行人重识别综述之Person Re-identification:Past, Present and Future
cvpr2016
https://arxiv.org/abs/1610.02984
0.1 REID 简介
0.1.1定义
“To re-identify a particular, then, is to identify
it as (numerically) the same particular as one
encountered on a previous occasion”
译:reid一个东西A就是在过去找找有没有A相似的(通过key值,在cv就是特征)
0.1.2流程
从技术上讲,视频监控中实际的person re-ID系统可以分为三个模块, 即人的检测、人的跟踪(单摄像头)和人的检索(跨摄像头)。通常认为,前两个模块是独立的计算机视觉任务, 因此大多数re-ID工作都集中在最后一个模块,即人的检索。 re-ID中最具挑战性的问题是如何正确地匹配同一人在敏感外观变化下的两个图像,例如照明、姿势和视角,其具有重要的科学价值。
0.1.3现状
早期的传统行人重识别方法是集中在手工提取特征(如纹理空间、颜色空间)、学习更好的相似度度量(如欧式距离、余弦距离)上,但是传统方法有一定的局限性,很难处理不同摄像头拍摄的行人存在的姿态、背景、光线、尺度不同等问题。行人重识别面临着许多挑战。目前,基于深度学习的行人重识别算法可按照提取图像特征方法的不同,大致分为基于全局特征、基于辅助特征、基于局部特征(分割)三种方法。
在视频监控领域,我们的最终目标是要做到多目标跨摄像头跟踪 (Multi-target Multi-camera Tracking, MTMC Tracking). 而行人再识别和行人跟踪都是为了达到这个最终目标的子任务。ReID是跨摄像头跟踪中解决目标因为视野丢失(跨摄像头)后再匹配起来的最直接(甚至可以说是唯一)的方法。目前RE-ID还是比较成熟,但是做MTMC相关工作的人比较少,故其发展相对缓慢。
0.2ReID和Tracking区别联系
0.2.1区别
ReID工作场景: 给定一张切好块的行人A图像,然后在一堆切好的图像上找这个行人A,这些图像通常是由不同摄像头拍摄的不连续帧。他的难点在于要在不同的角度、分辨率等因素下识别A。
Tracking工作场景: 给定一张切好块的行人A图像,在一段全景视频来找这个A,这段全景视频是由单个摄像头拍摄的连续帧。他的难点在于要预测未来,比如一个人突然形态发生了变化(蹲了下来,快速移动),遮挡。
0.2.2联系
两者都是把检测出来的行人图片提取一个feature,根据feature来判断两张图片的相似性
1.基于人工设置的REID
1.1任务目标
 可见reID必备的两个因素:image description and distance metrics.即特征提取和距离度量方式
可见reID必备的两个因素:image description and distance metrics.即特征提取和距离度量方式
1.2特征提取
颜色(最常用),纹理特征(用的较少)
----------------------------------------------------------------低级特征------------------------------------------------------------------
1.2.1《Person re-identification by symmetry-driven accumulation of local features》2010
从背景中分割出行人前景,并且为每个身体部分计算一个对称轴。基于身体形态,计算了加权颜色直方图WH(weighted color histogram);

最大稳定颜色区域MSCR(the maximally stable color regions);

循环的高结构块RHSP(the recurrent
high-structured patches)。
WH将较大的权重分配给对称轴附近的像素并生成每个部分的颜色直方图。MSCR检测稳定的颜色区域,并提取颜色、区域和质心等特征。相反,RHSP是一种捕捉循环纹理块的纹理特征。
1.2.2《Person reidentification using spatiotemporal appearance》2006
Gheissari等人提出了一种时空分割方法来检测稳定的前景区域。对于局部区域,计算HS直方图和edgel直方图,后者在edgel的任一侧对主要的局部边界取向和RGB比率进行编码。
HSV图像直方图,HSV空间由色调(H),饱和度(S),明度(V)构成
1.2.3 《Viewpoint invariant pedestrian recognition with an ensemble of localized features》2008
Gray和Tao在亮度通道上使用8个颜色通道(RGB,HS和YCbCr)和21个纹理滤波器,并将行人分割成水平条纹。
Y’为颜色的亮度(luma)成分、而CB和CR则为蓝色和红色的浓度偏移量成份
1.2.4《Pcca: A new approach for distance learning from sparse pairwise constraints》2012
从水平条纹中的RGB、YUV和HSV通道和LBP(局部二值模式)纹理直方图构建了特征向量。
YUV:亮度信息的平面,然后才是描述具体色彩的U和V平面,分别具有色度(Chrominance)和浓度(Chroma)信息。
1.2.5《Salient color names for person re-identification》2014
为了提高RGB值对光度变化的鲁棒性,引入基于显着性颜色名称的颜色描述符(SCNCD),用于全局行人颜色描述,也分析了背景和不同颜色空间的影响。
1.2.6《Consistent re-identification in a camera network》2014
将HSV直方图应用于头部、躯干和腿部的轮廓上,运用了划分,可以解决遮挡和姿势变化的问题。
1.2.7《Local fisher discriminant analysis for pedestrian re-identification》2013
在使用PCA进行降维之前从hsv和yuv空间中提取了颜色直方图和图像力矩(moment)
1.2.8《Salient color names for person re-identification》
为了提高RGB值对光度变化的鲁棒性,引入基于显着性颜色名称的颜色描述符(SCNCD),用于全局行人颜色描述,也分析了背景和不同颜色空间的影响。
1.2.9《Person re-identification by local maximal occurrence representation and metric learning》
Liao等人提出了包括颜色和SILTP直方图局部最大发生(LOMO)描述符
1.2.10《Scalable person re-identification: A benchmark》
对每个局部区域提取11-维的颜色名称描述符,并通过一个Bag-of-Words(BoW)模型将它们聚合成一个全局向量。
----------------------------------------------------------------中级特征------------------------------------------------------------------
除了直接使用低层颜色和纹理特性外,另一个不错的选择是基于属性的特性,可以将其视为中层表示。与低级描述符相比,属性对图像转换更具鲁棒性。
1.2.11《Person reidentification by attributes》
Layne等人在Viper数据集上注释15个与服装和soft biometrics特征相关的二进制属性。low-level的颜色和纹理特征用于训练属性分类器。属性加权后,生成的向量被集成到SDALF [13]框架中,与其他视觉特征融合。
1.2.12《Person re-identification:What features are important?》2012
以无监督的方式发现一些具有公共属性的行人原型,并根据原型自适应地确定不同查询人的特征权重。
1.2.13《Transferring a semantic representation for person re-identification and search》2015
从现有的时尚摄影数据集学习许多属性,包括颜色、纹理和类别标签。这些属性直接转移到监视视频下的re-ID并得到有竞争力的结果。
1.2.总结
传统REID发展方式使用不同的特征提取方式来提取特征或者是混合特征来生成其他属性类特征,有一篇博客详细介绍了不同的特征提取方式具体计算方法:https://blog.csdn.net/yuanlulu/article/details/82148429
1.3距离度量
在手工设置提取特征的REID,良好的距离度量方式是成功的关键。
1.3.1欧式距离(均方差):

1.3.2马氏距离:
![]()
![]()
∑是协方差矩阵。
马氏距离特性:
1.马氏距离去掉了量纲,是的具有不同维度的特征的样本也可以进行距离度量。当所有的数据具有独立同分布时候,我们的马氏距离就退化成了欧氏距离。
2.马氏距离还可以排除变量之间的相关性的干扰。
3.马氏距离的计算是建立在总体样本的基础上的,如果拿同样的两个样本,放入两个不同的总体中,最后计算得出的两个样本间的马氏距离通常是不相同的。所以在计算马氏距离的时候要求样本数量要大于属性数量。


1.3.3《Large scale metric learning from equivalence constraints》2012
提出了目前最流行的算法KISSME(keep it simple and straightforward metric):
H1:假设同一类,H0:假设非同一类,似然比为:

似然比较高意味着不是同一类(H0接受),似然比较低意味着是同一类(H0拒绝)。 δ ( x i , x j ) δ(x^i,x^j) δ(xi,xj)就是用来衡量i,j状态下目标x的距离,所以我们可以把齐转换为差分形式![]()
代入得:
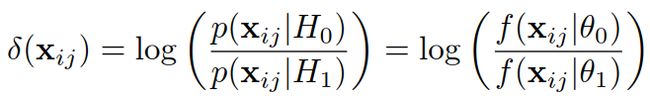
假设样本分布符合高斯分布,可以得

其中:


去掉常数项得:

最终得到反映了对数似然比检验的属性的马氏距离度量:
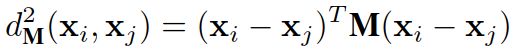
其中:

对数似然比特性: 似然比检验(likelihood ratio, LR) 是反映真实性的一种指标,属于同时反映灵敏度和特异度的复合指标。
参考资料:
https://blog.csdn.net/hyk_1996/article/details/79638556
https://www.cnblogs.com/orangecyh/p/11937443.html
1.3.4《Distance metric learning for large margin nearest neighbor classification》2005
提出了大间隔最近邻居(Large Margin Nearest Neighbor Metric,LMNN)这一无监督的分类方法,从字面意思上就知道是KNN的进化。
目标:使得 k 个最近邻样本总是属于同一类别,且不同类别样本之间的距离很大.
通常kNN分类器采用欧氏距离,然而欧氏距离完全不考虑训练集数据的统计特性。
1.3.
除了基于马氏距离的度量方法,还有一些基于支持向量机的方法
2.基于深度学习
2.0现状
常用的CNN模型有两种:第一类是用于图像分类和目标检测的分类模型。 第二种是使用图像对(image pairs)或三胞胎(triplets)作为输入的孪生模型(siamese model),其中孪生网络是最主要的模型。
目前遇到的瓶颈:缺乏训练数据。
2.1孪生Siamese思想简介

Siamese network就是“连体的神经网络”,神经网络的“连体”是通过共享权值来实现的,两张不同的照片通过同一个网络获得两个feature map后拉平成long vector通过距离度量来计算两个图片的相似度。
2.2发展历程
本文主要介绍Siamese这一支路。
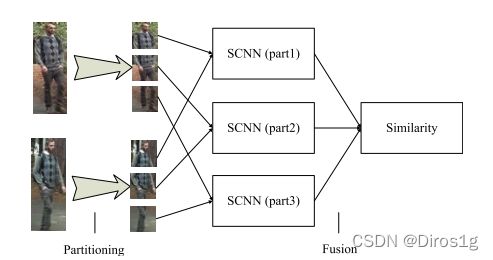
2.2.1《Deep metric learning for person re-identification》2014
行人重识别深度学习开山之作之一,将siamese网络结构用于行人重识别问题上
将输入图像划分为三个重叠的水平部分,并且三个部分通过两个卷积层和全连接层,该全连接层将它们融合并输出该图像的一个向量。采用余弦距离计算两个输出向量的相似性。
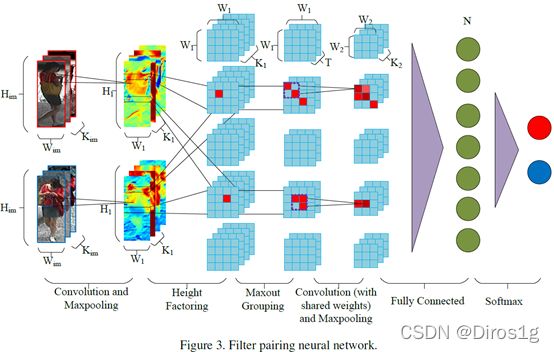
2.2.2《Deepreid: Deep filter pairing neural network for person re-identification》2014
另一篇行人重识别深度学习开山之作
添加了块匹配层,该块匹配层在不同的水平条纹将两个图像的卷积响应相乘(自注意力?),想法类似于ACS。
2.2.3《An improved deep learning architecture for person re-identification》2015
通过计算交叉输入邻域差异特征来改进Siamese模型,将来自一个输入图像的特征与其他图像相邻位置中的特征进行比较,强调了局部信息。

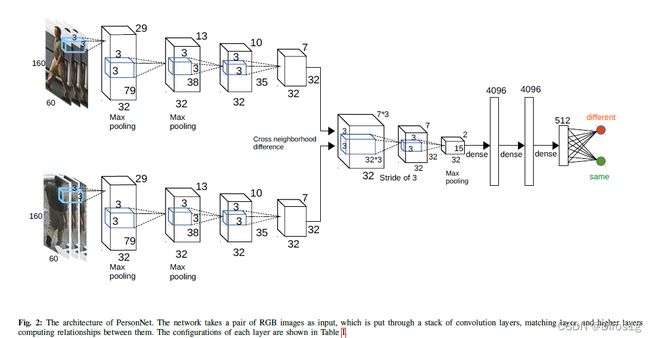
2.2.4《Personnet: Person reidentification with deep convolutional neural networks》2016
受到vgg的影响使用更小尺寸的卷积滤波器,没什么好讲的
2.2.5《A siamese long short-term memory architecture for human re-identification》2016
本文将长短期记忆模型 (LSTM)合并到一个Siamese网络中,加入了时序信息。
2.2.6《Gated siamese convolutional neural network architecture for human re-identification》
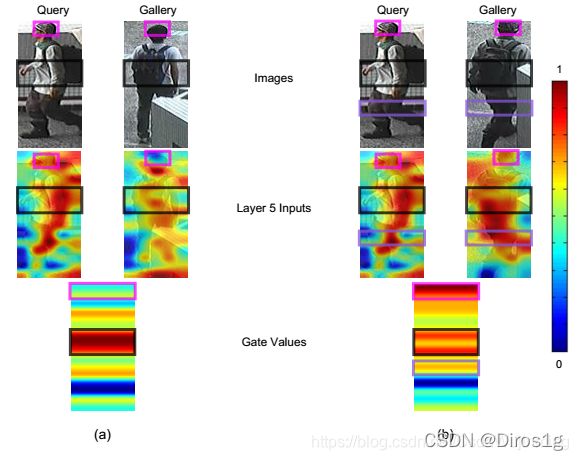
个人理解是在reid的时候要给每个照片检测出id,然后在库里进行匹配。
2.2.7《End-to-end comparative attention networks for person re-identification》2016
提出在siamese网络中集成一个基于软注意力的模型,以自适应地注重输入图像对的重要局部部分;然而,该方法也受到计算效率低下的限制。

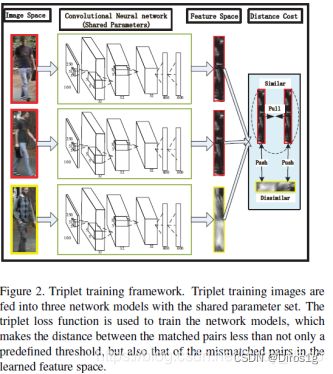
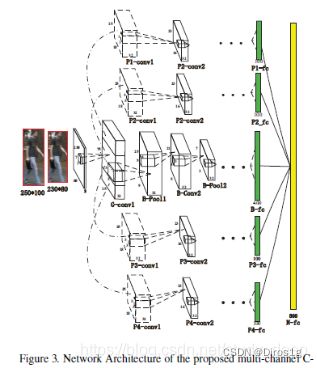
2.2.7《Person re-identification by multi-channel parts-based cnn with improved triplet loss function》2016
之前的方法都是使用图像对,而本文设计了以三个图像作为输入的三元组损失函数。在第一个卷积层之后,对每幅图像进行四个重叠的身体部分分割,并在FC层与一个全局特征进行融合。
参考:
Person Re-identification:Past, Present and Future
https://www.zhihu.com/question/68584669
https://blog.csdn.net/weixin_43152063/article/details/89085039
https://blog.csdn.net/qq_35631395/article/details/105925217
3.数据集
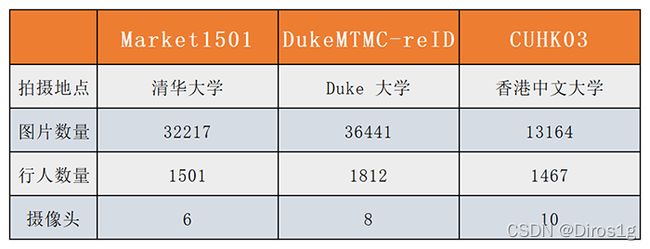
3.1CUHK03
CUHK03:包含1467个人、14097张图片、6个摄像头拍摄。提供两种标记:手工标记行人边界框和由DPM检测器自动检测.
3.2Market-1501
Market-1501包含1501个人、32668张图片、6个摄像头拍摄、在超市前。行人边界框是由DPM模型给出并由人工进一步验证被分成训练集(751个人的12936张图片)和测试集(750个人的19732张图片)对于测试集中的每个人,只选择每个相机的一张图像作为query,所以一个人最多有6张,共有3368张query图像
3.3 DukeMTMC-reID
DukeMTMC 数据集是一个大规模标记的多目标多摄像机行人跟踪数据集。它提供了一个由 8 个同步摄像机记录的新型大型高清视频数据集,具有 7,000 多个单摄像机轨迹和超过 2,700 多个独立人物,DukeMTMC-reID 是 DukeMTMC 数据集的行人重识别子集,并且提供了人工标注的bounding box。
参考:
http://t.zoukankan.com/geoffreyone-p-10314062.html
https://blog.csdn.net/ctwy291314/article/details/83544088
4.评价指标
4.1rank
rank1
步骤#1:计算数据集中每一个输入图像的类别标签的几率。
步骤#2:肯定真实标签是否等于具备最大几率的预测类别标签。
步骤#3:计算步骤#2为真的次数,而后除以总的测试图片数量。
rank5
rank-5准确度选取5个最大几率的类别,只要这5个类别中的一个和真实标签相同,该预测结果就为真。
步骤#1:计算数据集中每一个输入图像的类别标签的几率。
步骤#2:按降序对预测的类别标签几率进行排序。
步骤#3:肯定真实标签是否存在于步骤#2的前5个预测标签中。
步骤#4:计算步骤#3为真的次数,而后除以总的测试图片数量。
4.2CMC曲线
CMC曲线(Cumulative Match Characteristic Curve)横轴代表Rank-n,纵轴代表Accuracy。如果选取Rank-n排序列表为[1,2,5,10]的话,则CMC曲线就是一个由四个点连接而成的曲线。其中每个点的Rank-n的值都为所有测试数据的Rank-n的平均值。

4.3mAP、AP
不赘述
参考:
http://www.javashuo.com/article/p-hvjtuudz-mh.html