【模型部署】Jetson Xavier NX(eMMC)部署YOLOv5-5.0
文章目录
- 前言
-
- NX介绍
- 版本区别(SD | eMMC)
- 规格参数
- Jetpack4.6.1环境搭建
-
- 烧录系统(OS)
- SSD启动
-
- SSD分区
- 设置为启动项
- 深度学习环境搭建
-
- 设置语言/地区等信息
- 烧录SDK组件
- 换清华源(可选)
- YOLOv5-5.0
-
- 虚拟环境
- 下载v5.0仓库
- 推理Demo
- VScode连接NX
- USB摄像头实时检测
- 模型转换
-
- pt-->wts(在yolov5-5.0)
- wts-->engine(在tensorrtx-yolov5-v5.0)
- USB摄像头实时检测
- DeepStream部署
-
- 安装
- Demo测试
- 加速部署YOLOv5(Coming soon)
- CSI-2摄像头实时检测(Coming soon)
- Reference
前言
本文对在Jetson Xavier NX上部署YOLOv5-5.0的过程进行全面梳理和总结。
NX介绍
在此之前,首先要了解一下Jetson Xavier NX(以下简称NX)。NX是NVIDIA2020年发布的一款应用于边缘AI的超级计算机,NANO 般的大小,却可以在 10 W功率下可提供 14 TOPS,而在 15 W功率下可提供 21 TOPS,非常适合在大小和功率方面受限的系统。凭借 384 个 CUDA 核心、48 个 Tensor Core 和 2 个 NVDLA 引擎,它可以并行运行多个现代神经网络,并同时处理来自多个传感器的高分辨率数据。借助 NX,我们可以使用完整的 NVIDIA 软件堆栈,通过加速库来运行现代 AI 网络和框架,从而实现深度学习以及计算机视觉、计算机图形、多媒体等。
那么NX长什么样呢?没错,就长下面这模样:
 图1 Jetson Xavier NX 图1 Jetson Xavier NX
|
 图2 Jetson Xavier NX开发者套件 图2 Jetson Xavier NX开发者套件
|
其中图1是官方原装NX,一块只有sodimm接口的板子,没有风扇,USB、网口等接口,图2为开发者套件,提供各种外设接口。NX具体的硬件模块如下所示:
 图3 NX正面模块解析 图3 NX正面模块解析
|
 图4 NX背面模块解析 图4 NX背面模块解析
|
版本区别(SD | eMMC)
目前NX有两个版本:SD卡槽的版本,和带eMMC存储芯片的版本:
- 带SD卡槽的版本可以使用microSD卡烧录系统后直接插入使用,也支持通过虚拟机SDKManager软件刷入系统使用
- 带eMMC存储芯片的版本,容量为16G,不支持microSD卡烧录系统方式,支持虚拟机SDKManager软件刷入系统使用
两个版本除了储蓄方式不同,其他性能相同,烧录好系统后使用差异不大
规格参数
NX的规格参数如下所示:

关键参数:
- NX是arm64架构的,和x86有根本性不同,导致很多东西不能适配,所以在部署的时候必须根据实际情况来
- 4个USB接口(真香~)
- 摄像头支持CSI-2接口,但也可以用USB摄像头(后续会有实践)
Jetpack4.6.1环境搭建
现在开搞!!准备以下装备:
- 带USB接口的键盘
- 带USB接口的鼠标
- 1条母对母杜邦线
- 用于连接NX上的FC REC和GND引脚,使NX进入恢复模式
- USB-a对USB-b数据线
- 用于连接NX和自己的电脑
- 带HDMI接口的显示器
- 电源线
烧录系统(OS)
以下操作均在自己的电脑上,但必须要有Linux系统,可以是双系统,也可以是虚拟机,以下是本文环境:
- Jetson Xavier NX(developer kit version)
- VMware 16
- Ubuntu18.04
- Jetpack4.6.1
1、SDKmanager安装
直接浏览器搜索:SDKmanager,进入官网,首先进行注册(邮箱+密码即可),之后下载.deb格式文件,会自动下载到Downloads文件夹下:
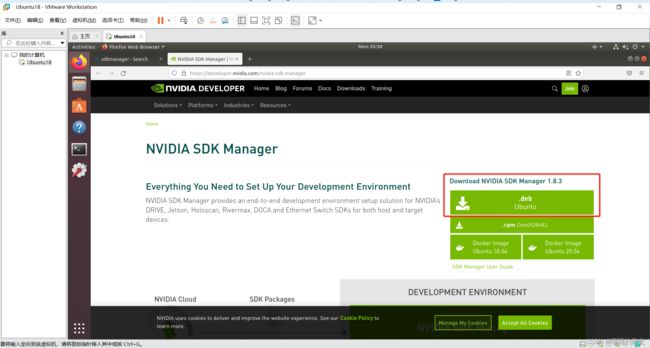
接着打开Terminal,cd到Downloads,ls查看是否已下载,最后sudo apt install ./sdkmanager_1.8.3-10409_amd64.deb进行安装:
xl@ubuntu:~$ cd Downloads/
xl@ubuntu:~/Downloads$ ls
nvidia sdkmanager_1.8.3-10409_amd64.deb
xl@ubuntu:~/Downloads$ sudo apt install ./sdkmanager_1.8.3-10409_amd64.deb
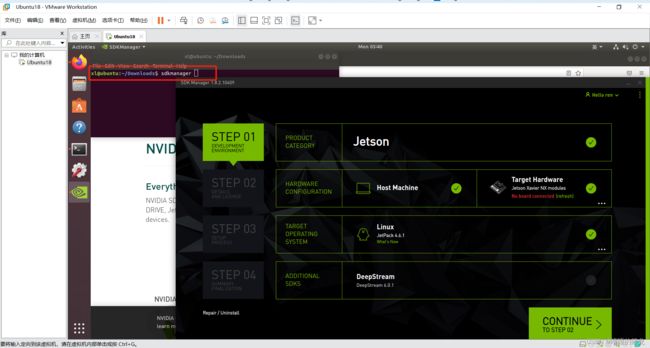
之后在Terminal中输入sdkmanager命令,打开应用窗口(第一次打开会进行login in步骤,就是登录之前注册NVIDIA账号和密码):
2、连接NX和自己电脑
现在开始连接我们的装备,按照下图所示进行连接:
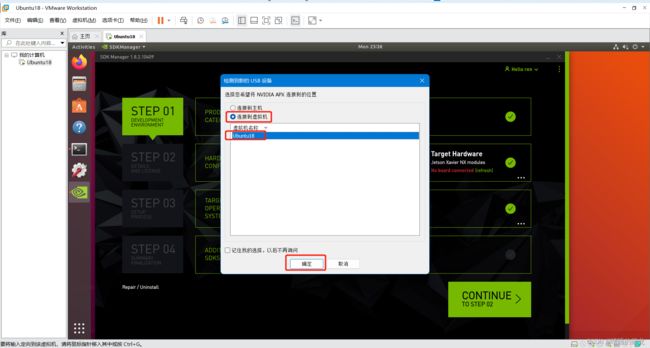
连接顺序没有强制要求,建议最后连接USB-b(即插入电脑),连接好后电脑会自动检查显示以下信息,我们选择连接到虚拟机中的Ubuntu18系统,确定即可
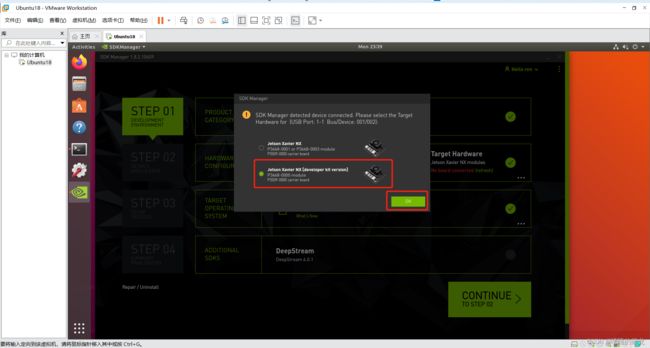
之后虚拟机就会自动显示NX版本信息,我们选择第二个开发套件版本,OK即可
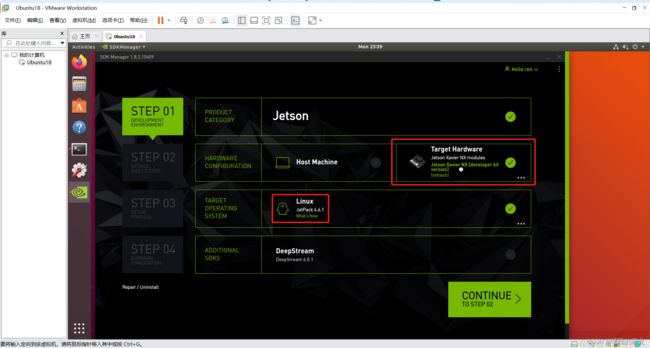
3、STEP01
之后就正式开始使用SDKManager烧录系统啦~~!!选择如下:
- 取消选择
Host Machine - 选择
Jetpack 4.6.1 - 取消选择
DeepStream
点击CONTINUE
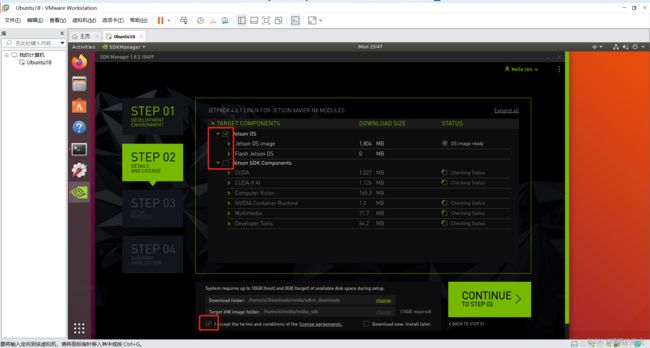
4、STEP02
这里只选择烧录OS系统,取消选择烧录SDK组件(容量只有可怜的16G,等后面装上SSD固态硬盘再装也不迟!!)
左下角是选择下载空间,SDKManager会将相关文件下载到虚拟机中之后,再转移到NX上去。这里就是存下载文件的地方,选择完下载路径之后,点击左下角的我接受,点击CONTINUE
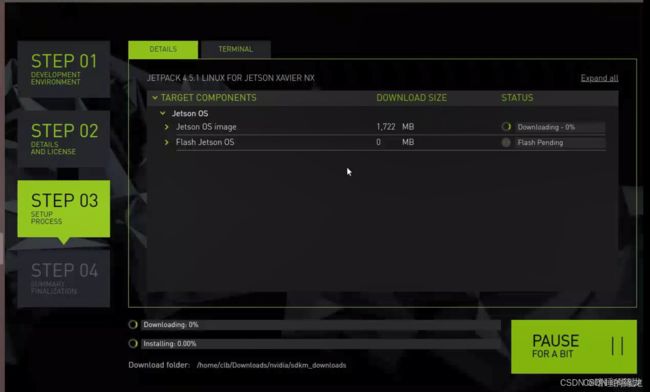
5、STEP03
之后就开始下载和安装啦(下面两个进度条,第一个是下载相关文件到虚拟机的进度,第二个是安装相关文件到NX上的进度),要注意,当Installing进行到50%的时候,会弹窗让我们进行一些设置:
- 如果是第一次烧录,就是用自动模式(Automatic),它会创建一个暂时的局域网连接,地址为192.168.55.1,然后输入新的用户名和密码
- 如果不是第一次,就选择手动模式(Manual),需要自己先去盒子上查询当前的IP地址
最后0.5%会异常缓慢,成功之后,点击FINISH退出即可
6、STEP04
恭喜你!!到这一步就烧录成功啦!!!
SSD启动
烧录完成之后,拔掉杜邦线,USB-ab线,给板子接上鼠标,键盘,显示器,然后开搞!!
NX使用SSD的读取速度是SD卡的7倍,因此从SSD启动不仅会对NX进行扩容,还会大幅度提高NX的性能,何乐而不为呢~~
SSD分区
首先,我们要有一个SSD,然后把它插到NX上:
然后,将NX接通电源,登录账号,搜索disk,打开Disks

可以看到NX已经显示SSD信息了,点击右上角选择Format Disk,进行格式化
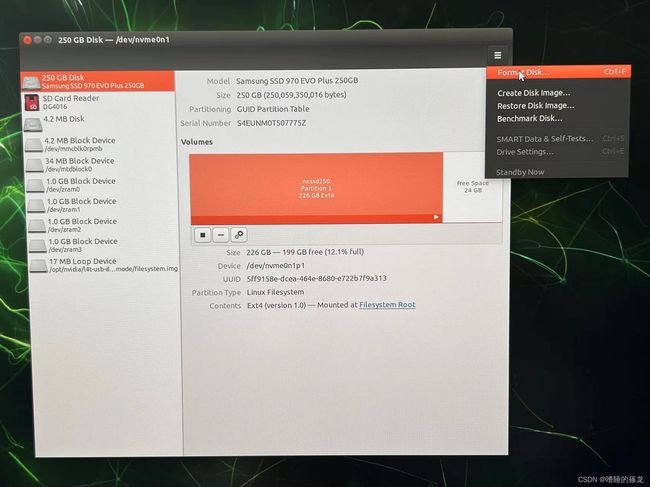
点击Format

完事之后可以看到SSD全部变成了Free Space了

接着点击加号+,进行空间分配,可以给Free Space16G,剩下全给我们的NX,点击Next
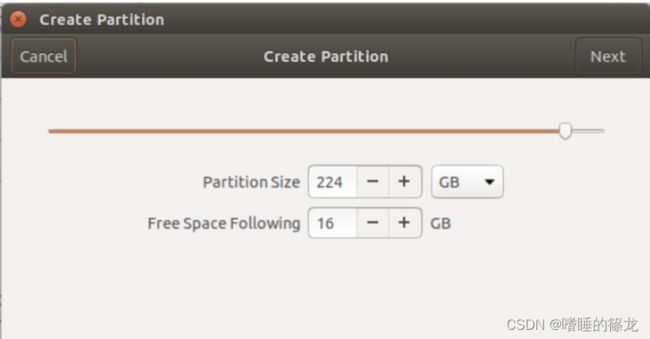
给新的卷命名,然后Create
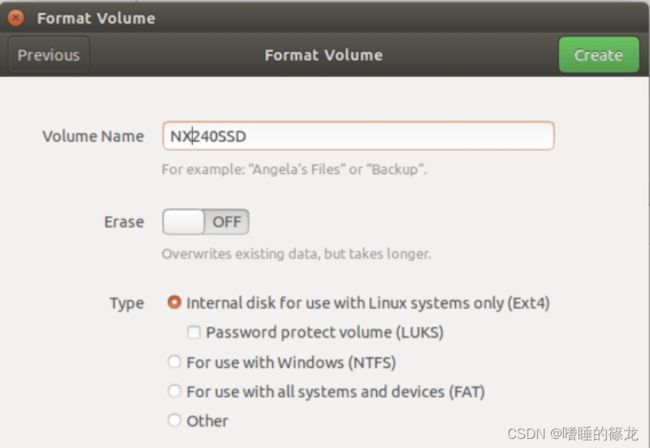
创建成功!!!
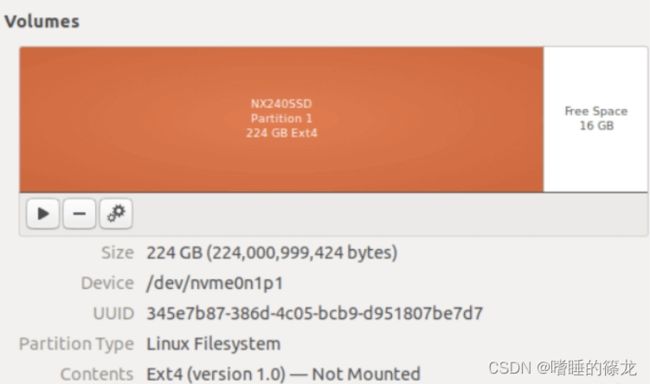
设置为启动项
接下来要进行安装,直接运行NX开源的脚本即可:
- 复制rootOnNVMe项目
- 将根源文件复制到自己的SSD
- 启用从 SSD 启动运行
- 重启以使服务生效
git clone https://github.com/jetsonhacks/rootOnNVMe.git
cd rootOnNVMe
./copy-rootfs-ssd.sh
./setup-service.sh
sudo reboot
深度学习环境搭建
至此,我们的NX基本环境搭建和SSD启动已经完成。下面,进行深度学习相关环境安装,以便于我们快乐的使用NX~~hhhh
设置语言/地区等信息
如果直接从SDKManager中烧录cuda,cudnn等组件,会出现以下报错:
Cannot contact to the device via SSH, validate that SSH service is running on the device
解决方式:在NX上设置完地区(上海)、语言、键盘等信息后,重启解决
烧录SDK组件
与烧录OS系统类似,不同的是,这里不用插杜邦线哦!!Jetpack4.6.1配套的组件版本信息如下:
- CUDA:10.2.300
- cuDNN:8.2.1.32
- TensorRT:8.2.1.8
- OpenCV:4.11
连接好接线后,打开SDKManager,在STEP02中,只选择第二项Jetpack SDK Components,点击CONTINUE
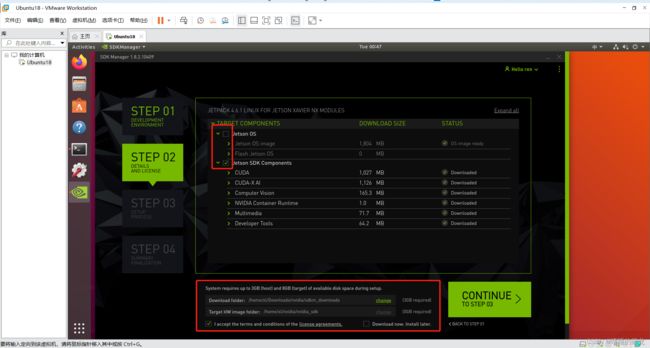
之后会让我们输入虚拟机的密码,然后检查安装环境是否正确,之后就正式开始下载和安装了,在这个过程中,会让我们输入NX的账号密码,最后我们点击Install即可

换清华源(可选)
- 重新编辑
source.list文件
sudo vim /etc/apt/sources.list
- 更换清华源
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-updates main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main restricted universe multiverse
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-security main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic-backports main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main universe restricted
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ bionic main universe restricted
- 更新源
sudo apt-get update
YOLOv5-5.0
现在,我们要在NX上安装YOLOv5-5.0算法库,首先安装Anaconda,创建虚拟环境,之后克隆YOLOv5-5.0仓库到NX,安装所需要的包,最后下载yolov5.pt进行推理测试
虚拟环境
在NX的Chromium浏览器中,直接搜索Anaconda,到官网进行下载,注意要下载ARM64版本的,默认下载到Downloads文件夹下

也可以直接使用wget命令,在Terminal中进行下载,执行bash命令进行安装:
wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-aarch64.sh
bash Anaconda3-2022.05-Linux-aarch64.sh
之后一路Enter+yes,直到安装完成
重新打开Terminal,发现命令行最前面有了(base),下面创建YOLOv5-5.0的虚拟环境:
(base) nx@ubuntu:~$ conda create -n yolo python=3.6 -y
(base) nx@ubuntu:~$ conda activate yolo
下载v5.0仓库
在YOLOv5官网找到v5.0版本的仓库,直接下载到NX,然后cd到yolov5-5.0仓库
在yolo虚拟环境中,安装对应库:
(base) nx@ubuntu:~$ conda activate yolo
(yolo) nx@ubuntu:~$ cd yolov5-5.0/
(yolo) nx@ubuntu:~/yolov5-5.0$ pip install -r requirements.txt
推理Demo
下载yolov5.pt到yolov5-5.0文件夹中,执行detect.py进行测试:(注意,如果直接执行python detect.py,会自动下载最新版本的yolov5.pt,而不是5.0版本的,因为5.0版本和最新版本网络结构不同,因此会报错)
(yolo) nx@ubuntu:~/yolov5-5.0$ wget https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.pt
(yolo) nx@ubuntu:~/yolov5-5.0$ python detect.py
结果如下:
 bus bus
|
 zidane zidane
|
VScode连接NX
参考:VSCode使用Remote SSH连接远程服务器
USB摄像头实时检测
首先,准备一个摄像头,可以是USB摄像头,或者官方配置的CSI-2接口摄像头,插到NX上
其次,修改datasets.py中的280行代码为:if 'youtube.com/' in str(url) or 'youtu.be/' in str(url):

然后,为了显示实时FPS,需要修改以下两个文件: datasets.py和detect.py
1、datasets.py:
2、detect.py:
最后,在Terminal中执行命令:python detect.py --source 0,结果如下:
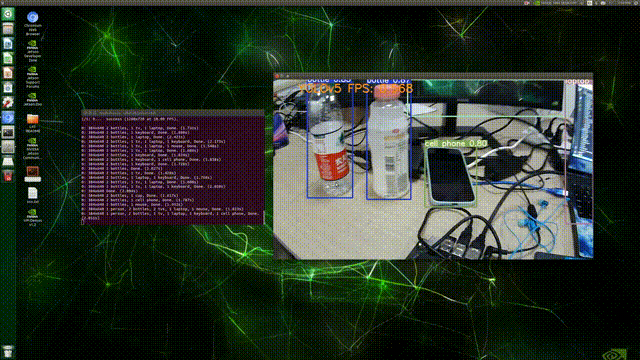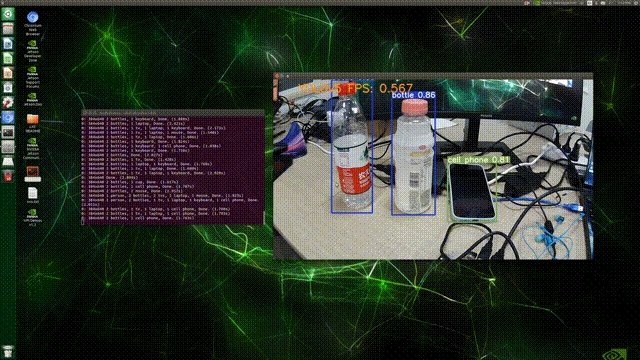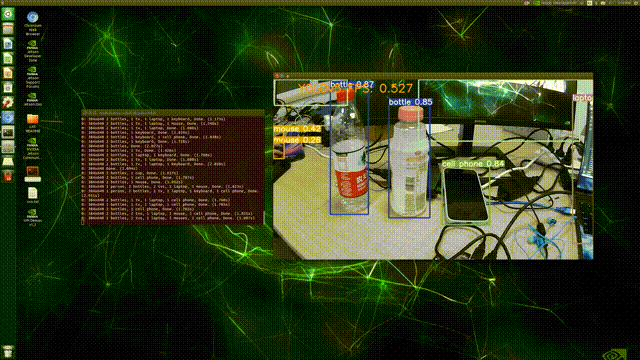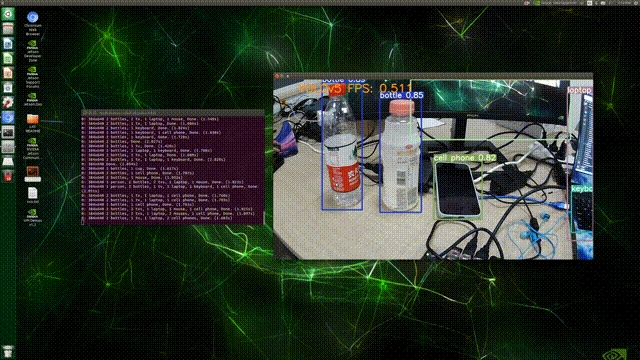
(PS:这FPS实在是太感人了/(ㄒoㄒ)/~~,不过检测精度倒还可以(●ˇ∀ˇ●))
模型转换
接下来,是本文的重头戏:使用TensorRT加速部署YOLOv5!!!!基本流程如下:
- 使用tensorrtx/yolov5中的
gen_wts.py文件,在yolov5-5.0中将yolov5.pt转换为yolov5.wts文件 - 在tensorrtx/yolov5中进行编译,生成可执行文件yolov5
- 使用yolov5可执行文件来生成
yolov5.engine文件,即TensorRT模型
pt–>wts(在yolov5-5.0)
首先,下载tensorrtx-yolov5-v5.0,注意要选择yolov5-5.0版本,然后将tensorrtx-yolov5-v5.0/yolov5/gen_wts.py复制到yolov5-5.0/中,然后执行命令就可以在当前目录下,生成yolov5.wts文件
(yolo) nx@ubuntu:~/yolov5-5.0$ python gen_wts.py -w yolov5s.pt
wts–>engine(在tensorrtx-yolov5-v5.0)
之后切换到tensorrtx-yolov5-v5.0/yolov5/目录,新建build文件夹,然后cd到build文件夹中,进行编译:
(yolo) nx@ubuntu:~$ cd tensorrtx-yolov5-v5.0/yolov5/
(yolo) nx@ubuntu:~/tensorrtx-yolov5-v5.0/yolov5$ mkdir build
(yolo) nx@ubuntu:~/tensorrtx-yolov5-v5.0/yolov5$ cd build
(yolo) nx@ubuntu:~/tensorrtx-yolov5-v5.0/yolov5/build$ cmake ..
(yolo) nx@ubuntu:~/tensorrtx-yolov5-v5.0/yolov5/build$ make
!!此时要注意!! 如果我们要转换自己训练的模型,需要在编译前修改yololayer.h中的参数:
static constexpr int CLASS_NUM = 80; // 数据集的类别数
static constexpr int INPUT_H = 608;
static constexpr int INPUT_W = 608;
将其中的CLASS_NUM修改为自己的类别数量,然后重新执行上述编译流程
此时编译完成,生成了可执行文件yolov5,我们可以用这个可执行文件来生成.engine文件,首先把上一步得到的yolov5s.wts文件复制到build目录下,然后执行如下命令生成yolov5s.engine:
(yolo) nx@ubuntu:~/tensorrtx-yolov5-v5.0/yolov5/build$ sudo ./yolov5 -s yolov5s.wts yolov5s.engine s
注意,这条指令中最后一个参数s表示模型的规模为s,如果我们使用的模型规模为n,l或x,需要把s改成对应的n,l或x
成功生成yolov5s.engine后就可以执行下述代码来进行一个小测试:
(yolo) nx@ubuntu:~/tensorrtx-yolov5-v5.0/yolov5/build$ ./yolov5 -d yolov5s.engine ../samples
此时在build目录下会得到检测的结果图,可以查看检测的效果:
 bus bus
|
 zidane zidane
|
USB摄像头实时检测
在生成yolov5s.engine之后,修改yolov5.cpp代码,调用USB摄像头实现实时检测,代码参考自:Jetson nano + yolov5 + TensorRT加速+调用usb摄像头,将以下代码直接替代yolov5.cpp原来的代码:
#include (end - start).count() << "ms" << std::endl;
int fps = 1000.0 / std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << "fps: " << fps << std::endl;
std::vector<std::vector<Yolo::Detection>> batch_res(fcount);
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
nms(res, &prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);
}
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
//std::cout << res.size() << std::endl;
//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
for (size_t j = 0; j < res.size(); j++) {
cv::Rect r = get_rect(frame, res[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 6);
std::string label = my_classes[(int)res[j].class_id];
cv::putText(frame, label, cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
std::string jetson_fps = "Jetson Xavier NX FPS: " + std::to_string(fps);
cv::putText(frame, jetson_fps, cv::Point(11, 80), cv::FONT_HERSHEY_PLAIN, 3, cv::Scalar(0, 0, 255), 2, cv::LINE_AA);
}
//cv::imwrite("_" + file_names[f - fcount + 1 + b], img);
}
cv::imshow("yolov5", frame);
key = cv::waitKey(1);
if (key == 'q') {
break;
}
fcount = 0;
}
capture.release();
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
return 0;
}
注意事项:
- 修改数据集类别名称

- 修改调用摄像头序号
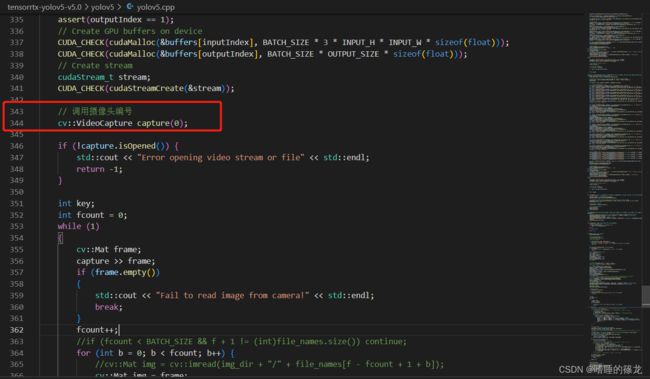
- 可选:修改摄像头输出信息
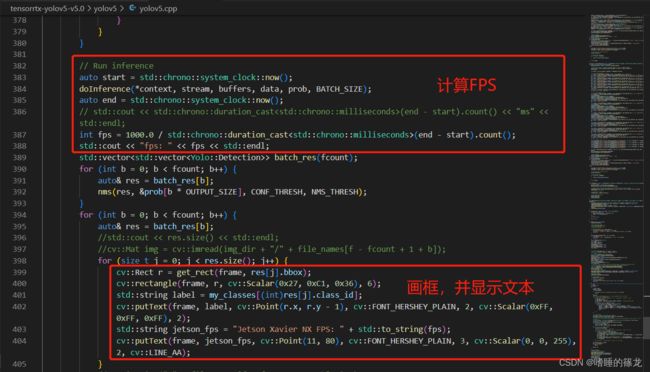
之后再次进行编译,然后执行测试代码:
(yolo) nx@ubuntu:~/tensorrtx-yolov5-v5.0/yolov5/build$ make
(yolo) nx@ubuntu:~/tensorrtx-yolov5-v5.0/yolov5/build$ sudo ./yolov5 -v yolov5s.engine
结果如下:
(PS:这次是真的很感人好不好!!!)
DeepStream部署
安装
1、安装前注意版本对应,Jetpack和DeepStream对应如下表:
| Jeppack | DeepStream |
|---|---|
| 4.6 | 6.0 |
| 4.5.1 | 5.1 |
| 4.4.1 | 5.0 |
本文安装的Jetpack版本为4.6,因此安装对应的DeepStream-6.0
2、安装相关依赖
执行以下命令以安装需要的软件包:
sudo apt install \
libssl1.0.0 \
libgstreamer1.0-0 \
gstreamer1.0-tools \
gstreamer1.0-plugins-good \
gstreamer1.0-plugins-bad \
gstreamer1.0-plugins-ugly \
gstreamer1.0-libav \
libgstrtspserver-1.0-0 \
libjansson4=2.11-1
3、安装DeepStream SDK
在第1步已经下载 DeepStream 6.0 Jetson tar package deepstream_sdk_v6.0.0_jetson.tbz2, 到 NX上了,现在输入以下命令以提取并安装DeepStream SDK:
sudo tar -xvf deepstream_sdk_v6.0.0_jetson.tbz2 -C / cd /opt/nvidia/deepstream/deepstream-6.0
sudo ./install.sh
sudo ldconfig
Demo测试
安装完成进入官方例程文件夹
cd /opt/nvidia/deepstream/deepstream-6.0/samples/configs/deepstream-app/
#测试一下
deepstream-app -c source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt
这个例程打开速度较慢,耐心等待,结果如下:
加速部署YOLOv5(Coming soon)
CSI-2摄像头实时检测(Coming soon)
Reference
Jetson“家族”在NVIDIA的定位是什么?对比市面上其他嵌入式平台,Jetson有什么优势?
Jetson Xavier NX 刷机+更换清华源完美讲解
Jetson开发实战记录(二):Jetson Xavier NX版本区别以及烧录系统
Jetson开发实战记录(三):Jetson Xavier NX具体开发(Ubuntu18.04系统)
YOLOV5环境快速配置 Jetson Xavier NX 版本(基本详细)
Jetson Xavier NX 部署Yolov5
Jetson nano上部署自己的Yolov5模型(TensorRT加速)
Jetson nano + yolov5 + TensorRT加速+调用usb摄像头
yolov5s模型转tensorrt+deepstream检测+CSI和USB摄像头检测
Jetson AGX Xavier实现TensorRT加速YOLOv5进行实时检测