JavaScript代码到底是怎么执行的?
学习指南:
- JavaScript执行原理
- V8引擎的执行原理
-
- V8执行JavaScript流程概述
- AST
-
- 词法解析
- 语法分析
- Ignition
-
- 什么是字节码?
- TurboFan
-
- 反优化
- 完结散花
- 参考文献
JavaScript执行原理
JavaScript下载好代码后,是如何一步步被执行的呢?
我们知道计算机只能识别二进制的机器语言,无法识别更高级的语言。
所以如果要用更高级语言的开发,需要先将这些语言翻译成机器语言,而语言种类大体可以分为解释型语言和编译型语言。
| 语言种类 | 翻译过程 | 优点 | 不足 | 常见语言例子 |
|---|---|---|---|---|
| 解释型语言 | 解释器 > 翻译成与平台无关的中间代码 | 与平台无关,跨平台性强 | 每次都需要解释执行 需要源文件 按句执行,执行效率差 | javascript、Ruby、Python |
| 编译型语言 | 预处理>编译>汇编>可执行的二进制文件 | 一次编译,永久执行 无需源代码,只需要可执行的源文件 运行速度快 | 不同系统可识别的二进制文件不同,跨平台兼容性差 | C、C++、java |
编译型语言在程序执行之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件。
这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了。
而由解释型语言编写的程序,在每次运行时都需要通过解释器对程序进行动态解释和执行。

JavaScript 就是一种解释型语言,支持动态类型、弱类型、基于原型的语言,内置支持类型。
一般JavaScript都是在前端侧执行,需要能快速的响应用户,所以这就要求这语言本身可以被快速的解析和执行。
JavaScript 引擎因此应运而生。
浏览器的内核一般由两部分组成:渲染引擎和JS引擎
以流行的webkit内核为例:
- WebCore:负责HTML解析、布局、渲染等等相关工作,即渲染引擎。
- JavaScriptCore:解析、执行
JavaScript代码,即JavaScript引擎。
Google 以在webkit内核的基础上,独立 fork 出了 Blink内核,将Chrome换成了自己的内核。
在Bink的基础之上,为了追求JavaScript 的极致速度和性能,Google工程师又创造出来了V8引擎。
V8引擎就如同webkit中的JavaScriptCore一样,用于负责解析、执行JavaScript代码,但在解析效率方面表现的极其优秀,所以解析来我们来着重讲讲V8的执行原理。
V8引擎的执行原理
V8 是用C++编写的 Google 开源的高性能JavaScript和WebAssembly引擎,它用于Chrome和Node.js等。
V8可以独立运行,也可以嵌入到任何的C++应用程序中。
V8的作用就是高效的将JS原生代码通过一系列的过程解析成计算机可以识别的二进制机器码。

V8执行JavaScript流程概述
首先原生的JavaScript代码用通过解析器(parser)解析(parse)后,生成抽象语法树(AST)和执行上下文,解释器(ignition)根据AST生成字节码。
最后在执行字节码的过程当中,如果发现有热代码(Hotspot)(被重复执行多次的一段代码就称为热代码)。那么后台的优化编译器 (TurboFan)就会把这段热点字节码编译为高效的机器码。
如果当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率。

AST
前面已经提到了,编译器或者解释器是理解不了高级语言的,但是AST是他们可以理解的结构。
无论你使用的是解释型语言还是编译型语言,在编译过程中,它们都会生成一个 AST。
这和渲染引擎将 HTML 格式文件转换为计算机可以理解的 DOM 树的情况类似。
其中最著名的一个项目是 Babel。Babel 是一个被广泛使用的代码转码器,可以将 ES6 代码转为 ES5 代码,这意味着你可以现在就用 ES6 编写程序,而不用担心现有环境是否支持 ES6。Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码。
生成AST需要经过两个阶段

词法解析
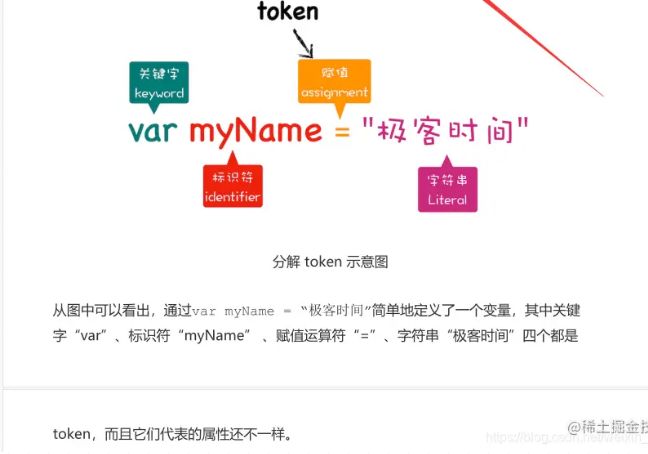
第一个阶段是分词(tokenize),又称为词法分析,是由词法分析器(scanner)来完成的,其作用就是将一行行的源码拆解成一个个token。
所谓token指的是语法上不可能再分的、最小的单个字符或字符串。
可以通过下图来更好的理解token。
语法分析
第二阶段是解析(parse),又称为语法分析,是由语法分析器(parser)完成的,其作用是将上一步生成的 token 数据,根据语法规则转化为AST。
按照逻辑结构 验证语法 生成树形结构对源码进行校验,如果源码符合语法规则,这一步就会顺利完成,但如果源码存在语法错误,这一步就会终止,并抛出一个‘语法错误’。
Ignition
有了AST和执行上下文之后,解释器 ignition 就登场了,它会根据AST生成字节码文件,并解释执行字节码。
什么是字节码?
字节码其实是机器码的抽象,各种字节码相互构成可以实现JS所需的所有功能。
并且字节码比机器码占有的内存要小得多,基本是机器码所在内存的几十甚至几百分之一,这也是为什么即使执行机器码的效率非常高效,但V8现在也不直接将AST转化成机器码。因为如果全部采用机器码的话,V8 需要消耗大量的内存来存放转换后的机器码,会占有大部分的移动端内存。

从图中可以看出,机器码所占用的空间远远超过了字节码,所以使用字节码可以减少系统的内存使用。
TurboFan

生成字节码之后,接下来就要进入执行阶段了。
通常,如果有一段第一次执行的字节码,解释器 Ignition 会逐条解释执行。
在执行字节码的过程中,如果发现有热代码(HotSpot),那么后台的编译器 TurboFan 就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率。
这里会有一个疑问,既然 CPU 不能识别字节码,还需要将字节码转成机器码呢,那不是多此一举,耽误时间嘛?
解释器在将 AST 转为字节码之后,会在执行的时候将字节码转成机器码,这个执行过程肯定是比直接执行机器码要慢的,所以在执行方面,速度上会比较慢。
但是 JS 源码通过解析器转 AST,然后再通过解释器转字节码,这个过程是比编译器直接将 JS 源码转机器码要快很多的,全流程看来,整个时间上是差不了多少的,但是却减小了大量的内存占用,何乐而不为。
TurboFan(优化编译器)当存在热代码的时候,V8会借着TurboFan将为热代码的字节码转为机器码并缓存下来。当再次调用热代码时,就不再需要将字节码转机器码,提升了执行效率。
反优化
JS作为动态语言,非常灵活,对象的结构和属性在运行时是可以发送改变的。
设想一个问题:如果热代码在某次执行的时候,突然某一个属性被修改了。
那编译成机器码的热代码还能继续执行吗? 答案肯定是不能。
这时候就需要用到TurboFan(优化编译器)的反优化了,它会将热代码回退到AST状态,这个时候解释器会重新解释执行被修改的代码,如果代码在被标记成热代码,那么会重复执行代码编译器的这个步骤。
整个流程不仅使用到了解释器,还用到了优化编译器。这种两者结合去处理的方式,业界称为 JIT (Just-In-Time)。使用这种结合的方式来处理 JS,主要是利用了 AST 形成的文件较小,而通过优化编译器编译后的热代码执行效率高,两者结合,各自发挥各自的优势,将效率尽量提升到最大。
即时编译(JIT)技术:

完结散花
ok以上就是对 JavaScript高级 |浏览器渲染过程 的全部讲解啦,很感谢你能看到这儿。如果有遗漏、错误或者有更加通俗易懂的讲解,欢迎小伙伴私信我,我后期再补充完善。
参考文献
coderwhy老师JS高级视频教程
https://juejin.cn/post/6981361874780569637