Python数据可视化
一、可视化概念
数据可视化,是关于数据视觉表现形式的科学技术研究,它为大数据分析提供了一种更加直观的挖掘、分析与展示当代手段。数据可视化以数据挖掘、数据采集、数据分析为基础;此外,它还是一种新的表达数据的方式,是对现实世界的抽象表达。
二、统计学概念
1、集中趋势的度量
集中趋势的度量通常称为平均值,用于描述概率分布的中心值或典型值。
平均值:将所有测量值相加,并除以观察值的数量所得到的算术平均值。
中位数:表示有序数据集的中间值,如果包含偶数个观测值,中位数将是两个中间值的平均值。与平均值相比,中位数不太容易出现异常值。其中,异常值表示为数据中较为独特的值。
模式(众数):模式被定义为最频繁的值,在多个值同样频繁的情况下,可能存在多个模式。
2、离散度的度量
离散度也称作可变性,是指概率分布被拉伸或压缩的程度。
方差:是指各个数据与其算术平均数的离差平方和的平均数,它描述了一组数字与其平均值间的距离。
标准偏差:表示为方差的平方根。
范围:表示为数据集中最大和最小值间的差。
四分位范围:也称作中间离散或中间50%,表示第75和第25百分位之间的差,或上四分位数和下四分位数之间的差。
3、相关性
相关性表示两个变量间的统计学关系。
在正相关中,两个变量在同一方向上移动。
在负相关中,两个变量以相反方向移动。
在0相关中,变量间彼此不相关。
注意:相关性并不意味着因果关系。相关性描述了两个变量间的关系,而因果关系则描述了一个事件如何被另一个事件所引发。
两个变量的相关性可以使用协方差来衡量。
三、numpy
1、概念:NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
核心对象ndarray
使用np.array方法创建数组,输入参数可以是任意序列(列表、元组、数组、生成器以及numpy数组等)

使用np.arange()方法构建N维组数

一般使用np.arange()方法,先创建一个一维值序列,再使用reshape方法变换高维数组形状

ndarray对象比较重要的属性:
属性 说明
ndarray.ndim 秩,即轴的数量或维度的数量
ndarray.shape 数组的维度,对于矩阵,n 行 m 列
ndarray.size 数组元素的总个数,相当于 .shape 中 n*m 的值
ndarray.dtype ndarray 对象的元素类型
ndarray.itemsize ndarray 对象中每个元素的大小,以字节为单位
ndarray.flags ndarray 对象的内存信息
ndarray.data 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。
2.索引和切片
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
import numpy as np
a = np.arange(10)
s = slice(2,7,2) # 从索引 2 开始到索引 7 停止,间隔为2
print (a[s])
输出结果 [2 4 6]import numpy as np
a = np.arange(10)
b = a[2:7:2] # 从索引 2 开始到索引 7 停止,间隔为 2
print(b)输出结果
3.Numpy常用方法
Np.max 用于计算数组中的元素沿指定轴的最小值。
Np.min 用于计算数组中的元素沿指定轴的最大值。
Np.average 用于根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值。该函数可以接受一个轴参数。 如果没有指定轴,则数组会被展开。加权平均值即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的权重的和。
Np.std 用于计算标准差。
Np.var 用于计算方差。
Np.random.normal 正态分布
Np.random.uniform
np.random.uniform(a,b)其中a是下界,b是上界,这个方法是在上下界的界定范围内随机取一个值
Np.linspace 创建等差数列。
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)
start:返回样本数据开始点
stop:返回样本数据结束点
num:生成的样本数据量,默认为50
endpoint:True则包含stop;False则不包含stop
retstep:If True, return (samples, step), where step is the spacing between samples.(即如果为True则结果会给出数据间隔)
dtype:输出数组类型
axis:0(默认)或-1
Np.arange
np.arange()
函数返回一个有终点和起点的固定步长的排列,如[1,2,3,4,5],起点是1,终点是6,步长为1。
参数个数情况: np.arange()函数分为一个参数,两个参数,三个参数三种情况
1)一个参数时,参数值为终点,起点取默认值0,步长取默认值1。
2)两个参数时,第一个参数为起点,第二个参数为终点,步长取默认值1。
3)三个参数时,第一个参数为起点,第二个参数为终点,第三个参数为步长。其中步长支持小数
#一个参数 默认起点0,步长为1 输出:[0 1 2]
a = np.arange(3)
#两个参数 默认步长为1 输出[3 4 5 6 7 8]
a = np.arange(3,9)
#三个参数 起点为0,终点为3,步长为0.1 输出[ 0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9]
a = np.arange(0, 3, 0.1)
Np.random.rand
通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
Np.random.randint

函数的作用是,返回一个随机整型数,其范围为[low, high)。如果没有写参数high的值,则返回[0,low)的值。
从random可以看出是产生随机数,randint可以看出是产生随机整数(int)
Np.random.randn
randn函数返回一个或一组样本,具有标准正态分布。
四、pandas
核心对象
Series和DataFrame
DataFrame对象的创建
方法1:由数组或列表组成的字典构建DataFrame(常用)
#字典的键作为列
import pandas as pd
data1 = {'a' : [1,2,3],'b' : [4,5,6], 'c' : [7,8,9]}
df1 = pd.DataFrame(data1)
print(df1)
###########
# a b c
#0 1 4 7
#1 2 5 8
#2 3 6 9方法2:由Series组成的字典构建DataFrame(常用)
data2 = {'a' : pd.Series(np.random.rand(3)),
'b' : pd.Series(np.random.rand(3)*10),
'c' : pd.Series(np.random.rand(3)*100)}
df2 = pd.DataFrame(data2)
print(df2)
#################################
# a b c
#0 0.713086 1.196266 98.645137
#1 0.810221 6.738664 37.399359
#2 0.153884 2.247200 47.458595方法3:通过二维数组构建DataFrame(常用)
df3 = pd.DataFrame(np.random.randint(10,100,(3,7)))
print(df3)
##############################
# 0 1 2 3 4 5 6
#0 32 89 34 99 96 79 79
#1 35 29 34 21 19 16 30
#2 80 92 65 46 15 60 36方法4:由字典组成的列表构建DataFrame
data4 = [{'a':1,'b':2},{'a':5,'b':10,'c':15}]
df4 = pd.DataFrame(data4)
print(df4)
###############
# a b c
#0 1 2 NaN
#1 5 10 15.0方法5:由字典组成的字典构建DataFrame
data5 = {'xiaoming':{'Chinese':np.random.randint(60,100),
'Math':np.random.randint(60,100),
'Endlish':np.random.randint(60,100)},
'xiaohong':{'Chinese':np.random.randint(60,100),
'Math':np.random.randint(60,100),
'Endlish':np.random.randint(60,100)},
'xiaogang':{'Chinese':np.random.randint(60,100),
'Math':np.random.randint(60,100),
'Endlish':np.random.randint(60,100)},
}
df5 = pd.DataFrame(data5)
print(df5)
######################################
# xiaoming xiaohong xiaogang
#Chinese 75 68 86
#Endlish 84 93 87
#Math 61 84 75增
删
改
查


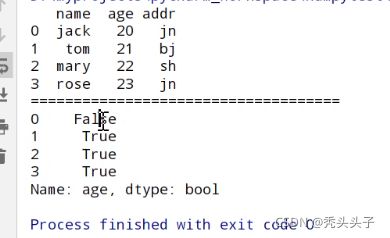



iloc 行
遍历
五、matplotlib
比较图
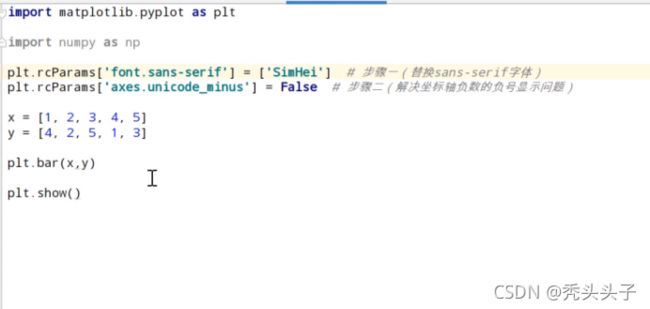
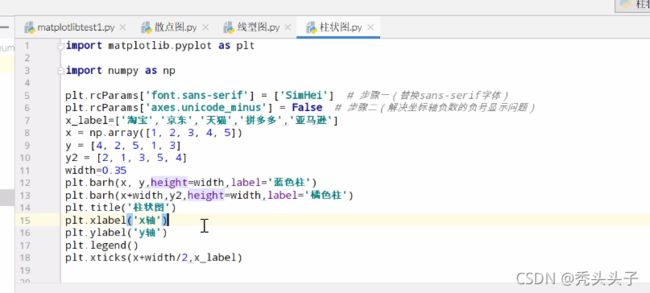
柱状图
线型图

雷达图
关系图
散点图
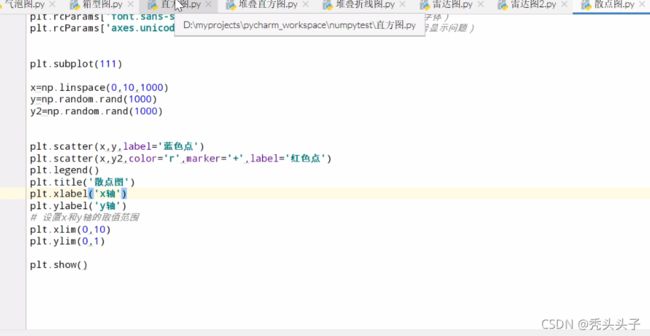
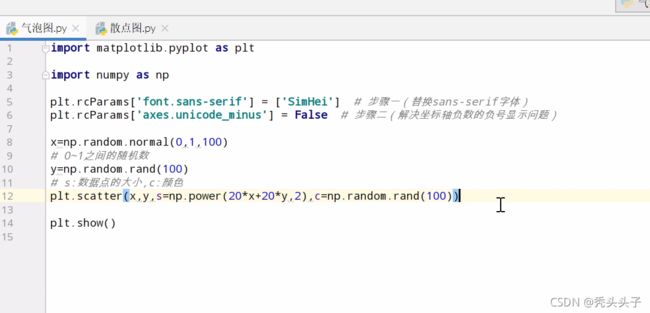
气泡图
热图
相关图
合成图
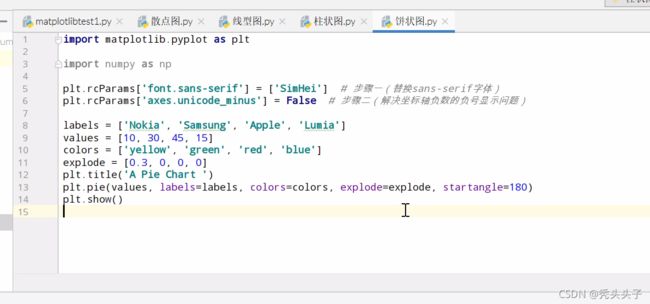
饼图
堆叠柱状图

韦恩图
分布图
直方图



箱型图
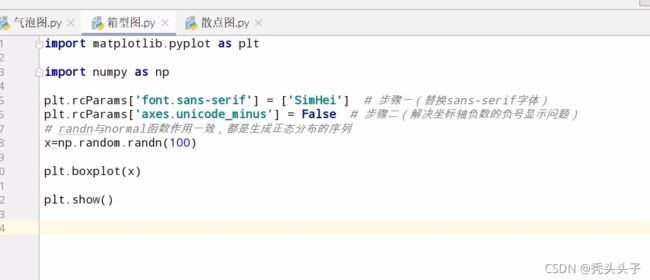
小提琴图
以上加粗内容要求能够编写代码实现
六、Matplotlib常用方法:
绘图方法,如:plot(线形图)、hist(直方图)、bar(柱状图)、pie(饼图)等
Subplot
matlab中subplot()的作用,就是在同一画面中创建和控制多个图形位置。
一般使用格式:subplot(m,n,p)
m——行数,即在同一画面创建m行个图形位置。
n——列数,即在同一画面创建n列个图形位置。
p——位数,在同一画面的m行,n列的图形位置。
Title
Xlabel
Ylabel
使用xlabel()和ylabel()函数设置x轴y轴的标签。这两个函数的使用方法非常相似。
Legend
显示图中的标签
Xticks
Yticks
Xlim
设定x轴范围的语句
Ylim
等
七、Seaborn
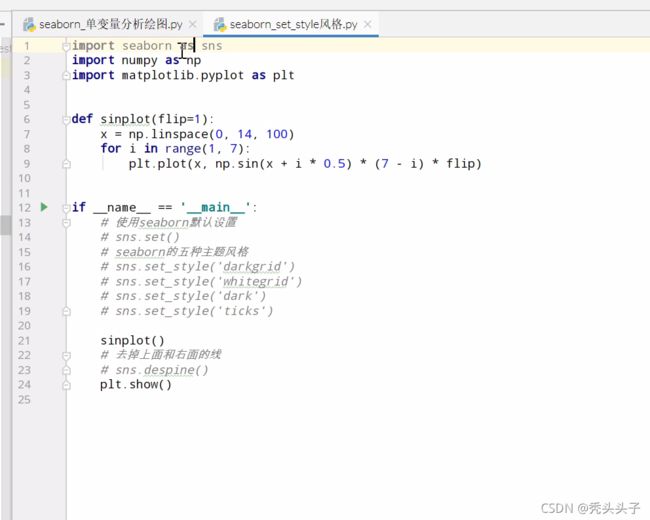
Set_style及五种风格
调色板的使用