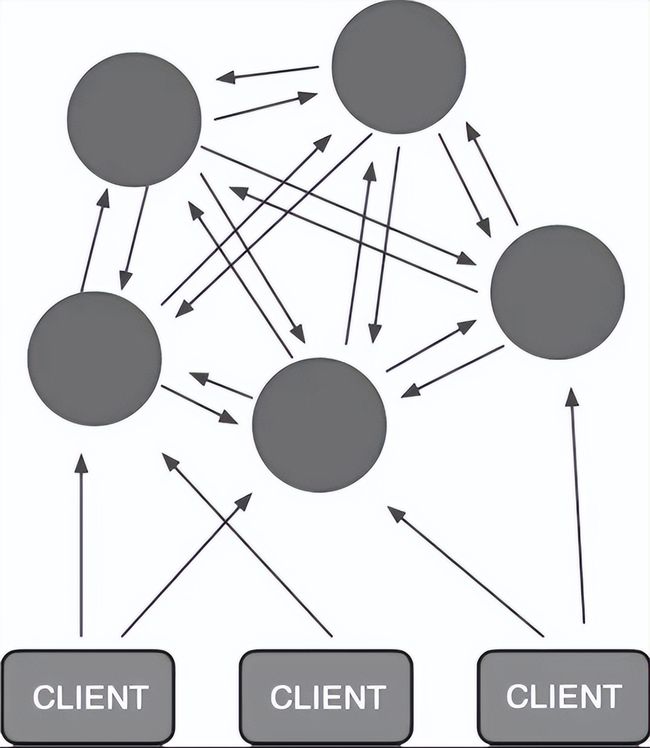
- 集群
Redis 3.0版本加入cluster功能,解决了Redis单点无法横向扩展的问题。Redis集群采用无中心节点方式实现,无需proxy代理,客户端直接与Redis集群的每个节点连接,根据同样的哈希算法计算出key对应的slot,然后直接在slot对应的Redis上执行命令。
从Redis视角来看,响应时间是最苛刻的条件,增加一层带来的开销是不能接受的。因此,Redis实现了客户端对节点的直接访问,为了去中心化,节点之间通过Gossip协议交换相互的状态,以及探测新加入的节点信息。Redis集群支持动态加入节点,动态迁移slot,以及自动故障转移。
Redis集群的架构示意如图所示。
那什么是 Gossip 协议呢? 感觉好高大上,各种协议频繁出现
Gossip 协议是一个多播协议,基本思想是:
一个节点想要分享一些信息给网络中的其他的一些节点。于是,它周期性的随机选择一些节点,并把信息传递给这些节点。这些收到信息的节点接下来会做同样的事情,即把这些信息传递给其他一些随机选择的节点。直至全部的节点。
即,Redis集群中添加、剔除、选举主节点,都是基于这样的方式。
例如:当加入新节点时(meet),集群中会随机选择一个节点来邀请新节点,此时只有邀请节点和被邀请节点知道这件事,其余节点要等待 ping 消息一层一层扩散。
除了 Fail 是立即全网通知的,其他诸如新节点、节点重上线、从节点选举成为主节点、槽变化等,都需要等待被通知到,所以Gossip协议也是最终一致性的协议。
这种多播的方式,是不是忽然有种好事不出门,坏事传千里的感脚
然而,Gossip协议也有不完美的地方,例如,拜占庭问题(Byzantine)。即,如果有一个恶意传播消息的节点,Gossip协议的分布式系统就会出问题。
注:Redis集群节点通信消息类型

所有的Redis节点通过PING-PONG机制彼此互联,内部使用二进制协议优化传输速度和带宽。
这个ping为啥能提高传输速度和带宽? 感觉不大清楚,小吒哥。那这里和OSI网络层级模式有关系了
在OSI网络层级模型下,ping协议隶属网络层,所以它会减少网络层级传输的开销,而二进制是用最小单位0,1表示的位。
带宽是固定的,如果你发送的数据包都很小,那传输就很快,并不会出现数据包很大还要拆包等复杂工作。
相当于别人出差1斤多MacPro。你出差带5斤的战神电脑。
Redis的瓶颈是什么呢? 吒吒辉给安排
Redis本身就是内存数据库,读写I/O是它的强项,瓶颈就在单线程I/O上与内存的容量上。 目前已经有多线程了,
例如:Redis6具备网络传输的多线程模式,keydb直接就是多线程。
啥? 还没了解多Redis6多线程模式,后面单独搞篇来聊聊
集群节点故障如何发现?
节点故障是通过集群中超过半数的节点检测失效时才会生效。客户端与Redis节点直连,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
Redis Cluster把所有的物理节点映射到slot上,cluster负责维护node、slot和value的映射关系。当节点发生故障时,选举过程是集群中所有master参与的,如果半数以上master节点与当前master节点间的通信超时,则认为当前master节点挂掉。
这为何不没得Slave节点参与呢?
集群模式下,请求在集群模式下会自动做到读写分离,即读从写主。但现在是选择主节点。只能由主节点来进行身份参与。
毕竟集群模式下,主节点有多个,每个从节点只对应一个主节点,那这样,你别个家的从节点能够参与选举整个集群模式下的主节点吗?
就好像小姐姐有了对象,那就是名花有主,你还能在有主的情况下,去选一个? 小心遭到社会的毒打
如果集群中超过半数以上master节点挂掉,无论是否有slave集群,Redis的整个集群将处于不可用状态。
当集群不可用时,所有对集群的操作都不可用,都将收到错误信息:
[(error)CLUSTERDOWN The cluster is down]。
支持Redis的客户端编程语言众多,可以满足绝大多数的应用,如图所示。
3.2.多级缓存实例
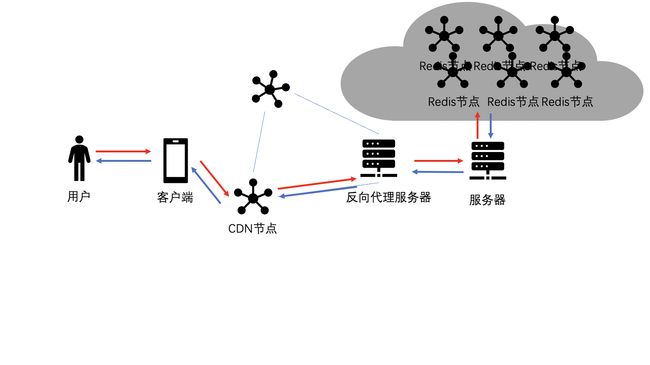
一个使用了Redis集群和其他多种缓存技术的应用系统架构如图所示

负载均衡
首先,用户的请求被负载均衡服务分发到Nginx上,此处常用的负载均衡算法是轮询或者一致性哈希,轮询可以使服务器的请求更加均衡,而一致性哈希可以提升Nginx应用的缓存命中率。
什么是一致性hash算法?
hash算法计算出的结果值本身就是唯一的,这样就可以让每个用户的请求都落到同一台服务器。
默认情况下,用户在那台在服务器登录,就生成会话session文件到该服务器,但如果下次请求重新分发给其他服务器就又需要重新登录。
而有了一致性hash算法就可以治愈它,它把请求都专心交给同一台服务器,铁打的专一,从而避免上述问题。 当然这里的一致性hash原理就没给大家讲了。后面安排
nginx本地缓存
请求进入到Nginx应用服务器,首先读取本地缓存,实现本地缓存的方式可以是Lua Shared Dict,或者面向磁盘或内存的 Nginx Proxy Cache,以及本地的Redis实现等,如果本地缓存命中则直接返回。
这本地缓存怎么感觉那么特别呢? 好像你家附近的小姐姐,离得这么近,可惜吃不着。呸呸呸,跑题啦
- Lua Shard Dict是指在nginx上,通过lua开辟一块内存空间来存储缓存数据。相当于用的是nginx的进程资源
- nginx Cache指nginx获取上游服务的数据缓存到本地。
- 本地Redis指nginx和Redis部署在同一台服务上,由nginx直接操作Redis
啥! nginx还可直接操作Redis呀,听我细细到来
这些方式各有千秋,Lua Shard Dict 是通过Lua脚本控制缓存数据的大小并可以灵活的通过逻辑处理来修改相关缓存数据。
而Nginx Proxy Cache开发相对简单,就是获取上游数据到本地缓存处理。 而本地Redis则需要通过lua脚本编写逻辑来设置,虽然操作繁琐了,但解决了本地内存局限的问题。
所以nginx操作Redis是需要借助于 Lua 哒
nginx本地缓存有什么优点?
Nginx应用服务器使用本地缓存可以提升整体的吞吐量,降低后端的压力,尤其应对热点数据的反复读取问题非常有效。
本地缓存未命中时如何解决?
如果Nginx应用服务器的本地缓存没有命中,就会进一步读取相应的分布式缓存——Redis分布式缓存的集群,可以考虑使用主从架构来提升性能和吞吐量,如果分布式缓存命中则直接返回相应数据,并回写到Nginx应用服务器的本地缓存中。
如果Redis分布式缓存也没有命中,则会回源到Tomcat集群,在回源到Tomcat集群时也可以使用轮询和一致性哈希作为负载均衡算法。

那我是PHP技术栈咋办?都不会用到java的Tomcat呀
nginx常用于反向代理层。而这里的Tomcat更多是属于应用服务器,如果换成PHP,那就由php-fpm或者swoole服务来接受请求。即不管什么语言,都应该找对应语言接受请求分发的东西。
当然,如果Redis分布式缓存没有命中的话,Nginx应用服务器还可以再尝试一次读主Redis集群操作,目的是防止当从Redis集群有问题时可能发生的流量冲击。
这样的设计方案我在下表示看不懂
如果你网站流量比较大,如果一次在Redis分布式缓存中未读取到的话,直接透过到数据库,那流量可能会把数据库冲垮。这里的一次读主也是考虑到Redis集群中的主从延迟问题,为的就是防止缓存击穿。
在Tomcat | PHP-FPM集群应用中,首先读取本地平台级缓存,如果平台级缓存命中则直接返回数据,并会同步写到主Redis集群,在由主从同步到从Redis集群。
此处可能存在多个Tomcat实例同时写主Redis集群的情况,可能会造成数据错乱,需要注意缓存的更新机制和原子化操作。
如何保证原子化操作执行呢?
当多个实例要同时要写Redis缓存时,为了保持原子化,起码得在涉及这块业务多个的 Key 上采用lua脚本进行封装,然后再通过分布式锁或去重相同请求并入到一个队列来获取,让获取到锁或从队列pop的请求去读取Redis集群中的数据。
如果所有缓存都没有命中,系统就只能查询数据库或其他相关服务获取相关数据并返回,当然,我们已经知道数据库也是有缓存的。 是不是安排得明明白白。

这就是多级缓存的使用,才能保障系统具备优良的性能。
什么时候,小姐姐也能明白俺的良苦心。。。。 默默的独自流下了泪水
3.3.缓存算法
缓存一般都会采用内存来做存储介质,使用索引成本相对来说还是比较高的。所以在使用缓存时,需要了解缓存技术中的几个术语。
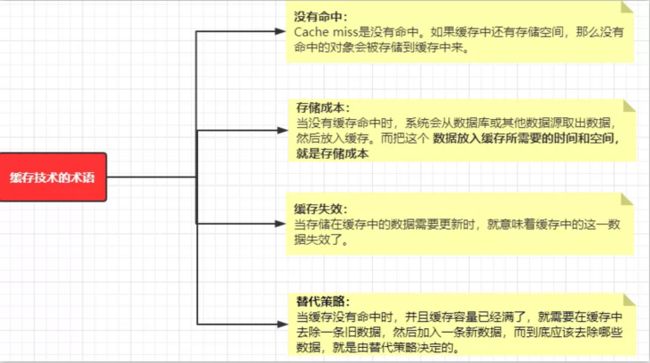
缓存淘汰算法
替代策略的具体实现就是缓存淘汰算法。
使用频率:
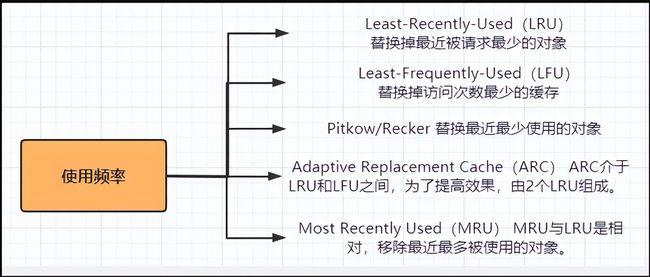
- Least-Recently-Used(LRU) 替换掉最近被请求最少的对象。
在CPU缓存淘汰和虚拟内存系统中效果很好。然而在直接应用与代理缓存中效果欠佳,因为Web访问的时间局部性常常变化很大。
浏览器就一般使用了LRU作为缓存算法。新的对象会被放在缓存的顶部,当缓存达到了容量极限,底部的对象被去除,方法就是把最新被访问的缓存对象放到缓存池的顶部。
- Least-Frequently-Used(LFU) 替换掉访问次数最少的缓存,这一策略意图是保留最常用的、最流行的对象,替换掉很少使用的那些数据。
然而,有的文档可能有很高的使用频率,但之后再也不会用到。传统的LFU策略没有提供任何移除这类文件的机制,因此会导致“缓存污染”,即一个先前流行的缓存对象会在缓存中驻留很长时间,这样,就阻碍了新进来可能会流行的对象对它的替代。
- Pitkow/Recker 替换最近最少使用的对象
除非所有对象都是今天访问过的。如果是这样,则替换掉最大的对象。这一策略试图符合每日访问Web网页的特定模式。这一策略也被建议在每天结束时运行,以释放被“旧的”、最近最少使用的对象占用的空间。
- Adaptive Replacement Cache(ARC) ARC介于LRU和LFU之间,为了提高效果,由2个LRU组成。
第一个包含的条目是最近只被使用过一次的,而第二个LRU包含的是最近被使用过两次的条目,因此,得到了新的对象和常用的对象。ARC能够自我调节,并且是低负载的。
- Most Recently Used(MRU) MRU与LRU是相对,移除最近最多被使用的对象。
当一次访问过来的时候,有些事情是无法预测的,并且在存系统中找出最少最近使用的对象是一项时间复杂度非常高的运算,这时会考虑MRU,在数据库内存缓存中比较常见。
访问计数
- Least Recently Used2 (LRU2)
LRU的变种,把被两次访问过的对象放入缓存池,当缓存池满了之后,会把有两次最少使用的缓存对象去除。
因为需要跟踪对象2次,访问负载就会随着缓存池的增加而增加。
- Two Queues(2Q) Two Queues是LRU的另一个变种。
把被访问的数据放到LRU的缓存中,如果这个对象再一次被访问,就把他转移到第二个、更大的LRU缓存,使用了多级缓存的方式。去除缓存对象是为了保持第一个缓存池是第二个缓存池的1/3。
当缓存的访问负载是固定的时候,把LRU换成LRU2,就比增加缓存的容量更好。
缓存容量算法
- SIZE 替换占用空间最大的对象,这一策略通过淘汰一个大对象而不是多个小对象来提高命中率。不过,可能有些进入缓存的小对象永远不会再被访问。SIZE策略没有提供淘汰这类对象的机制,也会导致“缓存污染”。
- LRU-Threshold 不缓存超过某一size的对象,其他与LRU相同。
- Log(Size)+LRU 替换size最大的对象,当size相同时,按LRU进行替换。
缓存时间
- Hyper-G LFU的改进版,同时考虑上次访问时间和对象size。
- Lowest-Latency-First 替换下载时间最少的文档。显然它的目标是最小化平均延迟。
缓存评估
- Hybrid Hybrid 有一个目标是减少平均延迟。
对缓存中的每个文档都会计算一个保留效用,保留效用最低的对象会被替换掉。位于服务器S的文档f的效用函数定义如下:
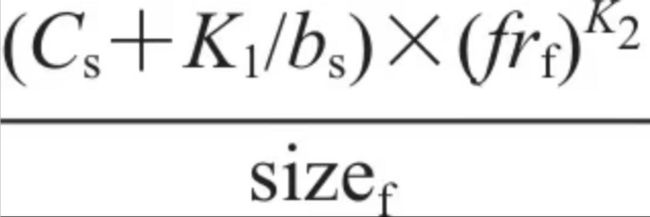
Cs是与服务器s的连接时间;
bs是服务器s的带宽;frf代表f的使用频率;sizef是文档f的大小,单位字节。K1和K2是常量,Cs和bs是根据最近从服务器s获取文档的时间进行估计的。
- Lowest Relative Value(LRV) LRV也是基于计算缓存中文档的保留效用,然后替换保留效用最低的文档。
随机与队列算法
- First in First out(FIFO)
FIFO通过一个队列去跟踪所有的缓存对象,最近最常用的缓存对象放在后面,而更早的缓存对象放在前面,当缓存容量满时,排在前面的缓存对象会被踢走,然后把新的缓存对象加进去。
- Random Cache 随机缓存就是随意的替换缓存数据,比FIFO机制好,在某些情况下,甚至比LRU好,但是通常LRU都会比随机缓存更好些。
还有很多的缓存算法,例如Second Chance、Clock、Simple time-based、Extended time-based expiration、Sliding time-based expiration……各种缓存算法没有优劣之分,不同的实际应用场景,会用到不同的缓存算法。在实现缓存算法的时候,通常会考虑使用频率、获取成本、缓存容量和时间等因素。
04.使用公有云的缓存服务

国内的共有云服务提供商如阿里云、青云、百度云等都推出了基于Redis的云存储服务,这些服务的有如下特点:
- 动态扩容:
用户可以通过控制面板升级所需Redis的存储空间,扩容过程中服务不需要中断或停止,整个扩容过程对用户是透明且无感知的,而自主使用集群解决Redis平滑扩容是个很烦琐的任务,现在需要用你的小手按几下鼠标就能搞定,大大减少了运维的负担。
- 数据多备:
数据保存在一主一备两台机器中,其中一台机器宕机了,数据还在另外一台机器上有备份。
- 自动容灾:
主机宕机后系统能自动检测并切换到备机上,实现了服务的高可用性。
- 成本较低:
在很多情况下,为使Redis的性能更好,需要购买一台专门的服务器用于Redis的存储服务,但这样会导致某些资源的浪费,购买Redis云存储服务就能很好地解决这样的问题。
有了Redis云存储服务,能使后台开发人员从烦琐的运维中解放出来。应用后台服务中,如果自主搭建一个高可用、高性能的Redis集群服务,是需要投入相当的运维成本和精力。
如果使用云服务,就没必要投入这些成本和精力,可以让后台应用的开发人员更专注于业务。
总结
更多java笔记资料,BAT大厂面试专题及答案,源码分析,分布式专题,并发编程,微服务架构,性能优化,数据结构与算法,后端开发,企业级落地实战等java笔记资料,直接后台小信封扣【999】撩我领取吧!
