项目中解决redis缓存击穿和缓存穿透两大常见问题
真快,今天都是农历2020年腊月二十三啦,也就是我们北方人所称呼的“小年”,家里的父老乡亲们都以背起行囊回到了家乡,然而我还在一线进行奋斗着辛苦搬砖,公司马上也要快放假了,我这上周给大家承诺的分享项目中解决redis缓存击穿和缓存穿透问题还没兑现呢,最近出来新项目一直在赶赶、、、现在闲下来一会,赶紧写这篇文章给大家分享下,废话少说,开始干,干就完了,接下来开始。
redis的详细描述我在之前已经写过了两篇,分别是:说会redis的帅哥都拿到了月入过万 和 咳咳,会用redis的帅哥拿到了上万,我这会用redis,还会配置redis的小鲜肉最低也待18k吧 这两篇,分别讲的是redis和springBoot的整合和用法,以及redis的各种配置等等,这里我就不过多聊这方面内容了哈,这里主要讲在项目中使用redis带来的几大问题。
一:缓存击穿、缓存穿透和缓存雪崩概念以及解决思路描述
1、缓存穿透(查询结果缓存中和数据库中都不存在):在使用缓存的情况下,我们查询数据时会先查询缓存,假如缓存中不存在,那么就会在数据库中查询,数据库中查询到的话会将查询的数据返回而且会将数据暂存在缓存中一份。缓存穿透可以理解为查询数据,这个时候缓存中不存在,然后进行去数据库中查询,数据库中也不存在。当持续查询某一数据时,查询数据压力全部扔给了数据库,这个时候数据库不堪压力,给崩掉了,这个时候就是缓存穿透。例如:id为-1的值肯定不存在,黑客持续访问这个id为-1的值,缓存中不存在,数据库中也不存在,数据库在持续的扛着高并发,当数据库承受不住的时候,数据库就给挂掉了,这就是缓存穿透。
可以采用布隆过滤器(这里不再详述,后期深入研究后进行补充),或者去数据库中查询,数据库中不存在,返回不存在同时在缓存中暂存为null值,这样等下次再来查询时就不需要再走刚刚的那重复步骤去数据库中查询,可以减轻数据库压力。
2、缓存击穿(量太大,缓存过期):缓存穿透和缓存击穿的区别是,缓存穿透是缓存中没有这个key,然后进数据库进行查询,但是数据库中也查询不到,在持续抗高并发,持续大量的去访问不存在的数据库,那么数据库不堪压力,最终挂掉;缓存击穿可以把缓存当作一堵墙,所有火力打在这堵墙上的某一个点上,把这个墙上的这一点给打穿,然后大量的火力穿透这堵墙上这一点直接打在数据库上,这时候数据库不堪压力,最后给崩掉。用官方话可以说:当缓存中的一个key值是非常热点,不停的抗高并发,高并发数据集中对这个key进行访问,当key值失效的瞬间,会访问数据库来访问数据,导致数据库压力过大,数据库瞬间崩掉。例如微博中爆料当某某明星出轨时,是一个非常热的热点,当这个key失效时,数据库受不了压力就会挂掉。这个时候就是我们常称为微博因某某明星出轨给挂掉了。
解决方案:1、设置key值永不过期;2、加互斥锁,只保证只有一个线程能够进去访问数据库,其余都进行等待。
3、缓存雪崩:在一段时间段内,缓存集中过期失效,Redis宕机。例如:双十一期间,凌晨十二点开始抢购,key值的有效期是一个小时,那么在凌晨一点的时候,会失效,那么压力全部打在了存储层,这个时候服务器就会造成周期性压力。
解决方案:1、利用redis的高可用性,多准备几台服务器,也就是异地多活,当其中一台服务器挂了,那么其他redis服务器可以进行工作,也就是搭建集群。
2、限流降级,在缓存失效之后,通过加锁或者队列来控制数据库写缓存的数量,比如某一个key只能允许一个线程查询和写缓存,其他线程等待。
二:简单讲下项目中引入redis
1、引入pom依赖:
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>2.9.0version>
dependency>
2、创建工具类RedisUtil类,代码如下:
package com.ygl.gmall.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class RedisUtil {
private JedisPool jedisPool;
public void initPool(String host,int port ,int database){
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(200);
poolConfig.setMaxIdle(30);
poolConfig.setBlockWhenExhausted(true);
poolConfig.setMaxWaitMillis(10*1000);
poolConfig.setTestOnBorrow(true);
jedisPool=new JedisPool(poolConfig,host,port,20*1000);
}
public Jedis getJedis(){
Jedis jedis = jedisPool.getResource();
return jedis;
}
}
3、创建RedisConfig配置类
package com.ygl.gmall.conf;
import com.ygl.gmall.util.RedisUtil;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RedisConfig {
//读取配置文件中的redis的ip地址
@Value("${spring.redis.host:disabled}")
private String host;
@Value("${spring.redis.port:0}")
private int port;
@Value("${spring.redis.database:0}")
private int database;
@Bean
public RedisUtil getRedisUtil(){
if(host.equals("disabled")){
return null;
}
RedisUtil redisUtil=new RedisUtil();
redisUtil.initPool(host,port,database);
return redisUtil;
}
}
目录如下图所示,我这里把redis配置类和工具类统一放在了service的工具类模块中。
4、接下来在yml中配置redis的连接地址和端口号等,注意:一定一定是在哪里使用就在那里的yml中去编写,千万不要在引入的工具类和配置类的模块中编写redis配置。我们这里在service模块中使用,那么我们在service的yml文件去编写配置文件。配置如下:
spring:
#redis配置
redis:
#redis地址
host: 192.168.80.133
#端口号
port: 6379
database: 0
好了,这里就用好了,接下来就可以在项目中使用redis了。
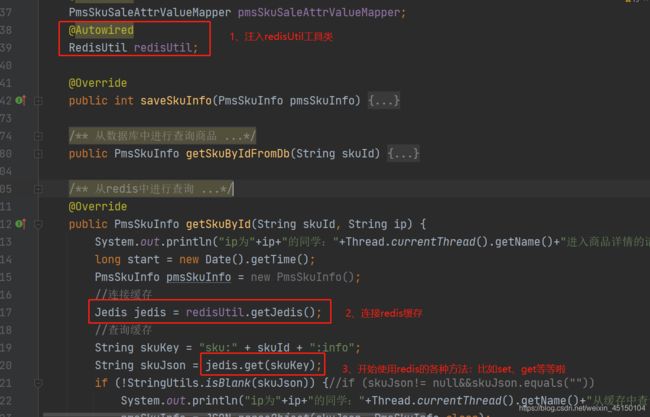
使用方法如下图所示:
4、解决redis的缓存穿透问题
首先我先用一张图给大家解释下解决缓存穿透的思路:
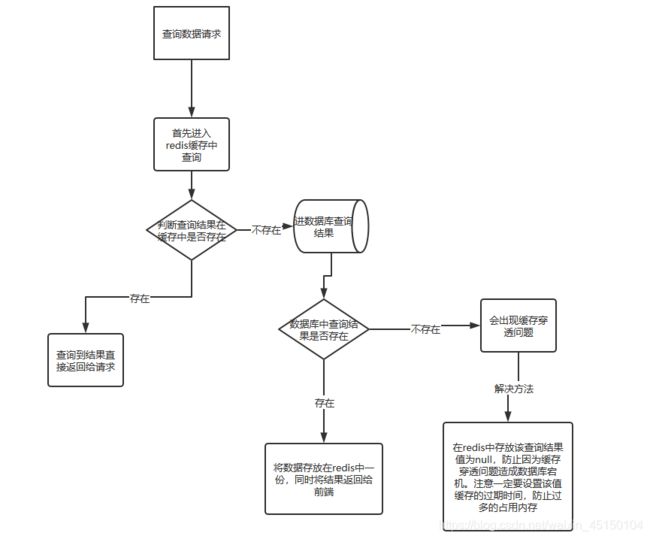 上图给大家非常清晰的描述出解决缓存穿透的问题,我在给大家解释下上面图描述的含义:当请求查询数据结果时,首先进入redis缓存中进行查询结果是否存在,如果存在结果,那么直接将该结果进行返回给前端;如果不存在,那么则需要去数据库中查询数据,如果在数据库中查询到该结果,那么将该结果返回给请求端,同时将该结果存放在redis缓存中,方便下次查找时直接在redis缓存中就可以查询到,进而不需要再进数据库中查询,因而下次查询时直接进redis查询,提高了非常高的查询效率。如果数据库中也查询不到结果,那么我们就要采用方法防止因缓存穿透造成数据库服务器压力过大,进而服务器宕机;我们可以采用布隆过滤器解决,这里我们将采用另外一种方法解决,就是将该结果设置成null值,存放在缓存中,而且要设置过期时间,减小缓存压力。
上图给大家非常清晰的描述出解决缓存穿透的问题,我在给大家解释下上面图描述的含义:当请求查询数据结果时,首先进入redis缓存中进行查询结果是否存在,如果存在结果,那么直接将该结果进行返回给前端;如果不存在,那么则需要去数据库中查询数据,如果在数据库中查询到该结果,那么将该结果返回给请求端,同时将该结果存放在redis缓存中,方便下次查找时直接在redis缓存中就可以查询到,进而不需要再进数据库中查询,因而下次查询时直接进redis查询,提高了非常高的查询效率。如果数据库中也查询不到结果,那么我们就要采用方法防止因缓存穿透造成数据库服务器压力过大,进而服务器宕机;我们可以采用布隆过滤器解决,这里我们将采用另外一种方法解决,就是将该结果设置成null值,存放在缓存中,而且要设置过期时间,减小缓存压力。
上面思路有了,那么我们开始上代码来解决其带来的缓存穿透问题:
package com.ygl.gmall.manage.service.impl;
import com.alibaba.dubbo.common.utils.StringUtils;
import com.alibaba.dubbo.config.annotation.Service;
import com.alibaba.fastjson.JSON;
import com.ygl.gmall.bean.PmsSkuAttrValue;
import com.ygl.gmall.bean.PmsSkuImage;
import com.ygl.gmall.bean.PmsSkuInfo;
import com.ygl.gmall.bean.PmsSkuSaleAttrValue;
import com.ygl.gmall.manage.mapper.PmsSkuAttrValueMapper;
import com.ygl.gmall.manage.mapper.PmsSkuImageMapper;
import com.ygl.gmall.manage.mapper.PmsSkuSaleAttrValueMapper;
import com.ygl.gmall.manage.mapper.SkuInfoMapper;
import com.ygl.gmall.service.SkuService;
import com.ygl.gmall.util.RedisUtil;
import org.springframework.beans.factory.annotation.Autowired;
import redis.clients.jedis.Jedis;
import java.util.Date;
import java.util.List;
import java.util.UUID;
@Service
public class SkuServiceImpl implements SkuService {
@Autowired
RedisUtil redisUtil;
@Override
public PmsSkuInfo getSkuById(String skuId) {
PmsSkuInfo pmsSkuInfo = new PmsSkuInfo();
//连接缓存
Jedis jedis = redisUtil.getJedis();
//查询缓存
//设置redis的key值
String skuKey = "sku:" + skuId + ":info";
String skuJson = jedis.get(skuKey);
//判断查询的结果是否存在
if (!StringUtils.isBlank(skuJson)) {//if (skuJson!= null&&skuJson.equals(""))
//将查询的String类型转换为实体类
pmsSkuInfo = JSON.parseObject(skuJson, PmsSkuInfo.class);
} else {
//如果缓存中没有,去mysql中查询
//调用进数据库中查询结果方法
pmsSkuInfo = getSkuByIdFromDb(skuId);
//mysql查询结果存放在redis缓存中
if (pmsSkuInfo != null) {
//将实体转换为String
String s = JSON.toJSONString(pmsSkuInfo);
//将查询的结果设置到redis中
jedis.set("sku:" + skuId + ":info", s);
} else {
//如果该sku不存在
//为了防止缓存穿透,设置一个短暂的key的skuId过期,值为空。一定要设置过期时间,否则会造成占用内存
jedis.setex("sku:" + skuId + ":info", 60, "");
}
}
//关闭缓存
jedis.close();
return pmsSkuInfo;
}
/**
*进数据库中进行查询结果
*/
public PmsSkuInfo getSkuByIdFromDb(String skuId) {
PmsSkuInfo pmsSkuInfo = new PmsSkuInfo();
pmsSkuInfo.setId(skuId);
PmsSkuInfo pmsSkuInfo1 = skuInfoMapper.selectOne(pmsSkuInfo);
return pmsSkuInfo1;
}
}
好了,上面成功解决缓存穿透问题,下面分享解决缓存击穿问题。
5、解决缓存击穿问题
老规矩,先上图让大家理解:
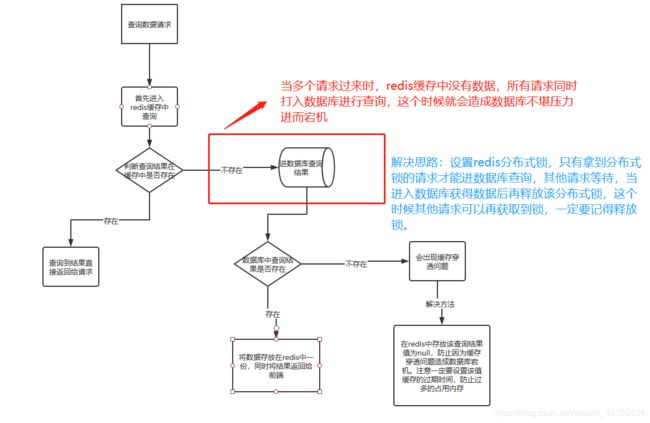
缓存击穿的定义在文章的刚开始就给大家解释了,刚刚在上图中又表述了下什么是缓存击穿和如何解决缓存击穿问题。这里我就不过多絮叨,直接在刚才解决缓存穿透的代码上进行更改,添加缓存击穿问题。代码如下:
package com.ygl.gmall.manage.service.impl;
import com.alibaba.dubbo.common.utils.StringUtils;
import com.alibaba.dubbo.config.annotation.Service;
import com.alibaba.fastjson.JSON;
import com.ygl.gmall.bean.PmsSkuAttrValue;
import com.ygl.gmall.bean.PmsSkuImage;
import com.ygl.gmall.bean.PmsSkuInfo;
import com.ygl.gmall.bean.PmsSkuSaleAttrValue;
import com.ygl.gmall.manage.mapper.PmsSkuAttrValueMapper;
import com.ygl.gmall.manage.mapper.PmsSkuImageMapper;
import com.ygl.gmall.manage.mapper.PmsSkuSaleAttrValueMapper;
import com.ygl.gmall.manage.mapper.SkuInfoMapper;
import com.ygl.gmall.service.SkuService;
import com.ygl.gmall.util.RedisUtil;
import org.springframework.beans.factory.annotation.Autowired;
import redis.clients.jedis.Jedis;
import java.util.Date;
import java.util.List;
import java.util.UUID;
@Service
public class SkuServiceImpl implements SkuService {
@Autowired
RedisUtil redisUtil;
@Override
public PmsSkuInfo getSkuById(String skuId) {
PmsSkuInfo pmsSkuInfo = new PmsSkuInfo();
//连接缓存
Jedis jedis = redisUtil.getJedis();
//查询缓存
//设置redis的key值
String skuKey = "sku:" + skuId + ":info";
String skuJson = jedis.get(skuKey);
//判断查询的结果是否存在
if (!StringUtils.isBlank(skuJson)) {//if (skuJson!= null&&skuJson.equals(""))
//将查询的String类型转换为实体类
pmsSkuInfo = JSON.parseObject(skuJson, PmsSkuInfo.class);
} else {
//如果缓存中没有,去mysql中查询
//设置分布式锁 token是设置分布式锁的value随机值
String token = UUID.randomUUID().toString();
//设置分布式锁,并且这种设置是只有当该key值不存在的情况下才能设置成功,否则设置失败,设置成功将返回OK,且过期时间是10s
String OK = jedis.set("sku:" + skuId + ":lock", token, "nx", "px", 10000);
if ((!StringUtils.isBlank(OK)) && OK.equals("OK")) {
//调用进数据库中查询结果方法
pmsSkuInfo = getSkuByIdFromDb(skuId);
//mysql查询结果存放在redis缓存中
if (pmsSkuInfo != null) {
//将实体转换为String
String s = JSON.toJSONString(pmsSkuInfo);
//将查询的结果设置到redis中
jedis.set("sku:" + skuId + ":info", s);
} else {
//如果该sku不存在
//为了防止缓存穿透,设置一个短暂的key的skuId过期,值为空。一定要设置过期时间,否则会造成占用内存
jedis.setex("sku:" + skuId + ":info", 60, "");
}
//在访问mysql后,要将mysql的分布式锁进行释放掉
String lockToken = jedis.get("sku:" + skuId + ":lock");
//判断lockToken不为空值且值与刚才生成的token相等,才表明就是自己的锁,否则可能会删除别人的锁,这样的话可以肯定删除的是自己的锁
//这里解决的问题就是: 如果redis锁已经过期了,然后锁过期的那个请求又执行完毕,回来删锁,删除了其他线程的锁怎么办?——可以采用判断key和value两个都相等来判断是否是自己的锁
if (!(StringUtils.isBlank(lockToken))&&lockToken.equals(token)){
jedis.del("sku:" + skuId + ":lock");//用token(也就是value和key两个一起判断)删除是否是自己的锁
}
}else{
//未成功获得分布式锁
//设置失败,开启自旋(线程睡眠几秒之后,重新尝试访问该方法)
return getSkuById(skuId);
}
}
//关闭缓存
jedis.close();
return pmsSkuInfo;
}
/**
*进数据库中进行查询结果
*/
public PmsSkuInfo getSkuByIdFromDb(String skuId) {
PmsSkuInfo pmsSkuInfo = new PmsSkuInfo();
pmsSkuInfo.setId(skuId);
PmsSkuInfo pmsSkuInfo1 = skuInfoMapper.selectOne(pmsSkuInfo);
return pmsSkuInfo1;
}
}
代码思维逻辑如下图所示:主要逻辑也就是请求获取分布式锁,请求获得分布式锁可以访问数据库,请求获得数据或者分布式锁因超时而自动释放,其他请求才可以再次获得锁。
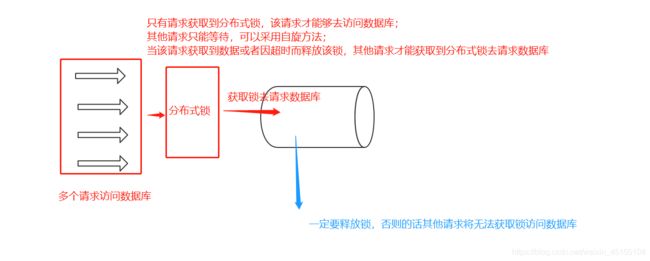 这里看似已经非常完美的解决了问题,其实还有问题存在,这个问题我用如图表示,我怕我用语言叙述的不清楚,图示如下:
这里看似已经非常完美的解决了问题,其实还有问题存在,这个问题我用如图表示,我怕我用语言叙述的不清楚,图示如下:
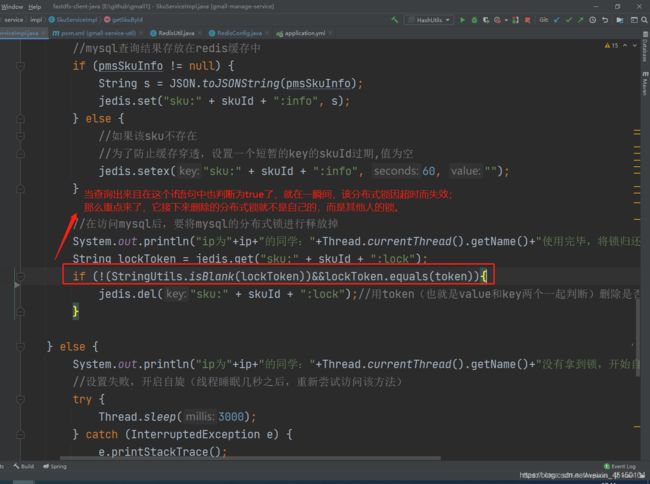 第一种方法:可以用lua脚本,在查询到key的同时删除该key,防止高并发时意外发生。
第一种方法:可以用lua脚本,在查询到key的同时删除该key,防止高并发时意外发生。
第二种方法:采用ression框架,将整个的操作片段给锁起来,防止其他请求过来,它的使用就类似与多线程的lock锁,我在这里就不详细描述,在图中我把代码分析下:
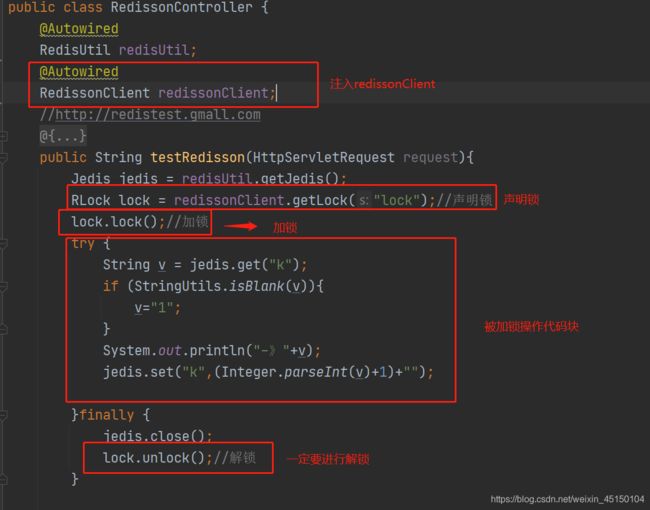 它这的用法和多线程的lock锁一样吧,我就不多谈了。
它这的用法和多线程的lock锁一样吧,我就不多谈了。
好了,这篇文章就分享到这了,大家有不懂的地方或者我讲的不对的地方,希望大家给我指出,谢谢大家。大家要记得三连哦,转发,点赞、收藏走一波 ,双击66666