在上一篇文章中,我们介绍了QueryByExampleExecutor动态查询的方法,那么今天我们来学习JpaSpecificationExecutor的详细用法。
1、JpaSpecificationExecutor用法
我们来创建实体类,第一步:创建User类和UserAddress类
// User类
@Data
@Entity
@NoArgsConstructor
@AllArgsConstructor
@Builder
@ToString(exclude = "address")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
private String name;
private String email;
@Enumerated(value = EnumType.STRING)
private SexEnum sex;
private Integer age;
private LocalDateTime createTime;
private LocalDateTime updateTime;
@OneToMany(mappedBy = "user",fetch = FetchType.EAGER)
private List address;
}
// Address类
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "user")
public class UserAddress {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String address;
@ManyToOne(cascade = CascadeType.ALL)
private User user;
}
// 性别枚举类
public enum SexEnum {
BOY,
GIRL
}
第二步:创建UserRepo ,我们继承JpaSpecificationExecutor接口
public interface UserRepo extends JpaSpecificationExecutor{ }
第三步:测试,构造查询条件
- name模糊查询
- sex精准查询
- age范围查询
- address的in查询
@Test
public void test02(){
User userQuery = User.builder()
.name("jack")
.email("[email protected]")
.sex(SexEnum.BOY)
.age(20)
.address(Lists.newArrayList(UserAddress.builder().address("shanghai").build()))
.build();
List userList = userRepo.findAll(new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder cb) {
List predicateList = new ArrayList<>();
// name模糊查询
if(StringUtils.isNotBlank(userQuery.getName())) {
predicateList.add(cb.like(root.get("name"),userQuery.getName()));
}
// sex精准查询
if(userQuery.getSex()!=null) {
predicateList.add(cb.equal(root.get("sex"),userQuery.getSex()));
}
// age范围查询
if(userQuery.getAge()!=null){
predicateList.add(cb.greaterThanOrEqualTo(root.get("age"),userQuery.getAge()));
}
// 关联查询
if(!ObjectUtils.isEmpty(userQuery.getAddress())) {
predicateList.add(cb.in(root.join("address").get("address")).value(userQuery.getAddress().stream().map(a->a.getAddress()).collect(Collectors.toList())));
}
return query.where(predicateList.toArray(new Predicate[predicateList.size()])).getRestriction();
}
});
System.out.println(userList);
}
SQL执行结果如下:
select user0_.id as id1_4_, user0_.age as age2_4_, user0_.create_time as create_t3_4_, user0_.email as email4_4_, user0_.name as name5_4_, user0_.sex as sex6_4_, user0_.update_time as update_t7_4_ from user user0_ inner join user_address address1_ on user0_.id=address1_.user_id where (user0_.name like ?) and user0_.sex=? and user0_.age>=20 and (address1_.address in (?))
2、JpaSpecificationExecutor语法详解
先看源码:
public interface JpaSpecificationExecutor{ Optional findOne(@Nullable Specification spec); List findAll(@Nullable Specification spec); Page findAll(@Nullable Specification spec, Pageable pageable); List findAll(@Nullable Specification spec, Sort sort); long count(@Nullable Specification spec); boolean exists(Specification spec); }
- findOne(@Nullable Specification spec):根据Specification 条件查询单个对象
- findAll(@Nullable Specification spec):根据Specification 条件, 查询List结果
- findAll(@Nullable Specification spec, Pageable pageable):根据Specification 条件, 分页查询
- findAll(@Nullable Specification spec, Sort sort):根据Specification 条件,带排序的查询结果
- count(@Nullable Specification spec): 根据Specification 条件,查询数量
- exists(Specification spec):根据Specification 条件,查询是否存在
2.1 Specification 接口

我们主要来看一下需要实现的方法:toPredicate(xx,xx,xx)
@Nullable Predicate toPredicate(Rootroot, CriteriaQuery query, CriteriaBuilder criteriaBuilder);
调试代码

我们可以分别看到Root的实现类是RootImpl,CriteriaQuery的实现类是CriteriaQueryImpl,CriteriaBuilder的实现类是CriteriaBuilderImpl。这三个实现类都是由Hibernate实现,也就是说JpaSepcificationExecutor封装了原本需要我们直接操作Hibernate中Criteria的API。
2.2 Root< User >root
解释:这个root就相当于查询和操作的实体对象的根,我们就可以通过Path get(xx)的方法,来获取我们想要操作的字段。
Path get(String attributeName);
例如:获取User实体类中的name字段
predicateList.add(cb.like(root.get("name"),userQuery.getName()));
2.3 CriteriaQuery query
这是一个Specific的顶层查询对象,它包含着查询的各个部分,比如select、from、where、group by 、Order by、distinct等。提供查询Root的方法,我们来看一下源码:
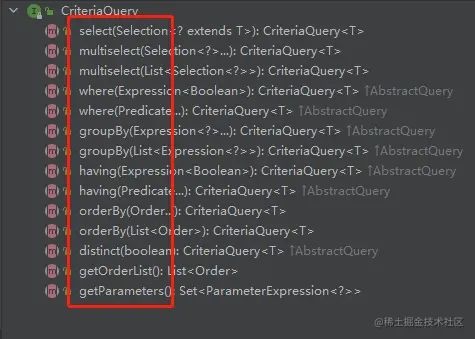
我们可以在上面的案例中看到query的用法:
return query.where(predicateList.toArray(new Predicate[predicateList.size()])).getRestriction();
我们可以再加一个groupBy的例子看看,如下所示:可以链式拼接
return query.where(predicateList.toArray(new Predicate[predicateList.size()])).groupBy(root.get("age")).getRestriction();
执行的SQL如下所示:
![]()
2.4 CriteriaBuilder cb
CriteriaBuilder是用来构建CritiaQuery的构建对象,其实就相当于条件或者条件组合,并以Predicate的形式返回,基本提供了所有常用的方法。

通过源码我们可以看到CriteriaBuilder 提供了and、any等用来查询条件的组合;还提供了between、equal、exist等用来做查询条件的查询。
例如:equal
predicateList.add(cb.equal(root.get("sex"),userQuery.getSex()));
例如:like
predicateList.add(cb.like(root.get("name"),userQuery.getName()));
例如:greaterThanEqualTo
predicateList.add(cb.greaterThanOrEqualTo(root.get("age"),userQuery.getAge()));
解释: 我们利用equal、like、greaterThanEqualTo 可以返回Predicate,而Predicate又可以组合起来,就构成了复杂的查询条件,完全满足日常开发使用。
以上就是Spring Data JPA系列JpaSpecificationExecutor用法详解的详细内容,更多关于Spring Data JPA JpaSpecificationExecutor的资料请关注脚本之家其它相关文章!