元宇宙人均月入过万?智联报告大揭秘(附下载);华盛顿大学·线性代数进阶课程;电子书·深度神经网络应用(Keras);前沿论文 | ShowMeAI资讯日报

日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子
人均『月入过万』?元宇宙领域就业现状究竟如何
自2021年元宇宙元年之后,大批元宇宙相关岗位如雨后春笋涌现在市场上。从耳熟能详的元宇宙社交、虚拟人、区块链,到大部分人极少接触的底层技术搭建,如何快速了解元宇宙行业?相关领域的发展前景如何?人才供需、薪资待遇、人才要求又有什么独特之处?智联招聘发布《2022元宇宙行业人才发展报告》,深入浅出解析元宇宙领域职场现状。
公众号回复『日报』获取完整版报告。
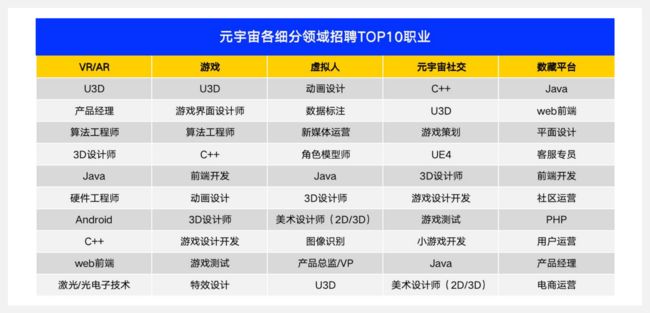
元宇宙技术在各行各业的应用情况
- 2022年1-7月元宇宙相关招聘岗位同比增长16.6%
- 元宇宙人才招聘高度集中在信息技术产业,向教培、传媒、制造等领域逐步渗透
- 一线城市元宇宙人才需求占全国一半,新一线城市增长快
- 政策发力下,武汉、杭州元宇宙人才需求增速亮眼
- 研发与设计岗是元宇宙主力军,U3D人才最吃香
- C语言、JAVA等底层技术是硬通货,3D建模、特效设计技能至关重要

元宇宙岗位薪资水平
- 2022元宇宙相关岗位平均薪资18515元/月
- 深度学习岗平均月薪39971元,位居榜首
- 人工智能技术“钱景光明”,复合型人才薪酬更高
工具&框架
『uie pytorch』通用信息抽取 UIE 的 PyTorch版
https://github.com/heiheiyoyo/uie_pytorch
Yaojie Lu 等人在 ACL-2022 中提出了通用信息抽取统一框架 UIE(Universal Information Extraction)。该框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力。
为了方便大家使用 UIE 的强大能力,PaddleNLP 借鉴该论文的方法,基于 ERNIE 3.0 知识增强预训练模型,训练并开源了首个中文通用信息抽取模型 UIE。
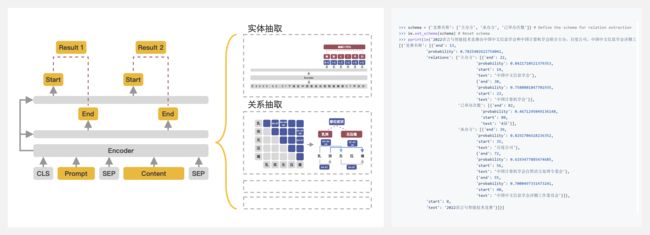
该模型可以支持不限定行业领域和抽取目标的关键信息抽取,实现零样本快速冷启动,并具备优秀的小样本微调能力,快速适配特定的抽取目标。本代码库是UIE的pytorch版本实现。

『MPSX』基于 MPSGraph 的 ONNX 推理引擎
https://github.com/prisma-ai/MPSX
https://prisma-ai.com/
MPSX 是一个基于 MPSGraph 的 ONNX 推理引擎,通过简单的几个步骤,你就可以用 MPSX 跑 ONNX 模型推理,不过大家需要熟悉 Metal API。
『GEEML』Google Earth Engine 机器学习包
https://github.com/Geethen/geeml
https://geethen.github.io/geeml/
GEEML 是一个 Python 工具包,它使得你可以方便使用并行处理和谷歌地球引擎的大容量终端,从谷歌地球引擎提取卫星数据。它支持以 csv 的形式提取传统机器学习的数据(表格数据)和提取 GeoTiff 图像补丁用于深度神经网络。它有以下特性:
- 支持并行导出图像或稀疏图像(例如,GEDI)
- 支持导出点或多边形的栅格值(ee.FeatureCollection)
- 支持归纳多边形内的栅格数据(ee.FeatureCollections)
- 支持提取表格式和深度神经网络(DNN)类型的数据集

『Diffusion Bee』M1/M2芯片苹果电脑上的开源Stable Diffusion图形界面应用
https://github.com/divamgupta/diffusionbee-stable-diffusion-ui
https://diffusionbee.com/
Diffusion Bee 提供了最简单的方式在 M1 Mac 上本地运行 Stable Diffusion 模型用于 AI 创作,它配有一键式安装程序,不需要依赖性或技术知识。且模型完全在本地运行,没有数据被发送到云端。
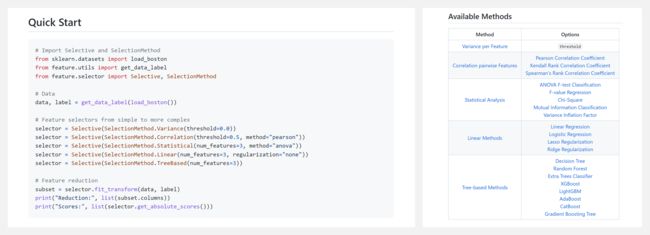
『Selective』白盒特征选择库
https://github.com/fidelity/selective
Selective 是一个白盒特征选择库,支持分类和回归任务的无监督和有监督的选择方法。具备以下特点:
- 支持简单到复杂的选择方法:方差法、相关法、统计法、线性法、基于树的法、或自定义法。
- 自动的任务检测。不需要指定特征选择方法适。
- 内置并行化的交叉验证对多个选择器测试。
- 检查结果和特征的重要性。
博文&分享
『MATH 318 A: Advanced Linear Algebra Tools and Applications』华盛顿大学 · 线性代数进阶工具与应用 · 课程
https://sites.math.washington.edu/~m318/
https://www.youtube.com/watch?v=R3IJWhzLzds&list=PLoxJTbDttvt4p6zPSy_0zURsJV1kDCqw1
Math 318 是一门线性代数进阶课程,讲解『矩阵』这一运算符和数据组织形式,重点是矩阵的结构、几何含义与应用。 注意!学习本课程前。需要掌握基础的线性代数知识。
课程前半部分的核心内容是特征值和特征向量,后半部分的核心内容是奇异值和一般矩阵的奇异值分解 (SVD)。除此之外,课程还讲解了一些新型的向量空间,如多项式向量空间(vector spaces of polynomials,应用于插值和求解多项式方程)、有限域上的向量空间(vector spaces over finite fields,应用于纠错码)和复向量空间(complex vector spaces,应用于傅里叶分析)。
- Eigenvalues and Diagonalization / 特征值和对角化
- Permutations and Determinant / 排列和行列式
- Difference Equations / 差分方程
- Nonnegative, Positive and Markov matrices / 非负、正和马尔可夫矩阵
- Orthogonality / 正交性
- Projections / 预测
- Symmetric matrices and Quadratic Forms / 对称矩阵和二次形式
- Positive Semidefinite Matrices / 半正定矩阵
- Polynomial Vector Spaces / 多项式向量空间
- Singular Value Decomposition / 奇异值分解
- Vector spaces over finite fields / 有限域上的向量空间
- Complex Vector Spaces / 复向量空间
『Applications of Deep Neural Networks with Keras』深度神经网络应用(Keras)·可下载书籍
https://github.com/jeffheaton/t81_558_deep_learning
书籍PDF:https://arxiv.org/pdf/2009.05673.pdf
作者 Jeff Heaton 自 2016 年开始,在圣路易斯华盛顿大学教授 T81-558 深度学习课程,并将课件与作业等资料放在GitHub上,并整理为此书。作者使用 Tensorflow 创建了最开始版本的内容,后续迁移到了 Keras,并在部分章节使用了 PyTorch 等更多库。内容章节如下:
- Python Preliminaries / Python预备课程
- Python for Machine Learning / Python机器学习
- Introduction to TensorFlow / TensorFlow 简介
- Training for Tabular Data / 表格数据训练
- Regularization and Dropout / 正则化与Dropout
- Convolutional Neural Networks (CNN) for Computer Vision / 计算机视觉的卷积神经网络 (CNN)
- Generative Adversarial Networks / 生成对抗网络
- Kaggle Data Sets / Kaggle 数据集
- Transfer Learning / 迁移学习
- Time Series in Keras / Keras 中的时间序列
- Natural Language Processing with Hugging Face / Hugging Face与自然语言处理
- Reinforcement Learning / 强化学习
- Advanced/Other Topics / 高级/其他主题
- Other Neural Network Techniques / 其他神经网络技术

数据&资源
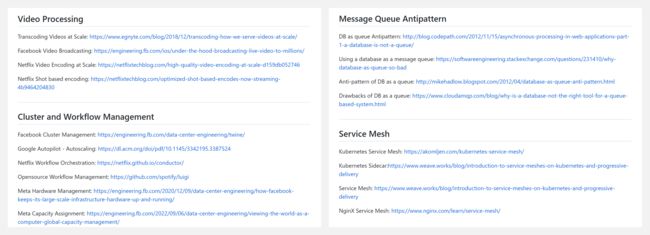
『System Design Resources』系统设计资源集
https://github.com/InterviewReady/system-design-resources
系统设计资源集,这里列写部分内容主题,更多内容可点击上方链接查看:
- Video Processing / 视频处理
- Cluster and Workflow Management / 集群和工作流管理
- Service Mesh / 服务网格
- Practical System Design / 实用系统设计
- Distributed File System / 分布式文件系统
- Time Series Databases / 时间序列数据库
- Network Protocols / 网络协议
- Subscription Management System / 订阅管理系统
- NoSQL Database Internals / NoSQL 数据库内部结构
- NoSQL Database Algorithms / NoSQL 数据库算法
- Database Replication / 数据库复制
- Containers and Docker / 容器和 Docker
- Capacity Estimation / 容量估算
- Microservices / 微服务
- Load Balancing / 负载均衡
- Alerts and Anomaly Detection / 警报和异常检测
- Distributed Logging / 分布式日志记录
- Batch Processing / 批量处理
- Real Time Stream Processing / 实时流处理
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.09.11 『神经网络』 Git Re-Basin: Merging Models modulo Permutation Symmetries
- 2022.09.09 『运动合成』 TEACH: Temporal Action Composition for 3D Humans
- 2022.08.25 『图像生成』 DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
⚡ 论文:Git Re-Basin: Merging Models modulo Permutation Symmetries
论文时间:11 Sep 2022
领域任务:神经网络
论文地址:https://arxiv.org/abs/2209.04836
代码实现:https://github.com/samuela/git-re-basin
论文作者:Samuel K. Ainsworth, Jonathan Hayase, Siddhartha Srinivasa
论文简介:Experimentally, we demonstrate the single basin phenomenon across a variety of model architectures and datasets, including the first (to our knowledge) demonstration of zero-barrier linear mode connectivity between independently trained ResNet models on CIFAR-10 and CIFAR-100./通过实验,我们在各种模型架构和数据集上证明了单盆现象,包括在CIFAR-10和CIFAR-100上首次(据我们所知)证明了独立训练的ResNet模型之间的零障碍线性模式连接。
论文摘要:深度学习的成功得益于我们能够相对容易地解决某些大规模的非凸优化问题。尽管非凸优化是NP-hard,但简单的算法–通常是随机梯度下降的变种–在实践中对大型神经网络的拟合表现出惊人的有效性。我们认为,在考虑了隐藏单元的所有可能的排列对称性之后,神经网络损失景观包含(几乎)一个单一的盆地。我们介绍了三种算法,对一个模型的单元进行排列,使其与参考模型的单元保持一致。这种转换产生了一组功能等同的权重,这些权重位于参考模型附近的一个近似于凸的盆地中。通过实验,我们在各种模型结构和数据集上证明了单盆地现象,包括在CIFAR-10和CIFAR-100上独立训练的ResNet模型之间首次(据我们所知)证明了零障碍线性模式连接。此外,我们还发现了有趣的现象,即在各种模型和数据集上,模型的宽度和训练时间与模式连接有关。最后,我们讨论了单一盆地理论的缺点,包括对线性模式连接假设的反例。

⚡ 论文:TEACH: Temporal Action Composition for 3D Humans
论文时间:9 Sep 2022
领域任务:Motion Synthesis, 运动合成
论文地址:https://arxiv.org/abs/2209.04066
代码实现:https://github.com/athn-nik/teach
论文作者:Nikos Athanasiou, Mathis Petrovich, Michael J. Black, Gül Varol
论文简介:In particular, our goal is to enable the synthesis of a series of actions, which we refer to as temporal action composition./我们的目标是实现一系列动作的合成,我们称之为时间性动作合成。
论文摘要:给定一系列自然语言描述,我们的任务是生成三维人类动作,这些动作在语义上与文本对应,并遵循指令的时间顺序。特别是,我们的目标是实现一系列动作的合成,我们称之为时间性动作合成。目前,文本条件下的动作合成技术只将单个动作或单个句子作为输入。这部分是由于缺乏合适的包含动作序列的训练数据,但也是由于其非自回归模型表述的计算复杂性,它不能很好地扩展到长序列。在这项工作中,我们解决了这两个问题。首先,我们利用了最近的BABEL动作文本集,它有广泛的标记动作,其中许多是在一个序列中出现的,并在它们之间有过渡。接下作的口述动作组合",为各种各样的动作和语言描述的时间组合产生现实的人类动作。为了鼓励这项新任务的工作,我们在我们的网站上提供了我们的代码供研究之用。


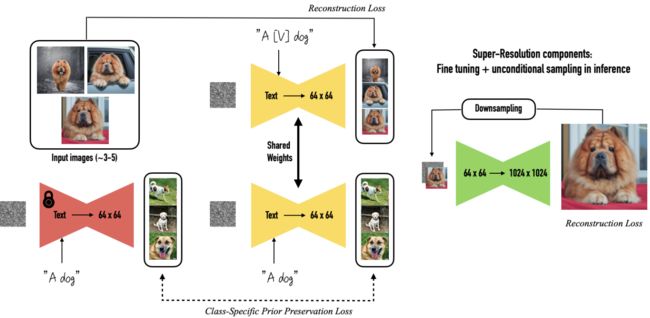
⚡ 论文:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
论文时间:25 Aug 2022
领域任务:Image Generation,图像生成
论文地址:https://arxiv.org/abs/2208.12242
代码实现:https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
论文作者:Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman
论文简介:Once the subject is embedded in the output domain of the model, the unique identifier can then be used to synthesize fully-novel photorealistic images of the subject contextualized in different scenes./一旦主体被嵌入到模型的输出域中,唯一的标识符就可以用来合成主体在不同场景中的完全创新的逼真图像。
论文摘要:大型文本-图像模型在人工智能的发展中实现了一个显著的飞跃,能够从给定的文本提示中合成高质量和多样化的图像。然而,这些模型缺乏模仿给定参考集中的主体外观和合成不同背景下的新颖演绎的能力。在这项工作中,我们提出了一种 "个性化 "的文本-图像扩散模型的新方法(根据用户的需要对其进行专业化处理)。只需输入一些主题的图像,我们就可以对预训练的文本-图像模型(Imagen,尽管我们的方法并不局限于一个特定的模型)进行微调,使其学会将一个独特的标识符与该特定主题绑定。一旦主题被嵌入到模型的输出域中,唯一的标识符就可以被用来合成该主题在不同场景中的全创新逼真图像。通过利用嵌入在模型中的语义先验和新的自体类先验保存损失,我们的技术能够在不同的场景、姿势、视角和照明条件下合成参考图像中没有出现的主体。我们将我们的技术应用于几个以前无法完成的任务,包括主体重构、文本指导的视图合成、外观修改和艺术渲染(同时保留主体的关键特征)。项目页面:https://dreambooth.github.io/


我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
