2022吴恩达机器学习第二周
吴恩达老师机器学习课程笔记-第二周 - 知乎机器学习笔记Markdown文件(视频下载地址公布):https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes 笔记目录 第一周 第二周 第三周 第四周 第五周 第六周 第七周 第八周 第九周 第十周 第2周 四、多变量线性… https://zhuanlan.zhihu.com/p/43478657
https://zhuanlan.zhihu.com/p/43478657
5、多变量线性回归
5-1、多维变量
目前为止,我们探讨了单变量/特征的回归模型,现在我们对房价模型增加更多的特征,例如房间数楼层等,构成一个含有多个变量的模型,模型中的特征为 (x1,x2,x3,x4,,,xn)

增添更多特征后,我们引入一系列新的注释:
n 代表特征的数量
![]() 代表第i个训练实例,是特征矩阵中的第i行,是一个向量
代表第i个训练实例,是特征矩阵中的第i行,是一个向量
比如:
![]() =
=
![]() 代表特征矩阵中第 i 行的第 j 个特征,也就是第 i个训练样本的第 j 个特征。
代表特征矩阵中第 i 行的第 j 个特征,也就是第 i个训练样本的第 j 个特征。
如:
![]() =3
=3
支持多变量的假设 f 表示为:
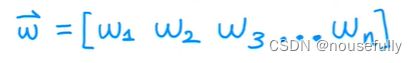
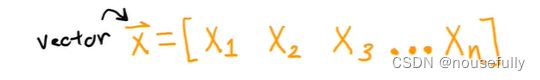

5-2、向量化

向量化的作用:提高计算效率

5-3、多变量梯度下降
与单变量线性回归类似,在多变量线性回归中,我们也构建一个代价函数,则这个代价函数是所有建模误差的平方和,即:
J(w1,w2,w3,,,,wn,b)=1/2m * 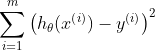 ,
,
多变量线性回归的批量梯度下降算法为:

def computeCost(X, y, theta):
inner = np.power(((X * w.T) - y), 2)
return np.sum(inner) / (2 * len(X))5-4、特征缩放 (特征工程-标准化)
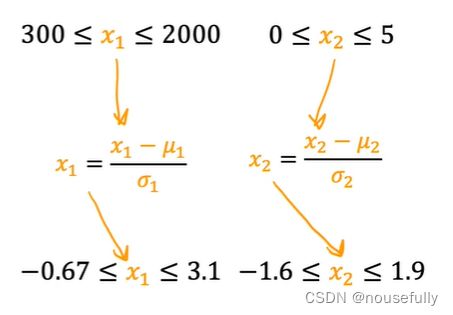
以房价问题为例,假设我们使用两个特征,房屋的尺寸和房间的数量,尺寸的值为 0-2000平方英尺,而房间数量的值则是0-5,以两个参数分别为横纵坐标,绘制代价函数的等高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。

解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间。如图:

最简单的方法是令: ![]() ,其中是
,其中是![]() 平均值, 是
平均值, 是 标准差。
标准差。
比如:
附加 标准差计算步骤:
1、找出平均值,数据加起来然后除以数据个数
2、再找出方差, 单个数据和平均数的差的平方 之和 除以个数
3、方差开方,加个根号 得到标准差
5-5、检查梯度下降是否收敛
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能提前预知,我们可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。

也有一些自动测试是否收敛的方法,例如将代价函数的变化值与某个阀值(例如0.001)进行比较,但通常看上面这样的图表更好。
梯度下降算法的每次迭代受到学习率的影响,如果学习率a 过小,则达到收敛所需的迭代次数会非常高;如果学习率 a过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。
通常可以考虑尝试些学习率:a=0.01, 0.03, 0.1, 0.3, 1, 3, 10
5-6、特征和多项式回归
线性回归并不适用于所有数据,有时我们需要曲线来适应我们的数据,比如一个二次方模型:
![]() 或者三次。
或者三次。
注意:如果我们采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要。
5-7、正规方程
到目前为止,我们都在使用梯度下降算法,但是对于某些线性回归问题,正规方程方法是更好的解决方案。如:
正规方程是通过求解下面的方程来找出使得代价函数最小的参数的:![]() =0.
=0.
假设我们的训练集特征矩阵为x,并且我们的训练集结果为向量y,则利用正规方程解出向量![]() 。
。
设矩阵A=![]() ,则
,则![]() =A-1
=A-1
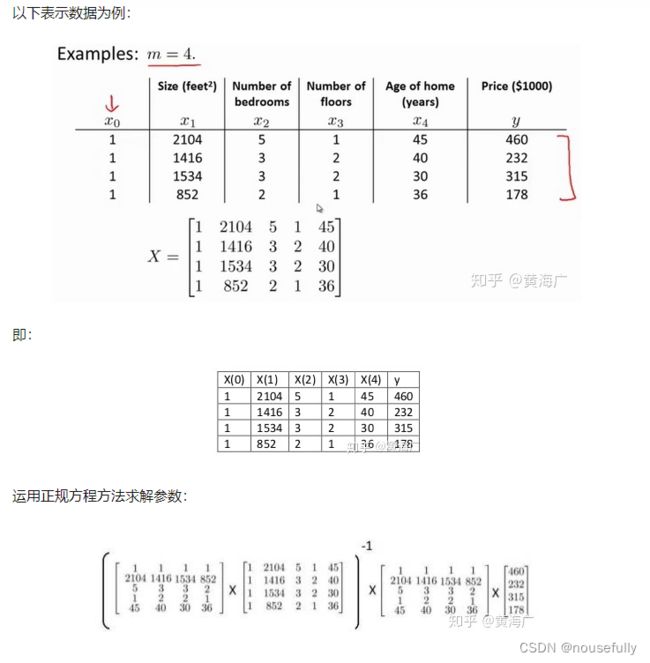
注:对于那些不可逆的矩阵(通常是因为特征之间不独立,如同时包含英尺为单位的尺寸和米为单位的尺寸两个特征,也有可能是特征数量大于训练集的数量),正规方程方法是不能用的。

总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数  的替代方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。
的替代方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。
随着我们要讲的学习算法越来越复杂,例如,当我们讲到分类算法,像逻辑回归算法,我们会看到,实际上对于那些算法,并不能使用标准方程法。对于那些更复杂的学习算法,我们将不得不仍然使用梯度下降法。因此,梯度下降法是一个非常有用的算法,可以用在有大量特征变量的线性回归问题。或者我们以后在课程中,会讲到的一些其他的算法,因为标准方程法不适合或者不能用在它们上。但对于这个特定的线性回归模型,标准方程法是一个比梯度下降法更快的替代算法。所以,根据具体的问题,以及你的特征变量的数量,这两种算法都是值得学习的。
正规方程的python实现:
import numpy as np
def normalEqn(X, y):
theta = np.linalg.inv(X.T@X)@X.T@y # X.T@X 等价于 X.T.dot(X)
return theta解题:

B

A

C

AB
注:matlab的从1开始,python的index从0开始,matlab的索引包含头尾,python的索引含头不含尾

A

AB

ABC
每个元素的平方而不是矩阵的平方,这两个完全不同

AB 总结:相同形状相乘只是相应位置相乘 不同形状相乘就是点积