LVS+Keepalived
群集的含义
Cluster,集群、群集
由多台主机构成,但对外只表现为一个整体,只提供一个访问入口(域名或IP地址),相当于一台大型计算机
问题
互联网应用中,随着站点对硬件性能、影响速度、服务稳定性、数据可靠性等要求越来越高,单台服务器已经无法满足负载均衡及高可用的要求
解决方法
使用价格昂贵的小型机、大型机
使用多台相对廉价的普通服务器构建集群
通过整合多台服务器,使用lvs来达到服务器的高可用和负载均衡,并以同一个IP地址对外提供相对的服务。
企业群集分类
群集的三种类型
负载均衡群集
高可用群集
高性能运算群集
负载均衡群集(Load Balance Cluster)
提高应用系统的响应能力、尽可能处理更多的访问请求、减少延迟为目标,获得高并发、高负载(LB)的整体性能
LB的负载分配依赖于主节点的分流算法,将来自客户机的访问请求分担给多个服务器节点,从而缓解整个系统的负载压力。例如,“DNS轮询”“反向代理”等
高可用群集(High Availability Cluster)
提高应用系统的可靠性、尽可能的减少中断时间为目标,确保服务的连续性,达到高可用(HA)的容错效果
HA的工作方式包括双工和主从两种模式,双工及所有节点同时在线;主从则只有主节点在线,当出现故障时从节点能自动切换为主节点。例如故障切换、双机热备等。
高性能运算群集(High Performance Computer Cluster)
以提高应用系统的CPU运算速度、扩展硬件资源和分析能力为目标,获得相当于大型、超级计算机的高性能运算(HPC)能力
高性能依赖于“分布式运算”、“合并计算”,通过装用硬件和软件将多个服务器的CPU、内存等资源整合在一起,实现只有大型、超级计算机才具备的计算机能力。例如,“云计算” “网格计算”等
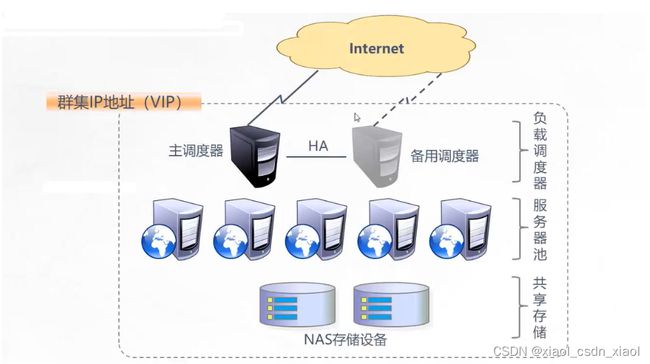
负载均衡集群架构
第一层负载调度器(Load Balancer或Director)
访问整个集群系统的唯一入口,对外使用所有服务器共有的VIP地址,也成为群集IP地址。通常会配置主,备两台调度器实现热备份,当主调度器失效以后能够平滑替换至备用调度器,确保高可用。
第二层服务器池(Srver Pool)
集群所提供的应用服务、由服务池承担,其中每个节点具有独立的RIP地址(真实IP),只处理调度器分发过来的客户机请求。当某个节点暂时失效时,负责调度器的容错机制会将其隔离,等待错误排除以后在重新纳入服务器池。
第三层共享储存(Share Storage)
为服务器池中的所有节点提供稳定、一致的文件存取服务,确保整个群集的统一性。共享储存可以使用NAS设备,或者提供NFS共享服务的专用服务器。
负载均衡的结构
keepalived工具介绍
专为LVS和HA设计的一款健康检查工具
持故障自动切换(Failover)
支持节点健康状态检查(Health Checking)
判断LVS负载调度器、节点服务器的可用性,当master主机出现故障及时切换到backup 节点保证业务正常,当master故障主机恢复后将其重新加入群集并且业务重新切换回master节点。
Keepalived实现原理剖析
Keepalived采用VRRP热备份协议实现Linux服务器的多机热备功能
VRRP(虚拟路由冗余协议)
是针对路由器的一种备份解决方案
由多台路由器组成一个热备组,通过共用的虚拟IP地址对外提供服务
每个热备组内同时只有一台主路由器提供服务,其他路由器处于冗余状态
若当前在线的路由器失效,则其他路由器会根据设置的优先级自动接替虚拟IP地址,继续提供服务
VRRP 相关术语
虚拟路由器:Virtual Router
虚拟路由器标识:VRID(0-255),唯一标识虚拟路由器
VIP:Virtual IP
VMAC:Virutal MAC (00-00-5e-00-01-VRID)
物理路由器:
master:主设备
backup:备用设备
priority:优先级
虚拟路由器的主备 是由priority:优先级决定的
VRRP工作过程
选举Master,比较优先级,高的为Master,若优先级相同无Master时,比较接口IP地址,大的为Master,Master设备发送ARP报文,承担报文转发工作;
状态维持,Master设备周期发送通告报文,公布配置信息和工作状态;
Backup设备根据收到的通告报文判断Master设备是否工作正常,如果Master设备主动放弃Master地位时,会发送优先级为0的通告报文,Backup设备收到后会快速切换成Master设备或者定时器超时后Backup设备认为Master设备无法正常工作,会切换状态为Master
当Master设备出现故障后怎么办
Master设备故障后,组内的备份设备一段时间(Master_Down_Interval定时器取值为:3×Advertisement_Interval+Skew_Time,单位为秒)内没有接收到来自Master设备的报文,则将自己转为Master设备。一个VRRP组里有多台备份设备时,短时间内可能产生多个Master设备,设备将会对收到的VRRP报文中的优先级与本地优先级做比较,从而选取优先级高的设备成为Master。
Master设备故障后恢复的时候会怎么样
Master设备恢复后,若其优先级为255则立即为Master设备,若优先级小于255,先切换为Backup设备,当Backup优先级高于Master设备时,如果此时工作模式为抢占模式,则Backup设备切换为Master设备,如果工作模式为非抢占模式,Backup设备不会切换为Master。(当设备切换为Master地位时都会发送免费ARP报文,承担报文转发功能)
Keepalived案例讲解

Keepalived可实现多机热备,每个热备组可有多台服务器
双机热备的故障切换是由虚拟P地址的漂移来实现,适用于各种应用服务器
Keepalived配置目录位于/etc/keepalived/
Keeplived及其工作原理
Keepalived是一个基于VRRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故障问题。
在一个LVS服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色的服务器,但是对外表现为一个虚拟IP。主服务器会发送VRRP通告信息给备份服务器,当备份服务器收不到VRRP消息的时候,即主服务器异常的时候,备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性
Keepalived体系主要模块及其作用
keepalived体系架构中主要有三个模块,分别是core、check和vrrp
core模块:为keepalived的核心,负责主进程的启动、维护及全局配置文件的加载和解析。
vrrp模块:是来实现VRRP协议的。
check模块:负责健康检查,常见的方式有端口检查及URL检查
LVS+Keepalived 高可用群集
结构图
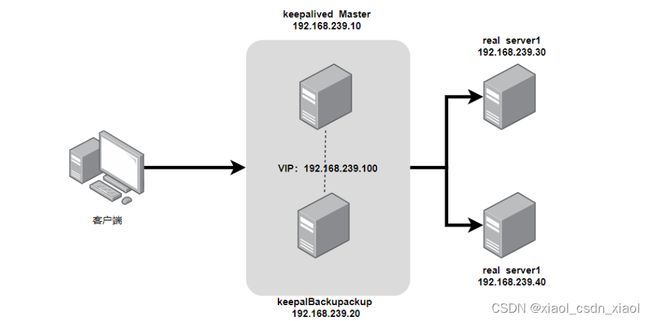
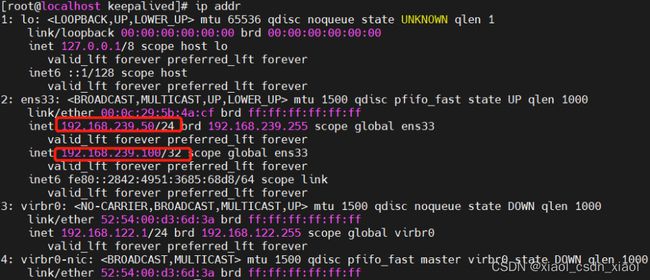
主DR 服务器:192.168.239.10
备DR 服务器:192.168.239.50
Web 服务器1:192.168.239.20
Web 服务器2:192.168.239.30
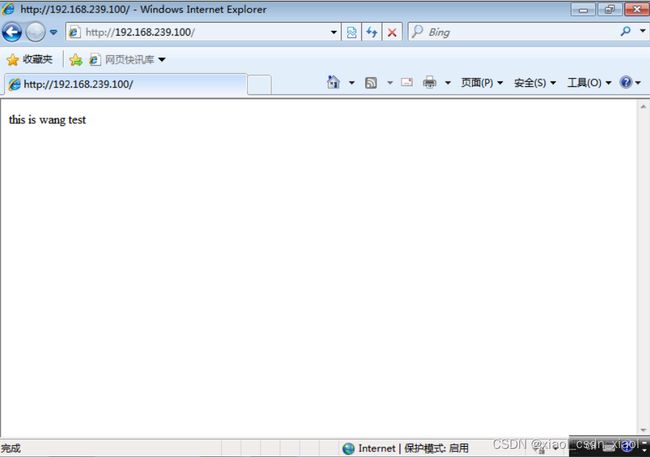
vip:192.168.239.100
NFS服务器:192.168.239.40
客户端:192.168.239.200
配置nfs共享服务器(192.168.239.40)


![]()

配置两台节点web服务器(192.168.239.20、192.168.239.30 )
第一台节点服务器(192.168.239.20)

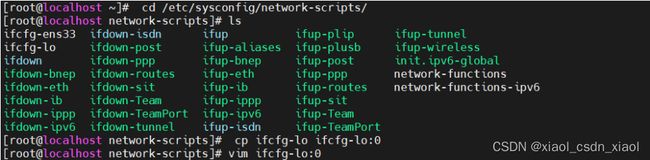

![]()
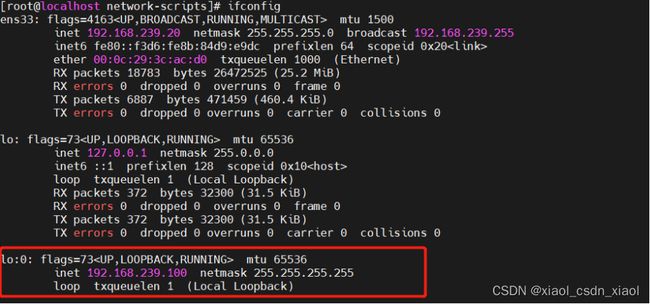

![]()
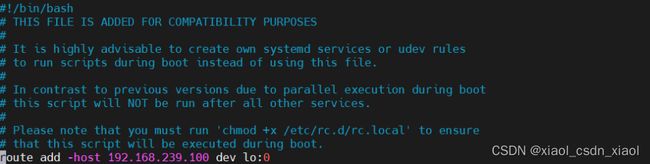
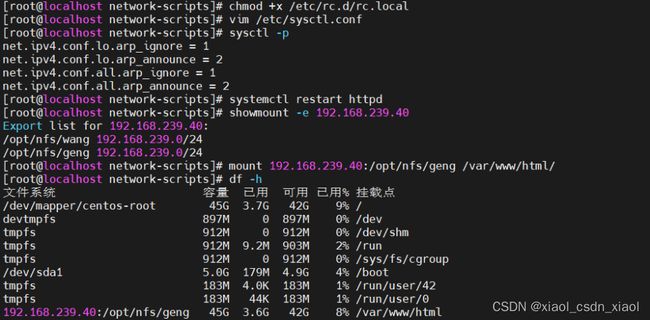
第二台节点服务器(192.168.239.30)
与第一台一致挂载文件不同
![]()
配置负载调度器(主:192.168.239.10)




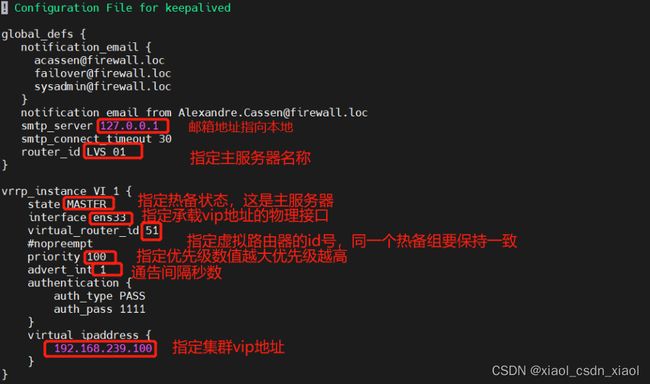

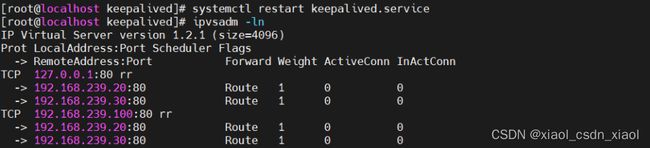



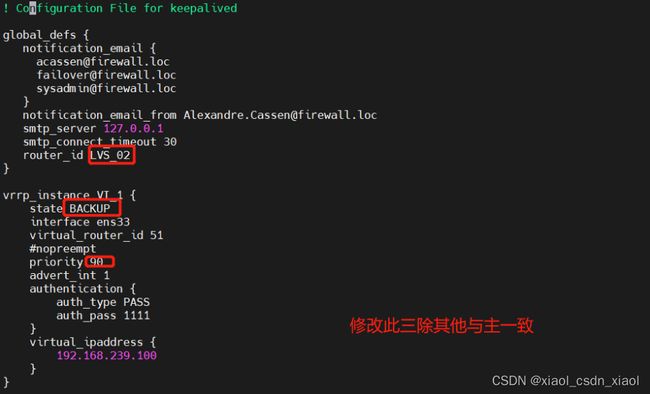
配置负载调度器(备:192.168.239.50)
与主配置一致唯一不同keepalived配置文件
![]()
测试
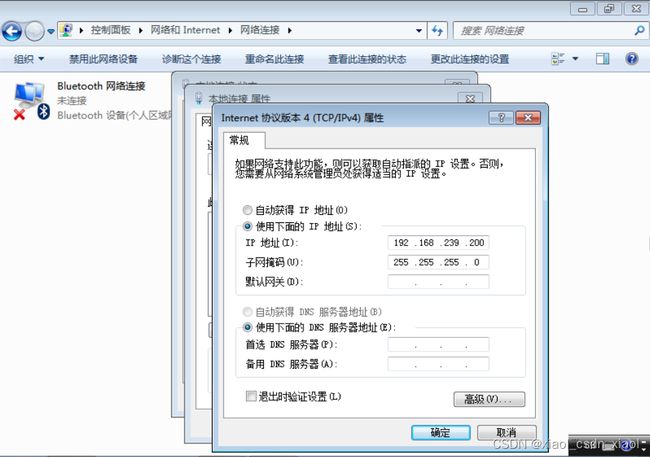
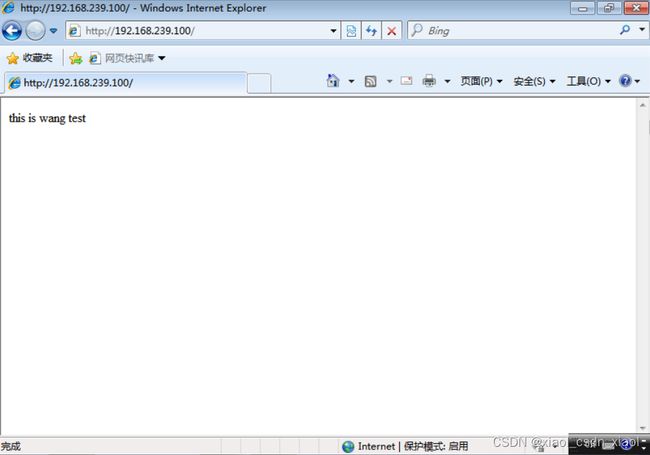
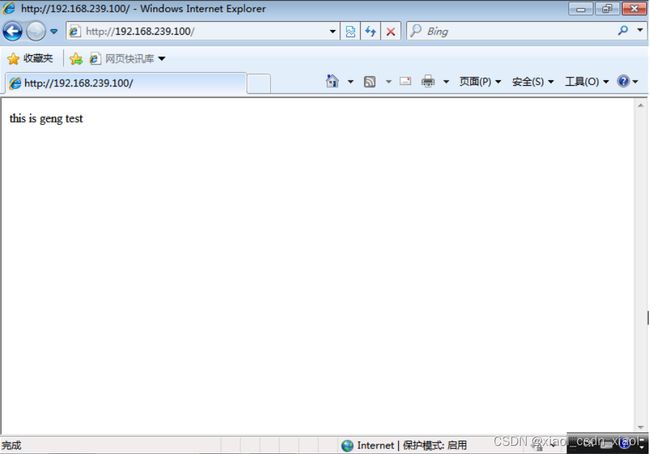
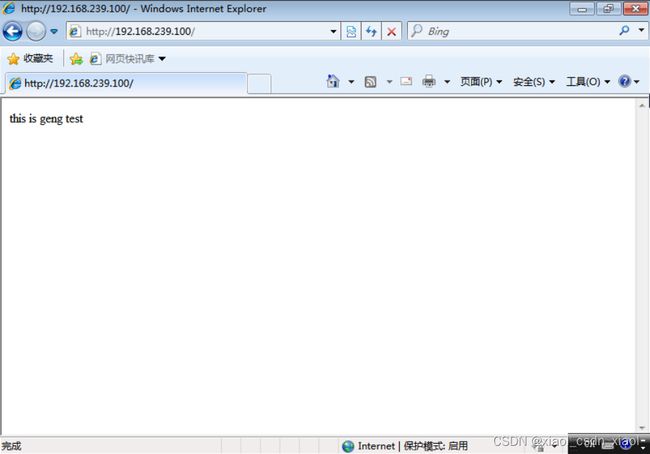
关闭主负载调度器的keepalived服务再次测试
![]()
此时备负载调度器则会将自己转为Master设备