VGG一维复现pytorch
VGG网络可以说是深度学习中最著名的网络之一,因为VGG网络模型只是纵向的延申,网络结构比较简单,就竖着堆就行了又能适应大部分任务,准确率还有保障。比起GoogLeNet,ResNet和DenseNet来简直就是小学生难度。
LeNet-AlexNet-ZFNet: LeNet-AlexNet-ZFNet一维复现pytorch
VGG: VGG一维复现pytorch
GoogLeNet: GoogLeNet一维复现pytorch
ResNet: ResNet残差网络一维复现pytorch-含残差块复现思路分析
DenseNet: DenseNet一维复现pytorch
VGG
原文链接: VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
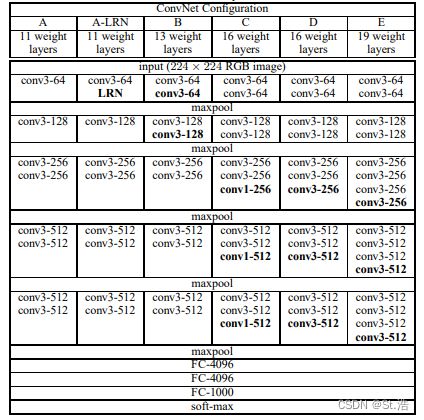
这几乎没什么好说的直接上干货
import torch
from torchsummary import summary
class VGG19(torch.nn.Module):
def __init__(self,In_channel=1,classes=5):
super(VGG19, self).__init__()
self.feature = torch.nn.Sequential(
torch.nn.Conv1d(In_channel, 64, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(64),
torch.nn.ReLU(),
torch.nn.Conv1d(64, 64, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(64),
torch.nn.ReLU(),
torch.nn.MaxPool1d(2),
torch.nn.Conv1d(64, 128, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(128),
torch.nn.ReLU(),
torch.nn.Conv1d(128, 128, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(128),
torch.nn.ReLU(),
torch.nn.MaxPool1d(2),
torch.nn.Conv1d(128, 256, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(256),
torch.nn.ReLU(),
torch.nn.Conv1d(256, 256, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(256),
torch.nn.ReLU(),
torch.nn.Conv1d(256, 256, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(256),
torch.nn.ReLU(),
torch.nn.Conv1d(256, 256, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(256),
torch.nn.ReLU(),
torch.nn.MaxPool1d(2),
torch.nn.Conv1d(256, 512, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
torch.nn.Conv1d(512, 512, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
torch.nn.Conv1d(512, 512, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
torch.nn.Conv1d(512, 512, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
torch.nn.MaxPool1d(2),
torch.nn.Conv1d(512, 512, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
torch.nn.Conv1d(512, 512, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
torch.nn.Conv1d(512, 512, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
torch.nn.Conv1d(512, 512, kernel_size=3, padding=1),
torch.nn.BatchNorm1d(512),
torch.nn.ReLU(),
torch.nn.MaxPool1d(2),
torch.nn.AdaptiveAvgPool1d(7)
)
self.classifer = torch.nn.Sequential(
torch.nn.Linear(3584,1024),
torch.nn.ReLU(),
torch.nn.Dropout(0.5),
torch.nn.Linear(1024,1024),
torch.nn.ReLU(),
torch.nn.Dropout(0.5),
torch.nn.Linear(1024, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, classes),
)
def forward(self, x):
x = self.feature(x)
x = x.view(-1, 3584)
x = self.classifer(x)
return x
if __name__ == '__main__':
model = VGG19(In_channel=1,classes=5)
input = torch.randn(size=(1,1,224))
output = model(input)
print(f"输出大小{output.shape}")
print(model)
summary(model=model, input_size=(1, 224), device='cpu')
运行结果
输出大小torch.Size([1, 5])
VGG19(
(feature): Sequential(
(0): Conv1d(1, 64, kernel_size=(3,), stride=(1,), padding=(1,))
(1): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,))
(4): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv1d(64, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(8): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU()
(10): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(11): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU()
(13): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv1d(128, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(15): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU()
(17): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(18): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU()
(20): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(21): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU()
(23): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(24): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(25): ReLU()
(26): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(27): Conv1d(256, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(28): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU()
(30): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(31): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU()
(33): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(34): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(35): ReLU()
(36): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(37): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(38): ReLU()
(39): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(40): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(41): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU()
(43): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(44): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(45): ReLU()
(46): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(47): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(48): ReLU()
(49): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,))
(50): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(51): ReLU()
(52): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(53): AdaptiveAvgPool1d(output_size=7)
)
(classifer): Sequential(
(0): Linear(in_features=3584, out_features=1024, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=1024, out_features=1024, bias=True)
(4): ReLU()
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=1024, out_features=512, bias=True)
(7): ReLU()
(8): Linear(in_features=512, out_features=5, bias=True)
)
)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv1d-1 [-1, 64, 224] 256
BatchNorm1d-2 [-1, 64, 224] 128
ReLU-3 [-1, 64, 224] 0
Conv1d-4 [-1, 64, 224] 12,352
BatchNorm1d-5 [-1, 64, 224] 128
ReLU-6 [-1, 64, 224] 0
MaxPool1d-7 [-1, 64, 112] 0
Conv1d-8 [-1, 128, 112] 24,704
BatchNorm1d-9 [-1, 128, 112] 256
ReLU-10 [-1, 128, 112] 0
Conv1d-11 [-1, 128, 112] 49,280
BatchNorm1d-12 [-1, 128, 112] 256
ReLU-13 [-1, 128, 112] 0
MaxPool1d-14 [-1, 128, 56] 0
Conv1d-15 [-1, 256, 56] 98,560
BatchNorm1d-16 [-1, 256, 56] 512
ReLU-17 [-1, 256, 56] 0
Conv1d-18 [-1, 256, 56] 196,864
BatchNorm1d-19 [-1, 256, 56] 512
ReLU-20 [-1, 256, 56] 0
Conv1d-21 [-1, 256, 56] 196,864
BatchNorm1d-22 [-1, 256, 56] 512
ReLU-23 [-1, 256, 56] 0
Conv1d-24 [-1, 256, 56] 196,864
BatchNorm1d-25 [-1, 256, 56] 512
ReLU-26 [-1, 256, 56] 0
MaxPool1d-27 [-1, 256, 28] 0
Conv1d-28 [-1, 512, 28] 393,728
BatchNorm1d-29 [-1, 512, 28] 1,024
ReLU-30 [-1, 512, 28] 0
Conv1d-31 [-1, 512, 28] 786,944
BatchNorm1d-32 [-1, 512, 28] 1,024
ReLU-33 [-1, 512, 28] 0
Conv1d-34 [-1, 512, 28] 786,944
BatchNorm1d-35 [-1, 512, 28] 1,024
ReLU-36 [-1, 512, 28] 0
Conv1d-37 [-1, 512, 28] 786,944
BatchNorm1d-38 [-1, 512, 28] 1,024
ReLU-39 [-1, 512, 28] 0
MaxPool1d-40 [-1, 512, 14] 0
Conv1d-41 [-1, 512, 14] 786,944
BatchNorm1d-42 [-1, 512, 14] 1,024
ReLU-43 [-1, 512, 14] 0
Conv1d-44 [-1, 512, 14] 786,944
BatchNorm1d-45 [-1, 512, 14] 1,024
ReLU-46 [-1, 512, 14] 0
Conv1d-47 [-1, 512, 14] 786,944
BatchNorm1d-48 [-1, 512, 14] 1,024
ReLU-49 [-1, 512, 14] 0
Conv1d-50 [-1, 512, 14] 786,944
BatchNorm1d-51 [-1, 512, 14] 1,024
ReLU-52 [-1, 512, 14] 0
MaxPool1d-53 [-1, 512, 7] 0
AdaptiveAvgPool1d-54 [-1, 512, 7] 0
Linear-55 [-1, 1024] 3,671,040
ReLU-56 [-1, 1024] 0
Dropout-57 [-1, 1024] 0
Linear-58 [-1, 1024] 1,049,600
ReLU-59 [-1, 1024] 0
Dropout-60 [-1, 1024] 0
Linear-61 [-1, 512] 524,800
ReLU-62 [-1, 512] 0
Linear-63 [-1, 5] 2,565
================================================================
Total params: 11,937,093
Trainable params: 11,937,093
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 4.92
Params size (MB): 45.54
Estimated Total Size (MB): 50.46
----------------------------------------------------------------
Process finished with exit code 0
如果需要训练模板,可以在下面的浩浩的科研笔记中的付费资料购买,赠送所有一维神经网络模型的经典代码,可以在模板中随意切换。